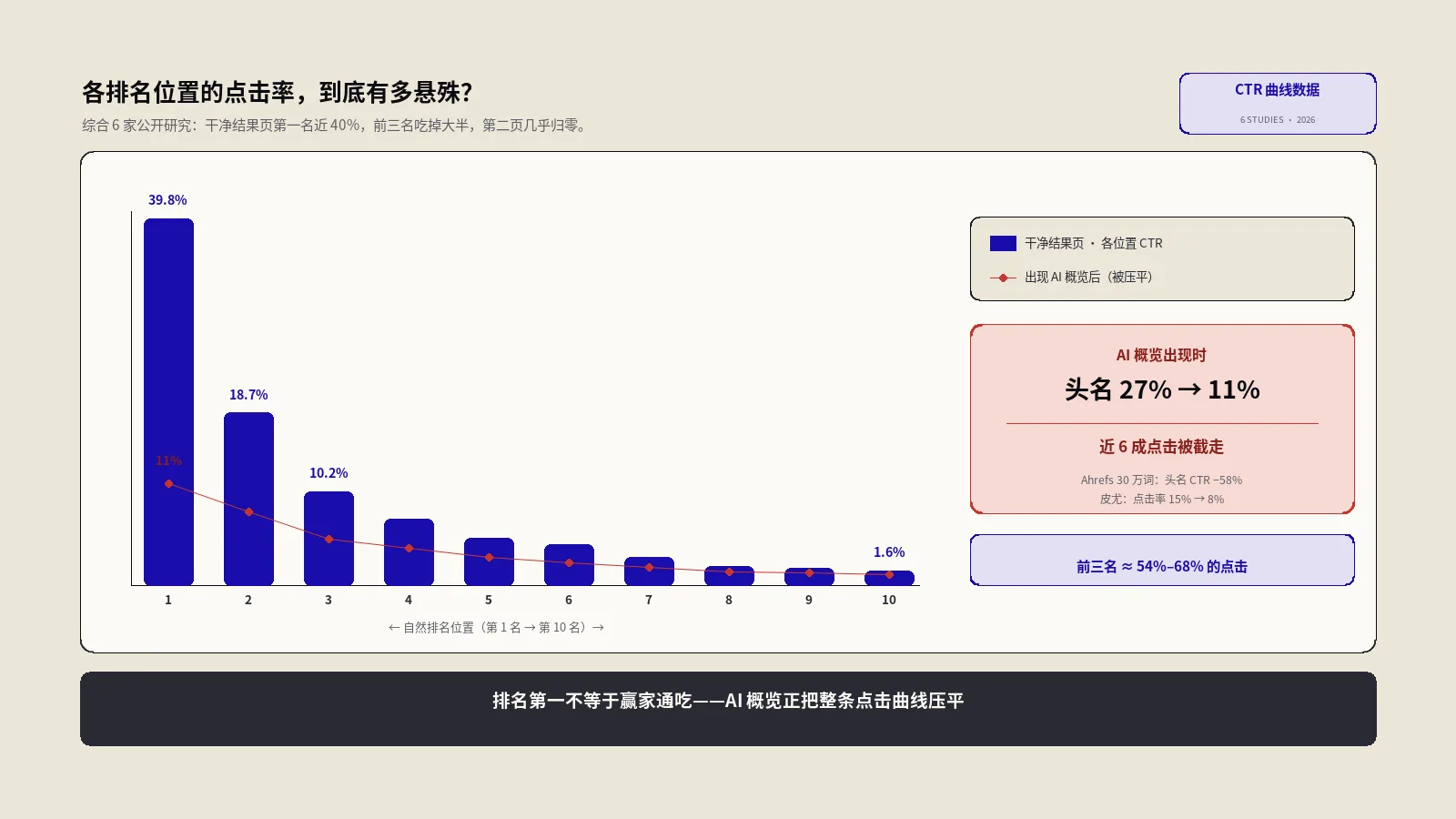
Google各排名位置的点击率是多少?2026 CTR曲线数据与AI概览冲击
搜索结果第一名点击率到底是多少?综合Backlinko、First Page Sage、Sistrix等6家研究,干净结果页头名约27% 到40%,前三名吃掉过半点击,第二页几乎没流量。本文把各家CTR曲线数据摆到一张表读懂差异,再讲清AI概览如何把整条曲线压平、外贸独立站该怎么用它做排位决策。
想让网站在谷歌和百度持续拿到免费流量,靠的不是碰运气而是体系。这里汇集保哥二十多年的SEO实战经验,从关键词研究、页面与技术优化到外链建设、内容策略和算法应对,手把手带外贸、独立站与SEO从业者把搜索排名做成可复制的长期增长。
搜索结果第一名点击率到底是多少?综合Backlinko、First Page Sage、Sistrix等6家研究,干净结果页头名约27% 到40%,前三名吃掉过半点击,第二页几乎没流量。本文把各家CTR曲线数据摆到一张表读懂差异,再讲清AI概览如何把整条曲线压平、外贸独立站该怎么用它做排位决策。
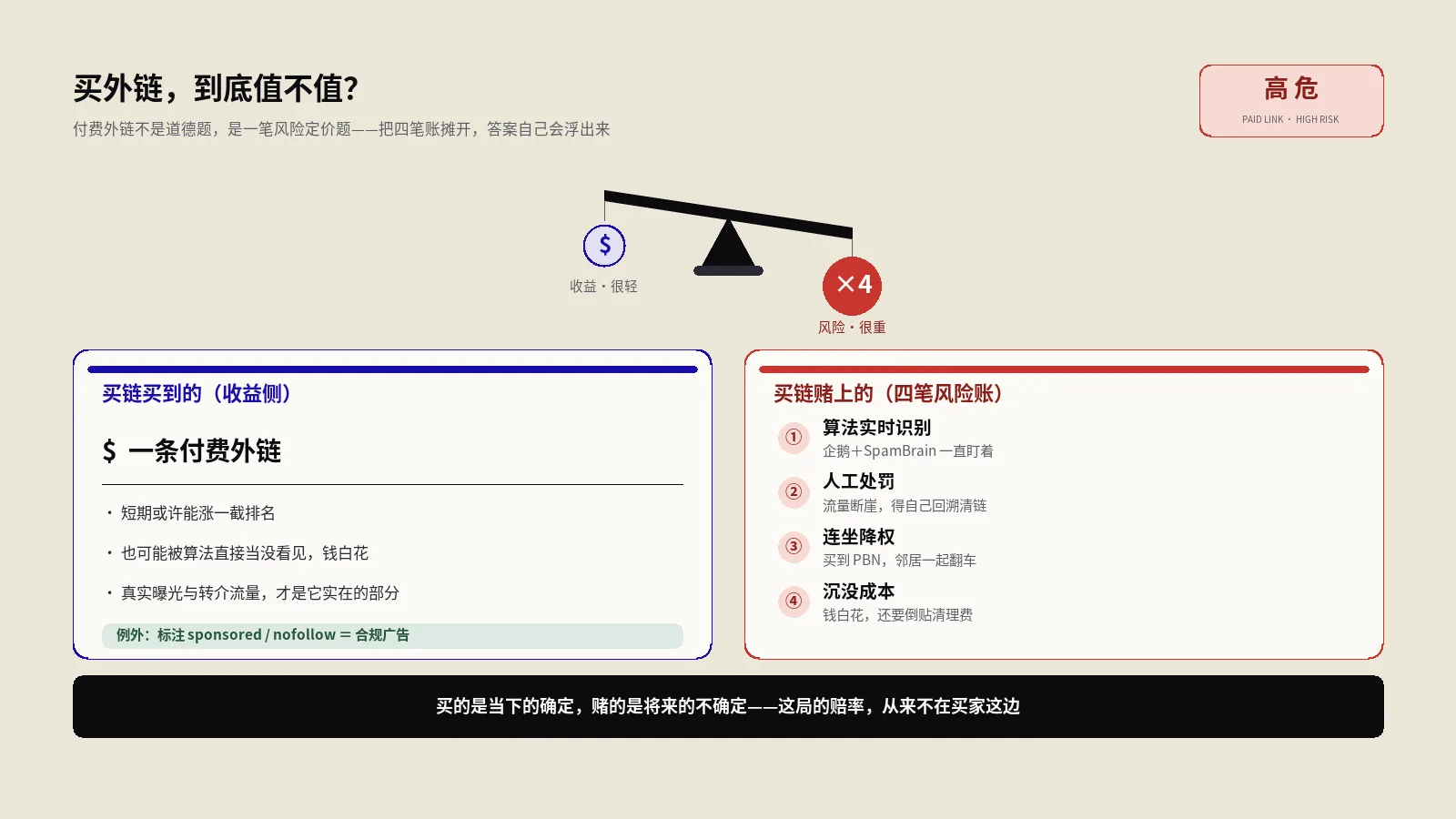
买外链值不值不是道德题,而是风险定价题。Google禁的是为传递权重而隐藏付费性质的链接,不是所有花钱出现的链接。本文摊开付费外链的四笔风险账(算法识别、人工处罚、连坐降权、沉没成本),给出买前必过的6问判断清单,并讲清三类合规付费链接和不买的正道替代。
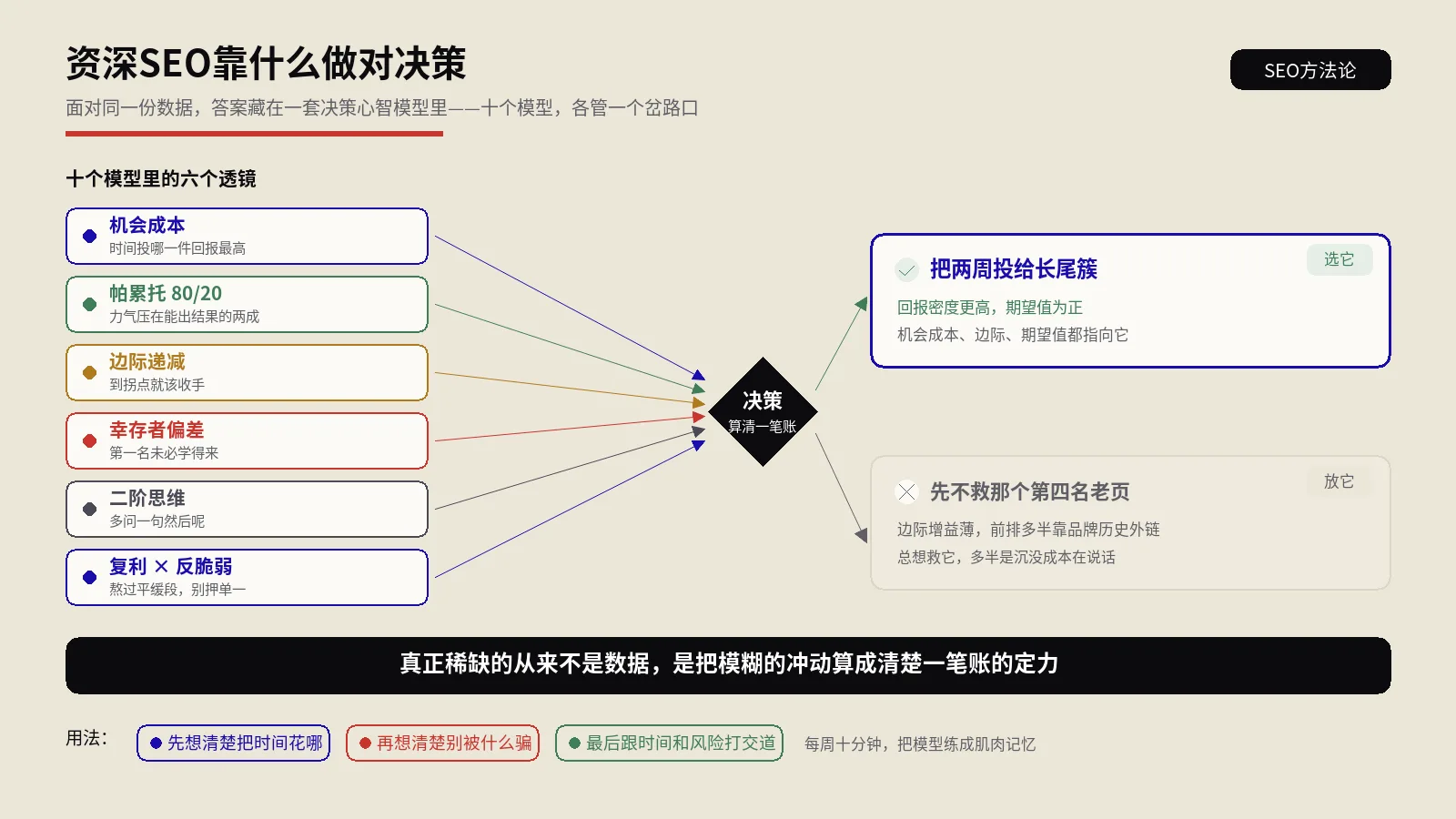
面对同一份数据,资深SEO和新手的决策为何天差地别?差的不是谁背下更多排名因素,而是一套在信息不全时做判断的决策心智模型。本文把资深顾问真正在用的十个模型,各绑一个具体的SEO岔路口,配真实数据讲清怎么把模糊的冲动算成清楚的账。
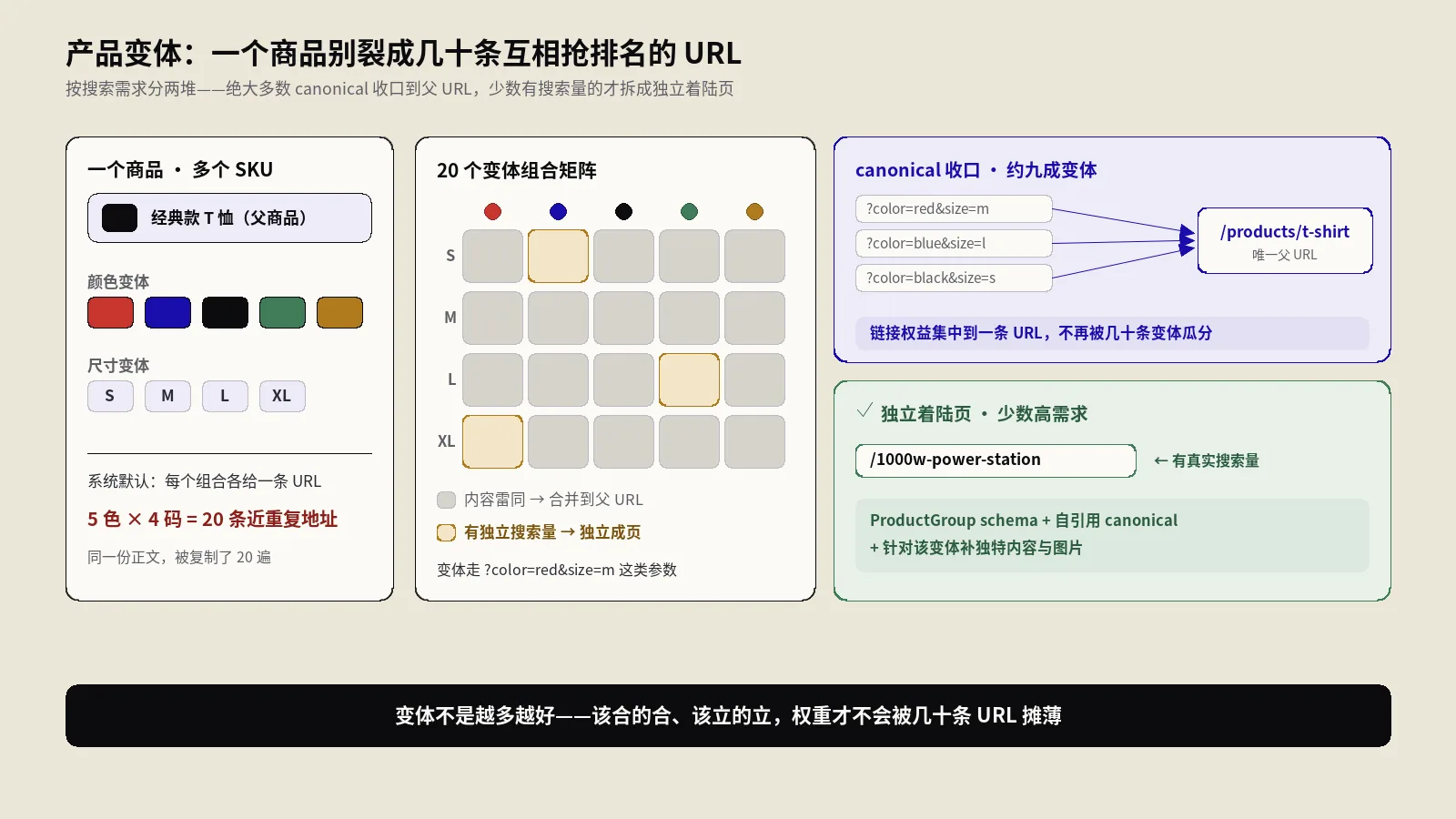
同一件商品的颜色、尺码、容量变体,常被电商系统拆成几十条近重复URL,互相稀释权重、吃抓取预算。本文讲清按搜索需求把变体分两堆:多数用canonical收口父URL,少数有搜索量的才独立成页,附ProductGroup结构化数据与三大平台落地。
很多人把产品描述、FAQ、参数收进折叠组件后就担心被降权。真相是谷歌对写进源码的折叠内容照常计权,会挨罚的只有白字堆词那类伪装。这篇讲清降权迷思的由来、组件懒加载为何让爬虫抓空、以及为什么核心卖点仍不该藏进面板。

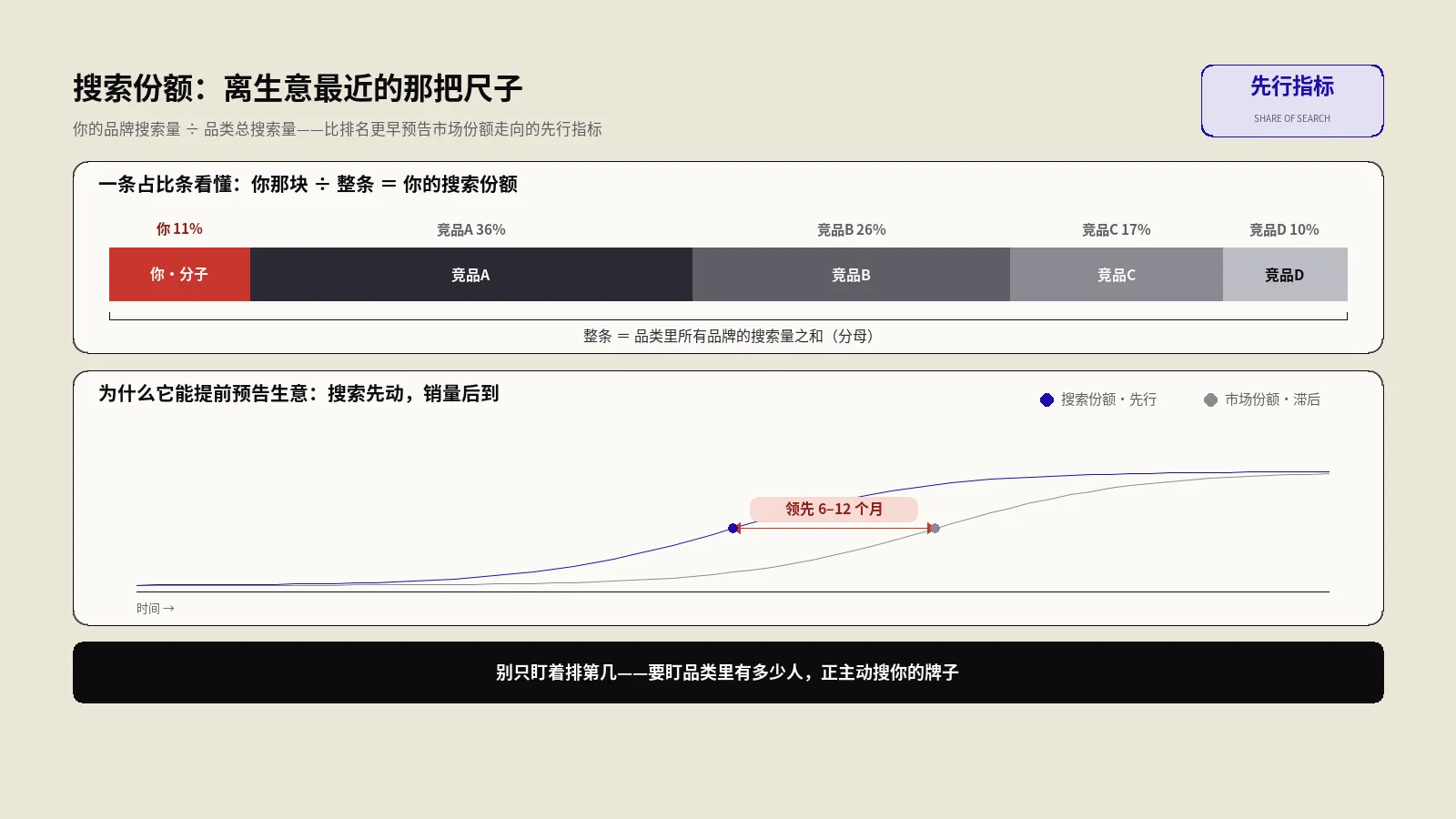
搜索份额(Share of Search)=品牌搜索量÷品类品牌搜索总量,是预测市场份额的先行指标。本文讲清公式怎么列、数据从哪拉、和媒介声量与心智份额的区别、四种实战用法,以及AI搜索时代该补的被模型提及份额。
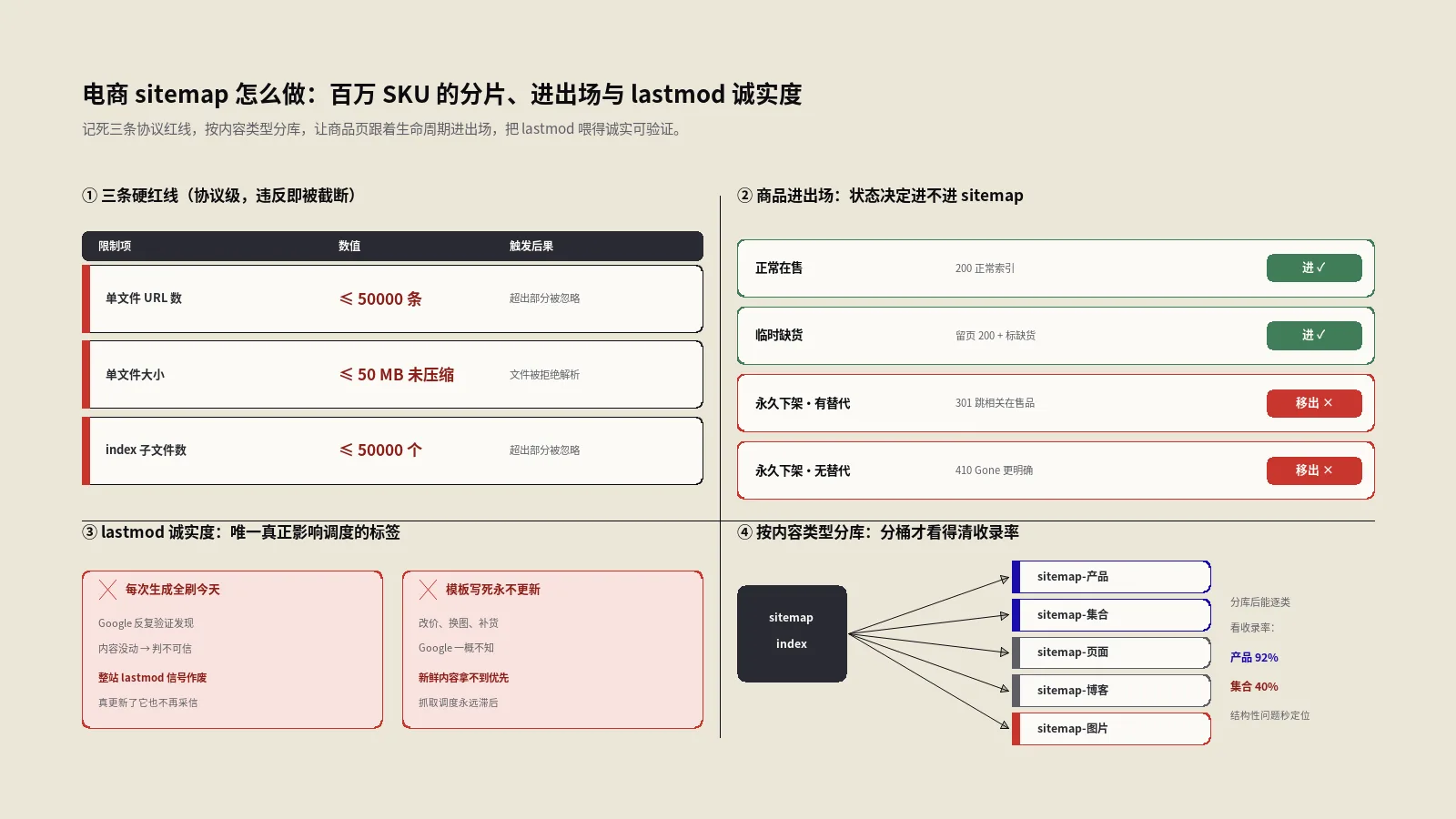
几十万SKU的电商站,sitemap是一座随时塌方重建的城市地图。本文按工程拆解:50000URL三条红线、按内容类型分库、产品页上下架进出场、变体进不进、lastmod诚实度、图片sitemap这条购物通道,最后给一份能直接照着跑的体检清单。
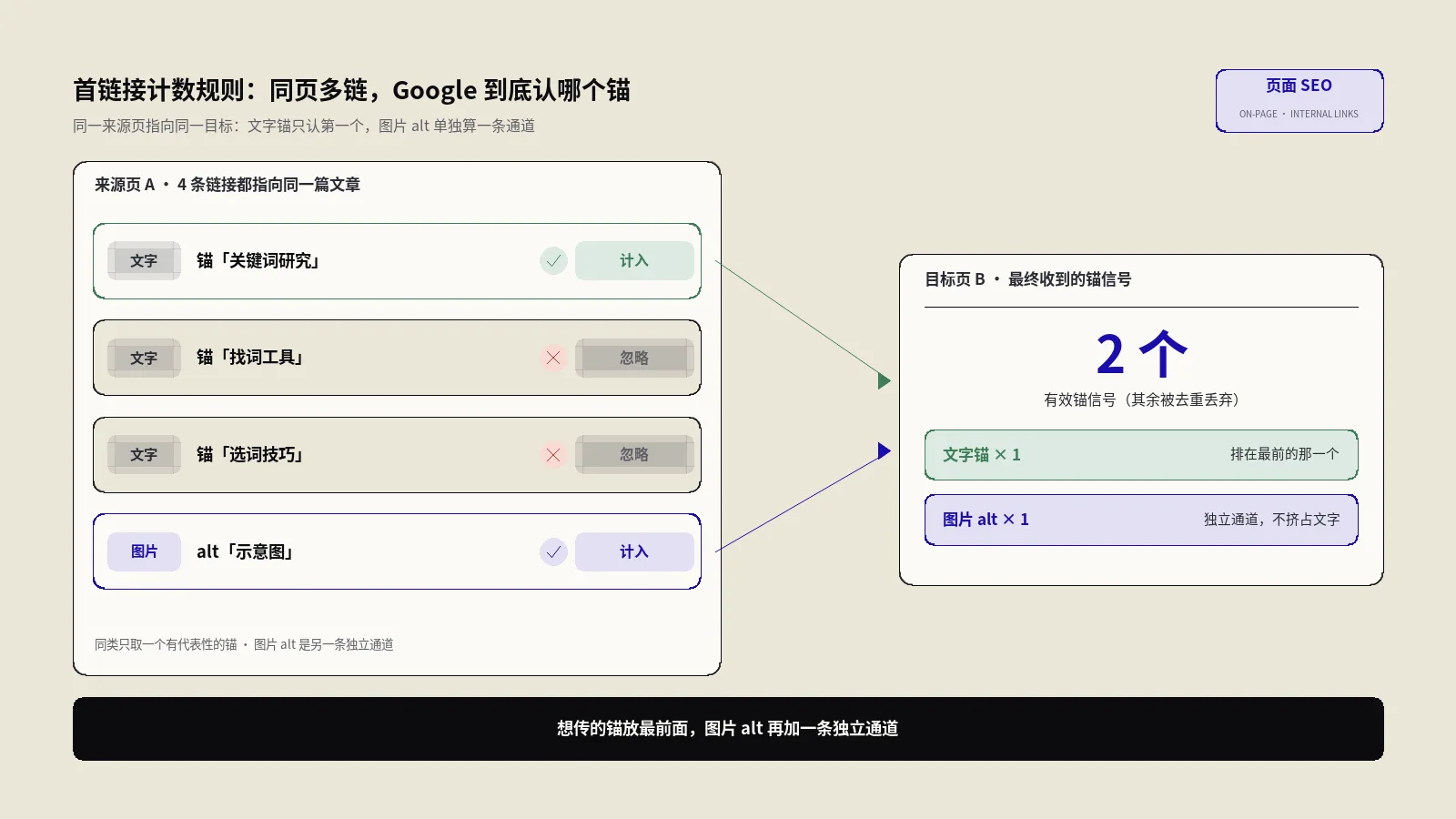
同页多条链接指向同一篇文章,Google只算第一个锚文本?这条2008年传下来的首链接计数规则早已降级。2023年实测证明是“选择性优先”:文字锚只认第一个,图片alt单独算。本文讲清来龙去脉、官方表态,再落到内链排序、图文双通道和反向筒仓三套打法。
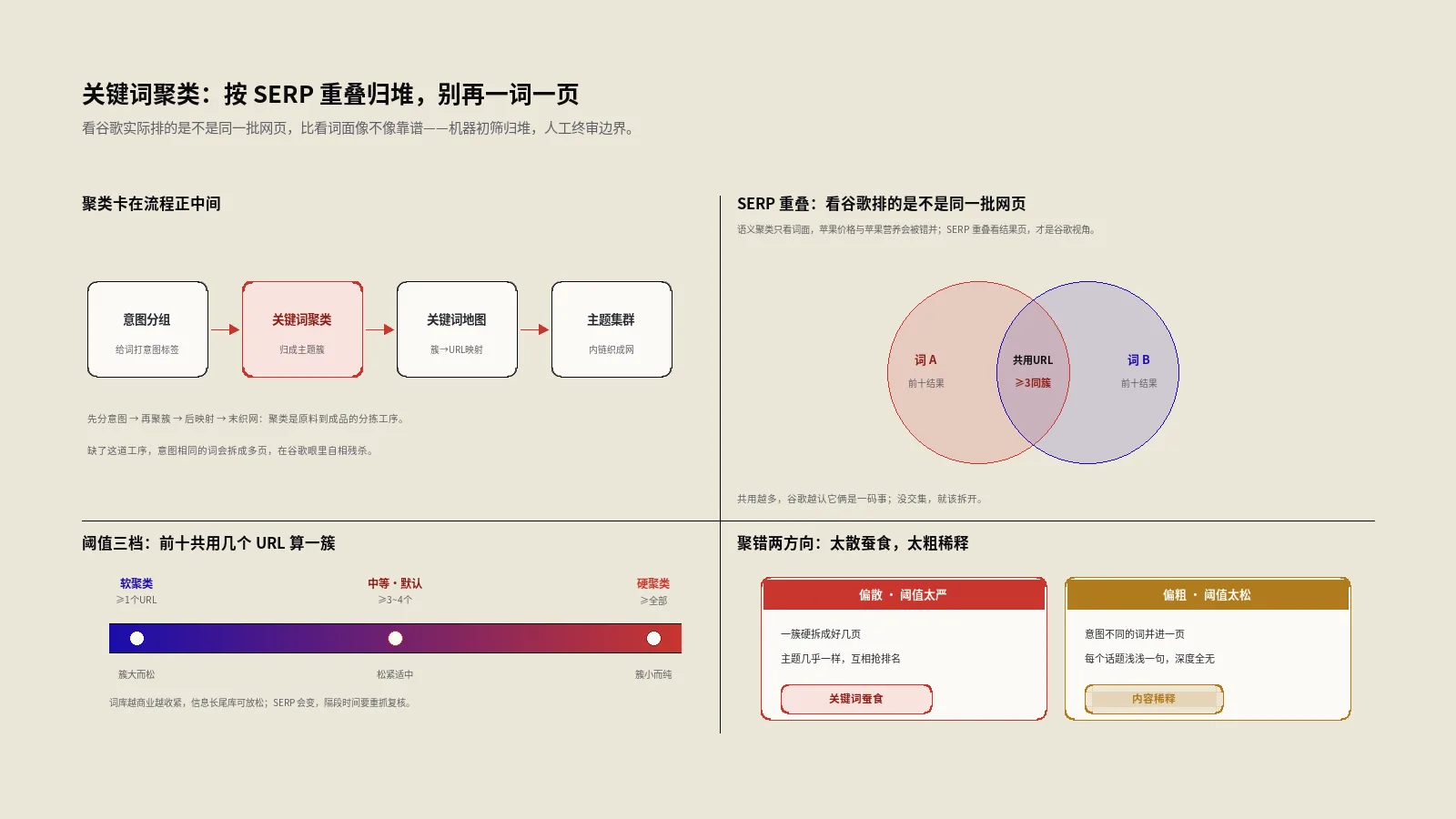
面对关键词工具吐出的成百上千个词,怎么决定哪些放一页、哪些拆开?答案是聚类。本文拆解语义与SERP两种聚法的差异、共同网址阈值的松紧档位、机器初筛加人工终审的五步做法,以及蚕食与稀释两个翻车方向,教你把散词收成能直接开写的作战地图。
电商站几乎天生重复内容成灾,但根子不是被Google罚,而是权重稀释和抓取浪费。本文把产品变体、分面、集合页、分页、参数、样板描述、缺货、跨站这8类电商特有成因画成地图,每类给诊断与治理手法,再配四步诊断工具箱和合并拆分拦截决策树。

出海进新市场第一道技术决策:内容放example.de、子目录还是子域名?本文按显式地理信号、权重归一还是稀释、维护成本三笔账,拆解ccTLD、子目录、子域名的真实取舍,点破GSC国际定位2022年已停用这个被多数教程漏掉的变化,并给一张按出海阶段走的决策树。

它是拼装台不是校验器。六种类型的XML骨架拼得很规整,但地址是不是你自己站的、日期有没有被界面吞掉、条目重不重复,全得你自己盯。哪些页面该进清单更是它管不了的事。

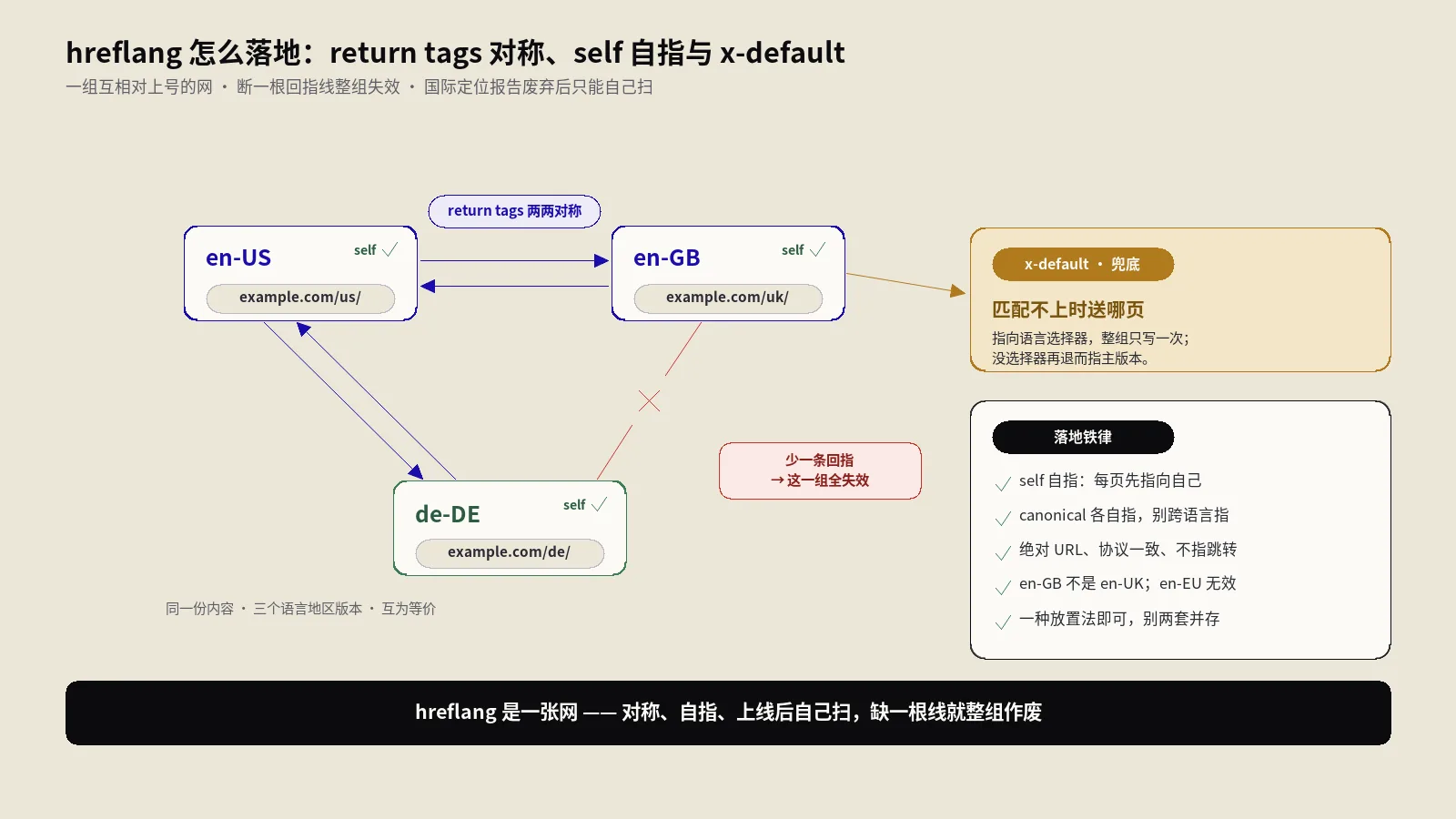
hreflang不是写几行标签就完事,它是一张每个语言版本必须互相对上号的网,断一根线整组失效。本文拆三种放置方式怎么选、return tags对称这个头号死穴、x-default该指哪、en-GB不是en-UK、canonical自指对齐,并给国际定位报告废弃后的自查三层法。
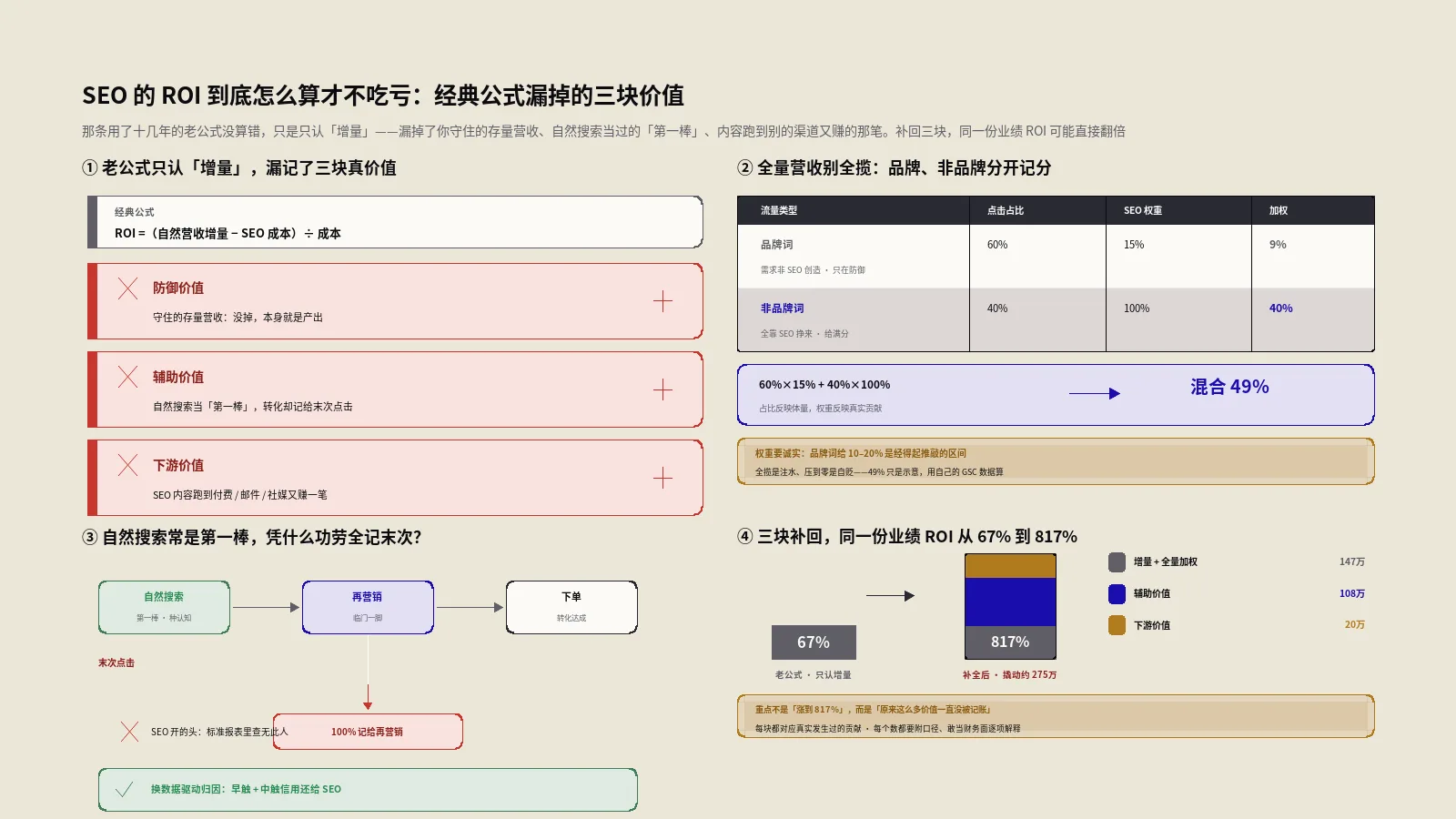
经典SEO ROI公式只算增量营收,系统性低估了SEO。本文给出补全模型的三块价值:防御存量营收、品牌非品牌加权归因与辅助转化首触、SEO内容跨渠道下游收益,附完整算法、对照案例与避免注水的原则。
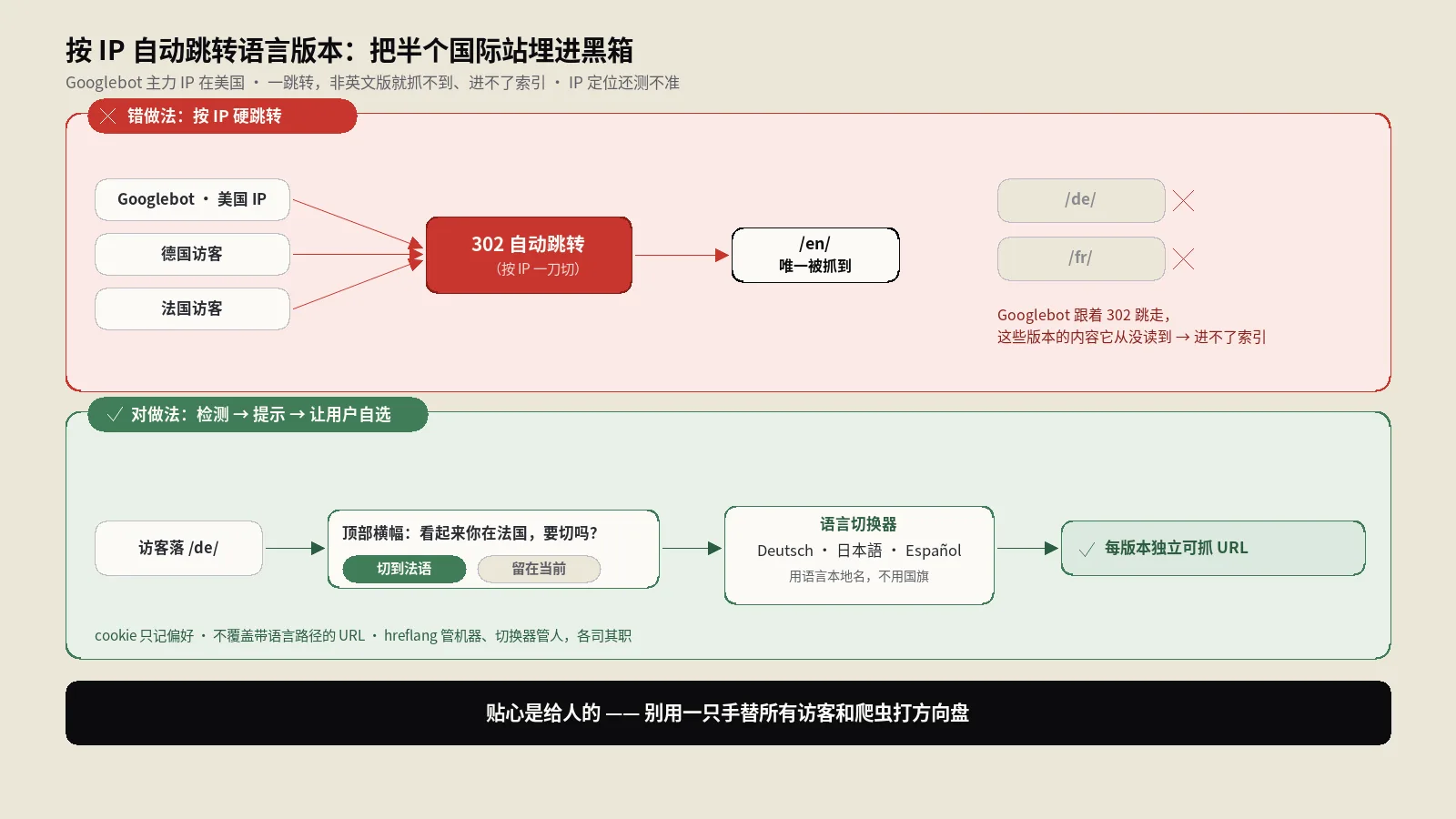
按访客IP自动跳转语言版本看着贴心,实则是把半个国际站埋进黑箱:Googlebot主力IP在美国,一跳转非英文版就抓不到、进不了索引,再叠加IP定位测不准,用户也被锁死在猜错的语言里。这篇拆清地理重定向、hreflang、语言切换器的分工,给一套检测就提示、提示让选择的落地方案。
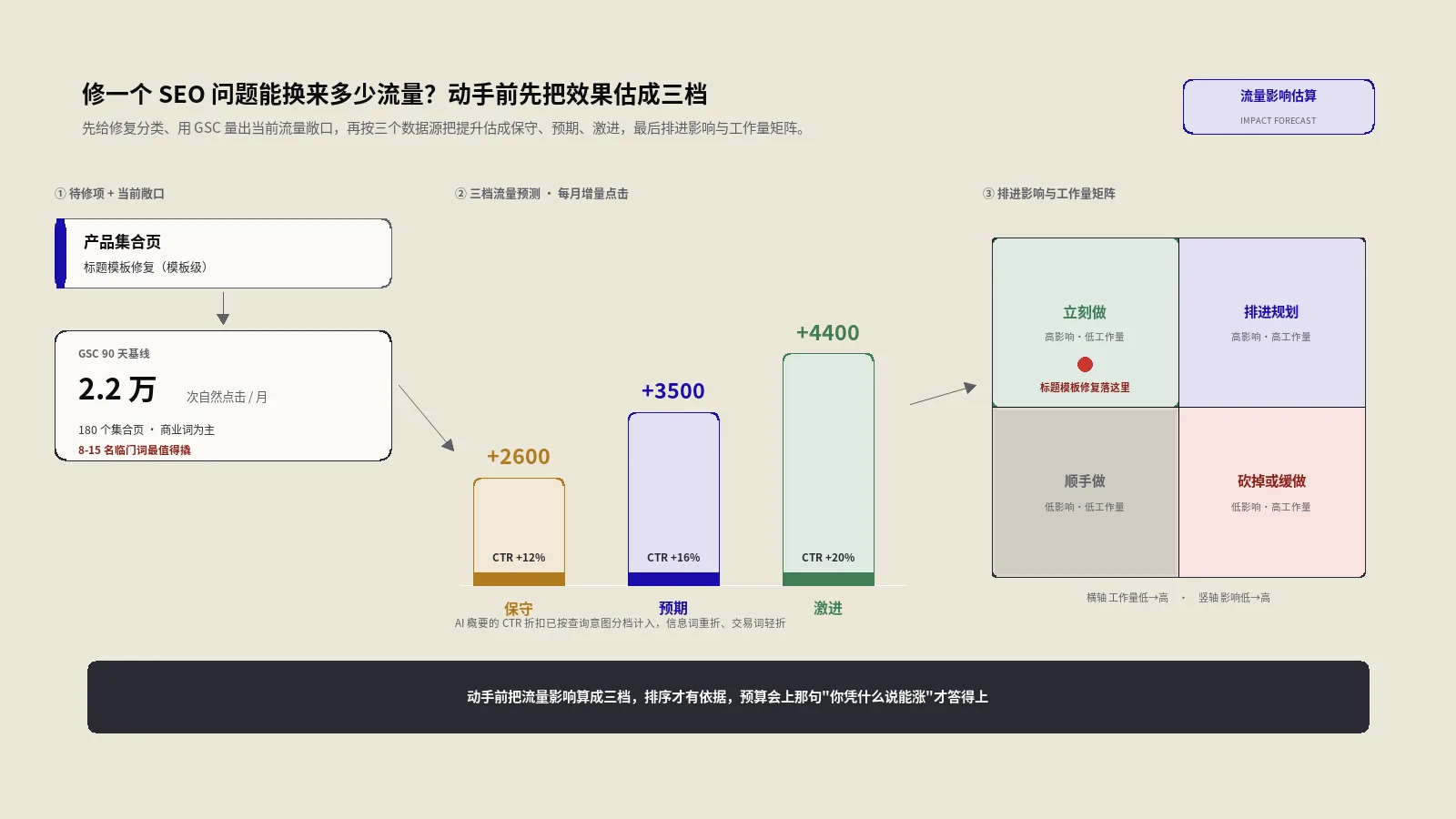
修一个SEO问题到底能换来多少流量,拍脑袋既排不出优先级,也扛不住预算会上的追问。这篇给一套上线前的量化估算法:先按站级、模板级、单页给修复分类,用GSC摸清当前流量敞口,再用历史、竞品和AI时代的CTR假设把效果算成保守、预期、激进三档,最后喂进影响与工作量矩阵排出先修谁。
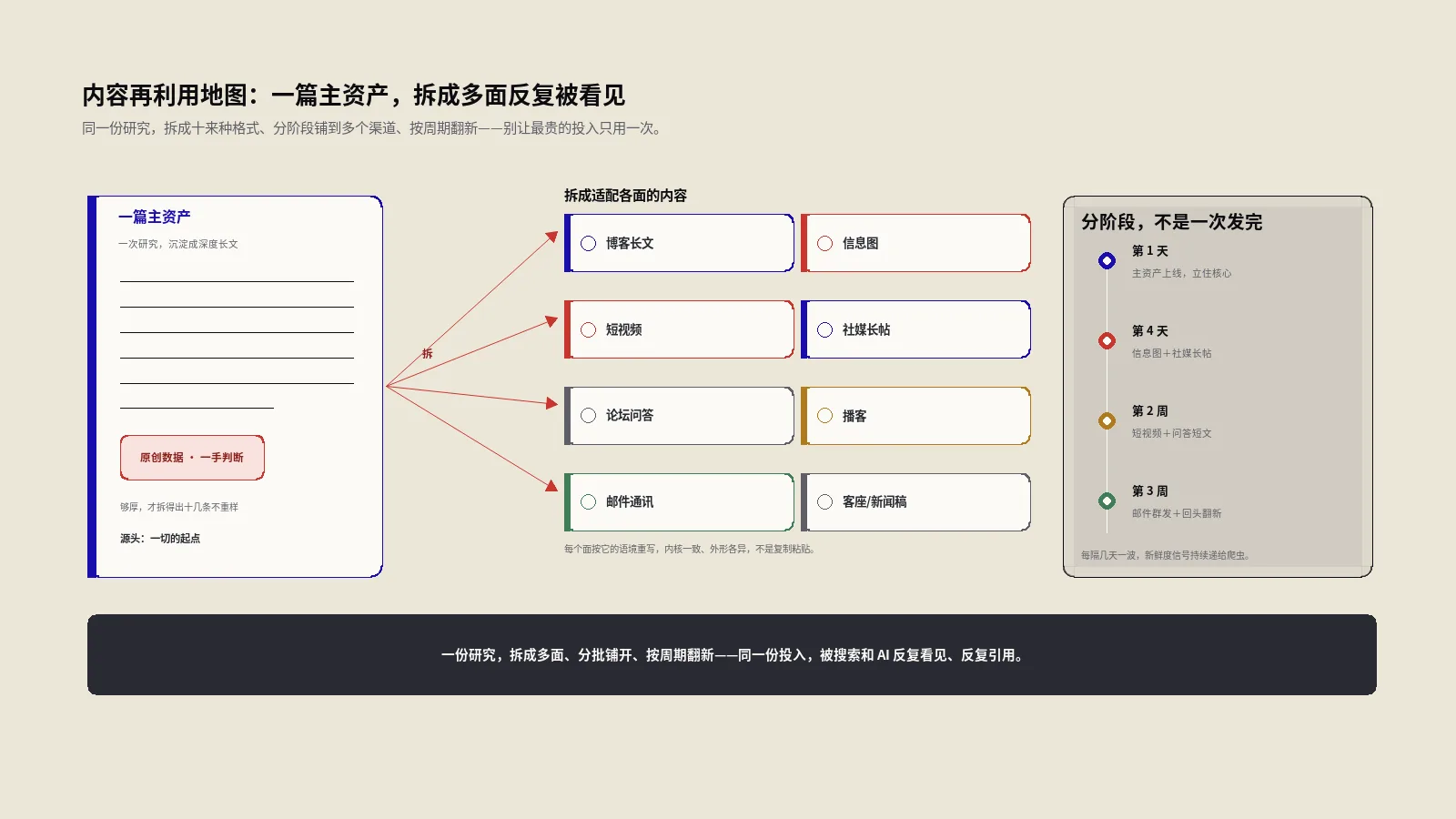
内容发完就不管、流量一路下滑?问题不在写得差,而在没把一份研究反复利用起来。这篇用一张六步生产地图,教你把单篇主资产铺成多格式、多渠道、能持续更新的内容资产。
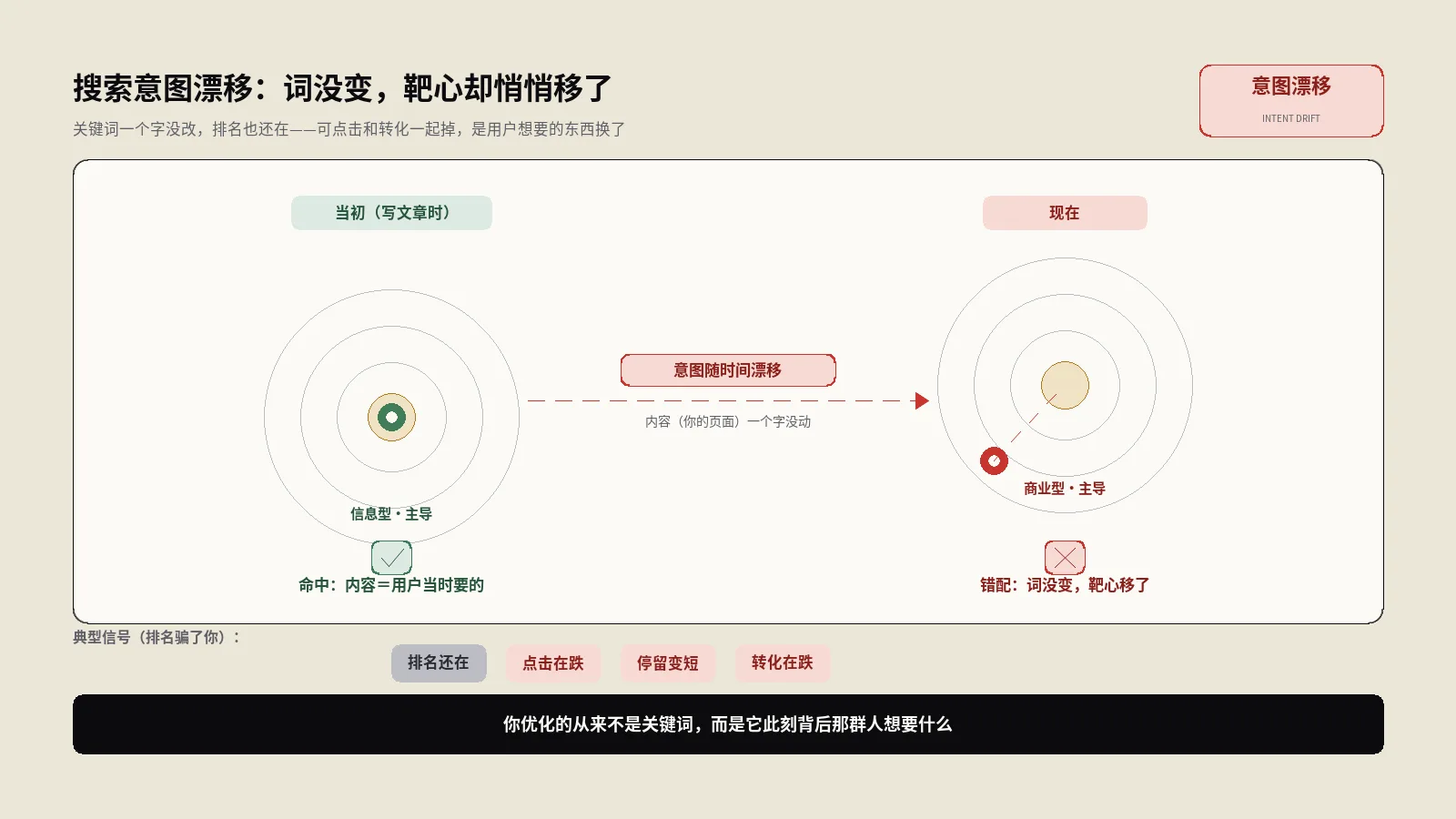
搜索意图漂移指关键词没变、但用户想要的内容类型随时间变了,表现为排名稳却点击和转化下滑。本文讲清它和内容衰退、关键词消失的区别,6个触发源,Ahrefs的7个真实案例,以及监测信号、季度SERP体检和按漂移类型分治的重新对齐打法。
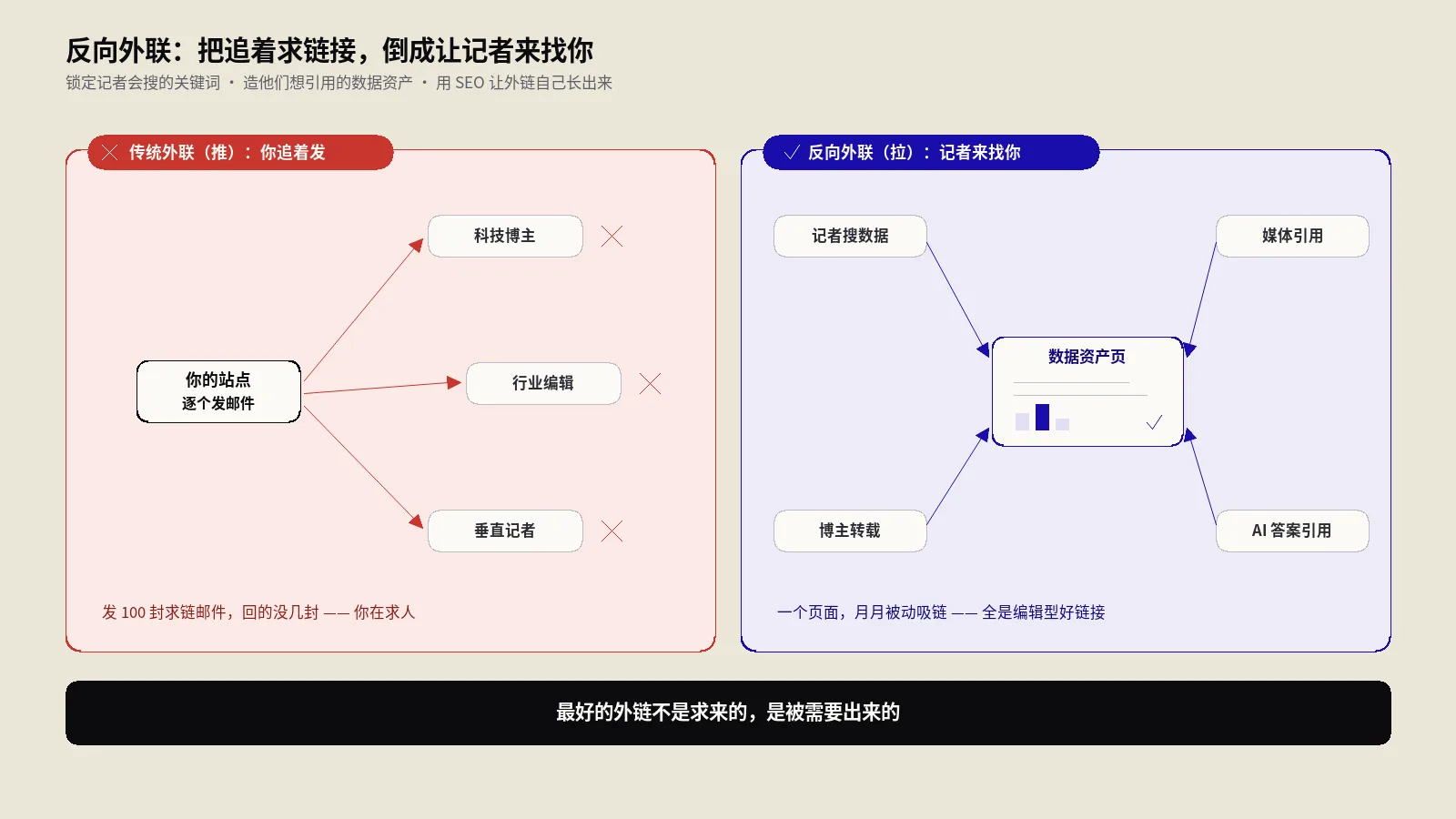
传统外链是你发邮件求人给链接,回复率低到心凉。反向外联把流程倒过来:锁定记者写稿会搜的关键词,造一个他们想引用的数据资产,再用SEO顶到搜索前排,让对方主动链接你。这篇讲清反向外联的底层逻辑、找记者关键词、造可引用资产、snippet bait写法和出海独立站落地。
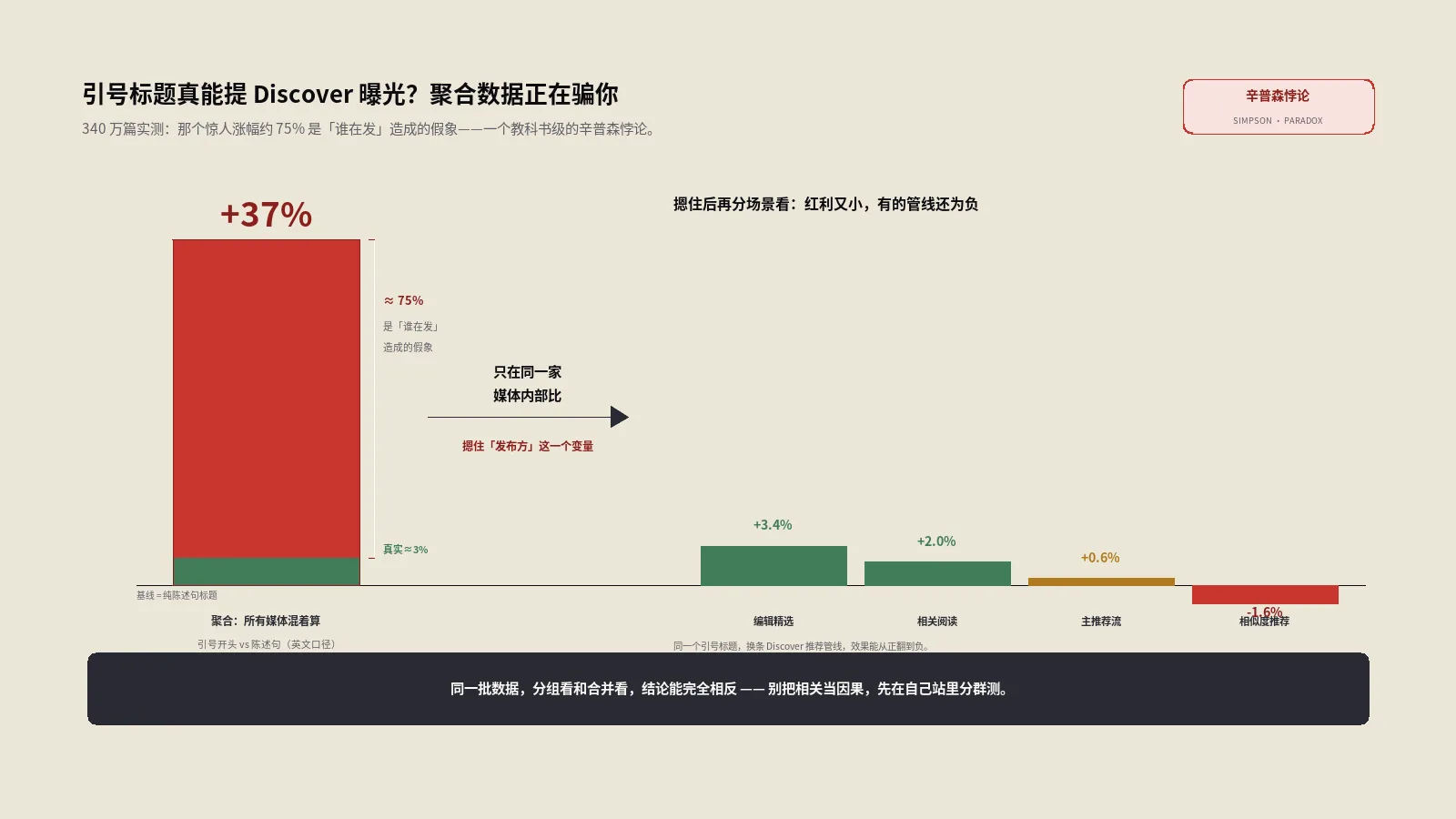
为什么某种标题格式能涨曝光这类结论多半不可信?本文用一份大样本Discover研究做案例,拆解相关与因果的混淆、辛普森悖论如何制造假红利,并给出在自己站上验证标题效果、不被全网平均忽悠的实操步骤。