Linux inotify文件监控怎么用才能文件一变就触发?inotifywait、incron与实时同步实战

本文目录
- inotify到底是什么?和定时轮询比强在哪?
- inotifywait怎么用才能实时盯住一个目录?
- 怎么用inotifywait写一个文件一变就触发的同步脚本?
- incron是什么?什么时候比自己写循环更省心?
- close_write和modify到底该监听哪个才不漏不重?
- 监控不递归、watch数量撞上限,这些坑怎么破?
- 配置文件被谁动了想第一时间知道,怎么用inotify做?
- 怎么把inotify监控脚本做成开机自启、挂了能自动拉起的服务?
- inotify不够用时,fanotify和auditd各适合什么场景?
- 常见问题解答
- inotify和cron定时轮询到底该怎么选?是不是inotify永远更好?
- 为什么我用inotifywait监听modify,一个文件被处理了好多次?
- inotifywait报 “Failed to watch; upper limit on inotify watches reached” 怎么办?
- incron和自己写inotifywait脚本,生产环境更推荐哪个?
- inotify能监控网络共享目录(NFS、Samba)上别人对文件的修改吗?
- 权威参考资料
摘要:很多人想在Linux上做这么一件事:某个目录里一有文件落地,就立刻把它同步到别处、或者触发一段处理脚本。第一反应往往是写个cron,每分钟扫一遍目录看有没有新东西。结果要么间隔太长延迟肉眼可见,要么间隔太短把CPU和磁盘空转得呼呼响,还经常在文件没写完时就被抓去处理,搞出半截文件。
根子在于:定时轮询是“主动去问有没有变化”,而文件系统其实能“变化时主动告诉你”。Linux内核早就提供了inotify这套机制,专门用来盯住文件和目录的增删改,事件级实时,几乎不耗资源。配上inotifywait命令或incron守护进程,写几行脚本就能做到“文件一落地立刻处理”。
保哥这篇按真实运维场景把inotify讲透:它和定时轮询的本质区别、inotifywait怎么实时盯目录、怎么写一个文件一变就触发同步的脚本、incron什么时候比自己写循环省心、close_write和modify该监听哪个、不递归与watch数量上限这些坑怎么破,最后给一套配置文件防篡改告警的实战。
先说个保哥真碰到的事。客户做跨境电商,上游ERP每隔几分钟往一台Linux服务器的指定目录里丢订单导出文件,下游有个脚本要把这些文件解析后推到独立站后台。最早的做法是cron每分钟跑一次,扫目录、挑没处理过的文件、处理掉。问题接二连三:有时文件刚传一半就被脚本抓去解析,得到半截JSON直接报错;有时一分钟内来了一批文件,下一分钟才被处理,客户嫌慢;为了求快把间隔压到每10秒一次,服务器又被这种空转拖得负载长期偏高。
这套毛病的共同根源,是用“定时去问”来应付“随机发生”的事。文件什么时候到是不确定的,你却用一个固定节拍去轮询,节拍快了浪费、慢了延迟,怎么调都别扭。真正对路的工具是inotify:让内核在文件真正写完、关闭的那一刻主动通知你,你再动手,既不空转也不抢跑。保哥在 用cron把独立站运维自动化那篇里讲过定时任务擅长什么,但“盯文件变化”恰恰是cron的短板,该交给inotify。
inotify到底是什么?和定时轮询比强在哪?
inotify是Linux内核内置的一套文件系统事件监控机制,从2.6.13内核起就有了。它的核心能力是:你向内核登记“我要盯住某个文件或目录”,之后这个对象一旦发生增、删、改、移动、被打开、被关闭等事件,内核就把事件实时塞给你,你读出来即可。整个过程是内核推送,不需要你反复去查。
按 Linux man-pages的inotify(7) 手册,使用它的底层流程是:inotify_init建一个inotify实例拿到一个文件描述符,inotify_add_watch往里加要盯的路径和关心的事件,然后read这个描述符就能源源不断读到事件。这是C程序的玩法,运维日常不用碰,因为有现成的命令行工具替你封装好了。
它和定时轮询的差别是“被动等通知”对“主动去查岗”。轮询是你拿着名单每隔一段时间挨个点名,名单越长、点名越勤,开销越大,而且两次点名之间发生的事你看不见、只能等下一轮。inotify是事件驱动,平时一个事件没有就一直安静地睡着,半点CPU不占,真有变化内核才把你叫醒,延迟是毫秒级。打个比方:轮询像保安每隔五分钟绕楼巡一圈,inotify像每个门口装了门铃,谁进出当场响。门铃方案既省人力又不漏人,这就是为什么涉及“文件一变就要立刻反应”的需求,inotify几乎是唯一正解。
inotifywait怎么用才能实时盯住一个目录?
命令行里用inotify,主力工具是inotify-tools包里的inotifywait(多数发行版要先装,比如apt install inotify-tools或yum install inotify-tools)。它把内核那套描述符操作封装成一条命令:你告诉它盯哪个路径、关心哪些事件,它就阻塞在那儿等,一有事件就打印出来。最常用的姿势是加 -m进入持续监控模式:
# -m 持续监控不退出,-r 递归含子目录
# -e 只关心这几类事件,--format 自定义输出
inotifywait -m -r -e create -e close_write -e delete \
--format '%T %w%f %e' --timefmt '%F %T' /data/incoming按 inotifywait(1) 官方手册,-m(monitor)让它收到事件后不退出而是一直跑,-r(recursive)会把传入目录的所有子目录一并盯上,-e指定只关心哪些事件类型、可以写多个,--format用类似printf的占位符自定义每行输出(%w是被监控的目录、%f是文件名、%e是事件名、%T配 --timefmt打时间戳)。不加 -m时它收到第一个事件就退出,这种一次性模式适合在脚本里“等某个文件出现就往下走”。
常用事件类型要分清:create是在被监控目录里新建了文件或目录,modify是文件内容被写入(一次大写入可能触发多次),delete是被删除,close_write是以可写方式打开的文件被关闭,move/moved_to/moved_from是移动或改名。实战里盯“新文件到位了没”,关键不是create也不是modify,而是close_write——下面专门讲为什么。
怎么用inotifywait写一个文件一变就触发的同步脚本?
把inotifywait的输出喂给一个while循环读取,就能做到“监听到事件→执行动作”。最经典的模板是配合read逐行消费事件:
#!/bin/bash
WATCH=/data/incoming
DEST=/data/processed
inotifywait -m -e close_write -e moved_to --format '%w%f' "$WATCH" |
while read FILE; do
echo "$(date '+%F %T') 检测到就绪文件: $FILE"
# 文件已完整落地,这里做你要的处理:同步、解析、推送
cp "$FILE" "$DEST/" && echo "已处理 $FILE"
done这段脚本的关键在两点。一是只监听close_write和moved_to,确保拿到的是“已经写完关闭”或“整体移动进来”的完整文件,绝不会在传输途中就抓走。二是用管道接while read逐个消费,事件来一个处理一个,天然串行、不会漏。把它配上nohup或做成服务后台常驻,目录里一有文件落地,几乎瞬间就被处理,再也不用cron那种一分钟的尴尬延迟。
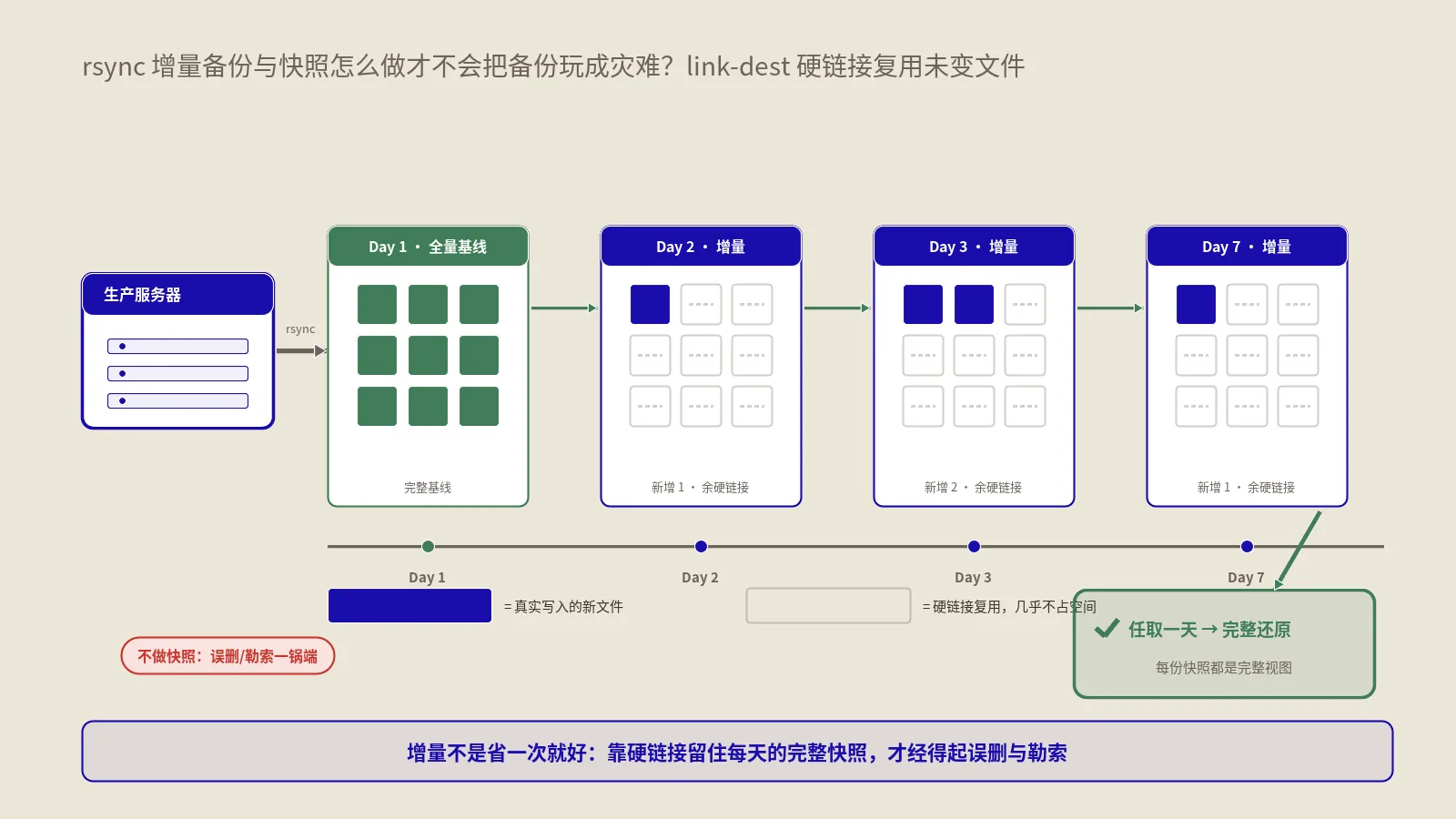
如果处理逻辑是把文件实时同步到另一台机器或异地备份,常见组合是inotifywait负责“感知变化”、rsync负责“高效搬运”:监听到事件后触发一次增量rsync,只传变化的部分。保哥在 用rsync做增量备份和快照那篇里讲透了rsync的增量与快照玩法,inotify给它补上了“实时触发”这一环,两者搭起来就是一套准实时的目录镜像方案。
不过这里有个性能注意点:如果短时间涌入大量文件,每个事件都立刻拉起一次rsync,会把进程开销堆高。更稳的做法是收到事件后不马上跑,而是设一个短延迟(比如攒2秒),把这段时间内的多个事件合并成一次同步,业内管这叫去抖动(debounce),能显著降低高频场景下的负载。
incron是什么?什么时候比自己写循环更省心?
自己写inotifywait + while循环虽然灵活,但要操心后台常驻、开机自启、进程挂了怎么拉起这些事。如果只是“某目录发生某事件就跑某命令”这种规则化需求,incron更省心。它的定位就像cron,只不过cron是按时间触发,incron是按文件事件触发,它本身是个常驻守护进程,开机自启、规则集中管理,你只管写规则。
incron的规则表用incrontab -e编辑,每行三段,按 incrontab(5) 官方手册的格式是“被监控路径 事件掩码 要执行的命令”,命令里可以用占位符:$@ 是被监控的目录路径、$# 是触发事件的文件名、$% 是事件标志的文字形式。一条典型规则长这样:
# 路径 事件 命令
/data/incoming IN_CLOSE_WRITE /usr/local/bin/handle.sh $@/$#这行的意思是:/data/incoming里只要有文件以可写方式打开后被关闭(IN_CLOSE_WRITE),就拿“目录路径/文件名”作为参数去跑handle.sh。事件掩码用的是内核那套大写常量名(IN_CREATE、IN_MODIFY、IN_DELETE、IN_CLOSE_WRITE等),和inotifywait的小写事件名一一对应。
incron的好处是规则一存就生效、进程它自己管,特别适合“放着不管也能稳定跑”的轻量自动化。但要做复杂逻辑——多步处理、去抖动、错误重试、按文件类型分流——还是自己写脚本配合systemd服务更顺手。一句话区分:固定的“事件到命令”一对一映射用incron,有点厚度的处理流程用脚本加服务。
close_write和modify到底该监听哪个才不漏不重?
这是用inotify翻车最多的地方,必须讲清。直觉上盯“文件变了”应该用modify,但modify是“内容被写入”事件,一个大文件分多次写入就会触发好多次modify,你要是每次modify都处理,一个文件可能被处理十几遍,而且很可能在它还没写完时就抢着去读,拿到半截内容。
正确的选择通常是close_write:它表示“一个以可写方式打开的文件被关闭了”,也就是写入彻底结束、文件已经完整。盯close_write,一个文件从开始写到写完只会触发一次,且触发时内容保证是完整的,不漏不重不抢跑。所以“等新文件就绪后处理”这类需求,几乎都该用close_write而不是create或modify——create只代表文件被创建出来,那一刻里面可能还是空的。
还有个隐蔽坑跟编辑器和某些程序的“原子保存”有关。很多软件保存文件不是直接往原文件写,而是先写一个临时文件、再rename成目标名覆盖过去。这种情况下你盯原文件的close_write根本等不到,因为真正被写的是临时文件,最后是一次rename。
应对办法是同时监听moved_to(或IN_MOVED_TO):rename进来的文件会触发moved_to,把它和close_write一起监听,原子保存和普通写入两种情况就都能覆盖。这也是上面同步脚本里同时写close_write和moved_to的原因——把这两个事件搭在一起监听,几乎能囊括所有“文件就绪”的情形。
监控不递归、watch数量撞上限,这些坑怎么破?
第一个反直觉的点是inotify不递归。inotify(7) 手册写得很明确:监控一个目录不会自动监控它的子目录,要盯子目录得为每个子目录单独加监控。inotifywait的 -r参数帮你做的,正是启动时遍历一遍、给每个现有子目录都挂上监控。但要注意,-r是启动那一刻递归挂载,如果监控期间新建了一个深层子目录,工具需要自己处理“给新目录补挂监控”的逻辑,否则新子目录里的事件会漏。inotifywait本身会处理新建子目录的补挂,但你若用底层API自己写,这是必须考虑的。
第二个坑是watch数量上限。每挂一个监控点都要占一份内核资源,系统对每个用户能创建的watch总数有上限,由 /proc/sys/fs/inotify/max_user_watches控制,很多发行版默认只有8192这个量级。如果你 -r递归监控一个有几十万子目录的大目录树,很容易撞满上限,表现是inotifywait报“no space left on device”之类的错——其实不是磁盘满,是watch配额满。
解决办法是临时用sysctl调大,比如sysctl fs.inotify.max_user_watches=524288,要持久化就写进 /etc/sysctl.conf或 /etc/sysctl.d/ 下的配置文件。更治本的思路是反过来想:监控范围是不是太大了?能只盯关键子目录就别整棵树递归,把node_modules、缓存目录这些不关心的排除掉,既省配额也省内核开销。
第三,inotify监控的是“路径”绑定的对象,文件被删除重建、或挂载点变化时,原来的watch可能失效。还有跨网络文件系统(NFS等)时,别的机器在远端改文件,本机的inotify收不到事件——inotify只能感知本机内核经手的文件操作。这些边界要心里有数,别在网络盘上指望inotify还灵。
第四个坑容易被忽略但后果严重:事件队列溢出。inotify把产生的事件放进一个内核队列等你读取,如果短时间内事件来得又多又猛、而你的脚本处理得慢,没及时把事件读走,队列被塞满后内核会丢弃后续事件,并扔出一个IN_Q_OVERFLOW溢出标志——一旦溢出,你就实实在在地漏掉了一批变化,且无从知道漏了哪些。
应对上有两手:一是让消费端尽量轻快,事件循环里只做最少的事、把解析同步这类重活儿丢到后台异步处理,别让读事件的那个循环被拖住;二是必要时调大 /proc/sys/fs/inotify/max_queued_events这个队列上限,给突发流量留更多缓冲。这也正是前面反复强调“inotify实时加cron兜底”的另一个理由:万一某次突发把队列冲爆、漏了几个文件,那个低频的cron全量扫描就是最后一道网,能把漏网的补回来,不至于真丢数据。
配置文件被谁动了想第一时间知道,怎么用inotify做?
最后给个保哥常用的实战:给关键配置文件做“一改就告警”的轻量监控。服务器上像nginx配置、SSH配置、计划任务这些文件,正常情况下不该频繁变动,一旦被改往往意味着有人在调整、或更糟——被入侵后篡改。用inotify盯住它们,改动一发生就记日志、发告警,比事后翻审计日志主动得多。
#!/bin/bash
inotifywait -m -e close_write -e moved_to -e attrib \
--format '%T %w%f %e' --timefmt '%F %T' \
/etc/nginx/nginx.conf /etc/ssh/sshd_config /etc/crontab |
while read TIME FILE EVENT; do
MSG="[告警] $TIME 关键文件被改动: $FILE ($EVENT)"
logger -t filewatch "$MSG" # 进 syslog
echo "$MSG" >> /var/log/filewatch.log
# 这里可接钉钉/企业微信/邮件告警的 curl 调用
done这个脚本盯三个关键文件,监听写入关闭、移动进来和属性变更(attrib能抓到权限被改这类动作),一有动静就同时写进系统日志和单独日志、并预留了告警接口。把它做成开机自启的常驻服务,是落地的关键一步——用systemd写个unit文件托管,进程挂了能自动拉起,比nohup靠谱得多。保哥在 用systemd把自己的程序做成服务那篇里讲了怎么写unit、设开机自启和自动重启,这类长期监控脚本正该这么托管。
需要提醒的是:inotify这套是“事件发生那一刻在场才抓得到”,监控进程没跑的时段发生的改动它不知道。所以它是“实时发现”的利器,但不能替代完整的文件完整性审计——真要追溯“到底改了什么、谁改的”,还得配合auditd、版本控制或定期校验文件哈希。两者定位不同,inotify负责第一时间报警,审计体系负责留痕追责。
怎么把inotify监控脚本做成开机自启、挂了能自动拉起的服务?
前面的脚本都是在终端里手动跑的,可生产环境要的是“放着不管也一直在盯”。最省事但最不靠谱的做法是nohup加 & 丢后台——它能让脚本在你关掉SSH后继续跑,但进程一旦因为任何原因挂了就彻底停了,没人拉起、也没人知道,等你哪天发现文件没被同步,故障早积了一堆。长期运行的监控脚本,正确的归宿是用systemd托管成服务。
做法是给脚本写一个unit文件,放到 /etc/systemd/system/ 下,核心是在 [Service] 段里设好启动命令和重启策略,关键一行是Restart=always——进程不管因为什么退出,systemd都会自动把它再拉起来,这正是裸nohup给不了的可靠性。写完systemctl daemon-reload,再systemctl enable --now你的服务名,就既开机自启又立刻开跑了。
具体怎么写unit文件、怎么设开机自启和自动重启策略,保哥在 用systemd把程序做成服务那篇里讲得很细,inotify监控脚本正是它的典型用例,托管给systemd之后才能真正做到放着不管也长期稳定运行。
还有个配套的运维细节:监控脚本会持续往日志里写东西,时间一长日志文件会越来越大,不管会撑爆磁盘。所以这类常驻脚本的日志要纳入轮转管理,定期切割、压缩、清理旧日志。保哥在 Linux服务器日志管理那篇里讲了logrotate和journald怎么管日志,把inotify脚本的日志接进去,才算一套能长期稳定跑的方案,而不是跑几个月把盘写满又出新故障。
inotify不够用时,fanotify和auditd各适合什么场景?
inotify很好用,但它有几个天生的边界,碰到这些边界就该换工具。前面说过它不递归、有watch数量上限、只能感知本机操作,还有一点:它是“按路径”监控的,没法低成本地盯住“整个挂载点上的所有文件操作”。当你的需求超出这些边界,Linux还有另外两套机制可以接力。
第一个是fanotify。它和inotify类似也是文件事件通知,但定位更偏“整块文件系统”:能针对整个挂载点做监控,不用一个个目录挂watch,特别适合杀毒软件、文件系统审计这类要覆盖大范围的场景。它还有个inotify完全没有的能力——访问控制,可以在文件被打开的那一刻拦下来做权限判断、决定放行还是拒绝。代价是它需要root权限、API更复杂,运维日常用得比inotify少,但要做“盯住整盘 + 能拦截”的需求,它才是对的工具。
第二个是auditd,它解决的是inotify的另一个软肋——追责。inotify只能告诉你“文件被改了”,但答不上来“是谁、用什么进程、在什么时间改的”,而且监控进程没在跑的那段时间发生的事它完全不知道。auditd是Linux的审计子系统,能给文件加监控规则,把“哪个用户、哪个进程、什么时间对这个文件做了什么操作”完整记进审计日志,是事后追溯和合规审计的标准工具。
三者分工其实很清楚:要“文件一变就实时触发处理”用inotify,要“覆盖整个挂载点或在访问时拦截”用fanotify,要“留痕追责、查清是谁在什么时候干的”用auditd。它们不是替代关系而是互补,按需求选,别拿一个硬扛所有场景。保哥的实战搭配常常是inotify负责第一时间发现并处理、auditd在旁边默默记账留证,两条线各管一摊。
常见问题解答
inotify和cron定时轮询到底该怎么选?是不是inotify永远更好?
不是,得看需求性质。如果你的需求是“文件随机什么时候到、到了要尽快处理”,inotify完胜:它事件驱动、毫秒级响应、平时不占资源,而cron轮询要么延迟大要么空转费机器。但如果需求本身就是按固定时间节拍来的,比如每天凌晨3点跑一次全量备份、每小时生成一次报表,那cron才是对的工具,没有任何文件事件可言,硬上inotify反而别扭。还有一类是“既要实时又要兜底”的场景:用inotify实时处理新文件,同时配一个低频cron(比如每小时一次)扫一遍有没有漏网的,把inotify万一漏掉或进程没跑那段时间的文件补处理掉。实战里这种“inotify实时 + cron兜底”的双保险组合非常稳,既快又不怕漏。
为什么我用inotifywait监听modify,一个文件被处理了好多次?
因为modify是“内容被写入”事件,而一次完整的文件写入在底层往往是分多块、多次写进去的,每写一块就触发一次modify,于是一个文件你看着是“存一次”,inotify视角里却是好几次modify。你要是在每个modify上都触发处理,自然就被处理了好多遍,更糟的是前几次modify时文件还没写完,你读到的是残缺内容。正解是别盯modify,改盯close_write——它只在文件写完、关闭的那一刻触发一次,既保证只处理一次,又保证内容完整。如果文件是被别的程序rename进来的(原子保存或移动),再补上moved_to一起监听。记住这个原则:要“文件就绪后处理”就用close_write,别用modify,能省掉一大半莫名其妙的重复和半截文件问题。
inotifywait报 “Failed to watch; upper limit on inotify watches reached” 怎么办?
这是撞上了watch数量上限,不是磁盘满。每个监控点占一份内核配额,每个用户能创建的watch总数由 /proc/sys/fs/inotify/max_user_watches限制,默认值在不少系统上只有8192。当你递归监控一个子目录极多的大目录树(比如带node_modules的项目、或层层嵌套的数据目录),watch一下就被吃满,于是报这个错。先用cat /proc/sys/fs/inotify/max_user_watches看当前值,再用sysctl fs.inotify.max_user_watches=524288临时调大试试,确认够用后写进 /etc/sysctl.d/ 下的配置文件持久化。另外也反思一下监控范围是不是太大了,能只盯关键子目录就别整棵树递归,把不必要的目录排除掉,既省配额也省内核开销。
incron和自己写inotifywait脚本,生产环境更推荐哪个?
看复杂度。需求简单、规则固定——“这个目录有新文件就跑这个脚本”——incron更省心,它自带守护进程、开机自启、规则集中在incrontab里管理,你不用操心后台常驻和进程拉起,写一行规则就完事。但incron的表达能力有限,它就是“事件→命令”一对一映射,做不了去抖动合并、多步流程、错误重试、按文件类型分流这些复杂逻辑。一旦处理逻辑稍微复杂,就该自己写inotifywait + while的脚本,把它用systemd做成服务托管,这样既有脚本的灵活又有服务的可靠(自动重启、日志、开机自启)。保哥的经验是:轻量规则化任务用incron,有点厚度的处理流程用“脚本 + systemd服务”,别用nohup裸跑长期任务,进程一挂就停了还没人知道。
inotify能监控网络共享目录(NFS、Samba)上别人对文件的修改吗?
基本不能,这是inotify的硬限制。inotify是内核机制,它只能感知“本机内核经手的文件操作”。当目录是NFS、Samba这类网络文件系统挂载过来的,别的机器在远端服务器上直接改了文件,这个修改没经过你本机的内核VFS层,你本机的inotify收不到任何事件。只有在你本机这台上对挂载点里的文件做操作,本机inotify才感知得到。所以想监控网络共享上的远端变动,要么在文件实际所在的那台服务器上跑inotify(在源头监控),要么退回到定时轮询比对(按修改时间或哈希),要么用文件系统自身或存储设备提供的变更通知机制。在客户端这边对网络盘指望inotify实时感知远端改动,是会踩空的,这点一定要提前知道。
权威参考资料
本文标题:《Linux inotify文件监控怎么用才能文件一变就触发?inotifywait、incron与实时同步实战》
本文链接:https://zhangwenbao.com/linux-inotify-file-monitoring-inotifywait-incron-realtime-sync.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0