JS压缩工具怎么用?压缩、混淆与那几个被夸大的开关

本文目录
- 这个JS压缩工具,到底能干哪三件事?
- 它的压缩是真解析代码,还是纯正则瞎删?
- 删注释会不会误删字符串里的双斜杠?
- 这工具具体怎么用?
- 为什么说"优化分号"那个开关其实没用?
- 它会帮我把变量名改短吗?
- 没写分号的代码,用它压缩会出事吗?
- 删console这个功能,可靠吗?
- 它的"混淆"到底混淆了什么,能防别人扒代码吗?
- 那个"自我保护"开关,真能防止代码被篡改吗?
- 压缩率为什么有时候是负的?
- 压缩JS对前端性能和SEO到底有多重要?
- 一个母婴推车独立站,怎么用它给落地页脚本减重?
- 用它压缩JS前,哪些坑要提前知道?
- 它和Terser、UglifyJS这类专业压缩器差在哪?
- 删空白之后代码为什么还能跑?它怎么知道哪里必须留空格?
- 用它美化压缩过的代码,能完全还原成原来的样子吗?
- 第三方库的压缩版,适合拿它再压一遍吗?
- 它和webpack、Vite这些打包工具的压缩,是一回事吗?
- 常见问题解答
- 权威参考资料
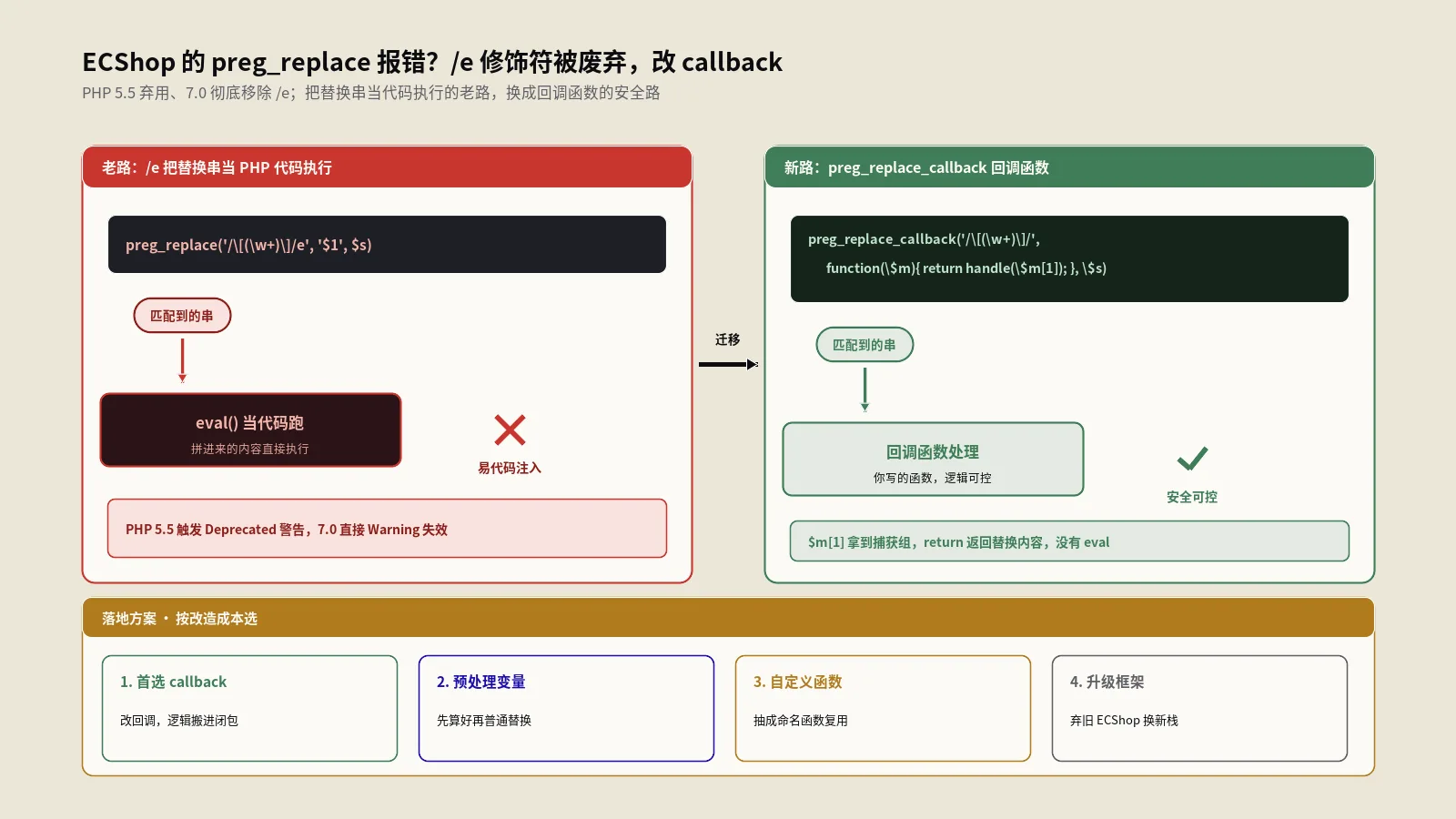
摘要:这个JS压缩工具能干三件事:压缩(把注释、空白删掉让脚本变小)、混淆(把字符串和数字藏起来增加阅读难度)、美化(把压扁的代码展开成好读的样子)。跟很多纯正则瞎删的在线工具不同,它的压缩是在后端PHP里做了真正的词法分析——能正确认出字符串、正则字面量、模板字符串,连ES6的箭头函数、解构都不会压坏,注释里还懂得保留/*!开头的版权声明。但有几件事必须说破:一是它根本不改变量名(不做mangle),而缩短变量名恰恰是专业压缩器最大的减肥手段,所以它压出来的体积不如Terser那类工具狠;二是界面上那个"优化分号"开关是个摆设,后端收到了却从不处理;三是它的"自我保护"被宣传成"代码被改就停止运行",实际只是包了层外壳做了点console兼容,根本不防篡改;四是对那种省略了分号、依赖自动分号补全的代码,压缩有翻车风险,压完务必验证能不能跑。把它当"会认语法的诚实压缩器",它靠谱;指望它的混淆能防住别人扒代码、或者那个开关真能保护脚本,会落空。
做前端,脚本体积是绕不过的一道坎。落地页塞了几个第三方库,打开慢得肉眼可见;自己写的那堆逻辑没经过处理就直接上线,注释、空格、好长的变量名全都原样发给用户下载,白白浪费带宽。把JavaScript压一压、让它瘦下来,是优化加载速度最基础的一步。
这个JS压缩工具就是干这个的。它能把脚本里那些给人看的空白和注释删掉、压成紧凑形态,也能反过来把压扁的代码展开、还能做点混淆。但JS压缩比CSS压缩凶险得多——JavaScript的语法里藏着字符串、正则、自动分号补全这些"碰不得"的地雷,压缩工具要是不懂语法瞎删,压出来的代码直接跑不了。这篇我们团队就把它怎么用、它的压缩到底靠不靠谱(是真懂语法还是瞎删)、几个被夸大的功能("优化分号"是摆设、"自我保护"防不了篡改、混淆挡不住扒代码),以及压缩JS对性能和SEO的真实意义,一次讲透。
这个JS压缩工具,到底能干哪三件事?
先把它的功能盘清楚。它核心就三个动作:压缩、混淆、美化。压缩是把脚本里多余的注释、空白删光,让文件变小,这是最常用的;混淆是在压缩的基础上再把字符串、数字藏起来,增加别人阅读的难度;美化正相反,是把压扁的代码重新展开成带缩进、好读的格式,方便你调试别人的压缩代码。
有一点和它的"同行"很不一样,值得先夸:它的核心处理是放在后端PHP里做的,前端只是把你的代码通过请求发过去、再把结果拿回来显示。这意味着它不是那种在浏览器里用几行正则瞎替换的玩具,后端那套逻辑是真刀真枪写了词法分析的。当然这也有个隐含前提——你的代码会被发到服务器处理,不像纯前端工具那样完全不出本机,对特别敏感的代码要心里有数。
把这三个动作和场景对上:日常上线减体积用压缩;想给自己的脚本加一层"不那么容易被一眼看懂"的保护用混淆(但别指望它真能防住);接手一份压扁的代码想读懂、调试用美化。认准这三件事,剩下的就是搞清楚每件事它做到了几分、哪里有水分。
这里要先建立一个贯穿全文的判断:评价一个压缩工具,不能只看它"压得有多小",更要看它"压完还能不能正确运行"。一个把体积压到极致却时不时把代码压坏的工具,远不如一个压得没那么狠但稳如老狗的工具好用。这工具的取舍正是偏向后者——它不追求极致压缩率(毕竟不改变量名),但在"压完别出错"这件事上下了真功夫。理解了这个取舍,你就能更公平地看待它的长短:它的"短"(压不到最小)和它的"长"(懂语法、相对安全)其实是同一个设计选择的两面。
它的压缩是真解析代码,还是纯正则瞎删?
这是判断一个JS压缩工具能不能放心用的核心问题。市面上很多在线压缩工具是纯正则的——用几条正则直接删注释、删空格,遇到稍微复杂点的代码就压坏。这个工具在这一点上做得明显更扎实:它的后端先对代码做了词法分析。
词法分析的意思是,它会先把整段代码扫一遍,拆解成一个个有类型的"词块"(token):哪段是字符串、哪段是正则字面量、哪段是模板字符串、哪段是注释、哪段是标识符或数字,都标得清清楚楚。在这个基础上再做删减,它就知道哪些空白是代码结构里可删的、哪些是字符串内部碰不得的内容。它甚至正确处理了好几个容易翻车的难点:字符串里的转义、正则字面量的识别(靠上下文判断那个斜杠是除号还是正则的开始)、模板字符串里${}的嵌套、以及十六进制二进制这些数字写法。
这带来的好处是实打实的:它压缩现代JavaScript(带箭头函数、模板字符串、解构赋值这些ES6以后的语法)不会把代码压坏,字符串里的内容、正则的写法都原样保留。比起那些纯正则、一遇到正则字面量就把斜杠当除号、一遇到字符串里的双斜杠就当注释删的玩具工具,它的可靠性高了一个档次。这是它最值得肯定的地方——压缩工具的第一要务是"压完还能跑",它在这一点上认真做了功课。
删注释会不会误删字符串里的双斜杠?
这是纯正则压缩工具最经典的翻车点,也最能体现这工具"懂语法"的价值。先说结论:它不会误删,因为它在词法分析阶段就把字符串和注释分得清清楚楚。
问题的背景是这样:JavaScript里//是单行注释的开头,但字符串里也可能出现//,比如var url = "http://example.com"这行里的双斜杠是网址的一部分,绝不能当注释删。正则字面量里也可能有看着像注释的内容。纯正则工具分不清这些,很容易把字符串里的双斜杠后面那截当注释一起删了,代码就坏了。
这工具因为先做了词法分析,字符串、正则字面量在删注释之前就被识别成了独立的词块,删注释时只删真正标记为注释类型的那些,字符串内部的//、正则里的内容都安然无恙。它还有个贴心的细节:删注释时会保留以/*!开头的块注释。这种写法是业界约定的"重要注释"标记,常用来放开源协议声明、版权信息,压缩时该留着——它懂这个规矩,不会把版权声明也一并删了。这些细节都说明它的压缩不是糊弄的。
这工具具体怎么用?
它的操作很直观,摸清三个动作和那几个勾选项就行。常走的流程是下面几步。
- 把要处理的JS代码粘进输入框。不管是自己写的还是第三方库的脚本,整段贴进去。它支持现代JavaScript语法,箭头函数、模板字符串这些都认。
- 上线减体积就选压缩,按需勾选项。压缩下面有几个开关:删注释、删空白是核心,建议都开;"删除console"能把调试用的
console.log清掉,上线前很有用。勾好点压缩。 - 想加点阅读门槛就用混淆。混淆会在压缩基础上把字符串提取编码、数字转成十六进制。但要清楚它只增加阅读难度,不是真正的加密,挡不住有心人。
- 要读懂一份压扁的代码就用美化。把压缩过的脚本粘进去美化,它会展开成带缩进的可读格式,方便你调试或研究。
- 处理完务必先验证再用。这是JS压缩和CSS压缩最大的区别——一定要把压缩或混淆后的代码拿去实际跑一下,确认功能正常,尤其是原代码省略了分号的情况。确认没问题再复制或下载使用。
整个流程的关键词是"验证"。JavaScript的语法陷阱多,任何在线压缩工具压出来的结果都该跑一遍确认,这工具虽然懂语法、可靠性不错,但下面要讲的几个边界(尤其是省略分号的情况)仍然值得你多留个心眼。
为什么说"优化分号"那个开关其实没用?
界面上压缩选项里有个"优化分号"的勾选框,听着像是能帮你智能处理分号的样子。但拆开源码看,这是个彻头彻尾的摆设——后端收到了这个选项,却从头到尾没用它做任何事。
具体说,前端确实把"优化分号"这个开关的状态发给了后端,后端也把它接住存进了配置里,但接下来的所有处理逻辑里,再没有一处代码读取或使用这个配置。换句话说,你勾不勾它,压缩出来的结果一模一样,它就是个没接线的按钮。
这对你的实际影响其实不大——因为它本来也不该指望靠这个开关解决分号问题(分号问题是个真陷阱,下面专门讲)。但知道这个开关是空的,至少能让你别对它有错误的期待:别以为勾了"优化分号",那些省略分号的代码就被妥善处理了,那是会误事的。它没做这件事,分号的安全得靠你自己写代码时规规矩矩加分号来保证。这种"UI有、实现没有"的功能在小工具里不少见,用之前心里有数就好。
它会帮我把变量名改短吗?
这是衡量一个压缩工具"减肥能力"的关键,答案是:不会。这工具不做变量名混淆(业界叫mangle),你代码里那些userAccountInformation之类的长变量名,压完还是原样那么长。
为什么这件事重要?因为缩短变量名是专业压缩器最有效的减肥手段。MDN的Minification术语词条里就把"缩短变量和函数名"和删注释、删空白、删未用代码一起,列为压缩的几大组成部分。专业压缩器(像Terser)会把局部作用域里的长变量名统统换成a、b、c这种一两个字母的短名,一份变量名起得很认真的代码,光靠改短变量名就能再省下相当可观的体积。
这工具只删空白和注释、不碰变量名,所以它的压缩率天然就比带mangle的专业工具低一截。这不算它撒谎——它没宣传自己会改变量名,混淆里做的也只是藏字符串和数字,不是改名。但你得有这个预期:拿它压一份代码,省下的主要是空白和注释那部分,变量名占的体积它动不了。要把脚本压到最小,最终还是得上构建链里的专业压缩器。它适合的是"快速压一下应个急",不是"把体积榨到极致"。
没写分号的代码,用它压缩会出事吗?
这是用这工具(其实是用任何JS压缩工具)最该警惕的一个坑。如果你的代码风格是省略分号、靠JavaScript自动补全的,那压缩——尤其是删空白这一步——是有翻车风险的,压完可能跑不了。
根子在JavaScript的"自动分号补全"机制。MDN的JavaScript词法语法文档里讲得很清楚:JavaScript会在消费词块流时自动插入分号,把一些本来非法的词块序列"修正"成合法语法,而这个自动补全的过程,恰恰依赖换行符(行终止符)来判断该在哪儿补分号。也就是说,很多没写分号但能正常跑的代码,是靠"换行"在替分号干活。
而压缩做的第一件事就是删空白、删换行。一旦那些充当"隐形分号"的换行被删掉,自动补全机制失去了判断依据,原本两条独立的语句可能就被粘成了一条非法语句,代码直接报错。举个直观的例子,两行没加分号的赋值,挤到一行又没了换行,就可能连成一句让引擎懵掉的东西。这工具的词法分析在大多数地方会按规则补上必要的空格,但自动分号补全这件事的复杂度,没有任何纯压缩能百分百兜住。
所以结论很硬:写代码老老实实加分号,是给压缩留的最大保险。如果你接手的是一份省略分号的代码,压完一定要实际跑一遍验证,别压完直接上线。这也是为什么前面把"验证"反复强调成流程里最重要的一步——JS压缩的风险,很大一部分就藏在这个分号问题里。
删console这个功能,可靠吗?
"删除console"是个挺实用的功能——上线前把那些调试用的console.log清掉,既干净又省一点体积。这工具确实做了这个功能,但它的实现方式有个边界,复杂调用可能删不干净。
它删console用的是正则匹配,而且是在词法分析之前就先用正则把console.xxx(...)这样的调用整段删掉。问题出在那个匹配括号内容的正则上——它只能正确处理一层嵌套的括号。如果你的console.log里参数很简单,比如console.log("调试信息"),它删得干净利落;但要是参数里又套了函数调用、嵌套了好几层括号,比如console.log(format(getData(id))),那个正则可能在括号配对上算错,导致删除不完整——删掉一截、留下一截,反而把代码弄坏了。
所以这个功能的安全用法是:用它删那些简单的console调用没问题,但如果你的调试语句里塞了复杂的嵌套表达式,删完要特别检查一下有没有留下残缺的代码片段。更稳妥的做法是上线前自己手动清理复杂的调试语句,简单的交给它批量删。它适合处理常见的简单情况,碰上刁钻的嵌套就别全指望它了。
它的"混淆"到底混淆了什么,能防别人扒代码吗?
混淆听起来很有安全感,好像代码混淆完别人就看不懂、扒不走了。得先把期待降下来:这工具的混淆只增加阅读难度,挡不住真想扒你代码的人。
它的混淆具体做了两件事:一是把代码里的字符串字面量提取出来、编码成数组形式,让你没法直接在代码里读到那些字符串;二是把数字转成十六进制写法,让数字看着没那么直观。这两招确实能让代码乍一看面目全非、读起来费劲。
但它有个关键的没做:不改变量名、不打乱代码结构。专业的混淆器会把变量名、函数名全换成乱码,再把代码的控制流搅成一团乱麻,让人极难还原逻辑。这工具的变量名、函数名、整体结构都原样保留,一个有经验的人,把它美化展开、再把那些十六进制数字和字符串数组对照着还原一下,逻辑还是读得出来的。
说到底,前端JavaScript是发到用户浏览器里执行的,源码天然就在用户手里,任何前端混淆都只是"提高门槛",不存在真正的"加密"。真正的核心逻辑、密钥这类东西,根本就不该放在前端。把它的混淆当成"劝退随便看看的人"的一道矮墙可以,当成"保护商业机密的保险柜"则是想多了。
那个"自我保护"开关,真能防止代码被篡改吗?
混淆选项里有个"自我保护"的开关,界面上把它描述成"代码被修改后会自动停止运行",听着像是个防篡改的厉害功能。但扒开看它的实现,这是本文里水分最大的一处宣传——它根本不防篡改。
它所谓的"自我保护",实际只做了两件很轻的事:把你的代码包进一层立即执行的函数外壳里,然后检查一下浏览器环境里console对象在不在、不在就补一个空的上去。就这么点东西。这跟"检测代码是否被修改、被改了就停止运行"完全不沾边——它既没有计算代码的校验值,也没有任何在运行时比对"代码有没有被动过"的逻辑。
所以这个开关的真实作用,顶多是做了一点点console的兼容处理、避免某些环境下报错,跟"自我保护""防篡改"这种说法严重不符。你要是冲着"开了它代码就被保护了"去勾,那是被界面文案误导了。这也提醒一个更普遍的道理:前端代码的"保护"基本是个伪命题,任何号称能防篡改、防调试的前端方案都经不起推敲,因为代码的执行环境完全在对方手里。需要真正保护的逻辑,做到后端去才是正路。这个开关,知道它名不副实就行,别依赖它。
压缩率为什么有时候是负的?
用这工具时你可能撞见一个反直觉的现象:明明是来"压缩"的,处理完文件反而变大了,压缩率显示成负数。这通常不是出bug,是你用了混淆。
道理在于混淆的副作用。前面说过,混淆会把字符串提取成一个数组放在代码开头,这个数组本身、以及把字符串编码、把数字转十六进制带来的额外字符,都会增加体积。对于字符串比较多的代码,混淆增加的这部分,可能比删空白删注释省下的还多,一来一去,文件就变大了。所以"混淆完体积增加"是正常现象,不是工具坏了。
这背后还藏着一个更重要的认识:真正决定用户下载体积的,不只是这一层文本压缩。现代网站传输几乎都会再叠一层gzip或Brotli压缩,而混淆产生的那些重复的字符串数组结构,gzip压起来反而效率不低。所以光看工具显示的字符数变化,并不能代表用户最终下载的真实体积——那得看gzip叠加之后的结果。如果你的目标是减小传输体积,纯压缩(不混淆)配合服务器开gzip才是正路;混淆是为了"难读"不是为了"变小",两个目标别混为一谈。
压缩JS对前端性能和SEO到底有多重要?
把功能和坑都讲透了,回头看压缩JavaScript这件事本身的价值。它对页面速度的影响,比压缩CSS还要直接,而速度又牵动着SEO。
JavaScript对性能的拖累是双重的:它不光要下载,下载完还要解析、编译、执行,这些都占用主线程、阻塞页面变得可交互。web.dev的优化文本资源编码与传输体积的文档里指出,压缩配合gzip这类压缩,能让JavaScript、CSS、HTML这类文本资源的体积总共减小高达90%,体积小了,下载就快、要解析的字节也少。脚本越瘦,页面就越早能响应用户的操作。对那些塞满了第三方脚本的落地页,把JS压一压是立竿见影的优化。
这跟SEO的关联就清楚了:页面加载速度和可交互的快慢,是搜索引擎核心网页指标里实打实的考量项,直接关系到排名时的体验信号。臃肿的、没压过的脚本会拖慢页面、推迟可交互的时刻,体验信号变差就是排名的减分项。反过来,把脚本压瘦、配合gzip传输,是改善加载体验的基本功之一。它和CSS压缩是一对——想顺带把样式表也减重,可以看我们团队的CSS格式化工具教程。把这两类文本资源都压好,前端性能的地基才算打牢。
一个母婴推车独立站,怎么用它给落地页脚本减重?
讲再多原理,不如顺一个真实场景。一个做母婴推车的出海独立站,主推一款新品的落地页加载特别慢,一查发现页面塞了好几段自己写的交互脚本——轮播、规格切换、加购动画,全是没经过任何处理就直接上线的源码,注释、空格、调试日志一应俱全。运营想在不重做整个落地页的前提下,先把这些脚本压一压、提提速。
第一步,逐段压缩。运营把每段脚本分别粘进工具,勾上删注释、删空白,再勾上"删除console"——这些脚本里散落着开发时留的一堆console.log,正好借这个功能清掉。压完它把每段脚本都明显缩小了,注释和调试日志一扫而空。
第二步,重点验证。因为这几段脚本是不同人写的,风格不一,运营特别留意了分号问题——其中有一段是省略分号风格的,压完她没敢直接信,把压缩版放进测试页面把轮播、切换、加购整个流程点了一遍,确认功能都正常才放心。果然,规规矩矩加分号的那几段压完即用,省略分号的那段虽然这次没出事,但她还是按"压完必测"的规矩走了一遍。
第三步,分清楚混淆和压缩。运营本来想顺手把脚本也混淆一下"保护"起来,了解清楚后打消了念头——这些落地页交互脚本没什么机密可言,混淆只会增加体积、拖慢加载,得不偿失;那个"自我保护"开关更是没必要开。最后她只做了纯压缩,把瘦下来的脚本配合服务器的gzip一起上线,落地页的加载和可交互速度肉眼可见地快了一截。整个过程,这工具承担的是"快速、安全地把脚本压小"这个体力活,而"压完要测""别瞎混淆"这些判断,靠的是对它脾性的了解。
用它压缩JS前,哪些坑要提前知道?
用这工具多了,会发现栽跟头的地方就那么几类,提前知道能避开大半。
头一类、也是最危险的,是省略分号的代码压完不验证就上线,撞上自动分号补全的陷阱导致脚本报错。记死"压完必测"这一条,尤其是非自己写的、风格不明的代码。第二类是对那几个有水分的功能抱了错误期待:以为勾了"优化分号"就处理好了分号(它是摆设)、以为开了"自我保护"代码就安全了(它不防篡改)、以为混淆完别人就扒不走(只是矮墙)。把这几处的真相记牢,就不会被界面文案带偏。
第三类是拿它当"极致减肥工具",结果发现压出来的体积不如预期——因为它不改变量名,减肥能力天然有限,要榨到最小得上专业压缩器。第四类是删console时遇到复杂嵌套调用删不干净却没检查,留下残缺代码。把这四类坑记牢,它在自己擅长的范围内(安全地压缩规范代码)就是个相当好用的帮手。说到底,脚本压缩只是前端交付的一环,样式压缩、缓存策略这些底层同样得跟上,它们都是出海站速度的基本功。和它配套的还有资源内联与编码这类活,想了解可以看我们团队的Base64工具教程。
它和Terser、UglifyJS这类专业压缩器差在哪?
用过之后总会问:它跟构建链里的Terser、UglifyJS到底差在哪,能不能替代?答案是替代不了,但它们的定位本就不同。
最大的差距在"减肥的狠劲"。Terser这类专业压缩器除了删空白注释,还会做这工具不做的几件大事:把局部变量名全换成一两个字母的短名(mangle)、删掉永远执行不到的死代码、做常量折叠和各种安全的等价改写、把函数和表达式做更激进的精简。这些加起来,专业工具能把体积压得比这工具狠得多,而且因为是建立在更完整的语法理解之上,安全性也更有保障,连分号那种陷阱都处理得更稳。
另一个差距在"自动化"。Terser这些是跑在构建流程里的,每次打包自动处理所有脚本、和打包工具严丝合缝,是工程化的标准一环。而这工具是手动的、一次处理一段,靠人复制粘贴。所以它们的定位完全不同:专业压缩器是生产线上的标配,是真正项目里JS优化该用的东西;这工具填的是"手头临时有段脚本想快速压一下、或者想美化看懂一份压缩代码"的零碎需求。它的价值不在于压得多狠,而在于即开即用、还懂语法不会瞎压坏。认清这个分工,就既不会拿它去干本该自动化干的活,也不会因为它简单就否定它的便利。
删空白之后代码为什么还能跑?它怎么知道哪里必须留空格?
有人会好奇:压缩把空白都删了,可有些地方空格明明不能删——比如return x里return和x之间那个空格,删了就变成returnx,引擎根本不认。这工具是怎么知道哪些空格该留、哪些该删的?这正是它"懂语法"的又一处体现。
秘密还在词法分析。它把代码拆成一个个词块之后,重新拼接成压缩形态时,并不是无脑把所有空格都删光,而是逐对相邻的词块判断:"这两个挨在一起会不会出问题?"它内部维护着一张JavaScript关键字表(return、typeof、in、instanceof这些),当发现前一个词块是关键字、后面紧跟着标识符时,就知道这里的空格是结构需要的、必须留;而像) {之间、; }之间这种纯属好看的空白,才放心删掉。
这套"按相邻词块类型决定留不留空格"的逻辑,是它压缩比纯正则可靠的根本原因。纯正则工具没有词块的概念,要么一刀切把所有空格都删(删坏return x),要么保守得不敢删(压不动)。这工具因为知道每个词块是什么类型,能精准地只删冗余空白、保住有意义的空格。理解了这一层,你就明白为什么它压规范代码这么稳——它不是在"删字符",是在"理解代码结构之后再删"。不过这套机制再聪明,也兜不住前面说的自动分号补全那种依赖换行的隐式语法,那是另一个维度的问题。
用它美化压缩过的代码,能完全还原成原来的样子吗?
美化是这工具挺实用的一个功能——逆着压缩来,把挤成一坨的脚本展开成带缩进的可读格式。但"展开成好读的"和"还原成原作者写的样子"是两码事,得分清楚。
能还原的是"格式骨架"。把一段压缩代码粘进去美化,它能重新加上缩进、换行,让代码层级清楚、读得下去,调试或研究别人的实现时很顺手。这一步它做得不错,足够你看懂这段脚本的逻辑结构。
还原不了的是"已经丢掉的信息"。压缩时删掉的注释,美化变不回来——注释是给人看的说明,压缩时被删了就是删了,美化只能给你展开代码,凭空造不出本来就没了的注释。更要命的是,如果这段代码当初是用专业工具压的、变量名被改成了a、b、c,那美化只能让这些短名排得好看,却没法还原它们本来的含义——你看到的还是一堆没有意义的单字母变量。
所以美化的定位是"让压缩代码变得可读",不是"还原源码"。研究一段线上压缩脚本时,靠它展开能读懂逻辑走向,但别指望读到原汁原味的、带注释带好变量名的源代码,那些信息在压缩那一刻就永久流失了。也正因如此,自己的代码一定要保留好未压缩的源文件版本,别指望哪天靠美化从线上压缩版倒推回来——倒不回来。源码管理才是你的安全网,压缩版只是给用户下载的产物。
第三方库的压缩版,适合拿它再压一遍吗?
有人会想:我引的那些第三方库(某个轮播插件、某个工具库)也挺大的,能不能拿这工具再压一遍省点体积?答案是:基本没必要,有时还可能帮倒忙。
道理在于,正经的第三方库,作者发布时给的那个生产版本(通常文件名带.min.js)早就用专业压缩器压过了——空白删光、变量名改短、死代码清掉,能压的都压到位了。你再拿这个只删空白不改变量名的工具去压一个已经压过的文件,几乎榨不出多少新空间,因为该删的空白人家早删了,而变量名你又改不动。费半天劲,体积没小多少。
更要留神的是,对已经混淆压缩过的代码再做一次混淆或处理,反而可能引入风险——多一道处理就多一分压坏的可能,而收益几乎为零。所以正确的做法是:第三方库直接用作者给的.min.js生产版本就好,那已经是压到位的;这工具的用武之地是压你自己写的、还没经过处理的源码。分清"已压过的别再折腾"和"没压过的拿来压",才不会做无用功还冒风险。
它和webpack、Vite这些打包工具的压缩,是一回事吗?
做现代前端项目的人会问:我用webpack或Vite打包,构建出来的代码本来就是压缩过的,那这个在线工具还有用武之地吗?两者确实不是一回事,定位差得远。
打包工具的压缩是工程化的、自动的。webpack、Vite这些在生产构建时,内部默认就集成了Terser这类专业压缩器,每次打包自动把所有模块压缩、改短变量名、做摇树(删掉没用到的导出)、代码分割等等,是一整套深度优化,而且全自动、不用你手动干预。这是真正项目里JS优化的主战场,压缩深度和这个在线工具完全不在一个量级。
那这个在线工具适合什么?是那些"没上构建流程"的零碎场景:你给一个老网站的页面里手写了一小段脚本想压一下,这页面根本没有webpack;你从哪儿拷了段代码想快速压扁应个急;或者你想美化一段线上压缩脚本看懂它。这些"杀鸡不用上构建链这把牛刀"的场合,正是它的舞台。
所以别拿它跟打包工具比压缩深度,那不公平——它比的是"即开即用、不用配环境"的便利。上了构建流程的项目,JS压缩交给打包工具自动完成;还没上构建、只是临时处理一两段脚本的零碎需求,这工具补位最合适。代码层面的活,除了压缩还有格式化美化,多语言的格式化可以看我们团队的代码格式化工具教程。
常见问题解答
它压缩会不会把我的代码压坏?规范的代码(老老实实加了分号的)基本不会,因为它做了真正的词法分析,能认出字符串、正则、模板字符串,不会瞎删。但省略分号、依赖自动分号补全的代码有翻车风险,删空白可能让原本靠换行分隔的语句粘到一起报错。所以任何代码压完都建议实际跑一遍验证,尤其是风格不明的代码。
它会帮我把变量名改短吗?不会。它不做变量名混淆(mangle),只删空白和注释,长变量名压完还是原样。而缩短变量名是专业压缩器最有效的减肥手段,所以它的压缩率比Terser那类工具低一截。要把体积榨到最小,得上构建链里的专业压缩器。
"优化分号"和"自我保护"这两个开关有用吗?基本没用。"优化分号"是个摆设,后端收到这个选项却从不使用,勾不勾结果一样。"自我保护"被宣传成"被改就停止运行",实际只是包了层外壳、做了点console兼容,根本不防篡改。别对这两个开关有期待。
混淆能防止别人扒走我的代码吗?不能,只能增加阅读难度。它的混淆只藏字符串和数字、不改变量名也不打乱结构,有经验的人美化还原后逻辑照样读得出。前端JS发到用户浏览器就在对方手里,任何前端混淆都只是矮墙,真正要保护的逻辑得放后端。
为什么混淆完文件反而变大了?正常现象。混淆要把字符串提取成数组、做编码转换,这些额外结构会增加体积,字符串多的代码混淆完可能比压缩省下的还大。而且真实传输体积要看叠加gzip后的结果。想减小体积就用纯压缩配合服务器gzip,混淆是为了难读不是为了变小。
本文标题:《JS压缩工具怎么用?压缩、混淆与那几个被夸大的开关》
本文链接:https://zhangwenbao.com/js-minifier-compress-obfuscate-bundle-size-performance-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0