按IP自动跳转语言版本,正在悄悄让你的国际站半数页面进不了Google索引
本文目录
- 先把三件事分清楚:地理重定向、hreflang、语言切换器各管什么
- 老教程的“IP重定向毁SEO”,今天只对了一半
- 但Google官方到今天还是那句话:别自动重定向
- 为什么自动跳转会让你半数页面进不了索引
- IP定位本身就不靠谱:你在拿测不准的信号做硬决策
- 自动跳转的第二宗罪:把人锁死在猜错的语言里
- 正确姿势一:检测可以有,但只用来“建议”,不用来“执行”
- 正确姿势二:语言切换器的UX细节,别用国旗代表语言
- 正确姿势三:用户选了之后怎么记住,又不污染爬虫看到的URL
- 地基:每个版本都要有独立、稳定、可直链的URL
- hreflang和重定向的分工:一个写给机器,一个服务于人
- 如果你已经上了IP硬跳转,怎么安全拆掉
- 别把语言、地区、货币三个维度塞进同一个跳转
- 边缘案例:CDN、缓存和移动网络会让事情更糟
- AI搜索时代:自动跳转的新风险
- 一张决策表:什么时候检测、什么时候提示、什么时候绝不跳
- 落地清单:10步搭好“不强跳”的国际站路由
- 5个最常踩的误区
- 一个外贸站的真实节奏
- 常见问题解答
- 按IP自动跳转语言版本,到底会不会被Google当作惩罚项?
- 那我到底还能不能用IP做任何地理逻辑?
- 语言切换器用国旗图标到底有什么问题?
- 用户选过语言后,我用cookie帮他自动跳转可以吗?
- Googlebot现在能从多个国家抓取,是不是意味着IP跳转的老问题已经不存在了?
- 地区自适应(同一URL按IP返回不同内容)和独立URL,到底该选哪个?
- 权威参考资料
摘要:很多出海站做完域名结构、贴完hreflang,最后栽在一个看起来最贴心的功能上——按访客IP自动跳转语言版本。老教程说“IP重定向会毁掉SEO,因为Googlebot只从美国抓取”,这话今天只对了一半:Google早在2015年就加了地理分布抓取和带Accept-Language的抓取,能模拟不同国家的访客。但即便如此,Google官方到今天仍然写着一句话——避免在不同语言版本之间自动重定向用户。原因不在于“机器人看不到”,而在于自动跳转会同时挡住用户和爬虫看到全部版本,再叠加IP定位本身测不准,结果就是你的国际站有一批页面长期进不了索引、用户被锁死在猜错的语言里。这篇把地理重定向、hreflang、语言切换器三者的分工彻底掰开,给一套“检测就提示、提示让选择、选择能记住、每个版本都有独立可抓URL”的落地方案,外加拆除存量硬跳转的安全步骤和一张决策表。
先把三件事分清楚:地理重定向、hreflang、语言切换器各管什么
这三个词天天被混着说,但它们处在完全不同的层。混淆它们,是几乎所有自动跳转事故的起点。
- 地理重定向(geo-redirect):服务器或前端根据访客的IP、浏览器语言、或cookie,主动把访客送到另一个URL。它是一个“动作”,会改变用户实际落地的页面。
- hreflang:写在页面里的标注,告诉搜索引擎“这一组页面是同一内容的不同语言/地区版本”。它不传递权重、不是排名因素,只决定搜索结果里给哪个版本,它从不重定向任何人。
- 语言/地区切换器(language switcher):页面上一个让用户自己点选版本的控件。它把选择权交还给人,而不是替人做主。
一句话记住它们的边界:hreflang是写给机器看的对账单,切换器是留给人用的方向盘,而地理重定向是一只替所有人打方向盘的手——问题就出在这只手上。关于hreflang这一层怎么落地不踩坑,hreflang标签实施那篇里讲过return tags对称和canonical冲突;这篇专门处理“人和爬虫到底落在哪个URL”这个上游问题。
老教程的“IP重定向毁SEO”,今天只对了一半
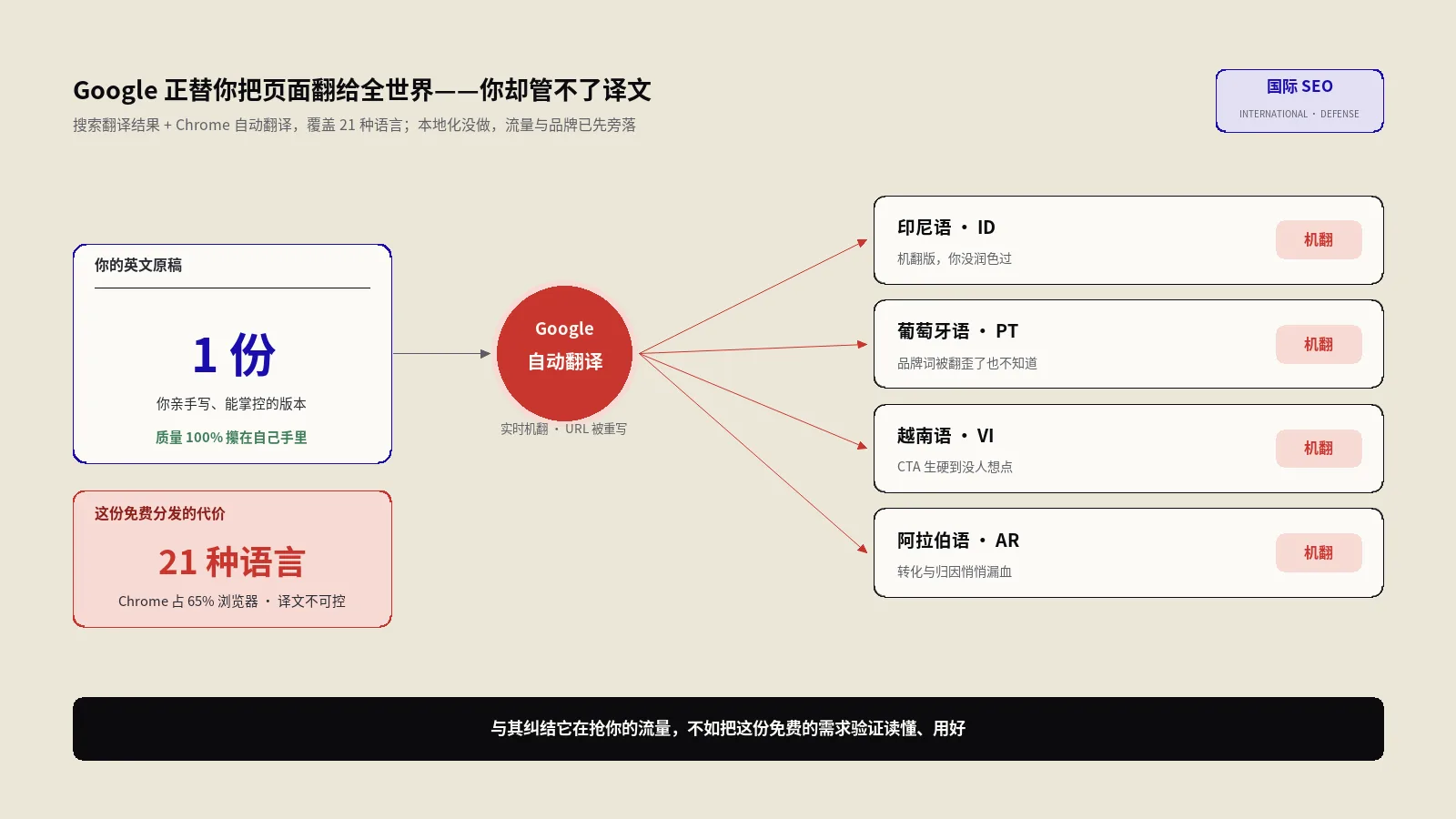
你大概率读到过这个说法:不要按IP跳转,因为Googlebot几乎只从美国IP抓取,你一跳转,它就只能看到美国版,其他国家版本永远抓不到、进不了索引。
这个逻辑在2014年之前基本成立。但2015年1月,Google公开说明了针对“地区自适应页面”(locale-adaptive pages)的两种新抓取方式:地理分布抓取——Googlebot会用美国以外的IP来抓;以及带语言的抓取——Googlebot会带上 Accept-Language 请求头来抓。换句话说,机器人现在能“假装”成德国访客或日本访客来看你的站。当年 Search Engine Land的报道也把这次变化解读成“Google终于支持抓取地区自适应页面了”。
于是市面上冒出第二种声音:“既然Googlebot能模拟各国访客,那IP跳转就没事了。”这个结论同样是错的,而且错得更危险,因为它给了人继续做硬跳转的借口。下一节说清楚为什么。
但Google官方到今天还是那句话:别自动重定向
翻开 Google现行的多区域站点管理文档,原话写得很直白:
“Avoid automatically redirecting users from one language version of a site to a different language version of a site.”(避免把用户从一个语言版本自动重定向到另一个语言版本。)
给出的理由是:“These redirections could prevent users (and search engines) from viewing all the versions of your site.”(这些重定向可能让用户和搜索引擎都看不到你网站的全部版本。)
推荐的替代做法:“Consider adding hyperlinks to other language versions of a page.”(考虑在页面上加指向其他语言版本的超链接。)
注意理由里那个并列的括号——“用户和搜索引擎”。Google反对自动跳转,从来不只是因为“爬虫的IP在美国”这种技术细节;它反对的是“替所有访客剥夺选择”这件事本身。地理分布抓取是Google自己加的能力,用来给那些已经在做地区自适应的站兜底,不是给你的硬跳转发许可证。同一份文档还补了一句关键的现状说明:“Most, but not all, Google crawls originate from the US, and we don't attempt to vary the location to detect site variations.”——大多数(但不是全部)抓取仍来自美国,而且Google不会主动变换位置去探测你的站点差异。两句话放一起读才完整:能力有,但不保证、不主动、不可依赖。
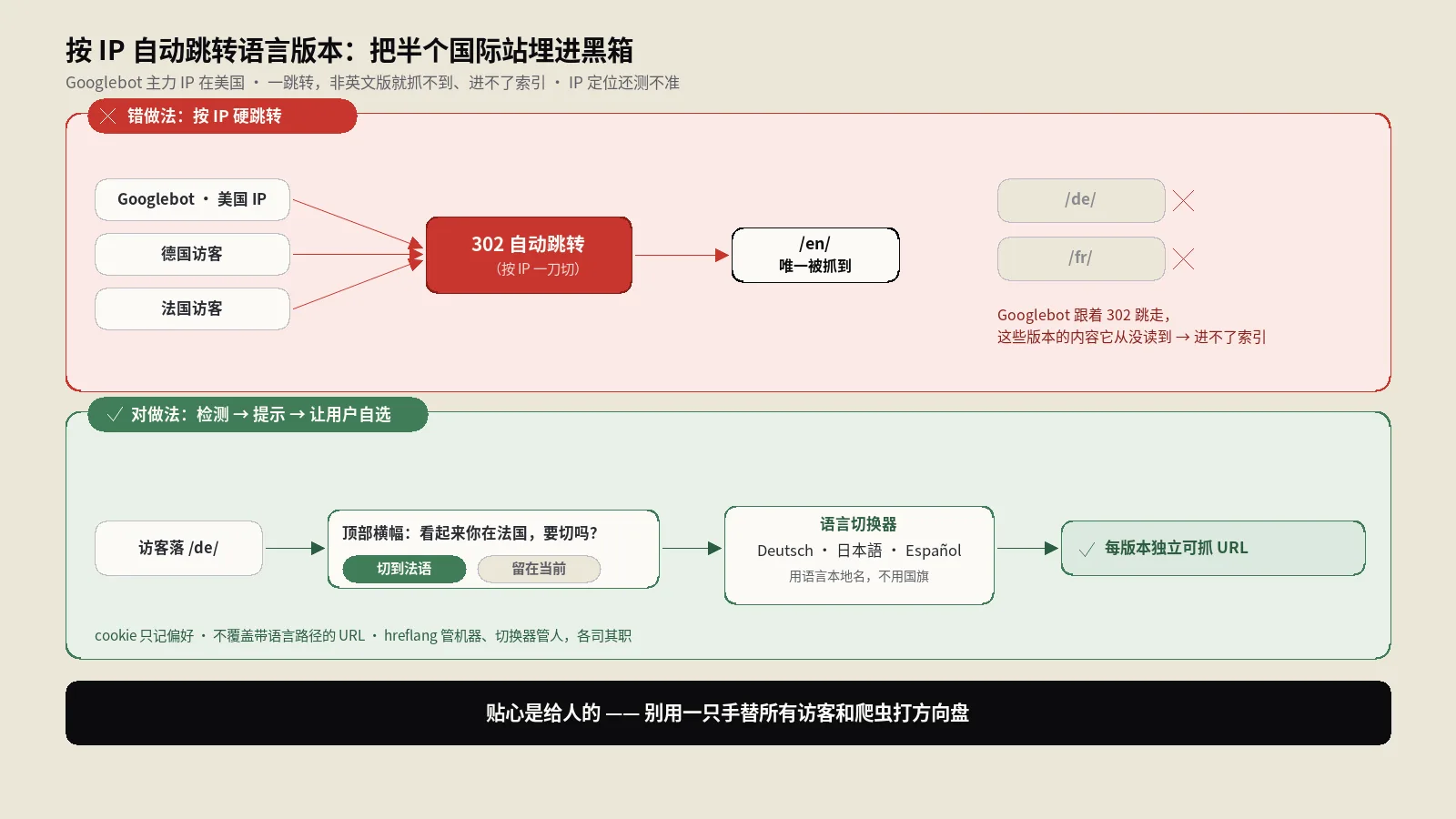
为什么自动跳转会让你半数页面进不了索引
把机制拆到最细,你就明白这不是玄学。假设你做了一个最常见的硬跳转:检测到非德国IP就302到 /en/,检测到德国IP就302到 /de/。
- Googlebot主力IP在美国,请求你的德语页
/de/produkt。 - 你的服务器一看是美国IP,按规则302把它送到
/en/product。 - Googlebot收到302,跟过去抓了
/en/product,然后把这个跳转记下来:它学到“/de/produkt会跳到/en/product”。 - 下次它倾向于直接抓目标页,德语页本身的内容它从没真正读到过。
结果就是:你以为上线了德语版,但在Google眼里德语URL只是一个永远指向英文的跳板,内容从未被收录。地理分布抓取理论上能缓解这点,可它只在Google“检测到你的页面是地区自适应”时才自动开启,触发条件不透明、覆盖不全、你无法控制也无法验证。把上索引这件大事押在一个你既不能开关也看不到日志的黑箱上,是在用整个国际站的可见度赌运气。
更隐蔽的一种翻车:有人用JavaScript在前端做跳转,认为“反正用户体验一样”。但前端跳转把判断逻辑放到了渲染层,AI爬虫和很多轻量抓取根本不执行你的跳转脚本,它们看到的是跳转前那一帧——往往是一个空壳或加载态。关于不同渲染方式对抓取的影响,本质和CSR/SSR的老问题同源。
IP定位本身就不靠谱:你在拿测不准的信号做硬决策
退一万步,就算抓取没问题,按IP定位也站不住脚,因为IP到地理位置的映射精度远没有大家想的那么高。
维基百科对IP地理定位的描述很冷静:精度“通常在国家级更高”,到城市、邮编级别就明显下滑。它还记录了一个经典翻车案例——数据库厂商MaxMind曾把约6亿个无法精确定位的IP统统映射到美国堪萨斯州一个农场的坐标,害得那户人家被各路执法和讨债找上门十几年。这说明IP定位的常见做法是“定不准就丢到一个默认中心点”,而你的跳转规则会把这些默认点当成真实位置来执行。
再叠加现实里的几层噪声:
- VPN和代理:用户随手开个VPN,你看到的就是出口节点的国家,跟人在哪毫无关系。维基百科直接点明VPN和代理可以绕过基于地理定位的限制。
- 移动网络:运营商的IP池可能集中注册在某个大城市,一个在慕尼黑用4G的人,IP可能显示在法兰克福甚至另一个国家。
- 企业出口和CDN:跨国公司的流量经常从总部所在国统一出口;用了CDN后,回源IP又是另一回事。
把这些加起来,你会发现“按IP自动决定给谁看哪个版本”是在拿一个误差可观、还能被一键绕过的信号,去做一个一旦做错就把人锁死的硬决策。这买卖怎么算都亏。
自动跳转的第二宗罪:把人锁死在猜错的语言里
SEO之外,自动跳转最伤的其实是真实用户。Semrush在它的国际SEO指南里举了一个特别精准的例子:一个住在美国、说西班牙语的用户,按IP会被你判成“美国人”从而强制跳到英文版——可他明明更想用西班牙语,而自动跳转剥夺了他的选择。
这种人比你想象的多得多:在德国工作的英语母语者、在日本留学的中国人、出差在外的本国客户、用着公司全球VPN的采购……语言偏好和地理位置从来不是一回事。你越“聪明”地替他们做主,越容易猜错;而猜错的代价不是“少看一个版本”,是用户落到一个读不懂的页面、找不到切回去的入口,直接跳出。Google那句“prevent users from viewing all the versions”,落到体验上就是这么具体。
正确姿势一:检测可以有,但只用来“建议”,不用来“执行”
那是不是地理检测一点都不能用?不是。检测信号本身没罪,罪在你拿它直接执行跳转。正确的用法是把“检测”和“动作”解耦:检测出访客可能更适合另一个版本,就提示他,而不是替他跳。
最经典的实现是一条非侵入式横幅(banner)。比如一个法国IP的访客落在了英文页,你在顶部挂一条不挡内容的提示条:
“看起来你在法国 —— 要切换到法语版吗? [切换到法语] [留在英文版]”
Semrush的建议正是如此:让用户自己选,用横幅给出“继续用当前语言”或“切到更适合你所在地的版本”两个选项,做得显眼但不强迫。Ahrefs在它的国际SEO最佳实践里说得更狠——按IP或cookie自动重定向应当完全避免,如果用户看的是错版本,就提示他切换,而不是强行送走。这条横幅的几个要点:
- 默认让访客留在他打开的那个URL,横幅只是“建议”,不改变落地页。
- 两个按钮都要有——“切过去”和“留下来”,不能只给一个选项假装尊重。
- 横幅本身不要用JS改变URL或history,保证Googlebot抓到的永远是干净的当前页。
- 用户一旦做了选择,记住它(下一节讲),别每次访问都弹。
正确姿势二:语言切换器的UX细节,别用国旗代表语言
横幅是“主动建议”,切换器是“随时可改”。一个合格的国际站,无论用户落在哪个版本,都应该能在页面上轻松找到切到其他版本的入口。这件事看着简单,细节坑很多。
- 别用国旗代表语言。这是头号经典错误。国旗代表国家,不代表语言。你用一面西班牙国旗代表西班牙语,墨西哥、阿根廷、哥伦比亚的几亿西语用户会觉得被无视;用美国国旗代表英语,英国、澳洲、印度用户同样别扭。语言用语言自己的名字来标——“Deutsch”“Español”“日本語”,用本地写法,别用“德语”“西班牙语”这种从访客视角看是外语的叫法。
- 区分“语言”和“地区”两个维度。如果你既分语言又分地区(比如en-US、en-GB、de-DE),切换器最好让用户先选地区/市场,再在其中选语言,而不是把十几个组合平铺成一长串。Yoast在它的国际SEO基础指南里也强调一个顺序:组织版本时先按语言、再按国家,能尽量按国家建站就别只按语言含糊带过。同语言多地区这套组合怎么不自己跟自己打架,保哥在 同语言多地区站那篇里专门拆过。
- 切换器要切到“对应的那一页”,不是首页。用户在读德语产品页时点“English”,应该落到英文的同一个产品页,而不是被甩回英文首页。这恰好就是hreflang那一组return tags维护的对应关系——切换器在前端复用同一套对应表最省事。
- 入口要稳定可见。放在页头或页脚的固定位置,别藏进三级菜单。它是国际站的基础设施,不是彩蛋。
正确姿势三:用户选了之后怎么记住,又不污染爬虫看到的URL
“让用户选”会引出一个问题:选完总不能每次来都重新弹横幅吧?所以要持久化用户的选择。这里有个关键分寸——持久化只对人生效,绝不能改变Googlebot抓到的内容。
做法是:把用户的选择存进一个cookie(比如 pref_lang=de),下次他主动访问首页或裸域名时,前端可以据此把横幅默认指向德语、或在他点logo回首页时带他去德语首页。但要守住三条红线:
- 不要用cookie在已经带语言路径的URL上做跳转。用户直接点开
/en/product,无论他cookie里存的是什么,都老老实实给他这个英文页。带明确语言路径的URL是用户和搜索引擎的“硬地址”,谁来都一个样。 - Googlebot不带cookie也不带Accept-Language(主力抓取场景下),所以它永远命不中你的持久化逻辑,看到的就是各URL的真实内容——这正是你要的。Google文档明确说抓取请求“without setting Accept-Language”,你的逻辑要默认“没有偏好信号”时一切照常、不跳转。
- 每个版本必须有自己稳定、可抓、可直链的URL。这是整套方案的地基,下一节单独说。
顺带一提,Google还明确推荐用不同的URL区分语言版本,而不是靠cookie或浏览器设置动态切内容——原话是“Google recommends using different URLs for each language version of a page rather than using cookies or browser settings to adjust the content language”。cookie只配做“记住偏好”的辅助,不配做“决定内容”的主力。
地基:每个版本都要有独立、稳定、可直链的URL
前面所有姿势能成立,靠的都是同一个前提:/de/ 永远是德语、/en/ 永远是英语,谁(人或机器、带不带cookie、从哪个IP)来访问都一样。这就是Google反复强调“用不同URL”的根本原因——URL是国际站唯一可被收录、可被分享、可被hreflang指向的稳定锚点。
反面教材是“同一个URL根据IP/cookie吐不同语言”的地区自适应方案。Google文档对此的态度是:“If you prefer to dynamically change content or reroute the user based on language settings, be aware that Google might not find and crawl all your variations.”(如果你坚持按语言设置动态改内容或重新路由用户,请注意Google可能找不到也抓不全你的所有变体。)一句话:能用独立URL,就别在一个URL上变戏法。先把域名结构这层定下来——是ccTLD、子目录还是子域名,保哥在 国际站域名结构那篇里给过决策树,结构选定了,每个版本的URL才有干净的归属。
hreflang和重定向的分工:一个写给机器,一个服务于人
很多人把hreflang当成“重定向的高级版”,这是根上的误解。它俩根本不在一个层面,而且是互补关系:
| 维度 | hreflang | 地理重定向 |
|---|---|---|
| 作用对象 | 搜索引擎 | 真实访客的浏览器 |
| 做什么 | 告诉引擎“这组页是同内容的不同版本,请给对的人展示对的版” | 把访客从一个URL送到另一个URL |
| 改变落地页吗 | 不改,只影响搜索结果里展示哪个 | 直接改变用户落到哪一页 |
| 对SEO的风险 | 配置对就帮忙,配错(缺return tag)整组失效 | 自动硬跳转会挡住抓取和用户选择 |
| 正确搭配 | 每个版本都标,自指必含 | 不做硬跳转,改成“检测→提示→用户选” |
正解是两者各司其职:hreflang在后台默默帮搜索引擎把“美国人搜到时优先展示en-US版”这件事做对;而当用户已经在站内、或者直接点开了某个URL,由切换器和横幅来服务他,绝不动用强制跳转。hreflang负责“搜索结果里露哪个脸”,切换器负责“进门后想换就换”,两套机制不抢活、不打架。
如果你已经上了IP硬跳转,怎么安全拆掉
存量站最怕的就是“知道错了但不敢动”。硬跳转拆除是有风险的——拆不好会短期波动,但留着是长期失血。给一套相对稳妥的步骤:
- 先盘清现状。用不同国家的VPN,或抓取工具模拟各国IP和Accept-Language,把“哪些URL会跳、跳去哪、用什么状态码(301还是302)”列成一张表。301比302更麻烦,因为它已经被引擎当成永久信号学进去了。
- 先停跳转,保留URL。第一步只做一件事:关掉自动跳转逻辑,让每个语言URL都能被直接访问并返回自己的内容。这一步不动hreflang、不动结构,影响面最小。
- 补齐hreflang和自指。确认每个版本互相指、且都自指,return tags对称——这块的坑在hreflang实施那篇里详细写过,这里只强调一点:拆跳转和修hreflang要分两次上线,别一锅端,否则出问题分不清是谁的锅。
- 上横幅和切换器。跳转拆掉后,把“检测→建议”的横幅和稳定的切换器补上,保证用户落错版本时有自助切回的路。
- 观察4到6周。盯GSC各国家维度的展示和点击、各语言URL的收录数。被压抑已久的非英文版本通常会逐步进索引、慢慢爬升。这期间少动多看,频繁改动只会拖长重新评估的时间——这点和站点迁移后的恢复节奏是一个道理。
别把语言、地区、货币三个维度塞进同一个跳转
电商出海最容易犯的一个错,是把“显示什么语言”“算哪个地区的运费政策”“标什么货币”全绑在同一个IP跳转里。这三件事的正确处理方式完全不同:
- 语言:用独立URL + hreflang + 切换器,就是这篇讲的全套。
- 地区/市场:影响的是库存、运费、合规、税费,通常对应不同的URL路径或站点,同样靠用户可选,不靠强跳。
- 货币:货币切换可以做得比语言轻——同一个URL上让用户切币种、用cookie记住即可,但要注意价格用结构化数据正确标注、避免不同币种产生重复内容。多语言多货币这层的hreflang和价格Schema怎么叠,是另一篇专门的活,不要混进语言跳转里一起做。
把三个维度拆开,每个维度用最适合它的机制,远比一个“超级智能跳转”稳。那种试图一次猜对用户语言、地区、货币的跳转,错一个维度就全盘皆错。
边缘案例:CDN、缓存和移动网络会让事情更糟
就算你坚持要做某种地理逻辑,下面这些技术现实也会反复咬你:
- CDN缓存撞上地理逻辑。如果你在边缘按IP返回不同内容,又开了缓存,很容易把“给德国人看的版本”缓存下来发给所有人,或者反过来。地理逻辑和强缓存天生互相敌对,要做就得在缓存键里带上地区维度,复杂度陡增。
- 回源IP不是用户IP。过了CDN之后,你的回源服务器看到的可能是CDN节点IP,需要正确解析
X-Forwarded-For才能拿到真实访客IP——配错就是把所有人都定位到某个CDN机房所在国。 - 移动和卫星网络:前面说过,运营商IP池和NAT让移动访客的IP定位经常偏到隔壁城市甚至隔壁国。
这些不是要劝你“把地理逻辑做得更精细”,恰恰相反——它们是又一组理由,说明把关键的“给谁看哪版”决策建立在IP之上有多脆弱。越想做精细,工程债越重,翻车面越大。
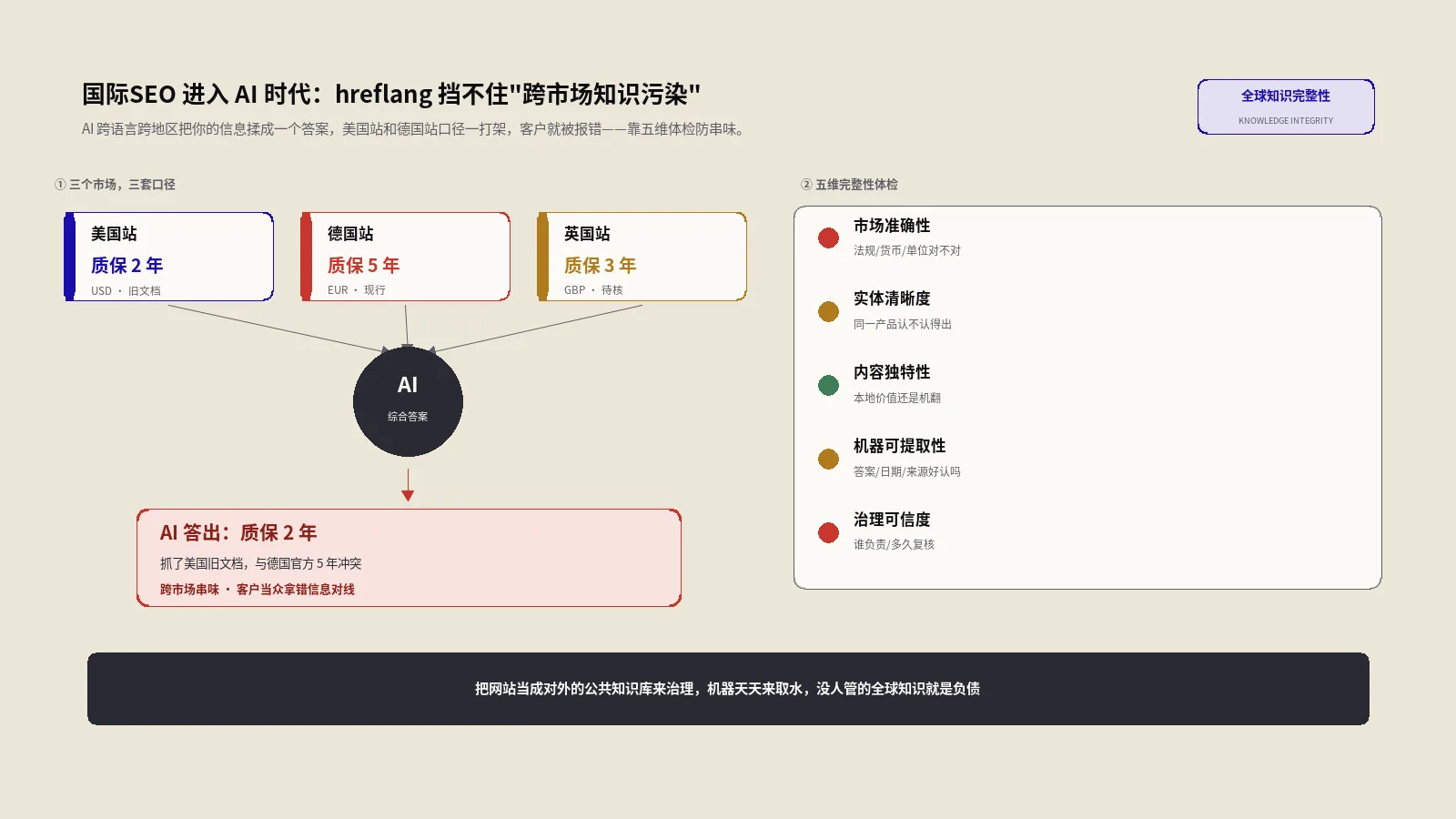
AI搜索时代:自动跳转的新风险
过去自动跳转的受害者是Googlebot,现在多了一类:各种AI爬虫和答案引擎。它们抓取你的内容用于生成回答和引用,而绝大多数AI爬虫不执行JavaScript、不带cookie、IP分布五花八门。你那套依赖前端跳转或IP判断的逻辑,在它们面前要么被绕过、要么命错版本。
后果有两层:一是AI可能只抓到你的英文版,导致非英文市场的用户在AI答案里完全看不到你的本地化内容;二是更隐蔽的——如果AI在不同语言版本里抓到的实体信息对不上(因为它压根没抓全),你的品牌在跨市场的知识表示就会出现裂缝。关于AI时代为什么连hreflang都挡不住跨市场的知识污染、品牌信息怎么在多语言之间保持一致,保哥在 跨市场知识完整性那篇里展开过。这里的结论很简单:在AI爬虫越来越多的当下,“每个版本都有独立、稳定、无条件可抓的URL”不再是SEO洁癖,而是让模型能把你看全、看对的底线。
一张决策表:什么时候检测、什么时候提示、什么时候绝不跳
| 场景 | 该怎么做 | 绝对别做 |
|---|---|---|
访客直接点开带语言路径的URL(如 /de/x) | 原样返回该版本,无条件 | 按IP/cookie再跳走 |
| 访客落在某版本,但IP/浏览器语言显示更适合另一版 | 挂非侵入横幅,给“切过去/留下来”两个选项 | 静默302/301强制跳转 |
| 访客访问裸域名或不带语言的首页 | 可据偏好建议或温和引导,但保留人工选择入口 | 按IP硬跳到某语言首页且无返回路径 |
| Googlebot / AI爬虫来访(无cookie、无偏好头) | 返回当前URL的真实内容,不跳转 | 按“无偏好”就默认跳到英文版 |
| 用户已在切换器里选过语言 | 用cookie记住,下次温和默认,但不锁死带路径URL | 用cookie在所有页面强制覆盖用户当前请求 |
落地清单:10步搭好“不强跳”的国际站路由
- 先定域名结构,确保每个语言/地区版本有独立、稳定的URL路径。
- 关掉一切基于IP的自动硬跳转(301/302),让每个URL可被直接访问。
- 每个版本写全hreflang,互指 + 自指,return tags对称。
- x-default指向语言选择页或不带地区偏好的兜底版本。
- 页头或页脚放固定、可见的语言/地区切换器。
- 切换器用语言本地名(Deutsch、日本語),不用国旗代表语言。
- 切换器切到对应的同一页,不甩回首页。
- 对落错版本的访客,用非侵入横幅“建议”切换,给双向按钮。
- 用户选择存cookie,仅用于温和默认,绝不覆盖带语言路径的直接请求。
- 用多国VPN + 抓取模拟验证:每个URL在任意IP、有无cookie下都返回自己的内容、状态码200、不跳转。
5个最常踩的误区
- 误区一:“Googlebot现在能多地抓取,IP跳转没事了。”能力存在但不保证、不可控、Google官方仍明确反对,把上索引押在黑箱上是赌博。
- 误区二:“前端JS跳转对SEO无害。”AI爬虫和轻量抓取不执行JS,看到的是跳转前的空壳,反而更糟。
- 误区三:“用国旗当语言切换器更直观。”国旗是国家不是语言,会系统性地得罪一大批跨国同语用户。
- 误区四:“cookie记住偏好就该全站强制跳。”cookie只配做温和默认,带语言路径的URL必须无条件返回自己。
- 误区五:“语言、地区、货币一个跳转全搞定最省事。”三个维度机制不同,绑一起错一个就全错,拆开各管各的才稳。
一个外贸站的真实节奏
分享一个保哥经手过的出海储能品牌的处理节奏,去掉具体数字只讲机制。这个站当初图省事,在CDN边缘按IP做了硬跳转:非美国IP一律302到 /en/,德国IP跳 /de/。上线大半年,德语和法语版的收录数一直趴在个位数,GSC里这两个国家的展示量几乎为零,团队还以为是“内容不够本地化”。
实际一查日志才发现:Googlebot的美国IP每次抓德语URL都被302弹去英文页,德语内容它压根没读到过。处理就按上面那套来——第一周只关跳转、让每个URL自给自足;第二周补齐hreflang对称;第三周上横幅和切换器。之后非英文版本的页面陆续进索引,目标市场的展示开始爬。中间有过两三周排名飘忽,是引擎重新评估的正常代价。复盘下来最值钱的一课不是“hreflang怎么写”,而是那个看起来最贴心的自动跳转,恰恰是把半个站埋进黑箱的元凶——贴心是给人的,不该用在替机器人和用户做主上。
常见问题解答
按IP自动跳转语言版本,到底会不会被Google当作惩罚项?
它不会触发“人工处罚”那种意义上的惩罚,但Google文档把IP重定向到不同URL描述为“可以说是一种cloaking(伪装)”,并明确建议避免自动重定向。真正的伤害也不是处罚,而是机制性的:自动跳转会让你的非主力语言版本长期抓不到、进不了索引,相当于自废武功。所以问题不在“会不会被罚”,而在“你会不会自己把半个站藏起来”。
那我到底还能不能用IP做任何地理逻辑?
能,但只用来“建议”不用来“执行”。检测到访客可能更适合另一个版本时,用非侵入横幅提示他,给“切过去”和“留下来”两个选项,默认让他留在打开的URL。绝对不要静默302/301把人或爬虫强制送走。检测信号没罪,罪在拿它直接改变用户落地页。
语言切换器用国旗图标到底有什么问题?
国旗代表国家,不代表语言。一面西班牙国旗代表西班牙语,会让墨西哥、阿根廷等几亿西语用户觉得被无视;一面美国国旗代表英语,英国、澳洲、印度用户同样别扭。正确做法是用语言自己的本地名字来标,比如“Deutsch”“Español”“日本語”,既准确又对每个市场的用户都友好。
用户选过语言后,我用cookie帮他自动跳转可以吗?
可以记住偏好,但要守住一条线:cookie只用于“温和默认”,比如他下次访问裸域名或首页时优先给他选过的版本。但如果用户直接点开了带语言路径的URL(如 /en/product),无论cookie存什么,都必须老老实实返回这个英文页。带明确语言路径的URL是用户和搜索引擎共同的硬地址,cookie不能覆盖它。
Googlebot现在能从多个国家抓取,是不是意味着IP跳转的老问题已经不存在了?
不是。Google确实在2015年加了针对地区自适应页面的地理分布抓取和带Accept-Language的抓取,但这是Google 自动检测到页面是地区自适应时才开启的,触发条件不透明、覆盖不全、你既不能控制也无法验证。同时官方文档至今仍写着“大多数抓取来自美国”且“不会主动变换位置探测差异”,并继续建议避免自动重定向。把上索引押在一个黑箱能力上,风险远大于收益。
地区自适应(同一URL按IP返回不同内容)和独立URL,到底该选哪个?
能用独立URL就用独立URL。Google明确推荐“为每个语言版本使用不同的URL,而不是靠cookie或浏览器设置动态切内容”,并警告动态切内容会让它“找不到也抓不全你的所有变体”。地区自适应只在你确实无法拆URL的硬约束下才退而求其次,且必须配合hreflang,并接受Google抓取覆盖不全的风险。
权威参考资料
- Google Search Central · 管理多区域和多语言站点:官方一手指引,明确“避免在语言版本间自动重定向用户”、推荐用不同URL而非cookie切内容、并说明抓取多数来自美国且不带Accept-Language。
- Search Engine Land · Google开始支持抓取与索引地区自适应页面:2015年报道,解读Googlebot新增地理分布抓取(美国以外IP)与带Accept-Language的抓取,并指出这是面向已有地区自适应站的自动能力。
- Ahrefs Blog · 国际SEO 10条最佳实践与清单:明确按IP或cookie自动重定向应完全避免,IP定位不可靠且会让本地化内容抓不到,应改用语言/地区切换器让用户自选。
- Semrush Blog · 国际SEO全球成功最佳实践:用“在美国的西班牙语用户被强制跳英文”的例子说明自动跳转剥夺选择,建议用非侵入横幅让用户继续当前语言或切到更适合所在地的版本。
- Wikipedia · 地理定位软件:IP地理定位精度国家级较高、城市级明显下滑,记录了MaxMind把约6亿IP误映射到堪萨斯农场的案例,并指出VPN与代理可绕过地理限制。
- Yoast · 什么是国际SEO:从语言优先、按国家建站、同语言多地区必用hreflang的角度,说明国际站结构与用户定位的基础原则。
本文标题:《按IP自动跳转语言版本,正在悄悄让你的国际站半数页面进不了Google索引》
本文链接:https://zhangwenbao.com/international-seo-ip-redirect-geolocation-language-switcher-ux.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0