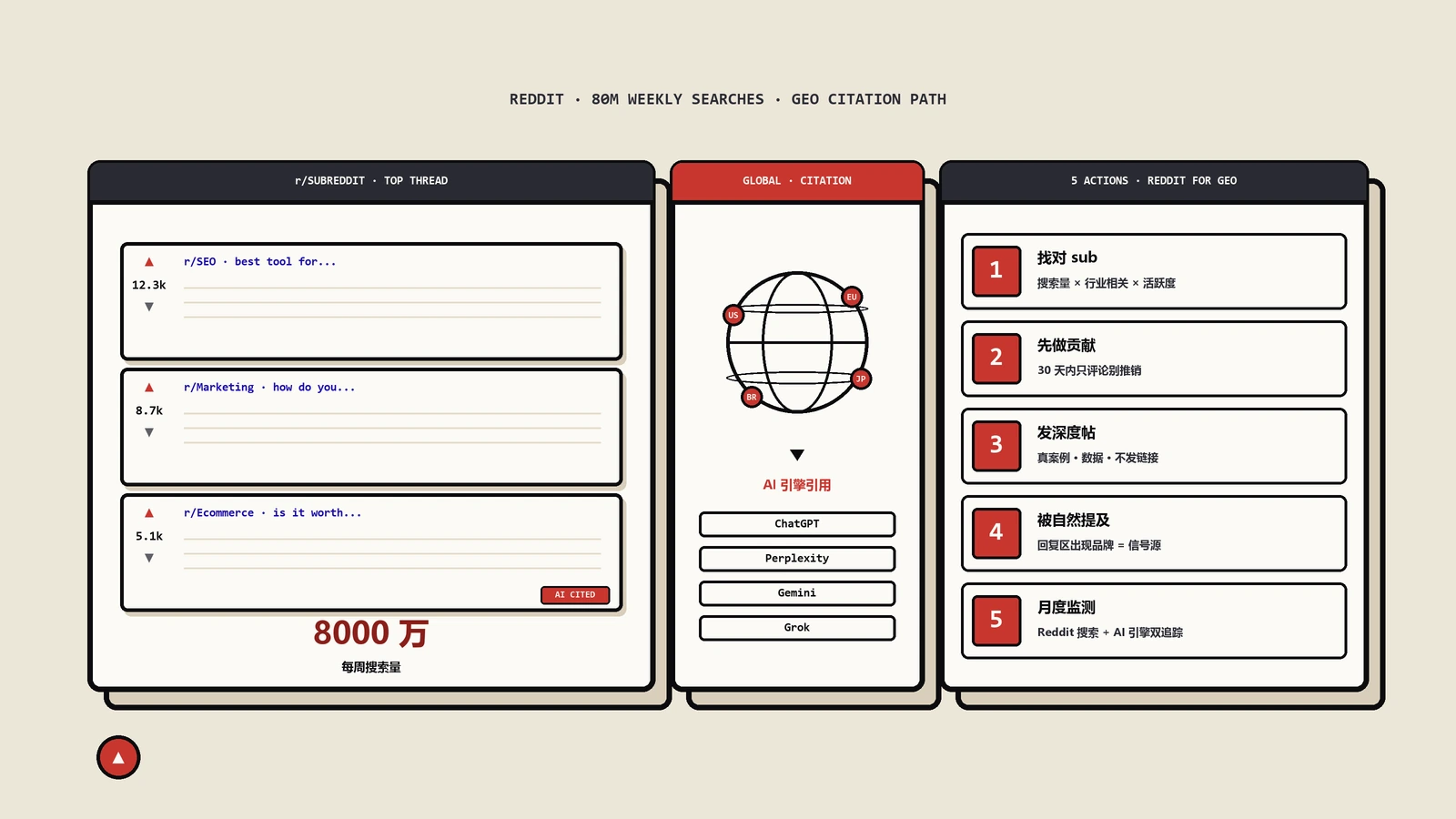
Reddit SEO实战:8000万周搜量出海怎么被搜到
本文目录
- 八千万人每周在Reddit里搜索,这个数字到底意味着什么?
- Reddit站内搜索和Answers合并后,检索链路是怎么跑的?
- 为什么出海品牌不能把Reddit只当成“外部AI的语料源”?
- Reddit站内搜索和Answers到底偏爱什么样的内容?
- 它偏爱真人体验密度高的内容
- 它偏爱有社区背书的内容
- 它对查询类型敏感
- 它对内容形态在扩展
- 被Reddit Answers抽成答案片段的内容,具体长什么样?
- 出海品牌想在Reddit被自然检索到,要怎么系统地做?
- 选区:先找到你的高意图subreddit
- 可信度:账号不是发广告的工具,是社区身份
- 贡献:让有用信息以不像广告的方式进入链路
- 合规:Reddit的ToS红线比Google严
- Reddit内容怎么二阶传导到Google AI概要和ChatGPT?
- 怎么衡量你在Reddit搜索面的可见度?
- 哪些做法在Reddit搜索面是反效果甚至危险的?
- 把Reddit搜索面纳入出海搜索矩阵,前90天该怎么落地?
- 这篇和站内相关文章差在哪?
- 常见问题解答
- 八千万周搜索量,是不是说明Reddit已经能当Google用了?
- 我们品牌官网内容很好,为什么在Reddit搜索和ChatGPT里还是输给匿名评论?
- 在Reddit上发推广帖能直接提升被AI引用的概率吗?
- Reddit这条线该用流量和转化考核吗?
- 小团队没人力长期养Reddit账号,值得做吗?
- Reddit改版把搜索前置、扩展媒体形态,对内容策略意味着什么?
- 权威参考资料
摘要:Reddit自己宣布每周有八千万人在站内搜索、Reddit Answers的提问量一年内从一百万冲到一千五百万,这个数字不是社媒涨粉,而是它正在变成一台搜索引擎兼答案引擎。出海品牌如果还把Reddit只当成“被外部AI抄走的语料堆”,就漏掉了更要命的那条线——它本身就是一个你必须被检索到的搜索面,而且站内被搜到与反哺外部AI是两条互相喂养、要分开运营和分开衡量的战线。
先把这件事的量级摆出来。Reddit在2025年第四季度财报电话会上给了一组数字:每周约八千万人在Reddit里做搜索,一年前这个数是六千万;它的AI答案产品Reddit Answers的周提问量,从一年前的一百万左右涨到了第四季度的一千五百万。与此同时,Reddit把原来的关键词搜索和AI答案合并成了一个入口,公开说要做一个让用户“在站内就能开始、也能结束一次搜索”的端到端搜索目的地,还在测试把搜索框前置到App首屏的新版式。
很多人看到这条消息的第一反应是“Reddit流量又涨了,去多发几个帖”。这是把搜索面当成了曝光位。真正的变化是结构性的:一个原本被当作论坛的地方,正在长出一套自己的检索—排序—答案合成链路,而且这套链路的输出,又通过数据合作反向喂进了Google的AI概要和OpenAI的回答里。对做出海的人来说,这意味着Reddit从“可选的内容分发渠道”升级成了“绕不开的搜索基础设施”。这篇就把这套链路拆开,讲清楚机制、两条战线怎么分别打、怎么衡量、哪些做法会把账号和品牌一起送走。
八千万人每周在Reddit里搜索,这个数字到底意味着什么?
判断一个平台值不值得投入,先看它的用户是来“逛”的还是来“查”的。逛是消遣型行为,注意力浅、意图弱;查是任务型行为,用户带着一个具体问题、一个待决策的购买、一个待排查的故障进来。八千万周搜索量说明的是后者——Reddit上有一大批人,是带着明确意图主动检索,而不是被信息流推着滑。
这条线最值钱的地方在意图的纯度。Reddit的搜索高频出现在一类查询上:要不要买这个、这两款哪个更好、真实用起来到底怎么样、有没有人踩过这个坑。这些查询的共同点是主观、经验依赖、高购买意图、且对厂商话术高度免疫。用户特意来Reddit搜,恰恰是因为他们不信品牌官网和测评稿,想看真人怎么说。这种意图在传统搜索里被稀释在一堆SEO优化页里,在Reddit站内搜索里却是高度集中的。
Reddit Answers一年涨十五倍的提问量,则说明另一件事:用户不只在Reddit里翻帖子,还在直接问它要答案。Reddit Answers的产品形态是输入一个问题,它从海量社区讨论里抽取、合成一个带引用的回答,引用直接指回原帖和评论。这等于Reddit在自己的语料上自建了一个垂直答案引擎,而它的语料是别人没有的——十几年沉淀的真人体验讨论。它官方也讲得很直白,Answers在“产品推荐、娱乐选择、体验型问题”这类主观查询上表现最好,因为这类问题本来就没有单一标准答案,社区视角比一篇权威文档更有用。
把这两个数字放一起,结论很清楚:Reddit已经同时是一个搜索引擎(关键词检索社区内容)和一个答案引擎(AI合成社区共识),而且这两者被合并进了同一个入口。它的运营官在财报会上把这种搜索行为描述成对现有使用的“增量且叠加”——意思是用户原本就在Reddit上消磨时间,现在又在高意图时刻(比较选项、研究是否下单)多了一层主动检索。对品牌而言,这层新增的高意图检索,就是新的可见性战场。
Reddit站内搜索和Answers合并后,检索链路是怎么跑的?
要在一个搜索面被检索到,得先知道它怎么检索。Reddit的搜索不是网页搜索那种全网抓取—建索引—排名,它是在自己封闭语料(帖子、评论、subreddit、投票、时间)上跑的检索,逻辑和通用搜索引擎的抓取、索引、排名三段式有相通处,但信号权重完全不同。可以把它拆成四步看。
第一步,查询理解。用户输入一个查询后,系统先判断这是个事实型问题还是主观型问题。事实型(“X的发布日期”)倾向于返回单条最相关帖子或直接给一句答案;主观型(“X和Y哪个值得买”)倾向于触发Answers,去多个帖子里抽取不同立场再合成。这个分流决定了你的内容要被命中,得先匹配对查询类型。
第二步,候选召回。系统在索引里召回与查询相关的帖子和评论,相关性不只看文本匹配,还看是哪个subreddit、帖龄、以及评论树的结构。一个高度垂直的subreddit里的帖子,对该领域查询的相关性权重,远高于一个泛领域大版的同样文本。
第三步,社区信号排序。这是Reddit和网页搜索最不一样的地方。排序的核心信号是投票数、投票速率、评论数与评论质量、发帖账号的历史可信度(karma与历史行为)、以及内容存活时长。一条获得几百个赞、底下还有一长串认真讨论的评论,会被判定为“社区已经达成某种共识”的高价值内容,无论它来自品牌还是一个匿名用户。
第四步,Answers的抽取与合成。对触发Answers的查询,系统从排序靠前的多个帖子和评论里,抽出可作为答案片段的句子,按观点聚合(多数人说好、少数人说有这个问题),合成一段带引用的回答,引用锚点回到具体帖子。它还在往“动态体察式结果”扩展,也就是把图片、视频等不同媒体形态也纳入答案。关键点是:被Answers引用的不是整篇帖子,而是其中一两句最能直接回答问题、且有社区背书的话。
这套链路解释了一个很多品牌想不通的现象:你花三个月打磨的产品对比页,在ChatGPT里问“五十人团队用哪款CRM”时被无视,胜出的是一条十八个月前、八百多个赞的匿名使用心得。不是你的内容不好,是它不在这套以社区共识为核心信号的检索链路里——它在你自己的域名上,没有投票、没有社区讨论、没有帖龄沉淀,对Reddit的排序器来说几乎不存在。
为什么出海品牌不能把Reddit只当成“外部AI的语料源”?
这里要做一个明确的区分,因为它直接决定你投入的方向对不对。站内已经有一篇专门讲Reddit等社区信号如何被外部AI搜索(ChatGPT、Google AI概要)当成引用源、品牌官网内容为何输给陌生人评论的实战指南;也有一篇讲Reddit作为GEO注入渠道为什么在2025年因为饱和与刷量降温、要往别的渠道转移;还有一篇拆AI推荐机制、讲别盲目刷Reddit和维基百科的。本篇要补的,是这些文章都没正面打的那条线:Reddit它自己就是一个搜索面和答案引擎,你得在它站内被检索到,这和你的内容被外部AI抄走,是两件要分开做、分开衡量的事。
把两条线摊开对比,会更清楚:
| 维度 | 战线一:站内被检索到 | 战线二:反哺外部AI |
|---|---|---|
| 谁在检索 | 八千万周活的Reddit站内搜索/Answers用户 | Google AI概要、ChatGPT、Perplexity的用户 |
| 命中靠什么 | subreddit相关性 + 投票 + 评论共识 + 帖龄 | Reddit内容被外部模型抓取/授权后的引用偏好 |
| 你能直接影响的 | 在对的subreddit里产出被社区认可的真实讨论 | 几乎只能间接影响(取决于站内那条线强不强) |
| 见效与衰减 | 较快、可被站内运营持续维护 | 滞后、依赖Reddit与各AI厂的数据合作关系 |
| 衡量方式 | 站内搜索可见 + 被Answers引用 + 品牌词讨论 | 外部AI答案里的品牌提及与归因(间接) |
这两条线的因果方向是单向的:战线一是战线二的上游。Reddit的内容之所以成为AI生成答案里最常被引用的来源之一,是因为Google与Reddit有内容授权合作、OpenAI与Reddit也有数据合作,外部AI大量拿Reddit语料做检索增强。但外部AI引用的,永远是那些在Reddit站内已经被社区顶起来、形成共识的内容。你没法直接去优化“被ChatGPT引用”,你只能把站内那条线做强,让外部AI在抓取时自然命中你参与塑造的那部分共识。
所以方向错了会很浪费:很多品牌的Reddit投入是“发完帖就不管、盯着ChatGPT里有没有提到自己”,这是只盯战线二、放弃战线一。正确的顺序是反过来——先在站内被检索到、被顶起来、进Answers的引用,外部那条线是它的副产品。关于站内被顶起来之后如何进一步从“被引用”走到“被推荐为品牌”,从被引用到被推荐的进阶打法那篇有更细的拆解,可以接着读,但前提仍是站内这条线先立住。
Reddit站内搜索和Answers到底偏爱什么样的内容?
知道了链路,下一步是搞清楚什么样的内容能在这套链路里胜出。把Reddit排序器和Answers抽取器的偏好拆成几条可执行的判断:
它偏爱真人体验密度高的内容
Reddit排序和Answers抽取,本质上是在找“一个真实用过的人会怎么说”。一段写法上像产品文案的内容(“行业领先、专业可靠、一站式解决方案”),即使发在对的版,也很难被顶起来,更不会被Answers当答案片段抽走。能胜出的是带具体场景、具体踩坑、具体取舍的第一人称叙述:用了多久、什么场景、解决了什么、有什么没解决、和哪个替代品比过。体验的颗粒度,就是这套链路里的相关性燃料。
它偏爱有社区背书的内容
同样一句话,匿名用户发在垂直subreddit、获得几百赞和一串认真追问的评论,和品牌官方账号发、零互动,对排序器是天壤之别。投票和评论是Reddit的“共识证明”。这决定了品牌在Reddit的打法不可能是单向广播,而必须是真实参与社区、靠贡献换可信度,最终让有用的信息被社区自己顶上去。
它对查询类型敏感
事实型查询(参数、兼容性、官方政策)和主观型查询(值不值得买、哪个更好、用起来怎么样)走的是不同分支。事实型可能直接命中一条权威帖;主观型才会触发Answers的多源合成。出海品牌的机会主要在主观型——因为这正是用户绕开你官网、特意来Reddit找真话的地方,也是Answers表现最好的地方。
它对内容形态在扩展
Reddit公开说在做“动态体察式搜索结果”,把图片、视频等媒体纳入答案。这意味着未来在某些品类(户外装备的实拍、3C的拆解视频、安装演示),媒体形态的真实内容会比纯文字更容易被抽进答案。现在就值得在内容形态上多押一手真实媒体,而不是只发文字。
把这几条合起来,能解释清楚那个“官网输给陌生人评论”的现象到底输在哪:官网内容缺真人体验颗粒度、缺社区背书、又不在Reddit的索引里。要赢回来,不是把官网写得更好,而是要让真实有用的信息以社区能接受的方式进入Reddit这套链路。
被Reddit Answers抽成答案片段的内容,具体长什么样?
前面讲的是排序器偏好的内容大类,这里再下沉一层,讲清楚一个更具体、也更可操作的问题:当一个查询触发Answers,系统从帖子和评论里抽的不是整段,是一两句话。哪种句子会被抽走,哪种永远不会,是有规律的。
会被抽走的句子有几个共同特征:它是一个直接的断言而不是铺垫;它自带可验证的具体信息(数字、时长、型号、场景);它没有营销修饰词;它能脱离上下文单独成立,读的人不需要回看前文也能懂。不会被抽走的句子则相反——它要么是过渡句和情绪句,要么观点和限定条件缠在一起一句话说不清,要么充满“专业可靠、行业领先”这类对答案合成毫无信息量的词。
| 不会被抽(典型) | 会被抽(改写后) |
|---|---|
| 这款产品整体来说还是挺不错的,值得推荐 | 这款用了八个月,出粮口没卡过一次,缺点是拆洗要拧四颗螺丝 |
| 它在很多方面都优于同类竞品 | 和某主流款比,它的电池能多撑大概一倍,但App没有定时分餐 |
| 用户体验非常好,操作很简单 | 第一次装好到能用大约十分钟,没看说明书,唯一卡住的是配网要关5G频段 |
这张对照表就是你产出Reddit内容时的句式标尺:每写一句,问它能不能脱离上下文被一个陌生人直接引用为答案。这条规律还有一个反直觉的推论——主动写出缺点和适用边界的句子,被抽中的概率反而更高,因为它们具体、可验证、且符合Reddit社区对“真话”的预期,而纯夸的句子在Answers的抽取里几乎是隐形的。把这条规律用顺了,你在Reddit的内容就不再是“发出去碰运气”,而是按答案引擎能用的形态去生产。
出海品牌想在Reddit被自然检索到,要怎么系统地做?
这部分给可落地的步骤,分成选区、可信度、贡献、合规四块。每一块都给“做什么、怎么做、怎么验证、做错会怎样”。
选区:先找到你的高意图subreddit
做什么:不是找最大的版,是找你的目标用户在做购买决策时真的会去搜的那几个垂直版。一个出海智能家居配件品牌,r/smarthome、r/homeautomation这类决策版的价值,远高于一个泛科技大版。怎么做:用Reddit站内搜索,搜你品类里的高意图查询(“best X for Y”“X vs Y”“is X worth it”),看返回的高赞帖集中在哪几个subreddit,那就是你的战区。怎么验证:这些subreddit里近一年是否持续有人问你品类的购买决策问题、且帖子有真实讨论而非一边倒灌水。做错会怎样:选了泛大版或低活跃版,内容沉底,投入全废。
可信度:账号不是发广告的工具,是社区身份
做什么:用真实、长期、有领域贡献的账号参与,而不是新号直接发推广。Reddit的排序和反作弊都重账号历史。怎么做:账号先在目标版做一段时间纯贡献——回答别人的问题、分享真实经验、不带链接不提自家,积累karma和版内信任,再在相关讨论里以“我是做这行的/我们团队踩过这个坑”的方式坦诚介入。怎么验证:账号在版内发言是否能稳定拿到正常的赞和理性回复,而不是被踩或被质疑是马甲。做错会怎样:新号或纯营销号会被社区和反作弊系统识别,轻则沉底,重则shadowban(你看得到自己的帖,别人看不到,你还以为在正常运营)。
贡献:让有用信息以不像广告的方式进入链路
做什么:产出真正解决问题的内容——详细的使用复盘、和竞品的客观对比(包括承认自家不足)、踩坑记录、安装/排障教程。怎么做:结构上用Reddit社区习惯的写法:结论先放、分点、给具体数字和场景、主动写出适用边界和不适用人群。坦诚承认局限反而是Reddit最吃的可信度信号。怎么验证:内容是否被自然顶起来、是否在站内搜索该查询时进入前排、是否开始被Reddit Answers抽为答案片段。做错会怎样:软文式贡献会被老用户一眼识破并公开拆穿,对品牌是负资产,且会连累账号可信度。
合规:Reddit的ToS红线比Google严
做什么:守住Reddit的内容政策和各版规——披露利益相关、不刷票、不开马甲互捧、不跨版重复刷。怎么做:涉及自家产品时主动标明身份(很多版有专门的厂商参与规则甚至需提前报备),AMA走官方流程。怎么验证:定期检查账号是否被限流、帖子是否异常零曝光(shadowban的典型症状)。做错会怎样:vote manipulation、马甲矩阵、未披露推广,一旦被识别是连号带内容一锅端,且Reddit的处罚往往不通知,你的可见度会无声归零。
这里值得单独提醒:Reddit这条线的脆弱性远高于做自己的网站。你的官网内容是自己的资产,Reddit上的可见度是建在别人地盘、靠社区情绪和平台规则维系的——一次封号、一次版规变动、一次社区反感,可能让多月积累瞬间清零。所以它该被定位成“高价值但高波动的补充战线”,不能拿它替代你自己可控的内容资产。
Reddit内容怎么二阶传导到Google AI概要和ChatGPT?
战线二是战线一的副产品,但搞清楚传导机制,能帮你判断投入的回报边界。
结构性原因有三层。第一层是数据合作。Google与Reddit有内容授权协议,Reddit的讨论被纳入Google的检索与AI概要生成;OpenAI也与Reddit有数据合作。这让Reddit语料在外部AI的检索增强里占了一个结构性高位。第二层是内容特性匹配。AI生成答案在主观、经验型问题上最缺“真人怎么说”的语料,而这正是Reddit的核心存货。模型在合成“X值不值得买”这类答案时,天然倾向于抽社区共识。第三层是信号继承。外部AI抓Reddit时,会参考Reddit自己的社区信号(高赞、强讨论)做内容质量代理。也就是说,你在站内被顶起来的那条共识,被外部AI复用的概率最高。
这条传导链的实战含义是:你无法直接优化“被ChatGPT引用”,能做的是让站内那条共识里有你客观参与塑造的成分。这背后还有一个更细的区别——内容被引用,不等于你的品牌被记住、被推荐。AI完全可能引用一条提到你产品的Reddit讨论,却在答案里把功劳归给“某国产品牌”而不点你的名。内容被引用却品牌没被推荐这个落差的成因和破解,那篇讲得更系统,放在这里正好接上:战线二的真正目标不是“Reddit上有人提我”,而是“外部AI在合成答案时,把我作为品牌实体准确归因”。
所以战线二的回报要现实预期:它滞后、间接、且受制于Reddit与各AI厂的商业关系(这些授权关系会变)。把它当作战线一做扎实之后自然溢出的红利,而不是一个能单独投入和承诺的KPI。
怎么衡量你在Reddit搜索面的可见度?
没有衡量就没有运营。Reddit搜索面没有Search Console,得自己搭一套观测,分三层。
第一层,站内被检索到。定期用一组固定的高意图查询,在Reddit站内搜索里手动跑(“best X”“X vs Y”“X worth it”“X problems”),记录前排结果里有没有你参与或塑造的讨论、它们的赞数与排位变化。这是最直接的可见度指标,也是唯一你能直接施力的一层。
第二层,被Reddit Answers引用。把同一组查询丢进Reddit Answers,看合成答案里抽的是哪些帖子和评论、有没有你的贡献被引为答案片段、品牌被提到时是正面还是负面、归因是否准确。这层反映的是你在主观型查询里的答案占位。
第三层,反哺外部AI的间接信号。把同组查询丢进ChatGPT、Google AI概要、Perplexity,看答案里是否出现源自Reddit的、与你相关的提及。这层只能间接观察、且滞后,别指望它和你的动作有清晰的因果对应。
| 层级 | 核心指标 | 采集方式 | 能否直接施力 |
|---|---|---|---|
| 站内被检索 | 高意图查询前排占位、赞数、排位趋势 | 固定查询集手动巡检 | 能(运营直接影响) |
| 被Answers引用 | 答案片段命中、品牌提及情感、归因准确度 | 固定查询集跑Answers | 较能(靠站内共识间接影响) |
| 反哺外部AI | 外部AI答案里源自Reddit的相关提及 | 跨AI平台手动抽检 | 不能(间接、滞后) |
这三层的衡量,和你整体AI流量度量的盲区是连着的:来自Reddit或经Reddit传导到外部AI的访问,在GA4里大多落进直接流量或被错误归因,你几乎不可能用一个会话数去倒推这条线的价值。所以Reddit搜索面的衡量天然是“可见度/份额型”而非“流量/转化型”——盯的是你在那组高意图查询里的答案占位率,不是它带来了多少可归因的会话。这一点和衡量AI搜索影响时不能只看GA4是同一个道理。
哪些做法在Reddit搜索面是反效果甚至危险的?
这条线的失败模式比成功路径更值得先记住,因为大多数品牌不是没做,是做反了。
公关式注水。把官网新闻稿、营销文案改个壳发上去,是Reddit最反感、也最容易被社区当场拆穿的动作。一次公开翻车,对品牌的负面比沉底严重得多——它会被截图、被嘲讽、被写进“这个品牌在Reddit装真实用户”的帖子里。
买赞与刷票(vote manipulation)。这是Reddit反作弊的高压线,识别能力很强,处罚是连号带内容清除,且通常不通知。你以为在涨可见度,实际是在给账号判死刑。
马甲矩阵互捧。开一批号自问自答、互相点赞,短期看似有效,但Reddit的关联识别(行为模式、时间、设备指纹)会把整组端掉,多月积累一次清零。
AI批量生成评论。用模型批量产社区评论,语言密度和真实体验颗粒度对不上,老用户和平台都越来越能识别,且这类内容即使没被立刻处理,也不会被排序器当成有社区背书的高价值内容,等于白做。
把Reddit当可控资产。最隐蔽的错误是战略层面的:因为Reddit这条线见效,就把内容和预算往它倾斜、弱化自己的站。前面说过,这条线建在别人地盘,规则和社区情绪一变就可能清零。它是补充战线,不是地基。
shadowban要单独说,因为它最坑:被shadowban后你自己看一切正常(能发帖、能看到自己的帖),但别人和搜索都看不到你。很多品牌运营了几个月才发现一直在对空气说话。所以前面衡量那一节里“帖子是否异常零曝光”必须是常规巡检项——用一个没登录的浏览器去搜你刚发的帖能不能搜到,是最简单的自检。
把Reddit搜索面纳入出海搜索矩阵,前90天该怎么落地?
给一个分三段的落地节奏,把预期和动作对齐,避免“发两周没效果就放弃”这种典型死法。
第0到30天:侦察与选区。不发任何推广。用站内搜索跑你品类的高意图查询,定位2到4个高意图subreddit,把它们的版规、厂商参与规则、高赞内容形态摸清;同时建立固定查询集和巡检基线(现在这些查询的前排是谁、有没有竞品、有没有关于你的讨论)。这一阶段的产出是一张战区地图和一条基线,不是流量。
第30到60天:可信度积累与真实贡献。账号开始在目标版做纯价值贡献——答疑、分享真实经验、客观对比,不带链接、不硬推。目标是账号在版内被当成一个懂行的真实参与者。这一阶段不该用流量或转化考核,该用“账号是否被社区正常接纳、贡献是否拿到自然互动”来考核。预期管理在这一段最关键,团队和老板都要明白这是在攒可信度本金。
第60到90天:被检索验证与反哺监测。开始在相关讨论里坦诚介入(披露身份),产出真正高质量的复盘和对比,观察固定查询集里的排位变化、是否进Reddit Answers的引用、外部AI是否开始出现间接提及。这一阶段才看可见度指标,且看的是答案占位率而非可归因会话。
三个案例的真实形态,可以说明这套节奏在不同业务里的差异。一个出海3C配件品牌(做手机/相机周边),战区在几个硬核器材讨论版,机会点是“X配件兼容性/值不值”这类主观查询,靠工程师身份做真实兼容性踩坑复盘建立可信度;一个出海户外运动装备品牌,战区在装备测评向的社区,机会点是长周期真实使用复盘(一件装备用一季后的衰减、和大牌的客观对比),媒体形态的实拍在这里权重高;一个B2B SaaS工具,战区在从业者职业讨论版,机会点是“X工具在真实团队里好不好用”,靠真实使用边界和不适用场景的坦诚换信任。这三类都没有靠精确营收数字证明,因为这条线的回报本来就难以单点归因——它们的共同点是都把第一笔投入花在了可信度而非曝光上,且都把这条线定位成补充而非替代自有资产。
这篇和站内相关文章差在哪?
说清楚边界,避免你读重复或读串。站内已有一篇讲Reddit等社区信号如何被外部AI搜索当成引用源、品牌官网为何输给陌生人评论的实战指南,那篇的主轴是“战线二”——内容如何被外部AI引用;还有一篇讲Reddit作为GEO注入渠道在2025年因饱和与刷量降温、要往别的渠道转移,那篇是渠道层面的策略取舍;另有一篇拆AI推荐机制、提醒别盲目刷Reddit和维基百科。本篇不重复这三条线,专打它们都没正面处理的“战线一”:Reddit它自己就是一个有八千万周搜索量的搜索引擎兼答案引擎,你必须在它站内被检索到,且这条线是战线二的上游。三篇放一起读是完整的:本篇讲站内检索面怎么立、那几篇讲外部传导与渠道取舍。
常见问题解答
下面几个问题,是出海团队在评估要不要投入Reddit搜索面时最常卡住的地方。
八千万周搜索量,是不是说明Reddit已经能当Google用了?
不是替代关系。Reddit搜的是它自己封闭语料里的社区讨论,强在主观、经验、购买决策型查询;事实查询、官方信息、广覆盖检索仍然是通用搜索引擎的地盘。正确理解是:在“真人用起来到底怎么样”这一类高购买意图的查询上,Reddit成了一个绕不开的搜索面,而不是它能替代Google。
我们品牌官网内容很好,为什么在Reddit搜索和ChatGPT里还是输给匿名评论?
因为Reddit的检索链路核心信号是社区共识——投票、评论、账号可信度、帖龄,而你的官网内容不在这套链路里,没有这些信号。它不是不够好,是没在那个被检索的语料和信号体系里存在。要赢回来不是把官网写更好,是让真实有用的信息以社区能接受的方式进入Reddit的链路。
在Reddit上发推广帖能直接提升被AI引用的概率吗?
几乎不能,还可能反效果。外部AI引用的是Reddit站内被社区顶起来、形成共识的内容,推广帖既进不了这套共识,又容易被识别和处罚。被外部AI引用是站内可信度做扎实后的副产品,没有捷径可以跳过站内这条线直接买到。
Reddit这条线该用流量和转化考核吗?
不该。来自Reddit及经它传导的访问在GA4里大多被错误归因,你拿会话数倒推会得出错误结论。这条线该用可见度/份额型指标考核——你在固定高意图查询集里的前排占位率、被Answers引用的比例、品牌提及的情感与归因准确度。
小团队没人力长期养Reddit账号,值得做吗?
值得做但要收窄。不要广撒网,只锁定1到2个最高意图的subreddit,把有限人力全压在“真实贡献换可信度”上,宁可少而真。Reddit这条线最忌讳的就是用营销号批量铺,那比不做更糟——会留下品牌装真实用户的负面证据。
Reddit改版把搜索前置、扩展媒体形态,对内容策略意味着什么?
意味着两件事:搜索行为会进一步增长,站内被检索到的价值还会涨;以及在户外、3C、安装演示这类品类,真实的图片和视频会比纯文字更容易被新版搜索和Answers抽取,值得提前在内容形态上押一手真实媒体,而不是只发文字复盘。
权威参考资料
本文标题:《Reddit SEO实战:8000万周搜量出海怎么被搜到》
本文链接:https://zhangwenbao.com/reddit-search-ai-citation-geo-strategy.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0