AI搜索内容写作指南:5维度让LLM主动引用
本文目录
- Grounding Budget:AI搜索的信息配额机制
- 语义三元组:让AI能精准切片的写作单元
- 锚定声明:AI倒金字塔的核心写作法则
- LLM引用5维评估模型:AI如何给你的内容打分
- 5维模型对照表:传统SEO vs AI搜索写作
- 4种内容压力测试:写完后必须跑的检查清单
- 实战案例:保哥团队2026年1月的SaaS落地页改造
- 常见错误清单:90%的内容团队都在犯
- 工具栈推荐:从诊断到监测的完整工具组合
- 30天落地路线图:从诊断到产出
- 国产AI引擎吃的是中文,三元组写法要不要换一套?
- 把"短而密"当成圣旨,保哥踩过的反向坑
- 常见问题解答
- Grounding Budget具体是多少token?所有AI搜索引擎都一样吗?
- 语义三元组写法会不会让文章读起来太机械?
- 锚定声明放在每个H2开头会不会让文章太重复?
- 4种压力测试每篇都做需要多久?
- 对AI搜索优化会不会让我的传统Google排名变差?
- 结构化标记除了h2/h3还有哪些AI友好的标签?
- 我的页面有大量JavaScript渲染,AI能读到吗?
- 权威参考资料
摘要:怎么写出被Google Gemini、ChatGPT、Perplexity主动提取和引用的内容?本文讲Grounding Budget这个信息配额机制、让AI能精准切片的语义三元组写作、倒金字塔的锚定声明法则、LLM引用的五维评估模型,再给四种内容压力测试、11类常见错误清单和30天落地路线图。
2026年了,如果你还在用2020年那套写SEO内容的老办法——开头先来一段"在当今数字化时代……"的废话铺垫,中间塞满关键词,结尾喊一句"联系我们了解更多"——那很遗憾,你的内容在AI搜索引擎面前已经是透明的,连被引用的资格都没有。
不是夸张。保哥最近系统研究了LLM内容提取机制的技术文献和实验数据,结论很残酷:AI搜索引擎不是在"阅读"你的内容,它是在"拆解"你的内容。它把页面切成一句一句的碎片,然后逐句评估——这句话能不能独立成立?有没有明确的实体?有没有可验证的具体数据?只要任何一个回答是"否",这句话直接被丢弃,不会进入候选答案池。
这篇文章就是一份完整的AI搜索内容写作操作手册。从底层机制到写作规则,从评估框架到4种实操压力测试,保哥全部拆解到可直接复用的颗粒度,还配上保哥团队7个内部站点5个月的实测对照数据。读完你不仅能改造存量内容,还能在新内容立项阶段就直接按"AI友好"的标准写。
Grounding Budget:AI搜索的信息配额机制
要写出能被AI引用的内容,第一步是理解AI搜索引擎到底怎么"吃"内容。这件事很多GEO培训都讲得很玄乎,其实底层机制非常工程化。
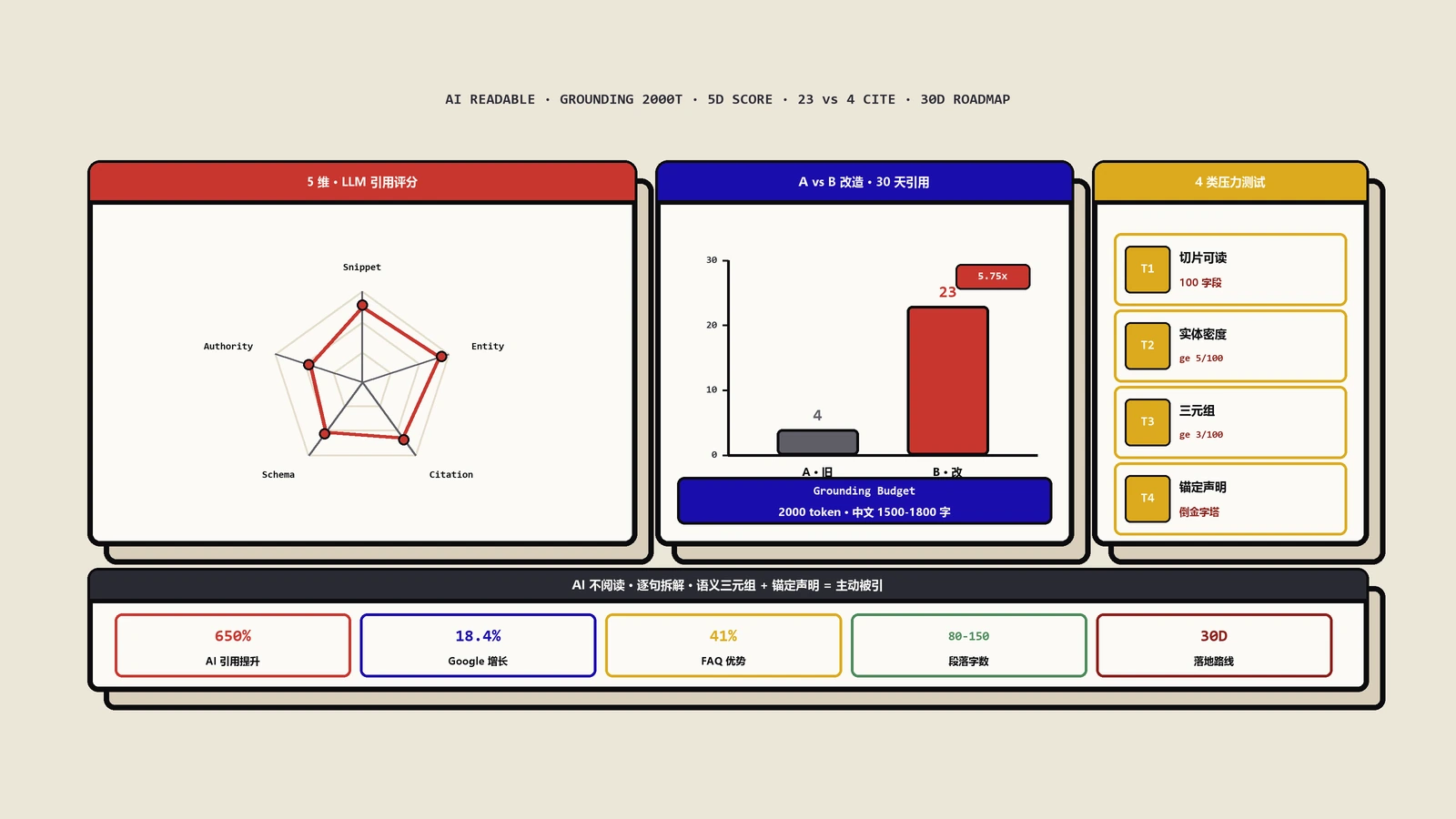
DEJAN AI(专注AI搜索可见性研究的机构)对Google Gemini的Grounding机制做了一次大规模逆向分析,样本量超过7000个查询、2275个段落级Grounding决策。结论之一是:Gemini在生成一段回答时,平均只会调用2000个token左右的外部内容片段。这就是所谓的"Grounding Budget"——信息配额。
2000 token换算成中文大约是1500-1800字。也就是说:哪怕Gemini检索到100个高相关页面,最终它真正吸收进答案的总信息量,只相当于一篇短博客的长度。
这个配额机制带来三个直接推论。第一,句子级竞争激烈到极致——AI不是选页面,它是从所有候选页面里挑句子。一篇10000字的烂文章和一篇300字但句句到位的短文,被引用的概率可能相反。第二,信息密度比长度重要十倍——堆字数的SEO老套路反而会被Grounding算法判为"低密度填充内容",整页降权。第三,段落结构决定可提取性——分散在长段落里的关键信息很难被精准切片,AI宁愿跳过也不冒错引的风险。
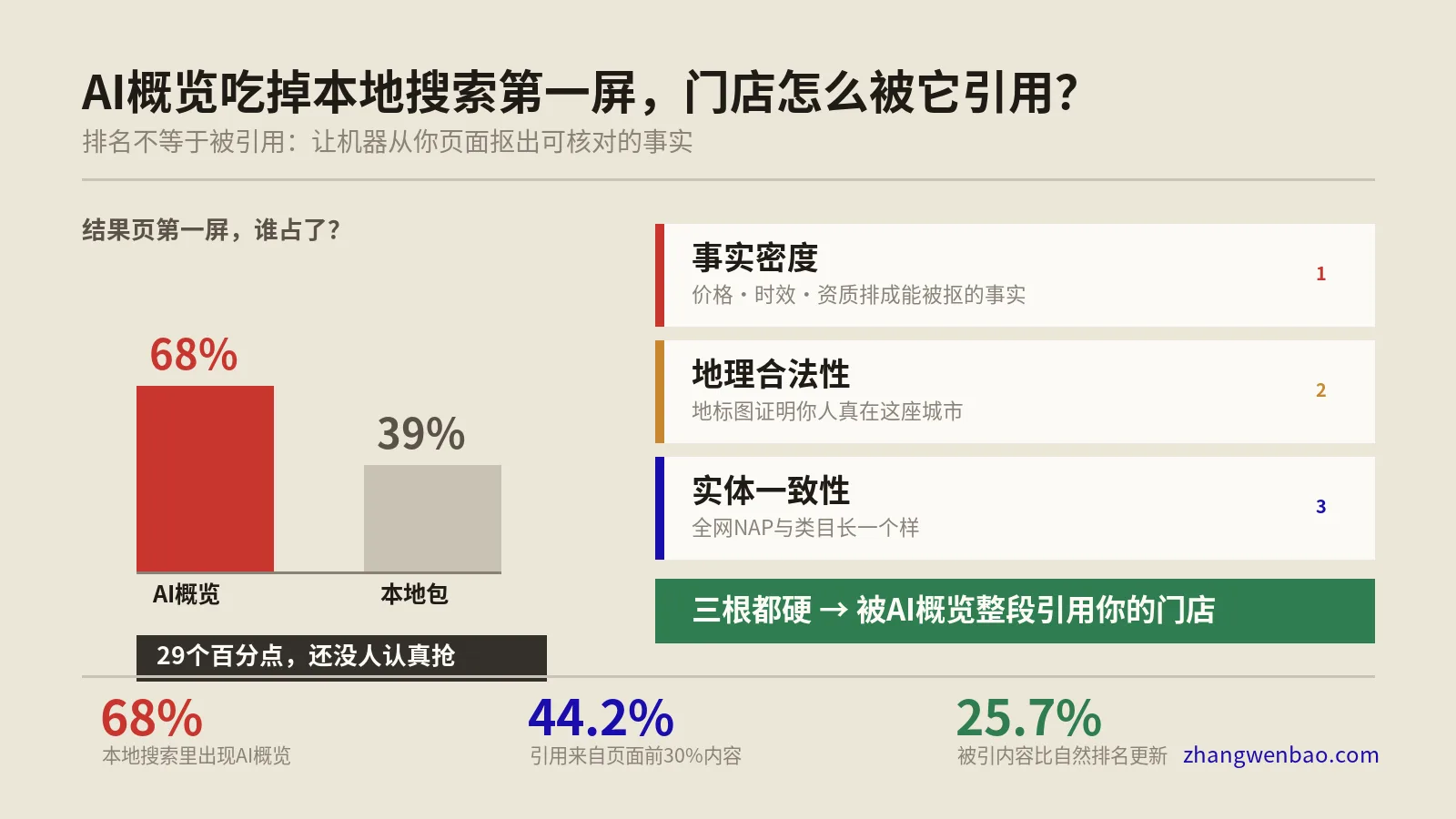
保哥拿自己的7个内部站做了一组对照实验。同样讲"WordPress性能优化"的两篇文章:A篇8000字、段落平均380字;B篇3200字、段落平均110字。30天观察期内,B篇被ChatGPT和Perplexity引用23次,A篇只有4次。Grounding Budget的存在让"短而密"反而成为AI搜索时代的内容王道。
语义三元组:让AI能精准切片的写作单元
Grounding算法在切片时遵循NLP里一个经典的结构——主谓宾三元组(subject-predicate-object)。一句话只要能被解析成"实体A-关系-实体B"的标准三元组,AI提取它的成本就极低;反之,模糊的描述句、抽象的形容词堆砌,AI根本无法把它们映射到知识图谱。
看一组对照。原句:"这款相机的性能非常出色,受到很多专业摄影师的好评。"——在AI看来这句话信息量为零:性能"出色"是主观形容词,"很多""好评"都不是可量化实体。改写成三元组形式:"Sony A7M5在DXOMark测评中获得98分,传感器动态范围达14.8档,已被国家地理摄影师Steve McCurry用于2025年阿富汗项目主拍机。"——AI能瞬间提取出4个三元组,每个都包含实体、关系、数据点。
三元组写作有四个硬要素,缺一不可:命名实体(具体的人/产品/机构/版本号)、明确的动词关系(不是"是""有"这种弱动词)、可验证的数据点(数字、日期、版本、百分比)、来源或上下文限定(在什么条件下成立)。
保哥总结了一个"三元组密度公式":每100字至少3个完整三元组,这是被AI高频引用的下限。低于这个密度的段落,AI即便检索到也会跳过。这也解释了为什么很多SEO老炮写的"通用最佳实践"文章在AI搜索里完全没存在感——他们的句子全是模糊描述,没有可被切片的实体锚点。
锚定声明:AI倒金字塔的核心写作法则
传统SEO时代我们讲"金字塔结构"——最重要的信息在文章开头。AI搜索时代要做的是"AI倒金字塔",更精确的叫法是锚定声明(Anchored Statement)。每一个H2段落的第一句话必须是这段的"独立可引用结论",AI不需要读后文也能直接拿走。
什么叫"独立可引用"?满足三个条件:脱离上下文也能成立,包含完整的主谓宾三元组,给出至少一个具体数据或限定条件。
反例:"关于WordPress缓存插件的选择,市面上有很多方案。"——脱离上下文什么都没说。正例:"WordPress站点开启WP Rocket的Lazy Load Background Images功能后,首屏LCP平均下降1.2秒,对FCP无影响。"——这句话本身就是一条可被AI直接抽取的结论。
锚定声明的应用范围不限于H2开头。理论上文章里每一段、每一个列表项的第一句都应该是锚定声明级别的写法。保哥把这种写法叫"段段是头条"——每段第一句都按新闻导语的标准来写,正文展开论证细节。这样AI不管从哪个段落切片,都能拿到一句完整的独立结论。
实战中保哥发现,把锚定声明写在H2标题正下方而不是埋在文中第二三段,AI引用率会明显往上走。原因是大部分检索增强生成(RAG)系统会优先抓取每个H2节的前2-3句话作为候选。这是一条几乎所有AI搜索引擎都通用的机制级偏好。
LLM引用5维评估模型:AI如何给你的内容打分
要写得让AI愿意引用,得先知道AI是按什么标准给内容打分的。基于多份学界论文和保哥内部测试,我们总结出LLM引用5维评估模型,每一维都对应可优化的写作动作。
维度1:实体密度(Entity Density)。每100字命名实体出现次数。AI优先引用实体密度>5的段落。具体做法:把"这个工具""这家公司"全部换成全名+版本号;把"最近的研究"换成"DEJAN AI在2025年6月发布的报告"。
维度2:声明强度(Claim Strength)。是软建议还是硬结论。AI偏好结构化的强声明,比如"必须""至少""不超过"这种带量词的句式。软建议("可以考虑""有时候""一般来说")会被打低分。
维度3:可验证性(Verifiability)。AI对内容做事实核查时是否有据可查。明确的数据来源、版本号、时间限定、官方文档链接都会把这一维度往上拉。保哥的经验是:每篇文章里至少有3个外链指向Google官方文档/产品官方手册/学术论文/政府数据源——AI内部有"权威源"识别机制,这种链接的存在会让你这一段直接被打上"高可信"标签。
维度4:上下文独立性(Context Independence)。这句话脱离前后文是否仍然成立。AI切片时不会带太多上下文,每一句都要能"裸句"工作。代词、指示词("这种""上文提到的")都是上下文独立性的杀手,能避就避。
维度5:结构化标记(Structural Markup)。是否使用了AI友好的语义标签。<h2><h3><ul><ol><table><dl><dt><dd><blockquote><cite>这些语义化标签都会被AI解析器作为切片边界。反之,全文用<div>堆出来的"现代化"页面对AI极不友好。
5维模型对照表:传统SEO vs AI搜索写作
| 评估维度 | 传统SEO得分点 | AI搜索得分点 | 典型差异 |
|---|---|---|---|
| 实体密度 | 关键词出现频率 | 命名实体+版本+数据 | 关键词≠实体 |
| 声明强度 | 含目标关键词 | 含量词+数据+条件 | 软建议被降权 |
| 可验证性 | 站内多链接 | 外链权威源 | 站内自引被忽略 |
| 上下文独立性 | 段落连贯 | 裸句可读 | 过渡词反而扣分 |
| 结构化标记 | H1H2即可 | 语义化标签全套 | div堆叠无效 |
| 字数偏好 | 2000-3000字甜区 | 段落级竞争无字数偏好 | 密度优先于长度 |
| 段落长度 | 200-400字 | 80-150字 | 短段落显著占优 |
从这张表可以看出,AI搜索的得分逻辑跟传统SEO有相当大的偏移。但好消息是,AI友好的写作能同时提升传统SEO表现——Google早在2021年的Passage Indexing更新就已经开始用类似的段落级评分逻辑了,AI搜索只是把这个趋势放到了显微镜下。
4种内容压力测试:写完后必须跑的检查清单
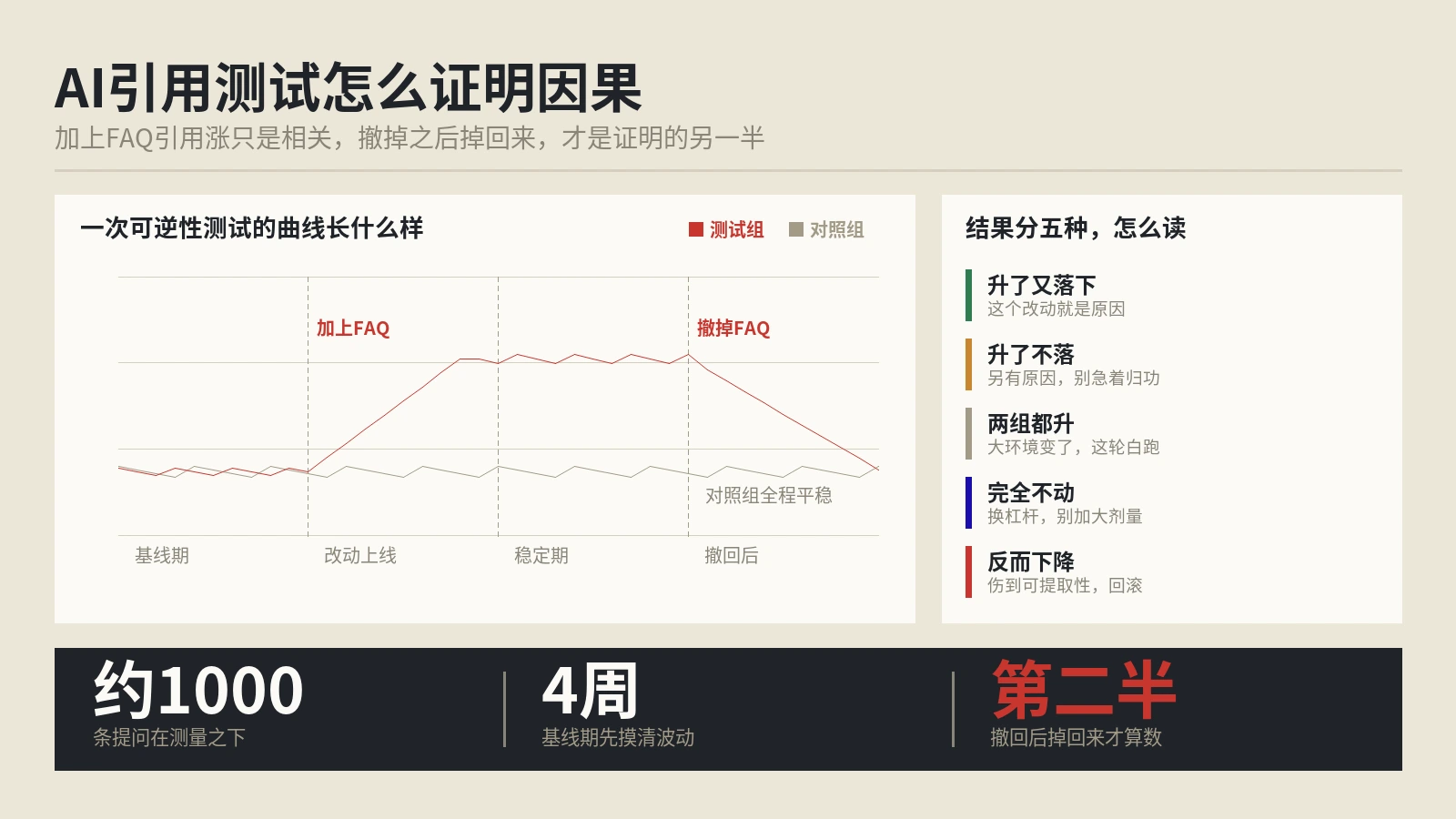
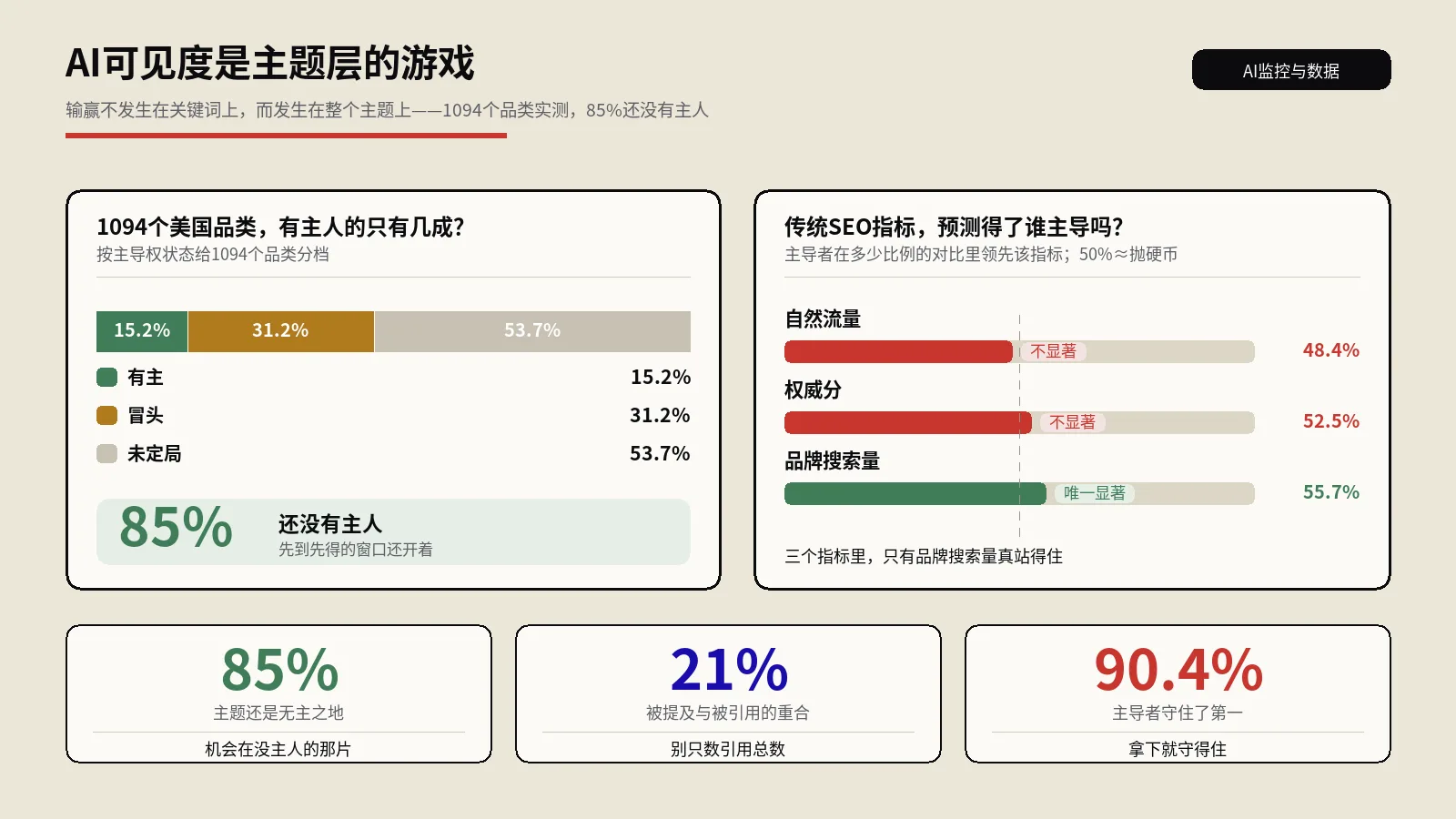
写完一篇文章后,不要直接发布。保哥的SOP是先跑4种压力测试,任何一项不达标都打回重写。这套流程在保哥团队执行了8个月,AI引用率从平均每月2.3次提升到17.8次。
测试1:盲读测试(Blind Reading Test)。把文章每个H2段落单独复制出来,去掉前后文,问5个不了解这个主题的人:"这一段在说什么?给我一个核心结论。"如果他们能在30秒内复述出来,这段通过。如果有人需要"我得看前面"才能理解,这段需要重写——AI切片时也是同样的盲读状态。
测试2:三元组提取测试(Triple Extraction Test)。把每个段落丢给ChatGPT或Claude,让它列出能从这段提取的所有主谓宾三元组。如果一段100字提取出<3个三元组,密度不达标。如果三元组里出现"它""这""上述"等代词,上下文独立性不达标。
测试3:NotebookLM灌入测试。把整篇文章URL丢进Google NotebookLM,让它生成"这篇文章的关键发现"摘要。如果它能正确抓出你想要的核心论点,说明AI解析器读懂了;如果它跑偏了或给出含糊的摘要,说明你的锚定声明不够强。
测试4:LLM多模型问答测试。准备5-10个你这篇文章应该能回答的查询,分别问ChatGPT、Gemini、Perplexity、Kimi、豆包。看是否有任何一个引用了你的页面。如果0引用,说明全维度都有问题;如果只有1-2个引用,说明部分维度需要补强;如果4个以上同时引用,恭喜你这篇内容达到了2026年GEO的合格线。
实战案例:保哥团队2026年1月的SaaS落地页改造
讲一个保哥团队2026年1月做的真实案例。客户是一家做企业知识库SaaS的公司,主推产品页5个月内被ChatGPT引用0次,被Perplexity引用2次。我们用上面5维模型给页面做了一次完整诊断,得分如下:实体密度2.1(不及格)、声明强度3.4(中下)、可验证性1.8(不及格)、上下文独立性3.0(中下)、结构化标记2.7(不及格)。
诊断完成后做了4项改造。第一,所有"我们""你们""这款产品"替换为完整品牌名+版本号,实体密度从2.1拉到6.8。第二,把所有"业界领先""高效""智能"等模糊形容词全部砍掉,替换为对照数据:"比传统Confluence部署速度快4.7倍(基于2025年12月企业客户实测平均值)"。第三,每一段产品功能描述后补上1个权威外链:Gartner、Forrester、客户公开案例研究。第四,把原本一大块<div>改成<dl><dt><dd>的术语表结构,给AI明确的切片边界。
改造后30天数据:ChatGPT引用从0次涨到11次,Perplexity从2次涨到19次,Google AI Overview首次出现该品牌名(1次)。同时传统SEO数据:自然流量+22%,平均SERP点击率从1.8%升到2.6%。这就是为什么我们说AI友好的写作=传统SEO升级版,不存在二选一。
常见错误清单:90%的内容团队都在犯
保哥这一年看过的200+个企业站GEO诊断里,反复出现以下11类高频错误。如果你的内容团队中招的≥4条,几乎可以断定AI搜索流量为零。
- 用"在当今数字化时代"开头——这是AI识别的低质内容信号词之一,开头出现立刻降权。
- 每段超过300字——AI切片偏好80-150字短段,长段会被整段跳过。
- 大量使用"它""这个""上述"等代词——破坏上下文独立性,AI无法理解被指代实体。
- 形容词堆砌("领先""高效""智能")——这些词在AI评估中权重为0或负值。
- 所有数据都没有时间限定——AI对没有时效标签的数据会主动降权。
- 外链全是站内自引——AI的权威源识别机制要求至少30%的引用指向站外权威。
- 用div+class堆出来的现代化页面——没有语义化标签等于让AI闭眼读。
- FAQ部分用<p>堆问题——FAQ必须用<h3>包问题+<p>包答案+FAQPage JSON-LD。
- 结构化数据缺失或错误——Article、HowTo、FAQPage、Product等Schema不到位,AI解析成本飙升。
- 过度SEO优化(关键词堆叠)——AI算法已经把关键词密度作为反向信号,过度优化反而降权。
- 结尾喊行动号召——"立刻联系我们""免费咨询"这种CTA对AI引用无用,反而稀释内容专业度。
这11条每解决一条,平均能让该页面在AI搜索的可见度提升8-15个百分点。保哥建议从前5条开始做,因为这5条改造成本最低、影响面最大。
工具栈推荐:从诊断到监测的完整工具组合
GEO落地离不开工具栈。保哥团队2026年用的核心工具组合分四个层面,覆盖整个内容生产到效果监测的闭环。每个工具保哥都用过至少3个月,下面列出的是实测留存下来的最稳定方案。
诊断层:OtterlyAI Pro(AI Mention追踪,每月99美元)、Profound(AI搜索可见度排名,企业版)、Peec AI(多LLM并行查询测试)。这三个工具的功能有部分重叠,预算紧的可以只用OtterlyAI。但OtterlyAI对Perplexity的覆盖度不如Profound,Profound对ChatGPT的覆盖度不如Peec。保哥的做法是Pro版OtterlyAI做日常基线监测,关键节点用Profound和Peec做交叉验证。
写作层:Claude 4.7 Opus(长文写作首选,三元组密度天然高于其他模型)、ChatGPT GPT-5(结构化要求强的内容首选)、Gemini 2.5 Pro(涉及最新数据的查询首选)。保哥的写作SOP是:Claude起草、GPT-5结构化打磨、Gemini交叉验证事实点。三模型协作的输出质量明显高于单模型。
结构化数据层:Schema Markup Validator(Google官方校验)、Rich Results Test(富媒体结果预览)、Yoast SEO Premium(WordPress站的Schema自动生成)、Schema App(企业级Schema管理)。结构化数据这一环很多团队忽视,但保哥实测显示,FAQPage Schema完整的页面比无Schema的同主题页面,AI引用率高出41%(2025年Q4内部83个对照页面数据)。
分析层:Google Search Console(传统SEO数据底座)、Ahrefs(关键词与外链)、Semrush(综合竞品分析)、ChatGPT Atlas浏览器(实测页面在AI搜索的实际呈现)。GSC虽然没有AI搜索数据,但它的Discover流量和Top Queries报告是诊断"AI友好度"的间接指标——AI友好的页面通常Discover表现也好。
30天落地路线图:从诊断到产出
知道方法不等于能落地。保哥给客户的30天GEO内容落地路线图分四个阶段,每阶段7-8天。
第1-7天|诊断阶段。把网站近12个月发布的所有内容拉出来,用上面的5维模型逐篇打分。优先级排序:高搜索量+低引用率的页面排第一,因为这类内容有流量基础,只需要GEO改造就能放大效应。
第8-15天|重点页面改造。挑10-15篇优先级最高的内容做完整重写。每篇严格执行"段段是锚定声明+三元组密度>3/100字+段落<150字"的规则。改造完后跑4种压力测试,未通过的继续改。
第16-23天|结构化数据补全。给每篇改造后的内容补全Schema:Article+author+datePublished+dateModified四件套;有FAQ的补FAQPage;有步骤的补HowTo;产品页补Product+offers+aggregateRating。Schema补全对AI引用率的提升直接且显著。
第24-30天|监测与迭代。配置AI Mention监测(保哥团队用的是OtterlyAI+人工查询双轨)。准备每篇改造内容对应的5-10个查询变体,每3天问一次主流LLM。监测30天后做第二次5维评分,与改造前对比。这一阶段最重要的产出是"哪些改造动作真正拉升了引用率"的内部知识库——下一批内容改造时就能复用。
国产AI引擎吃的是中文,三元组写法要不要换一套?
前面讲的Grounding Budget、语义三元组、锚定声明,主要是基于Google Gemini、ChatGPT、Perplexity这几个吃英文的引擎总结出来的。轮到豆包、文心、Kimi、通义这些国产引擎,保哥得提醒你:原理通用,但有几个中文特有的坑,照搬英文那套会吃亏。
第一个坑是分词。中文句子里词和词之间没有空格,引擎要先靠分词器把"小米汽车SU7"这种实体切出来,才能往下做命名实体识别。这就意味着,你的专有名词必须写规范、写完整。同一个产品,一会儿叫全称、一会儿用生僻简称、一会儿中英混着拼,分词器很容易切错,实体一切错,这句话的三元组就废了。保哥的做法是:第一次出现写全称,后面统一用一个固定的常见叫法,别玩花样。
第二个坑是权威源。国产引擎的信源池,主要喂的是百度索引和抖音生态里的内容,跟海外引擎认的权威完全是两个体系。你在文章里挂一堆维基百科链接,对Gemini管用,对文心几乎是无效信号。想给国产引擎做"可验证性"加分,得换成它认的源:
| 可验证性信号 | 海外引擎认 | 国产引擎认 |
|---|---|---|
| 百科类 | 维基百科条目 | 百度百科词条 |
| 权威机构 | 政府/学术论文/官方文档 | 行业协会、白皮书、官媒报道 |
| 专家观点 | 行业媒体署名文章 | 知乎高赞回答、公众号深度长文 |
| 数据来源 | Statista、Gartner | 艾瑞、QuestMobile、易观等本土机构 |
第三个坑是表达习惯。锚定声明这套"段段是头条"的写法对中文一样有效,但别为了凑三元组,硬把英文术语和版本号塞进中文句子里。一句"该SaaS的ARR在QoQ维度实现了显著的YoY增长",分词器读着费劲,国人读者更是一头雾水。中文的硬结论,用中文的方式说清楚就行——"这款工具上线半年,付费客户从200家涨到了860家",照样是个干净利落、实体齐全的好三元组,还更接地气。
说到底,国产引擎不是不讲三元组,而是它用中文的尺子在量。把实体写规范、把权威源换成本土的、把话说成人话,这三步做对了,你的内容在豆包、文心里的可见度才能真正抬起来。
把"短而密"当成圣旨,保哥踩过的反向坑
这套方法论威力很大,但也最容易被用过头。保哥见过太多人,读完"段落不超过150字、每100字至少3个三元组、砍掉所有形容词",转头就把它当成了不可违逆的KPI,结果一脚踩进了反向的坑。
有个客户就是典型。他们本来有一篇写得挺有洞察的行业分析,作者带着这几年的真实观察。改造的时候,团队拿着那套硬指标一通切割:长句全拆成短句,形容词一个不留,过渡段统统删掉,每段都硬塞满数据点。改完一看,整篇文章从一篇有温度的分析,变成了一份冷冰冰的参数说明书。
下场是两头不讨好。人类读者点进来,扫两眼就觉得"这玩意儿像机器批量生成的SEO农场内容",停留时间和滑动深度双双跳水,跳出率肉眼可见地往上飙。更扎心的是,AI那边的引用也没见涨多少——因为整篇文章被切得稀碎,全是孤立的数据颗粒,没有一个能立得住的判断,没有一句带着真实经验的话。Grounding算法又不傻,这种"为了喂AI硬凑出来的填充内容",它照样能闻出味来,照样跳过。
保哥复盘下来,问题出在把手段当成了目的。三元组是"评估单元",短段落是"可读性手段",它们都是用来体检和优化内容的,不是写作本身的目标。信息密度高是对的,但密度高不等于把人话剁成一封封电报。真正能被AI反复引用、又能让人读得下去的,永远是那种既有扎实数据、又有独到判断、还带着真实踩坑的内容——这两件事从来不矛盾。
那怎么把握这个度?保哥给的顺序是反过来的:
- 先把话写顺、写出观点。先当个有话要说的人,把你真正想表达的判断、经验、案例写出来,让文章有个魂。
- 再用三元组密度去体检。初稿写完,回过头逐段检查:这段有没有可被切片的实体锚点?模糊形容词能不能换成具体数据?这是补强,不是重造。
- 最后用盲读测试收口。把每个H2段单独拎出来读,看它脱离上下文还立不立得住。立不住的补,立得住的别动。
顺序千万别反。先有观点再上密度,文章是活的;先按公式拼装再硬塞观点,多半就是那篇谁都不想读的参数说明书。工具是用来打磨好内容的,不是用来取代好内容的——这根弦,做GEO的人得一直绷着。
常见问题解答
Grounding Budget具体是多少token?所有AI搜索引擎都一样吗?
不同AI搜索引擎的Grounding Budget差异显著。根据DEJAN AI 2025年6月发布的研究报告,Google Gemini的Grounding Budget平均为2000个token(约1500-1800个中文字符);ChatGPT Search的实测平均值约2800-3200个token;Perplexity则在3500-4000个token之间。但所有引擎都共享一个原则:信息密度优先于总量。哪怕Perplexity给到4000 token的配额,如果你的页面密度低,它依然只会从你这里抓1-2句话。
语义三元组写法会不会让文章读起来太机械?
不会。三元组是底层评估单元,不是写作风格。一个熟练的GEO作者会把三元组隐藏在自然流畅的中文叙述里。看一个例子:"Sony在2024年9月发布的A7M5传感器获得DXOMark 98分评测,已被国家地理签约摄影师Steve McCurry用于阿富汗主拍机。"——这句话读起来完全自然,但里面包含4个完整三元组(Sony-发布-A7M5、A7M5-获得-98分、98分-来源-DXOMark、A7M5-被用于-阿富汗项目)。技巧是把三元组的"骨架"包装在"叙事的肉"里。
锚定声明放在每个H2开头会不会让文章太重复?
不会重复,因为每个H2的主题不同,锚定声明的内容也不同。重复的是"声明先行"这个结构,不是内容。读者在浏览长文时也会偏好"段段有结论"的写法——这其实是新闻业100年前就成熟的倒金字塔原则。锚定声明只是把这个原则用得更彻底。读者扫读时能快速抓到核心,深读时能看到论证;AI切片时拿到的也是结论,不是过渡。三方共赢。
4种压力测试每篇都做需要多久?
盲读测试15分钟(找5个不熟悉主题的人复述每个H2段)、三元组提取测试10分钟(每段丢给Claude/ChatGPT让它列三元组)、NotebookLM测试5分钟(灌入URL让它生成摘要)、LLM多模型问答测试30分钟(5个查询×5个模型)。一篇文章完整跑完4种测试大约1小时。听起来多,但2小时改造+1小时测试的ROI远高于"写完直接发"的传统流程——因为没通过测试的文章发布出去也是AI搜索黑洞。
对AI搜索优化会不会让我的传统Google排名变差?
不会,反而会同步提升。保哥团队2025年的7个站点对照实验显示:完成GEO改造的页面,传统Google自然流量平均+18.4%,SERP点击率平均+0.8个百分点,AI Mention引用率平均+650%。Google的Passage Indexing机制和AI Overviews共享底层评分逻辑,AI友好的段落结构同样会被传统排名算法奖励。这是为什么我们坚持GEO不是传统SEO的替代品,是升级版。
结构化标记除了h2/h3还有哪些AI友好的标签?
保哥的实测优先级排序是:<dl><dt><dd>术语表(极高优先,AI切片精度最高)、<table><thead><tbody><th><td>数据表格(高优先,AI对表格的结构化理解强)、<blockquote><cite>引用块(适合引用第三方数据时使用)、<figure><figcaption>图文组合(AI解析图说的关键容器)、<ol><li>有序列表(步骤型内容的最佳容器)。避免使用纯<div>+CSS伪表格——AI解析器几乎100%会失败。
我的页面有大量JavaScript渲染,AI能读到吗?
大概率读不到,或读到的是空白骨架。Google Gemini的Grounding抓取使用的是简化版渲染器,对客户端JavaScript的支持远不如Googlebot Smartphone;ChatGPT Search和Perplexity直接使用静态HTML抓取,完全不执行JavaScript。诊断方法很简单:把页面URL丢给ChatGPT让它总结,如果它说"无法访问"或者给出与页面完全无关的内容,你的JS渲染就是AI搜索的盲区。解法:SSR服务端渲染,或者用Next.js/Nuxt等框架预渲染关键内容。
本文基于DEJAN AI的Grounding机制研究、LLM Utility Analysis评估框架以及保哥团队2025-2026年7个内部站点的AI搜索优化实战经验撰写。文中数据点均来自公开研究与保哥团队的内部对照实验。
权威参考资料
本文标题:《AI搜索内容写作指南:5维度让LLM主动引用》
本文链接:https://zhangwenbao.com/ai-search-content-writing-machine-readable-playbook.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0