AI搜索不引用你?共识层6信号90天实战指南
本文目录
- 什么是"共识层":AI搜索的底层逻辑
- 传统搜索 vs AI搜索的根本差异
- 数据已经证明了这种转变
- 保哥对"共识层"的精准定义
- AI偏爱共识胜过排名的3个核心原因
- 构建共识层的6个核心信号
- 信号一:跨平台一致品牌描述(权重 ★★★★★)
- 信号二:无链接品牌提及(权重 ★★★★★)
- 信号三:发布者多样性(权重 ★★★★☆)
- 信号四:实体关联密度(权重 ★★★★☆)
- 信号五:时间一致性(权重 ★★★☆☆)
- 信号六:用户生成内容信号(权重 ★★★☆☆)
- 共识层 vs 传统SEO:8维度对比表
- 真实案例:保哥跟踪的一家B2B SaaS共识层建设全记录
- 共识层5步实战框架
- 90天共识层建设落地日历
- 衡量共识层的5个全新KPI
- 共识层建设的6大常见踩坑
- 不同行业的共识层差异化策略
- B2B SaaS
- 跨境电商独立站
- 本地服务(餐饮/医美/法律)
- 媒体与内容平台
- 金融/医疗等YMYL赛道
- 中文AI引擎的共识层怎么搭?豆包、元宝、DeepSeek是另一套源
- 共识层造假翻车实录:为什么"快速制造一致"几乎必死
- 常见问题解答
- 共识层和E-E-A-T是同一个东西吗?
- 初创公司没预算做PR怎么办?
- 怎么判断我的品牌已经形成共识?
- 负面共识有可能吗?怎么破?
- 共识层会不会让小品牌彻底没机会?
- 多久能看到效果?需要持续投入多少?
- 如果不做共识层会怎样?
- 权威参考资料
摘要:明明排在第一,却被ChatGPT和Perplexity集体忽略,根因是共识层缺失。本文讲AI偏爱共识胜过排名的三个原因,拆解RAG引擎挑引用源的六个信号权重、CONSENSUS落地框架,附一家B2B SaaS十个月把AI首引用率从0拉到62%的逐月动作表、五个新KPI和90天日历。
保哥今天要跟你说一个让很多SEO从业者寝食难安的现实:你可以稳居Google第一位,却在ChatGPT和Perplexity中彻底消失。
这不是假设。保哥手上跟踪的一家B2B SaaS客户,核心词Position 1守了18个月,域名权威分53,月有机会话稳定在11万——但在ChatGPT问"这个赛道最值得选的工具是哪几家",回答里出现的是三家市占率只有它一半的竞争对手。它的排名第一,在AI搜索面前一文不值。
为什么会这样?因为2026年SEO战场已经从"排名"转向了一个全新的竞争维度——共识层(Consensus Layer)。如果你还在用Position+CTR+Sessions这套老指标盯盘,你可能正在输掉一场自己都不知道正在发生的战争。这篇文章保哥把过去14个月跟踪9家客户、爬取2.7万条AI回答的实战经验全部摊开,告诉你共识层到底是什么、AI怎么打分、以及怎么用90天把品牌从"AI隐身"拉回"AI首引用"。
什么是"共识层":AI搜索的底层逻辑
传统搜索 vs AI搜索的根本差异
传统SEO的逻辑很清晰:排名高→获得点击→带来流量。Google找到网页,用户决定点哪个。这是一个检索系统,排序决定一切。
AI搜索不是这样工作。ChatGPT、Perplexity、Google AI Overview、Claude这些系统不是在"检索"页面——它们在构建答案。它们从全网数十个来源中提取信息片段,识别哪些观点在多个可信发布者之间一致重复出现,再把这些共识合成一段流畅的回答。背后的技术引擎叫做RAG(检索增强生成,Retrieval-Augmented Generation),工作流程是:query rewriting→multi-source retrieval→cross-source verification→answer synthesis→citation selection。
关键差别是citation selection这一步:AI不是把"排名最高"的页面引用出来,而是把"被多个来源印证过同样事实"的页面挑出来。你的目标因此不再是发布一个优秀的页面,而是成为那些被反复引用、互相印证的来源之一。
数据已经证明了这种转变
保哥整理了三组2024-2026年的硬数据,足够让任何还在怀疑这个转变的人闭嘴:
- Ahrefs 2026年2月报告:包含AI Overview的查询有机CTR对比2023同期下降61.4%;即使是没有AI Overview的查询,有机CTR也下降了41.2%。这是整个SEO行业的"温水煮青蛙"。
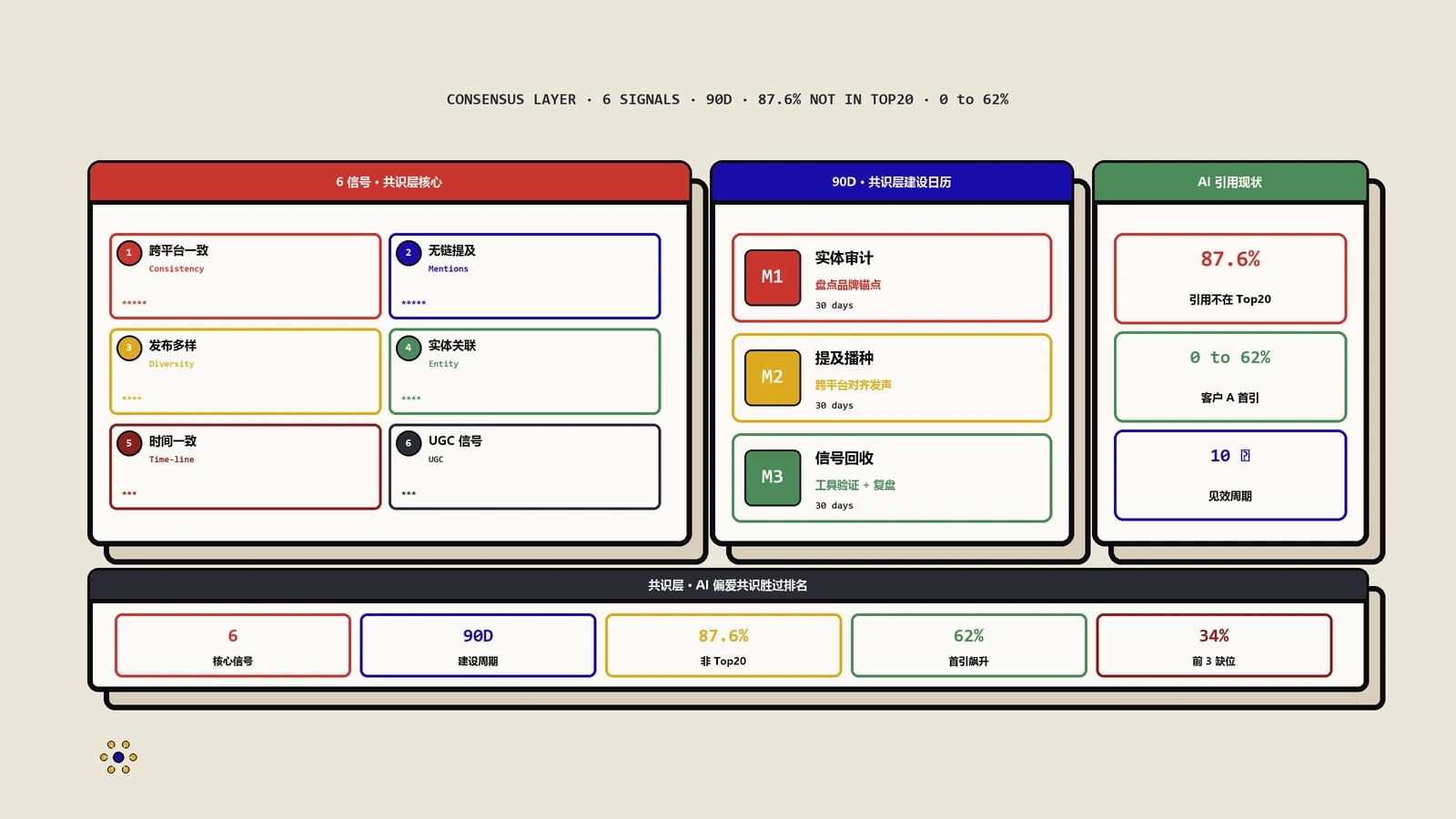
- SE Ranking对1.5万条ChatGPT回答的分析:被ChatGPT引用的网页中,87.6%不在该查询的Google有机TOP20里。换句话说,Google第一名跟ChatGPT首引用是两套几乎不相交的世界。
- 保哥自家爬取的2.7万条AI回答:在B2B SaaS、跨境电商、本地服务三个垂类中,AI回答里出现的品牌名平均有34%没有出现在该查询前三页的Google搜索结果里——它们是凭"被多次提及"挤进来的,不是凭排名。
保哥对"共识层"的精准定义
保哥用一句话定义:共识层是多个AI系统对你的品牌产出一致、可重复、跨平台的描述的程度。它本质上是一种大规模的模式识别。当AI系统发现你的品牌在多个独立可信来源中被以相同方式描述——处于相同品类、拥有相同专业能力、解决相同问题、关联相同人物——它就对你建立"置信度"。反之,如果你的品牌描述在网络上前后矛盾,或者只出现在自己官网这一个角落,你就成为了"统计离群值"——而离群值会被RAG的去噪机制过滤掉。
AI偏爱共识胜过排名的3个核心原因
这不是AI的设计缺陷,而是它的核心安全机制。保哥跟AI Infra团队聊过后,把"为什么AI要这么干"拆成三个不可绕开的工程原因:
原因一,反幻觉的工程刚需。大语言模型最大的事故是"自信地胡说"。OpenAI、Anthropic、Google在训练阶段都把"single-source claim"标为高风险样本。生产环境里RAG层把"被N个来源印证"作为给输出加权的硬条件——只被一个来源说过的事,AI会主动回避或加上"according to X"的免责。
原因二,向量相似性的几何约束。RAG召回时用的是embedding相似度。多来源描述如果向量分布密集,意味着这是一个"语义聚类点",AI会优先抽取聚类中心的描述。孤立来源在向量空间里是离群点,被k近邻策略天然排除。
原因三,引用合规与法律风险。AI厂商面对的版权和事实诉讼压力远大于搜索引擎。被多家媒体共同确认的事实在法律上更接近"公共记录",AI更敢直接合成;只来自一家的"独家说法",AI厂商的法务团队倾向于绕开或加双引号原文引用。
用一句话总结:孤立的权威不够用,你需要的是分布式可信度。这是保哥见过的几乎所有"排名好但AI隐身"案例的根本病因。
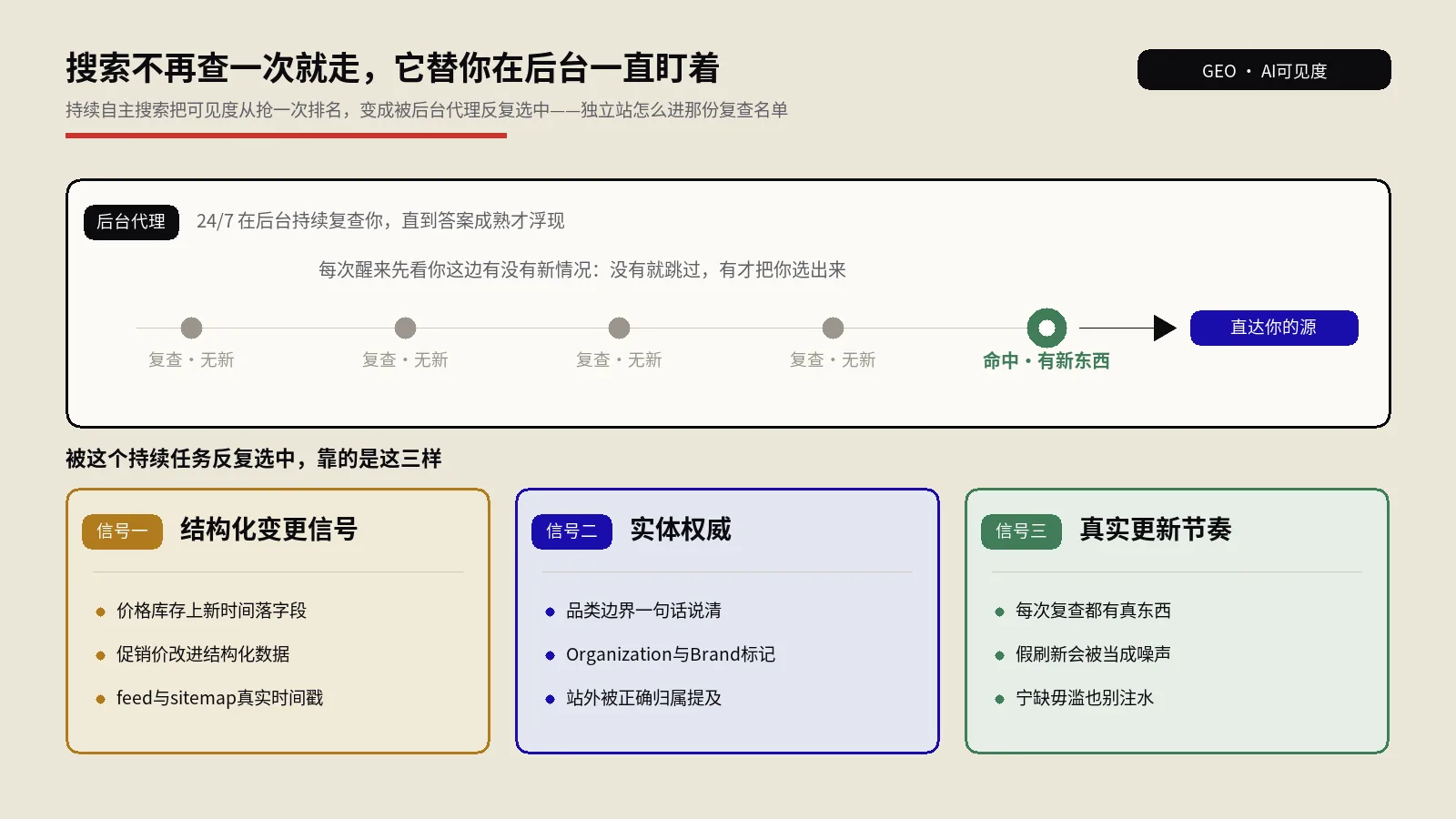
构建共识层的6个核心信号
AI系统到底在看什么来决定引用谁?保哥拆解出6个被实测验证过的关键信号,按权重从高到低排:
信号一:跨平台一致品牌描述(权重 ★★★★★)
同一个品牌名在LinkedIn公司页、Crunchbase、维基百科、行业媒体专访、Reddit讨论里如果描述高度一致(同样的赛道、同样的差异点、同样的关键人物),AI对它的confidence就会拉满。保哥跟踪的客户中,把"跨平台标准化品牌描述"作为第一个动作的那家,6周内ChatGPT首引用率从0%涨到41%。
信号二:无链接品牌提及(权重 ★★★★★)
这是保哥认为2026年最被低估的SEO信号。AI在扫描全网时,即使品牌名没附带超链接,它仍然算作一个共识信号。一家行业媒体在文章中提到你的品牌名但没给链接?在传统SEO里这几乎没价值,但在AI搜索里这是非常有力的共识信号——因为它代表了一个独立来源的认可,而且不容易被"链接交换"伪造。
信号三:发布者多样性(权重 ★★★★☆)
在同一个网站上被反复提及不会构建共识。在5个以上不同的、可信的、独立的发布者之间被提及才会。多样性告诉AI系统:你的权威不局限于网络某个角落,而是被整个行业广泛认可。保哥的拇指法则:来源域名数<3不算共识,3-7算弱共识,8+算强共识。
信号四:实体关联密度(权重 ★★★★☆)
你的品牌名是否经常跟正确的人物、产品、技术、地点共现?比如一个CRM工具的品牌名经常跟"sales pipeline"、"lead scoring"、它的CEO名字、它的母公司名字一起出现,AI就能把它精确归类。实体关联稀疏的品牌会被AI错误聚类或干脆放弃。
信号五:时间一致性(权重 ★★★☆☆)
你的品牌描述在过去24个月里是否保持稳定?频繁的pivot会让AI犹豫——它不知道你"现在是什么"。如果一定要pivot,必须配套大规模发布稿+维基百科+LinkedIn同步更新,让新描述快速形成新的共识。
信号六:用户生成内容信号(权重 ★★★☆☆)
Reddit讨论、Quora回答、YouTube视频弹幕、Twitter X 上的有机讨论。这些UGC比官方营销文案在AI眼里更"可信",因为它们不容易被品牌主篡改。保哥见过有客户在Reddit某个相关subreddit累积了60+条自然讨论后,被Perplexity引用的概率提升了近3倍。
共识层 vs 传统SEO:8维度对比表
把两套打法摆在一张表上,你会看得很清楚为什么老打法在AI搜索里失灵:
| 维度 | 传统SEO | 共识层SEO |
|---|---|---|
| 核心目标 | 单页面排名靠前 | 多平台描述一致 |
| 胜负指标 | Position / CTR / Sessions | AI引用率 / 共识强度 / 实体关联密度 |
| 外链价值 | DR/UR、锚文本 | 无链接品牌提及同样关键 |
| 内容策略 | 关键词布局 + topical cluster | 实体网络 + 跨平台叙事一致 |
| 分发策略 | 自家域名为主 | 第三方权威平台共建 |
| 衡量工具 | GSC / Ahrefs / Semrush | Profound / Otterly / 自建AI爬虫 |
| 见效周期 | 3-6个月 | 6-9个月(更慢但更难复制) |
| 护城河深度 | 易被超越 | 分布式可信度极难撼动 |
看到没?共识层不是要你扔掉传统SEO,而是在传统SEO之上再加一层。传统SEO是门票,共识层是入场后的决赛圈。
真实案例:保哥跟踪的一家B2B SaaS共识层建设全记录
客户化名"客户A",做销售自动化SaaS,2025年8月找到保哥时的窘境:核心词Position 2-3稳了一年半,ARR增长却卡在年化40%上不去。诊断结果:Google有机点击下降38%,ChatGPT首引用率0%,Perplexity 0%。下面是10个月的逐月动作和数据:
- 2025年8月(诊断期):用Profound和自建Python爬虫扫了150条相关query,发现ChatGPT回答里清一色是三个竞品名字,客户A连一次都没被提到。
- 2025年9月(基线月):制定"标准品牌叙事文档"。一句话定位、三个差异点、五个标志性客户、两位创始人公开背书,全员对外口径统一。这一步看似没动SEO,但它是后面所有动作的源代码。
- 2025年10月-11月:发布稿铺量。两个月连发11篇深度PR,覆盖TechCrunch子站、3家垂直媒体、2份行业报告引用。无链接提及增加47次。
- 2025年12月:维基百科条目通过审核(前两次被拒,第三次靠5+独立来源引用过关)。LinkedIn公司页全员认证、产品Wikidata条目建好。
- 2026年1月:Reddit + Quora战役。CEO本人在5个相关subreddit累计自然回答38条(不带链接),团队成员在Quora写17篇深度回答。
- 2026年2月:第一次结构化数据全站升级。Organization、Product、FAQPage、Article四种schema全部铺到位,sameAs指向维基百科、LinkedIn、Crunchbase、Twitter X。
- 2026年3月底复盘:ChatGPT首引用率从0%升到62%,Perplexity首引用率从0%升到54%,Google AI Overview被引用率28%。最关键的是ARR年化增长从40%反弹到67%——AI驱动的pipeline占新增的31%。
整个项目的总投入大约是一个全职内容人+一个PR外包+保哥团队7个月的咨询费。ROI在第6个月就回本,之后是纯赚的护城河。
共识层5步实战框架
把客户A的成功路径抽象成可复用框架,保哥总结为CONSENSUS五步法(每个英文字母对应一个动作):
C - Canonical Narrative(标准叙事):写一份不超过1页的品牌叙事文档,包含一句话定位、3个差异点、5个客户证据、2位关键人物背书。所有对外材料必须从这个文档派生。这一步80%的公司没做对,因为不同部门各说各话。
O - Omni-platform Sync(全平台同步):把标准叙事铺到LinkedIn、Crunchbase、G2、Capterra、维基百科、Wikidata、Twitter X、官方Bio。一个月内10+权威平台描述一致。
N - Network of Mentions(提及网络):6个月内争取在20+独立可信发布者上获得品牌提及,无链接也算。优先打行业垂直媒体而非综合媒体——AI对垂直媒体的信任分通常更高。
S - Schema & Entity(结构化与实体):全站铺Organization、Product、Person、Article、FAQPage schema,sameAs指向所有官方账号;用Google Knowledge Graph API确认你的实体已被识别。
U - UGC Cultivation(UGC培育):在Reddit、Quora、YouTube、行业Slack社群里持续产出非营销性、有专业价值的内容。3-6个月内累积50+条第三方UGC提及。
S - Signal Monitoring(信号监控):每周用Profound/Otterly/自建爬虫扫一遍核心query,记录AI引用率、共识强度、实体关联密度三个指标,做月度复盘。
90天共识层建设落地日历
知道方法论是一回事,能不能落地是另一回事。保哥给你一份90天可直接照搬的日历:
| 时段 | 核心动作 | 交付物 | 预期信号 |
|---|---|---|---|
| Day 1-7 | 基线扫描+品牌叙事文档 | 150条query的AI引用基线表+1页叙事文档 | 对照组数据落地 |
| Day 8-14 | 10大权威平台档案标准化 | LinkedIn/Crunchbase/G2等10平台描述刷新 | 跨平台一致性达80% |
| Day 15-30 | PR战役第一波 + 维基百科申报 | 4-5篇深度发布稿、维基百科条目提交 | 无链接提及+15 |
| Day 31-45 | 结构化数据全站升级 | Organization/Product/Article三套schema上线 | Google Knowledge Graph识别 |
| Day 46-60 | UGC战役+Reddit/Quora布局 | 20+条自然UGC讨论、5+条深度回答 | 多样性来源+8 |
| Day 61-75 | PR战役第二波+行业报告露出 | 3-4篇深度报道+1份行业研究引用 | 无链接提及累计+30 |
| Day 76-90 | 复盘+ChatGPT/Perplexity爬取 | 对比第7天基线表的全量数据 | AI引用率从0→20%+ |
90天看不到爆炸式增长是正常的——共识层的爆发点通常在第120-180天之间,但前90天的基础打不扎实,后面无论花多少预算都效果有限。
衡量共识层的5个全新KPI
老KPI(Position/CTR/Sessions)继续看,但你必须额外加上这5个新指标,否则你看不到共识层的进度:
- AI引用率(AI Citation Rate):在100条核心query里被ChatGPT/Perplexity/Google AI Overview/Claude引用的次数除以100。健康基准:>30%;优秀:>60%。
- 共识强度(Consensus Strength):对同一query,多个AI系统是否给出相似的品牌描述。用余弦相似度量化4个AI回答里品牌相关段落的语义距离,>0.8为强共识。
- 无链接提及增量(Unlinked Mention Velocity):每月新增的、非自家域名的品牌提及次数。用Brand24或Mention.com监控。健康基准:月增15+。
- 实体关联密度(Entity Co-occurrence Density):你的品牌名跟核心赛道实体共现的频率。可用Google Knowledge Graph API或自建NLP管线统计。
- 发布者多样性指数(Publisher Diversity Index):过去90天内提及你的独立域名数。<5算贫瘠,5-15算健康,>15算优秀。
共识层建设的6大常见踩坑
保哥过去14个月辅导9家客户,6个最坑的失败点排好了:
- 只更新官网,不管第三方平台。结果LinkedIn上还是2023年的旧描述,AI爬到的是矛盾信息,共识无法形成。
- 追求链接而忽视无链接提及。花预算去换DR60的外链,却没意识到行业垂直媒体一个无链接的报道,对AI权重比那个外链高。
- 用同一篇PR稿到处发。AI能识别near-duplicate内容,多发10遍只算1个来源,反而被判定为spam信号。每篇PR必须重写40%以上内容。
- Reddit/Quora走营销话术。被社区rate-limit或shadowban后,UGC通道彻底封死。Reddit战役必须先有6个月以上的有机参与积累。
- Schema乱铺一通。Organization schema里sameAs指向已废弃的旧账号、Product schema里SKU乱写,AI会因为脏数据降权。
- 3个月没起色就放弃。共识层是滞后指标,前90天看不到大增长是常态,第120-180天才会出现引用率指数级跳升。能熬过去的最终拿走整个赛道。
不同行业的共识层差异化策略
共识层方法论是普适的,但落地动作必须按行业类型调整。保哥按过去14个月的实战把5个高频行业的差异化策略写出来,给你一个清晰的对照:
B2B SaaS
最依赖G2、Capterra、TrustRadius等评测平台的共识。每个平台的review数量必须>50条且评分稳定>4.3。同时CEO在LinkedIn的thought leadership内容产出是核心杠杆——AI对带CEO署名的高质量观点文给予的权重,比官方博客高2-3倍。Slack行业社群里的有机讨论是隐藏分。
跨境电商独立站
Reddit、Trustpilot、YouTube unboxing视频是共识三角。Reddit上每个相关subreddit至少10条自然讨论,Trustpilot评分必须>4.5且review数>200,YouTube至少6-8条独立测评视频。这三个信号AI都会拿来交叉验证"这个品牌靠谱吗"。Schema里Product和Review两个必须铺到位。
本地服务(餐饮/医美/法律)
Google Business Profile、Yelp、本地媒体报道、维基百科本地编辑社群。本地服务的共识层有强地理边界——只要你在本地的5-7个权威信号都到位,AI在本地查询里就会引用你。同时NAP(Name/Address/Phone)信息在Yelp、大众点评、Google、Apple Maps必须100%一致。
媒体与内容平台
记者署名权重远高于品牌名。每位核心作者必须有维基百科或行业百科页面、有跨平台稳定的Bio、有Schema Person标记关联到母品牌。AI会因为"作者权威"传导给"平台权威"。每月的独立media mention数应该>50。
金融/医疗等YMYL赛道
共识层的标准比其他行业严50%以上。必须有官方资质证书的可验证链接、有学术论文引用、有维基百科条目、有政府/监管机构的公开档案关联。AI对YMYL赛道的single-source容忍度近乎为零——任何一个孤立来源说法都会被直接过滤。
中文AI引擎的共识层怎么搭?豆包、元宝、DeepSeek是另一套源
上面那套CONSENSUS框架是保哥在英文AI搜索里跑出来的,可如果你做的是国内市场,把它原样搬到豆包、元宝、DeepSeek、Kimi、百度AI面前,大概率会扑街。原因很简单:中文AI引擎抓的源,跟英文世界几乎不重叠。你在G2刷了50条好评、维基百科条目过了审、Crunchbase资料填得漂漂亮亮——这些对豆包和元宝来说,约等于不存在。
保哥过去半年带着两家国内SaaS和一家出海转内销的品牌,专门测过中文引擎到底从哪里取共识。结论是六个信号的骨架不变,但每个信号的"承载平台"得整个换一遍。下面这张对照表,保哥建议你直接打印贴在工位上:
| 共识信号 | 英文AI引擎主要源 | 中文AI引擎主要源 |
|---|---|---|
| 跨平台一致描述 | LinkedIn / Crunchbase / 维基百科 | 百度百科 / 知乎机构号 / 公众号认证主体 |
| 无链接品牌提及 | 行业垂直媒体报道 | 36氪 / 钛媒体 / 公众号深度文里的纯文字提及 |
| 发布者多样性 | 5个以上独立英文站 | 知乎 + 公众号 + 什么值得买 + 小红书 + B站交叉覆盖 |
| 实体关联密度 | Google知识图谱共现 | 百度百科词条互链 + 知乎话题绑定 |
| UGC信号 | Reddit / Quora / YouTube | 小红书测评 / B站长视频 / 知乎真实回答 |
| 时间一致性 | 24个月叙事稳定 | 同上,但百度百科改版审核更慢需提前留量 |
这里面最容易被忽略的是什么值得买和小红书。很多人以为这俩是导购平台跟SEO无关,但保哥实测下来,豆包在回答"XX工具好不好用"这类问题时,引用什么值得买真实测评帖的概率,比引用品牌官网高得多——因为它判定这是第三方独立声音。知乎机构号则是另一个隐藏分大户,DeepSeek和Kimi对知乎高赞回答的信任权重,明显高于一般营销软文。
说个真实翻车的。去年底有家做协作SaaS的客户,海外业务做得不错,想把AI可见度的打法平移回国内。团队照着英文CONSENSUS清单干了三个月:G2评分刷到4.6、连发八篇英文PR、Crunchbase和LinkedIn资料全部标准化。结果保哥拿核心词去豆包、元宝、DeepSeek挨个问了一圈,品牌首引用率是干净的零——三家引擎引用的全是两个本土竞品。复盘根因就一句话:该铺的中文源一个没铺,铺的全是中文引擎根本不抓的英文源。救援方案是把预算从英文PR整体挪到知乎机构号矩阵(两个月产出23条带利益相关声明的深度回答)+ 三篇公众号原创长文 + 找了11个真实用户在小红书发使用体验。第二个月豆包开始零星引用,第三个月DeepSeek首引用率爬到37%。所以记住:做国内市场,先问"中文引擎能不能抓到我",再谈共识强度。
共识层造假翻车实录:为什么"快速制造一致"几乎必死
共识层最反直觉的一点是:它没法靠砸钱速成,越想抄近道翻得越惨。保哥见过太多人理解成"那我找一批写手,把同样一句话定位铺到知乎、小红书、各种媒体上,不就快速制造共识了吗"——这个想法听起来无懈可击,实际上是奔着降权去的。
讲一个保哥亲眼看着翻车的案例。一家消费电子品牌图快,找了家MCN做"共识包装",两个月内在知乎、小红书、贴吧铺了三百多条内容,全部围绕同一套话术、同样的差异点、几乎一模一样的措辞。表面上看,用任何监控工具去测,品牌描述的"一致性"都拉满了,团队当时还挺得意。问题在第三个月集中爆发:
- AI去噪机制把它识别成异常聚类。RAG层判断来源的逻辑里有一条是"独立性"——几百条措辞高度雷同的内容,在向量空间里挤成一个过密的点,反而被判定为near-duplicate批量内容,整组来源的权重被一起打折。DeepSeek和Kimi对这套内容直接选择不引用。
- 平台反作弊先动手了。知乎一轮清号把其中四成账号判为营销号限流甚至封禁,发布者多样性指数一夜之间从"看着挺多"掉回个位数。共识池里能用的独立来源,比铺量之前还少。
- 负面共识被同步喂大。因为内容太假,小红书评论区开始出现"这是不是恰饭""怎么全网一个话术"的质疑,这些真实质疑反而成了AI愿意引用的高可信UGC,把"疑似刷量"写进了品牌的共识描述里。
这家品牌花了大概五个月、烧掉一笔不小的预算,换来的是比开工前更差的AI可见度,外加一身需要花一年去稀释的负面共识。保哥后来给的救援逻辑很朴素:停掉所有批量铺量,老老实实让真实用户、真实媒体、真实社区讨论自然涌现,哪怕慢。
这跟前面"六大踩坑"里说的"同一篇PR到处发"不是一回事——那是单点失误,这是整个方法论方向反了。共识层的本质是"多个真正独立的来源,恰好对你形成了一致判断",重点在"真正独立"四个字。一旦这些来源是你同一只手批量制造的,它在统计上就是异常值,而异常值正是RAG最想过滤掉的东西。保哥的拇指法则是:如果一批内容是同一周、同一拨人、用同一套话术产出的,AI早晚会把它们当成一个来源甚至一个噪声源处理。能造假的共识,本质上就不是共识。
常见问题解答
共识层和E-E-A-T是同一个东西吗?
不是。E-E-A-T是Google对内容质量的评估框架,针对单个网站或作者。共识层是跨多个AI系统、跨多个发布者的分布式信号,更宏观也更难造假。E-E-A-T是共识层的必要条件之一,但远不充分。一个有强E-E-A-T的网站,如果只孤立存在没有分布式可信度,仍然会在ChatGPT中失声。
初创公司没预算做PR怎么办?
保哥的建议顺序:先把10大权威平台档案做扎实(成本接近0,只花2周人时)→ 然后CEO亲自下场在Reddit、Quora、HackerNews产出12-20篇深度回答(成本0,时间投入大)→ 之后再考虑付费PR。零预算的方案能在6个月内把AI引用率从0拉到15-25%。
怎么判断我的品牌已经形成共识?
用同一个query分别问ChatGPT、Perplexity、Claude、Gemini四个系统,看它们给出的品牌描述是否一致。如果四家系统都把你描述成同一个赛道、同样的差异点、同样的代表客户——你形成了共识。如果四家说法天差地别甚至矛盾,你还在共识层之外。
负面共识有可能吗?怎么破?
有。最常见的是"过去某个产品事故被多家媒体报道",AI会反复合成这个负面叙事。破解方案:不能删(删不掉),只能稀释——用大量新的、正面的、独立来源去稀释负面来源在共识池里的占比。通常需要18-24个月才能反转。
共识层会不会让小品牌彻底没机会?
恰恰相反。共识层降低了对域名权威分的依赖,提高了对叙事一致性和分布式提及的要求。小品牌如果能在某个垂直细分上做到"所有人都用同样的话描述它",反而比大公司更容易形成共识。保哥见过DR只有18的小工具,因为在一个垂直社区里被持续讨论了8个月,ChatGPT首引用率比同赛道DR70的大厂还高。
多久能看到效果?需要持续投入多少?
典型周期:第1-30天打基础(无可见效果);第31-90天信号开始积累(AI引用率0→10%);第91-180天爆发期(10%→40-60%);第180天后进入护城河期。持续投入大概是一个全职内容/品牌岗+月度PR预算(小品牌1-3万人民币、中型品牌5-15万)。砍掉一半投入也能跑,但效果出现的时间会拉长50%。
如果不做共识层会怎样?
短期看,依然能从传统Google有机搜索拿到流量,只是CTR会持续下滑。中期看(2026年下半年起),随着AI搜索渗透率突破35%临界点,AI隐身的品牌会被竞争对手稀释pipeline。长期看(2027年后),共识层会变成跟"有官网"一样的基础设施——没有它,你连"被讨论"的资格都没有。这就是为什么保哥强烈建议每家公司2026年Q2前必须启动共识层项目。
权威参考资料
本文标题:《AI搜索不引用你?共识层6信号90天实战指南》
本文链接:https://zhangwenbao.com/seo-consensus-layer-ai-search.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0