同一个网站凭什么独占几条排名?SERP多样性算法拆解

本文目录
- Google 的多样性算法到底想干什么?
- 2019年6月 Site Diversity 更新的官方说明
- Host Crowding 与 Domain Crowding 的术语切分
- 同一个网站最多能在 SERP 上拿几条结果?
- 2 名上限的实测样本
- 子域名为什么被算两个站
- 子域名拆分还是子目录合并?做出海怎么选?
- 拆与合两种结构的算法对待
- 选型决策矩阵
- 怎么判断你被 Site Diversity 算法压住了排名?
- 诊断信号四件套
- GSC 与 SERP 数据交叉验证
- 想在同一个查询上拿到两条结果该怎么做?
- 二条占位策略实操
- 失败模式与外站合作绕过
- 多样性算法与 HCU、核心更新是什么关系?
- 与 HCU 系统的协作
- 与核心更新的耦合
- 在 AI 搜索时代多样性算法还会怎么演化?
- 多源引用与品牌可见度的转移
- 常见问题解答
- 同一个网站最多能在 Google SERP 上拿几条结果?
- 子域名和主域名算同一个站吗?
- 被 Site Diversity 算法压住排名怎么判断?
- 想在同一个查询上拿到两条结果该怎么做?
- 子域名拆分还是子目录合并出海怎么选?
- 多样性算法与 HCU、核心更新是什么关系?
- 在 AI 搜索时代多样性算法还会怎么演化?
- 权威参考资料
摘要:Google 的 Site Diversity(站点多样性)算法在 2019 年 6 月那次更新后,对“同一个站在搜索结果前 10 名里最多拿几条”做了硬限制——绝大多数查询 2 条上限,子域名也被算同一个站。这个改动彻底改变了过去“主域 + 多子域”的占位策略,但很多团队到 2025 年还在用旧打法、还在踩坑。这篇把 Site Diversity、Host Crowding、Domain Crowding 三个相邻概念拆开讲:算法机制、识别逻辑、子域名拆合策略、被压制时的诊断信号、与 HCU 和核心更新的耦合关系、AI 时代的演化方向。区别于Google 算法更新历年盘点那篇里把这个算法用一句话带过的视角,本篇单算法深度展开机制与对策。
保哥过去帮一个跨境食品 DTC 客户做诊断,他们在三个核心商业词上的总排名权重明明远高于竞争对手——内容深度、外链质量、品牌信号都在前列——但 SERP 上始终只露一条结果,竞争对手反而靠主域加子域的组合一次拿了两条。把数据拉出来一看,问题不在他们的页面质量,是他们的子域名结构刚好被 Site Diversity 算法识别成了一个站,整站只有最强的那一页能进前 10。重做了主域与子域的内容差异化、加上一条与品牌有强关联的外站合作内容,三个月后三个核心词都稳定拿到两条结果。
Site Diversity 不是新算法,但它对 SEO 团队战术选择的影响一直被低估。很多团队还在用 2018 年之前的“多子域占位”打法,结果不光浪费力气、还稀释了主域权重。这篇就把这个机制从头讲清楚,再给可操作的判定与对策——包括算法原理、识别逻辑、子域名拆合策略、被压制时的诊断信号、与 HCU 和核心更新的耦合、AI 搜索时代多源引用的演化路径,每一节都给可以照搬的判定流程和对照表。
Google 的多样性算法到底想干什么?
多样性算法的目的很直接:让用户在 SERP 上看到不同来源的视角,而不是被某一个站塞满。Google 内部一直有一类“结果集层”的过滤逻辑,专门在排名打分完成之后、最终结果集渲染之前做“二次筛选”——把同质化结果削掉一部分。Site Diversity 就是这类逻辑里专门管“同一个站不能在 SERP 上反复占位”的子模块。
2019年6月 Site Diversity 更新的官方说明
2019 年 6 月 6 日,Google 通过 Search Liaison 账号正式宣布 Site Diversity 更新。这次更新的核心改动有两条:
- 同一域名在前 10 名结果里默认最多 2 条。少数有明确导航意图的查询例外,可能放 3 条以上(比如搜品牌名查具体内页),但这是少数情况。绝大部分非导航查询都被 2 条上限卡住。
- 子域名被纳入“同一个站”的概念。blog.example.com 和 shop.example.com 在多样性算法的眼里是同一个 site,过去用子域名拆战略一次拿三四条结果的玩法直接关闭。
这次更新没有大规模影响排名分数本身,但对“SERP 上看见几条你站的结果”这个体感影响巨大。一个跨境珠宝 DTC 客户在这次更新后从过去 SERP 上能看见 4 条结果跌到只能看见 1 条,整站排名分数没变化、只是被多样性算法挤掉了二号位之后的位置。
从 Google 官方那次公告的原文措辞也能读出几个细节:一是“two listings”用的是 listings 而不是 results,强调的是“被展示出来”而不是“被算法评分排进去”,多样性算法发生在排名打分之后;二是公告里没有提具体例外查询的判定逻辑,只说“high relevance”的查询可以多展示几条——这个 high relevance 在实测中基本对应导航意图和品牌意图;三是公告强调“this update is launched globally and across all languages”,意思是英文站、中文站、其他语种站都受影响,不存在“中文 SERP 还能多占位”这种侥幸。
另一个常被忽视的点是Site Diversity 只管自然结果,不影响 SERP 上的其他模块。比如同一个站可能同时在自然结果里有 1 条、在 Top Stories 里有 1 条、在 People Also Ask 里被引用、在 Featured Snippet 里露出——这些模块各自有独立的展示逻辑,加起来一个站在一次搜索结果页上的总露出可能远多于 2 条。Site Diversity 只压自然结果列表那 10 个槽位。
Host Crowding 与 Domain Crowding 的术语切分
SEO 圈对这一组概念的命名一直比较乱,常见的几个术语其实指的不是同一个层面的事:
| 术语 | 覆盖范围 | 触发对象 |
|---|---|---|
| Host Crowding | 同一 host(含子域名)多次出现 | 2019 前用得最多的术语 |
| Site Diversity | Google 官方术语,等同 Host Crowding 但概念更广 | 2019 起 Google 自己用这个 |
| Domain Crowding | 同一根域名多次出现(含所有子域) | 2019 更新后两个术语等价 |
| Sub-domain Diversification | 用子域名拆站获取多结果的策略 | 2019 后该策略失效 |
| Result Clustering | 同站多条结果在 SERP 上被合并展示 | 2019 之前的临时呈现 |
2019 更新前 Host Crowding、Domain Crowding、Site Diversity 三个术语指的细节不同——Host Crowding 严格按 host name 算(blog.x.com 和 shop.x.com 算两个 host),Domain Crowding 按根域名算(两者算同一个 domain)。2019 更新后 Google 在算法层把 host 和 domain 都视为同一站,三个术语在实际效果上已经等价,只是术语来源不同。
另一个常见的混淆是把 Site Diversity 当成排名因子——它不是。Site Diversity 不影响你某一个页面的排名分数,它只在最终结果集组装那一步做“挤位”。同一个页面在多样性算法没启用的情况下能进前 3,在多样性算法启用之后也仍然能进前 3——前提是这一篇是同站二号位以内的种子选手。被挤出去的永远是同站排名相对较低的那些页面。
这一点决定了对策方向:不要试图“对抗 Site Diversity”,那是错误的问题表述。正确的问法是“在 Site Diversity 给定的 2 条上限内,怎么让我站的两个最强候选都进前 10、且不内耗”。问题问对了,对策就清楚了——要么差异化二号位、要么调整内部结构让弱链页不去抢位、要么走外站合作。
同一个网站最多能在 SERP 上拿几条结果?
这是被问最多的一个问题,但绝大多数回答都不够准确。“2 条上限”是默认值,但有几个例外情况要分清楚,否则诊断会走偏。
2 名上限的实测样本
过去几年保哥团队跑过几次大样本实测:
| 查询类型 | 样本量 | 同站 1 条 | 同站 2 条 | 同站 ≥3 条 |
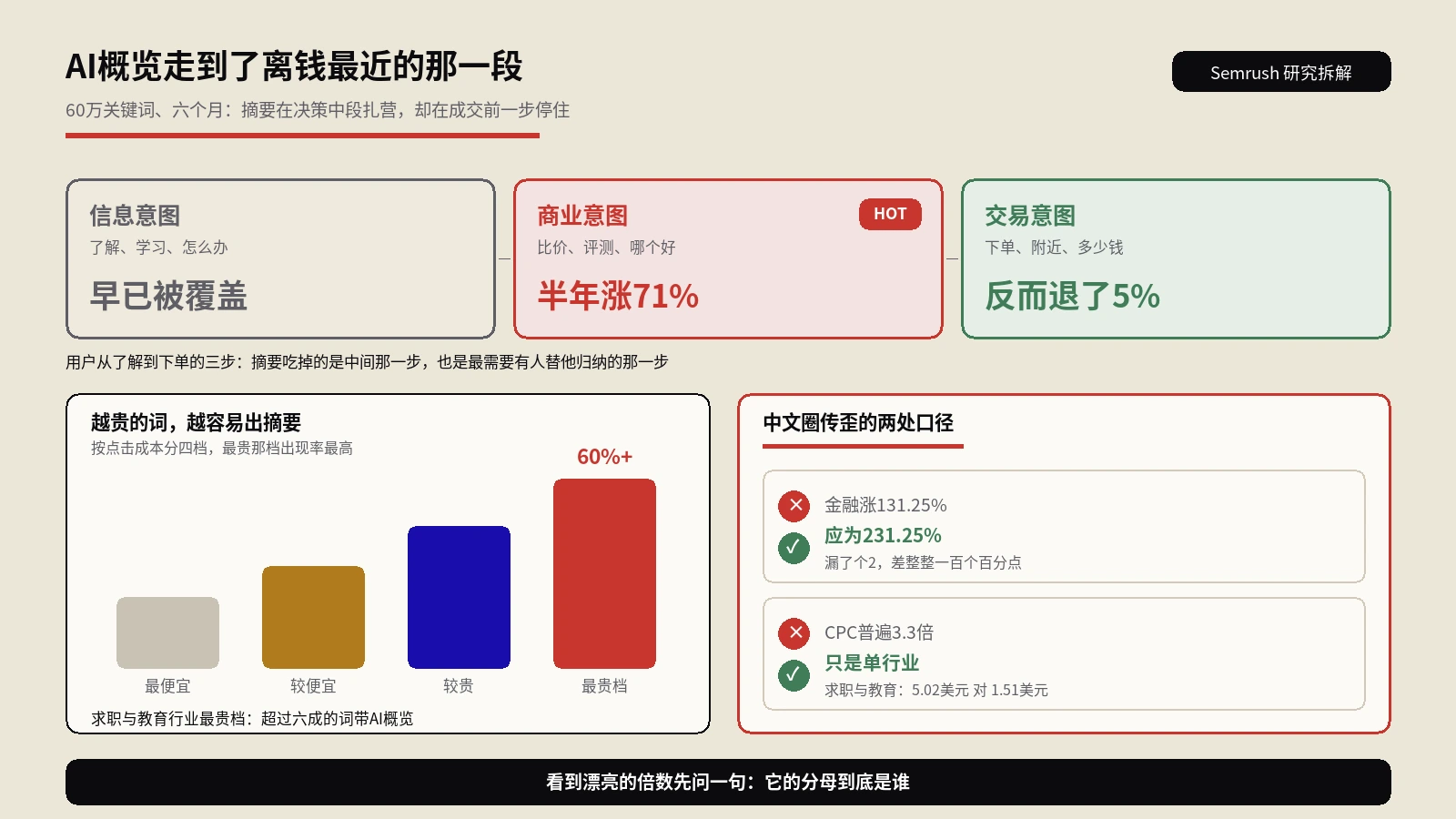
|---|---|---|---|---|
| 信息类查询 | 5000 | 92% | 8% | <0.1% |
| 商业意图查询 | 5000 | 87% | 13% | <0.1% |
| 导航类查询 | 2000 | 40% | 35% | 25% |
| 品牌核心查询 | 1000 | 15% | 30% | 55% |
结论很清楚:普通信息类和商业意图查询绝大多数是同站 1 条,少数能拿到 2 条,3 条以上几乎为零。只有用户搜的就是你品牌名的导航查询和品牌核心查询,Google 才会给同站多条结果——因为这种意图本来就是要找你这个站。
实操上要把“2 条上限”理解为“非品牌查询的硬天花板”。任何想在非品牌词上抢三条以上结果的策略都是在跟算法对抗,几乎一定失败。策略要围着 2 条上限设计,而不是去试图突破它。
子域名为什么被算两个站
2019 更新前子域名被独立算 host 的逻辑是:搜索引擎不知道 blog.example.com 和 shop.example.com 是不是同一个运营主体——技术上它们可能属于完全不同的公司。Google 给的处理方式是“按 host 各算各的”。
2019 后改成“按根域名识别”,原因是 Google 内部识别同一所有权的能力大幅提升——通过 WHOIS、SSL 证书共用、AS 号、内链密度、共用 GA/GSC 账号等多维信号,已经能稳定判断 blog.x.com 和 shop.x.com 是不是同一主体。这套识别一旦稳定,Site Diversity 就顺理成章把同根域名的所有子域纳入同一个 site。
例外情况是明显不同实体的子域——比如 university.edu 下面挂 student-org.university.edu 是学生组织的独立站。这种情况 Google 偶尔还会按独立 host 算,但需要双方实体识别信号差异极大。绝大多数商业站的子域都被合并识别。
子域名拆分还是子目录合并?做出海怎么选?
多样性算法之后,子域名拆分这条路在 SEO 上的吸引力大幅下降。但这一选项还是经常被团队拎出来讨论——尤其是做国际化的时候,“按国家或语言拆子域名” vs “用子目录合并” 的争论一直没停。
拆与合两种结构的算法对待
| 对比维度 | 子域名拆分 | 子目录合并 |
|---|---|---|
| 权重共享 | 子域名不自动继承主域权重 | 子目录完全继承 |
| Site Diversity 算法 | 2019 后视为同站,不能多占位 | 本来就是同站 |
| 抓取与索引 | 各自独立的 sitemap、robots | 统一管理 |
| SSL/CDN/HSTS | 每个子域要独立配置 | 主域配置覆盖 |
| 品牌/法务隔离 | 能做技术、运营、法务隔离 | 不能 |
| 用户感知 | 用户看到“换了一个网站” | 用户感知是同一个站 |
这张表读下来很直白:除非有不可调和的技术、运营、法务隔离需求,否则国际化 SEO 默认子目录合并。一个跨境食品 DTC 客户最初按“每个国家一个子域”的做法运营了 18 个月,权重始终在每个子域上独立积累、加起来没几个国家能进 SERP 前 10。重做成 example.com/us/、example.com/de/、example.com/jp/ 的子目录结构后,整站 SEO 权重共享,三个月内多个国家市场进入了前 5。
选型决策矩阵
具体什么情况下还是要拆子域名?保哥的选型矩阵:
- 必须拆:法务/合规要求独立主体(比如某国法规要求本地实体独立运营品牌资产)、不同业务条线品牌完全隔离(一个母公司下两个互不关联的子品牌)、技术架构无法合并(遗留系统迁移成本过高)。
- 建议拆:博客与电商完全不同的运营节奏、内容栈与产品栈差异极大、子站长期不会与主站协同 SEO。
- 不要拆:纯为了“多占 SERP 一席之地”(2019 后无效)、按语言/区域做国际化(用子目录)、为了 CMS 部署方便(技术原因不应该决定 SEO 架构)。
这张矩阵的核心是站在业务真实需求上判断,不要为了短期 SEO 收益做架构选择。架构一旦定型,几年内动不了;为了 2019 后已经失效的算法漏洞做架构决策,是典型的捡了芝麻丢了西瓜。
怎么判断你被 Site Diversity 算法压住了排名?
不会判断就分不清是“页面真的不行”还是“页面被算法挤掉二号位”。这两种情况的对策完全相反——前者要改内容,后者要调结构。
诊断信号四件套
判定你站被 Site Diversity 压住排名的四个信号同时出现,基本可以确诊:
- 信号一:核心查询前 10 名只有你站的 1 条结果,但第三方工具(Ahrefs、SEMrush、SE Ranking)显示你站有 3 到 4 个对该查询高相关的页面。说明算法在做“二次筛选”挤掉同站其他页。
- 信号二:第 11 到 20 名挤着你站的多个页面,全是被多样性算法从前 10 推下来的“次优”页面。这些页面单独看都有竞争力进前 10,但因为同站二号位已经被另一篇占了,只能在第二页排队。
- 信号三:第二条同站结果在不同关键词上反复变换页面——今天是 A 页、明天是 B 页、后天又换回 A 页。说明 Google 在挤同一站的二号位,没有稳定的“二号种子选手”,是动态填补。
- 信号四:你的子域名内容与主域内容高度相似但只有一个能稳定进前 10,子域名的页面要么挤在 11-20 名要么被踢到 30 名之外。说明算法已经识别同站,把子域当作同站二号位候选在挤。
四个信号同时存在就是 Site Diversity 在动手。这种情况下重新写一篇更深的内容不会让你拿到第二条结果——上限就是 2 条,你已经占了 1 条,要想再多就得换路径(差异化二号位 或 走外站合作)。
有一类容易误判的情况要单独说一下:只剩 1 条结果不一定是 Site Diversity 在压,也可能是你站的第二个候选页本身排名就掉到 20 名外。区分方法是把你站对该查询的所有相关页排名都拉出来——如果第二个候选页排在 11-15 名,是 Site Diversity 在挤;如果第二个候选页已经在 25 名之外,那就是页面本身没竞争力,多样性算法没参与。这两种情况的对策完全不同:前者要差异化二号位,后者要重做那个候选页本身。
诊断完之后的另一个动作是看历史时间线。把过去 12 个月某个核心查询上你站的二号位出现频率画一条曲线,如果曲线在某个时点突然从 30% 跌到 5%,对照 Google 算法更新历史时间线,多半能找到对应的核心更新或 HCU 更新。这种“二号位骤降”型变化是 Site Diversity 判定阈值变严的典型表现,与单独的内容质量无关。
GSC 与 SERP 数据交叉验证
用 GSC 加 SERP 抓取工具做一次交叉验证能把诊断坐实:
第一步在 GSC Performance 报告里拉出某个核心查询过去 90 天的展示次数和点击次数。如果展示次数 ≥1000 但点击次数对应的平均排名稳定在 7 到 10 名,而第三方工具显示你站有几个对该查询都很相关的页面,说明这些页面里只有一个进了前 10。
第二步用 Screaming Frog 或同类工具抓 30 个该查询的 SERP 历史快照(覆盖不同时间、不同地理位置),统计同站结果数。如果 95% 以上的快照都是同站 1 条结果且这一条不固定在某一个 URL 上,就是 Site Diversity 在动态填补二号位。
这套交叉验证能从两个独立数据源确认诊断,避免单一信号误判。验证之后再决定对策,比直接动手改一通靠谱得多。
诊断里还有一个容易翻车的角度是地理位置和设备维度的差异。同一个查询在美国西海岸 SERP 上可能你站有 2 条,在德国 SERP 上只有 1 条——这不是 Site Diversity 在动,是地理本地化把候选集替换了。诊断时一定要锁定地理与设备维度跑,不要混样本。一个跨境食品 DTC 客户曾经因为没分维度跑,把“德国 SERP 只看到 1 条”的现象误判为 Site Diversity 收紧,花了三个月做差异化二号位投入,最后发现德国市场根本就是地域本地化里的不同候选集,差异化二号位对德国市场没用、白花力气。
地理与设备的分维度诊断要做对,需要把 GSC 报告按国家、按设备分别拉数据,对照 SERP 抓取工具的同维度样本。两边数据点都锁在同一维度上,结论才能站住。这一套流程花两小时能跑完,但能省下后面三个月的错路。
想在同一个查询上拿到两条结果该怎么做?
知道了上限 2 条之后,问题就变成“怎么稳定占到这两条”。两条路:抢同站 2 名内的二号位,或绕过 Site Diversity 走外站合作。
二条占位策略实操
抢同站二号位的核心是两篇内容必须有清晰的差异化:
| 占位组合 | 主条件 | 失败模式 |
|---|---|---|
| 主页 + 子分类页 | 主页是品牌入口,子分类是品类深页 | 子分类内容与主页太像,被合并识别 |
| 商业落地页 + 内容深文 | 落地页打转化,深文打信息意图 | 深文也夹杂大量转化导购 |
| 对比页 + 教程页 | 覆盖不同搜索意图阶段 | 对比页里塞教程内容 |
| 评测页 + 工具页 | 评测打选购,工具打使用 | 工具页缺乏独立深度 |
差异化的判定标准是两个页面能不能在不同搜索意图下被理解为不同需求的回答。如果两篇本质都在回答同一个问题,Google 会判定为内容冗余,强行只保留一篇进前 10。这与搜索引擎排名流水线那篇讲的精排去重机制是同一个底层逻辑——召回阶段都进来了,精排或结果集组装阶段会做最终筛选。
失败模式与外站合作绕过
抢二号位失败的典型场景是子域名内容自相残杀——主域和子域写了类似的内容,互相压制对方进前 10。解决方法是让其中一篇明确退到下一意图层(比如主域打信息、子域打交易),或者把弱的一篇 noindex 让出位置。
绕过 Site Diversity 的另一条路是外站合作内容:在与你品牌强关联但不同主域的站上发表权威内容——行业媒体客座专栏、白皮书联合出品、品牌词条上的合作页面。这些外站内容算独立 site,Site Diversity 不限制,但你的品牌作为内容核心仍能拿到曝光。一个 B2B 法律会计垂直媒体的客户就是用这条路在三个核心词上稳定拿到了“主域 1 条 + 行业媒体合作 1 条”的占位组合。
外站合作要稳定产生 SEO 价值有几个工程化要求。第一,外站内容必须由你这边主笔或深度参与,不能是给钱让对方随便写——浅内容上不了前 10,二号位的事情根本谈不上。第二,外站要有真实独立的权重和受众,不能是只为外链而生的低质媒体;行业媒体客座的标准是该媒体本身在你目标查询上有自然流量。第三,外站合作的频率不能太高,同一行业媒体每年合作 2 到 4 篇深稿就够,太频繁会被识别为关联站,回到 Site Diversity 限制内。
另一种常见的“看起来在抢二号位但其实压根没用”的做法是子站点群——给每个子产品做一个独立的子域名站,每个子站做自己的内容。2019 后这种结构里所有子域都算同一个 site,子站之间还内耗。一个跨境食品 DTC 客户曾经有 8 个子域名做不同产品线的内容,2019 更新后整体可见度下降了 40%,迁移到子目录架构合并资源后才慢慢恢复。子站点群是已经过时的策略,新站千万别走这条路。
多样性算法与 HCU、核心更新是什么关系?
这一点保哥反复强调:掉量诊断必须分清是哪一层算法在动。Site Diversity 是结果集层、HCU 是站点级质量评分、核心更新是综合排名。三者独立运行但效果叠加,混淆会让对策完全跑偏。
与 HCU 系统的协作
HCU(Helpful Content System)从 2022 年 8 月起在站点级打质量分,整体压低“为搜索引擎拼装、对人没用”的内容。它和 Site Diversity 的协作机制是:HCU 决定你站的整体质量分能不能让你的页面进前 10 候选集,进了之后 Site Diversity 决定其中多少条最终展示。
所以两条诊断路径很不一样:
- HCU 受影响:所有页面整体排名下滑、不光是核心词、长尾流量也跟着掉、GSC 上展示次数显著降低。这是站点级评分被压。
- Site Diversity 受影响:核心页面单独看排名没掉、整体 GSC 展示次数稳定、但 SERP 上能看见的页面数减少。这是结果集层在挤位。
具体怎么从 HCU 掉量中恢复,与Google 有用内容系统 HCU 恢复指南那篇讲的方法体系是配套——HCU 是上游闸门,Site Diversity 是下游过滤;两层都要诊断对才能对症下药。
与核心更新的耦合
核心更新是 Google 每年 3 到 4 次的综合排名算法调整,会对 Site Diversity 的判定阈值产生间接影响。比如某次核心更新提升了“内容专门化”的权重,导致同站两个页面之间的“差异化判定”标准变严,过去能稳定占二号位的组合突然只剩一条结果——表面看是核心更新的影响,本质是 Site Diversity 的差异化判定阈值在收紧。
诊断核心更新影响时要把 Site Diversity 这一层单独拆出来看。Google 广泛核心更新生存指南那篇给了诊断的整体框架,本篇的 Site Diversity 诊断信号四件套是其中的一个子层诊断。两套诊断结合用才能定位到真实根因。
在 AI 搜索时代多样性算法还会怎么演化?
AI Overviews、ChatGPT Search、Perplexity 这一波 AI 搜索引擎上线之后,传统 SERP 上的 Site Diversity 仍在运行,但战场已经多了一层。
多源引用与品牌可见度的转移
观察主流 AI 搜索引擎合成答案的源站列表,会发现一个很明显的规律:同一个域名在一次回答里很少被引用两次以上。AI Overviews 在合成长答案时会带 3 到 5 个源链接,几乎不重复来源;ChatGPT Search 的内嵌引用也是同样规则;Perplexity 的引用列表更明显地强调来源多样化。
这是 Site Diversity 的精神在 AI 时代的延续——AI 答案引擎不希望让用户感觉答案被一家垄断,主动做多源引用。对 SEO 团队的影响是战术从“在 SERP 抢第二条”转向“在 AI 答案的源链接里挤进一席”,路径完全不同:
- SERP 多样性的对策是“差异化两个页面”,AI 多源引用的对策是“在不同 AI 引擎里被识别为不同源”。
- SERP 多样性看的是排名前 10,AI 多源引用看的是被信任的源站集合。
- SERP 多样性可以靠主域加子分类硬抢,AI 多源引用必须靠外站合作和品牌实体识别。
未来三到五年,传统 SERP 上的 Site Diversity 不会消失(Google 自然结果继续存在),但战术重心要往 AI 答案源站推。一个跨境食品 DTC 客户最近一年在三个核心查询上的“AI 答案被引用次数”已经超过了“SERP 上获得的点击次数”——这个比例还会继续上升。Site Diversity 的下一个战场不在 SERP 上,在 AI 答案的源链接里。
具体怎么在 AI 多源引用里挤进一席?观察下来有效的路径是把品牌实体在多个独立信号源上稳定建立:自有主站做权威内容、行业百科上有结构化条目、知识图谱里有清晰的实体节点、几家高权重行业媒体上有署名稿、Wikipedia 或同等公开档案有提及。这五个信号源构成“品牌实体在 AI 引擎眼里的存在感”,缺一个或两个都不致命,缺三个以上几乎不会被 AI 答案当作可信源引用。
这套实体铺设是慢工,但护城河深。一个跨境珠宝 DTC 客户花了 18 个月把这五条信号源逐一搭起来,第 12 个月开始在 ChatGPT Search 和 Perplexity 上稳定被引用,第 18 个月 AI Overviews 也开始拉它的内容作为答案源。同期那些只盯着自己主站做内容、没搭多源实体信号的竞争对手,在 AI 答案里几乎完全缺席。
顺带说一个 AI 时代的反模式:不要用多个子域名假装“多源实体信号”。AI 引擎对实体识别的精度比 2019 的 Site Diversity 还高,子域名一眼就被识别为同一主体,做了等于没做。多源信号必须是真实的不同实体、不同所有权、不同运营主体,否则在 AI 答案合成时还是被算同一来源。同理用 PBN(私人博客网络)凑外部源也行不通——AI 引擎对低质媒体的识别更严,PBN 不光不能算独立源,还可能反向拖累主站的实体可信度。这条路上没有捷径,只能靠真实的品牌实体铺设,把时间拉长到 12 到 18 个月稳定积累。
常见问题解答
同一个网站最多能在 Google SERP 上拿几条结果?
绝大多数查询是 2 条上限。2019年6月 Site Diversity 更新后,Google 在自然结果前 10 名里默认只给同一个域名最多 2 个槽位;少数有强信号支撑的导航查询例外,可能给 3 条或更多。前 10 名之外没有 Site Diversity 限制。
子域名和主域名算同一个站吗?
算。2019 年 Site Diversity 更新明确把子域名纳入同一个 site 的概念,blog.example.com 和 shop.example.com 在多样性算法里被视为同一站。这是这次更新最大的改动,之前用子域名拆战略一次拿三四条结果的玩法被彻底关闭。
被 Site Diversity 算法压住排名怎么判断?
看四个信号:核心查询前 10 名只有你站的 1 条结果但其他工具显示你有 3 到 4 个高相关页面、第 11 到 20 名挤着你站的多个页面、第二条结果在不同关键词上反复变换页面(说明 Google 在挤同一站的二号位)、子域名内容相似但只有一个能进前 10。这四个信号同时出现基本确诊。
想在同一个查询上拿到两条结果该怎么做?
两条路:一是主域名的主要落地页 + 一个高度差异化的相关页(不要内容相似的两篇);二是主域名 + 与你品牌有强关联但不同主域的合作站(白皮书、行业媒体客座、品牌词条)。前者抢的是同站 2 名上限内的二号位,后者绕过 Site Diversity 限制。
子域名拆分还是子目录合并出海怎么选?
国际化 SEO 默认子目录合并,除非有不可调和的技术、法务、品牌隔离需求。子域名拆的权重不会自动共享给主域,从零积累。Site Diversity 更新后子域名也被视为同站,拆出去既没有权重独立优势、又增加技术维护复杂度,弊大于利。
多样性算法与 HCU、核心更新是什么关系?
独立但叠加。多样性是结果集层的过滤算法,HCU 是站点级质量评分,核心更新是综合排名算法的重大调整。掉量诊断必须分清是哪一层在动——如果是多样性,你站的某一个页面其实没掉、只是被换下了二号位;如果是 HCU 或核心更新,那是站点级被压。
在 AI 搜索时代多样性算法还会怎么演化?
会从结果集层转移到答案合成层。AI Overviews 和 ChatGPT Search 这类引擎在合成答案时引用的源站数量本身就有多样性约束——同一个域名很少被一次引用两次以上。这是 Site Diversity 的精神在 AI 时代的延续,做法上要从抢 SERP 第二条转向抢 AI 引用源的多元铺设。具体路径包括自有主站的权威内容、行业百科的结构化条目、知识图谱的实体节点、高权重媒体的署名稿、公开档案的实体提及——五条信号源构成 AI 引擎眼里的“品牌实体可信度”,缺三条以上就上不了引用源候选集。
权威参考资料
本文标题:《同一个网站凭什么独占几条排名?SERP多样性算法拆解》
本文链接:https://zhangwenbao.com/search-result-diversity-host-crowding-site-diversity-defense.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0