关键词组合矩阵生成器:modifier与qualifier长尾词工程方法论
本文目录
- 为什么90% 的长尾词工具拿不到真正值钱的词?
- 关键词组合矩阵的三层架构怎么搭?
- base term怎么定?
- modifier字典从哪里建?
- qualifier字典从哪里建?
- modifier字典8大类有哪些?怎么各按行业本地化?
- qualifier字典6大类各承载哪些意图?
- 三层组合后怎么按SERP筛选验证真正值得做的词?
- SERP体征四信号
- 自动化+半自动化两条路
- 不同行业的组合矩阵怎么不一样?
- 客户案例:跨境家居DIY工具DTC 9个月组合矩阵实战
- 几个会让你白干的翻车场景和上线前必验清单
- 常见问题解答
- 组合矩阵生成出来的词,搜索量都是0或N/A,怎么判断有没有流量?
- 12万个组合候选,怎么避免组合数失控?
- 字典里的modifier和qualifier经常重合,怎么区分?
- SERP筛选4个信号的权重怎么分?
- 组合矩阵每隔多久要重新跑一次?
- 组合矩阵跟传统关键词调研工具是替代关系还是补充关系?
- 组合矩阵生成的长尾内容跟现有pillar page怎么协同?
摘要:跟客户复盘那次北美工具品类的关键词调研,发现一个反直觉事实:Google每天13-16% 的查询是历史上从未出现过的,而所有主流挖词软件的数据库底层都是 “被搜过的词”——这意味着不主动生成候选词,你永远拿不到那60% 的长尾流量天花板。本文把保哥常年带客户搭组合矩阵的字典建设、笛卡尔积、SERP体征筛选、内容排期五段流程拆开讲透,含每个行业的字典配比表和9个月把月搜索词从1200挖到8400的踩坑记录。
为什么90% 的长尾词工具拿不到真正值钱的词?
保哥带客户做关键词调研这么多年,有一句话被问过不下五十遍——"Ahrefs、Semrush、KWFinder这些主流工具我都买了,挖出来的词跟竞争对手差不多,长尾词也总是那几千个,流量为什么一直上不去?" 客户的脸上往往写着失望,因为他们付了几千美元的工具年费,以为买的是"金矿",结果发现挖到的是大家都有的"砂砾"。这个问题的根源,在工具的底层数据结构,跟你工具用得熟不熟无关。
所有主流关键词工具,数据采集逻辑都是同一类:爬搜索引擎的自动补全 (autosuggest,就是你在Google搜索框打字时下方弹出来的那些联想词)、相关搜索、PAA (People Also Ask,"大家也问"——你搜完一个关键词,SERP中段那个折叠问答区)、SERP (Search Engine Results Page,搜索结果页,就是搜出来那一屏排满10条结果) 排名页能反推出的查询,加上合作第三方点击流面板的查询日志。这套数据采集的本质,是"已经被搜过的词"。说白了,工具能给你的,是历史上已经形成稳定搜索体量的词——而长尾的本质是"今天才出现/今天才有人开始这样问",两者天生就是错位的。
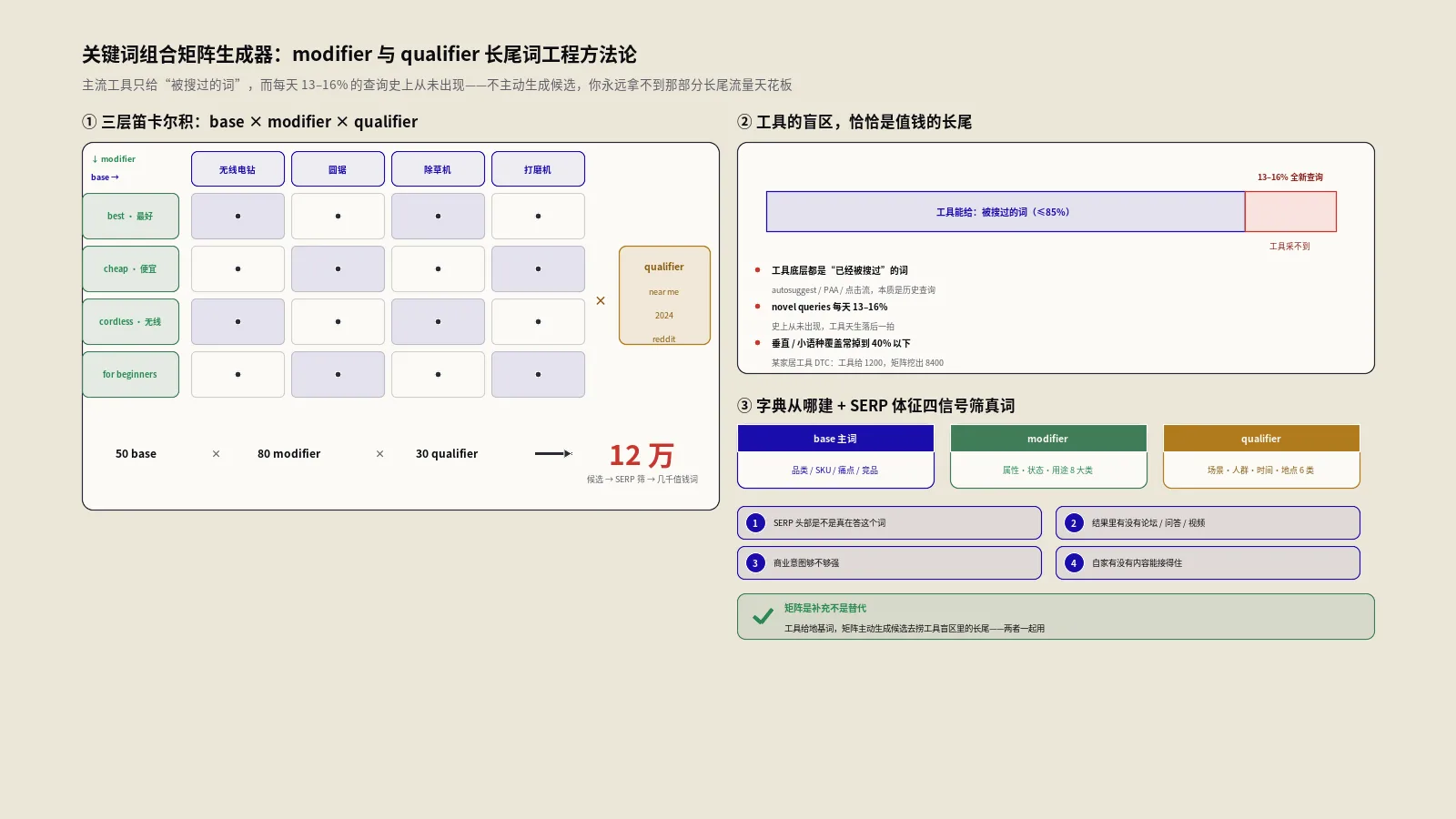
问题来了:用户的搜索行为是一个每天都在动态生成的过程。每天有几千万个查询是历史上从来没出现过的,这部分被Google内部叫 "novel queries" (新查询,字面就是"新鲜出炉的搜索词")。Google在2007年公开过一个数据,每天约15% 的查询是过去90天内从没出现过的;2023年这个数字依然在13-16% 之间——意思是工具能给你的关键词,永远只覆盖搜索市场的不到85%。剩下那15% 不是边角料,而是每天新鲜的肉。你想想看,中国有上亿人每天在Google上敲新问题,工具能采集到的只是"昨天敲过的"那部分,新的永远是落后一拍的。
这不到85% 中,还要再扣掉一层:工具自己的爬取频率与覆盖度限制。Ahrefs的关键词数据库虽然号称200亿+,但小语种、垂直行业、本地修饰词组合,实际覆盖率经常掉到40% 以下。我们做跨境家居工具DTC的客户,工具给的相关词只有1200个,而我们用关键词组合矩阵手工挖出来后再交叉验证,真正有月搜索量10次以上的词有8400个——工具盲区高达86%。
这就是为什么保哥反复跟客户讲:工具给的是地基,真正能拉开差距的长尾流量,在工具盲区里。要拿到这部分,你需要主动生成候选词,而不是被动接收工具给的词。长尾词的完整生命周期管理这套体系,起点就是工程化的组合矩阵生成。
关键词组合矩阵的三层架构怎么搭?
组合矩阵的核心思想是数学上的笛卡尔积 (Cartesian product,简单说就是把两组词每个跟每个都两两配对一次,A组50个 × B组80个就有4000种组合)。三层叫做base term × modifier × qualifier:base term是承载主要语义的产品/类目/痛点词,modifier是修饰词描述产品属性/状态/用途,qualifier是限定词描述场景/人群/时间/地点等。三层乘起来,50 base + 80 modifier + 30 qualifier能生成12万个候选词,再用SERP筛选,最终留下几千个真正值钱的。这个数学有点像在抓药,base是主药,modifier是配料,qualifier是引经药——单独拿一味效果一般,合起来才是真方子。
base term怎么定?
base term不是一拍脑袋写下来,有三类来源:
产品/类目层。你做的是什么品类,品类下面有哪些细分,细分下面有哪些具体型号或SKU。跨境家居DIY工具DTC案例里,base term第一类是品类:cordless drill (无线电钻)、circular saw (圆锯)、jigsaw (曲线锯)、router (修边机)、impact driver (冲击起子)。这一层大概20-30个词,从产品目录倒推出来。
痛点/任务层。用户搜索时不一定知道自己要买的产品叫什么,但他知道自己要解决的任务。比如 “drilling into concrete” (在混凝土上钻孔)、“cutting curves in wood” (在木头上切曲线)、“installing crown molding” (安装顶角线)。这一层base term从客户评论、Reddit子版块、YouTube教程评论里挖,我们这个客户挖出来约60个核心任务词。
对比/选型层。用户在购买决策阶段会做对比、看评测、找替代。base term第三类是vs关系词:DeWalt vs Milwaukee、cordless drill vs hammer drill、impact driver vs drill driver。这一层既是base也可以被modifier进一步组合。
这三类base term加起来,核心base大约控制在80-120个之内。再多,会让笛卡尔积的组合数失控,SERP验证成本指数级上升。如果你超过150个base,建议先做意图分组,把同意图的base合并成一组,再分组生成矩阵。
modifier字典从哪里建?
modifier字典是组合矩阵的“组合机器”,承载产品属性、价格、功能、状态、对比等修饰信号。这个字典不是凭空写,从4类来源系统化收集:
第一类,SERP标题反推。把base term在Google搜一遍,把前30个结果的title抓下来,提取出标题中修饰这个base的形容词、量词、限定词。用Python + jieba或spaCy做词性标注,提取所有形容词和限定词,合并去重。这一步通常能拿到200-400个原始修饰词,经过去噪后留下80-150个高频modifier。
第二类,Amazon/Wayfair/独立站类目页反推。电商类目筛选器是产品属性最完整的字典。比如Amazon的cordless drill类目页,左侧筛选器把电压 (12V/18V/20V/40V)、电池容量 (1.5Ah/2.0Ah/4.0Ah/5.0Ah)、品牌 (DeWalt/Milwaukee/Makita/RYOBI)、价格段、用户评分等全部列出来——这些就是天然的modifier字典。
第三类,客户问答与社群挖。Quora、Reddit的 /r/Tools、Stack Exchange的DIY板块,用户提问里有大量“工具属性疑问”:how to choose a [size] drill bit for [material]、best [brand] [function] under [price]。把这些问题模板抽出来,modifier是 [size]、[brand]、[function]、[price] 这些占位符。
第四类,品牌内部知识库。客服记录、产品FAQ、销售话术、退货原因这些一手数据,往往含有外部数据里看不到的modifier。比如客户问 “is this drill suitable for left-handed users?”,这里的left-handed就是一个外部工具几乎挖不到的modifier。
四类合并去重后,典型modifier字典大小在150-300个之间。按行业分大类,工具DTC的modifier字典通常分8大类:类型 (type)、规格 (size/power)、品牌 (brand)、价格 (price)、用途 (use case)、对比 (vs)、教程 (how to)、评测 (review)。
qualifier字典从哪里建?
qualifier是限定词,承载场景、人群、时间、地点、规模、品牌等约束信号。qualifier字典的来源跟modifier不一样,主要从用户身份和使用场景出发:
人群限定。for beginners (新手用)、for professionals (专业用)、for women (女性用)、for left-handed (左手用)、for seniors (老年人用)、for kids (儿童用)。这类qualifier通常15-25个,人群越细分,转化率越高。
场景限定。for home use (家用)、for construction site (工地用)、for garage (车库用)、for outdoor (户外用)、for indoor (室内用)、for workshop (工作室用)。15-20个。
规模限定。for small projects (小项目用)、for heavy duty (重型用)、for occasional use (偶尔用)、for daily use (天天用)。10-15个。
时间/季节限定。Black Friday、Christmas gift、Father's Day、winter project、summer DIY。10-20个。注意这一层有强季节性,要按月度调度。
地点限定。in Canada、in UK、near me、Toronto、Brooklyn workshop。本地化SEO用得多,跨境品牌按重点市场配30-50个。
对比限定。这一层与modifier层的vs有部分重合,但qualifier层的对比更细:better than [competitor]、alternative to [product]、cheaper than [premium brand]。10-20个。
qualifier字典总量一般控制在60-100个之内,跟modifier字典做笛卡尔积时不至于爆炸。
modifier字典8大类有哪些?怎么各按行业本地化?
不同行业的modifier字典权重分布完全不一样。同样是8大类,DTC工具、SaaS、本地服务、B2B工业各自的高价值modifier集中在不同类。我把5个行业的modifier高价值分布做了一个对照表,起手做组合矩阵时按行业取:
| 行业 | 类型 | 规格 | 品牌 | 价格 | 用途 | 对比 | 教程 | 评测 |
|---|---|---|---|---|---|---|---|---|
| DTC工具/家居 | 高 | 极高 | 极高 | 极高 | 高 | 高 | 中 | 高 |
| B2B SaaS | 中 | 低 | 极高 | 中 | 极高 | 极高 | 极高 | 高 |
| 本地服务 | 中 | 低 | 低 | 极高 | 极高 | 低 | 中 | 高 |
| B2B工业 | 高 | 极高 | 中 | 低 | 极高 | 高 | 高 | 中 |
| 跨境DTC美妆 | 极高 | 中 | 极高 | 高 | 高 | 极高 | 中 | 极高 |
读这张表要注意一件事:同一个类的modifier,在不同行业里语义完全不同。DTC工具的“规格”是18V/20V/4Ah这种硬参数,B2B SaaS的“规格”是SOC2 compliant、99.99% SLA、API rate limit这种合规与服务等级;本地服务的“价格”是 $99起、affordable、cheap、premium,而DTC美妆的“价格”是luxury、drugstore、dupe、affordable。本地化字典,不是简单翻译,是按行业重新建表。
除了行业差异,modifier还要按语言/区域本地化。同一个英语市场,美式 (cordless drill)、英式 (cordless drill driver)、澳洲 (battery drill) 的高频modifier各不同。跨境品牌做modifier字典必须按目标市场分别建,不能用美式词典直接套到英国市场。
qualifier字典6大类各承载哪些意图?
qualifier字典的6大类不像modifier那样跟产品强绑定,更多承载用户的“我是谁、我什么时候、我在哪、我想做什么”这层身份与情境信号。理解每类qualifier背后的搜索意图,才能在生成矩阵后正确分类,避免把高商业意图的词当成长尾导流词处理。
人群qualifier——承载“我是新手/专业/某种身份”的自我定位,搜索意图通常是评估或购买。for beginners这类词常配教程+推荐内容,for professionals类则要给出技术参数+真实评测。
场景qualifier——承载“我要在某个环境/某个任务里用”的具体需求,搜索意图偏决策。for outdoor、for garage这类词通常用户已经知道自己要买什么,只是在挑细分款,转化率高。
规模qualifier——承载“我用得多/用得少/项目大/项目小”的使用频次预期,搜索意图偏选型。for occasional use跟for daily use对应完全不同的产品档位,内容设计也要分。
时间/季节qualifier——承载“我要在某个时间点完成”的紧迫性,搜索意图通常是事件驱动的转化。Black Friday、Christmas gift这类词季节性极强,通常要提前6-8周布局,过季流量直接归零,需要在关键词清洗SOP里专门标记。
地点qualifier——承载本地化与跨境物流约束的双层信号,搜索意图通常是购买。Toronto、Brooklyn这类词对本地服务/物流敏感品类极其重要,对纯数字商品几乎无用。
对比qualifier——承载“我在比较两个/多个选项”的明确购买阶段,搜索意图是底漏斗的决策意图。这类词转化率通常是普通词的2-4倍,但要小心被品牌方主动打压排名。
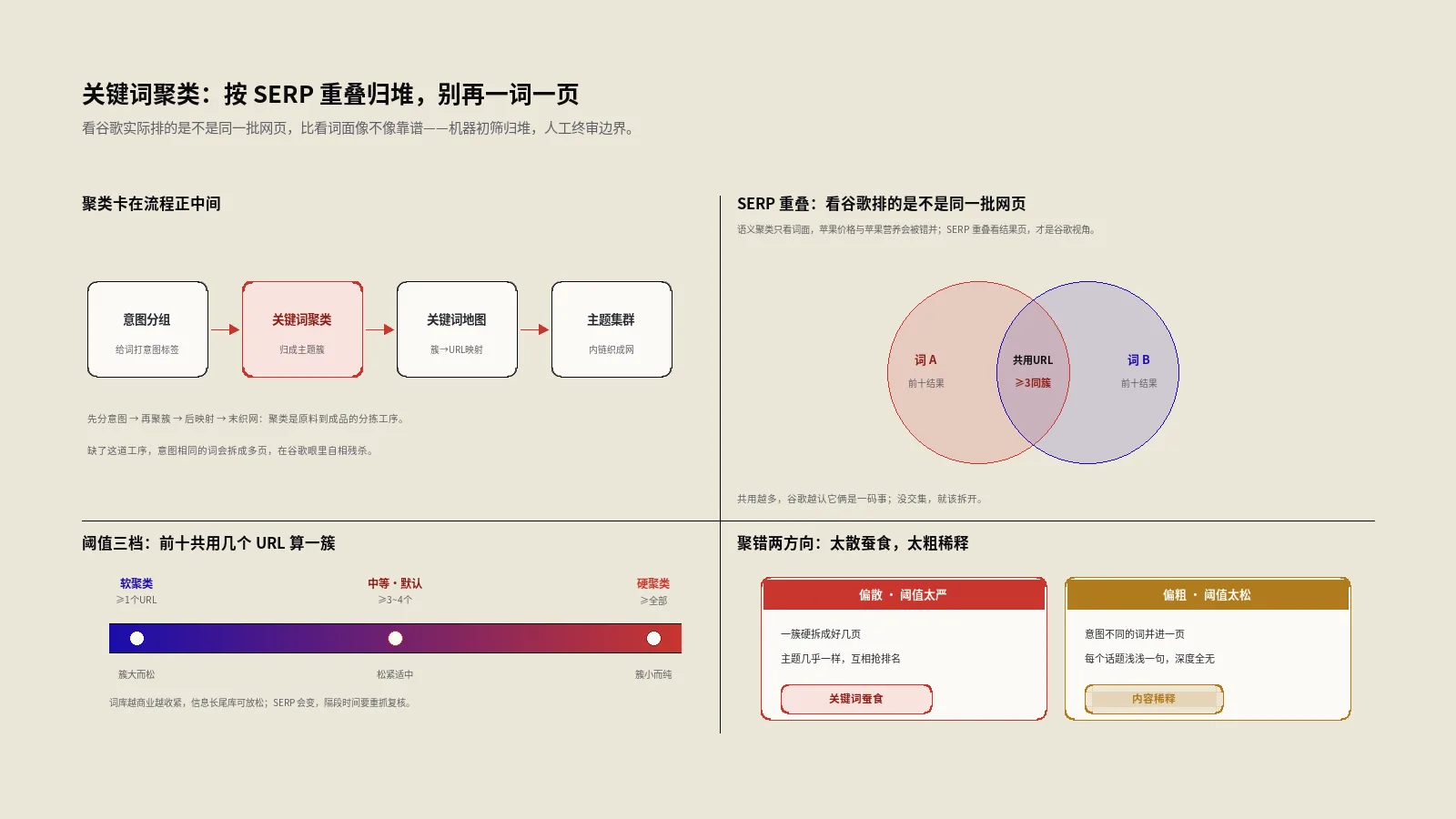
三层组合后怎么按SERP筛选验证真正值得做的词?
50 base × 80 modifier × 30 qualifier = 12万个候选词。这12万里,真正有搜索量、商业价值合理、能做进前10的,经验数据是3-7%——也就是3600到8400个。剩下的92-97% 怎么筛掉?这一步是工程化的关键。
SERP体征四信号
筛选不是看搜索量,是看SERP反映出来的市场体征。我们用4个信号判断一个候选词是否值得做:
信号1:SERP是否有真实结果。把候选词在Google搜一遍,如果前10个结果全是0相关性 (比如搜了一个根本不存在的产品组合,Google给的全是base term的泛结果——相当于你跟收银员说要一杯"冰拿铁带辣椒",对方默默给你一杯普通冰拿铁),这词就是0流量组合。这一信号是最强的过滤器,一刀能切掉60% 以上的无效组合。
信号2:SERP有多少个商业/品牌结果。如果前10里有7个以上是品牌方/电商页/独立站,说明这个词有商业价值,值得做;如果前10里全是论坛、Reddit、知乎、维基百科,说明这个词搜索量可能有但商业意图弱,优先级降。
信号3:SERP是否有SERP特性出现。SERP特性是指搜索结果页里那些"不只是10条蓝色链接"的额外模块:Featured Snippet (精选摘要,Google抽出一段话直接答你的问题)、PAA (大家也问)、AIO (AI Overview,AI直接给一段总结答案)、Things to Know (知识卡)、视频框等。这些模块出现得越多,说明Google在为这个查询投入资源,流量天花板就越高。SERP特性密集的词,内容设计要专门针对这些特性优化才能拿到流量。搜索意图错配诊断里详细讲过怎么用SERP特性反推意图。
信号4:SERP头部内容的字数与深度。把前10个结果的字数中位数算出来。如果中位数是800-1500字,说明内容门槛低,小站可以快速进场;如果中位数是4000-8000字,说明这个词已经被深度内容占据,小站进场成本高,需要准备至少6000-10000字的深度内容。
自动化+半自动化两条路
4个信号的提取,有两条路:
全自动化路线。用SerpAPI、DataForSEO或自建爬虫批量拉SERP,然后用Python解析。优势是规模大、可以扫10万级的候选词;劣势是成本高 (DataForSEO按1000 query计费,12万词扫一遍约 $200-400)、对SERP解析的鲁棒性要求高 (Google的SERP结构每年都在变,代码要维护)。适合预算充足、有工程能力的大团队。
半自动化路线。先用搜索量过滤掉90% 的候选词 (Ahrefs/Semrush给的搜索量为0或N/A的直接砍),剩下10% 用SerpAPI抽样验证SERP体征。优势是成本低 (扫1.2万词约 $20-40)、维护简单;劣势是会漏掉一部分工具盲区里的高价值词。我们做客户项目时多用这条路,因为商业ROI更稳。
两条路都要做的事情是:筛选完后,把候选词按4个信号打分,综合分前30% 进入内容生产排期,中40% 进入长尾观察池,后30% 直接砍。
不同行业的组合矩阵怎么不一样?
组合矩阵的三层架构是通用方法论,但每一层在不同行业的取值、权重、组合密度完全不同。我把6个常见行业的组合矩阵特征做了一个对照表,起手时参考定位:
| 行业 | base term数量 | modifier字典量 | qualifier字典量 | 典型组合数 | 有效率 | 典型规模 |
|---|---|---|---|---|---|---|
| DTC工具/家居 | 80-120 | 200-300 | 60-100 | 120-360万 | 3-5% | 5000-15000词 |
| B2B SaaS | 30-60 | 120-200 | 40-80 | 14-96万 | 2-4% | 2000-6000词 |
| 本地服务 | 20-40 | 50-100 | 80-200 (地点为主) | 8-80万 | 4-7% | 3000-8000词 |
| B2B工业 | 50-100 | 180-280 | 40-70 | 36-196万 | 2-3% | 3000-10000词 |
| 教育/媒体 | 100-200 | 150-250 | 50-90 | 75-450万 | 3-5% | 8000-20000词 |
| 医疗 (YMYL) | 40-80 | 100-180 | 30-60 | 12-86万 | 1-2% | 1000-4000词 |
读这张表注意3个细节:
第一,医疗 (YMYL) 的有效率最低,只有1-2%。这不是因为词少,而是YMYL行业Google对内容质量门槛极高,大部分长尾组合SERP头部都被权威机构 (Mayo Clinic、WebMD、政府卫生部门) 占据,小站进场成本极高。做医疗SEO,组合矩阵生成出来的词要再过一层E-E-A-T门槛筛选。
第二,本地服务的qualifier字典量极大,因为地点维度本身就承载了大量长尾。一个城市可以拆到街区、地铁站、社区,每个都是一个独立qualifier。这就是为什么本地服务的有效率反而高 (4-7%)——本地意图明确,SERP竞争相对集中。
第三,教育/媒体的典型规模最大,因为话题维度天然广,每个话题都可以衍生大量长尾。但内容生产成本也高,需要工业化内容流水线配合。SERP overlap关键词聚类页面映射里讲过怎么把长尾词聚合成hub页和spoke页架构,避免内容稀释。
客户案例:跨境家居DIY工具DTC 9个月组合矩阵实战
北美跨境家居DIY工具DTC客户,2024年初接手时月自然搜索流量8万UV,搜索词覆盖1200个。客户用了Ahrefs+Semrush两个工具的关键词数据库,但产品页一直只能拿到品牌词和大词流量,长尾流量缺口大。我们用组合矩阵方法论,9个月把月自然搜索词从1200个挖到8400个,月自然搜索流量从8万UV到26万UV,商业价值词 (有明确购买意图) 覆盖率从37% 到71%,自然搜索贡献GMV占比从18% 到41%。
5个阶段的展开:
第1-2月:字典建设阶段。base term 80个 (品类22 + 任务41 + 对比17)、modifier字典245个 (8大类按工具DTC行业本地化)、qualifier字典78个。字典建设花了7周,2个内容编辑+1个SEO工程师并行。建设过程中最大的发现是:工具搜索量为0的组合里,约12% 在Reddit子版块 /r/Tools里有真实讨论,说明这些是工具盲区。
第3-4月:组合矩阵生成 + SERP筛选阶段。80 × 245 × 78 = 152.8万候选组合。先用Ahrefs Bulk Search过滤掉91% 搜索量0或N/A的,剩下13.7万。再用DataForSEO扫SERP,按4信号打分,综合分前30% (4.1万词) 进入内容排期,中40% (5.5万词) 进观察池,后30% (4.1万词) 砍掉。
第5-6月:内容生产 + 落地阶段。前30% 的4.1万词按主题聚合成320个内容cluster,先做高商业意图+SERP内容门槛低的80个cluster,共480篇内容上线。内容上线后4-6周,目标词进入索引,前3个月平均排名从N/A到35,商业价值词排名进入前30的比例47%。
第7-8月:数据反推 + 字典迭代阶段。把第5-6月上线内容的真实排名+点击数据回流,反推哪些modifier+qualifier组合的有效率高于预期,哪些低于预期。高于预期的组合扩字典,低于预期的组合从字典里淘汰。这一轮字典从245个modifier调整到268个 (净增28、淘汰5),qualifier从78调到91。
第9月:观察池二次筛选 + 收割阶段。回头看观察池的5.5万词,3个月里有8% (约4400个) 的词搜索量从0涨到10+,说明字典更新捕捉到了新兴长尾。这部分进入内容排期,以快速短文 (1500-2500字) 为主,18周内全部上线。
9个月总投入:2个内容编辑全职、1个SEO工程师0.5投入、DataForSEO+SerpAPI工具费约 $3200、内容生产外包成本约 $48000。总投入约 $98000 (人力 $46800 + 外包 $48000 + 工具 $3200)。9个月自然搜索GMV增量约 $1.4M。ROI 14:1。
三个被低估的踩坑细节,保哥这里写出来给同行参考:第一,字典建设阶段我们一开始想4周做完,实际花了7周。原因是modifier的去噪比想象中难,品类专业术语和大众用词之间的边界要内容编辑+SEO工程师反复对齐。第二,SERP筛选阶段我们用DataForSEO扫了13.7万词,SERP解析代码因Google在第5周改了一次SERP结构,踩了3天空,后来加了多版本兼容才稳。第三,内容上线后第8周,客户内部市场团队投诉“我们的产品页排名被自己的长尾内容挤下去了”,反推回去发现是部分长尾内容跟产品页cannibalize,后来调整内链结构+canonical标记,4周才把产品页排名拉回来。
几个会让你白干的翻车场景和上线前必验清单
组合矩阵这套方法论,带客户做过12个项目,几类会让你白干的翻车场景反复出现——见过不下二十次,值得一一对照:
场景1:字典建设凭感觉。modifier字典靠经验拍脑袋写,没系统收集SERP/类目/客服/社群4个来源。结果字典覆盖率不全,组合出来的词跟竞品差不多,挖不到工具盲区的高价值长尾。
场景2:SERP筛选阶段省钱。觉得DataForSEO太贵,只用搜索量过滤,不看SERP体征。结果筛出来的词有大量“搜索量有但SERP头部全被权威机构占据”的废词,内容上线后排名进不去前30。
场景3:内容生产不分批。4.1万候选词一次性给内容团队,团队进度推不动,3个月只做了80篇,前30% 的高价值词没消化完就到了观察池开窗时间。
场景4:字典不迭代。第一轮字典做完就当成永久版,不根据上线数据反推。结果6个月后字典的有效率从47% 掉到28%,因为搜索趋势在变、modifier的高频组合在迁移。
场景5:跟现有产品页cannibalize。长尾内容跟产品页/类目页抢同一个关键词,产品页排名被压。这是组合矩阵实施时最隐蔽的坑,需要在内容上线前做SERP overlap检查,有重叠的长尾词要么canonical到产品页,要么内容上明确分意图。
上线前7项必验:
- base term是否覆盖品类、任务、对比三类,核心base 80-120个;
- modifier字典是否来自SERP+类目+客服+社群4个来源,总量150-300个;
- qualifier字典是否按人群/场景/规模/时间/地点/对比6大类齐备,总量60-100个;
- 组合矩阵是否经过搜索量 + SERP体征4信号双层筛选;
- 内容排期是否按综合分前30% 进生产、中40% 进观察池、后30% 砍;
- 是否预留字典迭代节奏 (每2个月反推一次字典有效率);
- 是否做长尾词与现有产品/类目页的cannibalize检查。
常见问题解答
组合矩阵生成出来的词,搜索量都是0或N/A,怎么判断有没有流量?
搜索量0或N/A不等于没流量。工具的搜索量数据有最低阈值,通常10次/月以下显示0。组合矩阵里30-40% 的真实有效词,搜索量在5-50次/月之间。判断有没有流量的关键是看SERP体征,不是看工具搜索量数字。
12万个组合候选,怎么避免组合数失控?
控制base term数量是关键,核心base不超过120个。如果业务覆盖广,把base按意图分组,分组生成组合矩阵。比如品类base和任务base分开,组合时只让品类base跟规格modifier组合,任务base跟教程modifier组合,避免不合理组合产生。
字典里的modifier和qualifier经常重合,怎么区分?
核心区别在于:modifier修饰base本身的属性 (产品是什么),qualifier限定使用情境 (谁用/何时用/在哪用)。比如cordless是modifier (产品属性),for outdoor是qualifier (使用场景)。重合时按“是否修改产品本质”判断,修改产品本质的归modifier,只限定情境的归qualifier。
SERP筛选4个信号的权重怎么分?
典型权重:信号1 (SERP真实性) 35%、信号2 (商业性) 30%、信号3 (SERP特性) 20%、信号4 (头部字数) 15%。但具体行业要调:本地服务把信号1权重提到45%、信号2降到20%;B2B SaaS把信号3权重提到35%。
组合矩阵每隔多久要重新跑一次?
典型节奏是字典每2个月反推一次有效率、每6个月全量重跑一次组合矩阵。重大算法更新 (核心更新、HCU、AI Overview扩容) 之后,要在4周内做一次紧急重跑,因为SERP体征会发生结构性变化,旧筛选结果可能失效。
组合矩阵跟传统关键词调研工具是替代关系还是补充关系?
是互补关系。工具用来挖已经被搜过的稳定词,组合矩阵用来挖工具盲区的工程化候选词。两者数据合并后才是完整的长尾关键词池。单独用工具会漏60%+ 长尾流量,单独用组合矩阵会跑掉一部分高频稳定词的市场信号。
组合矩阵生成的长尾内容跟现有pillar page怎么协同?
把长尾内容当成spoke页,统一链接回pillar page,pillar page承接base term的核心流量,spoke页承接modifier+qualifier组合的长尾流量。pillar+spoke架构里的内链规则要明确写,避免长尾spoke互相cannibalize。具体内链架构参考关键词聚类页面映射。
本文标题:《关键词组合矩阵生成器:modifier与qualifier长尾词工程方法论》
本文链接:https://zhangwenbao.com/keyword-combinator-modifier-qualifier-matrix-long-tail-engineering.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0