内容分块优化:AI为什么按“块”而不是按“页”检索你的内容
本文目录
- AI不是读你的“页”,是读你的“块”
- 什么是内容分块?和你理解的“段落”不是一回事
- 为什么AI偏要按块检索?向量检索的底层逻辑
- 块该切多大?200还是800 token,数据说话
- 重叠overlap:别让一句话被切成两半
- 语义分块vs固定分块:召回率能差多少
- 最致命的坑:块脱离了上下文
- 分块优化 ≠ Google的段落级排名,别搞混
- 外贸独立站怎么把内容改成“自包含块”?实操清单
- 图表、视频这类非文字内容,分块时去哪了
- 怎么验证内容到底有没有被切好?
- 中文内容分块,比英文更麻烦在哪
- 分块优化会不会过时?聊聊长上下文的冲击
- 关于分块优化的三个常见误解
- 常见问题解答
- 内容分块是我自己要在网站上做的操作吗?
- 一个块大概多少字最合适?
- 分块优化和加FAQ、加结构化数据是一回事吗?
- 这和Google的段落级排名有什么区别?
- 为什么块“脱离上下文”这么致命?
- 长上下文模型普及后,分块还有意义吗?
- 权威参考资料
摘要:AI搜索引用你的内容时,从来不是把整篇文章读一遍,而是先把它切成一个个几百字的“块”(chunk),再用向量检索从成千上万个块里捞出最相关的几个。这意味着排名单位从“页”变成了“块”——一篇结构再好的长文,只要某个段落脱离上下文、自己说不清自己在讲什么,就会在检索这一关被刷掉。这篇把内容分块的底层机制、块该切多大、重叠留多少、语义分块和固定分块怎么选、以及最致命的“块脱离上下文”问题讲透,最后给一套外贸独立站能直接照做的改造清单。它和Google的段落级排名不是一回事,文中会专门掰开。
AI不是读你的“页”,是读你的“块”
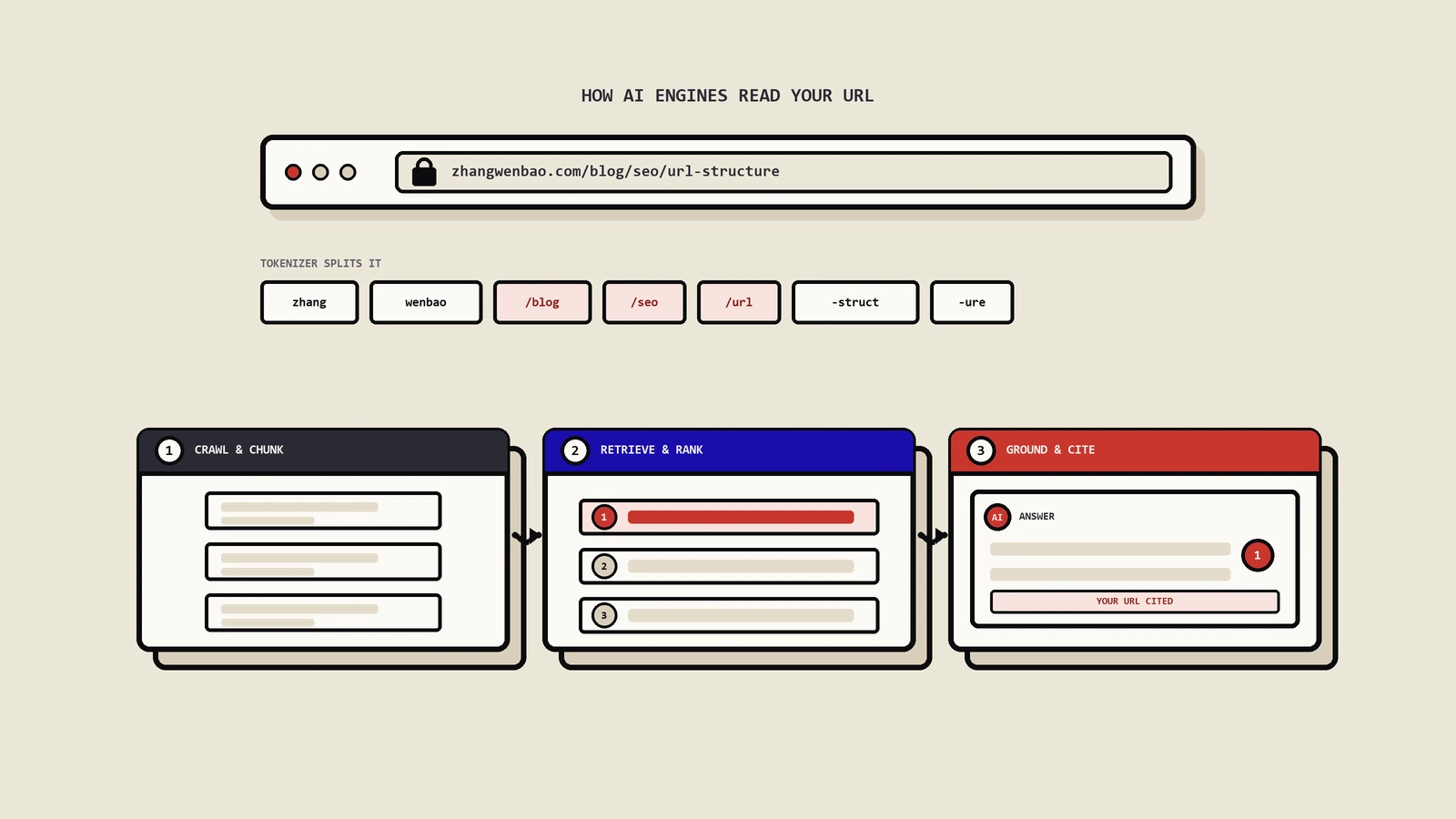
先说一个让很多人没反应过来的事实:当ChatGPT、Perplexity或者Google AI概览引用你的内容时,它读到的根本不是“你那篇文章”,而是你那篇文章被切碎之后的某一小块。
传统SEO时代,排名的最小单位是“页面”——一个URL去竞争一个关键词。但到了AI搜索这一层,检索系统会先把你的页面拆成一段段几百字的片段,每一段单独转成一串数字向量存进向量库;用户提问时,系统把问题也转成向量,去库里找“离得最近”的那几个片段,拼进上下文喂给大模型。最后被引用、被复述、被打上来源链接的,是片段,不是整页。
保哥第一次意识到这件事的严重性,是帮一个做工业配件出口的客户排查问题:他们有篇写得相当扎实的产品选型长文,Google自然排名稳在前三,可在AI概览和Perplexity里几乎从不被引。后来发现,问题不在内容质量,而在“切法”——文章里最干货的那段技术参数对比,前面铺垫了三百字背景,等切到那一块时,块里只剩半句话加一张表,机器根本看不懂这块在讲什么。内容是好内容,只是被切坏了。
这就是内容分块优化(chunk optimization)要解决的问题。它不是又一个玄学概念,而是AI检索(尤其是RAG,检索增强生成)这套技术架构逼出来的硬要求。理解它,等于拿到了GEO时代内容工程的一把底层钥匙。
什么是内容分块?和你理解的“段落”不是一回事
很多人一听“分块”,第一反应是“不就是分段嘛”。不完全是。
你写文章时分的“段落”,是给人读的——按语义、按节奏、按换气。而机器分的“块”(chunk),是给检索系统用的——按token数量、按语义边界、按一套切分算法机械地切。一个块可能正好等于你的一个段落,也可能横跨两三个段落,还可能把你精心写的一个长段从中间劈开。切分由谁决定?由抓取你内容的那个AI系统的分块策略决定,不由你。
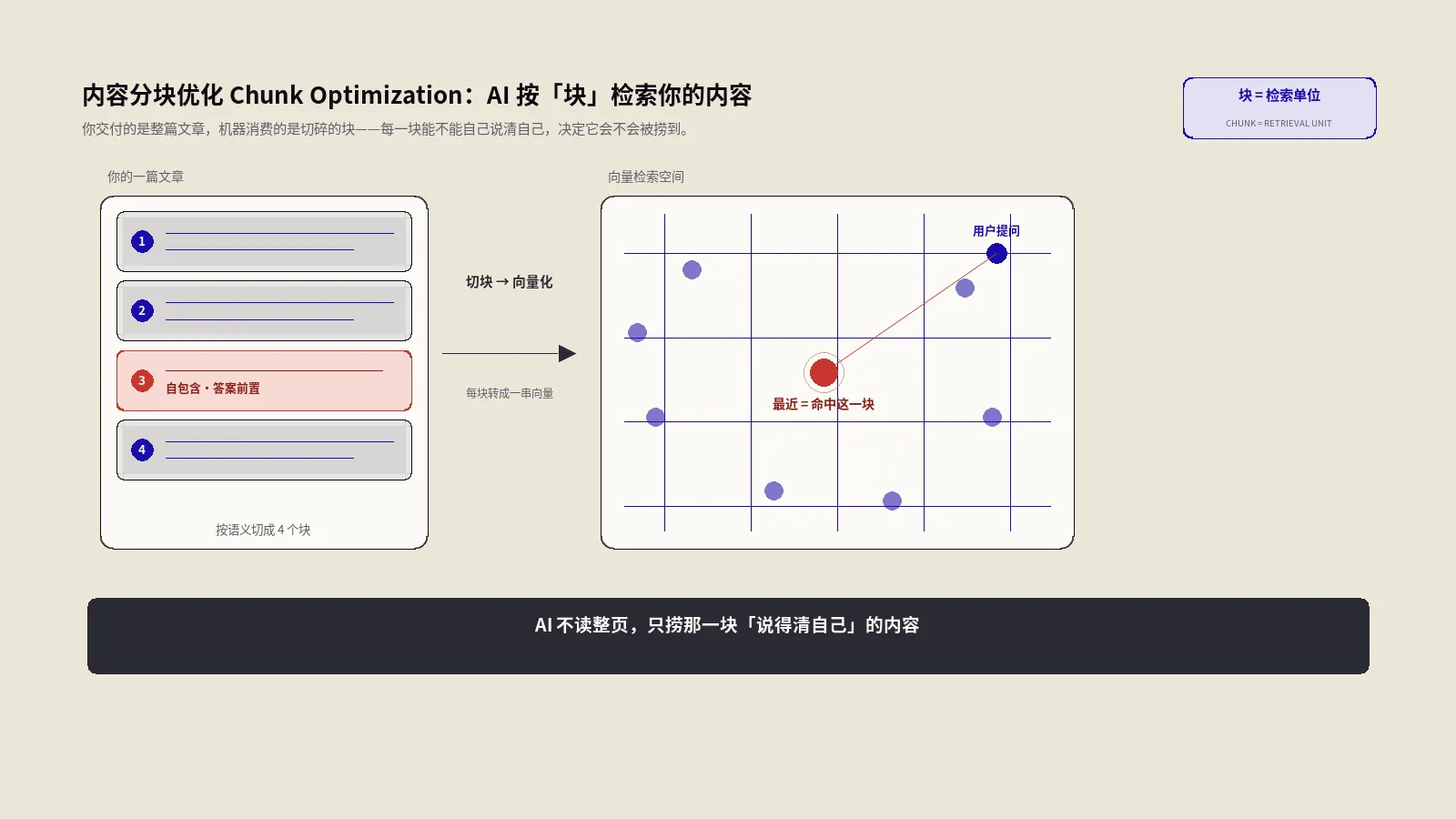
常见的切分方式有几类。最朴素的是按固定字数切,比如每500个token切一刀,不管语义。进阶一点是“递归字符切分”(recursive character splitting),优先在段落、句子这些自然边界下刀,实在不行才硬切。再高级的是“语义分块”(semantic chunking),用嵌入模型算相邻句子的语义相似度,在话题转折的地方断开,让每一块尽量是一个完整的意思。
关键认知是:你交付的是连续的文章,机器消费的是离散的块。你能控制的,是让自己的内容无论被哪种策略切,切出来的每一块都尽量自洽、自带身份、自己能说清自己在讲什么。这就是分块优化的全部出发点。
为什么AI偏要按块检索?向量检索的底层逻辑
要搞懂为什么要优化块,得先明白机器为什么非得把内容切块。
大模型的上下文窗口虽然越来越大,但你不可能把全网内容、或者一个站点的几千篇文章一股脑塞进去——又慢又贵,注意力还会被稀释。所以 RAG(检索增强生成)的思路是:先“检索”出最相关的一小撮内容,再“增强”进生成。检索这一步靠的是向量相似度。
系统会把每个块用嵌入模型(embedding model)转成一串高维数字(向量),这串数字编码了这块文字的语义。用户的问题同样转成向量。然后系统在向量空间里算距离,离问题向量最近的那些块,就被判定为最相关。这套机制决定了一件事:块是检索的原子单位。一个块要么整个被捞出来,要么整个被忽略,没有“半个块”。
这也解释了为什么块的“自包含性”如此致命。向量是对“这一块文字”整体语义的压缩。如果一块里全是“它”“这个方案”“上面提到的方法”这种指代,而被指代的对象在上一块里,那这块的向量就编码了一堆没头没脑的代词,语义模糊,自然检索不准。机器不会像人一样“往上翻一段看看在说啥”——它手里就这一块。
顺带说一句,检索往往不是一锤子买卖。成熟的系统会用两阶段检索:先用速度快的双编码器(bi-encoder)粗捞出50到100个候选块,再用更精细的交叉编码器(cross-encoder)重排序(rerank),挑出最终进上下文的那几块。这一层和之前聊过的 查询扇出机制是连着的——一个问题被拆成多路子查询分头检索,每一路都在你的块库里捞,捞中的概率高低,直接取决于你的块切得好不好。
块该切多大?200还是800 token,数据说话
“块切多大合适”是被问得最多的问题,而且有难得的硬数据可参考。
向量数据库厂商Chroma做过一份系统的分块策略评测,结论很反直觉:块不是越大越好,也不是越小越好,大小直接在“精度”和“召回”之间做权衡。他们的测试里,200 token的小块精度更高(最高8.0%),但召回偏低;800 token的大块召回冲到85.4%,可精度直接崩到1.5%。翻译成人话:大块更容易被捞到(因为信息多,总能沾上点关系),但捞到了也未必精准(因为一块里混了好几个话题,稀释了相关性)。最优区间,落在200到400 token之间。
另一份被广泛引用的行业数据也指向类似结论:以递归字符切分、512 token配10% 到20% 重叠作为大多数内容的稳妥起点。换算成中文,512 token大约对应300到400个汉字——也就是说,一个理想的块,差不多就是一个论点完整、能独立成立的小节,三五百字的体量。
这给内容写作一个非常具体的指导:别写那种铺垫五百字才进正题的段落,也别把一个完整论点摊成横跨两屏的大段。每隔三五百字,让内容自然形成一个“能被单独拎出来也读得懂”的语义单元。现在写长文,刻意每隔几段就回收一次主题、重述一次关键实体,本质上就是在帮机器切出干净的块。
重叠overlap:别让一句话被切成两半
切块时还有个容易被忽略的参数:重叠(overlap)。
固定切分最大的风险,是一刀正好切在一个完整意思的中间——上半句留在这块,下半句去了下一块,两块都残废。重叠就是为了对冲这个风险:让相邻两块共享一小段内容,像鱼鳞一样叠着,确保任何一个完整的句子或论点,至少在某一块里是完整的。
经验值是留块大小的10% 到20% 作为重叠,比如500 token的块配50到100 token重叠。但重叠也不是越多越好。Chroma的测试里有个值得警惕的发现:OpenAI助手的默认设置是800 token块配400 token重叠(也就是50% 重叠),结果性能反而相对较差——重叠太多导致大量冗余,块和块之间区分度下降,向量检索时一堆高度相似的块互相打架。他们的建议反而是用更小、甚至无重叠的块来提效率。
对内容创作者来说,重叠这个参数你控制不了(它属于抓取方),但你能做的是:在写作上主动制造“软重叠”。具体就是在每个小节开头,用一句话把上文的关键结论或关键实体重新点一遍,再展开新内容。这样即便机器在你段落中间硬切一刀,切出来的块开头也有锚点,不至于一上来就是个“因此”“这种情况下”的孤魂野鬼。
语义分块vs固定分块:召回率能差多少
切分策略本身也分高下。Chroma的评测里,不同策略的召回率能差出多达9个百分点——这在检索这个量级上是巨大的差距。
固定字数切分最省算力,但最容易切坏语义;递归字符切分会尊重段落和句子边界,参数调好了表现相当稳,是性价比最高的“默认选项”;而语义分块(用嵌入模型找话题断点)召回最高——评测里基于聚类的语义分块器拿到91.3% 召回配8.0% 精度,基于大模型的语义分块器召回更是冲到91.9%。代价是要给几乎每个句子都算一次嵌入,成本和延迟都高。
这里有个对内容人极其重要的推论:你没法决定抓你内容的系统用哪种切分策略,但语义分块的本质,是顺着“话题转折”断开。也就是说,如果你的文章话题切换清晰、每个小节主题单一、转折处有明确的过渡信号(小标题、“接下来谈另一个问题”这类承接句),那么无论对方用语义分块还是递归分块,都更容易在“正确的地方”断你——切出来的每一块刚好是一个完整话题。反过来,一段里东拉西扯混三个主题,再聪明的分块器也救不了你。
所以对抗坏切分的最好武器,不是去研究别人的算法,而是把自己的内容结构写清楚。结构清晰的内容,天然就是“分块友好”的内容。这一点上,GEO和老派的SEO内容结构化其实殊途同归。
最致命的坑:块脱离了上下文
讲到这里,得请出整个分块优化里最关键、也最反直觉的一个发现——它来自Anthropic的一份研究,几乎重新定义了“好的块”长什么样。
问题是这样的:传统RAG为了好检索,会把文档切成小块,但切碎的同时也切掉了上下文。Anthropic举的经典例子是,有个块里写着“该公司营收较上季度增长了3%”——这句话本身没毛病,可单独这一块拎出来,机器根本不知道“该公司”是哪家、“上季度”是哪个季度。向量编码的是一堆缺失主语的残句,检索自然不准。
Anthropic的上下文检索(Contextual Retrieval)研究给的解法是:在给每个块做嵌入之前,先用模型自动给这块生成一段50到100 token的简短说明,把“这块出自哪篇文档、讲的是哪家公司哪个时间段”补在块的前面,然后再嵌入。就这么一个改动,效果惊人——单用上下文嵌入,检索失败率从5.7% 降到3.7%(降35%);配合上下文BM25关键词检索,降到2.9%(降49%);再叠加重排序,降到1.9%,整整降低67%。
这个研究对内容创作者的启示,比对工程师还大。工程师可以用模型自动补上下文,而你,可以在写作时就把上下文焊死进每一块里。具体怎么做?少用指代,多用全称。别写“这个工具”,写“Ahrefs的外链分析功能”;别写“上面说的方法”,把方法名重新点一遍;每个小节里至少出现一次本节的核心实体全名和所属主题。让任何一块被单独拎出来,都能自报家门。这是分块优化里投入产出比最高的一招,没有之一。
分块优化 ≠ Google的段落级排名,别搞混
这里必须澄清一个高频混淆。有人会问:这跟Google早就有的“段落级排名”(passage ranking)不是一回事吗?
不是。两者长得像,机制完全不同。Google的段落级排名是传统搜索的能力——Google索引你的整页,但在排名时能识别出页面里某一个特别相关的段落,把它单独抽出来排进SERP,哪怕整页主题没那么对口。它的单位仍然挂在“页面”这个URL上,段落只是页面内部的一个加分项。保哥之前专门拆过这套机制,想深入可以看 段落级排名的可抽取块工程。
而内容分块面向的是RAG这套全新架构:内容被切成块、转成向量、存进向量库,检索时块脱离原页面独立参与竞争。它的单位是“块”本身,原页面的URL在向量检索这一步几乎不参与排序,只在最后引用时被找回来当来源标注。
一句话区分:段落级排名是“在一个页面内部挑出最好的段落”,分块检索是“在全网所有块里捞出最相关的块”。前者你优化的是页面结构,后者你优化的是每一块的独立生存能力。两套机制如今同时在跑,所以两边都得照顾——好在底层要求高度一致:结构清晰、每段自洽、答案前置。把内容写成一块块自给自足的小单元,是同时讨好这两套机制的最优解。
外贸独立站怎么把内容改成“自包含块”?实操清单
原理讲完,落到能动手的层面。以下是保哥团队给独立站做GEO改造时,专门针对分块优化的一套清单,外贸站尤其适用。
第一,每个小标题下自成一块。用H2、H3把内容切成主题单一的小节,每节控制在300到500字,正好对应一个理想块的体量。小标题本身用陈述句把这节的结论点出来,而不是只写个名词。
第二,答案前置,别让机器等。每个小节开头第一两句直接给结论或定义,后面再展开论证和案例。因为切块时块的前半部分权重更高,把最该被检索到的信息放在块的开头,命中率最高。
第三,实体全称化,消灭裸指代。通读全文,把“它”“这个”“上述方案”这类跨段指代,尽量替换成具体名词全称。产品名、品牌名、规格型号、专业术语,在每个相关小节里至少完整出现一次。
第四,关键信息别只放在表格或图片里。向量检索吃的是文字。一段核心参数如果只画在图里、或者全塞进一个大表格,切块时这块就成了“半句话加一张机器读不懂的表”——一定要在表格前后用文字把关键结论复述一遍。
第五,FAQ段落天生是好块。一问一答的结构,每个问答对就是一个自包含、答案前置、主题单一的完美块。这也是为什么做GEO的人都在拼命加FAQ——它几乎是为分块检索量身定做的格式。这点在结构化内容格式那篇里展开过,值得对照着改。
举个真实的对照:前面那个工业配件客户,按这套清单把那篇选型长文重排了一遍——把技术参数对比单独提成一个H2小节、开头一句话先给选型结论、表格前补一段文字复述关键差异、全篇把“该型号”改成具体型号名。改完没动一个字的核心观点,三周后在Perplexity和Google AI概览里开始稳定被引,相关长尾问题的引用露出从几乎为零到月均十几次。内容没变好,只是变得“好切”了。
图表、视频这类非文字内容,分块时去哪了
还有一类内容在分块这关吃大亏,却很少有人注意——非文字内容。
向量检索的嵌入模型主要吃文字。一张信息量爆棚的对比图、一段讲得很透的讲解视频、一个能现场算的交互计算器,在纯文本分块的世界里几乎是隐形的。切块时,这些内容要么被整个跳过,要么只留下一个干巴巴的alt文本或文件名。你以为自己交付了满满的干货,机器实际只看到一块空白。
这对外贸独立站是个隐蔽的大坑。很多站为了好看,把最核心的产品参数对比、规格差异、选型决策树全做成了精美的信息图——人看着一目了然,可机器一个数字都没读进去,这一块在AI检索里等于不存在。你最该被引用的硬信息,恰恰锁死在了机器读不到的地方。
解法不是不做图,而是“图文双轨”:每个重要图表、视频的前后,用文字把它的核心结论和关键数据点复述一遍。图和视频留给人看,文字留给机器读,两份内容讲同一件事。具体说,信息图配一段“这张图说明了什么”的文字总结,关键数字直接写进正文;视频配完整的文字转录或要点摘要;alt文本写实质内容(“不锈钢与碳钢法兰在耐腐蚀性上的对比数据”)而不是“图1”“product-image”这种废话。
多模态嵌入模型确实在进步,未来机器或许能直接看懂图、听懂视频。但就当下而言,把视觉和音频信息“翻译”成文字块,仍是确保它们参与检索的唯一可靠办法。记住一条朴素的判据:能被切成文字块的内容,才有资格进AI的引用候选池;进不了文字块的,做得再漂亮也是检索盲区。
怎么验证内容到底有没有被切好?
改完总得知道有没有效。验证分块质量,有几个不需要工程能力就能做的笨办法。
自己当一回分块器。把你的文章每300到400字硬切一刀,然后逐块读:每一块单独看,能不能说清自己在讲什么?有没有一上来就是“因此”“这种情况下”的孤立块?有没有哪块全是代词找不到主语?凡是单独读不通的块,就是检索的隐患,回去补上下文。
拿你的目标问题去问AI。把你这篇文章想覆盖的真实用户问题,逐个拿去问ChatGPT、Perplexity、Google AI概览,看它引用了谁、有没有引到你、引的是你哪一段。如果引到了竞品而没引你,去读竞品被引的那一块——它大概率比你的对应块更自洽、更答案前置。这是最直接的逆向学习。
关注“被引的是哪一块”而非“有没有排名”。AI搜索时代的内容诊断,颗粒度要下沉到块。一篇文章里,可能某一块频繁被引、另一块从不被引——把不被引的块单独拎出来按前面的清单改造,比整篇推倒重来高效得多。
顺带提醒一点:就算你的块切得完美,AI引用也未必立刻跟上。模型的训练截止时间、RAG索引的更新延迟,都会让“改了内容”到“被AI引用”之间有个时间差,这个滞后机制之前单独拆过,见 AI引用滞后的训练截止与RAG索引延迟。别改完三天没动静就慌着推翻,给它一点时间。
中文内容分块,比英文更麻烦在哪
上面引的评测数据大多基于英文,但中文内容做分块优化,有几个英文世界不会遇到的坑,外贸独立站做中文站或多语言站时尤其要留意。
token和汉字不是一回事。分块按token数算,而嵌入模型的分词器里,一个汉字常常占1到2个token,远高于英文里一个token约等于0.75个单词的密度。这意味着同样切512 token,中文实际只装得下300到400个汉字,比你按“字数”估的要短不少。后果就是:中文长段更容易被拦腰切断,你以为一个块能装下的完整论点,实际可能被切成了两块。
中文没有空格这个安全档。英文单词之间有空格,递归字符切分天然有“按空格断”这个最低保障,怎么切都不至于把单词劈开。中文是连续字符流,少了这一档,分块器在中文里更依赖标点(句号、分号、问号)来找安全的下刀点。如果你的中文写作习惯是长句一逗到底、三四行不见一个句号,等于把断点全藏起来了,分块器只能硬切——切在哪全凭运气。所以中文内容里,规范的标点不只是语文问题,是分块友好度问题,该用句号的地方别用逗号凑合。
嵌入模型对中文的支持普遍弱于英文。主流嵌入模型的训练语料以英文为主,对中文语义的编码精度往往略逊一筹。这反过来要求中文块的“自包含”标准要订得比英文更高——同样是上下文模糊的块,中文向量比英文更容易检索偏。换句话说,前面讲的“消灭裸指代、实体全称化”那套,中文内容做起来要更狠一点,容错空间更小。
落地建议很直接:中文内容多用短句短段,把长句拆成几句各自成立的话;关键术语用中文全称,必要时在首次出现处附上英文原词,让中英两种查询都能命中同一个块;标点务必规范,每个完整意思用句号收尾,给分块器留足合法的断点。这些动作单看都很小,但叠加起来,能显著降低你的中文好内容“被切坏”的概率。
分块优化会不会过时?聊聊长上下文的冲击
总有人问:模型上下文窗口都几百万token了,以后是不是不用RAG、不用切块,直接把全文塞进去就行,分块优化岂不是白学?
这个担心可以理解,但短期内站不住。原因很简单:成本和效率。把海量内容全塞进上下文,token费用、推理延迟、注意力稀释三样都扛不住,对要服务海量查询的搜索产品尤其如此。所以检索这一层不会消失,反而在往更精细的方向走——比如代理式RAG,让模型反复检索、反复推理,而不是一次捞完。这意味着块会被检索更多次、参与更多轮推理,块的质量只会更重要不会更不重要。这套演进保哥在 代理式RAG与GEO内容重写里专门聊过。
说到底,分块优化不是某个具体技术的临时技巧,而是“内容要以自包含的最小语义单元被消费”这个底层趋势的具体打法。哪怕将来检索架构再变,“每一段都能独立说清自己”这条原则都不会错——它本来就是好内容的标志,AI只是把这条标准从软建议变成了硬门槛。把内容写成一块块站得住的好砖,墙怎么砌是机器的事,砖好不好是你的事。
关于分块优化的三个常见误解
这个话题热起来之后,市面上的解读鱼龙混杂,有几个误解流传甚广,挨个掰一下。
误解一:把文章拆成超短段就行了。正好相反。块太小会丢上下文,前面Chroma的数据也摆着——小块精度虽高但召回偏低,一句话占一段,机器捞到的全是缺乏支撑的碎片,谁也说服不了。分块优化追求的是“自包含的完整论点”,是让每一块都站得住、说得清,而不是“切得越碎越好”。把一个完整的意思拆成七零八落的短句,是另一种切坏。
误解二:加一堆小标题就等于优化了分块。小标题确实帮分块器找到合法的断点,这一步没错,但它只是骨架。如果每个小节内部仍然指代混乱、答案埋在最后一句、关键实体从头到尾用“它”代替,那切出来的块照样不及格。结构是骨架,每一块的自洽性是血肉,光搭骨架不长肉,机器啃到的还是一具空架子。
误解三:分块是技术团队的事,跟写内容的人无关。这个误解最害人。真正的切块动作确实由抓取方的系统完成,你控制不了切多大、留多少重叠;但切出来的块质量好不好,九成取决于你内容本身的结构和写法。这是少数几个“内容人比工程师更能使上劲”的GEO环节——工程师能做的是补点上下文、调调参数,而决定每一块能不能自圆其说的,是写字的你。这块阵地,别拱手让出去。
说到底,分块优化考验的从来不是你懂不懂向量、会不会调嵌入模型,而是你能不能把一件事,在每一个三五百字的小段落里,都说清楚、说完整、说得不依赖上下文也成立。这本就是一个好作者的基本功,AI搜索只是让这项老掉牙的基本功,第一次直接挂上了流量的钩子。会写的人,其实早就赢在起跑线上了。
常见问题解答
内容分块是我自己要在网站上做的操作吗?
不是。实际的切块动作由抓取你内容的AI系统完成,你无法直接控制对方切多大、留多少重叠。你能做的是“分块优化”——通过内容结构和写作方式,让自己的内容无论被哪种策略切,切出来的每一块都尽量自洽、答案前置、自带上下文。换句话说,你优化的是“可切性”,不是“切”这个动作本身。
一个块大概多少字最合适?
从公开评测数据看,最优区间大致是200到400 token,换算成中文约200到350个汉字,对应一个论点完整的小节。块太小会缺上下文,块太大会混入多个话题稀释相关性。实操上,按小标题把内容切成每节300到500字、主题单一的小节,就基本踩在理想区间里了。
分块优化和加FAQ、加结构化数据是一回事吗?
相关但不等同。FAQ是分块优化的一个极佳载体——每个问答对天然就是自包含、答案前置的完美块;结构化数据(schema)则帮机器理解块的语义类型。但分块优化是更底层的原则,覆盖全文每一段,不只是FAQ区。可以理解为:分块优化是地基,FAQ和schema是建在地基上特别好用的两种结构。
这和Google的段落级排名有什么区别?
段落级排名是传统搜索的能力,Google索引整页、排名时抽出页内最相关的段落,单位仍挂在页面URL上。分块检索面向RAG架构,内容被切成块转成向量独立参与检索,单位是块本身、原页面URL基本不参与排序。前者优化页面结构,后者优化每块的独立生存力。好在两者底层要求一致:结构清晰、每段自洽、答案前置。
为什么块“脱离上下文”这么致命?
因为向量检索把每一块整体压缩成一串语义数字,机器手里只有这一块,不会像人一样往上翻看前因后果。如果一块里全是“它”“这个方案”这类指代,被指代的对象又在别的块里,那这块的向量就编码了一堆没有主语的残句,语义模糊、检索不准。Anthropic的研究显示,给每块补上一段简短上下文说明,能把检索失败率最多降低67%——可见上下文缺失的代价有多大。
长上下文模型普及后,分块还有意义吗?
短期内仍然非常有意义。把海量内容全塞进上下文,成本、延迟、注意力稀释三样都扛不住,搜索产品尤其负担不起,所以检索层不会消失,反而在往代理式RAG这种更精细、检索更频繁的方向走,块的质量只会更重要。更根本地说,“每段都能独立说清自己”本就是好内容的标志,这条原则不会因为窗口变大而失效。
权威参考资料
本文标题:《内容分块优化:AI为什么按“块”而不是按“页”检索你的内容》
本文链接:https://zhangwenbao.com/chunk-optimization-ai-rag-retrieval-geo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0