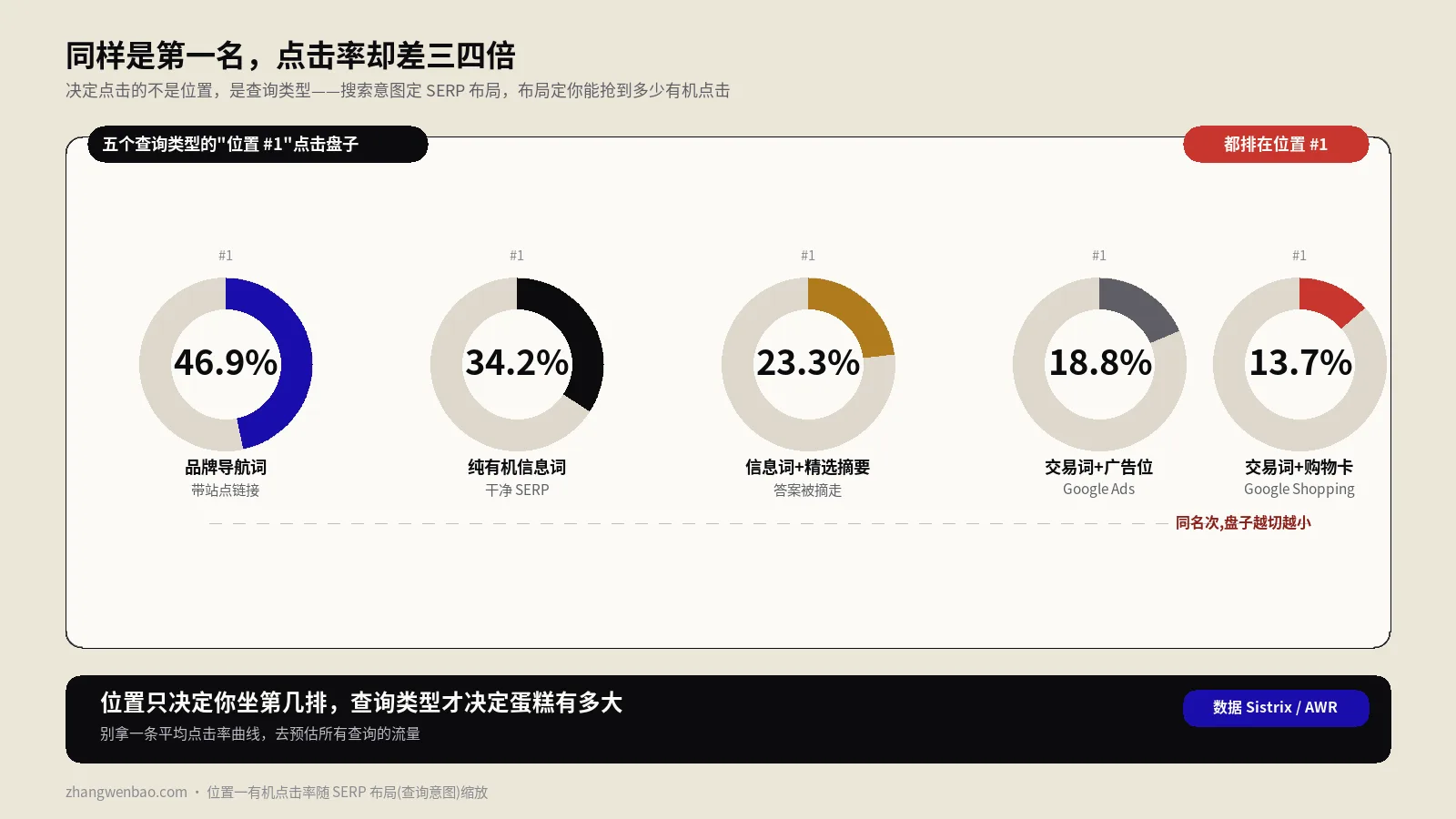
排名追踪要不要每天扫?跨设备位置怎么省钱5000站实战
本文目录
- 排名追踪到底要多频繁才算够?
- 频次×目标×预算的三轴决策表
- 日抓与周抓的真实差距测算
- 样本量该选100、1000还是10000个关键词?
- 统计意义上的样本量公式
- 核心全量加长尾分层抽样的混合做法
- 长尾分布的PPS抽样实操
- 桌面和移动要不要分开追踪?
- 移动优先索引后的设备样本采集
- iOS与Android的差异要不要细分
- 地理位置粒度该取国家、州还是邮编?
- 本地化SERP与跨区域差异
- 多语言多区域站的samp策略
- 排名变了到底是真变了还是噪声?
- 置信区间与统计功效
- 假阳性与假阴性的识别
- 怎么把追踪成本压下来又不掉精度?
- 分层错峰加价格弹性的省钱设计
- 跨境母婴DTC的1万词追踪成本压缩复盘
- 自建脚本与商业工具的成本拆解
- AI搜索时代排名追踪还该怎么改造?
- 排名与可见度份额与被引用份额的三件套
- 常见问题解答
- 排名追踪到底要多频繁才够?
- 样本量该选 100 个词还是 10000 个词?
- 桌面和移动要不要分开追踪?
- 地理位置粒度该取国家还是城市?
- 排名变了 3 名是真变了还是噪声?
- 排名追踪成本怎么压最有效?
- AI 搜索时代排名追踪还有意义吗?
- 权威参考资料
摘要:排名追踪不是抓得越频越准,本质是采样设计问题。频次按目标和预算反推、样本量靠置信区间公式算、设备和位置按真实用户分布分层、SERP波动用置信区间过滤再下结论。这篇把排名追踪当成一个工程学问题来解,给你能照着抄的频次表、样本量算法、自建与商业工具的成本拆解,再讲清楚AI搜索时代为什么不能只盯排名一个指标。本文与关键词排名监测方法论与可见度份额那篇不同——那篇讲“为什么对不上”,本篇讲“怎么从头设计才省钱不出错”,互为上下游。
保哥这几年帮客户排查排名追踪的问题,发现一个反直觉的现象:花得越多、抓得越频的客户,反而更容易被假数据骗。一个跨境母婴DTC团队过去每月在排名追踪工具上烧八百美金,三个 SaaS 工具的曲线对不上、移动端排名跟现场实测差五到十名、内部周会一半时间花在解释“为什么这个词又抖了”。介入重做后把追踪当成一个采样设计问题来解:分层抓、按需抓、有置信区间地下结论。三个月后月费压到两百美金,假阳性报警降了一半多,团队反而对排名变化更有判断力。
这件事让保哥彻底想清楚一件事——排名追踪不是数据采集问题,是统计学抽样设计问题。频次、样本量、设备组合、位置粒度,每一个都不是“越多越好”,而是“按目标反推到刚够”。这篇就把这套设计方法摊开讲,每一节都给具体公式、对照表和真实案例,照着改就能用。
排名追踪到底要多频繁才算够?
频次是所有追踪方案的第一笔成本,也是绝大多数团队选错的第一道关。常见的错有两类:一类是“开了日抓就再没动过”,另一类是“被工具默认配置牵着走,所有词都用同一个频率”。两种都在烧钱。
频次×目标×预算的三轴决策表
正确的做法是反过来:先问“我为什么要追踪”,再确定频次。下面这张表是这几年沉淀下来的频次决策矩阵:
| 追踪目的 | 典型词类 | 合理频次 | 样本量建议 | 成本权重 |
|---|---|---|---|---|
| 核心词稳定监控 | 品牌词、主力商品词 | 每天1次 | 100%全量 | 低(词少) |
| 竞品对标 | 核心词的同义集合 | 每天1次 | 核心100% | 中 |
| 异动告警 | 带商业意图的转化词 | 每天1到2次 | 100%全量 | 中 |
| 算法更新观察 | 抽样代表词 | 核心更新期6到12小时1次,平时周抓 | 分层抽样500到2000 | 高峰期高 |
| 新页学习期 | 新发布页的目标词 | 前30天每天,之后每周 | 新页全量 | 中 |
| 长尾大盘扫描 | 5000个以上的长尾池 | 每周或每两周 | 分层抽样10到20% | 大批量低单价 |
| 定期复盘 | 历史归档词 | 每月或每季度 | 分层抽样5% | 极低 |
真实的工作流里,一个站的词不是一个频次能罩住的。核心词每天扫、长尾每周扫、归档每月扫是基本骨架;这三层之外再叠一层“新页学习期临时频次”和“算法更新期临时加密”,就是完整方案。
之前帮一个出海宠物用品DTC客户做诊断,他们把所有8000个关键词都设了每天追踪。算下来一年差不多六千美金。改成核心800个日抓、中间2200个周抓、剩下5000个长尾月抓后,年费降到一千八,几乎没漏掉任何一次重要异动——因为长尾本来就不需要每天看,月维度的趋势才有意义。
日抓与周抓的真实差距测算
客户经常追着问:“日抓和周抓到底差多少?多花的钱值不值?”这个问题不能拍脑袋答,要算一下边际信息量。
之前拿同一批关键词(1500个词、覆盖核心和长尾)做过一个对照实验:一组日抓持续三个月,另一组周抓同样三个月,最后比较两边能捕捉到的“显著排名变化事件”数量。
| 对照维度 | 日抓组 | 周抓组 | 差距 |
|---|---|---|---|
| 三个月数据点 | 每词约90个 | 每词约13个 | 日抓多约7倍 |
| 捕捉到的显著事件 | 247起 | 189起 | 日抓多约30% |
| 捕捉到但事后证明是噪声 | 89起(36%) | 22起(11.6%) | 日抓假阳性多约3倍 |
| 真实有效事件 | 158起 | 167起 | 周抓反而略多 |
| 抓取成本 | 基准 | 约0.14倍 | 日抓贵约7倍 |
这张表里最反直觉的一行是真实有效事件——周抓不光没漏,反而比日抓少出了一些“假事件”。原因是日抓的高频数据更容易把个性化、抓取时间窗、本地化波动这些噪声当成“变化”记下来。频次高不等于精度高。
这个测算的结论后来写进了客户交付物的标准建议:除非你要做异动告警或算法更新观察,否则核心词每天1次、其他词每周1次就够。多花的钱大概率买的是噪声。
边际信息量这个概念值得多说一句。从经济学视角看,每多抓一次得到的“新信息”是递减的——抓第一次是从 0 到 1,价值无限大;从每周抓变成每天抓,价值是 1.3 倍;从每天抓变成每 4 小时抓,价值只多 1.1 倍。但成本是线性甚至超线性增长的——抓取量翻 7 倍,价格翻 7 倍,加上 SaaS 工具的“高频套餐溢价”,实际可能翻 10 到 12 倍。信息量边际收益递减、成本边际增长的不对称结构,是排名追踪频次选错就一定多花冤枉钱的数学原因。
这条还有一个延伸——异动告警的频次需求比常规监控高一档,但要单独走一条更窄的窗口,不能让告警的高频污染整个监控池。一个 B2B SaaS 客户曾把 200 个核心转化词单独配置了 6 小时一次的告警监控,其余 5000 个词仍走周抓,这样在不抬高整体成本的前提下保住了对异动的快响应。频次选择是分层叠加,不是一刀切。
样本量该选100、1000还是10000个关键词?
样本量是排名追踪里第二个被搞错的参数。要么贪多,把工具里能加的都加上、看到的数字一片汪洋;要么贪少,只盯几十个“觉得重要”的词,导致大盘波动从不进视野。这两种都不是设计,只是直觉。
统计意义上的样本量公式
把追踪当抽样问题来看,样本量是有公式的。要估算一个总体(你所有可能排名的关键词集合)的某个指标(比如平均排名、可见度份额)落在某个误差范围内的最小样本量,标准公式是:
n ≈ Z² × p × (1-p) ÷ E²,其中 Z 是置信度对应系数(95%置信对应 Z=1.96),p 是预估的指标比例(保守取 0.5 最大方差),E 是允许误差(例如 ±3% 取 0.03)。
代入算一下:95%置信、±3%误差,n ≈ 1.96² × 0.5 × 0.5 ÷ 0.03² ≈ 1067。也就是说,要稳定测出可见度份额±3%的变化,1000个左右的样本就够,再加也只是边际改善。
如果总体很小(比如总共只有3000个关键词),还要做有限总体校正:n_finite = n ÷ (1 + (n-1)/N)。N=3000、n=1067 时,校正后 n_finite ≈ 786。总体越小、校正幅度越大;总体超过10万词后,校正基本可以忽略。
核心全量加长尾分层抽样的混合做法
公式只回答“多少够”,没回答“哪些词进样本”。这一步是排名追踪能不能反映真实生意的关键,必须分层而不是简单随机抽样。
保哥的做法是先把关键词按“战略价值”分四层:
- 第一层 战略核心词:直接关联营收、品牌、转化页的词。这一层必须100%全量监控,没有抽样空间。
- 第二层 高商业意图词:带价格、对比、评测、品类名的词,转化率高但词更分散。这一层抽20到30%,按子类做分层。
- 第三层 信息类与导购长尾词:流量大但单价低、转化分散的词。按长尾分布做PPS(probability proportional to size)抽样,量级5000以上的总体抽10到15%。
- 第四层 抽样监测词:用来代表“整个站的健康度”的随机样本,与上面三层不重叠,定期更换。这一层2到5%即可。
这套分层做法对应到工具配置里就是“四组监控池+四种频次”。一个跨境美妆DTC客户在重做配置之前是把所有6000个词都按每天扫,月费六百多。换成四层结构后:第一层200个词日抓、第二层800个词周抓、第三层2000个词周抓+月汇总、第四层300个词月抓。月费降到一百五十,覆盖面没掉,反而因为分层显示问题更聚焦了。
长尾分布的PPS抽样实操
长尾词的搜索量极不均匀——一个词搜索量5000,另一个词搜索量50。如果用简单随机抽样,被抽到的小词无法代表它背后那批量级类似的“同等价值”词。按搜索量加权的概率抽样(PPS)是更专业的做法。
PPS的逻辑很简单:每个词被选中的概率与它的搜索量成正比,搜索量大的词进样本的概率高、搜索量小的词进样本的概率低,但所有词都有非零的概率。这样得到的样本对“流量加权的可见度”才有代表性。
实操上常用的是 Python 的 numpy.random.choice 配 p 参数,几行代码就能跑:先取所有候选词的搜索量做归一化,再按这个概率分布无放回抽出目标样本量。SaaS 工具里如果没有 PPS 抽样功能(绝大多数没有),用 Ahrefs 或 SEMrush 导出搜索量后在本地处理,再把样本回填进工具的监控组,效果一样。
PPS 抽样的样本要不要定期换?答案是一年换一次,灾难性流量变化后立刻换。原因有两个:一是搜索量分布会随季节、产品周期、行业动向漂移,去年的代表性样本今年可能已经过时;二是固定样本被监控久了,被搜索引擎识别为爬虫、被反爬掉的概率上升。一个跨境美妆 DTC 客户的实操是每年 1 月和 7 月各做一次样本再抽,旧样本中表现稳定的核心保留 30%,剩余按当下搜索量分布重新 PPS。这样既保了纵向对比的连续性,又避免了样本陈旧。
分层抽样还有一个常被忽视的验证步骤——抽完之后要做一次覆盖度对账:把样本词放回总体,看每个子类的占比是不是与目标分层比例一致。比如设定第三层信息长尾词占 60%,抽完发现实际 38%,那这次抽样就失败了,要回去检查分层定义或抽样代码。这一步不做,样本可能整体偏向某一类,结论被带歪。
桌面和移动要不要分开追踪?
这个问题客户经常来问,绝大多数答得太轻率。默认答案是“分开”,因为同一个词桌面和移动的 SERP 现在差异极大;但具体怎么分、要不要全量分,要看流量结构和资源约束。
移动优先索引后的设备样本采集
Google 在2018年移动优先索引彻底落地后,移动SERP和桌面SERP不再是“同一个 SERP 的两种渲染”,而是两个有独立排序信号、独立特性槽位的搜索系统。移动端的 People Also Ask、Local Pack、AI Overviews 占的屏占比远超桌面,自然结果的位置被往下压。同一个词,桌面前 5 名的页面在移动端可能因为 LCP 慢、字号小被挤到第 8 位。
设备追踪的分配原则是看 GA4 或同等分析里实际的设备流量分布:
| 真实流量分布 | 设备追踪建议 | 样本配置 |
|---|---|---|
| 移动占比≥70%(典型电商和DTC) | 移动为主、桌面抽样对照 | 移动100%、桌面30%抽样 |
| 桌面占比≥70%(典型B2B、工程类) | 桌面为主、移动抽样对照 | 桌面100%、移动30%抽样 |
| 两端均40到60%(媒体、教育、内容站) | 双端独立全量追踪 | 桌面与移动各一套样本 |
| 桌面占比≥90%(小众工业B2B) | 仅桌面追踪 | 桌面100%、移动仅抽样核心 |
常见的踩坑是桌面端默认开了、移动端却用了同一份桌面数据当结果汇报。这个错见过不止一次,团队拿着桌面排名跟实际移动流量挂钩,自然解释不通。
iOS与Android的差异要不要细分
这个问题答案比较干脆:大部分场景不要细分。Google 移动SERP 在 iOS Safari 和 Android Chrome 上的排序结果差异在 95% 的情况下小于 1 名,把追踪再切一层会让样本翻倍而几乎不带来新信息。
真正需要细分 iOS 和 Android 的场景只有两类:一是 App Indexing 和 Universal Links 的深链结果,这两类深链在两个系统上的呈现机制不同;二是 Google Discover 的内容覆盖,Android 端 Discover 流量大、iOS 端被 Apple News 分流。除此之外,iOS 和 Android 数据合并即可。
地理位置粒度该取国家、州还是邮编?
这一步是采样设计里最容易花冤枉钱的地方。粒度每细一档,样本量按地理单元数线性扩展,成本最容易失控。
本地化SERP与跨区域差异
Google 的本地化 SERP 在不同地理粒度上的差异不是线性的:
- 国家级:同一个国家不同城市的 SERP 差异,对纯信息内容词不超过 5%;对带本地意图的词(“附近”“XX市”这种)差异极大。
- 州或省级:美国不同州的 Local Pack 完全不同;中国不同省份的百度地图本地结果也是各自独立,但有机自然结果差异通常在 10% 以内。
- 城市级:本地服务(律师、牙医、修理)和实体店的城市间 SERP 完全独立,差异可达 100%。
- 邮编与区县级:同一城市不同区的差异主要出现在 Local Pack 和 Maps 结果上,有机自然结果几乎没差异。
判断粒度该取到哪一级,最准的方法是先用三到五个代表区抓一次对照,看到差异显著再细化。一个 B2B 物流货代 SaaS 客户最初按邮编级追踪整个北美市场,光是地理单元就上千个,每月追踪费过万美金。介入后用十个代表州做了一周对照,发现纯有机结果差异稳定在 6% 以内——粒度直接降到国家级,月费立刻压到原来的十分之一。
多语言多区域站的samp策略
多语言多区域的国际站不能直接套国内追踪的思路。这里有两个坑:
一是同语言不同国家,比如英语在美国、英国、加拿大、澳大利亚。SERP 差异中等,源于本地化内容、域名权重、品牌力。做法是先按四个主要英语市场各取代表样本对照一周,再决定是合一套样本还是四套独立。
二是同语言不同区域版本,比如简体中文在中国大陆、新加坡、马来西亚的 SERP 差异。这一类差异主要来自搜索引擎本身——大陆是百度、新加坡和马来主要是 Google。这种情况下不光要分区域,连用哪个搜索引擎追踪都要分。
多区域追踪粒度的判定要先做对照实测,再决定粒度——不要默认按邮编追踪整个海外市场,那是预算黑洞。
排名变了到底是真变了还是噪声?
这是排名追踪里最值钱的判断力——能不能识别噪声,决定你的团队是把时间花在解决问题上,还是花在解释噪声上。见过太多团队每天一开机就在追昨天的“掉一位”,结果九成都是个性化或抓取时段的波动。
置信区间与统计功效
判断一次排名变化是不是真变了,要回到统计推断。常规判定原则是:
| 变化幅度 | 持续时间 | 样本依据 | 结论 |
|---|---|---|---|
| ±1到2名 | 单次抓取 | 单点 | 大概率噪声,不报警 |
| ±3到5名 | 单次抓取 | 单点 | 可能噪声,等下一次 |
| ±3到5名 | 连续3次同一时段 | 多点 | 显著变化,进调查队列 |
| ≥6名 | 单次抓取 | 单点 | 可能真变化,立刻交叉验证 |
| ≥6名 | 连续2次 | 多点 | 真变化,启动归因分析 |
| 跌出前20名 | 单次抓取 | 单点 | 立刻确认是否被惩罚或失索引 |
置信区间的简化判据:如果同一个词同一时段连续N次抓取的标准差是σ,那 ±2σ 范围内的变化都算噪声,超过 ±2σ 才是显著。这个公式不需要专业统计软件,Excel 用 STDEV 函数就能算。
统计功效(power)是另一个常被忽视的概念。功效低意味着“真变化但你没检出来”的概率高——通常源于样本量太小或频次太低。一般要求功效≥0.8,配合 95% 置信度,对应的最小样本量大概是表里展示的数倍。这也是不建议把样本量切到 100 以下的统计学原因。
假阳性与假阴性的识别
排名追踪的两类误差要分开管理:
假阳性是“显示变化但实际没变”,主要来自个性化、地理本地化、抓取时段、SERP 特性槽位插入挤压自然结果。识别假阳性的核心方法是跨设备、跨地理、跨时段交叉验证——如果只有一个监控点报警、其他三个监控点都稳定,多半是假阳性。
假阴性是“实际变化但没检出”,主要来自样本不足、频次太低、关键词不在监测组里。识别假阴性的方法是定期用 Google Search Console 全量数据反推——GSC 的 Performance 报告里的曝光和点击数据是全量的,比第三方工具更接近真值,但延迟 1 到 3 天。把工具数据和 GSC 周比对一次,能抓出大部分假阴性。
处理排名数据的时候有个习惯:所有自动报警都带一个置信度标签——高、中、低。高置信度报警直接进每日早会;中等的进观察池,三天没消失再升级;低置信度的进周报附录,不打扰团队节奏。这一条做对,团队的注意力质量能立刻翻倍。
GSC 的周对账具体怎么做?步骤其实只有四步:第一步导出 GSC 上周的 Performance 报告,按页面 + 查询展开;第二步导出工具上周的同一批关键词排名快照;第三步用 SQL 或 Python 按页面 + 查询关键词做 join,对齐两边数据;第四步在 join 后的表里加一列“工具排名 - GSC 平均位置”,看分布。如果绝大多数差值落在正负 2 名内,工具数据可信;如果系统性偏高或偏低,要看是不是工具的样本设备/位置和真实流量来源不匹配。
这一套周对账跑成例行之后,你会发现工具数据与 GSC 经常有 3 到 5 名的系统性偏差,这不是工具错,是工具的采样位置 vs 真实用户位置分布不匹配的物理表现。把这个偏差量化下来作为校准系数,工具数据就能跟 GSC 对齐使用,不需要砍掉某一个工具,而是把两边都当作经过偏差校准的可信源。
怎么把追踪成本压下来又不掉精度?
预算压不下来的根本原因不是工具贵,是配置浪费。把上面四节的分层、频次、样本、设备、地理粒度都设对,成本自然就降了。但还有一些工程化的省钱手段可以叠加。
分层错峰加价格弹性的省钱设计
SaaS 排名追踪工具的定价模型几乎都是“关键词数×追踪频次”计费。要砍成本就要砍这两个乘数:
- 分层已经讲过,核心日抓、长尾周抓、监测月抓,三层一起设。
- 错峰是一个被忽视的小技巧。很多 SaaS 工具有“高峰时段加价”,比如美东工作日早9点到晚6点的查询费是 1.5 倍。把非紧急追踪批次(长尾、归档、监测)配置到非高峰时段(凌晨、周末)跑,能省 30 到 50%。
- 价格弹性是另一个杠杆。年付折扣、批量采购、合并多个项目到一个账号下,这些常规商务谈判能再压 10 到 20%。一个跨境母婴 DTC 客户把三个独立项目合并成一个账号后,月费从总和 800 美金压到 220,主要靠的就是合并谈价。
把这三个手段叠加,加上前面的分层和样本设计,1万词组合从月费 800 美金压到 200 美金不是营销话术,是工程上能复现的结果。
跨境母婴DTC的1万词追踪成本压缩复盘
把开篇提到的那个跨境母婴 DTC 案例完整拆开讲一下。重做之前的配置是:6 个区域市场(美/英/加/澳/德/法)、10000 个关键词全打、每天追踪、桌面与移动两个设备各一套。月费三家工具加起来 820 美金,但内部团队对数据信心反而低,每周会议要花 1 小时解释波动。
| 压缩动作 | 动作前 | 动作后 | 月费变化 |
|---|---|---|---|
| 分层频次(核心日抓+长尾周抓+监测月抓) | 10000词×日抓 | 800核心日抓+2200中量周抓+6500长尾月抓+500监测月抓 | 820→340 |
| 区域粒度(六区→三区代表+对照) | 6国全量 | 3国全量+3国仅核心词周抓 | 340→260 |
| 设备配比(移动80%+桌面20%抽样) | 移桌双全量 | 移动100%+桌面30%抽样 | 260→220 |
| 工具合并(三家→主SaaS+自建辅助) | 三家独立账号 | 合一主SaaS+自建脚本补 | 220→200 |
四步压缩做完,月费从 820 降到 200,年节省 7440 美金。更关键的是误报警从每周 14 次降到 5 次——分层之后噪声词被自动归类到月扫池,不再每天报警;置信区间过滤之后单点波动也不会被升级。团队周会的“解释波动时间”从 1 小时压缩到 15 分钟,节省下来的时间可以做实际的内容和外链工作。
这种压缩不是一次到位的,要分阶段灰度。建议每动一步配置都保留两周的“双轨数据”——新配置和旧配置并行跑,确认新配置没漏掉关键事件之后再切断旧配置。整个压缩过程在那个客户身上跑了两个月,第三个月起新配置完全独立运行至今没出过事。
自建脚本与商业工具的成本拆解
有一类特别敏感的客户会问:“为什么不自己写脚本抓?SaaS 工具不就是个爬虫加报表吗?”这个问题要分场景答。
| 对比维度 | 自建脚本 | 商业SaaS | 混合方案 |
|---|---|---|---|
| 启动成本 | 开发3到6周 | 当天上手 | SaaS起步+自建补 |
| 每千词月成本 | 20到50美金(代理+服务器) | 40到120美金 | 15到60美金 |
| 反爬抗压 | 需自己维护代理池 | 厂商负责 | 厂商负责主力 |
| 数据深度 | 可定制 | 受工具限制 | 核心SaaS+定制自建 |
| 团队依赖 | 需要工程同事 | SEO同事自己 | 分工明确 |
| 风险 | 被Google封 IP、维护断档 | 厂商涨价、跑路 | 双重冗余 |
推荐混合方案给大多数中型 SEO 团队:核心词和大盘对账用商业 SaaS(稳定、能跟竞品比、有团队协作),高频小样本和定制指标自建(省钱、可定制、抗厂商绑架)。两套数据周比对一次,互相校准。这套结构既不至于把工程同事拖死在维护代理池上,又不会被 SaaS 工具的涨价和功能阉割捏住。
关于第三方工具数据本身的偏差怎么校准着用,之前在第三方SEO工具数据校准方法论那篇讲得更细——排名追踪只是其中一个场景,其他指标也都有同样的偏差问题。
AI搜索时代排名追踪还该怎么改造?
2024 年 AI Overviews 在美国 SERP 大面积上线、2025 年 ChatGPT Search 和 Perplexity 等 AI 搜索接入广告变现链路之后,传统排名追踪面临一个根本性挑战:用户看到 AI 答案直接走了,自然排名第一也带不来点击。
这个时候很多团队的第一反应是“别看排名了”。保哥的观察相反——排名追踪不能停,但要从“看排名”改成“看可见度版图”。
排名与可见度份额与被引用份额的三件套
新一代的追踪指标至少要覆盖三个维度:
- 传统排名仍然有意义,但只是基线。它告诉你“在自然结果列表里你排第几”,没告诉你“这个列表本身还有多少人看”。
- 可见度份额(Share of Voice)是 SERP 上品牌占据的像素面积比例。AI Overviews 占了 30% 屏占比,自然第一名占 8%,那这个词的可见度份额你能拿到的最高就是 8 ÷(30+8+...)。这个指标比单纯看排名更接近真实流量预测。
- 被引用份额(Citation Share)是 AI 搜索答案里品牌被提到或被链接到的比例。同一个查询在 ChatGPT Search、Perplexity、Gemini、AI Overviews 里被点名的次数,是新世代品牌可见度的真信号。
这三个指标的关系不是替代,是叠加。传统排名追踪是基础数据层,可见度份额是商业价值层,被引用份额是 AI 时代品牌层。一个完整的追踪台账要把三层都放进去。
被引用份额具体怎么量?操作上分三步:第一步建一组“品牌探针提示词”,覆盖品牌词、品类词、对比词、问题词四类,每类 20 到 50 条,作为日常监测样本;第二步把这组提示词每周轮跑 AI Overviews、ChatGPT Search、Perplexity、Gemini、Claude 等主流 AI 答案接口,记录是否提到品牌、提到的语境(推荐/中立/负面)、出现位置(首段/列表项/链接);第三步算出每个 AI 平台上的被引用率,再按平台流量权重加权得到全网被引用份额。
这套监测不需要重型工具,一个 Python 脚本加几个 API 密钥就能跑起来,月成本通常在 50 美金以内。难的不是工具,而是提示词样本要选对——只测品牌词意义有限(被引用率自然高),要重点测“没带品牌名的品类词和对比词”,那才是 AI 答案里真正的露出战场。
可见度份额的量化稍复杂一点,需要把 SERP 截图按像素分析。可以用 Screaming Frog 的 SERP Snapshot 加上自写的像素面积计算脚本,或者直接用提供 SERP Pixel 数据的工具(Sistrix、SE Ranking 等已经在做)。这个指标对“AI 介入后我的真实曝光被压缩了多少”最敏感,是核心词跟踪的现代化必备维度。
具体怎么衡量 AI 引用,之前在零点击与AI SEO效果衡量那篇给过完整方法——从提示词级实验、引用源探针,到 GA4 与品牌搜索数据的衔接,三套配合才能在 AI 把流量截胡的时代还能量到真实价值。把这套思路与本篇的采样设计合在一起,就是一份完整的 2025+ 排名追踪改造方案。
底层的数据治理逻辑也是这整套追踪能不能稳的前置条件——一套SEO 指标层与单一事实源的数据治理把口径、汇报频次、指标定义都钉死,排名追踪只是这个指标层里的一个领域。光有数据不会做推断,再细致的追踪也只是表象,团队照样会被波动牵着鼻子走。
常见问题解答
排名追踪到底要多频繁才够?
按目标和预算反推,不是越频越好。监控核心词的稳定排名周抓就够;竞品对比和异动告警要日抓;研究算法更新和新页学习期需要 6 到 12 小时一次。日抓比周抓成本高约 7 倍,得到的信息密度只多 20 到 30%,性价比要看你到底要解决什么问题。
样本量该选 100 个词还是 10000 个词?
样本量按公式算:最小样本量 ≈ 1.96² × p ×(1-p) ÷ E²,外加抽样校正。一般 10 万词的总体取 1000 个分层样本能稳定测出 ±3% 的可见度变化;核心词必须 100% 全量不抽样,长尾才走抽样。直觉拍脑袋的“看着差不多就行”一定会出问题。
桌面和移动要不要分开追踪?
看流量来源。移动占比超过 70% 的电商和 DTC 站,移动必须独立追踪不能用桌面平均;B2B 和工程类桌面优先;五五开必须分两套样本对照。同一个词桌面和移动 SERP 现在差 30 到 50% 是常态。
地理位置粒度该取国家还是城市?
本地服务和实体店必须到邮编或区县级,跨州差异极大;电商和 DTC 国家级就够,州级是 nice-to-have;纯信息类内容站走 region 级。粒度细一档样本量乘 5 到 10 倍成本,按真实差异决策不要默认最细。
排名变了 3 名是真变了还是噪声?
看置信区间。单一数据点 ±5 名内都可能是噪声;连续 3 天同一时段抓到同一变化、且符合统计显著性(一般 95% 置信、变化大于等于 2 倍标准差)才能认定为真变化。短期单次跳动绝大多数来自个性化、地理、抓取时段等噪声。
排名追踪成本怎么压最有效?
三件事:分层(核心词日抓、长尾词周抓、抽样监测月抓)、错峰(避开 SaaS 工具高峰加价时段)、自建脚本与商业工具组合(自建做高频小样本,商业做大样本基线对账)。一个 1 万词组合从月费 800 美金压到 200 美金是真实可达的省钱比。
AI 搜索时代排名追踪还有意义吗?
有,但不能只看排名。要加三个新维度:被引用份额、可见度份额、零点击品牌曝光。传统排名追踪是基础,新指标是补充不是替代。AI Overviews 和 Perplexity 里被提到的频率、SERP 上品牌名占据的像素面积、出现在 AI 答案里没点击却留下的品牌印象,都要进监测台账。
权威参考资料
本文标题:《排名追踪要不要每天扫?跨设备位置怎么省钱5000站实战》
本文链接:https://zhangwenbao.com/rank-tracking-sampling-design-frequency-device-sample-cost.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0