AI搜索优化建议跨平台失灵:4层架构分歧实测
本文目录
摘要:传统SEO的优化建议能从一家搜索引擎照搬到另一家,是因为各引擎在2006年到2022年之间一起建过共享标准(Sitemaps协议、robots.txt、schema.org、IndexNow)。AI搜索没有这层协作底座:训练语料靠各自买版权、爬虫拆成三套独立用户代理、检索分别接Bing、Vespa、Google索引、Brave Search,对齐方式还分RLHF和Constitutional AI两条路。结果是同一份内容在不同AI平台命运完全不同——一项11.8万条AI响应的分析里,只有11%的被引用域名能跨多个平台出现,另外89%是单平台专属。这篇拆这套分歧的4层架构、用llms.txt和Google自家AI产品的内部割裂当反面教材,再给一份按平台分治的90天落地节奏。
有个做工业密封件出口的客户上个月找过来,手里攥着一份做得挺认真的优化方案,全部围绕ChatGPT展开。逻辑没错:他们的海外采购商确实越来越多在ChatGPT里问“EPDM密封圈耐温范围”这类选型问题,销售把聊天截图一张张发回来。问题是方案落地两个月,他们在Perplexity里搜同样的词,自己的站一次都没被引用过;在Gemini里更惨,连产品页都没进候选池。这位客户的第一反应是“方案做错了”。其实方案没错,错的是他默认“给ChatGPT做的优化,到别家也能用”。
这个默认假设,在传统SEO时代是成立的。给Google做的技术优化,搬到Bing、搬到Yandex,八成都还有效。但在AI搜索里,这个假设是整套打法里最贵的一个错误。要讲清楚为什么,得先回到传统SEO那条建议为什么能“搬”。
传统SEO的优化建议为什么能跨引擎通用?
很多人以为SEO建议能跨引擎,是因为各家引擎的排序算法差不多。这是误解。Google和Bing的排序信号从来都不一样,权重也对不上。真正让建议可以照搬的,不是算法相似,而是各家引擎在二十年里一起搭了一层共享标准——算法可以各算各的,但接收什么输入、认什么协议、对外公示什么规范,是统一的。
这层标准是一块一块拼出来的,时间线很清楚:
- 1994年,robots.txt由一位工程师提出,本来只是个民间约定。到2022年它被正式写成RFC 9309标准,所有主流爬虫都按同一套语法解析。
- 2006年,Google、Yahoo、微软三家一起采纳了Sitemaps协议0.90版。一个站点地图文件,三家都认。
- 2011年,同样是这三家引擎合建了schema.org,给结构化数据定了一套共享词汇表。你标一次Product或者Article,所有引擎读的是同一套字段。
- 2021年,IndexNow出现,Bing、Yandex、Naver、Seznam、Yep都接入了——你推送一次URL,多家引擎同时收到。这里有个细节值得记:Google至今没采纳IndexNow,这其实是后面AI时代“建议搬不动”的早期预兆。
看明白这条线,就懂了:SEO建议能跨引擎,靠的不是“引擎们想得一样”,而是“引擎们在输入端口上谈妥了”。你做一个干净的XML站点地图、写一份规范的robots.txt、标一套schema,这些动作在哪家引擎面前都说得通,因为底层协议是各家联合制定、联合背书的。协作发生在标准层,竞争才发生在算法层。这是传统SEO能有“通用最佳实践”这个概念的全部前提。
举个具体的:你给Google写的XML站点地图,原样提交给Bing站长工具,Bing照单全收,不用改一个字节。你为Google做的结构化数据,Bing、Yandex解析时认的是同一套schema字段。甚至robots.txt里你对Googlebot写的那条规则,换成对Bingbot,语法完全一样。这种“一次做好、多处生效”的体验,是整个SEO行业过去二十年的默认体感——默认到大家几乎忘了,它其实是各家引擎刻意协作换来的,不是天然如此。哪天这层协作没了,体感就会立刻翻车。
而AI搜索时代,恰恰是这层协作底座没有了。
AI平台的优化建议为什么搬不动?
AI平台之间没有一个对应schema.org的东西。没有哪三家大模型坐下来一起定过“AI内容标注协议”,也没有一份被所有LLM认账的爬虫规范。结果是各家的技术栈从底到顶各走各的,分歧不是一两个参数的差别,而是结构性的、分四层叠起来的。
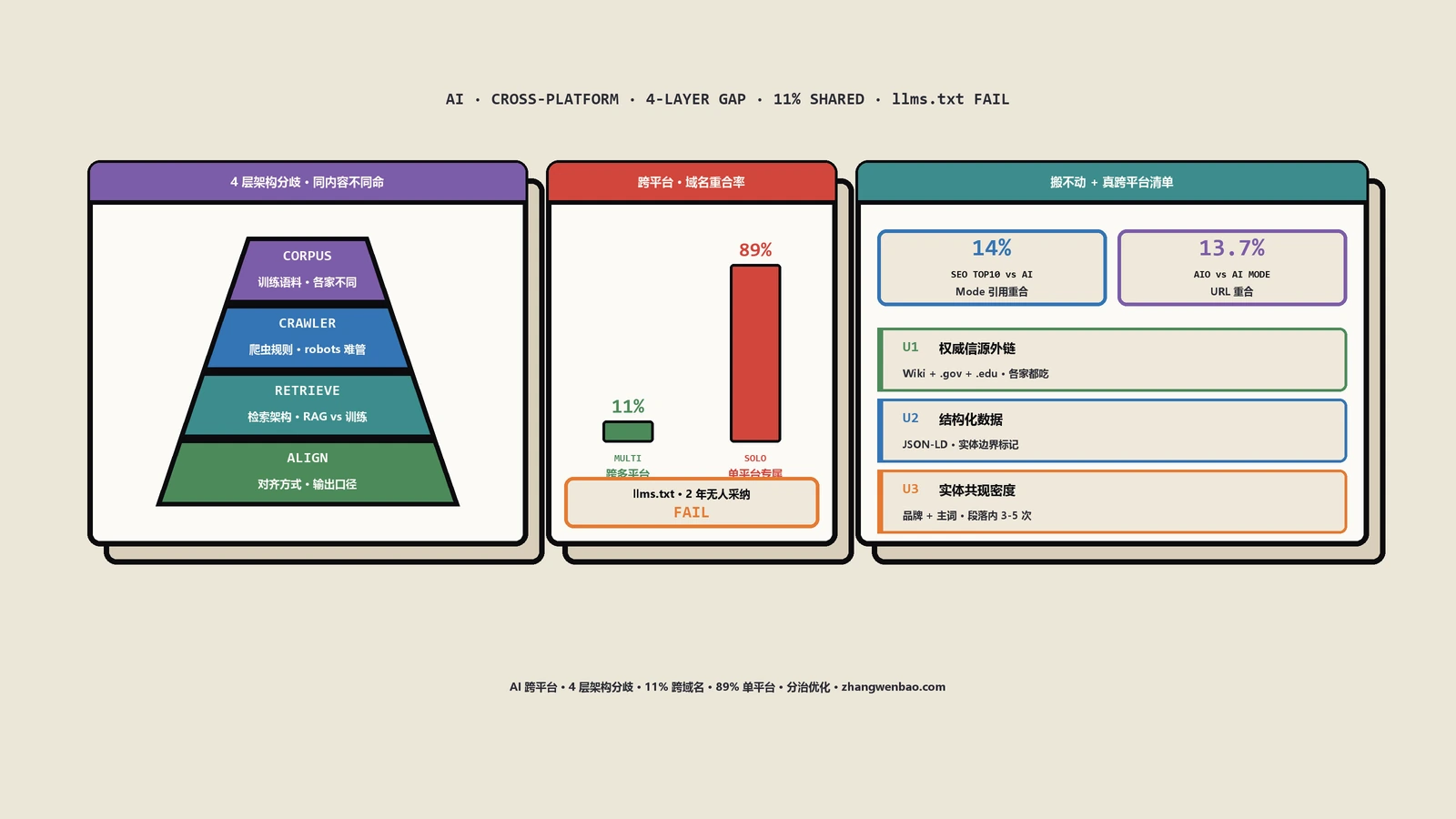
这四层从下往上是:
- 训练语料层:每家模型“读过的书”不是同一批文档。
- 爬虫层:每家用独立的用户代理体系,没有统一的“AI爬虫”这个东西。
- 检索层:回答你问题时,各家去查的索引不是同一个。
- 对齐层:拿到同样的检索结果,各家用不同方法决定怎么措辞、引谁不引谁。
四层里任意一层不同,你的内容在这家平台和那家平台的命运就会分叉。四层全不同,分叉就是常态而不是例外。下面这张表先给个总览,后面四节逐层拆开讲机制——这部分如果想直接对照各家引擎的偏好做调参,可以配合站内那篇三大AI引擎GEO偏好差异实测一起看,那篇是操作手册,这篇讲的是为什么得分开做。
| 分歧层 | 传统SEO的状态 | AI搜索的状态 | 对你的直接影响 |
|---|---|---|---|
| 训练语料 | 引擎不靠“读过什么”排序 | 各家版权采购清单不同 | 同一品牌在各模型里的“先验印象”不同 |
| 爬虫规则 | robots.txt一套语法通用 | 每家三套以上独立用户代理 | 一条规则管不全,漏写就漏抓 |
| 检索来源 | 引擎查自家索引 | 分别接Bing、Vespa、Google、Brave | 在A平台可见不等于B平台可见 |
| 对齐方式 | 无此环节 | RLHF与Constitutional AI两条路 | 同样的检索结果,引用决策不同 |
训练语料各家不一样,对你的内容意味着什么?
大模型回答问题时,并不是每次都现查网页。很多时候它先用训练阶段“记住”的东西垫一层底,再决定要不要去检索补充。所以训练语料里有没有你、怎么描述你,会变成模型对你品牌的“先验印象”。而这批语料,各家根本不是同一份。
差别主要来自版权采购。OpenAI公开披露过的内容授权交易就有一长串:和News Corp的协议价值最高到5年2.5亿美元,和Axel Springer大约每年1300万美元,和Reddit大约每年7000万美元。Google则被报道以大约每年6000万美元拿到Reddit的数据,而且是带实时API的。Anthropic到目前为止没有公开披露过同量级的大型出版商授权交易。
把这些数字翻译成你能用的判断:同一个行业话题,在ChatGPT里模型的底层印象很可能带着News Corp系媒体和Reddit讨论的色彩,在Gemini里带着Reddit实时数据的色彩,在Claude里则更依赖公开网络抓取而不是付费授权内容。这就是为什么同一个品牌问题,三家给的“默认答案”语气和倾向会不一样——不是模型有偏见,是它们读的书不一样。
这个差异有个简单的验证方法,你现在就能做:拿你自己的品牌名,分别去ChatGPT、Gemini、Claude里问同一句“某某这家公司怎么样”。大概率你会看到三段语气、侧重、甚至事实选取都不一样的回答。有的会强调你被哪些媒体报道过,有的会复述社区论坛里的评价,有的则因为训练语料里关于你的信息太少而答得含糊其辞。这不是哪家AI更准或更不准,是它们各自训练语料里关于你的那份“底稿”根本就不是同一份。把这三段回答存下来、每个季度重测一次,本身就是一份几乎零成本的训练语料层监测——它帮你看清,你的品牌在三家模型脑子里的“第一印象”正在往哪个方向漂。
对策不是去猜每家买了什么版权,那是查不全的。对策是认清一个事实:你没法控制训练语料,但你能控制检索阶段能不能被抓到、被抓到的内容够不够干净。所以与其纠结“怎么进训练集”,不如把力气压在后面三层——那三层是你真能动的。
为什么一条robots.txt规则管不住所有AI爬虫?
传统SEO里,你写一行robots.txt,Googlebot、Bingbot、各家爬虫都按同一套规则读。AI时代这条经验直接失效,因为根本不存在“AI爬虫”这一个东西。每家AI公司把抓取任务拆成了好几个独立的用户代理,各管一段:
- OpenAI:GPTBot负责训练抓取,OAI-SearchBot负责给搜索功能建索引,ChatGPT-User负责用户实时提问时的即时拉取。三个代理,三种用途。
- Anthropic:对应的是ClaudeBot、Claude-SearchBot、Claude-User,同样三套。
- Perplexity:PerplexityBot和Perplexity-User两套。
- Google:在2023年9月单独放出了Google-Extended,专门用来控制内容要不要进Gemini的训练,它和负责传统搜索的Googlebot是分开的两个开关。
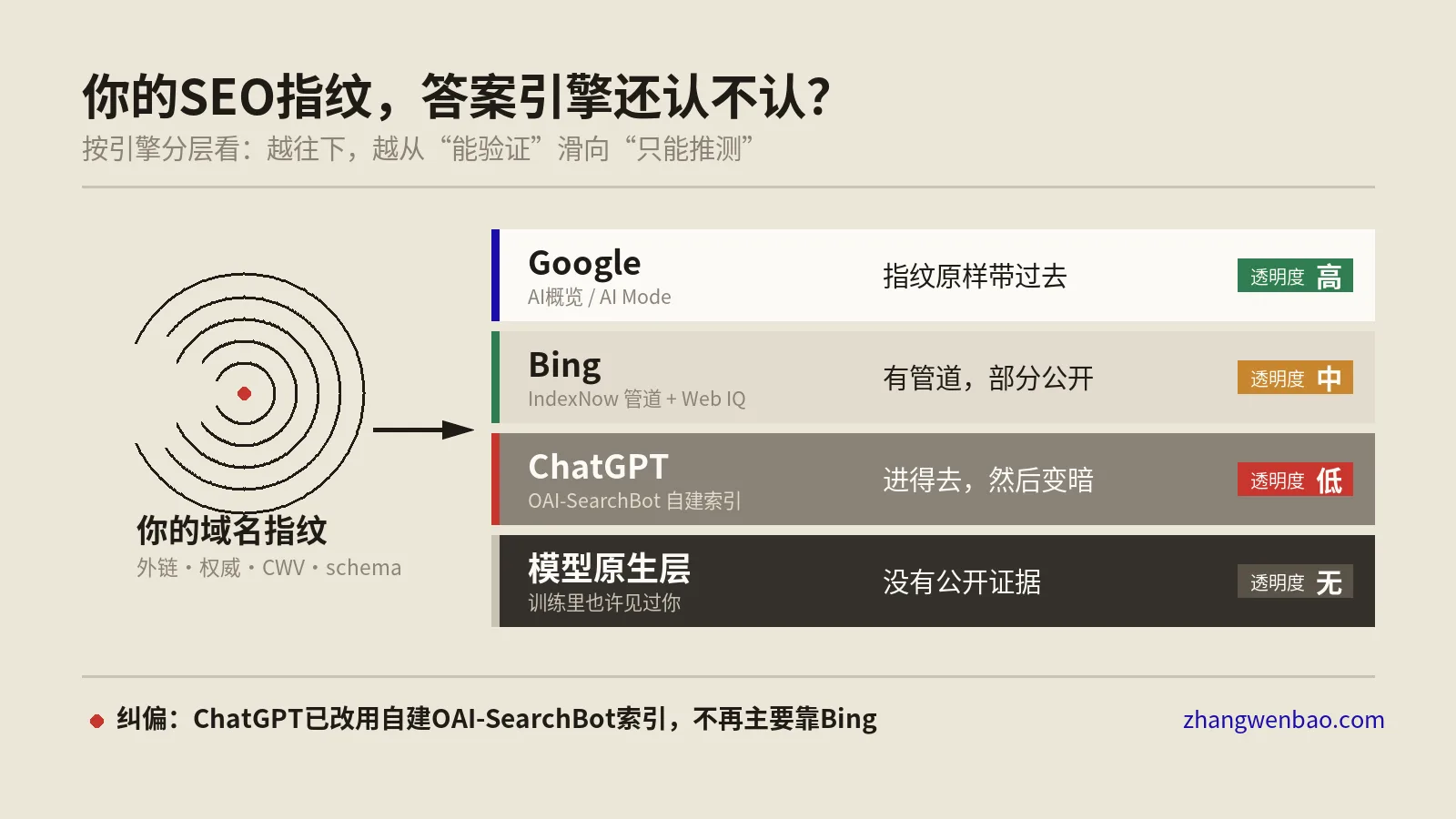
这意味着什么?意味着你robots.txt里如果只写了对GPTBot的规则,那OAI-SearchBot和ChatGPT-User照样按默认行为来——你以为关掉了OpenAI,其实只关掉了三分之一。反过来,你想让内容被某家AI检索引用,却在robots.txt里手滑屏蔽了它的Search代理,那它训练能读到你、回答时却抓不到你的实时页面,引用率直接归零。各家用户代理的命名规则、默认行为都不一样,官方说明散落在各自的文档里,Google这边可以查它的爬虫总览文档逐个核对。
实操上记一条铁律:不要写“AI爬虫规则”,要写“每一个具体用户代理的规则”。把目前在用的十几个代理列成清单,逐行确认是放行、是只放训练不放检索、还是全关。这件事没有捷径,因为没有一条通配规则能替你管全部。
检索架构分歧怎么决定你能不能被引用?
回答你问题的时候,AI去哪儿“查资料”,这一步叫检索。检索接的索引不同,你能不能进候选池就不同。这一层的分歧最直接影响可见性:
- ChatGPT:长期以来主要用微软Bing的索引作为检索来源。所以你的页面在Bing里收录得好不好、排名高不高,会实打实影响ChatGPT能不能找到你。这也解释了为什么有人说“做Bing SEO在AI时代突然又有用了”。
- Perplexity:跑的是基于Vespa的检索流水线,它把文档和文档里的“段落块(chunk)”都当成可被独立检索的单位。换句话说,Perplexity可能不引用你整篇文章,只抽走其中一段。
- Google Gemini:用Google自家的索引,再叠一层知识图谱(Knowledge Graph)做实体校准。
- Claude:检索合作方是Brave Search,这是一个独立于Google和Bing的第三方索引。
四家,四个不同的索引来源。这就是为什么前面那位密封件客户在ChatGPT里能见、在Perplexity里查不到——他的页面在Bing收录情况不错,但Perplexity的Vespa流水线对他那种“整页才说得清一个参数”的内容结构很不友好,段落块切下来语义不完整,进不了候选。同一份内容,检索层一换,命运就翻面。
这里还藏着一个对内容生产者很要紧的提醒:Perplexity那种段落块检索,意味着你的文章可能被“拆开零售”。它不引用你整篇,只抽走最对题的那一段。所以面向这类平台时,每一段都得写得能独立成立——一段话被单独抽出来、脱离上下文,读者也能看懂、也站得住。这和传统SEO“谋篇布局看整体”的思路是有出入的,是检索架构分歧硬逼出来的一条新写作要求。
这里要破一个迷思:很多人以为“被某家AI引用”是内容质量问题。不全是。它首先是个检索可达性问题——你的内容得先出现在那家AI接的那个索引里,质量才有机会被评估。检索层进不去,内容写得再好也是零。关于不同来源的AI引用怎么分平台布局,站内那篇AI引用多平台分发指南给了4大模型的差异化布局思路,可以接着看。
对齐方式不同,会改写同一份内容的命运吗?
会,而且这是最容易被忽略的一层。模型检索到了内容,不等于会引用它、会按你希望的方式措辞。检索完到生成答案之间,还隔着一层“对齐”——决定模型说话的方式、引谁不引谁、对不确定的信息多保守。各家的对齐方法不是同一条路:
OpenAI主要走RLHF,也就是基于人类反馈的强化学习,用大量人工打分把模型“调教”到人类偏好的方向。Anthropic走的是Constitutional AI,给模型一套原则,让它按原则对自己的草稿做自我批评和修改。这两套方法训出来的“性格”不一样:一个更倾向给直接、流畅的答案,一个更倾向在不确定时加限定、标明边界。
结果就是——同一段被检索回来的内容,喂给两个用不同方法对齐的模型,可能产出两个差别很大的回答。一个模型可能直接把你的数据当结论引用,另一个可能因为你没标清楚适用条件而选择不引、或者引用时加一句“据某来源称”。你内容里有没有写清楚“这个数据在什么条件下成立”,在RLHF模型那里可能无所谓,在Constitutional AI模型那里就是被不被引用的分水岭。
所以“给内容加适用边界、加来源、加局限说明”这件事,在不同平台的回报率是不一样的。它在偏保守对齐的模型上回报最高。这也是一条没法跨平台照搬的优化建议。
llms.txt为什么是“建议搬不动”最好的反面教材?
2024年9月,Jeremy Howard提出了llms.txt——一个放在网站根目录的Markdown清单文件,思路是主动告诉LLM“我这站哪些内容重要”。提案一出,SEO圈反应很热,不少站点很快就部署了。两年下来结果怎么样?
到2026年中,没有任何一家主流LLM提供商确认自己在消费这个文件。主流AI爬虫并不会例行去请求你的/llms.txt。Google这边的John Mueller把它类比成早就被废弃的meta keywords标签;Gary Illyes在2025年7月的一次官方活动上明确说过Google不支持llms.txt、也不打算支持。你可以去llms.txt的官方提案页看它的规范,规范本身写得很清楚,问题不在规范。
问题在协作结构。回想前面讲的schema.org——它能成,是因为三家引擎一起建、一起背书,提出来就有人认。llms.txt是一位研究者单方面提出的,再被它本想服务的那些平台集体忽略。它不是技术上不好,是它走了和schema.org相反的路径:没有跨平台的联合制定,就没有跨平台的采纳。
这就是为什么llms.txt是最好的反面教材。它用两年时间、用整个行业的部署成本,演示了一件事:在AI搜索时代,任何“一家提出、指望大家都用”的优化建议,默认结局是搬不动。所以你看到一个新的AI优化技巧,第一个该问的不是“它有没有用”,而是“它是哪家认的,别家认不认”。站内那篇llms.txt到底有没有用的90天实测记了具体的实验数据,想看一手结论可以去翻。
连Google自己内部,优化路径都不统一了?
如果说不同公司之间的分歧还能理解,那下面这个现象就有点反直觉了:分歧已经发生在Google一家公司内部。
先看一组数字。2024年底,AI Overviews引用的来源里,大约75%能在Google传统搜索的前12名里找到——也就是说,那时候“做好传统排名”基本能换来“被AI引用”。但2026年初Gemini 3升级之后,这个比例塌了:一项Ahrefs的分析显示只剩38%的引用出现在前10名,BrightEdge报的数字更低到17%,SE Ranking则发现大约42%的被引域名被整个换掉了。
再看Google自家两个AI产品之间的割裂。Google同时有AI Overviews和AI Mode两个东西。它们给出的结论在86%的情况下语义相近——但引用的具体URL只有13.7%是同一个。还有一个数字:AI Mode引用的来源里,只有14%能排进传统搜索的前10名。
为什么连一家公司内部都统一不了?因为AI Overviews和AI Mode虽然同属Google,却是为不同场景、用不同管线搭起来的两个产品。它们各自的检索召回、各自的重排逻辑、各自的引用策略,都是独立迭代的,谁也不等谁。它们没有义务、技术上也没有动力时刻保持一致。一家公司、一个团队群、共享同一套基础设施,尚且做不到两个AI产品引用同一批来源——你就能体会“跨公司通用”是个什么量级的难题了。它要求的不是默契,是工程层面的刻意对齐,而眼下没有任何一方有动力去做这件吃力不讨好的对齐。
把这几个数字连起来看,结论是一个“倒置”:Google公开的那套SEO指南,现在仍然是冲进Google传统搜索结果的最干净路径——但传统排名已经不再是“被Google自家AI引用”的可靠代理指标了。你照着Google官方文档把传统排名做到位,进得了蓝链结果,却进不了同一个公司的AI答案框。一家公司、两套逻辑、两条优化路径。连Google都没法给你一套“内部通用”的建议,跨公司的“通用最佳实践”就更是幻觉。
哪些“看起来通用”的AI优化建议其实是陷阱?
分歧讲到这里,有必要专门点几个最容易被当成“通用”的优化建议——它们听着像放之四海皆准,实际一搬就废。识别这些“伪通用”建议,比记住任何一条具体技巧都重要。
陷阱一:把结构化数据标到极致,所有AI都买账。schema这套结构化标记在传统搜索里是稳赚的,因为前面说过它有跨引擎的共享词汇表。但到了AI检索环节,各家对schema的依赖天差地别——有的检索流程会读取schema辅助理解实体,有的几乎只看正文文本、把schema当噪声直接跳过。你花大力气把全站schema标到满分,可能在某家AI那里颗粒无收。schema该标还得标,它对传统搜索和实体识别仍有价值,但别指望它是一把能开所有AI平台门的万能钥匙。
陷阱二:被一家AI引用了,说明内容质量过关,别家迟早也会引。这是最普遍的误判。被引用,是“检索可达、质量达标、对齐认可”三件事同时发生的结果,而前两件在每个平台都不一样。一篇内容在ChatGPT被引,只证明它过了Bing检索这一关、过了RLHF对齐那一关。换到Perplexity,它要重新过的是Vespa段落块检索这道全新的考试——一道它可能根本没复习过的考试。引用不是内容质量的盖章证书,它只是“某一条特定链路全程跑通”的回执,回执不能跨链路通兑。
陷阱三:盯住一个主平台做透就够了,其余都是长尾、可以先不管。在传统SEO里这个判断有时成立,因为Google一家独大,做透它约等于覆盖大盘。但AI搜索的用户分布远没有这么集中,而且前面那个11%的数字已经把话说死了:主平台做到极致,成果里也有89%搬不到别家。你把九成资源压在一个平台,换来的不是“覆盖了大盘”,而是“在一个平台很强、在其余平台彻底隐形”。在AI搜索流量越来越分散的趋势下,这是个会一年比一年更贵的赌注。
这三个陷阱有个共同点:它们都是把传统SEO时代成立的经验,未经检验就平移到了AI搜索。判断一条AI优化建议靠不靠谱,先问一句——这条建议背后假设的那个“通用前提”,在AI时代还存在吗?多数时候,冷静查下去,答案是不存在了。
那到底还有什么东西是真能跨平台通用的?
讲到这儿不能只拆不立。确实有一小撮东西是跨平台通用的,把它们认清楚很重要——但更重要的是看清这个集合有多小。
真正能跨平台通用的,大概是这几条:爬虫得能访问到你的内容,这是所有系统的共同前提;一手的、原始事实型的内容,比二手聚合的内容在各家都更容易拿到引用;干净、可被切块检索的结构,对所有检索系统都友好;以及在高权威站点(维基百科、YouTube、Reddit、主流新闻)上有存在感,这条在各家都像个“放大器”。
但别高估这个集合。有一项覆盖11.8万条AI响应、横跨ChatGPT、Perplexity、Google AI Mode和Claude四个平台的分析,结论很扎心:只有11%的被引用域名能在多个平台上同时出现,另外89%是单平台专属的。换句话说,你做对了那一小撮通用的事,最多也就拿到11%的“跨平台保底”。剩下89%的可见性,是必须一个平台一个平台单独去挣的。
把这一小撮通用动作落成一份能打勾的清单,很有必要:爬虫能不能访问到正文(不被JS挡、不被权限墙挡)、关键页面是不是一手原始信息而非二手拼凑、每个核心事实能不能被切成自包含的语义块、品牌在维基百科和高权威站上有没有起码的存在感。这四条打勾打满,你就拿到了那11%的入场券。它不华丽,但它是整个地基里唯一不用返工、做一次各家都认的部分——值得第一个做、第一个做扎实。
所以正确的心态是:把分歧当默认,把重叠当例外。那一小撮通用动作是地基,地基必须打,但打完地基不等于盖好楼。每多覆盖一个AI平台,都是一份独立的、搬不动的工作量。这不是坏消息,是把预期摆正——预期摆正了,才不会像那位密封件客户一样,做完一个平台就以为大功告成。
跨平台优化的90天落地节奏怎么排?
认清分歧之后,落地就不能再是“做一套优化方案”,而是“按平台分治”。给一份90天的节奏,分四个阶段,可以直接抄进排期表。
第一阶段(第1到2周):建平台分治矩阵。横轴列出你要覆盖的AI平台(至少ChatGPT、Perplexity、Gemini、Claude四列),纵轴列四层分歧(爬虫规则、检索来源、内容结构偏好、对齐特征)。先把每个格子填上“现状”,空着的格子就是你的盲区。这一步不写优化动作,只做体检。
第二阶段(第3到6周):先做通用地基。把前一节讲的那一小撮通用动作全部做掉——爬虫可达性自查、robots.txt按每个具体用户代理逐行重写、一手内容比例提上去、关键页面的检索可切块结构整理好。这一阶段的产出是那11%的跨平台保底,性价比最高,先吃掉。
第三阶段(第7到11周):按平台单独攻坚。这是工作量最大的一段。每个平台单独排一个小迭代:ChatGPT这条线重点盯Bing收录与排名;Perplexity这条线重点改内容的段落块自包含程度;Gemini这条线重点做实体信号和知识图谱对得上;Claude这条线重点补适用边界和来源标注。四条线并行,但各做各的,不要指望一条线的成果自动惠及另一条。
第四阶段(第12周起,转常态):建分平台监测。每个平台单独测可见性,不要用一个总分。监测频率上,AI平台的检索行为变动比传统搜索快得多——Gemini 3那次升级一夜之间换掉42%的引用域名就是例子,所以监测周期建议比传统SEO的月度排查更密。一旦某个平台的引用率掉了,先排查是不是那个平台的检索架构改了,而不是先怀疑内容质量。
监测这一步还值得再建一样东西:一份“分歧事件日志”。每次发现某个AI平台的行为变了——引用域名大换血、对内容结构的偏好变了、又冒出一个新的用户代理——就记一条,写清日期、哪个平台、观察到的具体变化、你做了什么应对、效果如何。这份日志攒上半年,你手里就有了一份别人没有的资产:它让你下一次遇到流量波动时,能在几分钟内判断出“这是那个平台又改了规则”还是“我自己的内容真出了问题”。在一个分歧是常态、变动是高频的环境里,这种快速归因的判断力,本身就是一道别人短期内追不上的壁垒。
这套节奏的核心就一句话:地基一起打,楼一栋一栋盖。那位密封件客户后来按这个矩阵重做,第二阶段补完通用地基后Perplexity终于开始零星引用,第三阶段单独为Perplexity改了产品页的参数呈现结构——把原来“整页才说清一个参数”改成每个参数一个自包含小段——之后两个月Perplexity的引用从0爬到每月稳定二十多次。不算惊艳,但这是单平台单独挣来的,搬不动,也丢不掉。
常见问题解答
给ChatGPT做的AI优化,能直接用到Gemini上吗?
基本不能直接照搬。只有“爬虫可达、内容干净一手、结构可切块”这一小撮通用动作能共享,覆盖面大约只占跨平台可见性的11%。剩下的检索来源、内容结构偏好都得按平台单独做。
为什么AI搜索没有一个像schema.org那样的统一标准?
因为schema.org是三家引擎联合制定、联合背书才成的。AI平台之间至今没有这种跨公司协作,谁也没动力把自家技术栈对齐别家,所以缺一层统一标准底座。
llms.txt到底要不要部署?
到2026年中没有任何主流LLM确认消费这个文件,部署它对AI可见性几乎没有实测回报。它最大的价值是当反面教材:单方面提出、没有跨平台采纳的建议默认搬不动。
做好Google传统SEO,是不是就能被Google的AI引用?
不再可靠了。Gemini 3升级后,传统排名前10与AI引用的重合度大幅下降,AI Mode引用里只有14%来自传统前10。传统排名现在只是“进蓝链结果”的代理,不是“被AI引用”的代理。
robots.txt里写一条规则能管住所有AI爬虫吗?
管不住。不存在统一的“AI爬虫”,每家AI公司把抓取拆成训练、检索、即时拉取等三套以上独立用户代理。必须把在用的每个具体代理列清单,逐行确认放行还是屏蔽。
跨平台优化的工作量到底比传统SEO大多少?
粗算是“通用地基一份,加上每个平台一份独立攻坚”。覆盖四个主流AI平台,大致相当于在传统SEO之上再叠四份各不相同、互不复用的优化工作量。
权威参考资料
本文标题:《AI搜索优化建议跨平台失灵:4层架构分歧实测》
本文链接:https://zhangwenbao.com/ai-optimization-advice-not-portable-cross-platform.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0