拼音转换工具怎么用?把中文标题转成能用的URL slug,多音字才是真坑
本文目录
- 这个拼音转换工具,到底能做什么?
- 它支持哪些输出形式?
- 它是怎么转的,纯前端还是上传服务器?
- 这工具怎么用最顺手?
- 最该先记住的坑:多音字它会读错,对吧?
- 为什么它的多音字处理注定不准?
- 中文转URL slug,到底该不该用拼音?
- 拼音和英文翻译做slug,到底哪个更好?
- 拼音slug用中横线还是下划线、大小写怎么定?
- 它能处理人名和姓氏吗?
- 生僻字、繁体字、儿化音它都认吗?
- 声调符号它标得准吗?
- 一个国风茶具出海站,怎么用它把中文标题转成可用的URL slug?
- 拼音URL对百度和谷歌,到底有没有SEO价值?
- 数字声调和符号声调,分别该用在哪?
- 拼音汉字对照模式,主要用在什么场合?
- 拼音重名撞了slug,除了手动加词还有别的办法吗?
- 汉语拼音、注音符号、威妥玛拼音,工具认哪种?
- 给中文数据库做拼音排序和检索,怎么用它?
- 把整篇长文章转拼音,性能和体验上要注意什么?
- 拼音转换和国际化,还有哪些场景用得上?
- 用它转拼音,最容易栽的几个坑怎么提前绕开?
- 常见问题解答
- 权威参考资料
摘要:这个拼音转换工具,核心就一件事:把中文字符转成对应的汉语拼音。你给它一段中文,它逐字查内置的拼音字典,输出带声调符号的nạ hǎo、数字声调的ni3 hao3、不带声调的ni hao,还能改大小写、换分隔符——其中换连字符那一档ni-hao正是给做URL slug用的。整个转换在你浏览器本地用JavaScript跑,字典也嵌在页面里,不联网、不上传,隐私上很干净。它最实用的场景就是把中文标题、品牌名转成拉丁化的URL slug或做国际化辅助。但有一条边界必须先钉死:它是逐字查表、取每个字最常见的那一个读音,完全不看上下文、也没有词库分词——所以多音字它必然读错,"重庆"的"重"、"银行"的"行"、"长大"的"长"它都只会给固定的那个音,做人名地名的slug尤其危险。还有几条小边界:它不做繁简转换、不处理姓氏特殊读音、不标儿化轻声、超出常用汉字区的生僻字会显示问号。把它当"批量出拼音草稿、再人工校对多音字"的助手,它很顺手;指望它一键给出零差错的拼音,尤其是人名地名,会翻车。
做中文内容出海、或者给中文站做国际化,迟早会撞上一个具体问题:中文怎么变成URL里能用的拉丁字符。一篇标题叫"茶具选购指南"的文章,URL总不能直接塞中文(塞了会被编码成一长串看不懂的百分号乱码),于是要么转拼音cha-ju-xuan-gou-zhi-nan,要么翻译成英文。把中文转拼音,就是这道工序里最常走的一条路。
拼音转换工具干的,就是把中文字符批量翻译成拼音。你丢一段中文进去,它把每个字的拼音拼出来,再按你要的形式(带不带声调、什么分隔符、大小写)排好。这篇我们团队就把它怎么用、那几种输出形式各有什么用、它最致命的多音字短板从哪来、中文转URL slug到底该不该用拼音、以及它在繁简、姓氏、生僻字上的边界,一次讲透——尤其是多音字这个坑,不讲清楚很容易拿它去坑了自己的URL。
这个拼音转换工具,到底能做什么?
先把它的本职说清。它做的是单向的"中文转拼音":输入中文,输出拼音。你给它"你好",它给你ni hao;给它"百度搜索",它给你bai du sou suo。它不做反向的"拼音转中文",也不做翻译,就是把汉字一个一个对应到拼音。
它的工作方式是逐字查表。它内置了一张拼音字典,覆盖大约两万个常用汉字,转换时把你输入的每个汉字拿去字典里查它的拼音,再拼成结果。这张字典嵌在页面里,转换全在你浏览器本地完成,所以速度快、不联网,输入的中文也不会传到任何服务器——这点对处理一些不便外传的内容是个实打实的好处。
理解它"逐字查表"这个根本机制很关键,因为它的所有优点和所有坑都从这里来。优点是简单、快、隐私好;坑是它眼里只有一个一个孤立的字,看不到字与字组成的词,更看不懂上下文——这正是它处理多音字必然出错的病根,后面会专门展开。先记住:它是个"逐字翻译器",不是"懂中文的理解器"。
它支持哪些输出形式?
把它的输出花样盘清。同一段中文,它能按好几种形式输出,组合起来挺灵活。
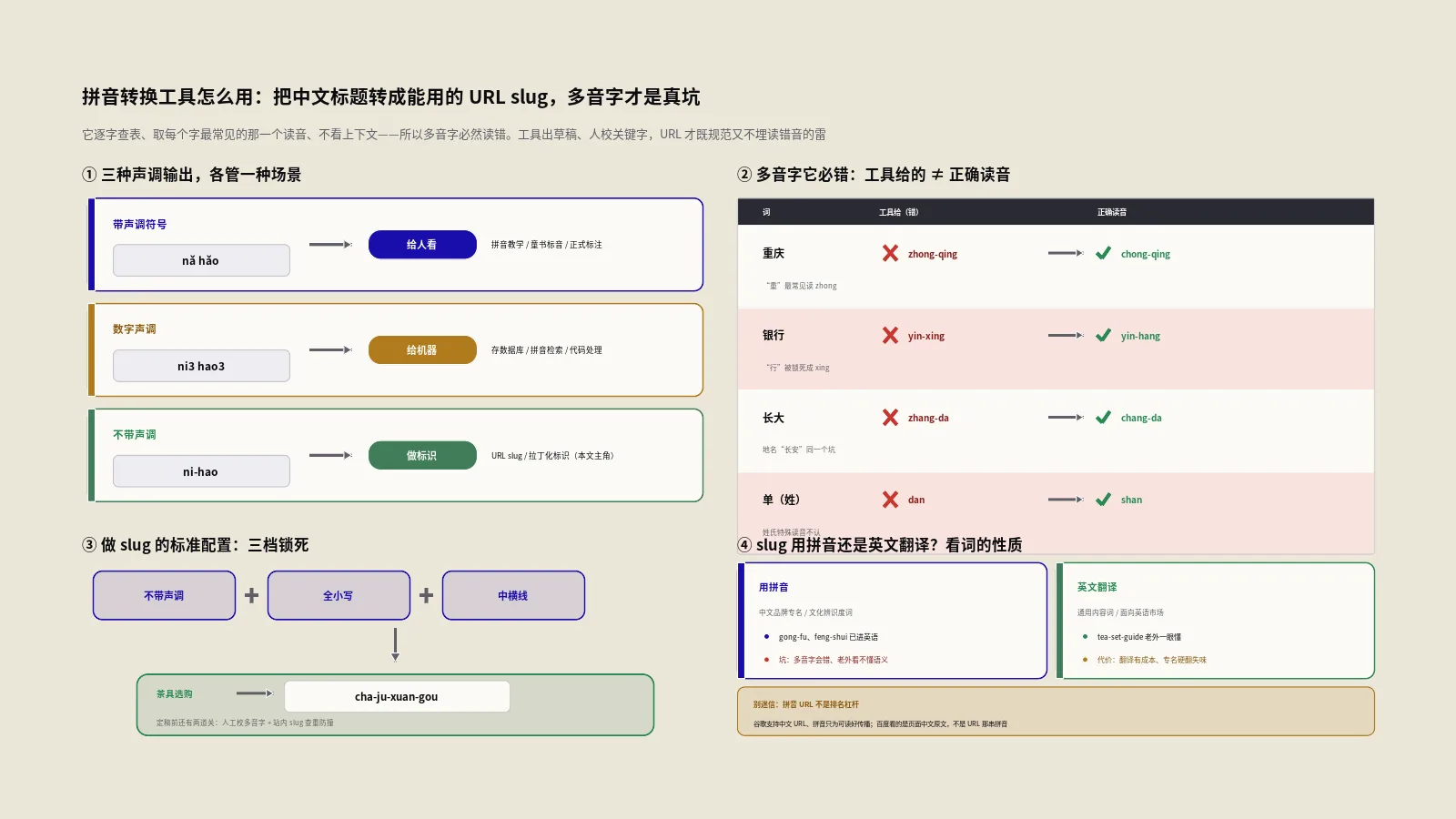
第一维是声调。它有三种:带声调符号的,把声调标在元音上,像nạ hǎo,最像正规拼音;数字声调的,用数字表示声调,像ni3 hao3,适合程序处理或不方便显示符号的场合;不带声调的,纯字母ni hao,做URL slug、做拉丁化标识用的就是这一种,因为URL里不能带声调符号。维基百科的汉语拼音词条说明,汉语拼音是标准汉语最通用的罗马化系统,用四个变音符号ā á ǎ à标声调,也可以用数字1到4表示,这工具的三种声调形式正对应这套规则。
第二维是大小写:全小写、首字母大写、全大写三种,注意全大写时声调符号会失效(因为没有带声调的大写字母)。第三维是分隔符:字之间不加分隔、用空格、用中横线、用下划线,四选一。还有一种特别的"拼音汉字对照"模式,把汉字和它的拼音上下对齐展示,适合教学或核对。这几维自由组合,常用的几个落点是:要正规拼音就"带声调符号+空格",要URL slug就"不带声调+中横线+全小写",要程序里用就"数字声调+下划线"。
它是怎么转的,纯前端还是上传服务器?
这一点和隐私相关,值得明确。它是纯前端的:拼音字典以JavaScript对象的形式嵌在页面里,转换逻辑也是前端的JavaScript,整个过程在你浏览器本地跑完,全程不向服务器发任何请求。它源码里虽然也带了一段后端PHP,但HTML这套是能独立完整工作的,前端转换根本用不到后端。
这带来几个实打实的好处。一是隐私:你输入的中文不出本机,处理涉密的人名、未公开的产品名这类内容时很安心。二是速度:本地查表没有网络往返,转换是瞬时的。三是离线可用:页面加载完,断网也能继续用。
代价是那张嵌进页面的字典让页面体积大了一截——光字典数据就有几十KB。但对一个查拼音的工具来说,这个代价换来的纯本地、零上传,是划算的。和那些把内容发到服务器处理的格式化工具相比(比如前面提过的货币、日期那类走后端的),这个纯前端的拼音工具在隐私上明显更让人放心。理解它纯前端这个底子,你也就明白它的字典是固定打包的、不会动态更新,能转什么不能转什么,在它打包那一刻就定死了。
这工具怎么用最顺手?
把它用顺,主线是"贴中文、选形式、出拼音、人工校多音字"。实战流程如下。
- 把要转的中文贴进输入框。整段标题、一串品牌名、一篇短文都行,它对输入长度没硬限制,非汉字字符(英文、数字、标点)会原样保留不动。
- 按用途选好声调、大小写、分隔符三档。做URL slug就选"不带声调+全小写+中横线",做正规拼音标注就选"带声调符号+空格",按场景配。
- 读输出结果,重点盯多音字。这是最该养成的习惯——结果出来别急着用,先逐个检查有没有多音字被读错的,尤其人名、地名、专有名词,这些最容易栽。
- 把读错的字手动改对。工具给的是"最常见读音"的草稿,碰上"重庆"被读成
zhong、"长安"的"长"读成zhang这种,手动把那个字的拼音改成正确的。 - 校对无误再复制走,做slug还要单独查重。确认拼音都对了再复制;如果是拿来做URL slug,还要确认这个slug在你站内不和别的页面撞,撞了得手动加区分。
这套流程里,第3、4步的人工校对不是可选项,是必须项。工具帮你把九成不会读错的字批量转好,省掉大量机械劳动,但那剩下一成的多音字,必须靠你这双懂中文的眼睛兜住。摸清这条主线,剩下的关键全在于理解它为什么多音字必然出错、以及slug到底该怎么做——这正是接下来要展开的。
最该先记住的坑:多音字它会读错,对吧?
这是整篇最该先钉死的一点。这个工具处理多音字必然会出错,不是偶尔失手,是机制上注定的——它逐字取每个字最常见的那一个读音,完全不看上下文。
汉语里多音字极多,一个字在不同词里读音不同,得靠上下文判断。"重"在"重要"里读zhong、在"重新"里读chong、在"重庆"里读chong;"行"在"行走"里读xing、在"银行"里读hang;"长"在"长短"里读chang、在"长大"里读zhang;"和"在"和平"里读he、在"和面"里读huo。这些读音的切换,人靠的是认出这是哪个词、在什么语境里。
而这个工具眼里只有孤立的字,它查"重"字,字典给它一个固定的最常见读音(比如zhong),无论这个"重"出现在"重要"还是"重庆"里,它都输出zhong。所以"重庆"会被它转成zhong qing而不是正确的chong qing,"银行"会被转成yin xing而不是yin hang。工具自己的说明里其实也诚实承认了这点:纯客户端实现没法做上下文分析,多音字可能不准。这不是bug,是它的设计就决定了的。
为什么它的多音字处理注定不准?
再往深挖一层,看看为什么从机制上它就不可能把多音字处理对。这要从它字典的构建方式说起。
它的字典里,一个汉字其实可能对应多个读音条目——比如"行"字,理论上字典数据里可以同时有xing和hang。但它在初始化字典时有个规则:每个字只保留第一次遇到的那个读音,后面再遇到同一个字的其它读音,直接跳过。所以"行"字最终在它的查询表里只剩一个音,另一个音被丢掉了,查的时候根本取不到。
有意思的是,这种"取第一个、最常见读音"的做法,和权威字符数据库的设计思路其实是一致的,只是用途不同。Unicode的Unihan汉字数据库规范就明确记录,很多汉字有多个普通话读音,它的拼音字段会按"最常用程度"排序、把最常见的读音列在最前。也就是说,"一个字多个读音、最常见的排第一"是汉字的客观事实,权威数据库都这么记。工具取了"第一个最常见读音",对孤立的字而言是合理的默认,但问题在于:真实文本里的字从来不是孤立的,它在词和句子里,正确读音常常不是那个"最常见"的默认值。
要真正解决多音字,工具得有词库、能分词、能根据上下文选音——比如认出"银行"是个词、整体读yin hang。但这个工具没有词库、不做分词,它只会一个字一个字地查那张"每字一音"的表。所以它的多音字短板是结构性的,不是加几个特例能补全的。明白了这层,你就知道为什么对它的多音字结果必须人工复核,也知道这不是工具偷懒,而是纯查表方案的天花板。
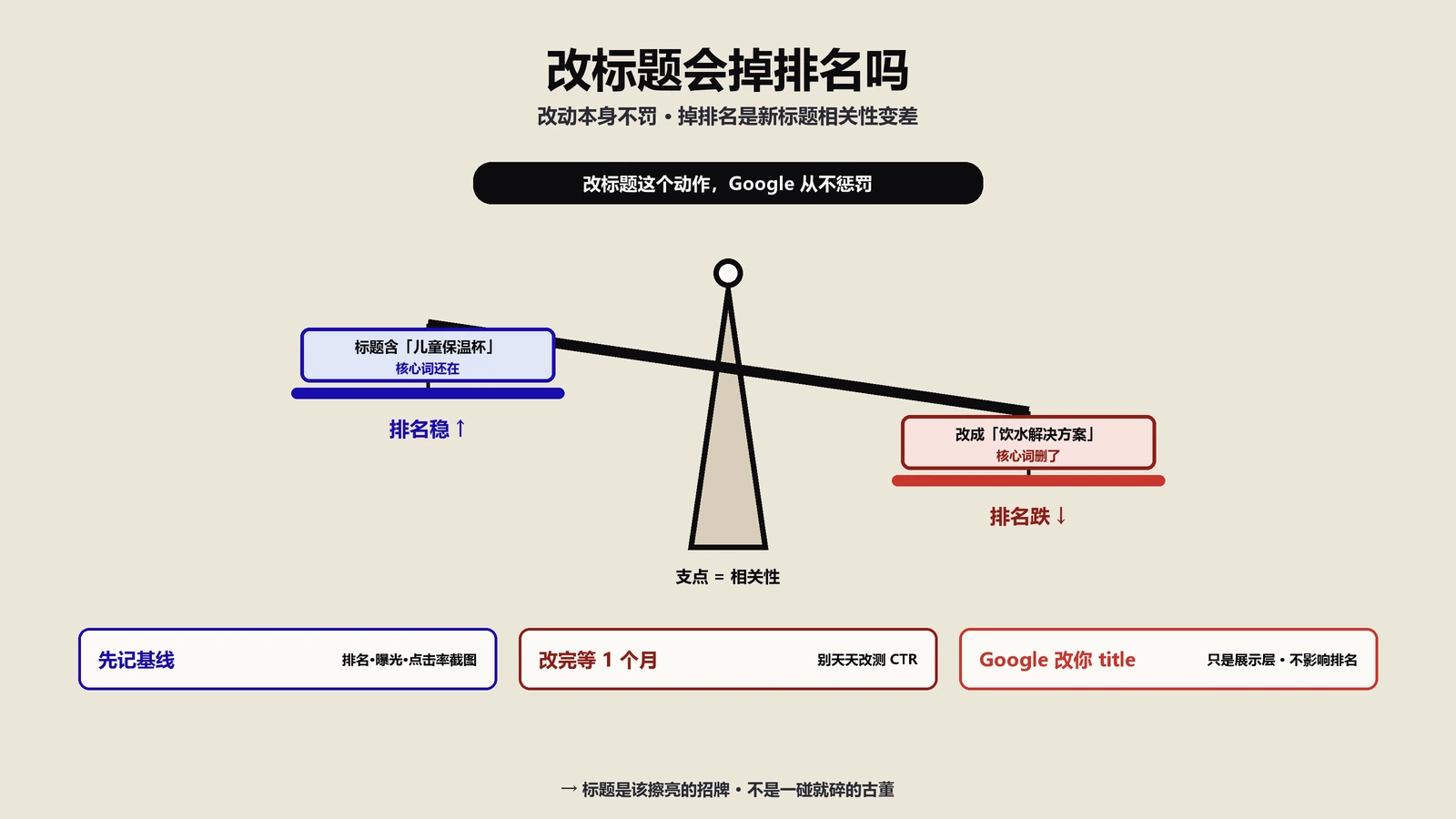
中文转URL slug,到底该不该用拼音?
这是这工具最主要的SEO用途,也最值得好好掰扯。中文标题要变成URL,转拼音是常见做法,但该不该用、怎么用,有讲究。
先说为什么要做这步。谷歌的URL结构最佳实践文档推荐URL里用"可读的词"而不是一长串无意义的ID数字,因为可读的URL对用户和搜索引擎都更友好。中文直接放URL里会被百分号编码成一长串乱码(像%E8%8C%B6%E5%85%B7这样),既不可读、复制传播也难看。把"茶具"转成cha-ju放进URL,至少是拉丁字符、能读出音、比一堆百分号强。这是拼音slug的价值所在。
但有几个前提得清楚。第一,谷歌其实是支持非ASCII字符URL的——你直接用编码后的中文URL,谷歌能正常处理,只是显示出来是百分号串。所以拼音不是非用不可,它更多是为了"好看、好读、好传播",不是SEO的硬要求。
第二,也是最要命的,拼音slug最容易栽在多音字上:一个含人名、地名或多音字的标题,工具转出来的slug可能读音是错的,比如把"重庆火锅"转成zhong-qing-huo-guo,这个错误的slug一旦定下来、被收录了,再改就要做跳转,很麻烦。所以用工具转slug,多音字的人工校对是绝对不能省的一步。第三,slug还得查重,同站内不同页面的slug不能撞。
拼音和英文翻译做slug,到底哪个更好?
定了要把中文标题拉丁化做slug,其实有两条路:转拼音,或者翻译成英文。这俩各有利弊,该选哪个值得掰一掰,不是无脑选拼音。
拼音的好处是直接、保留原读音、对中文品牌有辨识度——"功夫"的gong-fu、"风水"的feng-shui这类已经进入英语的词,拼音反而比翻译更地道。它的坏处前面讲透了:多音字会错、对非中文用户来说zhong-guo这串字母没有任何语义(老外不知道这是"中国")、还可能撞slug。
英文翻译的好处是对目标市场用户有语义——做英文站给英语用户看,tea-set-guide(茶具指南)比cha-ju-zhi-nan让老外一眼懂得多,URL里的英文词还可能贴合用户搜索的英文关键词,这对面向英语市场的SEO是实打实的加分。它的坏处是翻译有成本、有时一个中文词没有简洁贴切的英文对应、品牌专名硬翻反而失了味道。
所以实用的判断是:面向英语市场、追求URL语义和英文关键词贴合,优先用英文翻译;做中文品牌专名的拉丁化、或保留东方辨识度,用拼音。很多成熟的出海站是混用的——通用内容词翻译成英文,品牌名和特色文化词用拼音。打个比方,一个国风茶具站,介绍性文章的slug用英文翻译贴合老外的搜索词,而像"盖碗""功夫茶"这类没有贴切英文对应、又承载文化辨识度的专名,用拼音保留原味,两条路按词的性质分着走。
工具在这套策略里负责把该用拼音的那部分转好,但"这个词到底该翻译还是该拼音"的判断,是你做URL策略时要拍的板。拼音不是唯一答案,也不是默认答案,它是混合策略里专门处理"中文专名拉丁化"那一档的趁手工具。想清楚每个词该走哪条路,再让工具去执行拼音那部分,URL才既规范又对用户友好。
拼音slug用中横线还是下划线、大小写怎么定?
定了用拼音做slug,还有几个格式细节要拍对,不然slug做得不规范,照样影响可读性和SEO。
最该注意的是分隔符:用中横线,别用下划线。谷歌的URL结构文档明确建议用中横线(-)而不是下划线(_)来分隔URL里的单词,因为中横线能帮用户和搜索引擎更好地识别出一个个独立的概念,而下划线在编程习惯里常表示"这几个应该连在一起",语义正好相反。所以工具的分隔符档要选中横线那一档,把"茶具选购"转成cha-ju-xuan-gou,别选下划线。
大小写上,URL里习惯用全小写,所以选工具的"全小写"档。一来URL大小写在某些服务器上是敏感的,统一小写能避免大小写不一致导致的重复URL问题;二来全小写的slug更整洁、更符合通行习惯。声调当然是不带的——URL里放不了声调符号,必须用纯字母。
所以做slug的标准配置就是"不带声调+全小写+中横线"这一组。把这组配置固定下来,工具出来的就是格式规范的slug草稿,剩下的就是前面反复强调的两件事:人工校多音字、查重防撞。中文内容的拉丁化处理之外,简繁转换是另一类常见的中文本地化需求,想一起搞清可以看我们团队的中文简繁转换工具教程。
它能处理人名和姓氏吗?
这个问题单独拎出来,因为人名是拼音转换里最容易出大错的地方,而工具在这块的短板尤其明显。简单说:它不处理姓氏的特殊读音,转人名很容易错。
中文里不少姓氏的读音和这个字作普通字时不一样,是典型的多音字,而且姓氏读音往往不是那个"最常见"的默认音。"曾"作姓读zeng、作"曾经"读ceng;"单"作姓读shan、作"单独"读dan;"解"作姓读xie、作"解决"读jie;"仇"作姓读qiu、作"仇恨"读chou;"区"作姓读ou、作"地区"读qu。这些姓氏读音,懂的人一看名字就知道,工具却只会给那个最常见的非姓氏读音。
因为工具没有姓氏库、也不做"这是个人名"的识别,它把"曾国藩"老老实实转成ceng-guo-fan(错,应是zeng),把"单晓"转成dan-xiao(错,姓单应是shan)。这意味着,凡是涉及人名的slug或拼音标注,工具的结果几乎一定要人工核对,尤其是那些有姓氏特殊读音的姓。做用户名转拼音、做作者页URL、做人物专题这类涉及真实姓名的场景,别信工具的一遍结果,一个一个核对姓氏读音是基本功。这也再次印证那条主线:工具出草稿,人校关键字。
生僻字、繁体字、儿化音它都认吗?
除了多音字和姓氏,还有几类字符的处理边界得说清,免得你以为它无所不能。
先说生僻字。它的字典覆盖的是常用汉字区,大约两万个字,这个范围里的字基本都能转。但汉字总量远不止这些,那些收在扩展区的生僻字、异体字,它的字典里没有,碰上会显示成问号或原样留着,转不出拼音。日常内容里这种字极少,但要是你处理的是古籍、生僻人名、专业术语里的冷字,得有心理准备它认不全。
再说繁体字。它的字典里同时包含简体和繁体字的拼音,所以繁体字也能转出拼音——但要分清,这是"繁体字转拼音",不是"简繁转换",它不会把简体字转成繁体字、也不会反过来。你给它繁体它给你繁体字的拼音,给它简体给你简体字的拼音,字形它不动。最后是儿化音和轻声:它不做特殊处理,"花儿"的儿化、轻声字的弱读,它都按普通读音给,标不出儿化和轻声的特殊性。这些边界叠加起来看,结论还是那句:它能把绝大多数常规中文转成像样的拼音草稿,但凡涉及生僻、姓氏、多音、儿化这些"非常规"情形,都需要人来把最后一关。
声调符号它标得准吗?
前面讲了一堆它不准的地方,这里说个它做得对的:声调符号标注的位置,它是按规则正确处理的。这点值得肯定,免得你以为它哪儿都不行。
汉语拼音标声调有套规则:一个音节里有多个元音时,声调符号该标在哪个元音上是有讲究的,不是随便标。规则大致是:有a或e就标在a或e上;没有a、e但有ou就标在o上;其余情况标在最后一个元音上。比如hao标在a上成hǎo、jiu标在u上、gui标在i上。这套规则工具实现得是对的,带声调符号输出时,符号位置基本都标得准。
所以要区分看:工具的读音选择(是哪个音)在多音字上会错,但它对一个给定读音的声调符号位置处理是规范的。也就是说,只要那个字的读音它取对了(绝大多数非多音字都对),那它标出来的带声调拼音就是正规、位置正确的。这让它在"给常规文本批量标注规范拼音"这件事上挺好用——做拼音学习材料、给一段没多音字的文本标音,它出来的东西是可以直接用的。把它的长处(规范标注常规字)和短处(多音字读音选择)分开评价,才能用对地方。
一个国风茶具出海站,怎么用它把中文标题转成可用的URL slug?
讲再多规则,不如顺一个真实场景。一个做国风茶具的出海站,内容偏文化向,有一批中文标题的文章要发英文站,运营决定URL用拼音slug(保留东方韵味、也比英文翻译更贴品牌调性),这就得用工具批量转、再人工把关。
第一步批量转。把一批标题贴进工具,配置选定"不带声调+全小写+中横线"这组做slug的标准配置,一次性把几十个标题的拼音slug草稿生成出来。像"盖碗茶冲泡"转成gai-wan-cha-chong-pao、"宋代点茶"转成song-dai-dian-cha,大部分常规字它转得又快又对,省去逐字敲拼音的功夫。
第二步逐条校多音字,这是重头戏。运营拿着草稿一条条过,专挑多音字和专有名词:有个标题是"长兴紫砂","长兴"是地名,"长"在这里读chang,工具转的恰好对;但另一篇"重庆沱茶",工具把"重庆"转成了zhong-qing,错了,手动改成chong-qing;还有篇讲制茶人的"单师傅的手艺","单"作姓读shan,工具给的dan是错的,改过来。这一步把工具读错的全揪出来纠正。
第三步查重定稿。校完读音,再确认这些slug在站内不和已有页面撞——发现"茶道"和"茶到"两个不同标题都转成了cha-dao,撞了,手动给其中一个加个区分词。全部校对查重无误,slug才定下来写进URL。整套流程里,工具承担的是"把几十个标题的拼音草稿批量出好"这段最费机械劳动的活,而多音字校对、姓氏核对、slug查重这几道决定成败的关,靠的是运营这层人工把控。工具提速,人保质,配合着来,才能既快又不在URL上埋下读错音的雷。
拼音URL对百度和谷歌,到底有没有SEO价值?
做完slug,得清醒看待一个问题:拼音URL到底给SEO加了多少分。这事不能想当然,对百度和谷歌还不太一样。
对谷歌,前面说过,它支持编码后的中文URL,也接受拼音URL,拼音的好处主要是"可读、好传播",而不是直接的排名加权——谷歌不会因为你URL是拼音就给你加分,URL里的关键词对排名的影响本就很弱。所以拼音slug对谷歌更多是体验和品牌层面的考量,不是排名杠杆。
对百度,要更清醒:百度作为中文搜索引擎,最看重的是页面里的中文原文——标题、正文里的中文关键词,而不是URL里那串拼音。一个拼音URL不会因为"是拼音"就在百度获得中文关键词的相关性加分,因为拼音不等于中文词。甚至历史上有种说法,纯拼音的域名和URL在中文搜索里并不占优。
所以别指望把中文转成拼音塞进URL,就能在百度提升中文关键词排名——真正决定中文排名的,是页面内容里那些货真价实的中文关键词。拼音URL的合理定位是:让URL有个拉丁化的、可读可传播的形态,是体验和规范层面的优化,而非排名层面的灵丹。
把它放在"做了更整洁、但别指望它直接拉排名"这个位置,预期才不会落空。和它一样属于跨境本地化基本功、做对了加体验分的,还有价格的本地化展示,可以看我们团队的货币格式化工具教程;日期时间的标准格式规范,则可以看日期格式化工具教程。
数字声调和符号声调,分别该用在哪?
工具的三种声调形式里,带符号的和带数字的容易让人犯选择困难,其实它俩各有各的适用场合,分清楚就不纠结了。
带声调符号的(nạ hǎo)最像正规拼音,声调直接标在元音上,给人读、给人学最直观。所以面向人的场景——拼音教学材料、给童书标音、正式的拼音标注,用符号版。它的缺点是这些带声调的字符是特殊的Unicode字符,在一些老旧系统、某些字体、纯ASCII环境里可能显示不出来或乱码。
带数字声调的(ni3 hao3)用数字1到4表示四个声调(轻声常用0或5或不标),全是普通ASCII字符,兼容性极好,到哪儿都能正常显示。所以面向机器、面向程序处理的场景用数字版——存进数据库、做拼音检索的索引、在代码里处理,数字声调不会有字符编码的麻烦,而且程序提取声调信息也方便(直接读那个数字就行)。至于不带声调的纯字母版,前面说过,是专门给URL slug和那些不需要声调、只要个拉丁化标识的场景用的。一句话归总:给人看用符号、给机器用数字、做标识用无声调,按这个分,三种声调形式各得其所。
拼音汉字对照模式,主要用在什么场合?
工具里有个相对特别的"拼音汉字对照"模式,把汉字和它的拼音上下对齐排版,这个模式平时不起眼,但在两个场合特别好使。
第一个是教学和学习。给一段中文逐字标上拼音、上下对齐,正是对外汉语教材、儿童识字材料的标准排版方式——上面一行汉字、下面一行拼音,学的人一眼就能把字和音对上。做这类内容的,用对照模式批量生成,比自己一个个排版省事得多。
第二个,也是和本文主题更相关的,是校对多音字。前面反复强调工具的多音字会读错、必须人工校,而对照模式正好是校对的利器——汉字和拼音一一对齐摆着,你扫一遍就能快速发现哪个字的拼音标得不对,比在一长串连续的拼音里找错字直观得多。所以拿工具转完一段含多音字的内容,切到对照模式核对,是个高效的校对姿势。这也呼应了用这工具的核心心法:它出草稿、你来校,而对照模式就是让"校"这一步变快的辅助视图。把它当校对助手用,能让你那道绕不开的人工核对关走得更顺。
拼音重名撞了slug,除了手动加词还有别的办法吗?
用拼音做slug,绕不开一个结构性问题:中文不同的词,转成拼音可能一模一样,导致slug撞车。这个问题值得单独说说怎么处理。
同音不同字的中文太多了。"茶道"和"茶到"都是cha-dao,"工事"和"攻势"都是gong-shi,"会议"和"汇议"都是hui-yi。拼音丢掉了汉字的字形信息,只保留读音,所以一旦两个不同标题读音相同,转出来的slug就撞了。而URL是不能重复的,撞了必须想办法区分。
处理办法有几种。最直接的是手动加区分词——给其中一个slug补上一个能区分的词,比如把一篇"茶道"文章的slug做成cha-dao-ru-men(茶道入门),靠补充词拉开。第二种是接受拼音的局限、改用英文翻译做这部分slug,翻译能保留语义区分。第三种是在slug里掺入分类或其它维度,比如加个栏目前缀。
但不管哪种,关键是转完slug必须查重——把新slug和站内已有的比一遍,撞了立刻处理,别等收录了才发现两个页面抢一个URL。工具只负责把中文转成拼音,查重和去重这步它做不了,得靠你在流程里卡一道。理解拼音"只留音、丢了形"这个本质,你就明白撞slug是必然会碰上的、得有预案,而不是偶发意外。
汉语拼音、注音符号、威妥玛拼音,工具认哪种?
中文的罗马化或注音方案其实不止汉语拼音一种,做国际化时偶尔会碰到别的方案,得清楚这个工具只认其中一种。
中文的拉丁化和注音历史上有好几套体系。最通行的是汉语拼音,也就是这个工具用的这套——大陆、新加坡、联合国、国际标准都用它。但还有别的:台湾地区过去常用的注音符号(用ㄅㄉㄍ这类符号而非拉丁字母);早年西方流行的威妥玛拼音(把"北京"拼成Peking那一类,和汉语拼音的Beijing不同);以及一些地名人名沿用的旧拼法(像Tsingtao青岛、Confucius孔子)。
这个工具只输出汉语拼音,不做注音符号,也不输出威妥玛拼音或其它旧式拼法。所以你要的如果是汉语拼音(绝大多数现代场景都是),它对路;但你要是处理一些沿用旧拼法的专有名词、或者面向还在用注音的特定场景,它给不了,那些得另查。好在如今国际通行的就是汉语拼音,旧拼法主要存在于一些约定俗成的历史地名人名里,日常做slug、做品牌拉丁化,认准汉语拼音这套就够用,工具的输出正好对得上现在的主流标准。
给中文数据库做拼音排序和检索,怎么用它?
拼音转换还有个不那么显眼但很实用的后端用途——给中文数据做拼音排序和检索。这块和SEO没直接关系,但做中文产品、中文站后台时常用得上,顺带讲讲。
问题出在中文本身不像英文那样有天然的字母顺序。一批中文名字、中文商品名要按"首字母A到Z"排序(就像通讯录那样),或者要支持用拼音首字母快速检索(输入bd就能找到"百度"),都得先把中文转成拼音,拿拼音去排序和建索引。这是很多中文应用后台的标准做法。
用工具的思路是:把中文字段批量转成拼音(通常用不带声调的形式,排序检索不需要声调),存进数据库的一个辅助字段,排序和检索就基于这个拼音字段做。不过老问题还在——多音字。如果某个名字含多音字、工具读错了,那它的拼音排序位置就会错(比如姓"单"被读成dan,就被排到D而不是正确的shan那一档)。
所以涉及人名的拼音排序,关键的多音字姓氏仍要人工校正,否则检索和排序会出现"找不到、排错位"的怪事。工具能帮你把大批中文快速转出拼音草稿供后端使用,但它那条多音字短板,在排序检索这种对准确度敏感的场景里同样需要人来兜底。
把整篇长文章转拼音,性能和体验上要注意什么?
工具对输入长度没硬限制,理论上你能把一整篇长文章贴进去转,但真这么干,有几个性能和体验上的点要注意。
先说性能。工具是纯前端的,转换、渲染全在你浏览器里跑,输入特别大时(比如几万字的长文),浏览器要逐字查表、还要渲染出同样长的拼音结果,可能会卡顿一下,尤其是用对照模式(要排版大量上下对齐的字音对)时更吃性能。所以处理超长文本时,分段转、别一次性灌一整本书进去,体验会更顺。
再说实用性。把一整篇文章转成拼音,结果往往不是你真正想要的——你多半只是要标题或某些词的拼音(做slug、做标注),而不是整篇拼音化的文本(那东西没人读)。所以实战里更常见的是把短文本(标题、词、短语)丢给它,而不是长文。
真要给长文逐字标音(比如做教材),那是对照模式的活,也建议分段处理、分段校对,因为长文里的多音字更多,一次性校完一整篇容易看花眼、漏掉错的。把"短文本快速转、长文本分段转加分段校"作为习惯,既避开性能坑,也让那道人工校对关更可靠。说到底,它最擅长的还是处理标题、品牌名这类短文本,长文是它能干、但不是最优的用法。
拼音转换和国际化,还有哪些场景用得上?
除了做URL slug,拼音转换在国际化和日常开发里还有些实用场景,顺带点一下,让你知道这工具的用武之地不止一处。
一是品牌和产品的拉丁化命名。中文品牌出海要有个拉丁字母的名字,拼音是最直接的来源——"小米"的xiaomi、"百度"的baidu就是这么来的。用工具把中文品牌名转成拼音,是起拉丁名的第一步(当然还要考虑这个拼音在目标语言里好不好读、有没有歧义)。二是数据的拼音排序和检索:通讯录按姓名首字母排序、给中文数据建拼音索引方便检索,都要先把中文转成拼音,工具能批量出这个。
三是拼音学习和标注材料:给中文文本批量标注拼音做对外汉语教材、给童书标音,工具在常规文本上能出规范的带声调拼音。四是输入法、语音相关的一些辅助处理。这些场景的共同点是"需要中文对应的拼音表示",工具都能批量提供草稿。但凡这些场景里涉及人名、地名、多音字的,老规矩——人工校对那一关不能省。把工具当成一个"快速出拼音草稿"的通用助手,它在国际化这条线上能省你不少重复劳动,只要你始终记得它出的是草稿、关键处要人来定。
用它转拼音,最容易栽的几个坑怎么提前绕开?
用这工具多了,会发现踩的坑就那么几类,提前知道能省下大返工。
第一类,也是最致命的,是多音字——它逐字取最常见读音、不看上下文,"重庆""银行""长大"这类必错,做URL slug尤其危险,转完必须人工逐字校多音字。第二类是姓氏:它不认姓氏特殊读音,"曾""单""解""区"作姓全会读错,涉及人名的一个个核对。
第三类是把拼音URL当排名灵药:对谷歌它只是更可读、对百度排名看的是中文原文不是URL拼音,拼音slug是体验优化不是排名杠杆,别指望它直接拉排名。
第四类是边界字符:生僻字超出常用区会变问号、繁体只转音不做简繁转换、儿化轻声不标,碰上这些得另想办法或人工补。把这四类坑记牢——多音字必校、姓氏必核、排名别迷信、边界字心里有数——再配上"做slug统一用不带声调+全小写+中横线、定稿前查重"这套规范,拼音转换就能又快又稳。它是个好用的草稿机,但中文这门讲究上下文的语言,最后一关永远得靠懂它的人来把。
常见问题解答
这个拼音转换工具为什么会把"重庆"读错?因为它逐字查表、取每个字最常见的那一个读音,完全不看上下文,也没有词库分词。"重"最常见的读音是zhong,所以它把"重庆"转成zhong qing,而正确的是chong qing。这是纯查表方案的结构性短板,不是偶尔失手,凡多音字都得人工校对。
用它转出的拼音做URL slug安全吗?常规标题基本安全,但含多音字、人名、地名的标题不安全。工具可能把读音转错,错误的slug一旦被收录再改就要做跳转。做slug务必转完逐字校多音字、核对姓氏读音,再确认slug在站内不撞重,校对查重都过了才定稿。
它能把简体字转成繁体字吗?不能。它只做中文转拼音,不做简繁转换。它的字典同时包含简体和繁体字的拼音,所以简体繁体都能转出各自的拼音,但字形它不动,不会把简体变繁体或反过来。要做简繁转换得用专门的简繁工具。
拼音URL能帮我在百度提升排名吗?基本不能。百度作为中文搜索引擎最看重页面里的中文原文关键词,而不是URL里那串拼音,拼音不等于中文词,不会因此获得中文关键词的相关性加分。拼音slug的价值是让URL可读、好传播,是体验和规范优化,不是排名杠杆。真正决定中文排名的是页面内容里的中文关键词。
它转人名为什么总出错?因为它不处理姓氏的特殊读音,也不识别"这是个人名"。很多姓氏是多音字且读音不是最常见的那个,比如"曾"作姓读zeng不读ceng、"单"作姓读shan不读dan,工具只会给最常见的非姓氏读音。凡涉及真实姓名的转换,都要人工逐个核对姓氏读音,别信工具的一遍结果。
本文标题:《拼音转换工具怎么用?把中文标题转成能用的URL slug,多音字才是真坑》
本文链接:https://zhangwenbao.com/pinyin-converter-chinese-url-slug-romanization-polyphone-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0