AI可见性审计总漏的那一层:schema堆满了,实体之间的关系却没人审
本文目录
- 为什么你的schema做到几千行,AI还是把你漏在推荐名单外?
- 机器能不能读懂你,为什么非得拆成四层来看?
- 实体图回答你是谁,完整性图谱回答你和周围怎么连
- 一家出海品牌的schema全都对,AI却答不出德国到底保不保修?
- 市面上的AI可见性工具,到底帮你查了什么、又漏了什么?
- 关系完整性审计,到底要逐条对清哪些连接?
- 这张关系网怎么落进结构化数据里?给几组能照抄的连接写法
- 国际站最容易塌的一层:怎么把hreflang从URL升到知识层?
- 机器进得了门,不等于它读到对的东西——开了门反而更危险?
- 怎么把可见性审计升级成关系完整性审计?一份照着走的清单
- 这是不是只有大企业才用得上?小独立站该从哪一步起步?
- 常见问题解答
- 完整性图谱和知识图谱、实体图是一回事吗?
- 我的schema已经做得很全了,还需要做关系完整性审计吗?
- 关系完整性审计具体查哪些东西?
- 接了MCP、写了llms.txt,是不是就等于关系完整了?
- 小独立站、单一市场,也需要管这个吗?
- 知识层面的hreflang和普通hreflang有什么区别?
- 没有开发资源,关系完整性审计能先从哪步做起?
- 权威参考资料
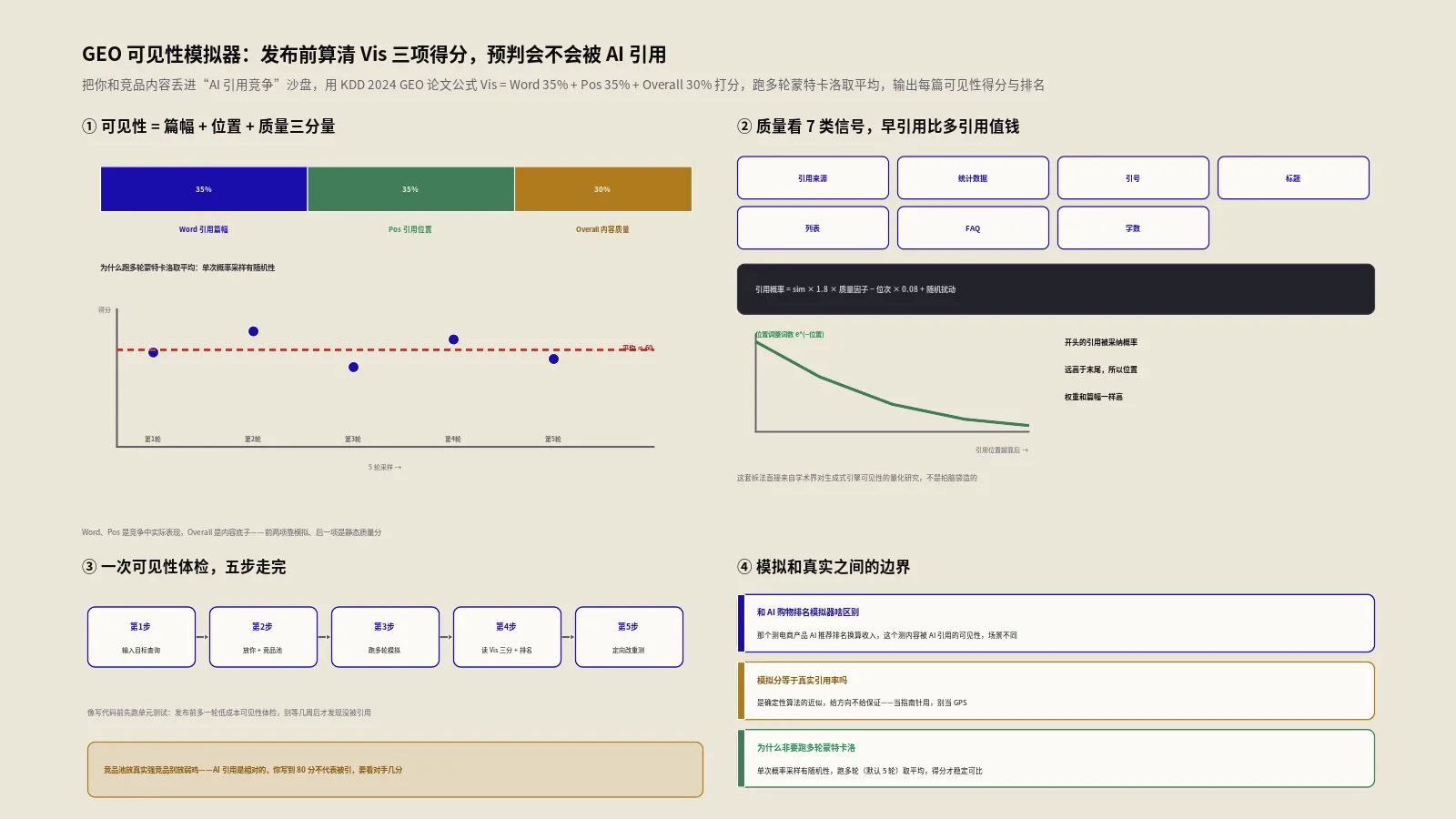
摘要:你给网站堆了几千行schema,单页验证全是绿勾,AI却还是不把你放进推荐名单——问题往往不在标记够不够,而在实体之间的关系压根没人审。机器读懂你分四层:能不能抓到、能不能调用、能不能认出你是谁、能不能读懂这些实体彼此怎么连。前三层全网都在卷,第四层关系完整性几乎没人碰,这就是AI可见性审计漏掉的那一层。这篇把它拆成照着走的清单:实体关系图、六条必审连边、把hreflang从URL升到知识层。出海做多市场、多法律实体、多产品线的站,最该补这一层。
为什么你的schema做到几千行,AI还是把你漏在推荐名单外?
先说一个很多技术SEO都撞过的墙:标记做得无可挑剔,结构化数据测试工具一片绿,单页验证条条通过,可一到AI概要、ChatGPT、Perplexity给用户推荐同类商家时,名单里就是没有你。
第一反应通常是再加标记。给产品补 Offer,给组织补 sameAs,给文章补 author,越加越细。可加到几千行,AI还是那副不认识你的样子。这时候该换个思路了:缺的可能不是更多标记,而是标记之间的连接。
打个比方,你把公司的每个零件都擦得锃亮——营业执照、产品手册、门店地址、服务条款,单拿出来每一份都齐整。但没人把这些零件装到一起,告诉机器:这个品牌归这家公司、这条产品线下有这几款、这项服务只在这几个市场办、这些条款只对欧盟用户成立。机器看到的是一地散件,拼不出一台能跑的车。
AI系统要做的事,恰恰是把散件拼成车。它要综合信息、要给推荐、要替用户行动,靠的不是单页有没有标记,而是实体之间那张关系网完不完整。单页验证再漂亮,也只证明了零件合格,证明不了整车能开。这就是审计里最容易被跳过、又最致命的一层。
更要命的是,这个洞越大的站越不容易自己发现。小站就几页,关系简单,断不了几条线;恰恰是SKU上千、市场好几个、标记做得最认真的大站,节点多到关系网密如蛛网,断几条线根本看不出来,验证器还一路给你绿灯。等你发现AI死活不推荐你,往往已经在这层盲区里裸奔很久了。
机器能不能读懂你,为什么非得拆成四层来看?
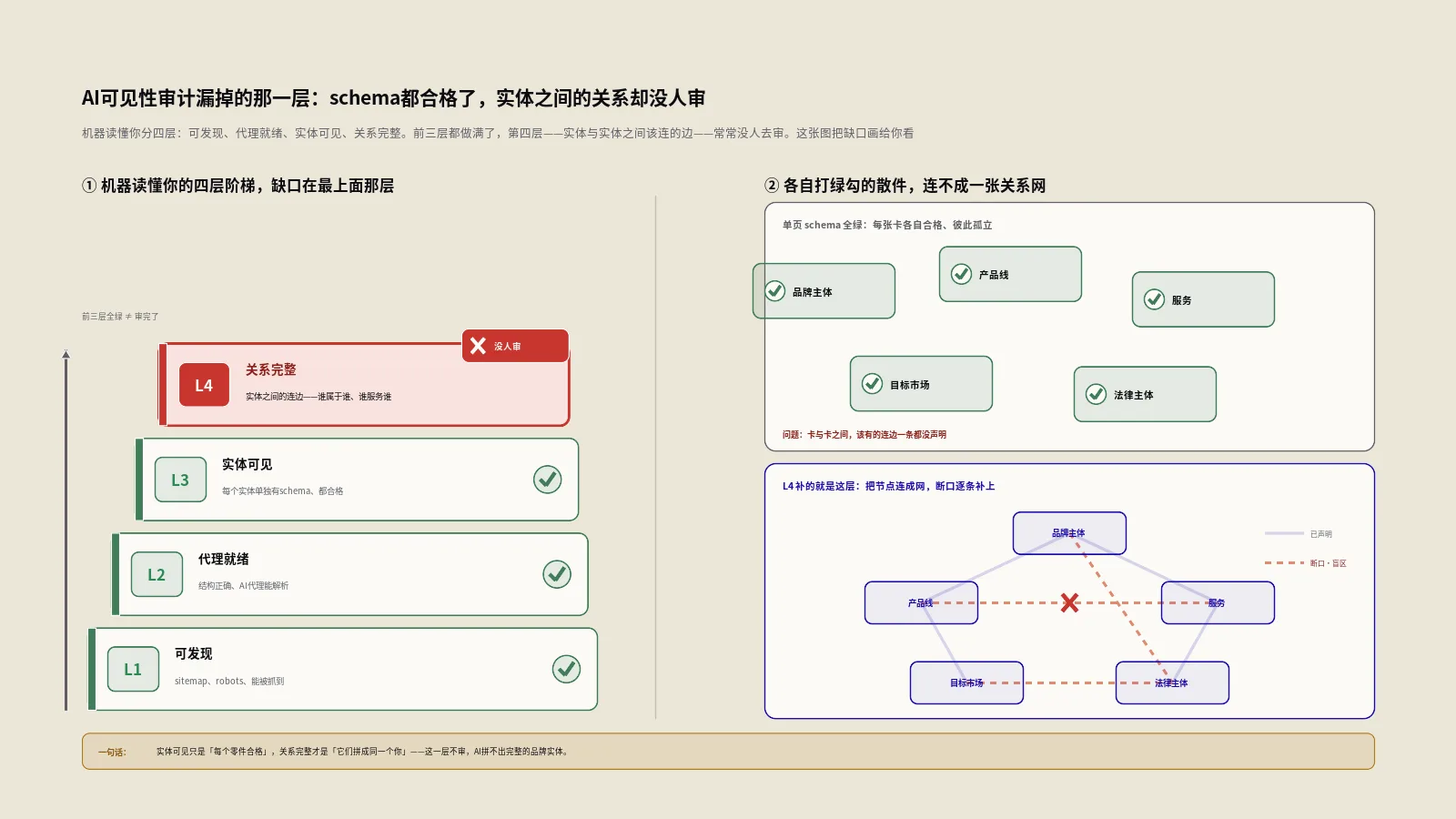
把机器理解你这件事拆开,会发现它不是一个开关,而是依次叠起来的四层能力。每一层都依赖下一层,缺了底下的,上面的就架空。
| 层 | 它在问什么 | 现状 |
|---|---|---|
| L1可发现·可访问 | AI爬虫抓不抓得到你的页面、读不读得到内容 | robots、渲染、抓取预算,老话题,工具一抓一大把 |
| L2代理就绪 | 机器能不能发现你提供的能力、调用你的接口 | llms.txt、MCP、agents.md正在抢标准 |
| L3实体可见 | AI认不认得出你是谁这个独立实体 | 实体SEO、知识图谱、sameAs 卷得飞起 |
| L4关系完整 | 机器读不读得懂你这些实体之间到底怎么连 | 几乎没人系统做——就是缺的那一层 |
L1是地基,解决能不能被抓到。这是技术SEO的老本行,抓取、渲染、可访问性,市面上每个审计工具都在查,不必多说。
L2往上一层,问的是机器能不能发现你的能力并跟你交互。这两年冒出来的llms.txt、agents.md,以及把网站能力暴露成接口的 Model Context Protocol官方规范,争的都是这一层的入口。值得提醒的是,这套代理标准的真实采用率,比社媒上的热闹低得多——一份针对美、英、德高知名度网站的基准盘点发现,绝大多数站点压根没暴露任何当下被热推的代理发现机制。要不要现在就为AI agent改造,本身就值得先做个决策,这事我在网站要不要为AI agent改造里专门拆过。
L3再往上,问的是AI认不认得出你是谁。这就是实体SEO的主场:用结构化数据、知识图谱、跨平台一致的实体信号,让机器把零散提及收敛成一个清晰可辨的实体,怎么搭这张语义网络可以看实体SEO指南。这一层这两年也卷成了红海。
问题出在第四层。前三层全网都在加码,唯独L4——机器能不能读懂你这些实体之间怎么相互关联——几乎没人当回事。大多数所谓的AI可见性审计,查到L3就收工了:确认AI认得出你,就宣布大功告成。可认得出你,和读得懂你和周围一切怎么连,完全是两码事。
为什么必须分层,而不是揉成一个AI可见度分数?因为四层的病因和药方完全不同。L1出问题是工程活,改robots、修渲染;L4出问题是建模活,得重画实体关系。揉成一个分数,你只知道分低,却不知道是抓不到、还是没接口、还是认不出、还是关系断了,等于体检报告只给一个不及格,不告诉你哪个器官出了事。分层,是为了让每一层的毛病各自归位、各自能修。
实体图回答你是谁,完整性图谱回答你和周围怎么连
这里要分清两个东西:实体图,和完整性图谱。
实体图解决的是身份。它把世界上的人、地、物、组织标成一个个节点,让机器知道苹果是家公司不是水果,知道你这个品牌是个确定的实体。Google结构化数据入门指南里讲的那套,本质上就是帮机器认节点。
但身份只是开始。真正决定AI能不能综合、能不能推荐、能不能替用户行动的,是节点之间那些边——谁拥有谁、谁属于谁、谁在哪儿可用、谁受哪条规则约束。完整性图谱要保住的,正是这些边上的上下文真实。
换句话说,实体图告诉机器你是谁,完整性图谱告诉机器你和你的产品、服务、门店、市场、法规之间到底是什么关系,而且这些关系是不是对的、是不是完整的、放在具体的市场和受众面前还成不成立。前者是名片,后者是关系网。AI给人推荐时,靠的是关系网,不是名片。
为什么偏偏是AI这一代特别吃这层关系?因为它干的三件事——综合、推荐、行动——每一件都建在关系上。综合,是把分散的信息拼成一个连贯回答,拼的就是节点间的边;推荐,是判断你适不适合这个用户这个场景,判断的是你和需求之间的关系;行动,是替用户下单、预约、咨询,每一步都要它确认哪个主体、哪项服务、哪个市场对得上。传统搜索给十个蓝链接让人自己拼,AI要直接给答案、给动作,拼的活儿落到了它头上,关系断一条,它就拼错一步。
这也解释了为什么单页schema全对,整体却塌方。因为schema验证只看一张名片填得规不规范,看不到名片之间该连的线断没断。一堆合格的名片堆在一起,机器照样拼不出一个能被信任、能被推荐的你。
这里的关键词是上下文真实,得多嚼一下。它不只要求信息正确,还要求信息在具体语境里正确。同一句这款产品保修两年,对美国用户是真的,对德国用户可能就是假的——不是数据错了,是它脱离了该成立的上下文。完整性图谱审的,就是每一条边在它该成立的市场、受众、辖区里,到底还成不成立。这一步,光靠把字段填对,永远查不出来。
一家出海品牌的schema全都对,AI却答不出德国到底保不保修?
讲个把这件事说透的场景,是国际化做大之后几乎必然撞上的坑。
设想一个做家居的中国品牌,出海几年,盘子铺得不小:在美国用品牌A卖,在德国因为商标撞车只能用品牌B,旗下还分了三条产品线,背后挂着两个不同的海外法律主体收款。这套结构,营收做得很漂亮,schema也每一块都做得很认真。
组织标记?完整。每个站点的 Organization 信息齐全。产品标记?完整。几百个SKU的 Product 和 Offer 一个不少。本地站点标记?也完整。地址、语言、货币都标得清清楚楚。单看任何一页,验证全过。
可当一个德国用户问AI:这个牌子的沙发,在德国坏了能保修吗、找谁保?AI卡住了。因为没有任何一处结构化数据告诉它:品牌A和品牌B其实是同一个品牌、保修这项服务在美国由主体一提供、在欧盟其实是走第三方、德国用户该联系的是品牌B名下的本地客服而不是美国总部。
这些信息,品牌自己当然门儿清。但它从来没有把哪个产品通过哪项服务交付、哪项服务在哪个市场可用、哪个法律实体对哪个市场负责这些连边,用机器能读的方式表达出来。schema描述了一个个孤立的节点,却没有描述它们如何组成一个连贯的、能运转的业务。AI读到的是一地合格的零件,拼不出德国能不能保修这个答案,于是它干脆不推荐,或者更糟,凭空猜一个错的。
这不是标记不够多,是关系没建。再加一千行 Product 也救不了,因为缺的根本不是产品信息,是产品、服务、市场、主体之间那张没人画的关系网。
顺带说一句,这个坑不分行业。把家居换成跨境SaaS,就是不同地区的套餐、计费主体、数据合规条款对不上;换成B2B制造,就是不同市场的认证、可售型号、售后网点连不起来。只要你的生意是多市场、多主体、多产品线,schema全绿和AI读不懂你,就会同时成立。
市面上的AI可见性工具,到底帮你查了什么、又漏了什么?
这两年AI可见性审计工具冒出来一堆,各有各的角度,但摊开看,它们大多卡在前三层,没人真正碰第四层。一张表对清楚:
| 审计类型 | 它查的 | 它漏的 |
|---|---|---|
| 抓取可见性审计(Common Crawl那一路) | AI爬虫能不能发现、抓取、读到你的内容 | 读到了,但读不出实体之间的关系 |
| 代理就绪审计 | 机器接口在不在、能不能调用 | 接口通了,但喂出去的数据准不准、全不全没人管 |
| 品牌AI可见性审计 | AI认你这个品牌认得准不准 | 认得准,但放到具体市场和上下文里对不对,照不到 |
| 关系完整性审计(这篇讲的) | 实体之间的连边对不对、全不全、在语境里成不成立 | 它正是来补前三者那个共同的盲区 |
看出门道了吗?前三类工具的盲区是同一个:它们各自把自己那层查得很细,却都默认实体之间的关系是对的、是全的。可现实是这张关系网恰恰最常断。你拿三把不同的尺子量了三遍,结论都是合格,但三把尺子没有一把量过连边。
所以别被一份漂亮的AI可见性报告骗了。报告全绿,只说明你过了前三层的体检,不等于AI能把你的业务读成一个连贯整体。真正该追问的是:有没有哪份审计,是拿着我的实体关系图,逐条去对连边的?如果没有,那第四层就还是个没人看过的黑箱。
怎么一眼看出一份审计有没有真碰第四层?看它的产出物。只查前三层的报告,给你的是一堆单页清单:这页缺schema、那页robots拦了爬虫。真碰第四层的审计,给你的是一张关系图加一份连边对账表,上面写的是品牌A和品牌B没互指、保修服务没标市场这种跨实体的结论。前者治的是页,后者治的是关系——交付物长什么样,基本就暴露了它查到第几层。
关系完整性审计,到底要逐条对清哪些连接?
那关系完整性审计,具体审什么?把抽象的关系落到地上,对出海和多市场的站来说,至少有六条连边必须逐个对清楚。它们不是新标记,而是已有节点之间该连而常常没连的线。
- 品牌归属:哪个法律实体真正拥有这个品牌。一个集团下挂好几个主体、几个商标,AI到底该把信誉、评价、责任算到谁头上,不能靠猜。
- 产品线隶属:哪些单品归到哪条产品线、哪个系列。产品线、系列、单品的层级关系断了,机器就没法理解你某个系列整体的定位。
- 服务与市场:哪项服务只在哪些市场提供。保修、退换、本地配送、安装,往往不是全球统一的,哪儿有哪儿没有,必须说清。
- 渠道与能力:哪个渠道或网点办得了哪些业务。线上线下、不同站点、不同区域仓,能力边界各不相同。
- 辖区与规则:哪个国家或地区适用哪一套规则。合规声明、税、退换政策、数据条款,按辖区走,张冠李戴就是事故。
- 全球与本地:哪些信息全球通用、哪些只对本地成立。价格、可用性、法律声明,混为一谈,AI就会把美国的条款讲给德国用户听。
这六条边,恰恰是单页schema验证永远照不到的盲区。验证器只会告诉你这一页的 Product 字段填全了没,不会告诉你这个产品和那项服务、那个市场之间的线断了。审关系完整性,审的就是把这些线一条条接上、并且确认接对了。
对清楚的诀窍,是别用是非题,要用配对题。不要只问品牌归属标了没,要问这个品牌到底归哪个主体、机器从标记里读出来的那个答案对不对。六条边,每一条都该能从你的结构化数据里读出一个明确、唯一、正确的另一端。读出来是空的、是错的、是模糊的多选,都是待补的洞。
举个最常见的待补洞:辖区与规则这条边。一个站把退换政策写成全站一个版本,schema里也只有一份 MerchantReturnPolicy,可实际上欧盟的14天无理由和美国的政策根本不是一回事。机器读到的是一份笼统政策,于是把美国的规则讲给了德国用户。这条边的修法不是删政策,是按 applicableCountry 把它拆成对应辖区的多份,让机器清楚哪份对哪个市场成立。
这张关系网怎么落进结构化数据里?给几组能照抄的连接写法
好消息是,这些连边大多不用造新轮子。Schema.org的数据模型文档里讲的 @id 引用机制,本来就是干这个的:给每个实体一个稳定的 @id,再在别的实体里用这个 @id 去指它,节点之间的线就连上了。几组最常用的写法:
- 品牌归属:在
Brand上用parentOrganization或在Product的brand里用@id指向那个唯一的Organization,把品牌和它背后的法律主体焊在一起。 - 产品线隶属:用
isPartOf或ProductGroup,让单品指回它所属的产品线,机器就能把散落的SKU收成一个系列。 - 服务与市场:在
Service、Offer上用areaServed标清楚这项服务、这个报价覆盖哪些地区,没覆盖的地区机器就不会乱许诺。 - 多市场马甲互指:用
sameAs把同一品牌在不同市场的不同名字、不同站点互相指认,告诉机器品牌A和品牌B是一个东西。
用 @id 连线的骨架,大概长这样:
{
"@context": "https://schema.org",
"@graph": [
{ "@type": "Organization", "@id": "https://example.com/#org-us", "name": "主体一" },
{ "@type": "Brand", "@id": "https://example.com/#brand-a",
"name": "品牌A", "parentOrganization": { "@id": "https://example.com/#org-us" } },
{ "@type": "Service", "@id": "https://example.com/#warranty-de",
"name": "保修服务", "areaServed": "DE",
"provider": { "@id": "https://example.com/#org-eu" } }
]
}注意这里的 @graph 把好几个实体装在一起,再靠 @id 互相引用——这正是把名片连成关系网的动作。难点从来不在语法,schema.org早就备好了这些属性;难的是先把关系想清楚,知道该连哪条线、连到哪个 @id。语法是体力活,建模才是脑力活。
所以别指望某个插件一键生成就万事大吉。插件能批量吐 Product,但它不知道你这个SKU该归哪条产品线、这项服务只在哪个市场办——这些只有你自己清楚,得你来连。工具负责把线画规范,你负责决定线往哪儿连。
还有个容易踩的坑:@id 一定要全站统一、稳定。同一个主体,在首页标成一个 @id,在产品页又换一个,机器就会把它当成两个不同的东西,你辛苦连的线反而把实体劈成了两半。给每个核心实体定一个唯一的、长期不变的 @id,再到处引用它——这是关系网能立住的地基,比多写几种类型重要得多。
国际站最容易塌的一层:怎么把hreflang从URL升到知识层?
六条连边里,出海站塌得最频繁的是最后两条——辖区和全球本地的区分。而这一层的代表性老工具,就是被误用得最狠的hreflang。
大多数人理解的hreflang,停在URL层:告诉Google这个页面的德语版在这儿、法语版在那儿,让搜索引擎给对的人发对的页。这套该做还得做,怎么做不出岔子可以参照 Google多地区多语言版本(hreflang)官方指南。但它解决的只是同一个东西的不同语言外壳,是页面层的对应。
AI时代要补的,是知识层的对应。机器需要知道的不只是这页有德语版,而是:在德国这个市场,这个品牌叫什么、哪个主体负责、哪项服务可用、价格和条款按哪套走。这不是翻译问题,是事实问题——同一个集团,在不同市场,事实本身就不一样。
知识层的hreflang,要回答的是给定一个市场和受众,关于你的哪些事实是正确的。德国用户看到的保修方、法国用户适用的退换窗口、美国用户认的品牌名,都是这张表上不同的格子。光在页面头上塞一行 hreflang 标签,机器只知道有个德语版,不知道德语版背后那套事实和英语版根本是两回事。
这也是国际化SEO最反直觉的地方:最难的从来不是把hreflang标对,而是把跨市场的实体、主体、服务、条款对齐成一张机器读得懂的事实表。这件事我在国际化SEO最难的不是hreflang里掰开讲过,跨语言的实体对账,才是大站真正卡壳的地方。把hreflang从URL层升到知识层,本质上就是把关系完整性的最后两条边补上。
机器进得了门,不等于它读到对的东西——开了门反而更危险?
这一节想泼一盆冷水,专门给那些急着上llms.txt、急着接MCP的人。
给机器开一扇可读的门,本身没错。但门只有在通向准确、连接、上下文完整的信息时才值钱。如果门后面那套关系模型本身是残的、是错的,那你开的不是机会之门,是一条把错误信息更快送出去的高速路。
这是个容易被忽略的反转:代理访问让信息更容易被取到,可如果信息本身不完整,它只是让不完整更容易被检索、被引用、被当成事实讲出去。原本错误信息藏得深,少有人挖;现在你亲手修了条专用通道,把它直接递到AI嘴边。机器进门进得很顺,读到的却是张缺了一半的关系网,然后一脸笃定地把缺的那半边猜出来讲给用户——这比它压根找不到你,麻烦得多。
所以顺序不能反。不是先开门再补关系,而是先把关系建对、建全,再去开那扇机器可读的门。L2的代理就绪,前提是L4的关系完整。底层关系模型是残的,你接的MCP、写的llms.txt越完善,错误传得越快越广。说白了,把一条断头路修成八车道高速,车只会撞得更整齐。
这条原则反过来也给了你一个判断标准:在系统性补齐关系完整性之前,别急着把自己包装成AI-ready。能被机器调用,和值得被机器调用,中间隔着的就是这张关系网完不完整。先问自己一句,机器顺着我开的门进来,读到的是不是一套对的、全的关系——答不上来,这门就先别急着开。
怎么把可见性审计升级成关系完整性审计?一份照着走的清单
道理讲完,落到能动手的步骤。把现有的AI可见性审计,升级成带关系完整性的审计,可以照这条线走。
第一步,先把该做的可见性审计做扎实。L1到L3不是不重要,而是关系完整性的前提——抓不到、认不出,谈连边没意义。抓取、内容、实体、AI可见度这套完整诊断怎么排,可以对着企业网站SEO审计该查什么过一遍,把前三层的底子打牢。
第二步,画一张实体关系图。把你这门生意里所有的实体列出来——法律主体、品牌、产品线、单品、服务、门店或区域、目标市场,然后在它们之间画线:谁拥有谁、谁属于谁、谁在哪儿可用、谁受哪条规则管。这张图不用工具也能画,一张白板就够,关键是把脑子里默认的关系,第一次显式地摆出来。很多洞,你一画图就当场看见了——原来这条产品线和那个主体之间,自己都说不清是什么关系。
第三步,逐条验证连边在结构化数据里有没有被表达。拿着关系图上的每一条线,去问:这条关系,机器从我的标记里读得出来吗?品牌归属有没有用 parentOrganization 或 brand 连上?产品线隶属有没有 isPartOf?服务和市场有没有 areaServed?同一品牌的多市场马甲有没有 sameAs 互指?连边在图上有、在标记里没有,就是一个待补的洞。
第四步,跨市场对账。按市场拉一张事实表,每个市场一列,把品牌名、负责主体、可用服务、适用条款、价格口径逐格填清,确认机器在每个市场读到的事实都是对的。这一步就是前面说的知识层hreflang,是出海站最容易出错、也最值钱的一步。
第五步,把它变成固定动作。关系不是建一次就一劳永逸的——你上了新产品线、进了新市场、换了海外主体、改了退换政策,关系网就动了。保哥的建议是把关系完整性审计排进季度复盘,跟着业务的真实变动滚动更新,而不是等出了问题再回头补。
怎么知道补对了?最直接的验法,是拿你最关心的几个真实问题去问AI——某产品在某市场保不保修、某条款对哪些用户成立——看它答得上、答得对没有。改之前它含糊其辞或张冠李戴,改之后能干脆答对,这条边就算接通了。这比盯着验证器的绿勾靠谱得多,因为你测的正是AI最终读出来的那个答案。
这是不是只有大企业才用得上?小独立站该从哪一步起步?
看到这儿可能有人想,我就一个单一市场的小独立站,哪来那么多主体和市场,这套是不是大集团才玩得起?
关系完整性的颗粒度,是跟着生意复杂度走的,但起点对谁都一样。哪怕你只有一个市场、一个主体,你照样有实体:品牌、几条产品线、几款主推单品、退换和配送政策。把它们之间的隶属和归属关系,用 isPartOf、brand 这些机制显式连起来,成本极低,却能让AI早一步把你读成一个连贯的整体,而不是一堆散页。
真正该把它当回事、当成系统工程来做,是这几种信号同时出现的时候:你开始进第二个、第三个市场;你为了合规或商标,在不同地区挂了不同主体或不同品牌名;你的产品线多到客户自己都容易绕晕;你的服务(保修、退换、配送)开始按市场分化。命中两条以上,关系完整性就从锦上添花变成了必修课。
给个最朴素的起步动作:今天就画那张实体关系图,哪怕画在一张纸上。把你的主体、品牌、产品线、服务、市场列出来,互相连线,然后挑出三条你觉得最关键、却很可能没在标记里表达的关系,去验证一下机器到底读不读得到。大概率,你会在半小时内找到至少一条断掉的线。补上它,就是这套方法给你的第一笔回报。
说到底,下一代竞争优势不在于谁的schema最多、谁的页面最多、谁挂的AI接口最多,而在于谁能给出关于自己的实体、产品、服务、位置、品牌、市场如何相互关联的最清晰、最完整、最可信的那一份表示。认出一个实体只是起点,读懂这个实体和它周围的一切怎么连,才是价值真正所在的地方。
常见问题解答
完整性图谱和知识图谱、实体图是一回事吗?
不是一回事,是上下游关系。实体图和知识图谱解决的是身份——把人、地、物、组织标成一个个能被机器认出的节点。完整性图谱往上走一层,关心的是节点之间那些边对不对、全不全:谁拥有谁、谁属于谁、谁在哪个市场可用、谁受哪条规则管。前者让机器认得出你,后者让机器读得懂你和周围怎么连。AI给人推荐时靠的是后者那张关系网,不是前者那张名片。
我的schema已经做得很全了,还需要做关系完整性审计吗?
需要,而且schema越全越该做。schema全,证明的是每一页的字段填得规范,属于单页验证;关系完整性审计查的是页与页、实体与实体之间该连的线断没断,是跨实体的事。两者照的是完全不同的盲区。现实里恰恰是标记做得最认真的大站,最容易栽在关系上——节点个个合格,连边却没人管,机器照样拼不出一个能被推荐的你。
关系完整性审计具体查哪些东西?
核心是六条连边:品牌归哪个法律实体、单品归哪条产品线、哪项服务在哪些市场可用、哪个渠道办得了哪些业务、哪个辖区适用哪套规则、哪些信息全球通用哪些只对本地成立。审的方式是先画一张实体关系图,把这些关系显式摆出来,再逐条去验证它在结构化数据里有没有被表达、表达得对不对。验证器照不到这一层,得靠人拿着关系图一条条对。
接了MCP、写了llms.txt,是不是就等于关系完整了?
恰恰相反,顺序反了反而更危险。MCP和llms.txt解决的是机器能不能进门、能不能调用你,属于代理就绪那一层。它们让信息更容易被取到,但如果你底层的关系模型本身是残的、是错的,开这扇门只会让错误信息更快地被检索和引用。正确的顺序是先把关系建对建全,再去开机器可读的门,否则等于把一条断头路修成了八车道高速。
小独立站、单一市场,也需要管这个吗?
需要,只是颗粒度小很多。哪怕只有一个市场、一个主体,你也有品牌、产品线、单品、退换和配送政策这些实体,把它们之间的隶属关系用 isPartOf、brand 显式连起来,成本很低,却能让AI早一步把你读成一个整体。真正要当系统工程来做,是在你进了多个市场、挂了多个主体或品牌名、产品线变多、服务按市场分化的时候——命中两条以上,它就从可选变成必做。
知识层面的hreflang和普通hreflang有什么区别?
普通hreflang是URL层的,告诉搜索引擎同一个页面的德语版、法语版各在哪儿,解决的是语言外壳的对应。知识层的hreflang是事实层的,要让机器知道在某个具体市场关于你的哪些事实成立——这个市场你叫什么品牌、哪个主体负责、哪项服务可用、条款按哪套走。同一个集团在不同市场,事实本身就不一样,这不是翻译能解决的,得把跨市场的实体和事实对齐成一张机器读得懂的表。
没有开发资源,关系完整性审计能先从哪步做起?
从一张纸开始,不需要任何工具。把你的法律主体、品牌、产品线、单品、服务、市场列出来,互相连线,这张实体关系图就是整套审计的骨架。画完挑出三条你觉得最关键、却很可能没在标记里表达的关系,手动去验证机器读不读得到。这一步零成本,却几乎一定能让你当场发现至少一条断掉的线。后续要补标记、要跨市场对账,再按优先级慢慢排资源。
权威参考资料
本文标题:《AI可见性审计总漏的那一层:schema堆满了,实体之间的关系却没人审》
本文链接:https://zhangwenbao.com/integrity-graph-relationship-completeness-ai-visibility-audit.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0