社交平台成了AI的二级搜索框:别人在别处怎么说你,决定AI信不信你
本文目录
- 先把话说清楚:社交平台不是新的Google,是AI的二级索引加验证层
- AI引擎为什么开始“读”社媒:一手语料、实时性、真人信号
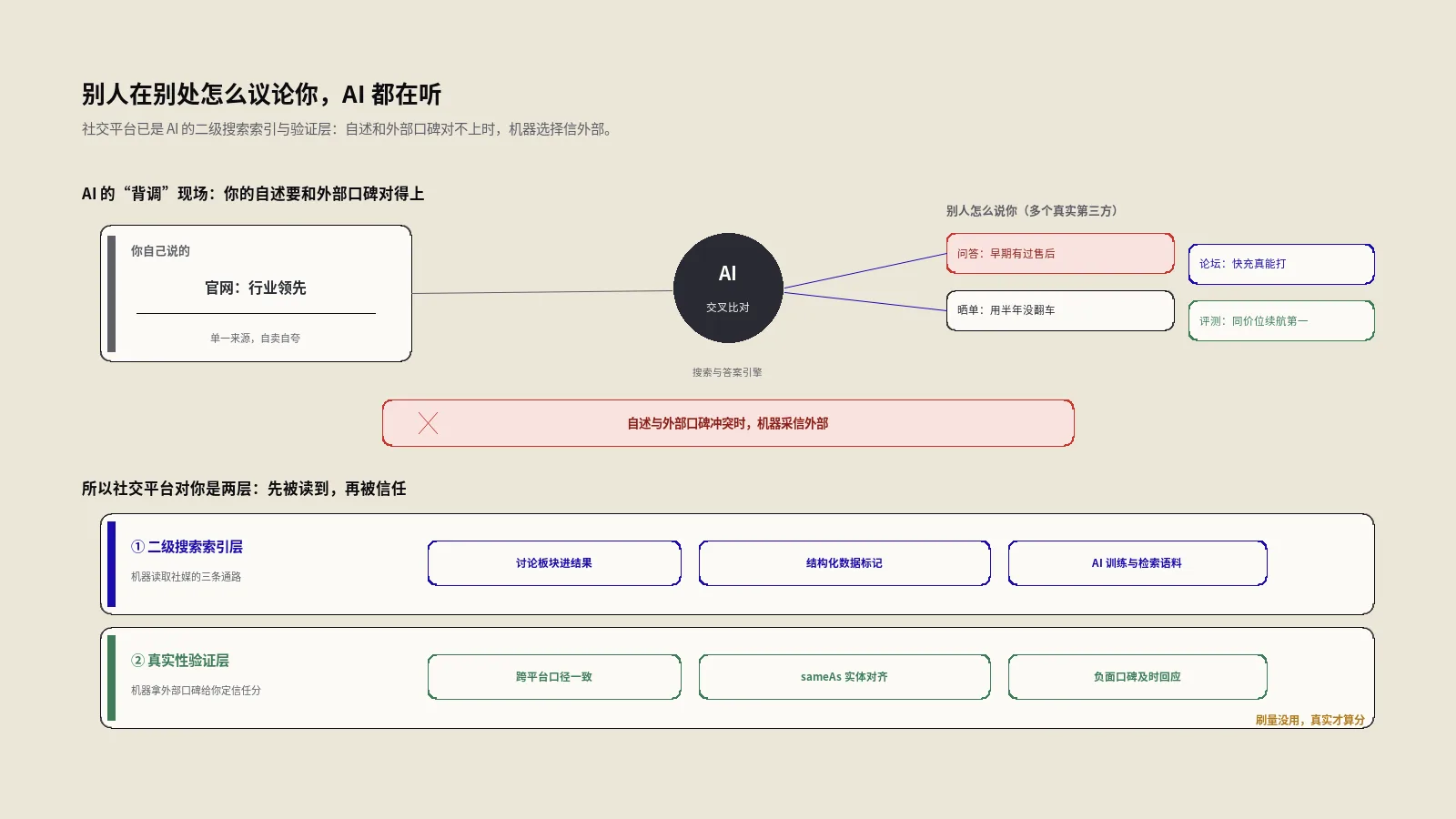
- “二级搜索索引”到底指什么:机器读取社媒的三条真实通路
- 通路一:搜索结果里的独立讨论板块
- 通路二:结构化数据把社区内容标成“机器可识别”
- 通路三:直接进AI训练与检索语料
- 真实性验证层:AI怎么用“别人怎么说你”给你定信任分
- 落地打法:把社媒经营成机器可读的验证层
- 把社媒验证层接进现有工作流:四个接入点
- 一个出海独立站的真实切片
- 三个最容易踩的误区
- 常见问题解答
- 社交平台真的会取代Google成为主搜索吗,我是不是该把预算搬过去?
- 我是纯SaaS建站,改不了底层代码,结构化数据和sameAs这些还能做吗?
- 我没有站内论坛或评论区,DiscussionForumPosting这套是不是跟我没关系?
- 这件事见效要多久,能不能像投广告那样立刻看到结果?
- 负面讨论我到底是该回应还是该想办法压下去?
- 怎么衡量我在“真实性验证层”上做得好不好,有没有可看的指标?
- 权威参考资料
摘要:社交平台在AI时代的角色已经换了——它不再只是给你引流的渠道,而是变成了机器读取与交叉验证你这个品牌的“二级搜索索引”。Google把Reddit的内容抬进搜索结果、又花钱拿它训练AI,AI答案越来越多地引用论坛和社媒里的真人讨论,本质都是同一件事:你在别处被怎么议论,正在直接决定AI信不信你、推不推你。这篇不教你去刷粉刷量,而是把社媒拆成两层来经营——一层是“能被机器读懂”的二级索引层,一层是“口径一致、有第三方背书”的真实性验证层,给出可落地的步骤、一份出海独立站的真实切片,以及三个最容易踩的误区。
先说一个让不少独立站老板别扭的判断:你花最多预算的那块SEO,可能正在被你最不当回事的那块社媒悄悄决定。
过去十几年,社媒在大多数人的脑子里就一个定位——流量渠道。发帖、投广告、把人导到站上来,转化,结束。粉丝数、互动率、引流UV,这套指标体系大家都熟。但AI搜索把规则改了。今天一个潜在客户在ChatGPT、Gemini或者Google的AI概要里问“XX这个牌子靠谱吗”“做XX的有哪些值得买的”,给出答案的那台机器,不只是读了你自己官网上的自卖自夸,它还去翻了Reddit的吐槽帖、翻了行业论坛的对比、翻了你被别人顺嘴提到的那些角落——然后把这些拼起来,决定要不要把你放进答案里。
换句话说,社媒已经从“你说给用户听的地方”,变成了“机器替用户去核实你的地方”。保哥把这个新角色拆成两层:它既是AI的二级搜索索引,也是AI的真实性验证层。这篇就把这两层讲透,再落到你下周就能动手的清单上。
先把话说清楚:社交平台不是新的Google,是AI的二级索引加验证层
这两年“社媒就是新的搜索引擎”这种话满天飞,听上去很带感,但容易把人带沟里。我们先把数据摆正。
确实有大趋势在发生。Axios关于Z世代越来越多用TikTok与YouTube做搜索的报道把这股风讲得很清楚:年轻一代找信息,第一站越来越常是社交平台而不是搜索框。第三方调研里这个体感也对得上——把TikTok当搜索用过的消费者比例,这两年从四成出头涨到了近一半,Z世代里“用过TikTok搜东西”的更是接近三分之二。
但如果你就此得出“赶紧把预算从Google搬到TikTok”,那就读偏了。同一批调研里有个被大多数标题党忽略的细节:真正“偏好TikTok胜过Google”的Z世代,比例反而从2024年的约8% 掉到了2026年的4%,几乎腰斩。也就是说,社媒搜索的盘子在变大,但它吃掉的不是Google的主菜,更多是作为一道“补充菜”存在——用户先在某个地方看到你,再去另一个地方核实你,来回交叉。
这个“来回交叉”才是关键词。社交平台真正的新身份,不是取代主搜索的那个框,而是:
- 二级索引层——主搜索引擎和AI引擎在生成答案时,会把社媒和论坛上的真人内容当成一个独立的、可被读取的语料库去检索,作为它们对一个话题“还有没有别的声音”的补充来源。
- 真实性验证层——当机器拿不准“你自己说的”到底可不可信时,它会去这些第三方场景里找佐证,看你的口碑和你的自我描述对不对得上。
把这两层分清楚很重要,因为它直接决定你该往哪使劲。如果你以为社媒是新主搜索,你会去拼播放量、拼爆款;可一旦你认清它是二级索引加验证层,你会转而去经营“被机器读懂的结构”和“被第三方背书的口碑”——这两件事跟刷量几乎没关系。这些年帮出海站做GEO,最常见的浪费就是这个错位:钱砸在涨粉上,结果AI答案里依然查无此人。
关于“被检索”和“被推荐”到底是两套不同的功夫,之前单独写过一篇拆解,想把底层机制吃透的可以先看这篇区分“被检索”和“被引用”两套打法的文章,这里不展开重复,下面直接讲社媒这一层怎么落地。
AI引擎为什么开始“读”社媒:一手语料、实时性、真人信号
要理解社媒为什么成了二级索引,得先搞清楚AI引擎缺什么。大模型最怕两件事:一是只能看到“被精心包装过的官方话术”,二是知识停在某个训练截止日、跟不上现实。而社媒和论坛恰好同时补上了这两个缺口——它有海量真人原话,而且是实时滚动的。
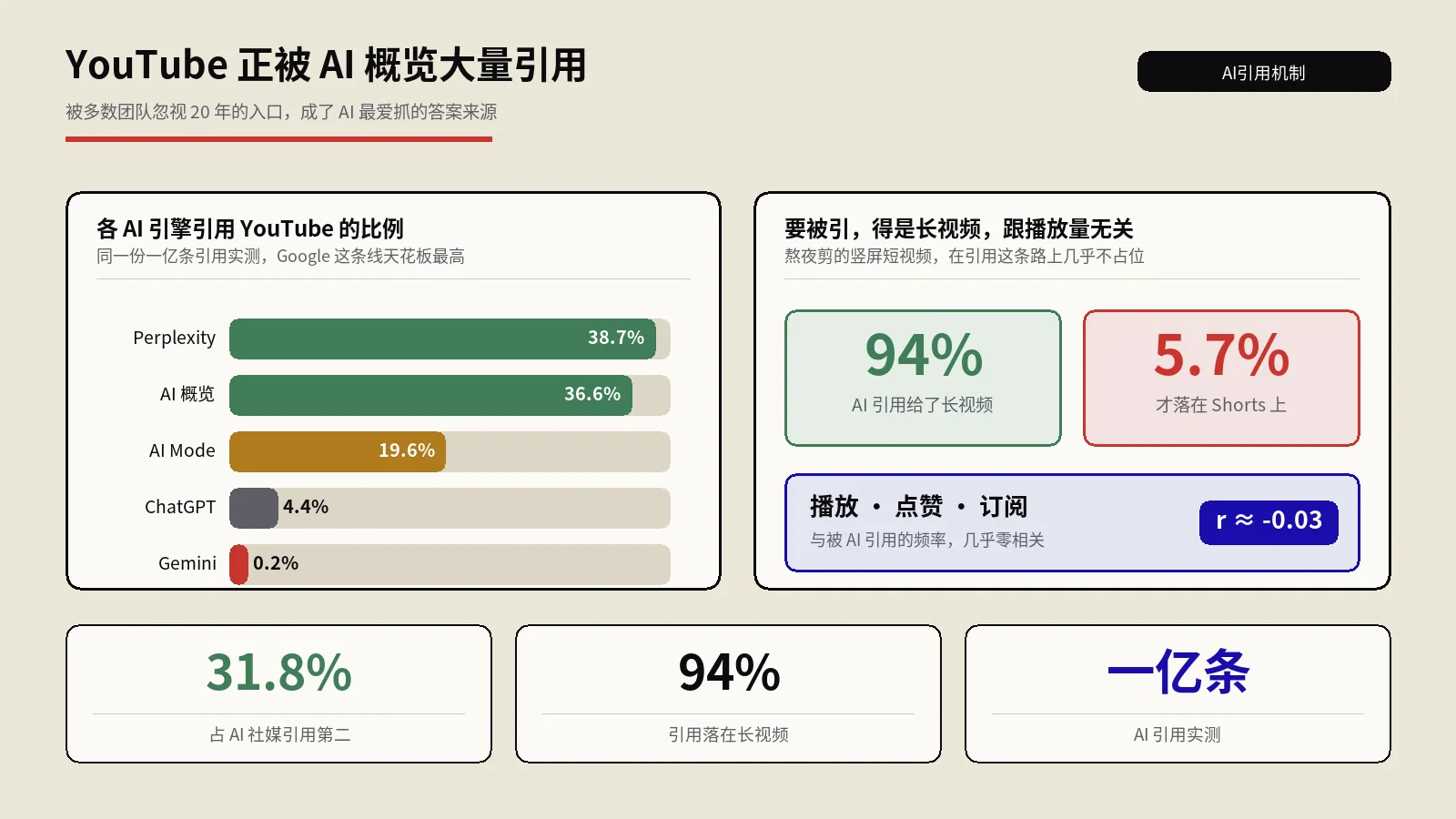
所以你会看到平台方真金白银地去买这块语料。Google官方扩大与Reddit合作的公告把意图写得很直白:通过接入Reddit的数据接口,让自家产品能更高效地理解人们真实的对话。CBS News对这笔每年约6000万美元协议的报道则点明了价码和用途——Google拿这笔钱换的是用真人帖子训练AI的权利。后来Reddit又跟另一家头部AI公司签了一份每年约7000万美元的类似协议。一份用户生成内容,被两家巨头分别按千万美元级别采购,这件事本身就说明了它在AI眼里的分量。
这里有个常被忽略的连锁反应:Reddit在拿到这些合作之后,它在Google自然结果里的可见度坐了火箭——业内统计它在美国自然搜索的域名可见度,从2023年的几十名开外,一年内冲进了前五。这不是巧合,是平台、搜索、AI三方利益绑在了一起。对你来说,这意味着一件很现实的事:哪怕你不经营Reddit,你的潜在客户在Google搜你这个品类时,越来越可能先撞见一个Reddit讨论帖,里面有没有你、别人怎么提你,你说了不算。
实时性这一层也别小看。官网内容、博客、白皮书,这些都是你“精修”过的、有滞后的;而社媒讨论是当下正在发生的。当一个用户问AI “XX最近是不是出了质量问题”,模型如果能接触到近几周的社媒讨论,它的回答就会带上这个时效信号——而这恰恰是你那篇半年没更新的官网FAQ给不了的。保哥常跟客户说一句糙话:官网是你的简历,社媒是你的背调,AI招不招你进答案,越来越看背调。这跟在Reddit这类社区里被搜到、被AI引用是一个道理,想吃这块的可以看这篇Reddit SEO实战。
“二级搜索索引”到底指什么:机器读取社媒的三条真实通路
“社媒被机器读取”这话太虚,落到工程上,其实是三条具体的通路。把这三条搞清楚,你才知道哪些动作是真有用、哪些是自我感动。
通路一:搜索结果里的独立讨论板块
Google早就在结果页里单独切出了“讨论和论坛”这一块,专门展示来自社区的真人讨论。它跟传统蓝链是两套逻辑——传统蓝链比的是页面权威和关键词匹配,讨论板块比的是“这个话题下有没有真实、有来有回的对话”。出海站想进这一块,靠的不是堆外链,而是你的内容真的在某个社区里被讨论起来。之前专门写过Google社区论坛板块怎么优化的内容进入策略,想吃这块流量的可以对着做。
通路二:结构化数据把社区内容标成“机器可识别”
如果你站内本身就有论坛、问答区、用户评论这类UGC,那你有一个被严重低估的抓手:用结构化数据明确告诉机器“这是真人讨论,不是我自己写的”。Google关于DiscussionForumPosting结构化数据的官方文档把字段讲得很细:必填的有作者、发布时间、正文或图片视频;推荐的里面有几个特别值钱——commentCount 标讨论热度,interactionStatistic 标点赞转发等互动,sharedContent 标这条帖子里转引了什么,还有一个 digitalSourceType 专门用来区分内容是真人产出还是算法生成。
注意官方的一条红线:这套标记只能用在真正的用户生成内容上,绝不能拿去标你自己或你雇人写的东西。digitalSourceType这个字段的存在本身就是个信号——在AI内容泛滥的当下,机器越来越想分清“哪些是真人说的”,而能诚实标清楚这一点的站,反而占便宜。把它当成一次表态:我这里的讨论是真的。
通路三:直接进AI训练与检索语料
这是最“黑箱”但影响最深的一条。前面说的千万美元级数据采购,结果就是社媒内容直接进了大模型的训练或实时检索池子。你没法控制模型怎么学,但你能控制“它学到的关于你的内容是什么样”。如果关于你的讨论全是零散吐槽、口径混乱,模型综合出来的印象就好不到哪去;如果你在对的社区里持续被正面、具体地提及,那这就是在给模型喂正确的“你”。这跟在全渠道铺真实声量的思路是一脉相承的,之前写过的红人内容Search Everywhere全渠道实战讲的就是怎么系统化地铺这层声量。
这三条通路有个共同点:它们读的都不是你的“主张”,而是你在第三方场景里留下的“痕迹”。这就自然引出了第二层——验证。
真实性验证层:AI怎么用“别人怎么说你”给你定信任分
如果说二级索引解决的是“机器能不能读到你”,那真实性验证解决的是“读到之后信不信你”。这一层的底层逻辑,其实Google早就白纸黑字写下来了。
Google的搜索质量评估指南(PDF)里有一条原则,我觉得每个做品牌的人都该背下来:评估一个网站的声誉时,不能只看它自己怎么说,必须去找独立的、外部的声誉信息;当网站的自我描述和外部可信来源说的对不上时,相信外部来源。指南还特意说明,这种声誉信息要看“人写的东西”——新闻报道、维基词条、博客、杂志文章、论坛讨论、独立机构的评分,都算数。
这条原则套到AI时代,威力被放大了好几倍。人类评估员是抽样看,而AI引擎是规模化、自动化地干这件事——它会把你官网的自我描述,跟它在社媒、论坛、评测里读到的关于你的内容做交叉比对。一致,加分;冲突,那它信外面的。E-E-A-T这套框架里,信任(Trust)被明确放在最重要的位置——再有经验、再专业、再权威,只要不可信,整体评价就上不去。而“可信”这件事,越来越多地由你控制不了的第三方场景来裁定。
这就是为什么说社媒是“验证层”。你在官网说自己是“出海家居品类领先品牌”,机器不会照单全收,它会去看:有没有真实用户在讨论你的产品?这些讨论的口碑是正是负?你在不同平台上呈现的是不是同一个品牌、同一套信息?任何一处对不上,信任分就往下掉。
这里还藏着一个很多人忽略的技术细节——跨平台的实体一致性。机器要确认“官网上的这个你”和“社媒上的那个你”是同一个实体,靠的是显式的身份关联。Schema.org的sameAs属性说明就是干这个的:你可以在官网的组织结构化数据里,用sameAs把你所有官方社媒主页、维基词条、权威目录页一条条链起来,等于亲口告诉机器“这些账号都是我,请把它们的口碑算到我头上”。少了这一步,你在社媒上积累的正面信号,可能根本没被归到你这个实体名下,白攒了。这步在实操里最常被漏,因为它不直接产出任何能写进周报的流量数字,回报全藏在机器那一侧;可偏偏是它,决定了你前面所有口碑功夫到底算不算到你头上。零成本、高杠杆、还容易被忽略,这种活儿往往最该排在最前面做。
落地打法:把社媒经营成机器可读的验证层
道理讲完,下面是保哥带客户实际在跑的动作清单。顺序是有讲究的——从“先别让自己减分”开始,再到“主动加分”。
- 先统一口径,做实体对齐。把品牌名、一句话定位、核心品类、官网地址,在所有官方社媒资料里改成完全一致的表述,别一个平台叫一个名。然后在官网组织结构化数据里用sameAs把这些官方主页全部关联上。这一步几乎零成本,却是机器把你认成“一个完整实体”的前提,优先级最高。
- 让自己在“真问题”里被提及,而不是在广告里。机器看重的是真人语境下的自然提及。与其投一堆硬广,不如让真实用户、合作红人在讨论具体问题(“XX品类怎么选”“XX用着怎么样”)时,具体地、带场景地提到你。一句“我用过XX,它的XX功能解决了我XX问题”,价值远超一百个泛泛的点赞。
- 给站内UGC上结构化数据。如果你有评论区、问答、用户晒单社区,按官方文档把DiscussionForumPosting或对应类型标记上,把作者、时间、互动数、digitalSourceType都填对。这等于把你站内的真人声音,翻译成机器能直接读懂的格式。
- 监测“别人怎么说你”,把它当一项例行巡检。定期搜一下你的品牌词在主流社媒、论坛、问答平台上的出现情况,看口碑基调、看有没有事实性错误在传播。这跟监测自然排名一样,该是每月固定动作,而不是出事了才慌忙去搜。
- 认真处理负面口碑,但别想着删。验证层的逻辑下,一条没人回应的负面讨论,比十条好评更扎眼——因为机器会读到“有问题且品牌方没出面”。正确动作是公开、专业地回应和解决,把负面讨论变成“看,这家会负责”的正面证据。想删反而是下策,既删不干净,又坐实了心虚。
- 沉淀可被引用的“原话素材”。把真实的用户故事、具体的使用数据、可核对的事实,以真人口吻沉淀在社区和问答里。这些是AI最爱引用的那种内容——具体、有来源、像真人说的。这一步是把前面所有动作的成果,固化成可被反复读取的资产。
这套清单跑下来你会发现,没有一条是关于“涨多少粉”的。验证层经营的是结构和口碑,不是声量数字。
把社媒验证层接进现有工作流:四个接入点
讲到这儿可能有人开始犯怵:又是结构化数据,又是口碑监测,又是跨平台对齐,听着像要新开一个部门、立一个大项目。其实完全不用。验证层最务实的做法,不是单拉一摊人马,而是把它拆成四个接入点,分别挂到你本来就在跑的SEO和GEO流程上,几乎不额外占用人力。下面这四个点,你对照自己现有的工作节奏一个个塞进去就行。
接入点一,选题调研阶段。在你拍板下一篇内容写什么之前,本来就要做关键词和需求调研。把这一步顺手延伸一下:去目标社区、问答平台、相关话题标签下搜一圈,看真人在这个话题下到底问什么、用什么词、抱怨什么、推荐什么。这一搜同时喂饱两件事——一是你的选题和用词更贴近真实需求,写出来的东西更容易在AI答案里被当成“说到点子上”的来源;二是你顺手就记下了哪些讨论里“本该有你却没有你”,那张清单就是验证层最直接的待办。调研本来要做,多花十分钟,等于白捡了半套验证层规划。
接入点二,技术上线清单。你每次发布新页面或改版,多半已经有一份技术SEO的checklist,会过标题、canonical、结构化数据测试这些。把验证层的两件事直接并进去:组织信息里的sameAs关联有没有补全、站内UGC有没有按官方规范标记。把它们跟既有项排在一起,就不会再被当成“以后有空再说”的额外工作,而是每次上线都顺手过一遍的固定动作。固定下来之后,新页面天生就是“机器认得清、归得对”的。
接入点三,口碑监测看板。你大概率已经在每月固定看自然排名、看GSC的曲线。那就在同一张月报里多加一栏:品牌词在主流社媒和论坛上的提及量、基调走向、有没有冒出在传播的事实性错误。关键是放进同一个会、同一张表里一起看——口碑的异动和排名的异动摆在一起,你才看得出它们之间的因果,也才不会让一条正在发酵的负面拖到季度复盘时才被发现。监测工具用现成的就行,重点是把这双眼睛常态化,而不是出事了才临时去搜。
接入点四,GEO月度实测。这一条是把前面所有动作串成闭环的关键。准备一组固定的、贴近你所在品类真实购买决策的问题,比如“预算两千以内的便携储能怎么选”“做跨境的有哪些靠谱的XX供应商”,每个月固定在主流AI助手里各问一遍,记录三件事:你有没有出现、被怎么描述、答案引用了哪些来源。如果引用来源里反复出现某个社区、某篇讨论,那就是在明明白白告诉你验证层的哪一块在真正起作用、哪一块还是空白。这套实测既是方向盘,也是唯一能反过来证明前面那些动作到底有没有奏效的尺子。没有它,你做的一切都只是“感觉应该有用”。
四个接入点没有一个要求你新招人、新搭流程,无非是在你已经在做的四个环节里,各嵌进去一个不起眼的小动作。观察下来,验证层经营得好的团队,往往不是最舍得砸钱的那个,而是最早把这四件小事变成肌肉记忆、月复一月不偷懒的那个。复利就藏在这种不起眼的坚持里。
一个出海独立站的真实切片
讲个保哥手上的匿名案例,免得上面全是道理。
一家做户外储能的出海独立站,产品力其实不弱,但有阵子很苦恼:官网SEO做得挺扎实,自然排名也有,可一到AI概要和问答场景,问“有哪些靠谱的便携储能品牌”,答案里翻来覆去就是那几家老牌,从来没它。团队一开始的反应是经典错位——加大社媒投放,冲粉丝量,三个月粉丝涨了不少,AI答案里依然没有它。
后来我们换了个思路,按验证层来排查,找到三个真问题:第一,它在三个平台上的品牌简介各写各的,连主打品类的措辞都不一样,官网也没用sameAs把这些账号关联起来,机器根本没把它们认成一个实体;第二,它在出海玩家聚集的几个社区里几乎是“查无此人”,仅有的几次提及还是零散的售后吐槽,没人回应;第三,站内其实有不少真实用户晒单和问答,但完全没做结构化数据标记,机器读不出那是真人内容。
动作也对应着三条:先花一下午统一了全平台口径、补上sameAs关联;接着用了两个月,让真实老用户和几个垂直红人在讨论“露营带什么储能”这类真问题时,具体提到这个品牌和它最能打的快充功能;同时把站内晒单区按DiscussionForumPosting标记上线,对那几条老售后吐槽也逐一公开回应、给了解决方案。
过程里有个细节挺能说明问题。团队一开始觉得最没必要、最像走过场的,恰恰是处理那几条老售后吐槽——都是一两年前的帖子了,沉在底下早没人翻,回不回好像无所谓。结果偏偏是这块见效最快:在公开回复里把当时的问题出在哪、后来怎么改的、现在是什么解决方案一条条讲清楚之后,再去AI助手里问这个品牌“是不是出过质量问题”,答案的口风从含糊的“有用户反映过问题”变成了“早期有过个别反馈,品牌已公开说明并完成改进”。同一条负面,处理前是实打实的减分项,处理后反倒成了“这家肯认账、肯负责”的加分证据。这件事把团队的观念彻底掰过来了:验证层从不怕你有负面,它怕的是负面没人管、品牌方装看不见。
大约四个月后,变化不是“流量暴涨”那种戏剧性的——而是更结构性的:在主流AI助手里问那类品类问题,它开始稳定地作为候选之一被提到了,附带的描述也基本准确,引用的常常正是社区里那些真实讨论。团队后来复盘时说了句挺到位的话:原来不是要喊得更大声,是要让别人替你说、还要让机器听得见。这正是验证层的全部要义。
三个最容易踩的误区
方向对了,执行上还有几个坑,几乎在每个客户那都见过,提前说一声。
误区一:把验证层当成新的刷量战场。有人一听“社媒影响AI”,第一反应是找水军刷讨论、刷好评。这是把路走反了。机器越来越会识别非自然的、批量的、空洞的内容,digitalSourceType这类字段的出现就是冲着这个去的。刷出来的虚假繁荣不仅没用,被识别后还可能反向减分。验证层认的是真实,不是数量。
误区二:照搬国内社媒的打法去做海外。平台生态、用户习惯、内容调性,海内外差得很远。国内那套强运营、强投放、追热点的打法,搬到以真实讨论和长尾沉淀见长的海外社区,往往水土不服。出海要按目标市场用户真实聚集的地方、真实在意的问题来打,这也是一直强调本土化的原因——验证层尤其吃这一套,因为它的评判者是当地真人加机器。
误区三:只盯粉丝数这类虚荣指标。粉丝、播放、点赞这些数字好看,但跟“AI信不信你”的相关性远没你想的那么高。验证层真正该盯的是另一组指标:品牌被自然提及的次数和语境、口碑基调、跨平台口径一致性、站内UGC的结构化覆盖率、负面讨论的响应率。把仪表盘换成这几个,你才是在对着AI时代的真目标做优化。
说到底,社交平台从流量渠道变成二级索引加验证层,对认真做产品、认真对客户的品牌反而是好事。它奖励的是真实、一致、负责任,惩罚的是包装、混乱、回避。这套游戏规则里,会做产品、敢露脸、肯回应的人,和只会拍脑袋砸预算的人,差距只会越拉越大。
常见问题解答
社交平台真的会取代Google成为主搜索吗,我是不是该把预算搬过去?
大概率不会取代,所以别急着搬家。数据上社媒搜索的使用确实在涨,但“偏好社媒胜过Google”的比例反而在回落,它更多是作为主搜索之外的补充和验证场景在变重要。正确的姿势不是二选一,而是把社媒重新定位成AI时代的二级索引和验证层去经营——这跟你原有的SEO不冲突,是叠加。把它当成“别人替你背书、机器去核实你”的地方,而不是又一个要单独冲量的流量池。
我是纯SaaS建站,改不了底层代码,结构化数据和sameAs这些还能做吗?
大部分能做。统一全平台品牌口径、在真实讨论里争取自然提及、监测和回应口碑,这些跟底层代码毫无关系,纯运营动作,SaaS站照样做。结构化数据这块,主流建站平台和插件大多支持给组织信息加sameAs、给站内评论或问答加对应标记,不一定要手写代码,先用现成能力铺上核心字段,再用官方的结构化数据测试工具验证有没有真生效就行。真正受限的只有极少数深度定制场景,但那不该挡住你先把能做的八成做了。
我没有站内论坛或评论区,DiscussionForumPosting这套是不是跟我没关系?
结构化数据那条通路确实用不上,但二级索引和验证层的另外两条通路跟你关系很大。你依然需要让品牌在外部社区的真实讨论里被提到、依然需要保证跨平台口径一致、依然需要监测和处理别人怎么说你。站内有没有UGC只影响“通路二”这一个抓手,不影响整体逻辑。没有自有社区的品牌,反而更要在外部第三方场景里把声量和口碑做扎实,因为你少了一块自己能完全掌控的阵地。
这件事见效要多久,能不能像投广告那样立刻看到结果?
不能,它更像SEO不像投放,是个累积的过程。口径统一和sameAs这种动作上线快,但“在真实讨论里被自然提及、被机器读取并综合进印象”需要时间发酵,通常要按月看而不是按天看。前面那个储能站的例子是大约四个月才看到AI答案里稳定出现。好处是这种累积一旦形成就比较稳,不像广告停了就归零。心态上把它当成长期资产建设,别用投放的即时性去要求它,否则容易半途而废。
负面讨论我到底是该回应还是该想办法压下去?
回应,几乎永远比压制好。在验证层的逻辑里,一条没人理的负面讨论传递的信号是“有问题且品牌不出面”,这比负面本身更伤。公开、专业地回应并给出解决方案,等于把一次危机变成“这家会负责”的正面证据,机器和真人读到的都是后者。想靠删帖或刷正面去压,既很难删干净,又容易被识别为操纵,反而坐实心虚。当然,对明显的造谣诽谤该走平台举报和法律渠道,那是另一回事,但日常口碑别想着压,想着答。
怎么衡量我在“真实性验证层”上做得好不好,有没有可看的指标?
有,但要换一组指标,别再盯粉丝和播放。可以看这几项:品牌被自然提及的次数和语境基调(是不是在真问题里被正面具体提到)、跨平台品牌信息的一致性、站内UGC的结构化数据覆盖率、负面讨论的响应率和响应速度,以及最终的“AI可见度”——在主流AI助手里问你所在品类的问题,你出现的频率和被描述的准确度。最后这一项最接近真目标,建议每月手动测一组固定问题做记录,攒成自己的基准,比任何外部报告都管用。
权威参考资料
本文标题:《社交平台成了AI的二级搜索框:别人在别处怎么说你,决定AI信不信你》
本文链接:https://zhangwenbao.com/social-secondary-search-ai-authenticity-verification.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0