国际SEO进入AI时代:为什么hreflang挡不住跨市场知识污染
本文目录
- 先讲个让人后背发凉的场景
- 传统国际SEO是"指路",AI时代要的是"防串味"
- 为什么hreflang、FAQ、schema这些招到这儿就不灵了
- 给"跨市场知识污染"下个定义
- AI在综合答案时,到底优先信你哪个版本?
- 全球知识完整性矩阵:每个市场拿五把尺子量一遍
- 先从哪些内容下手?高风险清单
- 落地六步:从审计重复到建治理流
- 把治理写进技术层:几组能照抄的标记
- 一个出海3C品牌的真实切片
- 把监测做成例行:每月二十分钟的跨市场体检
- 组织层面:你可能需要一个"答案负责人"
- 常见问题解答
- 我是小独立站,就一两个海外市场,也要搞这么复杂的矩阵吗?
- 跨市场知识污染和普通的重复内容问题,是一回事吗?
- 这套东西归SEO管,还是归内容、法务、产品管?
- 我怎么知道AI现在到底有没有在污染我的品牌信息?
- 把过时的旧内容直接删了,会不会丢掉已有的排名和外链权重?
- 设答案负责人是不是又要多招一个人、多一份预算?老板大概率不批。
- 权威参考资料
摘要:过去做国际SEO,目标是把对的人引到对的那个本地化页面,hreflang一配,搜索引擎各回各家。AI搜索把这件事彻底搅乱了:它会跨语言、跨地区、跨页面把你的信息揉成一个答案,根本不管你美国站和德国站说的是不是同一回事。结果就是"跨市场知识污染"——同一个品牌,AI在不同市场给出互相打架的说法,而你毫不知情。本文给你一套可落地的应对:先看清污染怎么发生,再用"全球知识完整性矩阵"给每个市场逐项体检,按高风险内容排优先级走六步治理,最后聊聊为什么大一点的出海团队该考虑设一个专门盯"答案一致性"的角色。这不是又一套hreflang技巧,而是把网站当成"对外的公共知识库"来管。
先讲个让人后背发凉的场景
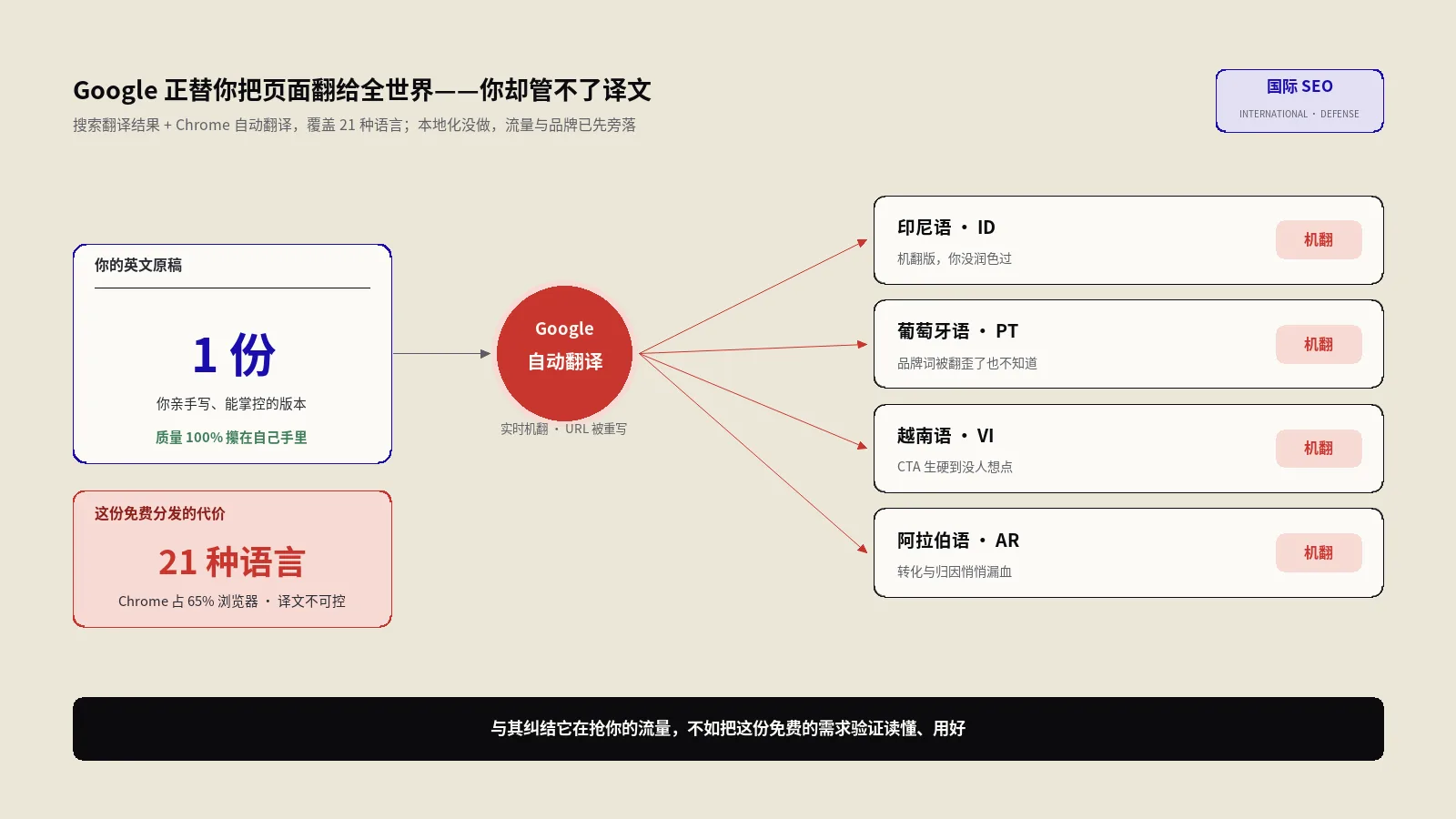
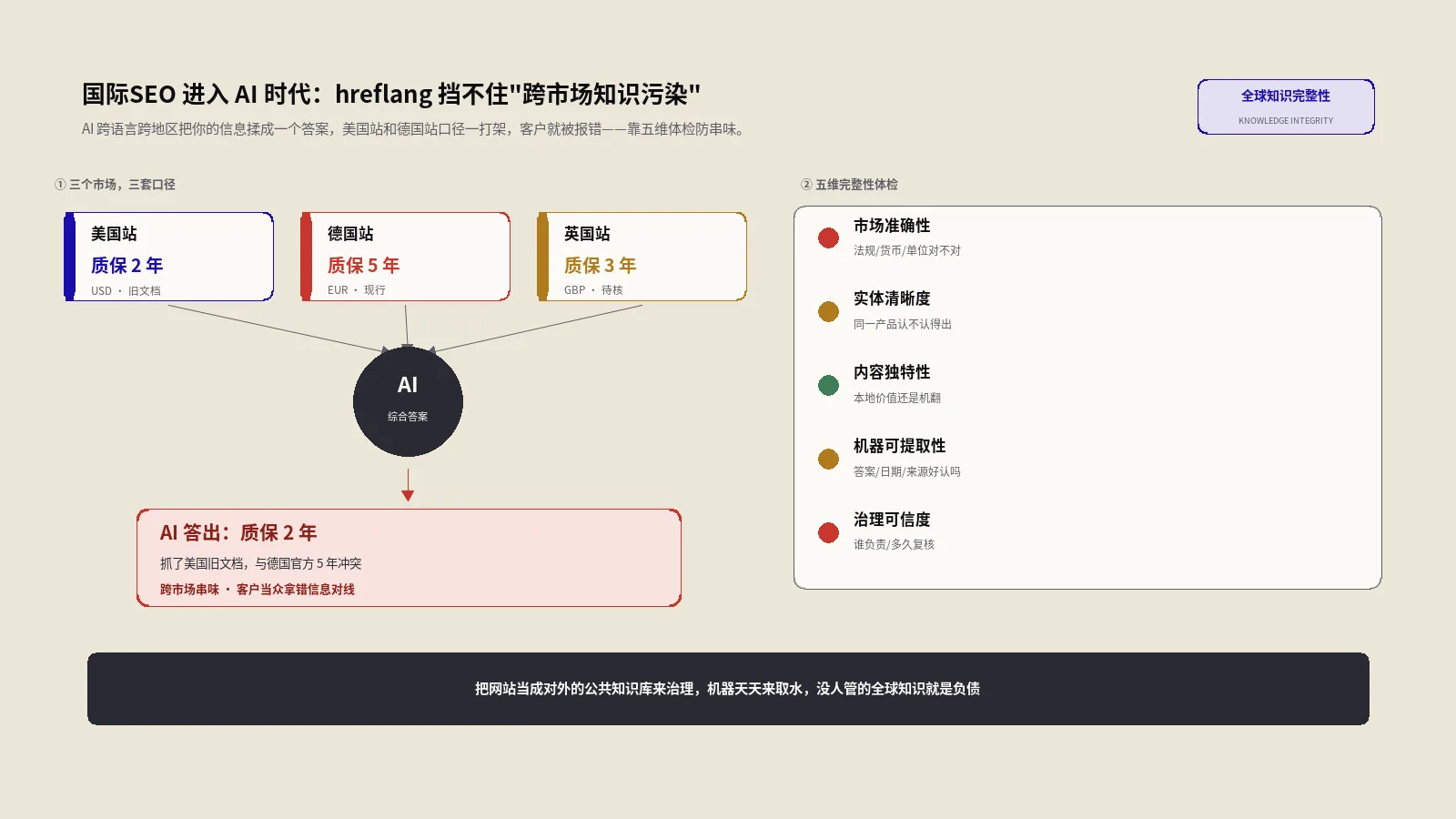
你是一家出海做家用储能的品牌,美国站、德国站、英国站都配齐了hreflang,各语言版本都能在对应市场的搜索结果里正常排名。这套打法跑了五六年,一直没出过岔子。
直到有一天,一个德国采购在ChatGPT里问"这个牌子的储能电池质保几年"。AI给出的答案是"两年"——可你德国站白纸黑字写的是五年,那个"两年"是从你美国早期一篇没更新的支持文档里抓出来的。德国客户拿着这个"两年"来找你客服理论,客服一脸懵:我们德国从来就是五年质保。
问题出在哪?没人填错信息,hreflang也没配错,每个页面单独看都是对的。出岔子的是AI把分属两个市场的信息合并成了一句话,而它合并的时候,压根没把"美国"和"德国"当成需要隔离的两个世界。这就是这篇要聊的核心——在AI综合答案的时代,国际SEO真正的战场已经从"指路"变成了"防串味"。
这种事现在一点都不小众。生成式AI的使用率已经渗透进绝大多数行业,问AI拿建议、做品牌对比、查产品参数,正变成普通人的日常动作。Similarweb发布的2026生成式AI可见度统计显示,AI助手影响的查询占比一路走高,而每一次这样的查询,都是一次你的多市场信息被重新拼装的机会。拼对了是惊喜,拼错了就是上面那种当众翻车。
传统国际SEO是"指路",AI时代要的是"防串味"
把时间往回拨。传统国际SEO的核心命题,其实就一句话:让对的搜索引擎,把对的用户,送到对的那个本地化页面。美国人搜到 .com的美元定价页,德国人搜到 /de/ 的欧元定价页,hreflang负责告诉爬虫"这几个页面是一回事的不同语言地区版本,别当成重复内容互相打架"。
这套逻辑有个隐含前提:每个市场的信息是被一道墙隔开的。搜索引擎给德国用户看的,永远是德国那一面墙里的内容,不会跑到美国那面墙后头去拿东西。所以哪怕你美国站和德国站的质保口径不一致,传统搜索也不会当众揭穿你——它一次只展示一面墙。
AI综合答案把这道墙拆了。它的工作方式不是"挑一个最相关的页面给你",而是"把它能找到的相关信息全部读一遍,综合成一段话讲给你听"。读的时候,它不会因为某条信息来自美国站就自动排除掉德国语境下的提问。墙没了,串味就开始了。
再举个更日常的例子:定价。你美国站标199美元,欧洲站标219欧元,本来各卖各的市场,井水不犯河水。可当一个法国客户问AI"这产品大概多少钱",AI很可能把它读到的两个数字一起端出来,甚至直接报个199(因为美国页面权重高、被引用多),让客户误以为欧洲也是这个价。等他到了欧洲站发现要219欧元,第一反应不是"汇率不同",而是"这牌子是不是在坑我"。你什么都没做错,但在客户眼里你"价格不透明"——这口锅,是AI拆墙之后强行扣到你头上的。
所以这不是把旧打法做得更精细就能解决的。你hreflang配得再完美,也只是告诉爬虫页面之间的对应关系,管不住AI在生成答案那一刻从哪几个来源取材、怎么揉。打个比方:hreflang像是给每个房间挂了门牌号,但AI是个不看门牌、闯进所有房间翻东西、再凑一桌菜端给客人的厨子。门牌号再清楚,也拦不住它把美国厨房的盐和德国厨房的糖倒进同一口锅。关于跨语言实体本身怎么被认成同一个、机器翻译又怎么把这件事搞砸,我在国际化SEO最难的不是hreflang那篇里拆得更细,这里不重复。
为什么hreflang、FAQ、schema这些招到这儿就不灵了
很多人第一反应是:那我把页面级的优化做扎实点不就行了?多配FAQ结构化数据、把schema堆满、hreflang查三遍。可惜这些都是页面级的招式,而跨市场知识污染是系统级、治理级的病。拿页面级的药治系统级的病,治标都算不上。
说几个具体的失灵场景:
- FAQ结构化数据救不了互相冲突的产品数据。你德国站FAQ写五年质保,美国支持文档写两年,两个都标得规规矩矩,AI照样能同时读到,照样会困惑该信哪个。结构化只是让机器更容易读,不负责让机器读到的内容彼此一致。
- schema补不了过时的区域内容。三年前上传、早就该下架的旧版产品描述,只要还挂在某个角落能被抓取,schema标得再漂亮,它也是一颗随时会被AI翻出来的雷。
- hreflang管对应关系,不管内容真伪。它能告诉爬虫"这两个页面是对应的",但不会替你检查这两个页面说的是不是同一件事。两个页面互相矛盾,hreflang一样会乖乖把它们绑在一起。
真正的根子,是组织内部对"AI到底在消费我们哪些信息"缺乏治理。哪些内容该对外、哪些早该下架、谁对每个市场的口径负责、多久复核一次——这些问题没人管,页面级的优化做得再花哨也是给一栋地基松动的楼刷外墙漆。Google多区域与多语言站点管理官方指南讲的是技术层怎么搭,但技术层之上的"谁来保证各市场说法一致"这层,文档不会替你回答,得你自己补。
给"跨市场知识污染"下个定义
把这个概念说清楚,后面才好对症。跨市场知识污染,指的是来自不同地区、不同语言、不同时间点的关于同一品牌或产品的信息,在AI检索与综合的过程中失去语境、互相串味,最终被拼成一个对某个具体市场来说不准确、甚至违规的答案。
它通常由三个动作叠加而成:
- 跨边界取材。AI为了回答得"全面",会尽量多读来源,不会主动按地区给信息上锁。你以为只在德国可见的内容,对它来说只是又一份语料。
- 语境剥离。"这是2021年的美国旧文档"这种语境信息,在被综合的瞬间往往就丢了。AI留下的是事实碎片"质保两年",扔掉了"这是哪国、哪年、是否还有效"。
- 自信合成。最要命的是AI不会说"我不太确定",它会用斩钉截铁的语气把这些碎片缝成一句话。德国客户读到的不是"可能是两年也可能是五年",而是确定的"两年"。
这三步里最危险的是医疗、金融、法律这类强监管领域。一个在美国获批的适应症,在德国可能根本没批;一条在美国合规的金融宣传话术,搬到欧盟可能直接踩GDPR或当地广告法的线。AI一旦把这些跨市场揉到一起,轻则误导客户,重则给你惹上合规麻烦。这一层的危险,本质上和实体之间的关系没人审是同一类问题,我在关系完整性审计那篇里专门讲过"机器进得了门不等于读到对的东西"。
AI在综合答案时,到底优先信你哪个版本?
既然AI会同时读到你好几个互相打架的版本,那它最后端给客户的那句话,到底是从哪个版本里挑的?搞清楚这个,你才知道治理时该往哪儿使劲。根据观察,影响AI取材偏好的,大致是这么几个信号叠加:
- 新鲜度。带明确更新日期、且日期更近的内容,往往更容易被当成"现行有效"的版本采纳。那篇没日期的旧文档之所以害人,部分原因就是它没有任何"我已经过期了"的信号,机器只能默认它还有效。
- 权威性。来自主域名核心页面、被多处一致引用的信息,比藏在某个子目录角落的孤立页面更被信任。如果你的权威口径反而埋在不起眼的地方,等于把话语权拱手让给了那个更显眼的错误版本。
- 结构化清晰度。用结构化数据明确标出"这是质保期、单位是年、适用地区是德国"的内容,比一段只能靠机器自己猜的自然语言,更容易被准确提取。机器爱省事,你把答案喂到它嘴边,它就少出错。
- 跨源一致性。这条最关键也最反直觉:当你多个来源说的是同一件事时,AI的置信度会显著上升,引用起来也更果断;而当来源互相矛盾,它要么随机挑一个,要么干脆给出一个含糊甚至错误的折中。一致性本身就是一种排名信号。
把这四点反过来读,就是你的治理方向:给内容补日期(提新鲜度)、把权威口径放到显眼的核心位置(提权威性)、用结构化数据标清楚关键字段(提可提取性)、消灭跨市场矛盾(提一致性)。这也解释了为什么"更多曝光不一定更好"——如果你被引用的信息本身就互相打架,AI引用你越多,制造的混乱反而越大。声量不等于可信度,一致才等于。
全球知识完整性矩阵:每个市场拿五把尺子量一遍
光知道有病不行,得有个能动手的体检表。我把它整理成一个矩阵——对你进入的每一个市场,都用下面五个维度各打一遍分。哪个维度分低,哪个就是AI给你串味的入口。
| 维度 | 它在问什么 | 分低的典型症状 |
|---|---|---|
| 市场准确性 | 这条信息对该国用户在法规、货币、单位、当地预期上是不是对的 | 德国站还在用美元、用美国的退货政策 |
| 实体清晰度 | 你的产品、机构、地点在各系统里是不是被明确识别为同一个 | 同一产品在不同语言站叫不同名字,AI认不出是一回事 |
| 内容独特性 | 本地内容是真有本地价值,还是机翻一遍交差(W3C对国际化与本地化的区分说得很清楚,二者不是一回事) | 德国站就是英文站的机翻,没有任何本地化实质 |
| 机器可提取性 | 答案、来源、日期、关系,机器能不能轻松识别出来 | 关键信息埋在图片里、没有日期、没有结构化标记 |
| 治理可信度 | 这块内容有没有明确的负责人、复核周期、审批流程 | 没人知道这页谁维护、上次复核是哪年 |
用法很简单:把你的核心市场列成行,五个维度列成列,逐格用"红黄绿"标一遍。第一次做完你大概率会被吓到——绿格往往没你想的多,尤其"治理可信度"这一列,多数团队全是红的,因为压根没人专门管。这张表不追求精确打分,追求的是把"我们到底乱在哪个市场的哪个环节"从一团模糊变成一格一格看得见。Schema.org的sameAs属性定义就是改善"实体清晰度"这一列最直接的抓手——用它把同一实体在各平台的身份串成一条线,AI才不容易把你认岔。
先从哪些内容下手?高风险清单
矩阵铺开你会发现要治的地方太多,一上来全治会累死,也没必要。按"出错代价"排序,优先盯这几类高风险内容:
- 产品页与规格参数。型号、兼容性、质保、认证,这些跨市场最容易不一致,也最容易被AI当成"事实"直接引用。
- 价格与货币。串味成本最直观的一类。AI把美国售价报给欧洲客户,要么吓跑人,要么客户上门讨说法。哪怕只是货币代码标错(把EUR写成USD),机器也会照单全收,建议各市场严格对照 ISO 4217国际货币代码标准来标,别留模糊空间。
- 医疗与金融声明。前面说过,这类一旦跨市场污染,风险从"客户不满"直接升级到"合规事故"。
- 法律与免责声明。退货政策、隐私条款、保修责任,各市场法规不同,串了味就是给自己挖坑。
- 门店与联系信息。地址、营业时间、服务范围,本地用户一查就用,错了影响立等可见。
- 支持与帮助文档。过时旧文档是污染源头重灾区,那篇害人的"两年质保"大概率就藏在这儿。
一个偷懒但有效的起步动作:去你各市场的站点上,把同一个高频问题(比如"质保多久""怎么退货")在每个语言版本里都搜一遍,把答案抄到一张表里并排放。只要你看到并排的答案对不上,AI就一定也看到了,而且它比你更勤快。
这张并排表还有个隐藏好处:它能帮你区分"真差异"和"假矛盾"。有些跨市场的不一致是合理的——德国法定退货期就是和美国不同,这不该被抹平,而该被明确标注成"此政策仅适用于德国"。另一些则是纯粹的疏忽——同一个全球统一的质保政策,在三个站点被写成三个数字,这才是要消灭的污染。把这两类分开,你才不会一刀切地把本该本地化的差异也给"统一"没了。治理的目标从来不是让所有市场说一模一样的话,而是让每个市场说的话,对它自己那个市场来说都是准确的、且不会被AI跨市场误读的。
落地六步:从审计重复到建治理流
方向有了,给一套能照着走的流程。别指望一口吃成胖子,这六步是按"先止血、再固本"的顺序排的。
- 审计跨市场重复。把各市场关于同一主题的内容拉到一起,找出哪些是重复的、哪些是矛盾的。工具帮你抓,判断得人来。
- 标记冲突点。所有口径打架的地方挑出来,按高风险清单排序,质保价格合规这种先处理。
- 指定权威源。每个冲突,明确"以哪个市场、哪个页面、哪个版本为准"。没有权威源,后面所有动作都是空中楼阁。
- 下架与归档过时内容。那些早该消失却还能被抓取的旧文档,要么更新,要么彻底下架。能被爬到的就是活的语料,删不掉就是定时炸弹。
- 强化本地信号与结构化。给保留下来的内容补上明确的日期、负责人、地区标记和结构化数据,让机器一眼看出"这是哪国、哪年、还有效"。
- 建治理工作流。定下每块内容的负责人、复核周期、改动审批路径,让"保持一致"变成一个有人盯的常态流程,而不是一次性的大扫除。
前五步是止血,第六步是固本。很多团队做完前五步松一口气,半年后旧病复发,就是因为没建第六步——AI时代的内容一致性,不是项目,是个需要长期有人养的工程。
把治理写进技术层:几组能照抄的标记
前面讲的都是流程和组织,落到执行层,还得让机器一眼读懂"这块内容是哪国、哪年、还有没有效"。结构化数据就是干这个的。给几组方向,不用全套照搬,挑你高风险内容最缺的那几项先补上:
- 明确地区适用范围。产品的服务区域、配送范围、某项政策的适用地,可以用
areaServed这类属性把"这只适用于德国"写成机器能读的字段,而不是埋在正文里指望它自己悟。优惠或资格类信息还可以配合eligibleRegion限定生效地区。 - 把货币和价格标死。价格信息务必带上
priceCurrency并填对ISO货币代码,别只写个数字让机器去猜是美元还是欧元。一个价格字段缺了货币标记,就是一次潜在的跨市场报错。 - 声明内容语言。用
inLanguage标清这块内容是哪种语言,配合hreflang,让机器在语言和地区两个维度上都不至于认岔。 - 钉死更新日期。给关键页面补上
dateModified,这是提"新鲜度"信号最直接的一招。带准确更新日期的内容,被当成现行版本采纳的概率明显更高。 - 串好实体身份。用
sameAs把你的组织、产品在各官方平台、知识库里的身份关联成一条线,机器才不容易把你的德国实体和某个同名的别家公司搞混。
这些标记不是越多越好,而是越准越好。一个标错地区的字段,比没有这个字段更糟——它会让机器更"自信"地把错误信息当事实。所以补结构化数据这一步,一定要放在"指定权威源、消除矛盾"之后做,先把内容本身理顺,再给机器贴标签,顺序反了就是给错误内容盖钢印。
一个出海3C品牌的真实切片
说个保哥手上把这套走通的例子,细节做了脱敏。一家做智能家居配件的出海品牌,三个主力市场:美国、德国、英国。找过来时的症状很典型——客服反映欧洲客户老拿一些"我们根本没承诺过"的说法来对线,但谁也说不清这些说法从哪冒出来的。一开始大家都往"是不是被竞品黑了"的方向想,查了半天才发现,黑他们的不是别人,是他们自己三年前没下架的旧文档。
我们做的第一件事,就是上面那个偷懒动作:把"质保多久""支持哪些型号""退货多少天"三个高频问题,在三个市场的站点、帮助中心、甚至还能搜到的旧PDF里全捞了一遍,并排放进一张表。结果触目惊心:质保口径有三个版本,型号兼容列表有两份互相矛盾的,退货天数美国30天、德国14天,但有篇英文旧文档笼统写着"30天无理由",被欧洲客户在AI答案里读到了。
处理过程没什么花活,就是老老实实走六步:指定每个市场的权威页、把那份害人的英文旧文档归档下线、给保留页面补上"适用地区+更新日期"的明确标记、给价格字段补全货币代码、给产品实体串上sameAs,最后给三个市场各指派了一个对内容口径负责的人。整个过程没动一行炫技代码,最费工夫的反而是第三步"指定权威源"——光是确认"德国退货到底以哪个页面为准",就拉着产品、法务、本地化开了两次会,因为之前真没人能拍板。
两三个月后,客服反馈"客户拿错信息来对线"的频次明显降了,他们自己跑那套每月体检,关于他们的关键参数在AI答案里的"红格"从一开始的七八个降到了一两个,而且稳定下来不再乱跳。最让团队意外的一个副产品是:理顺口径的过程,倒逼他们把三个市场各自真正的差异(质保政策本来就不同、退货天数受当地法规约束)梳理清楚了,连内部培训客服的话术都跟着规整了一遍。没有黑科技,就是把"谁说了算、什么时候复核"这件一直没人管的事,变成了有人管——AI串味只是把这个一直存在的组织漏洞,第一次摆到了所有人面前。
把监测做成例行:每月二十分钟的跨市场体检
大扫除做完只是开始,难的是别让它半年后旧病复发。AI消费的内容是流动的,你今天理顺了,明天某个团队又上传一版新文案,污染随时可能卷土重来。所以治理这件事,监测必须常态化,而且要简单到没人嫌烦才能坚持下来。
给一套保哥自己在用的轻量例行,一个人每月花二十分钟就能跑完:
- 固定一组问题。挑5到8个你最怕被报错的关键问题(质保、价格、退货、合规、型号兼容),写死,每月问的就是这几个,方便横向对比。
- 逐市场逐引擎问一遍。用每个目标市场的语言,在两三个主流AI助手里把这组问题各问一遍,把答案截图存档。
- 红黄绿标注。每个答案对照你的官方口径打分:完全对(绿)、含糊但不算错(黄)、明确错误或跨市场串味(红)。红的立刻排查源头。
- 记一条趋势线。把每月的红黄绿数量记成一行,攒三个月你就有了自己的基准。数字往绿走,说明治理有效;某个市场突然飘红,多半是有人又上传了矛盾内容。
这套东西的价值不在某一次的结果,而在趋势。单看一次,你只知道现在乱不乱;连着看几个月,你才能发现污染是从哪个环节、哪次改动渗进来的,从而把堵漏的动作前置。很多团队不是不会治理,是治完就不管了,等客户又来对线才发现旧病复发——一个每月二十分钟的例行,就能把"被动救火"变成"主动体检",性价比高得离谱。
组织层面:你可能需要一个"答案负责人"
走到最后你会发现一个尴尬的事实:跨市场知识污染本质上是个组织问题,不是SEO问题。产品团队管参数、市场团队管文案、本地化团队管翻译、法务管合规,每个团队都只对自己那块负责,没有任何一个人对"AI在所有市场关于我们的那个综合答案到底准不准"负责。这个真空,就是污染的温床。
所以越来越多大一点的出海团队开始设一个新角色,姑且叫它"答案负责人"。这个人不取代任何现有团队,而是横跨它们——确保公司在搜索引擎、AI系统、各区域网站、结构化数据里对外说的话是一致、准确的。说白了,就是有个人专门盯着"别人(包括机器)问起我们时,得到的答案对不对、各市场一不一致"。
这不是凭空设岗。组织治理与AI成熟度的关系,麦肯锡2025全球AI现状报告讲得很直白:把AI用出价值的组织,和原地踏步的组织,差距往往不在技术,而在治理、问责和组织准备度。能不能把"对外信息一致性"这件事落到一个具体的人头上,恰恰是这种组织成熟度的体现。你的网站早就不只是营销物料了,它是对外的公共知识基础设施,机器天天来取水。没人管的全球知识,在综合答案的时代不是资产,是负债。
当然,小团队不需要专门设岗,让现有的SEO或内容负责人多扛一顶帽子就够了。规模到了,再考虑独立成岗。关键不是头衔,是这件事有没有一个明确的人负责。
说到底,AI时代的国际SEO已经不是一个纯技术活,而是一个"技术 + 内容 + 组织"三合一的治理工程。hreflang、schema这些技术手段还得做,但它们从"主菜"退成了"配菜";真正决定你在各市场AI答案里被怎么描述的,是你内部对信息的治理纪律。把网站当成对外的公共知识库来管,给它配上明确的负责人、复核周期和一致性标准,你才能在综合答案的时代守住一件最基本的事——不管哪个市场的客户问起,机器给出的关于你的答案,都是对的。多市场的AI可见度怎么系统地测、翻译内容为什么在AI检索里天然吃亏,可以接着看多语言AI可见性那篇,跟本文是一套组合拳。
常见问题解答
我是小独立站,就一两个海外市场,也要搞这么复杂的矩阵吗?
不用搞复杂版,但核心动作一个都不能省。小站的好处是内容少、市场少,那个"把高频问题在各市场并排抄进一张表"的偷懒动作,你可能一个下午就做完了。你不需要五个维度全打分、不需要专门设岗,但你必须知道:你两三个市场里关于质保、价格、退货这些关键信息,口径是不是一致、有没有过时的旧页面还在被抓取。小站船小好调头,发现问题改起来比大企业快得多,别因为"我小"就不做,恰恰是小站更经不起AI当众报错一次。
跨市场知识污染和普通的重复内容问题,是一回事吗?
不是,这是两个层面的事,别混。重复内容是SEO老问题,指的是多个URL内容雷同、互相抢排名,解决靠canonical和hreflang告诉搜索引擎"这几个是一回事,别重复计算"。跨市场知识污染是AI时代的新问题,指的是不同市场的信息被AI综合成一个互相矛盾的答案,它的矛盾点不在"页面重复",而在"内容打架"。两个页面可以完全不重复(一个讲美国一个讲德国),却照样能被AI揉出污染。hreflang能解决前者,解决不了后者,这也是为什么我反复强调页面级招式到这儿就不够用了。
这套东西归SEO管,还是归内容、法务、产品管?
它哪个团队都不完全归,这正是它难办的地方,也是为什么需要一个横跨各团队的"答案负责人"。具体动作会落到不同团队:参数一致归产品、文案口径归内容、合规声明归法务、结构化数据和可提取性归SEO。但"确保这些拼在一起对外是一致准确的"这个总责,传统组织架构里是没人扛的。现实里建议先由SEO或内容负责人牵头,因为这两个角色最常和"机器怎么读我们"打交道,对问题最敏感。牵头不等于全包,是负责把各团队拉到一张桌上对齐口径。
我怎么知道AI现在到底有没有在污染我的品牌信息?
最直接的办法是亲自当一次你的海外客户。挑几个主流AI助手,用目标市场的语言、站在那个市场客户的角度,问几个关键问题:你们质保多久、支持不支持某型号、价格多少、退货政策怎样。把每个市场都问一遍,把答案抄下来比对。只要AI给某个市场报的信息和你那个市场站点的官方口径对不上,污染就已经发生了。建议把这组固定问题做成一个每月跑一次的小例行,攒成你自己的基准线,比任何外部工具都贴合你的实际情况。这件事不花钱,只花二十分钟,但绝大多数团队从来没做过。
把过时的旧内容直接删了,会不会丢掉已有的排名和外链权重?
会有影响,但要分清"删"和"乱删"。一个还在带流量、带外链的旧页面,直接硬删确实可惜,正确做法是更新它的内容、补上"适用地区+日期"、或者301重定向到现行的权威页,把权重导过去而不是丢掉。真正要彻底下架的,是那些既没流量、又口径错误、还在污染AI答案的"纯负债"页面——这种留着只有害处,删了一身轻。所以第四步我写的是"下架与归档过时内容",不是"无脑全删"。每个旧页面下手前问一句:它还有价值吗?有就改造,没有才下线。
设答案负责人是不是又要多招一个人、多一份预算?老板大概率不批。
多数情况下不用招人,是把责任明确到现有的某个人头上。这件事卡在没人负责,不是卡在没人手——你团队里本来就有人在管SEO、管内容,缺的只是有没有把"对外信息一致性"这个总责正式挂到某个人名下。跟老板汇报时也别讲"我要设个新岗位",讲"我们现在有个没人负责的风险敞口:AI正在跨市场给客户报错信息,已经引发过客服纠纷,我建议明确由某某牵头来盯这件事"。把它框成"堵一个正在漏水的风险",比框成"我要加预算"好批得多。规模真大到一个人扛不动,再谈独立成岗的事。
权威参考资料
- Google搜索中心:多区域与多语言站点管理指南——Google 多区域与多语言站点管理的官方指南。
- Schema.org:sameAs属性定义(实体身份关联)——sameAs 属性定义,跨市场实体身份关联的依据。
- W3C:国际化与本地化的区别——W3C 对国际化与本地化区别的权威解释。
- ISO 4217:国际货币代码标准——ISO 4217 国际货币代码标准。
- McKinsey:2025全球AI现状报告(治理与组织成熟度)——麦肯锡全球 AI 现状报告。
- Similarweb:2026生成式AI可见度统计——生成式 AI 可见度统计。
本文标题:《国际SEO进入AI时代:为什么hreflang挡不住跨市场知识污染》
本文链接:https://zhangwenbao.com/international-seo-global-knowledge-integrity-cross-market-ai.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0