claude-mem深度解析:给Claude Code装上跨会话的永久记忆

本文目录
- Claude Code为什么会“失忆”,claude-mem怎么补这一刀?
- 它的架构是怎么搭起来的?
- Hook:在你不知不觉时记下一切
- Worker服务:中央调度器
- 双数据库存储
- 它怎么把一整段对话压缩成“记忆”?
- 检索为什么能比传统RAG省10倍token?
- 几个版本下来,它把token省到了什么程度?
- 它和原生CLAUDE.md到底是什么关系?
- 怎么装、怎么配置?
- 性能和许可证这些坑,要注意什么?
- 什么样的人最该装它,什么人没必要?
- 常见问题解答
- claude-mem会不会拖慢Claude Code?
- 它的许可证到底是什么?能商用吗?
- 数据会上传到云端吗?安全吗?
- 有了claude-mem还需要CLAUDE.md吗?
- 它现在还只支持Claude Code吗?
- 怎么安装才是当前正确的方式?
- 记忆库会占很大磁盘吗?
- 它和Git worktree一起用会冲突吗?
- 权威参考资料
摘要:claude-mem是给Claude Code外挂的一套“永久记忆”插件,靠Hook在你和Claude互动时无感捕获过程,用AI把它压缩成结构化的“观察”,下次开新会话再智能注入相关上下文,专治Claude Code跨会话“失忆”。它跑在Bun上,本地用SQLite加Chroma向量库双存储,检索走三层渐进式,号称比传统方案省约10倍token。要提醒的是:这工具迭代极快,截至2026年中已到v13.4.0,许可证是Apache 2.0(不少老文章还在写AGPL),安装也早从插件市场改成了一行
npx claude-mem install。这篇按当前版本把原理、架构、安装配置和取舍讲清楚。
用Claude Code久了,多数人都被同一件事消耗过耐心:昨天花半天跟它捋清楚的项目背景、踩过的坑、定下的方案,今天开个新会话,它又是一张白纸。你只能一遍遍重新交代——这既费时间,也费token。
原生的解法是写一份CLAUDE.md把项目知识固定下来,但它是静态的、要手动维护、还不能搜索。claude-mem想补的正是这块空白:把“工作过程”这种动态记忆自动攒下来。需要说明的是,这是社区开发者的第三方开源项目,迭代非常快,网上能搜到的教程很多还停留在早期版本。保哥按它当前的版本重新核对了一遍,下面这些细节和半年前的说法已经有不小出入。
举个真实的体感场景:一个做跨境独立站的小团队,主力工程师连着几天用Claude Code排查一个支付回调偶发失败的问题,中间试了好几条假设、推翻了两版方案,最后定位到是第三方网关的重试机制和自己的幂等校验打架。这套排查思路价值很高,可惜会话一关就散了。等过两周同类问题在另一个站点复现,新接手的同事又得从零趟一遍同样的坑。装上claude-mem之后,这种排查过程会被自动记成结构化的“观察”,下次相关会话一开,Claude就把当初的关键结论捞回来——团队的踩坑经验第一次有了能复利的载体。这对人手紧、又频繁切换项目的出海团队,价值尤其明显。
Claude Code为什么会“失忆”,claude-mem怎么补这一刀?
根子在于大模型的上下文窗口是有限的。Claude Code的上下文虽然不小,但你让它读几十个文件、跑十几轮工具调用之后,窗口很快就被填满,更早的内容会被挤出去。更要命的是上下文消耗大致随交互次数平方增长——每多一轮,前面所有内容都要再带一遍,所以大约几十次工具调用之后,窗口就接近饱和了。会话一结束,这些上下文更是全部归零,下次得从头来过。
这种“失忆”的代价分两层:一层是时间,你得反复交代同样的背景;另一层是钱,每次重新喂上下文都在烧token。对个人开发者,这是烦;对按量付费、又重度使用的团队,这就是实打实成本。claude-mem要解的,正是这两层一起的痛。
CLAUDE.md能解决一部分,但它的定位是“静态规则手册”——适合写技术栈、目录约定、代码规范这种不怎么变的东西。可你排查一个偶发bug的完整思路、某次架构权衡的来龙去脉,这类动态的工作历史,让你手动一条条记进CLAUDE.md既不现实、文件也会越堆越臃肿。
claude-mem的思路是:既然过程数据这么有价值,那就让机器自动把它捕获、压缩、归档,需要时再精准取回来,全程不用你操心。它和CLAUDE.md不是替代关系,而是各管一摊,这点后面会专门对比。
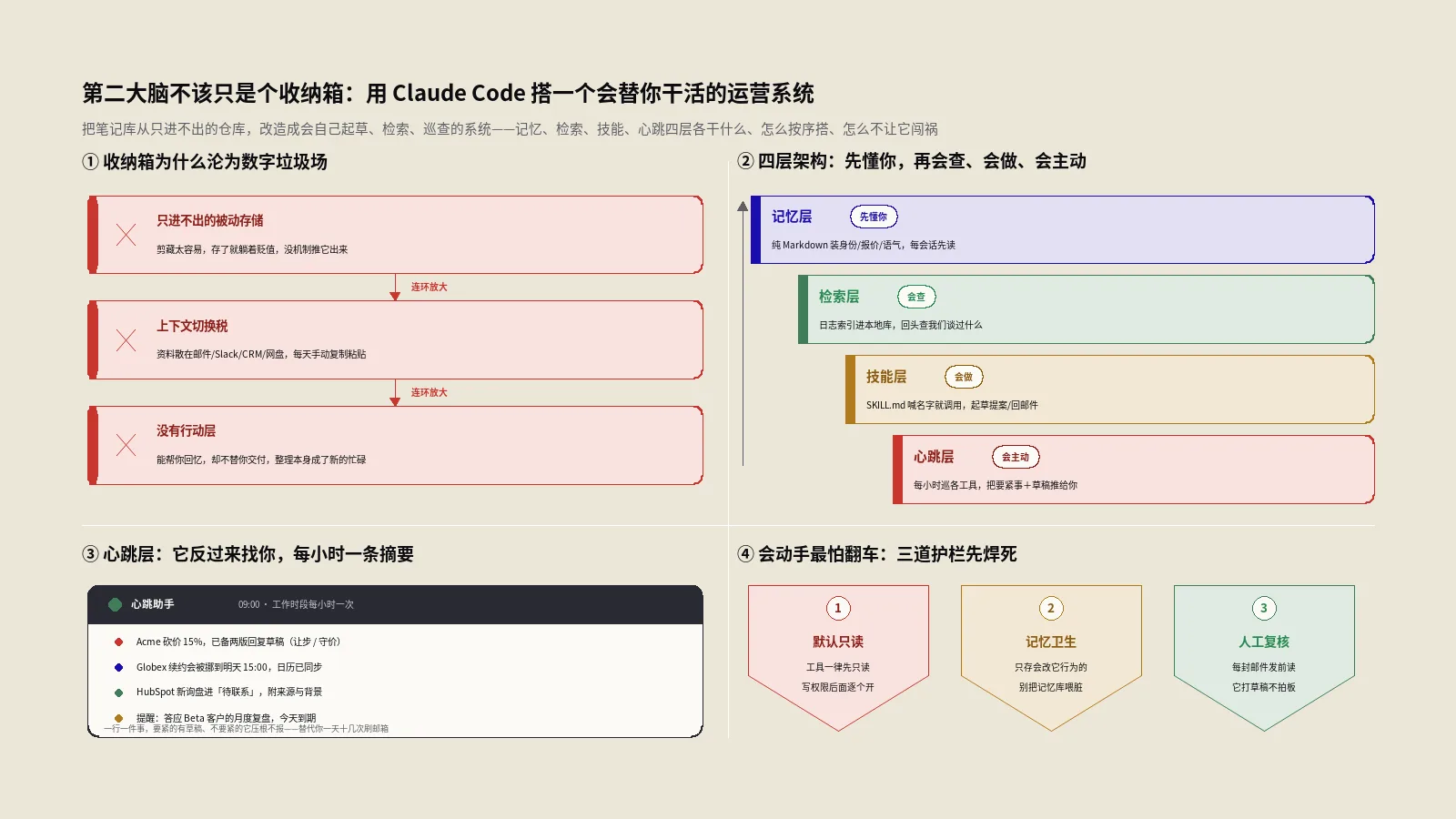
它的架构是怎么搭起来的?
整套系统可以拆成四块协同:一组Hook脚本负责无感捕获,一个常驻的Worker服务负责调度,本地双数据库负责存储,再加上一个供Claude检索的接口层。把它们串起来看,一次完整的记忆循环是这样的:你开始会话,Hook去库里检索相关记忆注入进来;你和Claude你来我往地干活,每次工具调用后Hook把过程发给Worker;Worker调度AI把过程压缩成观察、分别写进两个数据库;会话结束再生成一份摘要。下次再开会话,循环重新开始,只不过这回库里已经攒了上一轮的经验。
这个闭环最妙的地方是它自我增强:你用得越久,库里的记忆越厚,注入的上下文越贴合你的项目,Claude表现得越像一个真正熟悉你代码库的老搭档。下面把四块逐一拆开看。
Hook:在你不知不觉时记下一切
claude-mem挂了一组生命周期Hook,每个都很轻量,在关键节点自动触发,异步发请求、不卡你的操作:
| Hook | 触发时机 | 干什么 |
|---|---|---|
| SessionStart | 会话开始 | 检索并注入相关上下文 |
| UserPromptSubmit | 你发出消息 | 记录输入 |
| PostToolUse | 工具调用之后 | 捕获观察结果 |
| Stop | 一轮回答结束 | 收尾处理 |
| SessionEnd | 会话结束 | 生成摘要 |
这套Hook设计的精髓在于“无感”——它不打断你的工作流,全部异步执行:你照常跟Claude对话、让它干活,捕获在后台悄悄发生,你几乎察觉不到。这和需要你主动维护的CLAUDE.md形成鲜明对比,记忆这件事第一次从“你要记得记”变成了“它自动帮你记”。
这里还有个值得更新的细节:早期版本是五个Hook加一个装依赖的预检,而当前版本里多了个Stop钩子,专门处理每轮回答结束时的收尾,捕获的颗粒度比早期更细。Hook机制本身和Claude Code原生那套同源,想吃透它的运作可以参考Claude Code Hooks完全指南,理解了原生Hook,就明白claude-mem为什么能做到无感捕获。
Worker服务:中央调度器
这些Hook捕获到的东西,统一交给一个常驻的Worker服务处理。它跑在Bun(一个高性能的JavaScript运行时)上,监听本地的127.0.0.1:37777端口,负责会话管理、调度AI去压缩、编排搜索、实时广播状态,还能在崩溃后恢复。注意它只绑在本地回环地址上,不对外开放。
为什么要单独起一个常驻服务,而不是让每个Hook各自为战?因为压缩、向量检索这些活儿有点重,要是塞进Hook里同步做,必然卡住你的会话。抽出一个独立的Worker,Hook只管把数据快速甩过去就返回,重活在后台慢慢消化,这样你的交互才能保持顺滑。它启动时还会分两步走:先快速绑好端口能接活,再在后台慢慢做初始化,避免你一开会话就干等它就绪。这种工程上的取舍,是它能做到“无感”的另一半原因。
双数据库存储
记忆落到本地两个数据库:一个是SQLite,存结构化的观察、会话摘要等,靠FTS5做全文搜索;另一个是Chroma向量库,存语义向量,做相似度匹配。为什么要两个?因为单一搜索方式都有盲区:纯关键词搜,你得记得当初用的确切词,换个说法就搜不到;纯语义搜,又可能把意思相近但其实不相干的东西也捞上来。两者配合,既能按关键词精确命中,也能按语义模糊召回,最后混合排序,召回的准头比单用一种高不少。所有数据都在你本地,不上云,这对在意代码和业务信息不外流的团队是个硬性加分。
它怎么把一整段对话压缩成“记忆”?
claude-mem不会傻乎乎地把原始对话整段存下来——那样既占空间又没法用。它的核心是用AI把过程提炼成一条条结构化的“观察”(observation)。一条观察大概长这样:
{
"type": "discovery",
"title": "发现 API 认证中间件的竞态条件",
"narrative": "排查 /api/users 偶发 401 时,定位到 token 过期未加锁……",
"facts": ["auth 中间件在 token 过期时没有加锁"],
"concepts": ["problem-solution", "gotcha"]
}一条观察大约只占500个token,却把“发现了什么问题、怎么排查的、结论是什么”这些核心洞察都保住了。相比原始对话动辄几千上万token,压缩比能做到10:1甚至100:1。注意它存的不是流水账,而是带类型(是发现、是决策还是踩坑)、带事实、带概念标签的结构化数据——这恰恰是它后面能精准检索的前提,散文式的笔记可没法这么查。
这一步靠AI完成,工具也允许你选不同的引擎来做压缩,各有取舍:
| 引擎 | 特点 | 适合谁 |
|---|---|---|
| Claude(默认) | 压缩质量最高 | 追求效果、不差那点成本的人 |
| Gemini | 有免费额度 | 预算有限、想省钱的人 |
| OpenRouter | 上百种模型可选 | 想灵活实验、对比模型的人 |
这个设计很务实:压缩是个会持续发生的后台动作,让你能把它分流到便宜甚至免费的模型上,主力的Claude额度就能省下来干正事。对成本敏感的团队,把压缩引擎换成Gemini,是个几乎无痛的省钱开关。
检索为什么能比传统RAG省10倍token?
存下来不是目的,能高效取回才是。claude-mem的检索走的是三层渐进式,关键在于“先看目录、再决定要不要展开全文”,而不是一上来就把一堆长文塞进上下文:
- 索引层:先返回紧凑的索引——ID、标题、日期、类型,每条只要50到100个token,让Claude先扫一眼有哪些相关记忆;
- 时间线层:需要理清因果和决策链时,再拉出相关的时间线上下文;
- 详情层:只有真正选中的那几条,才取回完整内容,每条500到1000个token。
这套“按需展开”的打法,相比传统RAG把候选片段一股脑塞进去,能省下约10倍的token。打个比方,它不是把整座图书馆搬到你面前,而是先递给你一张书目卡片,你说要哪几本,它再把那几本抽出来——绝大多数无关的内容,从头到尾都没进过你的上下文。检索本身是关键词(SQLite的FTS5)和语义向量(Chroma)混合排序的,精确匹配和模糊语义两头都顾得上。
一个值得一提的演进:早期它把这套能力做成了九个MCP工具,现在已经收敛成一个Skill来调用,光是工具定义占用的上下文就从两千多token降到了两百多。这是个很典型的“少即是多”优化——工具越多,模型每次都要先读一遍它们的说明,反而占地方;收敛成一个Skill后,既好用又省上下文。
几个版本下来,它把token省到了什么程度?
claude-mem迭代得很猛,而每一版的主线几乎都在围着“同样的记忆,怎么用更少的token喂给模型”打转。把几个关键节点的数字摆出来,最能看清它在优化什么:
| 对比项 | 早期版本 | 当前思路 |
|---|---|---|
| 每次会话上下文注入量 | 约25000token(全量塞) | 约1500token(压缩加渐进式) |
| 检索工具占用 | 九个MCP工具约2500token | 收敛成一个Skill约250token |
| 单条记忆体积 | 原始对话几千上万token | 压缩成观察约500token |
最直观的是第一行:早期版本开一个新会话,光是注入历史记忆就要吃掉约25000token,相当于还没开始干活,上下文就被记忆占去一大块;优化到现在,同样的“工作简报”只要约1500token,省了九成多。这背后是两件事叠加——压缩引擎把每条记忆做小,渐进式检索又只在需要时才展开详情。对重度用户来说,省下的这部分token,等于把更多的上下文窗口留给了真正要解决的问题。理解了这层,你也就明白它为什么值得装:它省的不只是你重新交代的时间,更是每次会话实打实的token开销,这笔账和Claude速率限制里讲的用量逻辑是一脉相承的。
它和原生CLAUDE.md到底是什么关系?
很多人纠结“有了claude-mem是不是就不用CLAUDE.md了”,答案是恰恰相反,两者最佳的姿势是搭配着用。先看本质区别:
| 维度 | CLAUDE.md | claude-mem |
|---|---|---|
| 记忆方式 | 手动编写 | AI自动捕获 |
| 内容类型 | 静态规则 | 动态工作历史 |
| 搜索能力 | 无 | 语义加关键词 |
| token效率 | 文件越大越浪费 | 渐进式按需加载 |
所以合理的分工是:CLAUDE.md放项目级的静态知识(技术栈、规范、原则这些你想让它每次都遵守的硬约束),claude-mem放动态的工作过程(bug排查、架构决策、实验方案这些攒下来的经验)。一个是写死的说明书,一个是自动增长的工作日记,互不挤占。换个角度看:CLAUDE.md回答的是“这个项目的规矩是什么”,claude-mem回答的是“我们之前在这个项目上踩过什么、决定过什么”。前者靠你定,后者靠它攒,缺了哪一个,AI对你项目的理解都是残缺的。关于CLAUDE.md本身怎么写得精炼又管用,可以看CLAUDE.md记忆管理指南,那篇也讲了官方原生的自动记忆机制,可以和claude-mem对照着理解。把这两层记忆都搭好,AI才算真正“认识”你的项目,而不是每次都当新人重新认。
怎么装、怎么配置?
这部分是和老教程出入最大的地方,务必按当前版本来。早期是从插件市场装,现在官方主推一行命令:
npx claude-mem install它会自动把缺的依赖(包括Bun)补齐。如果你习惯用Claude Code的插件市场,那条路也还在:
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem值得一提的是,当前版本早已不只服务Claude Code一家——通过--ide参数,它也能装到Gemini CLI、OpenCode等其它命令行工具上,生态扩得比早期宽不少。
关键配置项放在~/.claude-mem/settings.json,常用的几个:
| 配置项 | 默认值 | 说明 |
|---|---|---|
| CLAUDE_MEM_PROVIDER | claude | 用哪个AI引擎做压缩 |
| CLAUDE_MEM_CONTEXT_OBSERVATIONS | 50 | 每次注入多少条观察(1到200) |
| CLAUDE_MEM_WORKER_PORT | 37777 | Worker端口 |
| CLAUDE_MEM_LOG_LEVEL | INFO | 日志级别 |
装好后,浏览器打开http://localhost:37777就有一个可视化界面,能看当前会话的观察流、翻历史会话、搜记忆库,还能调参数。
隐私这块它也想到了:不想被记下来的敏感内容,用<private>标签包起来,那段就不会进记忆库。涉及密钥、客户数据这类东西,记得主动包一下——虽然数据本来就只存本地,但记忆库会被翻来覆去地注入和检索,敏感信息少进去一点总是更稳妥。
配置这块的取舍也值得说一句。CLAUDE_MEM_CONTEXT_OBSERVATIONS这个值(每次注入多少条观察)不是越大越好:调高了召回更全,但注入占的token也更多;调低了省上下文,又可能漏掉相关记忆。默认的50对多数项目够用,记忆库特别大、或者发现注入开销偏高时,再往下调。压缩引擎CLAUDE_MEM_PROVIDER则可以按前面说的,成本敏感就切到Gemini。把这两个调顺了,省钱和好用基本就平衡住了。
性能和许可证这些坑,要注意什么?
有几个容易踩或容易被老资料误导的点,单独拎出来说。
许可证:是Apache 2.0,不是AGPL。这是更正得最值得强调的一条。不少早期文章写它是AGPL-3.0,那会让很多想在商业/生产环境里用的团队望而却步——因为AGPL是“传染性”许可证,一旦你把它作为网络服务部署,可能被要求连带公开自己的相关修改,这对闭源的商业项目是个不小的顾虑。但项目早已把主许可证换成了Apache 2.0,对商用和嵌入到自家产品里都友好得多,开发者也明说这是为了让它能被企业和生产系统放心采用。一句话:如果你之前因为“听说是AGPL”就把它拉黑了,现在真的可以重新评估。这也提醒我们,引用第三方开源工具的关键信息时,许可证这种会随版本变的东西,一定要回原仓库核对最新的,别照抄二手资料。
Endless Mode仍是Beta,有延迟代价。它有个突破上下文窗口极限的Endless Mode,思路是给Claude装上一套仿生的两层记忆:当前在用的“工作记忆”留在上下文窗口里(压缩过的观察,每条约500token),完整的原始输出则归档到磁盘的“归档记忆”,要用时再调。具体到操作上,是工具调用之后等AI把完整输出压成观察、再用压缩版替换掉原始内容,从而把token消耗从随调用数平方增长拉回到线性,工具调用容量能翻约20倍。
但代价实打实:每次工具调用会多出几十秒的延迟(它得等AI压缩完),而且这功能目前还在Beta通道,要在Web界面的设置里手动开。所以要不要用,本质是个权衡——你是在做那种需要上百次工具调用、普通模式根本撑不住的超长任务,那这点延迟换来的容量值;如果只是日常的中短任务,普通模式的顺滑体验更重要,没必要开。保哥的建议是默认关着,真碰到撑爆上下文的硬任务再临时开。
数据安全:全本地,不上云。所有记忆都存在本地的~/.claude-mem/目录,Worker也只监听本地回环地址,不往外传。磁盘占用方面,SQLite通常几十MB,向量库也在可接受范围,现代硬盘不成问题。它和Git worktree也兼容,多个worktree能共享统一的记忆上下文——并行开发的玩法可以结合Claude Code Worktree并行指南一起用。
什么样的人最该装它,什么人没必要?
工具再巧,也得对上场景才值得折腾。保哥的判断是这样的。
最该装的几类人:一是长期维护同一个或几个大项目、经常需要回溯“当初为什么这么改”的人,记忆复利在你身上回报最高;二是频繁切换项目、靠脑子记不过来的多线程选手,自动捕获帮你卸下记账负担;三是按量付费、又重度使用的团队,省下的token注入开销日积月累很可观;四是想把个人或团队的踩坑经验沉淀成可检索资产、而不是散落在一次次会话里的人。
可以先不急的几类人:如果你只是偶尔用Claude Code打打杂、单次任务做完就走,跨会话记忆对你意义不大,原生的CLAUDE.md加手动整理就够了;如果你对在本地常驻一个后台Worker服务、多占一点磁盘和内存有顾虑,也得先掂量一下这份开销值不值;还有就是你所在环境对第三方工具引入有严格审计要求的,记得先走完合规流程——好在它现在是Apache 2.0许可证,这一关比早期的AGPL好过多了。
也得实话实说它的几点不足,免得你抱着不切实际的期待去装。一是它毕竟是社区第三方项目,迭代快是好事,但也意味着版本之间行为可能有变化,跟着官方仓库的更新走才不踩坑;二是Endless Mode那几十秒的延迟代价是真实的,不是所有人都受得了,常规场景别轻易开;三是记忆库的质量取决于压缩引擎,如果你为了省钱把引擎换成能力弱的模型,攒下来的观察可能不够准,检索时反而帮倒忙。工具是好工具,但它替代不了你对项目本身的理解——它存的是你的经验,不是凭空给你长经验。
一个稳妥的上手节奏:先在一个你最熟、最常回头的项目上装来试两周,看它注入的记忆是不是真的帮你省了重复交代。觉得顺手,再推广到其它项目和团队;觉得鸡肋,卸载也干净。别一上来就全家桶铺开。
最后把这篇收一下。claude-mem解决的是一个真问题——Claude Code跨会话的失忆,以及由此带来的时间和token双重浪费。它的解法也很巧:Hook无感捕获、AI压缩成观察、三层渐进式检索,把记忆这件事从“你得记得记”变成“它自动帮你记、需要时精准还给你”。但比工具本身更重要的,是别被过时资料带偏——它现在是v13.4.0、是Apache 2.0许可证、装法是一行npx命令、还支持多个IDE,这些都和半年前的说法不一样。先在一个熟项目上小范围试,配合写好的CLAUDE.md,让静态规则和动态记忆各就各位,你会真切感到Claude越来越像个懂你项目的老搭档,而不是每次都要重新认人的新人。
常见问题解答
claude-mem会不会拖慢Claude Code?
正常模式下不会,所有Hook都是异步执行,不阻塞你的操作。唯一明显增加延迟的是Beta阶段的Endless Mode,每次工具调用会多出几十秒,那是它压缩完整输出的代价,常规使用用不到这个模式。
它的许可证到底是什么?能商用吗?
当前版本是Apache 2.0,对商用和嵌入生产系统都友好。网上有些老文章写的AGPL-3.0已经过时,如果你之前因为许可证顾虑放弃过,现在可以重新评估。
数据会上传到云端吗?安全吗?
不会。所有数据都存在本地的~/.claude-mem/目录,Worker服务只监听127.0.0.1本地回环地址,不对外开放。敏感内容还能用private标签排除在记忆之外。
有了claude-mem还需要CLAUDE.md吗?
需要,两者最好搭配用。CLAUDE.md放静态的项目规则和硬约束,claude-mem放动态的工作过程和经验。一个是写死的说明书,一个是自动增长的工作日记,分工不重叠。
它现在还只支持Claude Code吗?
不止了。当前版本通过安装参数也能装到Gemini CLI、OpenCode等其它命令行工具上,生态比早期宽了很多。但它最成熟、最主力的适配对象仍是Claude Code。
怎么安装才是当前正确的方式?
官方主推一行命令npx claude-mem install,会自动补齐包括Bun在内的依赖。也保留了插件市场的装法:先add插件市场再install。早期教程里那套纯插件市场流程依然能用,但npx这条更省事。
记忆库会占很大磁盘吗?
通常不会。SQLite那部分一般就几十MB,Chroma向量库稍大一些但也在可接受范围,现代硬盘完全不成问题。它压缩比很高,存的是观察而非原始对话,所以即便用很久,体积增长也比想象中慢。真担心的话,可视化界面里能看到记忆库的规模,心里有数。
它和Git worktree一起用会冲突吗?
不冲突,当前版本支持多个worktree共享统一的记忆上下文。也就是说你在不同worktree里并行开发,攒下的经验是互通的,不会各记各的、互相看不见。这点对常开多个worktree并行干活的人很友好。
权威参考资料
本文标题:《claude-mem深度解析:给Claude Code装上跨会话的永久记忆》
本文链接:https://zhangwenbao.com/claude-mem-deep-dive.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0