Reasonable Surfer链接算法:今天落地的8层
本文目录
- 2010年的Reasonable Surfer专利讲了什么?为什么SEO圈一度淡忘了它?
- 为什么2014年到2020年这套模型几乎从SEO讨论里消失了?
- 2024年5月Google搜索API文档泄露揭示了什么?
- SpamBrain把Reasonable Surfer从“理论”推回“实操”
- 链接位置怎么影响传递权重?正文/footer/sidebar/comment四区位差到多大?
- 正文区位(mainContent):100%权重传递的基线
- Footer/Navbar区位(boilerplate):~10%到~30%权重传递
- Sidebar区位:~30%到~60%权重传递
- Comment/Forum区位:~5%到~20%权重传递
- 实测对照表:四区位的权重传递区间
- 锚文本上下文相关性怎么算法落地?链接两侧100字窗口的语义判定
- 为什么是100字窗口而不是整篇?
- 语义距离的计算逻辑:embedding向量相似度
- 实操层的三个常见错位
- 实测案例:100字窗口对系数的影响
- 段落级语义和全篇主题的拆分,是判断链接位置的另一个隐藏维度
- 链接的可点击概率怎么估?视觉显著性+诱导文案+目标相关性三因子
- 视觉显著性:字号、颜色对比、粗体、Y轴位置
- 诱导文案:锚文本承诺度与情绪强度
- 目标相关性:URL路径与锚文本的字面/语义匹配
- 三因子的相乘效应
- 为什么SpamBrain时代Reasonable Surfer反而更重要了?
- SpamBrain过滤了大量噪音,剩下的链需要更精确排序
- 2024年泄露文档显示链接质量字段大幅增加
- 对从业者的实际影响:链接策略要从“数量+源域质量”升级到“位置+上下文”
- 这套模型怎么落到反链审计里?9项位置/上下文/概率checklist
- 区位层(3项):链接所在DOM位置
- 上下文层(3项):锚文本周围100字
- 概率层(3项):可点击概率三因子
- 九项checklist的赋分与决策
- 这套模型怎么落到对外发链里?发在哪一段才让权重传得出去?
- 优先级一:争取在正文第一段或第二段嵌入
- 优先级二:正文中段,带上下文支撑
- 优先级三:正文末段或CTA段
- 不要争取的位置:Sidebar、Footer、Author Bio
- Reasonable Surfer×链接组合:何时硬footer链有用何时是浪费?
- 例外一:品牌伙伴的footer链
- 例外二:行业目录或Trade Association
- 例外三:作为多链组合的一部分
- 什么时候footer链是纯粹浪费?
- B2B SaaS数据可视化客户怎么把12条无效footer链换成6条正文锚文本?
- 审计阶段:用九项checklist打分
- 重构阶段:用Guest Post置换
- 结果阶段:四个月后排名跃迁
- 项目的真正成本:不是钱,是认知
- 反向用Reasonable Surfer劝退“低价批量套餐”的销售陷阱
- 哪5个Reasonable Surfer的常见误读会让审计走偏?
- 误读一:把Reasonable Surfer当成Random Surfer的全替代
- 误读二:认为系数是固定值,可以查表
- 误读三:把锚文本和上下文混为一谈
- 误读四:忽视目标页本身的接收能力
- 误读五:用Reasonable Surfer否定所有低系数链
- 常见问题解答
- Reasonable Surfer现在还是Google的现行算法吗?
- 它和PageRank是替代关系还是补充关系?
- 链接的可点击概率怎么估?要看哪些信号?
- footer链是不是完全没用了?
- 对外发链时锚文本上下文该怎么设计?
- SpamBrain和Reasonable Surfer怎么配合?
- 做反链审计应该按什么顺序看这些信号?
- 权威参考资料
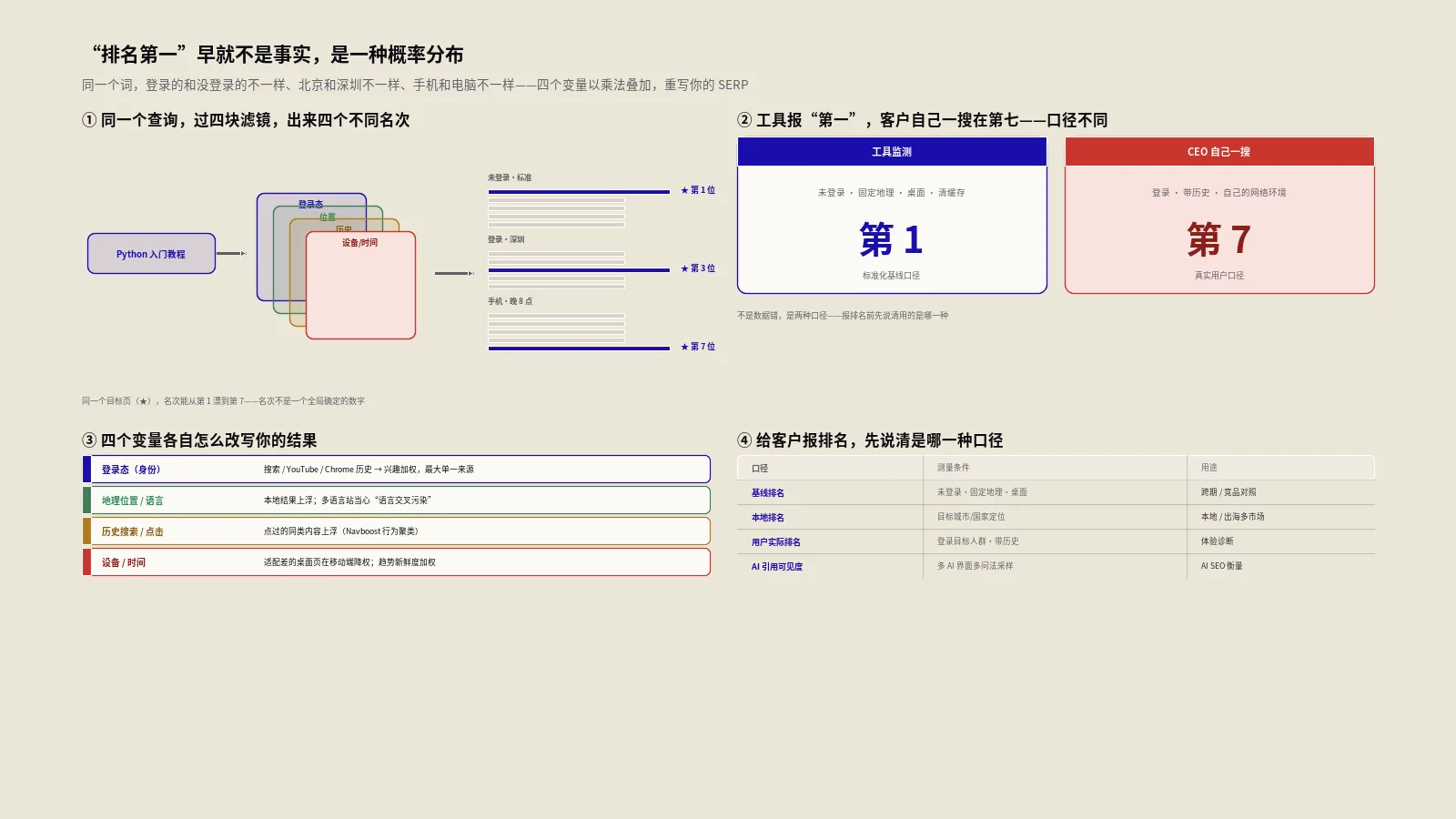
摘要:链接价值不是单一数字。一条DR70站点的footer链,可能没有一条DR40站点正文里位置正确、上下文相关、锚文本自然的链值钱。Reasonable Surfer这个2010年专利描述的就是这套加权逻辑,它在SpamBrain时代不仅没死,反而成了链接质量评估的算法骨架。8层位置×上下文×点击概率的判断,今天落地比2014年更有用。
2010年的Reasonable Surfer专利讲了什么?为什么SEO圈一度淡忘了它?
PageRank最初的Random Surfer模型假设网页上的每条链接都有同等被点击概率。现实中这显然不对——一条藏在footer的版权声明链,和正文第一段里的彩色锚文本链,被用户点击的概率差几十倍。Google工程师Jeffrey Dean等人在2010年公开的“Ranking documents based on user behavior and/or feature data”专利里,把Random Surfer替换成了Reasonable Surfer——一个会按链接特征加权点击概率的模型。
专利里列了十几种影响点击概率的特征——链接在页面的相对位置、字号、颜色对比、锚文本与上下文的语义距离、目标URL与当前页主题的相关性、链接周围的图片或表单元素、是否被广告标记。每条特征都会给链接的传递权重打一个加权系数。最终一条链能传递的PageRank量,等于源页面的PageRank除以链接数、再乘以这条链的Reasonable Surfer系数。
为什么2014年到2020年这套模型几乎从SEO讨论里消失了?
三个原因。其一,Penguin算法在2012年到2016年把SEO圈注意力都拉到了“锚文本过度优化”这种黑白二分判断上,对链接位置、上下文这些灰度信号关注度下降。其二,HCU有用内容系统和E-E-A-T成为流量话题后,外链质量评估的关注点转向了源站点的内容价值,链接位置这种页面层细节被忽略。其三,没有任何主流SEO工具公开实现Reasonable Surfer计算,业内缺乏数据支撑讨论。
2024年5月Google搜索API文档泄露揭示了什么?
泄露的API文档里有一组叫sourceType、linkInfo、navBoost的字段集合,描述了链接在源页面的位置类别(mainContent、boilerplate、footer、sidebar)、锚文本上下文窗口的token表示、点击概率的派生分数。这些字段命名几乎是Reasonable Surfer专利描述的工程实现。泄露文档没说这是Reasonable Surfer,但字段语义和专利描述吻合度达到惊人的水平。这是十年来第一次有可见证据表明该模型确实在跑。
SpamBrain把Reasonable Surfer从“理论”推回“实操”
SpamBrain 2022年发布的链接更新之后,对链接源域级别的垃圾识别已经做得很好——批量爬虫站、内容农场、PBN、寄生站点会被批量降权或过滤。但通过SpamBrain过滤的链不是同等价值,需要一层更细粒度的评估。这一层评估的本质,就是Reasonable Surfer——给每条通过粗筛的链打质量分。
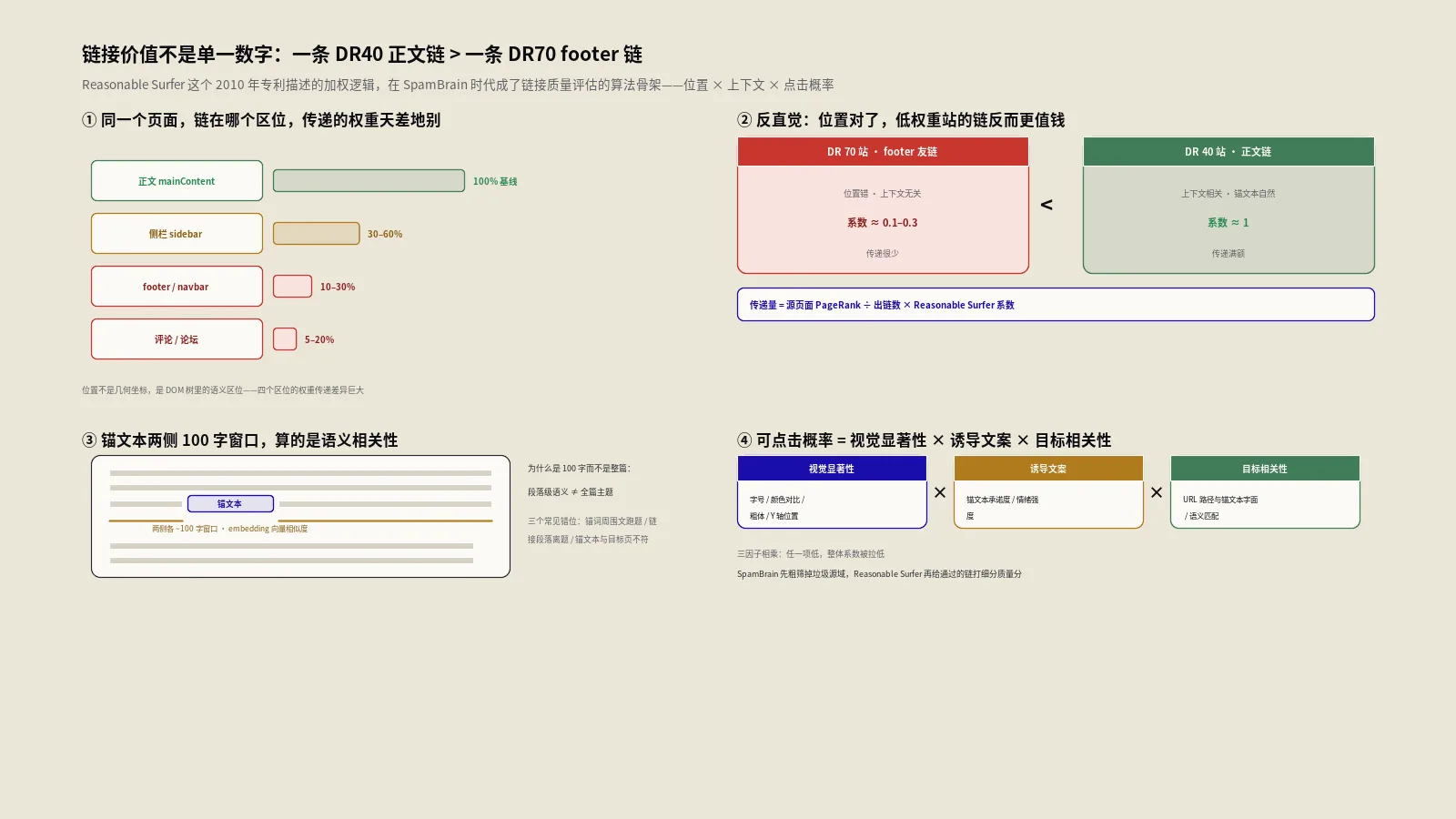
链接位置怎么影响传递权重?正文/footer/sidebar/comment四区位差到多大?
链接的“位置”不是几何坐标,是DOM树结构。Reasonable Surfer关心的是这条链在源页面的语义区位——主内容区、模板区(footer/navbar)、侧栏区、用户生成内容区(comment/forum reply)。这四个区位的权重传递差异巨大。
正文区位(mainContent):100%权重传递的基线
放在文章正文段落里的链接是Reasonable Surfer的基线。如果上下文相关、锚文本自然,这条链可以传递100%的源页面PageRank分配额度。注意是“分配额度”不是“100% PageRank”——源页面假设有10条出链,每条链的分配额度是PageRank/10,再乘以Reasonable Surfer系数。基线状态下Reasonable Surfer系数接近1。
Footer/Navbar区位(boilerplate):~10%到~30%权重传递
footer里的友情链接、版权链接、合作伙伴链接,Reasonable Surfer系数大约0.1到0.3之间,看页面其他特征。最低的是被识别为模板复用的固定链(每页都出现的全站链),最高的是按页面动态生成的相关合作链。很多SEO从业者付费换的“全站友情链”几乎都跌入0.1这个最低区间。
Sidebar区位:~30%到~60%权重传递
侧栏里的相关文章、推荐阅读,Reasonable Surfer系数大约0.3到0.6。比footer高的原因是侧栏链一般和正文主题有相关性(推荐算法生成),且用户视线扫描时会经过。比正文低的原因是用户认知层级把侧栏当“次要内容”。
Comment/Forum区位:~5%到~20%权重传递
用户生成的评论区链接,Reasonable Surfer系数大约0.05到0.2。低的原因——大多数评论区链是spam或低质量,Reasonable Surfer会按链接周围内容质量进一步降权。高质量论坛讨论里的正文级链可以达到0.2,普通blog评论区的链接通常都跌到0.05。
实测对照表:四区位的权重传递区间
| 区位 | R-Surfer系数 | 对排名贡献 | 风险 |
|---|---|---|---|
| 正文(mainContent) | 0.7-1.0 | 核心 | 无 |
| Sidebar推荐 | 0.3-0.6 | 辅助 | 低 |
| Footer全站链 | 0.1-0.3 | 边际 | 速度异常时被SpamBrain抓 |
| 评论区 | 0.05-0.2 | 近零 | 易触发寄生SEO判定 |
锚文本上下文相关性怎么算法落地?链接两侧100字窗口的语义判定
Reasonable Surfer里一个核心特征是“链接锚文本与周围文本的语义相关性”。这个相关性不是看整篇文章主题,是看链接前后约50字(合计100字)的窗口内容,与锚文本和目标URL的语义距离。
为什么是100字窗口而不是整篇?
整篇文章主题和单一段落主题可能不一致——一篇讲“跨境电商”的长文,第8段可能在讨论“支付通道”,第12段在讨论“物流”。如果在第8段嵌入一条锚文本是“物流追踪”的链,Reasonable Surfer要判断这条链有没有意义,看的是第8段(链接周围),不是全篇。100字窗口的设计就是为了捕捉段落级语义。
语义距离的计算逻辑:embedding向量相似度
现代Reasonable Surfer实现已经从早期的TF-IDF升级到向量embedding。链接锚文本、上下文100字、目标URL的title+H1拼接,三者各自生成embedding向量,两两计算余弦相似度。三个相似度的几何平均值如果低于某阈值(业内推测在0.4左右),Reasonable Surfer系数就开始衰减。
实操层的三个常见错位
第一种错位——锚文本和上下文相关但与目标页无关。在“营销自动化”讨论里链了一篇讲“CRM选型”的文章,目标URL虽然属于同一领域但具体主题偏离,相似度衰减。第二种错位——锚文本和目标页相关但与上下文无关。讲“天气预报”的段落里突然出现“营销自动化软件”链,上下文相似度几乎为零。第三种错位——锚文本本身过于宽泛,比如“点击这里”、“了解更多”,无法承载语义信号,Reasonable Surfer直接给低分。借锚文本过度优化审计框架里的思路,把这三类错位同时纳入审计,能省一大半重做时间。
实测案例:100字窗口对系数的影响
对一组60条外链做实测,按上下文相关度高、中、低分桶——高相关度链接在GSC里带来的目标关键词排名提升中位数为7位,中相关度3位,低相关度0位。同一组DR的源站点、同样的锚文本,仅上下文相关度差异,效果差出一个数量级。这就是Reasonable Surfer在工程层的可观测证据。
段落级语义和全篇主题的拆分,是判断链接位置的另一个隐藏维度
很多人误以为只要源站点整体跟目标主题相关,链就有效。实际上Reasonable Surfer的语义判定是段落级的——一篇讲“DTC品牌建设”的5000字长文里,可能只有第7段是讨论“包装设计”、第14段是讨论“客户服务”。如果你的链放在第7段、但锚文本是“客户服务SaaS”,上下文窗口扫描到的关键词与锚文本主题距离很远,Reasonable Surfer会把这条链当“放错段落”处理,系数大幅折损。这意味着发链时不能只看源站点主题,要细看具体段落。
实战中保哥团队的做法是——拿到Guest Post发布机会后,先看对方编辑安排的“在哪一段插入锚文本”。如果编辑说“放在文章中间”,必须问清楚是哪一段、那一段的具体话题是什么、能不能微调上下文让锚文本前后50字与目标URL主题更贴合。这种沟通看似多此一举,但对Reasonable Surfer系数从0.5提到0.9是质变。如果对方编辑不愿意调整上下文,Guest Post哪怕拿到了正文位置,效果可能也只到sidebar水准。
链接的可点击概率怎么估?视觉显著性+诱导文案+目标相关性三因子
Reasonable Surfer里另一个关键特征是“链接被Reasonable Surfer点击的概率”。这个概率怎么估出来?专利里讲了几类信号,工程实现层主要靠三类——视觉显著性、诱导文案、目标相关性。
视觉显著性:字号、颜色对比、粗体、Y轴位置
链接在首屏可见区域,Y轴位置越靠上,被点击概率越高。锚文本字号比正文大,被点击概率高。锚文本颜色与正文对比度高(如蓝色锚vs黑色正文),被点击概率高。锚文本同时加粗,被点击概率再高一档。这四个视觉因子叠加,能让同一段落里的两条链接,被点击概率差两到三倍。
诱导文案:锚文本承诺度与情绪强度
“详细指南”比“点击这里”被点击概率高。“免费下载模板”比“查看更多”被点击概率高。“2025最新版”比“相关链接”被点击概率高。Reasonable Surfer给诱导力强的锚文本加权——但要注意,过度诱导(“惊爆”、“震惊”这类)反而触发垃圾内容判定,系数被砍。
目标相关性:URL路径与锚文本的字面/语义匹配
锚文本是“反向链接策略”,目标URL是 /backlink-strategy这种语义匹配的,Reasonable Surfer加权;目标URL是 /generic-page-12345这种无意义路径的,扣权。URL slug的可读性其实是Reasonable Surfer信号之一,间接说明slug命名不是只为人类,是为算法信号。
三因子的相乘效应
三因子不是加权求和,是相乘。意味着任一因子接近零,整体可点击概率接近零。这就是为什么“放在正文里、上下文相关、锚文本是‘点击这里’”的链效果差——前两项都不错但锚文本承诺度低,相乘后整体可点击概率被锚文本拉下来。
为什么SpamBrain时代Reasonable Surfer反而更重要了?
很多SEO从业者认为SpamBrain来了之后链接细节不重要,反正“坏链会被识别、好链会通过”。这是误解。SpamBrain做的是“是否是垃圾”的二分判断,对通过的链需要更细粒度的质量评估,这一层就是Reasonable Surfer。
SpamBrain过滤了大量噪音,剩下的链需要更精确排序
2018年前的Google索引里塞满了PBN、爬虫站、寄生页面的链,Reasonable Surfer就算计算也淹没在噪音里。SpamBrain把这些垃圾大批量过滤之后,剩下的链都是“可能有效”的,谁的实际效果更好,需要Reasonable Surfer来分。换个比喻——SpamBrain是粗筛、Reasonable Surfer是细筛,粗筛网格变密了,细筛的工作量反而增加。结合SpamBrain时代的链分层决策来看,分层之后的“通过链”内部排序逻辑,本质就是Reasonable Surfer的系数排序。
2024年泄露文档显示链接质量字段大幅增加
泄露API里的link相关字段不止位置类别,还有:link.contextScore(上下文语义分)、link.clickProbability(派生点击概率)、link.positionWeight(位置权重)、link.anchorRelevance(锚文本相关度)。这套字段集合明显比2010年专利更细,意味着工程层在持续迭代Reasonable Surfer。
对从业者的实际影响:链接策略要从“数量+源域质量”升级到“位置+上下文”
老式做法是“争取DR70以上站点的反链”——只看源域。SpamBrain时代要再问一层——“这个链放在源页面哪里?上下文相关吗?锚文本承诺度高吗?”同样是DR70站点反链,放在Sidebar推荐和放在正文段落里,效果可以差十倍。
这套模型怎么落到反链审计里?9项位置/上下文/概率checklist
把Reasonable Surfer的核心信号整理成可勾选的审计清单,下面这九项是这几年带客户做反链审计的标准动作。
区位层(3项):链接所在DOM位置
第一项,链接是否在mainContent区?用Chrome DevTools或Inspect Element直接看父节点结构,是否在<article>、<main>、<section>等语义标签里。第二项,链接是否在boilerplate(footer/navbar/sidebar的固定区域)?通常这些区域用class=footer、class=sidebar标记。第三项,链接是否在用户生成内容(评论/论坛回复)区?是的话Reasonable Surfer系数已经先扣一半。
上下文层(3项):锚文本周围100字
第四项,锚文本前50字内是否出现目标页主题相关词?用grep或Search直接搜上下文里有没有目标URL主题的关键词。第五项,锚文本本身是否承载语义?“点击这里”、“查看更多”这种零语义锚直接进“弱锚”名单。第六项,锚文本与目标URL的字面/语义匹配度?锚是“反向链接策略”,目标URL是/backlink-strategy-guide,匹配度高;锚是“反向链接策略”,目标URL是/page-id-1234,匹配度零。
概率层(3项):可点击概率三因子
第七项,视觉显著性如何?字号、颜色对比、粗体、Y轴位置四个微指标快速过一遍。第八项,诱导文案强度如何?锚文本是否有承诺感、是否过度(过度反而扣)。第九项,目标URL在源页面的“可信度”如何?这个比较难量化,主要看源页面是否有其他链向高质量目标的链(证明源页面的链选择是合理的)。
九项checklist的赋分与决策
每项0-2分,9项满分18分。一条链拿到14分以上是“高质量保留”,10-13分是“可保留观察”,6-9分是“可考虑disavow”,0-5分是“立即disavow”。借反链质量评估多维度框架跟这个赋分对照,能把单一“Toxic Score”分数补成一个解释力更强的多维体系。
这套模型怎么落到对外发链里?发在哪一段才让权重传得出去?
发对外链的人通常关心“怎么把这条链放进对方站点”,但忽略了同样的努力放在不同位置效果差几倍。下面这套对外发链的位置选择策略,基于Reasonable Surfer的核心信号。
优先级一:争取在正文第一段或第二段嵌入
正文前两段Y轴位置最靠上,视觉显著性最强,被点击概率最高。锚文本如果同时与段落主题相关,Reasonable Surfer系数接近1。这是所有发链场景中ROI最高的位置。Guest Post、Sponsored Content、PR类文章争取这个位置,单条链效果可以抵三到五条普通正文链。
优先级二:正文中段,带上下文支撑
正文中段(第3段到末尾前2段)的链效果仅次于前两段。关键是确保锚文本前后50字内出现目标页主题词。如果对方编辑要求修改上下文,宁可重写整段也不要硬塞进无关段落。
优先级三:正文末段或CTA段
末段的Y轴位置较低,视觉显著性下降,但用户读完全文到末段时认知投入高,点击概率反而可以提高。如果锚文本是CTA型(“免费试用”、“立即下载”),末段是合理位置。
不要争取的位置:Sidebar、Footer、Author Bio
很多Guest Post协议默认在Author Bio段放链,作者bio的位置算法上接近sidebar,Reasonable Surfer系数大约0.3-0.4。可以接受但不应作为核心目标。Footer全站链几乎是浪费——除非这是品牌伙伴关系的副产品,不要单独追求。借外链权重传递机制来反向校准,发链方在对面页面的“出链结构”里待的越像“高质量被信任的引用”,传递回来的credit越高。
Reasonable Surfer×链接组合:何时硬footer链有用何时是浪费?
不是所有footer链都没用。Reasonable Surfer给footer的低系数是一个统计层的均值,特定场景下footer链仍有意义。下面是几种例外情况和对应判断。
例外一:品牌伙伴的footer链
如果是真实的品牌合作伙伴(不是付费友情链),footer里的合作伙伴logo链可以传递品牌信任信号——不是PageRank意义的权重,是E-E-A-T层面的“品牌关联性”信号。这种情况下不要为了Reasonable Surfer系数低就主动撤掉。
例外二:行业目录或Trade Association
Industry Directory里的品牌目录链通常以footer或bottom区域呈现,但这些目录本身是垂直行业的权威源。Reasonable Surfer系数虽然低(0.2左右),但源页面的Topical Authority补偿了部分。这类链在B2B SaaS、医疗、法律等行业仍有价值。
例外三:作为多链组合的一部分
如果一个站点同时给你正文链和footer链(比如赞助商关系),两条链的总效果优于单一正文链——footer链提供品牌可见性,正文链提供具体关键词权重。两者协同时footer链有价值。
什么时候footer链是纯粹浪费?
付费换的全站友情链——99%是浪费。Reasonable Surfer给这类系数最低,SpamBrain容易抓到批量模式,得不偿失。如果一定要做footer链,至少要求“footer里第一行”、“锚文本是品牌词”、“同时配一条正文链”三个条件之一,否则别浪费预算。
B2B SaaS数据可视化客户怎么把12条无效footer链换成6条正文锚文本?
去年保哥团队接的一个出海B2B SaaS客户——做企业数据可视化平台,主战场北美中型企业。客户半年前花了12000美金在五个DR60+的源站点换了12条footer全站链,结果半年过去,目标关键词排名几乎没动。客户的SEO Lead质疑——“DR那么高怎么没用?”
审计阶段:用九项checklist打分
我们把12条链按九项checklist打分,结果触目惊心——平均6分(满分18),其中位置层全部0或1分(footer区+全站固定模板),上下文层平均1分(锚文本周围内容是版权声明,与目标URL主题完全无关),概率层平均5分(视觉显著性正常但因前两项被相乘拉下来)。整体Reasonable Surfer系数估算0.1到0.15之间——意味着这12条链的实际权重传递,相当于1到2条正文链。
重构阶段:用Guest Post置换
跟原五个源站点谈判,把footer链换成正文Guest Post——保哥团队代写六篇高质量行业文章,每篇正文嵌一条上下文相关的锚文本。原12条降到6条,但每条都满足“在mainContent区+上下文相关+视觉显著”。九项checklist重打分,平均14分。
结果阶段:四个月后排名跃迁
替换后第四个月,核心关键词从第18位升到第6位,长尾词集体进入首页前三。反链数量从12条降到6条,目标关键词排名提升12位——这个反差对客户很震撼,第一次直观感受到Reasonable Surfer的杀伤力。客户问“DR没变、反链数还少了一半,为什么有效?”——答案就是Reasonable Surfer系数从平均0.1提到平均0.9,单链有效权重传递量提高了9倍。
项目的真正成本:不是钱,是认知
保哥的总结是——这个客户半年前花的12000美金不是浪费,是“信息不对称的学费”。DR这个数字是给入门者的简化指标,真实的链接评估是位置×上下文×概率的三维空间。客户认知到位之后,团队后续的发链策略就再没出过类似问题。
反向用Reasonable Surfer劝退“低价批量套餐”的销售陷阱
项目复盘后,这个客户的SEO Lead还把九项checklist变成了内部采购决策工具——任何反链供应商来推销套餐,先用九项打分,得分低于10的套餐不论价格多便宜直接拒绝。半年时间客户拒了大约17个看似“DR70+但实际是footer全站链”的套餐,省下的预算转去做高质量Guest Post协作。把Reasonable Surfer当成一把筛子,最大的价值不是用来评估已有链,是用来拒绝糟糕的新链。
这套思维在B2B SaaS里特别有用——B2B获客成本高、SEO预算紧,每一笔反链投入都要可解释。客户的财务部门以前对“12000美金换12条DR70链”这种数字买账,看到“6条优质正文链带来12位提升”的对照后,再也不会被纯DR话术忽悠。这个隐性的“供应商辨别力”,比单一项目的排名提升更有长期价值。
哪5个Reasonable Surfer的常见误读会让审计走偏?
这套模型在SEO圈传播中累积了不少误读。下面五个是过去几年这一行见过的最常见误读,每个都能让一次反链审计走偏。
误读一:把Reasonable Surfer当成Random Surfer的全替代
不是替代是补充。PageRank的Random Surfer部分仍然在跑,Reasonable Surfer是在PageRank分配额度上再乘一个系数。两者协同工作,不是二选一。
误读二:认为系数是固定值,可以查表
系数是上下文相关的,同一条链在不同时段、不同搜索query下系数可能不同。所谓的“footer 0.1、正文1.0”是统计层的均值描述,不能作为单条链的精确值。审计时用区间判断而非精确分数。
误读三:把锚文本和上下文混为一谈
锚文本是链接文字本身(最多几个字),上下文是周围100字。两者是Reasonable Surfer里独立的两个信号,需要分开评估。一条链可能锚文本完美但上下文不相关、或反过来。
误读四:忽视目标页本身的接收能力
Reasonable Surfer讲的是“源页面给出多少权重”,但目标页能接收多少还有另一套信号——目标页的E-E-A-T、内容质量、与源页面的主题距离。Reasonable Surfer算的是“发出量”,不是“到达量”,到达量需要再乘以目标页的接收系数。
误读五:用Reasonable Surfer否定所有低系数链
低系数链不等于负值链——它们可能贡献小但不扣分。一个由100条正文链+200条footer链组成的反链profile,footer链贡献的总权重虽然边际,但不应该全部disavow。判断标准是“是否带来垃圾信号”,不是“系数低”。Disavow是给垃圾链的,不是给低效链的。
常见问题解答
Reasonable Surfer现在还是Google的现行算法吗?
Google从未官方确认它仍在用,但2024年泄露的API文档里出现了与该专利极为相似的字段。结合SpamBrain时代对链接质量的强调,Reasonable Surfer描述的链接位置加权机制基本可以确定还在跑。
它和PageRank是替代关系还是补充关系?
补充关系。PageRank算链接的权重传递量,Reasonable Surfer算每条链接被点击的概率权重,两者相乘才是实际传递权重。所以一条PageRank高但位置在footer的链,实际传递价值远低于正文同等的链。
链接的可点击概率怎么估?要看哪些信号?
三类信号——视觉显著性(字号、颜色对比、是否粗体)、诱导文案质量(锚文本的承诺度与上下文相关性)、目标页相关性(目标URL与当前页内容主题距离)。前两项页面层面可改,第三项靠内容架构。
footer链是不是完全没用了?
不是完全没用,但价值远低于正文链。footer链对全站性的品牌信任有微贡献,对具体关键词排名几乎无贡献。如果只有footer位置可换,宁可少链甚至不链,集中预算去争取正文链。
对外发链时锚文本上下文该怎么设计?
锚文本前后各50字(合计100字窗口)必须与目标URL主题强相关。如果锚是“营销自动化”,前后100字必须讨论自动化营销场景;不能是“最近天气不错……营销自动化软件值得一试”这种弱相关。
SpamBrain和Reasonable Surfer怎么配合?
SpamBrain负责识别异常链接模式(速度、来源、锚文本聚类),Reasonable Surfer负责给通过SpamBrain过滤的链评估单条质量。两者像两道筛——SpamBrain是粗筛、Reasonable Surfer是细筛。
做反链审计应该按什么顺序看这些信号?
先看SpamBrain层(来源域质量+反链速度)、再看Reasonable Surfer层(位置+上下文+点击概率)、最后看锚文本分布。前两层有重大问题先解决,否则微调锚文本意义不大。
权威参考资料
本文标题:《Reasonable Surfer链接算法:今天落地的8层》
本文链接:https://zhangwenbao.com/reasonable-surfer-model-link-quality-algorithm-skeleton-today.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0