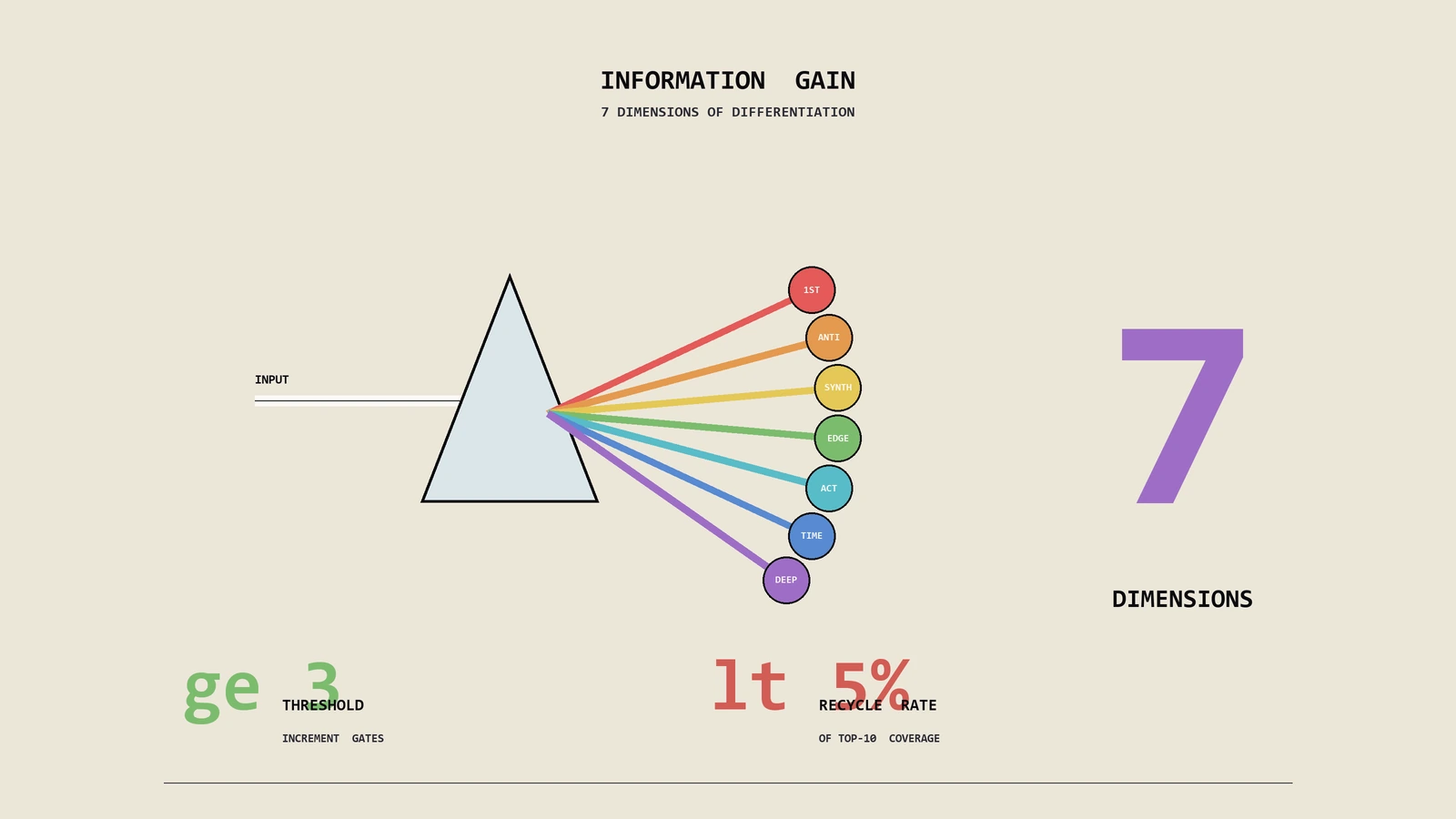
电商关键词SEO与SEM怎么分?意图分层实战与预算不内耗5步
广告点击自然结果各排第一,转化没涨预算花两份?答案不在加预算,是给两个团队画一张分工图。本文给出按转化距离切的三圈词表、SEO 与广告各自的主战场、互踩词清单与告警,以及把方法跑成日常需要的看板与复盘节奏。
想让网站在谷歌和百度持续拿到免费流量,靠的不是碰运气而是体系。这里汇集保哥二十多年的SEO实战经验,从关键词研究、页面与技术优化到外链建设、内容策略和算法应对,手把手带外贸、独立站与SEO从业者把搜索排名做成可复制的长期增长。
广告点击自然结果各排第一,转化没涨预算花两份?答案不在加预算,是给两个团队画一张分工图。本文给出按转化距离切的三圈词表、SEO 与广告各自的主战场、互踩词清单与告警,以及把方法跑成日常需要的看板与复盘节奏。
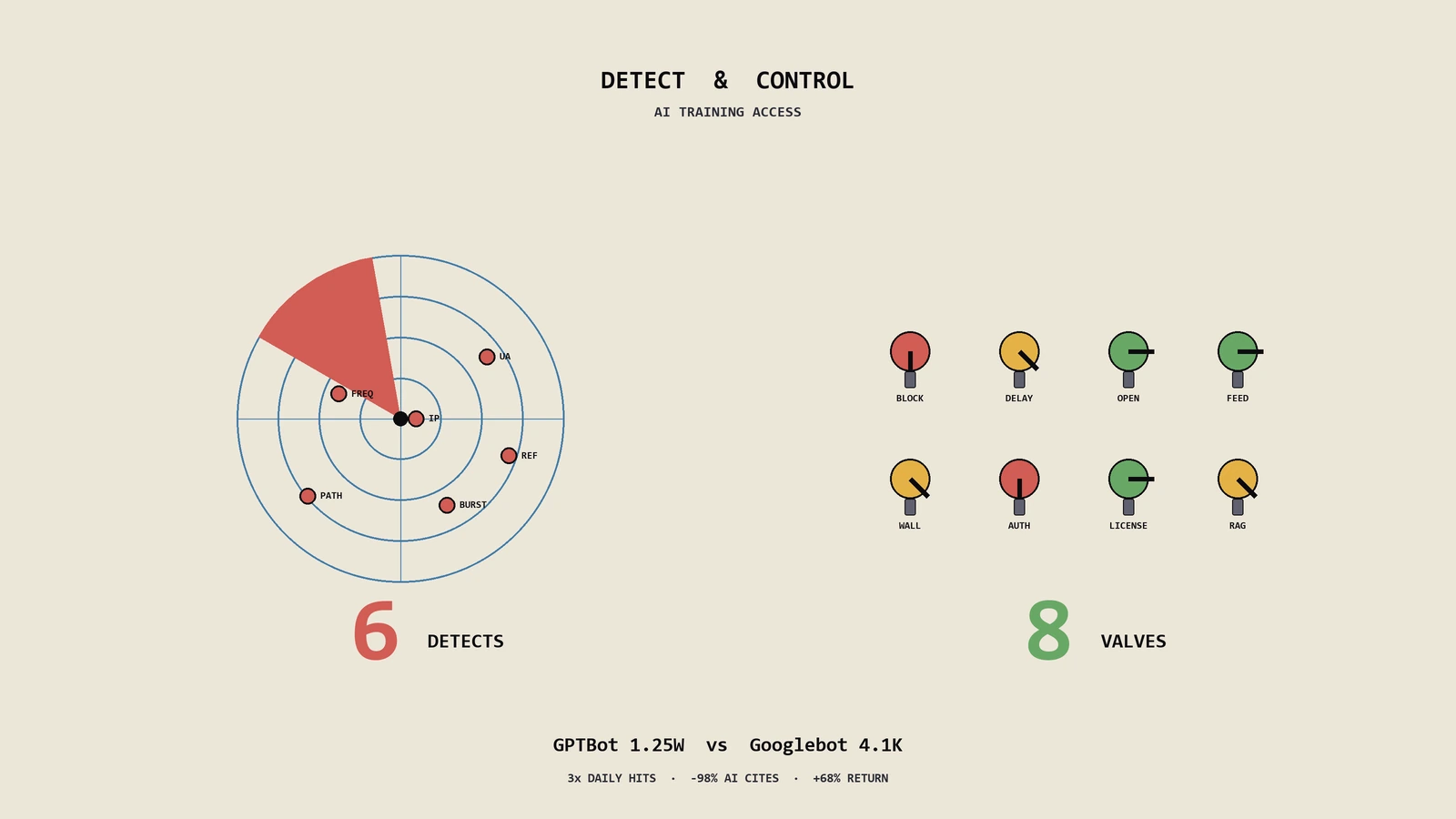
出海精油护肤DTC客户上周拿来一份Cloudflare日志,问我那批名字奇怪的爬虫是不是在偷她家产品文案训练AI。答案多半是,但靠常规思路盲拦不是好路子,需要先用6种方法把检测做实,再按内容资产价值、流量回路、品牌曝光、法律边界4维度走8种授权选择决策矩阵,最后把AI引用反向变成新流量入口。
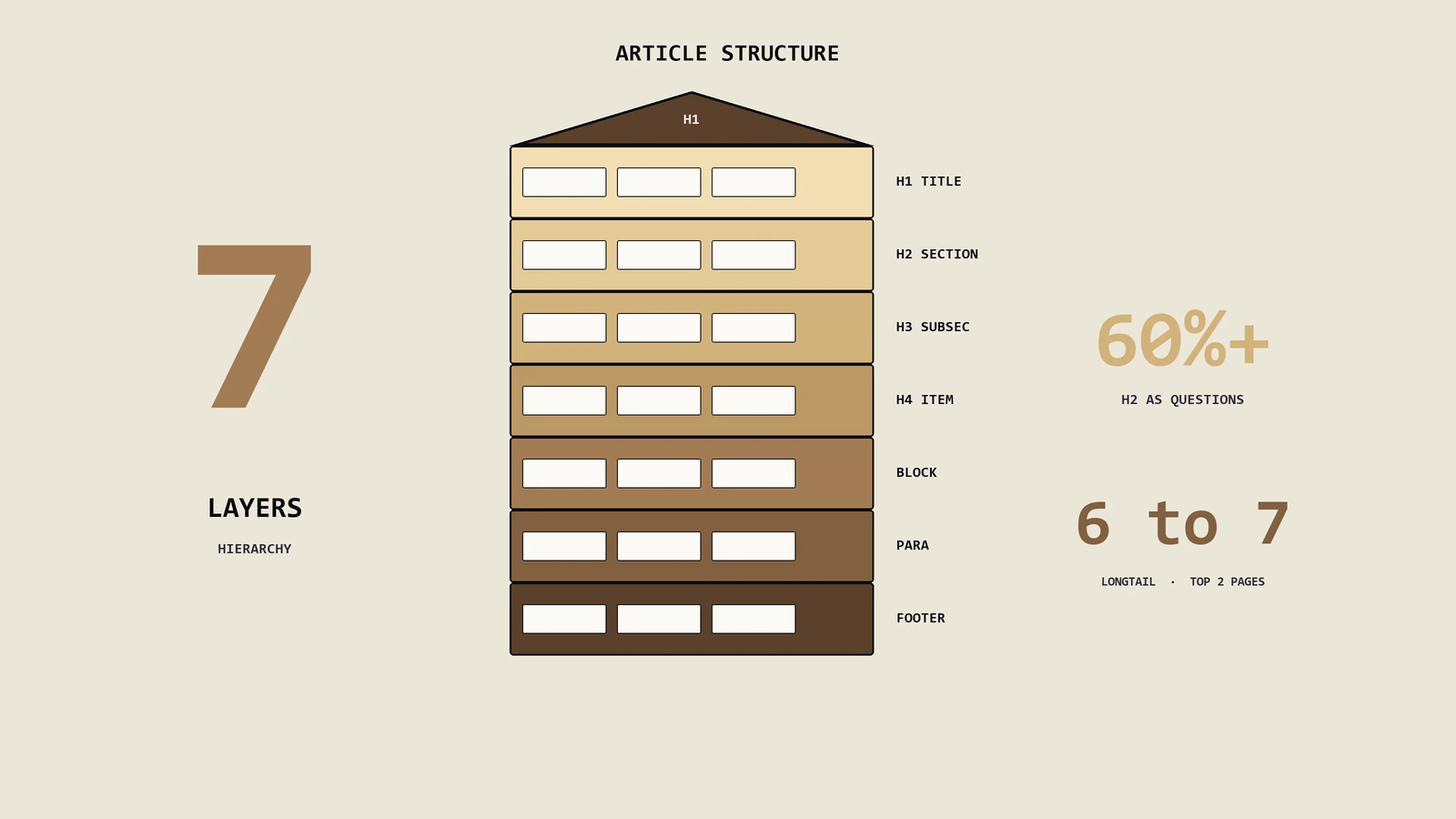
内容不少却排不上、AI从不引用,根子常在结构没切到引擎能用的形状。本文从搜索引擎解析文档结构的机制讲起,给出标题层级、段落信息块切分、主题聚合的可落地规则,并附一个出海男装独立站的真实结构改造案例与收尾自查清单。
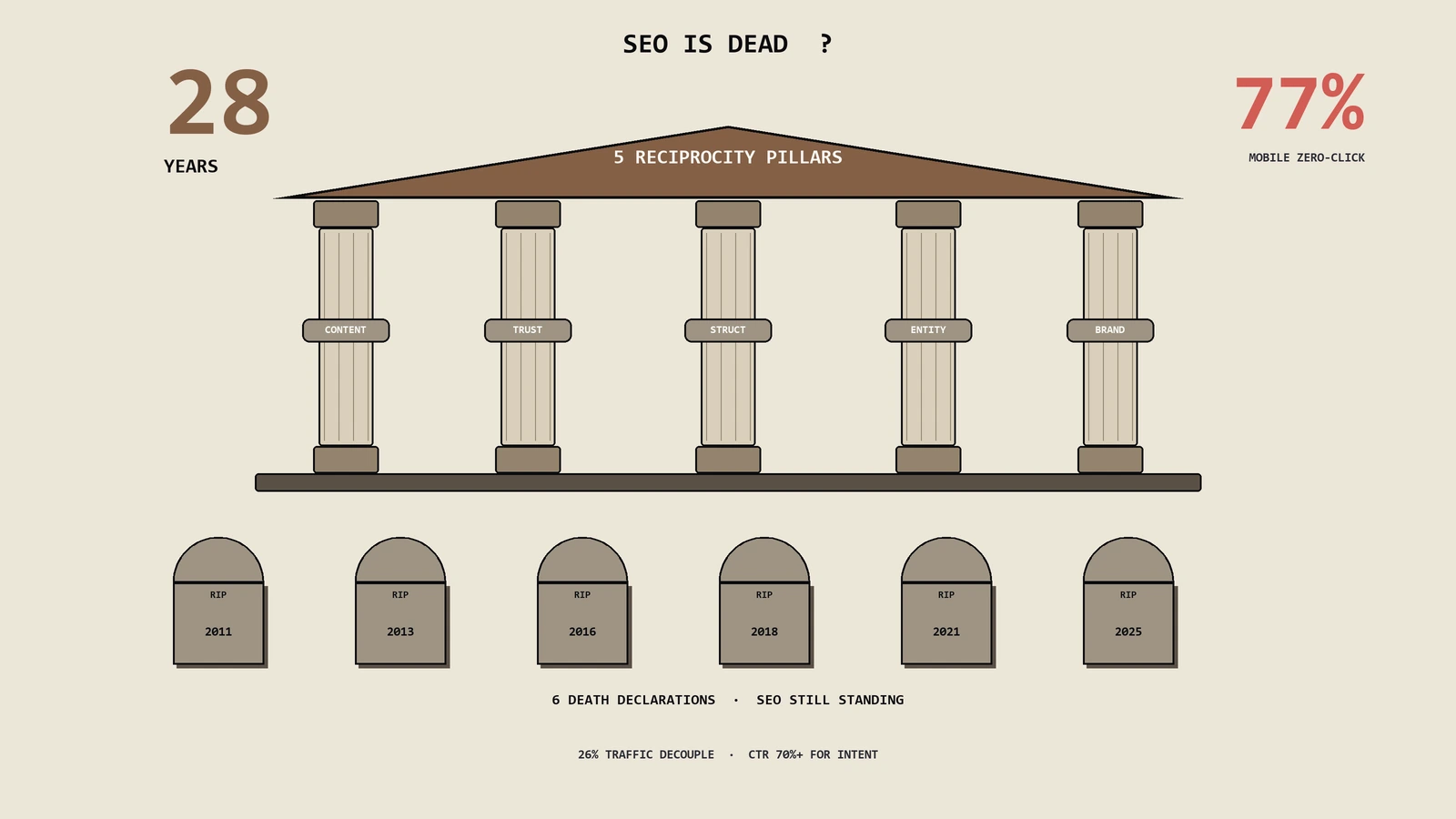
出海手工瓷器DTC老板上周问保哥:AI Overviews把月3万自然流量打掉8000,SEO是不是真死了?答案是没死,但2008-2026已经有6次同样的死亡宣告,零点击数据看着吓人,商业转化型查询点击率却仍在70%以上,关键看清搜索引擎和网站之间5大互惠机制现在崩了几个、哪3类SEO工作要真没了、哪5类反而更值钱。
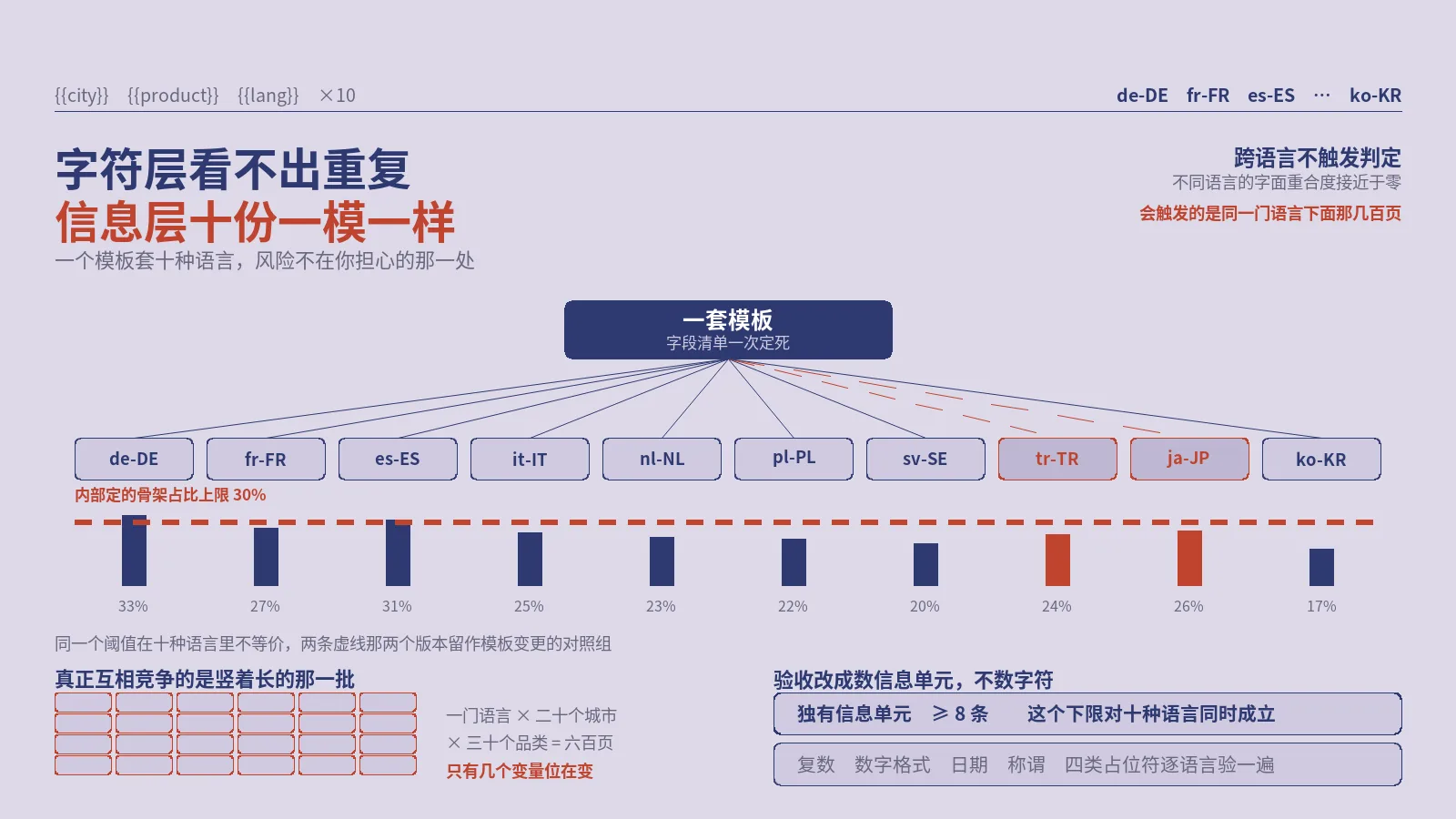
团队一般是先担心十个语言版本互相重复,在跨语言标注上花掉大半精力,真正出事的却是同一门语言下按城市和品类铺开的那几百页。这里按把重复分成跨语言与同语言两层分别判、按语言重算模板骨架占比、把复数与数字与日期这些占位符逐语言验一遍、留两个语言版本当模板变更的对照组、每季度抽样核对信息缺口五步收口。
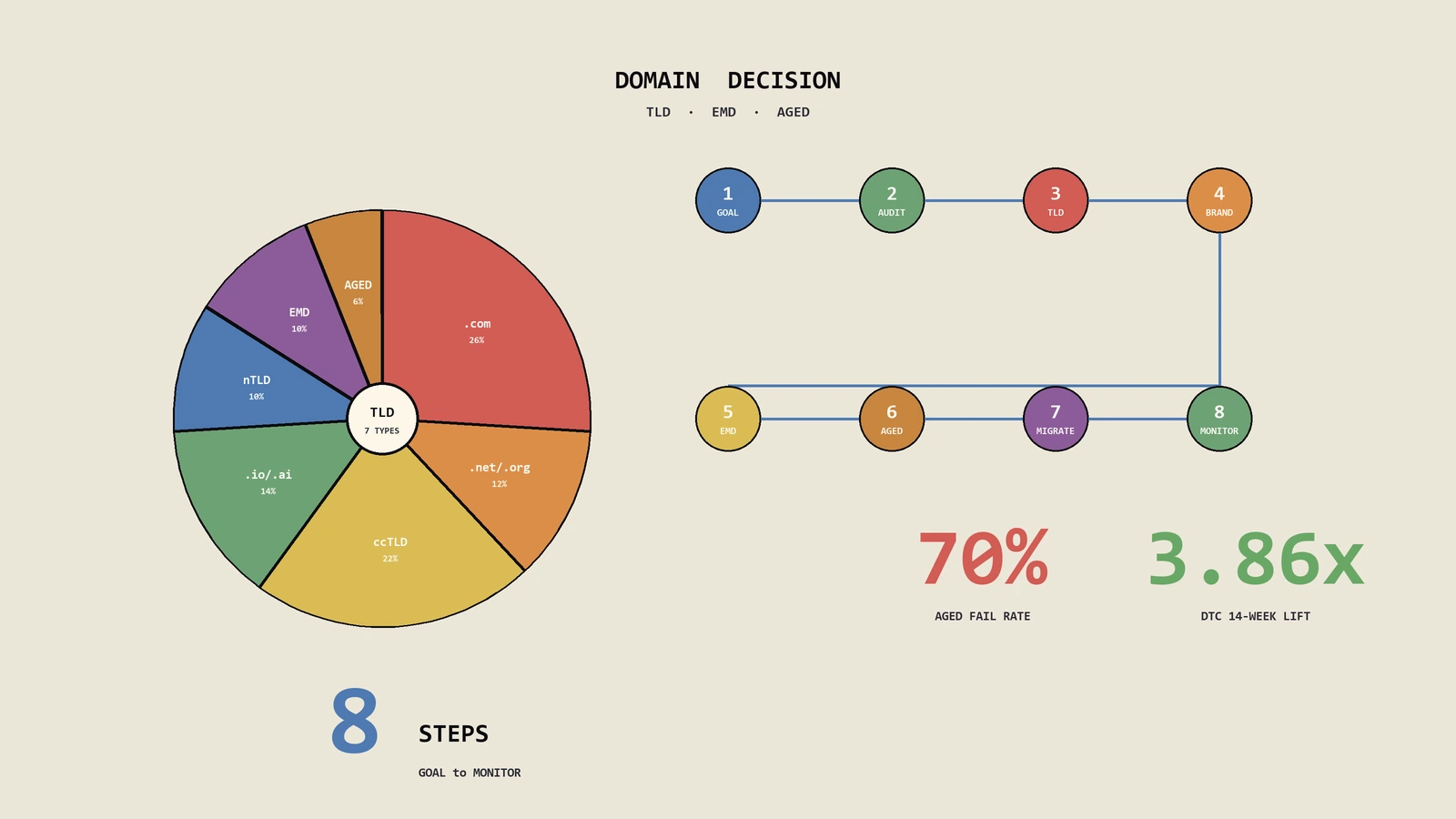
域名选择是SEO决策成本最高的一步——5年后想换品牌等于推倒重来。过去3年帮28家出海独立站做域名选型实操,跑出来一些反常识结论:EMD不再香、老域名70%是坑、多TLD防御性注册过头反而稀释品牌信号。本文把TLD 7类的SEO信号差异、品牌词对EMD的决策路径、老域名收购6维度评估法、新站沙盒期28客户实测数据、Google惩罚域名识别8步审查清单、出海hreflang矩阵下的域名编排、北美宠物用品DTC 5国域名矩阵14周翻4倍真账…
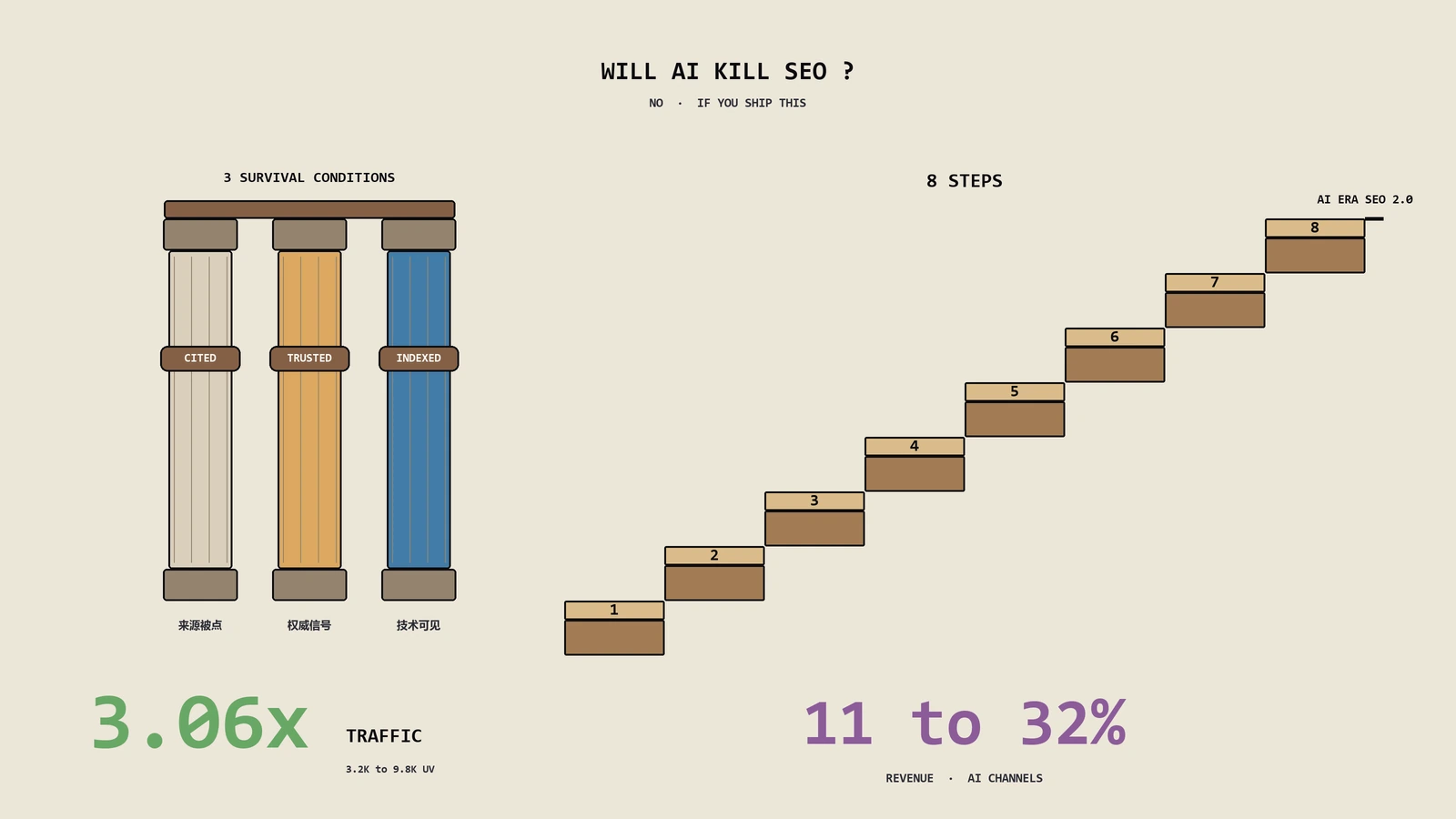
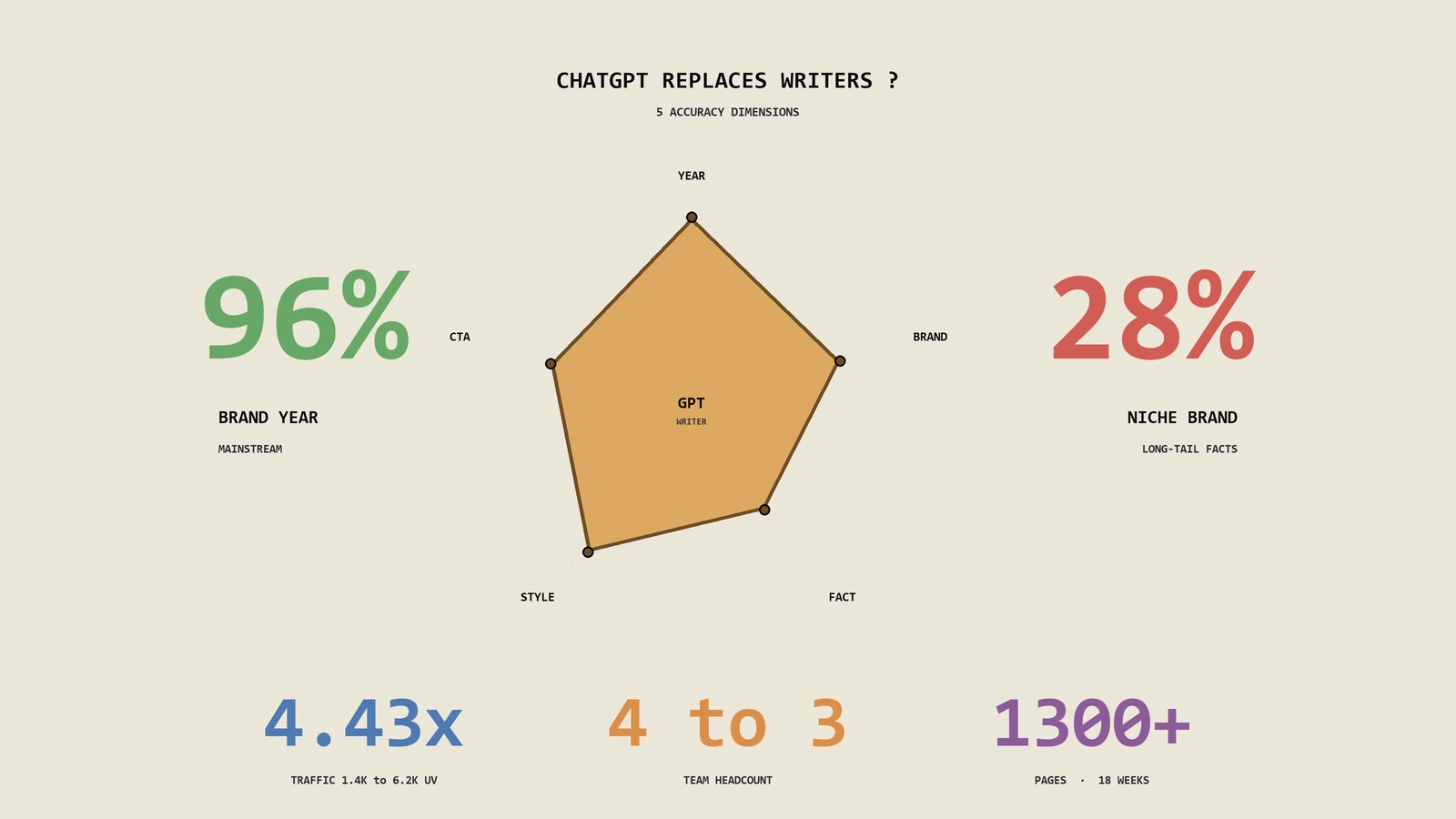
ChatGPT级别AI到底会不会让SEO消失?这篇从Bing整合ChatGPT保留编号出处和Google Bard初期隐去链接两条路径切入,把SEO在AI搜索时代的三大生存条件(出处链接、版权合规、AI准确率瓶颈)8步实战工作流讲透,含一个出海户外野营装备DTC客户16周从被AI冷落到月自然流量3200做到9800、AI来源月引用从0涨到月1240次的完整复盘,再加12类必做必停清单。读完不止知道SEO不会死,更知道接下来怎么把SEO升…
ChatGPT到底能不能取代内容写手?答案不是是非题,是分类题。哪5类内容AI能稳定取代、哪5类必须真人主导、Google有用内容更新为什么和ChatGPT能力边界精确镜像对应、三段流水线模式怎么分工、出海英伦绅士手工皮鞋DTC18周从纯人工切到AI辅助效率翻倍的完整路径,一次性拆开
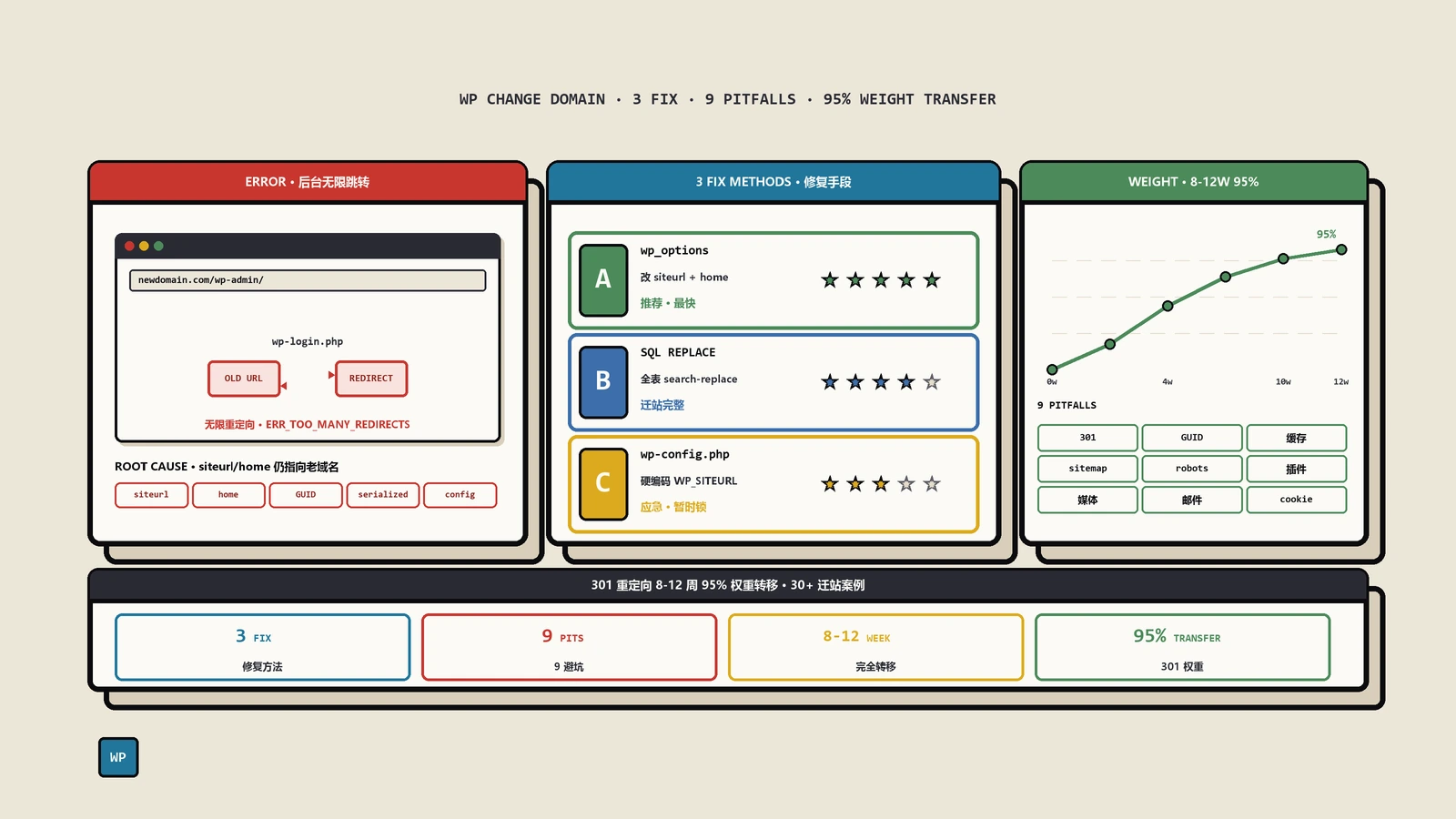
WordPress 换域名后用新域名访问后台始终跳回老域名,根因是 wp_options 里 siteurl 与 home 没改。本文给出 phpMyAdmin 改字段、SQL 全库 REPLACE、wp-config 硬编码三种修复方法及九条迁站清单。
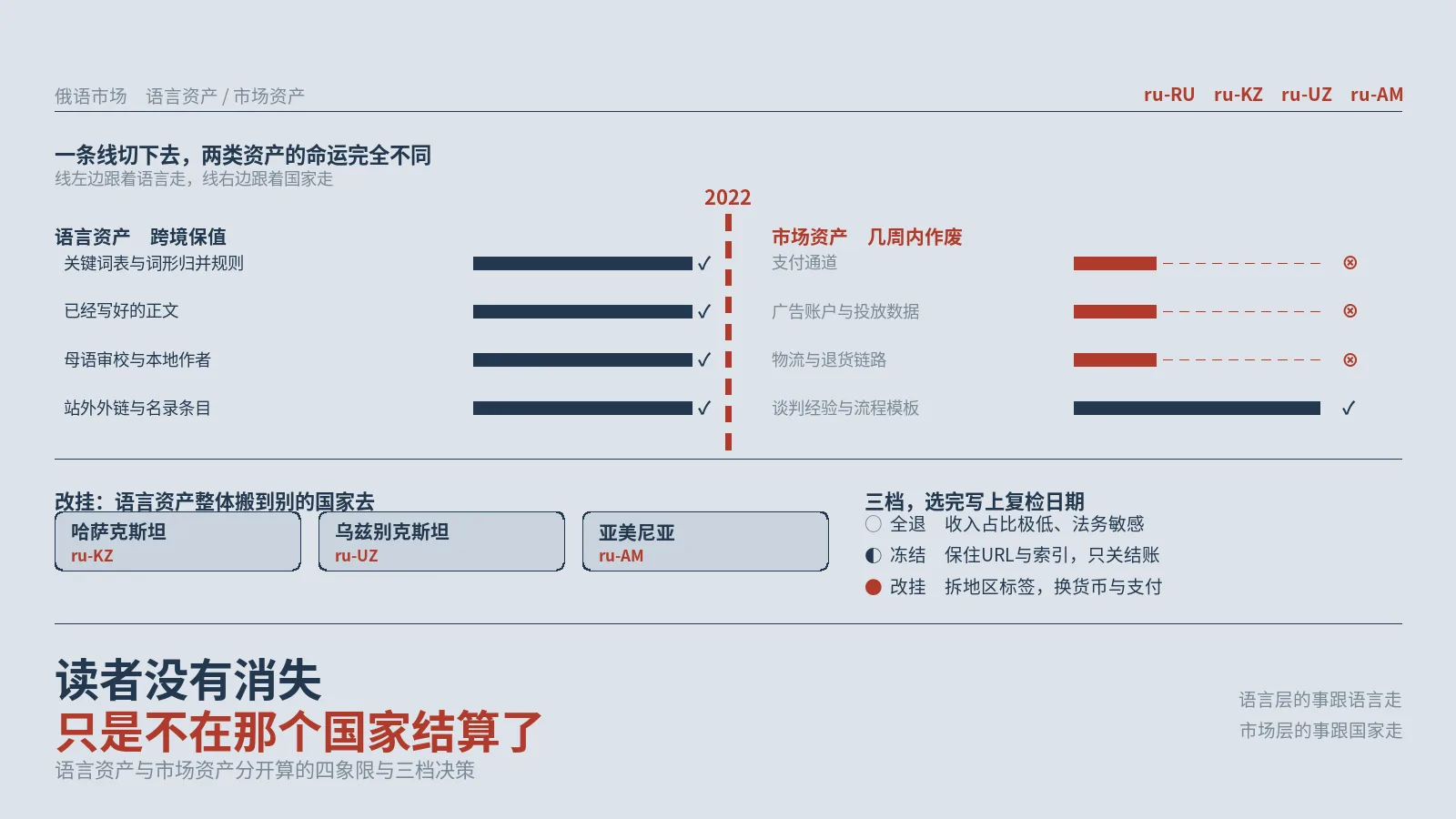
团队一般是开个会决定砍还是不砍,砍了发现关键词规则和词形归并这些最费时的东西一起没了,不砍又眼看着支付和物流两头断掉。这里按把流量按国家拆开重数一遍、把资产分成语言与市场两类填四象限、按四条判据在全退与冻结与改挂之间定档、冻结时保住URL与索引只关结账、改挂时逐行核对七个字段、给决策写上复检日期与负责人六步收口。
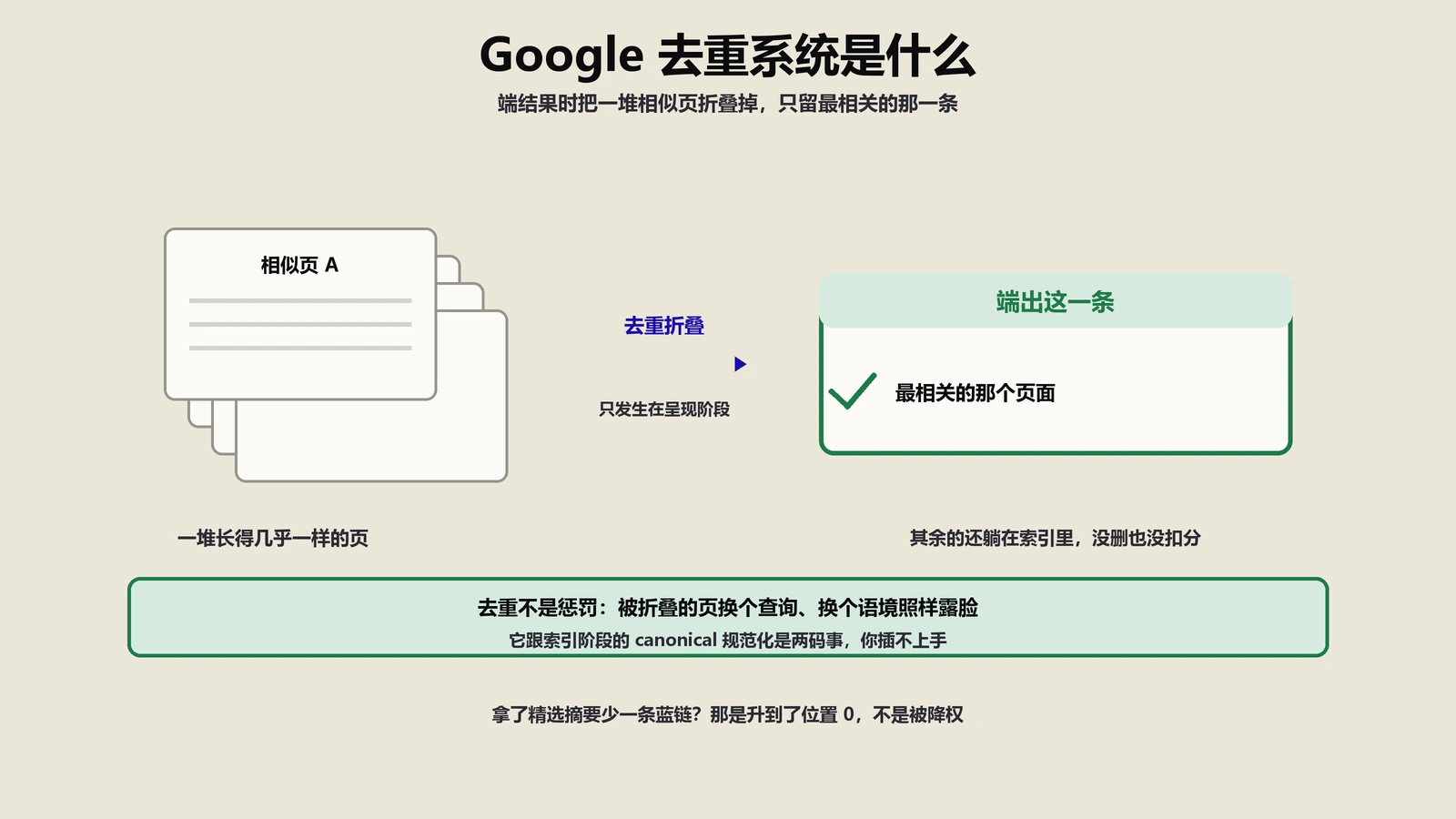
拿了精选摘要,普通排名那条却不见了,是被降权吗?多半不是,是去重系统在折叠重复。带一个客户以为被降权、其实是升到位置0的真实案例,讲清去重卡在搜索哪一步、跟canonical规范化和重复内容惩罚误区怎么分清。
判断搜索引擎蜘蛛在内容更新、网站重构、A/B测试、反爬限流等合规场景中很常用。本文系统拆解301、302、Meta Refresh、HTTP状态码、JS跳转5种原理,给出Discuz黑白名单、分类日志统计、UA全集匹配、判断后跳转、JS referrer分流5种PHP代码实战,并补充2026年AI爬虫识别清单、双向DNS校验进阶方案与cloaking合规红线。

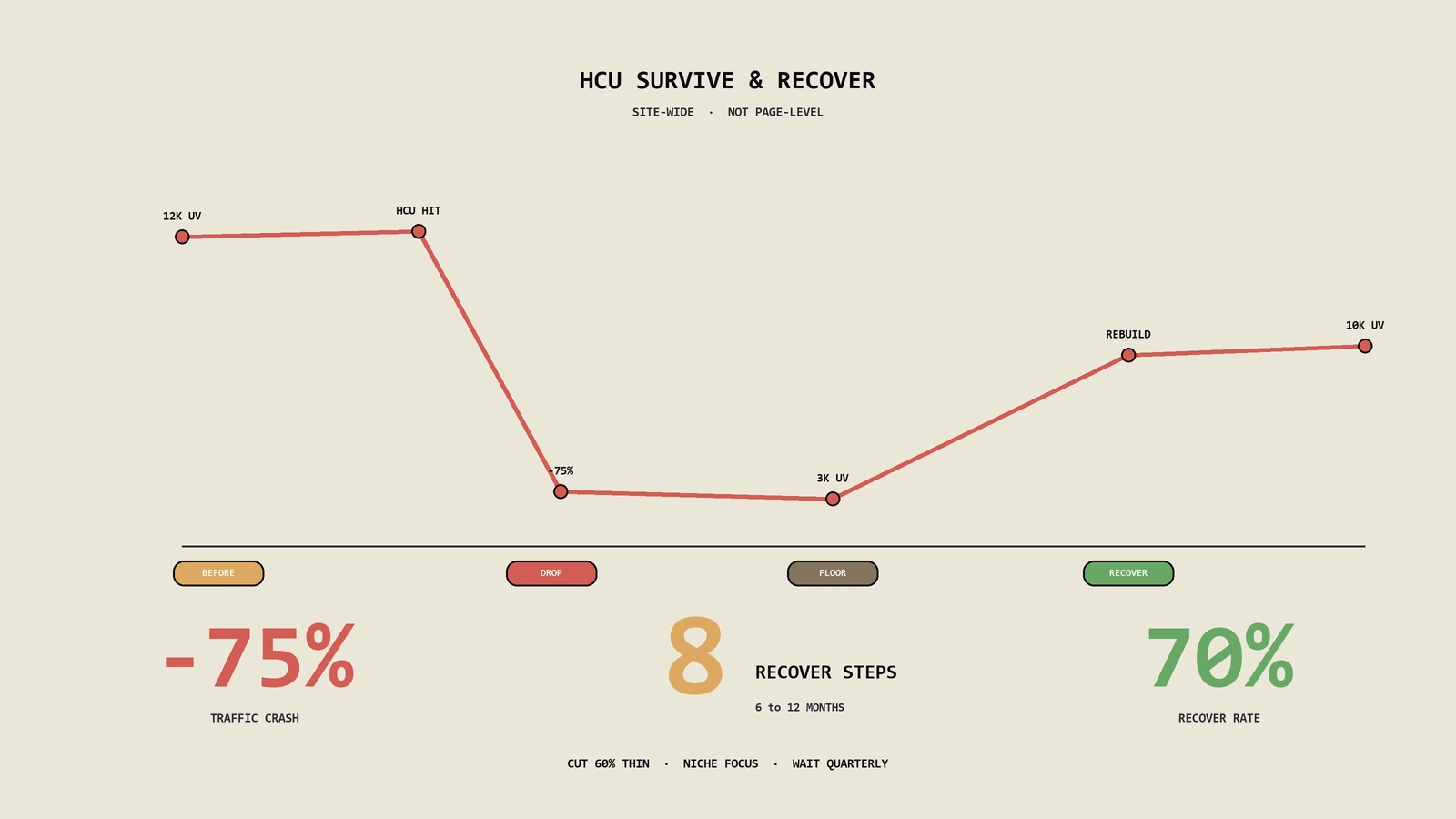
有用内容系统(HCU)是 Google 持续运行的站点级质量分类器,单页 SEO 改动救不了它。本文讲清它的机制、谁是中招重灾区、怎么用目录级数据自查,以及一条在客户站上真正跑通、跨越多次核心更新的恢复路径。
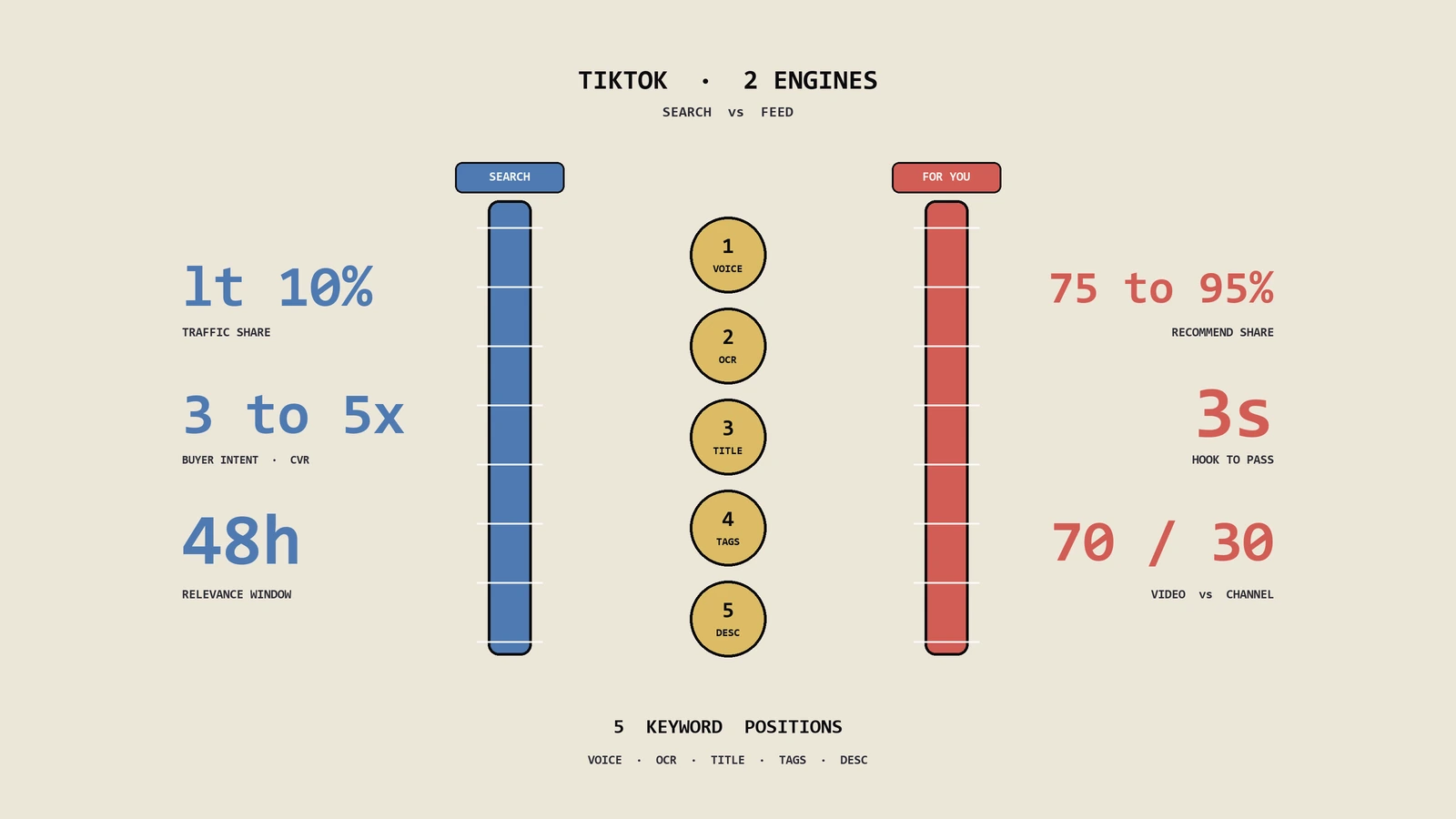
大量年轻用户遇事先在TikTok里搜,而不是打开Google或百度,可绝大多数人还在用做爆款的思路做搜索,方向从一开始就错了。这篇把TikTok怎么读懂一条视频、搜索结果和For You到底差在哪、关键词该落在哪五个位置、和YouTube小红书机制有什么本质区别、出海品牌词被占了怎么抢回来,按机制一层层拆开。
团队一般是拿一张使用人口排名表从上往下勾,勾完发现本土语页面上线三个月没有一条自然流量。这里按先查这门语言有没有书面商业语域、按承载度分成整站与只做词表与交给殖民语三档、把语言与货币与物流三条边界各画一遍、豪萨语词表改用键盘打得出的退化拼法当主键、每个市场先跑三个月只做词表的试水期五步收口。

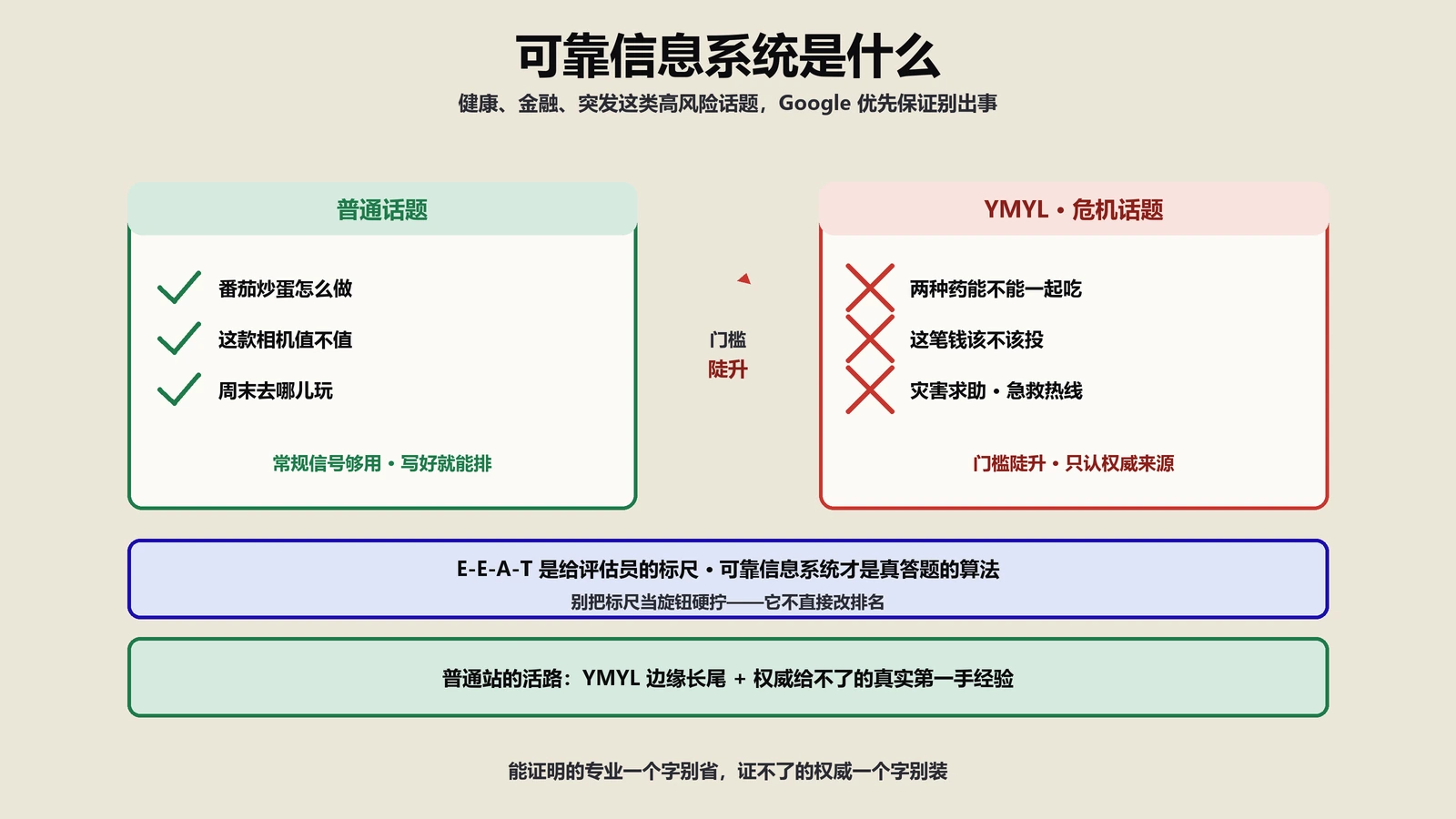
健康、金融、突发事件这类高风险话题,为什么普通站怎么写都排不过权威机构?答案藏在可靠信息系统和危机信息系统里。带一个健康监测客户撞YMYL墙半年、转真实体验翻身的案例,讲清它们跟E-E-A-T和YMYL的关系。
Google2024年用INP替代FID当作Core Web Vitals的交互指标,许多原本绿盘的站点掉进黄红区。这篇把背后的统计口径、三段时序、主线程长任务机制、四类修复手法和不同框架的具体配方逐一拆透,并讲清楚它对SEO排名的真实权重。

团队一般是把这个市场归进英语那一格,英文站原样复用,直到转化率长期低于同批投放的其他地方,才回头查最上游那份关键词表。这里按导出站内搜索与客服对话只采样不加工、穷举他加禄语疑问壳做笛卡尔积、把品类词换成当地英语说法、标题与问答区改成问句形态、商品页的尺码地址付款三组字段一起动、客服模板按两档语域各出一版六步收口。

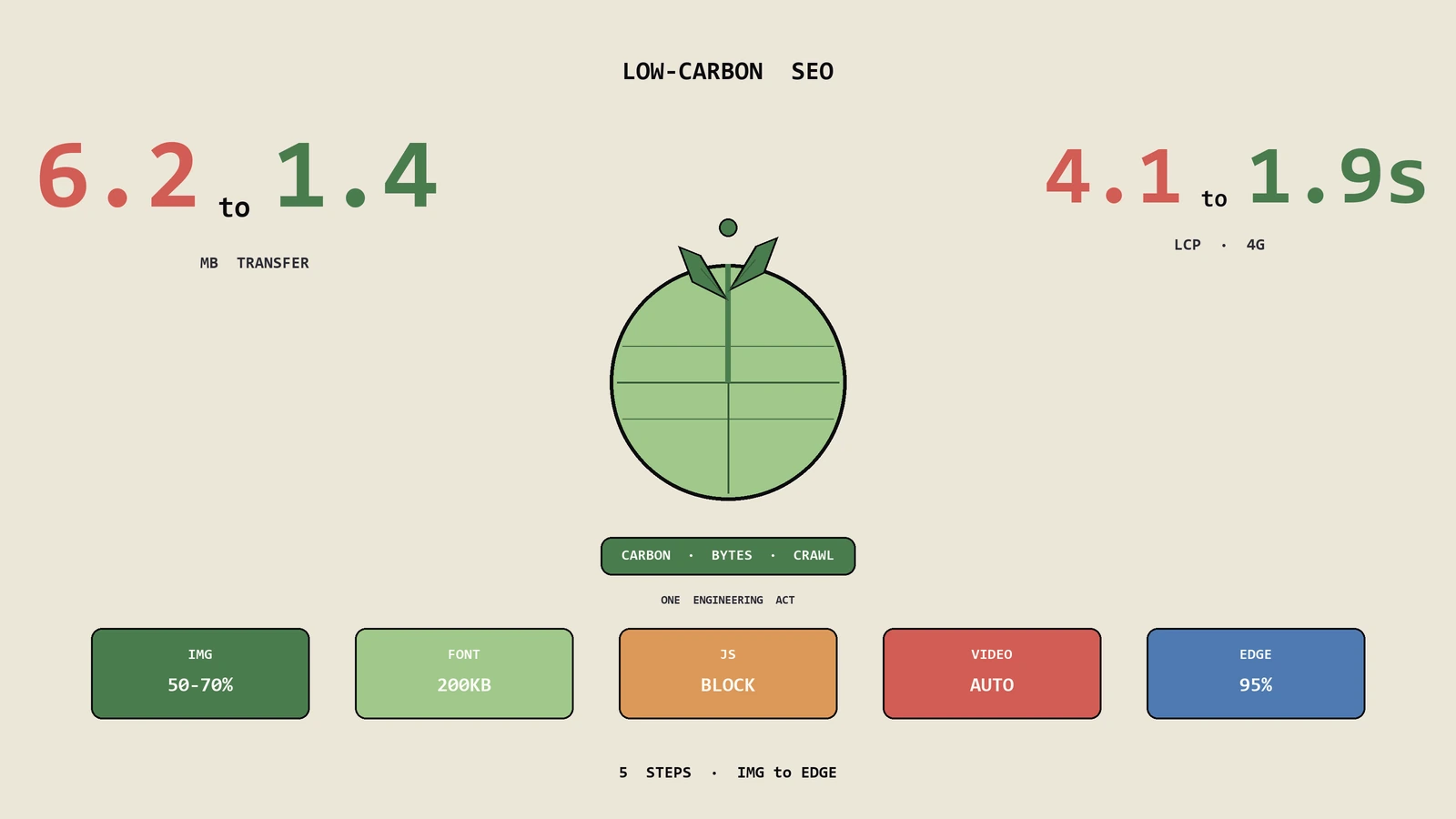
低碳SEO常被当成营销噱头或道德议题,其实它是一道工程题:本文从网页碳排放的能耗模型讲起,拆解绿色徽章为何不是排名信号、页面瘦身按图片字体脚本的什么顺序与阈值推进、CDN与绿电主机怎么辨洗绿、以及AI爬虫暴涨后抓取预算这道账被怎样重算,最后给一套能排进季度的可持续SEO体检清单。
盯着对手第一名写一篇更长更全的去盖,这套早不灵了。本文讲清搜索引擎与AI怎么按相对结果集的增量评估页面,增量从七个真实维度怎么产生,动笔前怎么做增量盘点,以及为什么没增量的长是被同时惩罚的。