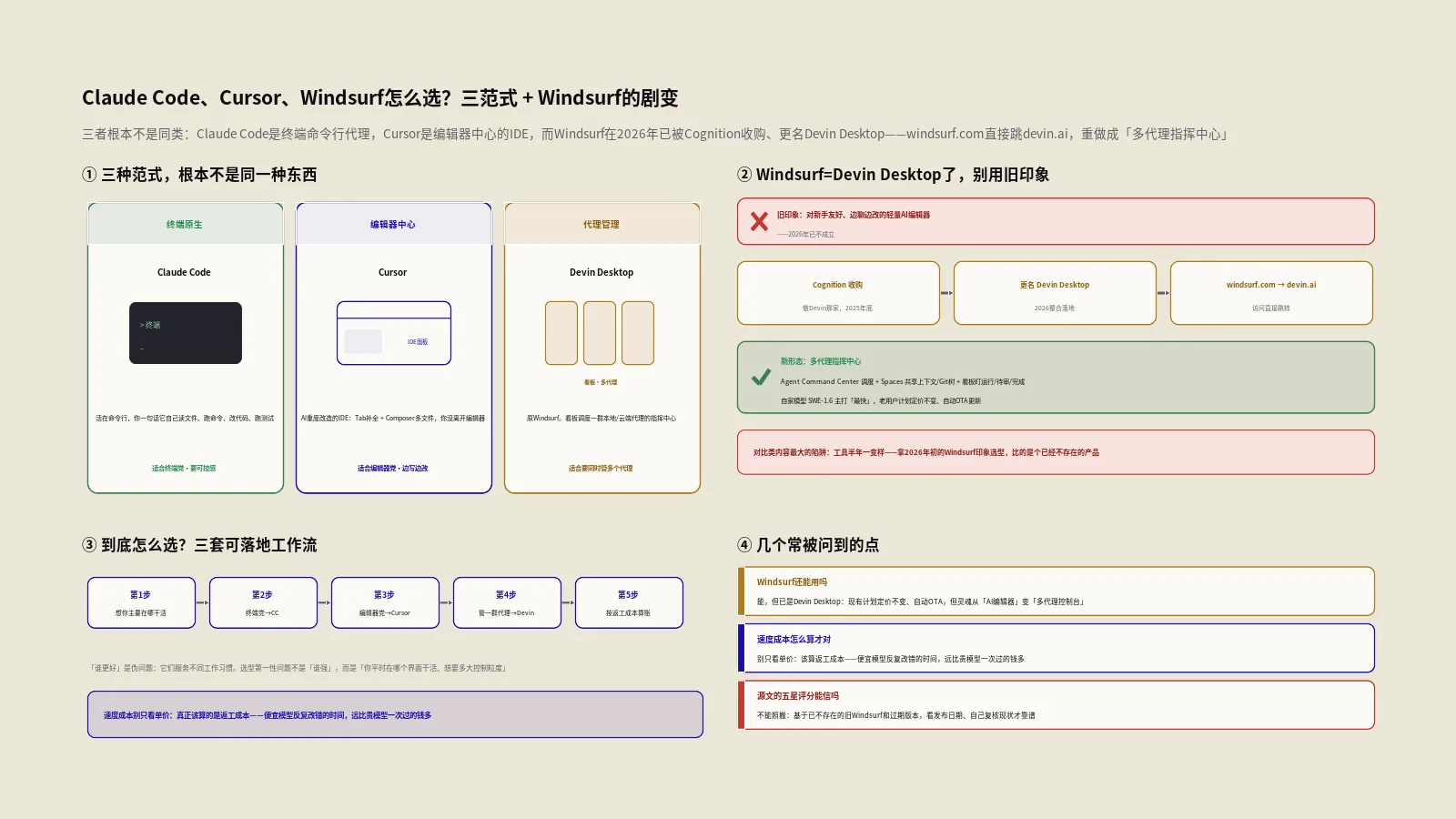
Claude Code Worktree实战:一个仓库并行跑多个AI任务

本文目录
- 为什么并行开发时分支切来切去这么痛?
- claude --worktree到底帮你做了什么?
- worktree里那些gitignore的文件(.env)怎么办?
- 怎么从一个PR或指定分支开worktree?
- 能不能让子代理各自在隔离的worktree里跑?
- worktree用完会自动清理吗?
- 开了好几路并行,怎么盯得过来又不丢进度?
- worktree和直接切分支,到底差在哪?
- 真实场景:一个人同时推几个任务是什么体验?
- 有哪些坑和适用边界?
- 常见问题解答
- Worktree和git clone有什么区别?
- 跟在--worktree后面应该写什么?
- worktree里能正常提交代码吗?
- worktree里改的东西怎么合并回主分支?
- worktree会自动清理吗?
- .env这类gitignore文件为什么worktree里没有?
- 一个人同时开几路worktree比较合适?
- worktree里跑的测试和主目录会互相影响吗?
摘要:大多数人以为“让Claude Code并行干活”得开好几个文件夹、手动
git worktree add一通折腾。其实2026年的Claude Code早就把这套内建了:一条claude --worktree feature-auth,它自己开好隔离的工作目录、拉好新分支、连.env都能按规则带过去。真正卡住新手的从来不是命令,而是不知道每个worktree是独立checkout——依赖要重装、环境变量不会自动跟过来。这两点想通了,一个人同时推三四个任务才不会乱套。
保哥团队带跨境SaaS和独立站的研发时,经常碰到这种场景:一个紧急线上bug要修,手头的新功能又写到一半,传统做法是git stash存一下、切分支、修完再切回来、stash pop,一来一回不仅烦,还容易把改了一半的代码搞乱。Git worktree加上Claude Code的原生支持,正是为了根治这种“切来切去”的痛。这篇把内建的--worktree用法、隔离文件怎么带、子代理隔离、自动清理规则,到一个人开多路并行的真实体感,一次讲透,所有命令对着官方文档校过。
为什么并行开发时分支切来切去这么痛?
先说传统单工作目录的死结。一个Git仓库默认只有一个工作目录,同一时刻只能停在一个分支上。你正在feature-a上写新功能,老板说线上有个急bug,你只能:
git stash # 把没写完的改动塞进暂存区
git checkout hotfix-branch # 切到修复分支
# ……修完bug,提交,再切回来
git checkout feature-a
git stash pop # 把刚才的改动捞回来这套流程有三个隐患:stash多了容易忘记哪个是哪个;切分支会让编辑器里打开的文件、跑着的开发服务器全部失效;最要命的是,如果你同时想让AI在feature-a上继续写、又在hotfix上修bug,单工作目录根本做不到——它俩会抢同一批文件。
这里还藏着一笔很多人没算过的隐性成本:语境切换。你写新功能写到心流状态,被迫切去修bug,等修完切回来,脑子里那张“我刚才改到哪了、接下来要干嘛”的地图已经糊了,得花好几分钟重新捡起来。一天被打断三五次,光是重新进入状态就耗掉大半个小时。开发圈早有共识,切换任务的真实代价从来不是切换那几秒,而是切换之后重新聚焦的那十几分钟。worktree的价值恰恰在这里:新功能那一路的编辑器、开发服务器、跑了一半的测试,全都原样留在它自己的工作目录里,你修完bug回来,现场跟离开时一模一样,不用重新热身。对一个人要扛多条线的独立开发者和小团队,这种“现场保留”比并行本身更值钱。
Git worktree的解法很优雅:同一个仓库,可以挂多个工作目录,每个目录停在不同分支上,共享同一份提交历史和远程。手动版长这样:
git worktree add ../project-hotfix -b hotfix-branch # 新建一个工作目录+新分支
git worktree list # 看现有worktree
git worktree remove ../project-hotfix # 用完移除这样../project-hotfix是个独立的文件夹,停在hotfix-branch上,你在主目录的feature-a改动一点不受影响。两个目录可以同时跑两个Claude Code会话,互不打架。这就是并行的基础。
claude --worktree到底帮你做了什么?
手动git worktree能用,但繁琐。Claude Code把它内建成了一个标志,这是源教程里讲得最浅、其实最该展开的一块。直接:
claude --worktree feature-auth这一条命令背后,Claude Code替你做了三件事:在仓库根目录下的.claude/worktrees/feature-auth/建好一个隔离的工作目录;在上面拉一条名为worktree-feature-auth的新分支;然后直接在这个目录里把Claude会话起起来。短选项-w完全等价,敲claude -w feature-auth一样。
在第二个终端里换个名字再跑一次,就是第二路隔离会话:
claude --worktree bugfix-123它常和计划模式搭着用。开一个worktree专门跑那种你拿不准、想先看方案再动手的改动,进会话后用--permission-mode plan或者会话里按Shift+Tab切到计划模式,Claude会先读文件、给出一份计划,你点头之前它不碰任何磁盘文件。在隔离的worktree里审方案,审完不满意整个目录一弃了之,主分支毫发无伤——这种“低风险试验田”正是worktree最舒服的用法之一。
有个容易被忽略的细节:跟在--worktree后面的是worktree的“名字”,不是任务描述。不少人照着某些教程写成claude --worktree "帮我加个用户接口",把一整句任务塞进去,结果生成一个名字怪异的目录。名字就给个短横线连接的标识,比如feature-auth、bugfix-123。要是懒得起名,干脆省略,Claude会自动生成一个像bright-running-fox这样的名字:
claude --worktree还有个体验很顺的地方:你已经在一个会话里了,直接对Claude说“在一个worktree里干这个活”,它会用内部的EnterWorktree工具自己开一个。开完之后还能再切到.claude/worktrees/下的另一个worktree,原来的那个原封不动留在磁盘上。
两个前置条件得记住。第一,某个目录第一次用--worktree前,必须先在该目录裸跑一次claude,过一遍工作区信任弹窗,否则--worktree会直接报错让你先这么做。第二,强烈建议把.claude/worktrees/加进.gitignore,免得worktree内容在主目录里显示成一堆未跟踪文件。把Claude Code装好跑通这些前置,可以先看Claude Code安装配置完全指南。
worktree里那些gitignore的文件(.env)怎么办?
这是新手第一个真正会栽的坑,源教程只用一句“记得cp .env”草草带过,其实官方早就给了更优雅的方案。
问题的根源在于:worktree是一份全新的checkout,那些被gitignore掉的本地文件——.env、.env.local、本地密钥配置——根本不会跟过来。你在新worktree里一跑就报“缺少环境变量”,一脸懵。手动cp当然能解,但每开一个worktree都得复制一遍,迟早忘。
官方的解法是在项目根目录放一个.worktreeinclude文件,用.gitignore同样的语法,列出要自动带进每个新worktree的文件:
# .worktreeinclude
.env
.env.local
config/secrets.json有了它,每次Claude Code建worktree都会自动把这几个文件复制进去。这里有个安全又贴心的限制:只有“既匹配规则、又确实被gitignore”的文件才会被复制,已经被Git跟踪的文件绝不会重复拷贝。而且它对--worktree、子代理worktree、桌面版的并行会话全都生效。配好这一个文件,环境变量这个坑就彻底填平了。
怎么从一个PR或指定分支开worktree?
默认情况下,worktree从仓库的默认分支origin/HEAD切出来,所以它起点是干净的、和远程对齐的状态。如果没配远程或者拉取失败,就退回到你当前的本地HEAD。想让它永远从本地HEAD切(带上你还没推的提交和特性分支状态),在设置里把worktree.baseRef设成head:
{
"worktree": {
"baseRef": "head"
}
}这个设置只认fresh和head两个值,填别的git引用无效。它在隔离子代理、需要基于“进行中的工作”操作时特别有用。
更实用的是直接从一个PR开worktree。把PR号加上#前缀传进去,或者贴完整的GitHub PR链接,Claude Code会从origin拉pull/<号>/head,在.claude/worktrees/pr-<号>建好worktree:
claude --worktree "#1234"做代码审查时这招太省事了——一条命令就把别人的PR拉到一个隔离环境里,让Claude帮你审,审完直接弃掉,主分支一点没动。保哥团队现在review外包或新人提交的PR,基本都走这条路:开一个PR worktree,让Claude先通读改动、列出潜在风险点,自己再带着这份清单逐处确认。比起在网页上对着diff一行行看,这种“拉到本地、跑得起来、AI先过一遍”的方式,既能实际运行验证,又不会把半成品代码混进自己的工作区,审查效率和质量都高了一截。
当然,如果你要的是完全自定义的位置和分支配置,手动git worktree仍是最灵活的:
git worktree add ../project-feature-a -b feature-a # 新分支
git worktree add ../project-bugfix bugfix-123 # 基于已有分支
cd ../project-feature-a && claude # 进去起会话
git worktree list # 列出
git worktree remove ../project-feature-a # 移除手动建的worktree记得自己初始化开发环境:装依赖、建虚拟环境、跑项目该跑的setup,一样都不能少。想把这些初始化动作自动化,可以用钩子,详见Claude Code Hooks完全指南。
能不能让子代理各自在隔离的worktree里跑?
能,而且这是worktree最被低估的用法。当你让Claude派出多个子代理(subagent)并行探索或改代码时,它们默认共享同一份文件,并行写就可能撞车。给子代理配上worktree隔离,每个子代理都在自己的临时worktree里干活,互不干扰。
临时起意的话,直接对Claude说“给你的代理们用worktree”。想固化成默认行为,就在自定义子代理的frontmatter里加一行isolation: worktree。每个子代理会拿到一个临时worktree,干完活如果没产生任何改动,这个worktree会被自动清掉,不留垃圾。
子代理worktree的基准分支和--worktree一致,默认从仓库默认分支切,除非你把worktree.baseRef设成了head。这套机制配合Claude Code的多代理协作,才是真正意义上的“一个人指挥一支并行小队”——每个成员有自己的隔离工位,谁也不会动到别人的桌子。
这里要厘清一组容易混的概念,因为它们都跟“并行”有关,但解决的是不同层面的问题。worktree管的是文件隔离,让并行的编辑互不覆盖;子代理管的是把一块独立的活委派出去,让它在自己的上下文窗口里读文件、查代码,只把结论带回来,不污染你的主对话;代理团队(agent teams)则更进一步,自动协调多个Claude会话之间的分工。三者经常叠用:让子代理开着worktree隔离去并行改代码,是最常见的组合。搞清楚“隔离、委派、协调”分别由谁负责,你才知道一个具体场景该用哪一招,而不是一股脑全堆上。
worktree用完会自动清理吗?
会,但规则得搞清楚,不然要么留一堆垃圾目录,要么误删了没保存的改动。退出worktree会话时,清理逻辑取决于你有没有改东西:
- 没有任何未提交改动、未跟踪文件、新提交:worktree和它的分支会被自动移除。如果这个会话起了名字,Claude会先问你一句,方便你留着以后用。
- 存在未提交改动、未跟踪文件或新提交:Claude会问你保留还是移除。保留就把目录和分支留着,以后回来接着干;移除会删掉worktree目录和分支,连带丢弃所有未提交改动、未跟踪文件和提交——这一步要看清楚再点。
- 非交互运行:用
--worktree配-p跑的非交互任务不会自动清理,因为没有退出时的询问环节,得自己git worktree remove。
还有个区别要记牢:Claude给子代理和后台会话建的worktree,会在超过你设置的cleanupPeriodDays天数后被自动清扫掉(前提是没有未提交改动、未跟踪文件、未推送提交);但你自己用--worktree建的worktree,永远不会被这个定时清扫动到,得手动收拾。这条分界线很多人不知道,结果要么以为自己的worktree会自己消失(不会),要么担心子代理留垃圾(会自动清)。
开了好几路并行,怎么盯得过来又不丢进度?
很多人卡在这一步:worktree是开起来了,可三四个终端铺开,眼睛根本忙不过来,一个会话跑完了自己都不知道。这其实是并行的真正门槛——不是开不出来,是管不过来。Claude Code在这块也给了配套。
第一招是给会话起名字。带名字的worktree会话,退出时不会被默默清掉,Claude会专门问你留不留,方便你过几天回来接着干。名字也让你在一堆并行会话里一眼认出哪个是哪个,不至于对着三个匿名终端发懵。
第二招是续接,别重头再来。一个任务跨好几次坐下来做很正常,没必要每次重新跟Claude讲一遍背景。Claude Code会把每段对话存在本地:
claude --continue # 直接续上当前目录最近的那次会话
claude --resume # 从一个列表里挑要续的会话--continue会接上当前目录最近的一次会话,要是这个目录还没有会话,它会提示No conversation found to continue然后退出。--resume则弹出列表让你挑。在worktree并行的语境下,这两条命令就是你的“存档读档”——每一路任务都能随时离开、随时回到原地。
第三招,如果你嫌开一堆终端太累,可以让并行会话跑成后台代理,在一块屏幕上统一盯着所有进度,而不是在终端之间来回切窗口。审查别人PR时还有个顺手的入口:用gh pr create建的PR会自动和会话关联,之后claude --from-pr <号>就能回到那次会话。把“起名字、能续接、统一监控”这三件事配齐,并行才真正可持续,不然开三路只会比单路更乱。
worktree和直接切分支,到底差在哪?
一句话:切分支是“一个工位换着用”,worktree是“多开几个工位”。摊开看:
| 维度 | Worktree模式 | 直接切分支 |
|---|---|---|
| 文件隔离 | 每个worktree独立文件系统,互不可见 | 共享同一份文件,切换即覆盖 |
| 并行能力 | 多会话真并行,可同时跑多个Claude | 单线程,同一刻只能在一个分支 |
| 依赖安装 | 每个worktree独立装一次 | 切回来按需重装 |
| 磁盘占用 | 每个worktree各占一份文件 | 只有一份文件 |
| 编辑器/开发服务器 | 各worktree独立,不会互相打断 | 切分支会让打开的文件、跑着的服务失效 |
取舍很清楚:worktree拿磁盘空间和一次性的依赖安装,换来真正的并行和零干扰。对要同时推多个任务、或者想让AI多路作战的人,这笔账非常划算;只是偶尔切一下分支、磁盘又紧张,那直接切分支更省。
真实场景:一个人同时推几个任务是什么体验?
讲点保哥这边的实际带队经验。一个做Shopify生态工具的小团队,三个开发,以前是典型的“一人一分支、串行干”。引入Claude Code的worktree并行后,工作方式整个变了样。
一个开发的常态变成:终端一里claude -w fix-webhook,让Claude盯着一个偶发的订单webhook丢失问题;终端二里claude -w dashboard-v2,自己带着Claude写新版数据看板;终端三里claude -w refactor-auth,跑一个登录模块的重构。三路并行,一个人盯着三块屏,哪块出结果了就过去review一下。原来一个上午只能推一件事,现在三件事的进度条一起往前走。
他们也实打实踩过坑,正好印证前面讲的两点。最早没配.worktreeinclude,新worktree里npm run dev一跑就报缺.env,开发一脸问号以为环境坏了,排查半天才发现是worktree不带gitignore文件。配上.worktreeinclude把.env和本地配置自动带过去,再写个一行的setup把npm install串进去,这坑就再没犯过。还有一次,一个worktree里改了一半没提交,退出时手一快点了移除,改动全没了——从那以后团队约定:带名字起会话、退出看清提示再动。这些不是命令本身的问题,是“每个worktree是独立checkout”这个心智模型没建立起来时的必然学费。
真正让他们效率上一个台阶的,是把worktree和前面说的“起名字、能续接”配齐之后。每路任务都带个一眼能认出的名字,做到一半被别的事打断,claude --continue回到那个worktree接着干,背景一句不用重讲。有了这套,三路并行不再是“同时开三个头、最后哪个都没收尾”,而是真能各自往前推、各自收口。一个开发现在一天能合三四个小PR,放在串行时代是想都不敢想的节奏。
用顺之后,他们还把常用操作包了个bash函数简化,本质上就是给claude -w套个壳少敲几个字。这类小工具因人而异,但思路是相通的:把高频动作做成肌肉记忆,并行才跑得顺。配合Claude Code高效开发技巧里的若干习惯,一个人当三个人用不是夸张。不过保哥也常提醒:并行是放大器,它放大产出,也放大混乱。底子是清晰的分支纪律和及时review,worktree只是把这套纪律的天花板抬高了,替代不了纪律本身。
有哪些坑和适用边界?
最后把容易被忽视的边界条件集中列一下:
- worktree不是越多越好:每个worktree都占一份磁盘、装一次依赖,盲目开七八个,磁盘和心智负担都会爆。一个人同时盯的并行任务,三到五路是比较舒服的上限,再多review都顾不过来。
- 非git版本控制也能用:默认走git,但SVN、Perforce、Mercurial可以通过配置
WorktreeCreate和WorktreeRemove钩子来自定义创建和清理逻辑。注意一旦用了钩子替代默认行为,.worktreeinclude就不再生效,得在钩子脚本里自己复制本地配置文件。 - 桌面版会给每个新会话自动建worktree:如果你用Claude Code桌面版,它默认就给每个新会话开一个worktree,并行是开箱即用的,不用手动敲命令。
- worktree只解决文件隔离:它管的是“编辑不打架”,至于多个任务之间怎么协调、谁先谁后,那是子代理和多代理协作要解决的事,别指望worktree帮你做任务编排。
- 共享同一份历史和远程:所有worktree背后是同一个仓库,你在某个worktree里提交、推送,其它worktree
git fetch后都能看到。它们是平行的工作面,不是互相独立的克隆。 - 同一个分支别开两个worktree:Git不允许两个worktree同时检出同一条分支,会直接报错。每个worktree要么用各自的新分支,要么基于不同的已有分支,这是设计使然,不是bug。
- 大型仓库要留意磁盘和node_modules:前端项目一个
node_modules动辄上百MB,开五个worktree就是五份。磁盘紧张时,可以考虑用包管理器的全局缓存或硬链接方案(如pnpm)来摊薄,否则几路并行下来磁盘见红是常事。
把这些理清,worktree就从一个“听起来很高级”的功能,变成你每天都离不开的并行底座。它的全部官方细节,以Claude Code官方worktrees文档为准;想了解它在并行会话整体工作流里的位置,可以读Claude Code官方的常用工作流指南;而worktree底层依赖的Git机制,Git官方的git-worktree文档讲得最透彻。把这三份当底本,任何二手教程里把任务描述当worktree名、或漏讲.worktreeinclude的错,你一眼就能识破。
常见问题解答
Worktree和git clone有什么区别?
git clone是把整个仓库连同历史完整复制一份,各自独立、占空间大;worktree只新建一个工作目录,背后共享同一份提交历史和远程,轻量得多。要并行开发用worktree,要完全独立的副本才用clone。
跟在--worktree后面应该写什么?
写worktree的名字,一个短横线连接的标识,比如feature-auth、bugfix-123,不是任务描述。别把整句任务塞进去。想偷懒可以完全省略名字,Claude会自动生成一个。
worktree里能正常提交代码吗?
能,每个worktree停在自己的分支上,提交、推送都正常,和普通工作目录无异。它们共享同一个远程,你在一个worktree推的提交,别的worktree fetch后就能看到。
worktree里改的东西怎么合并回主分支?
和平时一样走分支合并。worktree用的分支名默认是worktree-加你给的名字,在主目录里git merge这个分支即可,或者推上去开PR合。worktree只是隔离了文件,分支合并流程不变。
worktree会自动清理吗?
分情况:没改过任何东西的会话退出时自动移除worktree和分支;有未提交改动会先问你。子代理和后台会话的worktree超过cleanupPeriodDays天自动清扫,但你自己用--worktree建的永远不会被定时清扫,得手动remove。
.env这类gitignore文件为什么worktree里没有?
因为worktree是全新checkout,被gitignore的本地文件不会跟过来。解法是在项目根放一个.worktreeinclude文件,用gitignore语法列出要自动带进每个worktree的文件,Claude Code建worktree时会自动复制。
一个人同时开几路worktree比较合适?
经验值是三到五路。再多,你review和切换的注意力就跟不上,反而每路都推不动。worktree能力上不设限,但人的带宽有限,配合给会话起名字、用--continue续接,三五路是既高产又不乱的舒服区间。
worktree里跑的测试和主目录会互相影响吗?
文件层面不会,各worktree文件系统独立。但要当心共享资源:如果几路测试都连同一个本地数据库、抢同一个端口,照样会打架。涉及外部资源的并行任务,记得给每路配不同的端口或独立的测试库。
本文标题:《Claude Code Worktree实战:一个仓库并行跑多个AI任务》
本文链接:https://zhangwenbao.com/claude-code-worktree.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0