AI内容检测工具怎么用?12项语言特征拆解AI痕迹,附逐句降痕实战
本文目录
- 为什么AI写的内容,老练的读者一眼就能看穿?
- 这款AI内容检测工具到底在算什么?
- 12项语言特征分别是怎么打分的?
- 句式均匀度与段落均匀度
- 词汇丰富度(类符形符比)
- AI偏好短语(权重最高的一项)
- 过渡词、句首重复、被动、模糊、确定性
- 情感中立度与列举结构
- 综合AI概率分是怎么加权算出来的?
- 逐句标注的红黄绿是怎么判定的?
- 这款工具的检测,和GPTZero那种到底差在哪?
- 检测分高了,到底该怎么把它降下来?
- 把AI痕迹降下来,会不会反而伤了被AI引用的机会?
- 中文内容用这款检测工具,结果靠谱吗?
- 一段AI稿和一段真人稿,分数差距是怎么一项项拉开的?
- 不同体裁的内容,AI检测基线为什么天生不同?
- 那120多个AI偏好短语,到底长什么样?
- 怎么把AI检测嵌进日常内容生产的流程里?
- 常见问题解答
- AI检测分降到多少才算安全?
- 这工具能100% 骗过所有AI检测器吗?
- 把AI痕迹改没了,会不会内容质量也下降了?
- 为什么我用真人写的稿子,也被判了高AI分?
- 降低AI分和做GEO让AI引用,是不是矛盾的?
- Google会因为内容是AI写的就惩罚我吗?
- 权威参考资料
摘要:这款AI内容检测工具不调用大模型,而是用12项语言特征(句式均匀度、AI偏好短语、过渡词密度、词汇丰富度等)做加权打分,把一篇文章的“AI味”量化成0到100分,并逐句标红,告诉你哪一句最像机器写的、为什么像、该怎么改。本文拆开它的全部公式与权重,讲清它和GPTZero那类困惑度检测的真实差距,再给一套把检测分降下来、同时不丢失专业度的实战流程。
保哥这两年帮出海客户审稿,遇到一个反复出现的尴尬:一篇读起来“挺顺”的文章,丢进检测器却被判90分AI生成。客户慌了,问是不是要全部重写。其实大可不必。AI味不是玄学,它是一组可以被测量的语言学指纹——句子一样长、过渡词扎堆、爱用那几个万能形容词、几乎没有个人情绪。把这些指纹一项项拆开看,你就知道该动哪里,而不是把整篇推倒。
这篇教程拆的就是我们团队内部常用的一款AI内容检测工具。它的特别之处在于:算法全部公开、可手算复现,不像商业检测器是个黑盒。理解它怎么打分,比单纯看一个分数有用得多——因为你最终要骗过的不是这一个工具,而是搜索引擎背后那套“这内容到底是不是真人写的、值不值得信”的判断。
为什么AI写的内容,老练的读者一眼就能看穿?
大语言模型逐词预测下一个最可能的词,这个机制天然带来两个副作用:句子长度趋同、用词趋于“安全”。学术界把这种特征叫做困惑度(perplexity)低、突发性(burstiness)低。困惑度衡量一段文字对模型而言有多“意外”,AI自己写的东西对它自己来说毫不意外,所以困惑度低;突发性衡量的是全文节奏的起伏,真人写作长短句交错、忽快忽慢,AI则平铺直叙,突发性也低。
GPTZero这类主流检测器的第一层,正是建立在困惑度与突发性这两个指标之上。它们用一个语言模型去算每句话的困惑度,再看全文的波动。学术界更进一步的方法是Mitchell等人2023年提出的DetectGPT,它发现模型采样出的文本会落在模型对数概率函数的负曲率区域,用这个曲率特征判断文本来源,把GPT-NeoX生成假新闻的检测AUROC从0.81提到了0.95。
这里有个关键认知:上面这些方法都需要一个真正的语言模型来算概率。而我们要拆的这款工具走的是另一条路——它不加载任何大模型,纯靠可观察的语言学特征去逼近这些信号。这条路精度上有取舍,但胜在透明、免费、可解释,每一分都能追溯到具体哪一句、哪一个词。对要快速自查、批量过稿的内容团队来说,这种“看得见原因”的检测往往比一个冷冰冰的概率分更实用。
还有个现实背景值得记住:AI检测一直是一场军备竞赛。模型在进步,生成的文本越来越像人;检测器也在迭代,特征库不断更新。这意味着没有哪个检测分是永久有效的——今天判30分的写法,半年后换个新模型可能就不灵了。所以真正稳妥的策略,不是去钻研“怎么刚好骗过某一版检测器”,而是理解AI味的底层来源,把内容做得真有人的思考和经验在里面。后者是任何一代检测器、任何一个搜索引擎都认的硬通货,前者只是一时的捷径。本文把算法拆这么细,目的也在这里:让你掌握原理而非依赖某个工具的具体分数。
这款AI内容检测工具到底在算什么?
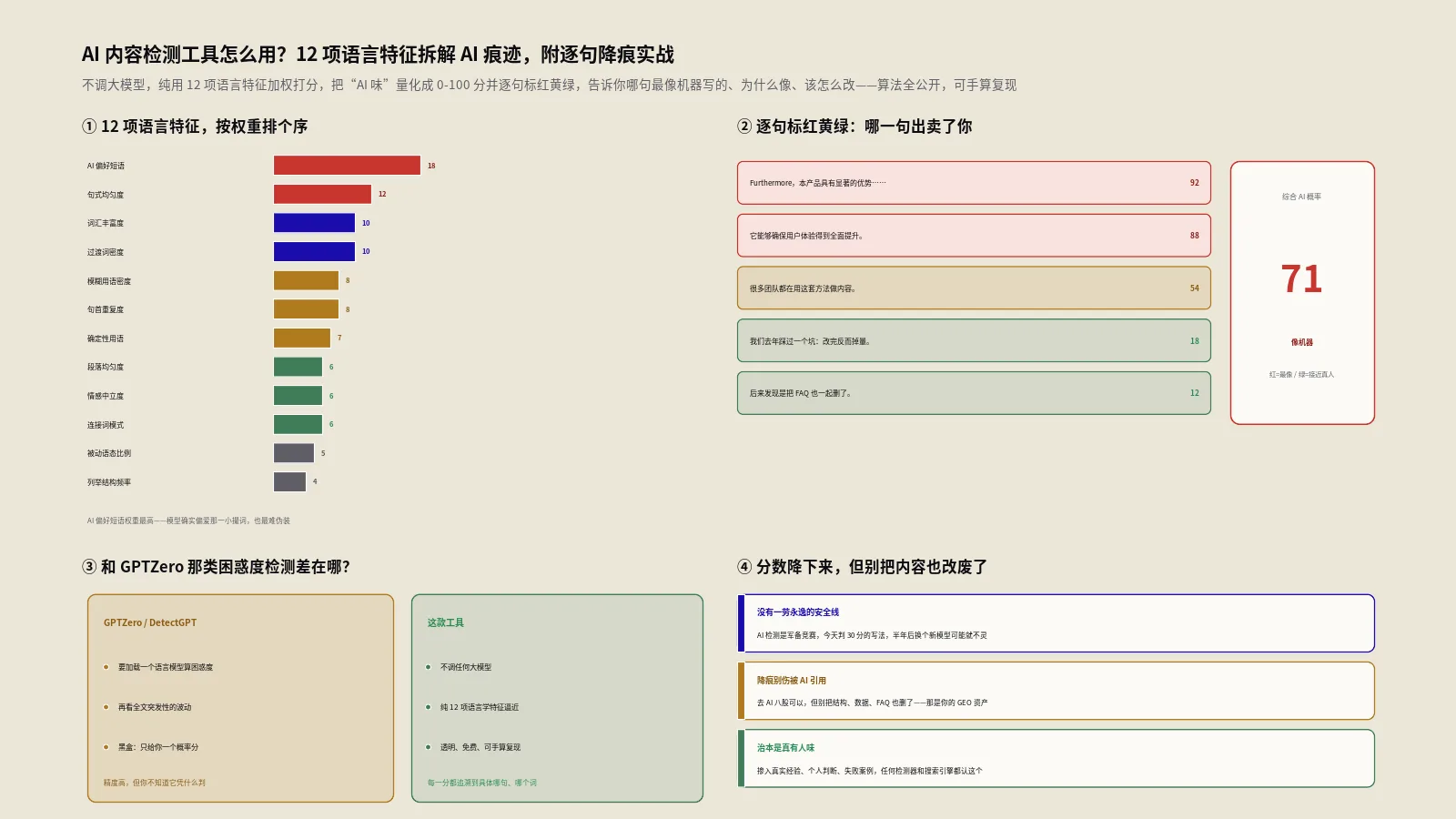
工具把一段文本切成句子和段落,然后并行计算12项语言特征,每一项给0到100分(分越高表示越像AI),最后按预设权重加权平均,得到总分。总权重正好是100,方便心算。下面这张表是全部12项信号和它们的权重,这是整个工具的骨架:
| 信号 | 权重 | 它在抓什么 |
|---|---|---|
| AI偏好短语 | 18 | 命中120多个AI爱用的英文短语/中文表达 |
| 句式均匀度 | 12 | 句子长度的离散程度,对应突发性 |
| 词汇丰富度 | 10 | 类符形符比,用词重不重复 |
| 过渡词密度 | 10 | furthermore、moreover这类衔接词扎堆程度 |
| 模糊用语密度 | 8 | various、significant这类万能形容词 |
| 句首重复度 | 8 | 多少句话用同一个词开头 |
| 确定性用语 | 7 | ensure、crucial、undoubtedly这类断言词 |
| 段落均匀度 | 6 | 段落长度的离散程度 |
| 情感中立度 | 6 | 有没有第一人称情绪表达 |
| 连接词模式 | 6 | 过渡词与句首模式的综合 |
| 被动语态比例 | 5 | 被动句占比 |
| 列举结构频率 | 4 | 编号列表、项目符号的密度 |
看权重分配,你立刻能读出工具的判断逻辑:AI偏好短语权重最高(18),因为它最难伪装——模型确实偏爱那一小撮词;句式均匀度次之(12),因为突发性是公认的强信号。而被动语态、列举结构权重很低,因为真人也常用,区分度弱。这套权重不是拍脑袋来的,它和GPTZero把突发性放在第一层、把短语模式作为补充的思路是一致的。
12项语言特征分别是怎么打分的?
这一节把每个公式摊开。先说英文模式(工具对英文支持最完整),中文模式后面单独讲。所有公式都做了0到100的截断,下面只写核心算式。
句式均匀度与段落均匀度
先算每个句子的词数,求平均值与标准差,再算变异系数cv(标准差除以均值)。得分是100减去cv乘200。cv越小说明句子越一样长,越像AI,所以扣得越狠。当cv小于0.25,工具直接提示“句子长度非常均匀——AI典型特征”。段落均匀度同理,只是把单位从句换成段,系数从200换成180。这两项合在一起,就是工具版的“突发性”。
词汇丰富度(类符形符比)
英文模式下,工具取全部小写单词,算ttr等于不重复词数除以总词数的平方根(这是修正版TTR,避免长文本天然偏低)。得分是100减去ttr乘12。ttr越低,说明翻来覆去用那几个词,越像AI。这正是大模型的通病:它倾向于用高频、安全的词,而真人会蹦出更多生僻、口语、行业黑话。
AI偏好短语(权重最高的一项)
工具内置120多个AI高频英文短语,比如delve into、leverage、robust、seamless、a wide range of、it is worth noting、game-changer、at the end of the day,以及一批中文表达,比如“值得注意的是”“众所周知”“综上所述”“赋能”“助力”。它逐个去全文里找,命中数除以每百词,得到短语密度,再乘15。这一项最毒,因为这些词是模型的“口头禅”,一篇正常人写的稿子很少会三句话蹦一个leverage。
过渡词、句首重复、被动、模糊、确定性
- 过渡词密度:统计furthermore、moreover、however、consequently等20多个衔接词的出现次数,每百词的密度乘20。密度超过3就判“过渡词使用频繁”。
- 句首重复度:找出现次数最多的那个句首词,除以总句数,乘250。如果30% 的句子都用同一个词开头,分数会冲很高。
- 被动语态比例:用正则匹配is/are/was + 过去分词的结构,占句数比例乘4。权重只有5,因为区分度弱。
- 模糊用语密度:various、significant、comprehensive、substantial等19个万能形容词的密度乘18。
- 确定性用语:ensure、crucial、undoubtedly、invariably等断言词密度乘25。AI爱用绝对化措辞,真人反而常留余地。
情感中立度与列举结构
情感中立度反着算:得分是80减去情感词密度乘25。情感词包括love、hate、honestly、I think、I feel、in my opinion,以及中文的“我觉得”“说实话”“老实说”。情感词越多,分越低(越像人);一篇完全没有“我”的文章,这一项会高。列举结构则统计编号列表和项目符号的密度乘5——AI特别爱把一切都列成一二三。
综合AI概率分是怎么加权算出来的?
拿到12项分数后,工具做加权平均:把每项得分乘以它的权重,全部相加,再除以总权重100。公式就是这么朴素,但威力在于权重的取舍。我们来手算一个例子,假设一篇典型AI稿测出如下分数:
| 信号 | 得分 | 权重 | 得分×权重 |
|---|---|---|---|
| AI偏好短语 | 85 | 18 | 1530 |
| 句式均匀度 | 80 | 12 | 960 |
| 词汇丰富度 | 55 | 10 | 550 |
| 过渡词密度 | 70 | 10 | 700 |
| 模糊用语密度 | 75 | 8 | 600 |
| 句首重复度 | 60 | 8 | 480 |
| 确定性用语 | 65 | 7 | 455 |
| 段落均匀度 | 70 | 6 | 420 |
| 情感中立度 | 78 | 6 | 468 |
| 连接词模式 | 65 | 6 | 390 |
| 被动语态比例 | 40 | 5 | 200 |
| 列举结构频率 | 50 | 4 | 200 |
把最后一列加起来是6953,除以总权重100,得到约70分。这就是这篇稿的综合AI概率分。你会发现,光是AI偏好短语和句式均匀度两项(合计权重30)就贡献了2490分,占了三分之一强。这给了一个非常清晰的优化方向:想最快把分降下来,先动这两项——删掉那些AI口头禅,再把句子打散成长短不一。后面的实战环节会反复用到这个杠杆思路。
逐句标注的红黄绿是怎么判定的?
除了全文总分,工具还会逐句给一个aiScore,然后标成三色:绿色(human,像人)、黄色(mixed,存疑)、红色(ai,像机器)。这个句级分的规则比全文简单粗暴,但很实用:
- 句子里命中AI偏好短语:加30分,每多命中一个再加10分,并列出是哪几个词。这是最重的一项。
- 句子长度和全文均值高度一致(偏差小于15%,且全文超过5句):加15分。太“标准”反而可疑。
- 以AI典型句式开头(furthermore、it is important、this ensures、“值得注意”“综上所述”等):加20分。
- 英文句里同时出现2个以上模糊词或确定性词:加15分。
累加后截断到100,大于等于50标红,25到50标黄,低于25标绿。这套规则的妙处是它会告诉你“这句为什么红”——是因为含了delve into,还是因为句长太标准。改稿时你不用猜,直接照着原因动手。实际审稿时最依赖的就是这个逐句视图,比盯着一个总分高效太多。
这款工具的检测,和GPTZero那种到底差在哪?
必须把话说透,否则就是误导。GPTZero、DetectGPT这类方法的核心是用真正的语言模型去计算困惑度或对数概率曲率,它们能“感知”到文本在模型概率空间里的位置,这是语言学特征替代不了的精度。我们这款工具不算真困惑度,它用句式均匀度逼近突发性、用120短语库逼近“AI口头禅”、用TTR逼近用词多样性——是一组聪明的代理指标,不是原版。
| 维度 | 本工具(特征法) | GPTZero/DetectGPT(模型法) |
|---|---|---|
| 是否调用大模型 | 否 | 是 |
| 困惑度 | 用句长离散度近似 | 真实逐句计算 |
| 可解释性 | 每分可追溯到具体词句 | 多为黑盒概率 |
| 对改写的鲁棒性 | 较弱,删短语即可降分 | 较强 |
| 成本与速度 | 免费、毫秒级 | 需算力、较慢 |
所以正确的用法是:把它当成稿件出厂前的快速体检和改稿地图,而不是当成法庭证据。它告诉你“这篇大概率会被判AI、问题主要出在短语和句式上”,你据此修。至于最终能不能过某个商业检测器,还得拿目标检测器复测。两类工具是互补的:特征法帮你定位病灶,模型法帮你做终判。
检测分高了,到底该怎么把它降下来?
这是大家最关心的。基于工具的权重结构,降分有明确的优先级。我们把它整理成一份从高杠杆到低杠杆的清单,按这个顺序动手,效率最高:
- 先扫AI偏好短语(最高杠杆):把delve、leverage、robust、seamless、it is worth noting、综上所述、赋能助力这类词逐个揪出来,换成具体、口语、有行业气味的说法。光这一步常能砍掉15到20分。
- 打散句长(次高杠杆):把几个长句拆开,再合并几个短句,制造长短交错。目标是把变异系数cv拉到0.4以上。一句三五个字的短促断句,杀伤力极大。
- 稀释过渡词:删掉一半的however、furthermore、综上所述。衔接靠逻辑而非靠词。
- 注入第一人称与情绪:加几处“我当时判断错了”“说实话这个坑我踩过”,把情感中立度压下去。这同时是真人痕迹和E-E-A-T信号,一举两得。
- 换句首词:别让一堆句子都从The、This、它 开头。
举个去标识化的真实案例。保哥一个做家用医疗器械出海的客户,产品页配套博客最初全靠AI批量生成,检测分普遍在88到92。我们没重写,只做了上面前三步:删短语、拆句、砍过渡词,分数掉到55左右;再补第四步,给每篇加一段创始人试用产品的第一手描述(含具体型号、佩戴体感、踩过的售后坑),分数稳定到30出头,同时这些段落后来成了被AI搜索引用的高频片段。整个过程没动一处事实,只动了语言肌理。
更值得说的是后续。很多人担心降AI痕迹会不会顺手把搜索表现也改差了,这个客户的数据给了答案。改写后三个月,那批博客的自然点击不降反升,平均停留时长涨了将近四成。我们的判断是:删套话、加第一手经验这套动作,本质上是在提升内容的真实信息密度,读者愿意多读一会儿,搜索引擎的行为信号也跟着变好。所以“降痕”从来不是为了应付检测器的防御性动作,它和“写出好内容”指向的是同一件事。真正要警惕的,反倒是那种为了刷低分硬塞口水话、把好句子改烂的操作——那才是真的赔了夫人又折兵。
把AI痕迹降下来,会不会反而伤了被AI引用的机会?
这是个好问题,也是很多人没想清楚的地方。降AI痕迹(humanize)和被AI引用(GEO)听起来像两个相反的目标,其实不冲突,它们管的是内容的两个不同层面。
降AI痕迹管的是语言肌理:让句子读起来像真人、有突发性、有第一手经验,这恰恰是Google和AI引擎判断内容可信度的依据。被AI引用管的是结构骨架:清晰的标题层级、列表、对比表格、Answer-First的开头,让AI容易抽取你的内容。一篇理想的稿子应该是“真人的肌理 + 利于抽取的骨架”——读起来像专家随手写,结构上却整整齐齐方便机器引用。
所以我们团队的标准流程是三步走:先用本文这款检测器测AI味、降到合理区间保住真人感;再用差异化处理避免和全网AI稿千篇一律;最后才上结构优化,让内容既像人写又被AI爱引。这三件套构成完整闭环,下一篇会专门讲怎么按引擎偏好重写结构。关于为什么“原创人类视角”本身就是AI搜索时代的硬通货,可以读站内那篇AI搜索奖励深度原创内容的14周实操账本。
中文内容用这款检测工具,结果靠谱吗?
得诚实说:这款工具,包括市面上绝大多数AI检测器,对英文的支持都远好于中文。原因在底层——中文没有空格分词,类符形符比、被动语态正则这些英文里成熟的算法,搬到中文都得打折。工具自己也在中文模式里做了降级处理:被动语态分直接给固定值30,句首模式靠句式均匀度推断,词汇丰富度改用单字多样性来算。
中文模式下真正有效的信号,是那套中文AI偏好表达库(“值得注意的是”“随着……的发展”“综上所述”“赋能”“助力”“数字化转型”等)和句段均匀度。所以如果你的内容是中文,建议这样用:把工具结果当成“短语命中清单 + 句式节奏参考”,对总分打个问号,重点看它标红了哪些句、揪出了哪些AI套话,据此手改。需要更严肃的中文判断,再上中文专门的检测服务做复核。把局限讲明白,本身就是专业度的体现,也是给读者的E-E-A-T信号。
一段AI稿和一段真人稿,分数差距是怎么一项项拉开的?
抽象公式看多了容易飘,不如看两段对照。下面左边是AI直出的段落,右边是按本文方法改写后的版本,主题都是“怎么挑选跨境物流服务商”。先看AI版:
选择合适的物流服务商至关重要。furthermore,它显著影响着客户体验。一个优质的物流合作伙伴能够提供全面的解决方案,确保货物安全及时地送达。moreover,它还能优化你的运营成本。值得注意的是,可靠性是关键考量因素。
这段在工具里大概率红到80以上。逐项拆:句子都是中等长度、节奏均匀(均匀度高分);连命中furthermore、moreover、综上同族的过渡词(过渡词密度高分);“至关重要”“全面的”“确保”“值得注意的是”全是短语库里的钉子(AI偏好短语爆表);通篇没有一个“我”、没有任何具体数字(情感中立度高分)。五项强信号同时拉满,总分自然高。
再看改写版:
挑物流商,我只看一件事先于价格的东西——旺季还能不能交货。去年双十一,我一个做户外装备的客户,账面最便宜的那家直接爆仓,三千单压在仓库出不去。后来换了贵8% 但有自营海外仓的服务商,妥投率从86% 回到97%。便宜是真便宜,赔起来也是真赔。
同样的意思,这段在工具里基本是绿的。变化在哪:句子长短交错,有“挑物流商”这种三字短促开头(均匀度被打散);零过渡词,全靠逻辑承接;没有一个短语库里的词;有第一人称、有具体场景、有86% 到97% 的真实数字(情感中立度被压低,反而是E-E-A-T信号)。你看,不是改了意思,是改了肌理。把这两段并排放在工具里跑一遍,每一项信号怎么动,一目了然——这也是建议新手上手时做的第一个练习。
不同体裁的内容,AI检测基线为什么天生不同?
有个坑很多人没意识到:同样是真人写的,不同体裁的“天然AI分”差很多。如果你不按体裁调整期望,很容易冤枉好内容、放过坏内容。原因在于,某些体裁本身就要求工整、克制、术语密集,这些特征恰好和AI特征重叠。
| 体裁 | 天然AI检测基线 | 为什么 |
|---|---|---|
| 个人随笔/复盘 | 低(最像人) | 第一人称多、情绪足、句式随性、有具体经历 |
| 行业教程/How-to | 中等 | 需要列举步骤、用标准术语,但仍有判断和经验 |
| 产品营销文案 | 偏高 | 爱用“全面”“高效”“领先”这类万能形容词 |
| 学术/技术规范 | 高(最易误判) | 被动语态多、措辞克制工整、几乎无情绪 |
| 新闻通稿 | 高 | 结构模板化、用词中立、句长均匀 |
这张表的用法是:拿到一个分数,先问“这是什么体裁”。一篇学术综述测出60分,未必是AI写的,可能只是体裁使然;而一篇个人复盘测出60分,那就很可疑了——这个体裁本该轻松压到30以下。我们团队内部的做法是给不同体裁设不同的红线:随笔卡35,教程卡45,规范类放宽到55,而不是一刀切用同一个阈值。把体裁纳入判断,检测才不会变成机械的猎巫。
这也回到一个根本认知:检测分是手段不是目的。它帮你发现“这段读起来像不像机器”,但最终决定内容价值的,是有没有真本事、有没有第一手洞察。脱离体裁和内容质量去抠那个数字,是把工具用反了。
那120多个AI偏好短语,到底长什么样?
既然AI偏好短语是权重最高(18)的信号,把这份清单吃透就是性价比最高的功课。工具的短语库可以分成几个家族,理解它们的“气味”比死记硬背更有用:
| 家族 | 英文典型 | 中文典型 |
|---|---|---|
| 万能动词 | delve into、leverage、utilize、facilitate、harness、foster | 赋能、助力、驱动、引领、推动 |
| 万能形容词 | robust、seamless、holistic、comprehensive、cutting-edge | 全面的、高效的、创新的、深入的 |
| 装腔短语 | it is worth noting、at the end of the day、in terms of | 值得注意的是、需要指出的是、归根结底 |
| 结构口头禅 | let's delve in、as mentioned earlier、a wide range of | 综上所述、总而言之、首先……其次……最后 |
| 夸张断言 | game-changer、state-of-the-art、without a doubt | 毋庸置疑、众所周知、扮演着重要角色 |
| 套话名词 | landscape、tapestry、cornerstone、ecosystem、paradigm | 数字化转型、可持续发展、解决方案 |
这些词本身没罪,问题在密度。真人偶尔用一个leverage很正常,但AI会三句一个、五句一个,密度高到刺眼。工具算的就是这个密度,所以你的改写目标不是把它们清零,而是把密度压回正常区间。
这里的落地建议是:把这张表做成团队的“禁用词速查表”,让写手在初稿阶段就有意识地绕开高密度套话。这比写完再回头一个个删高效得多。更进一步,可以针对自己的行业补充专属套话——每个垂直领域都有自己泛滥的“黑话模板”,比如外贸圈的“一站式”“全链路”“闭环”,这些虽然不在工具默认库里,但同样是一眼假的AI味来源。把行业套话也纳入自查,稿子的真人度会再上一个台阶。
怎么把AI检测嵌进日常内容生产的流程里?
单次检测的价值有限,把它做成流程才有复利。我们给客户落地的SOP大致是这样:
- 出厂体检:每篇稿发布前必测一次,AI概率分卡在40以下放行,超过就退回改写。把这一步写进发稿清单,谁都不能跳。
- 逐句过红:重点看红色句,逐句对照原因修,而不是盲目改全文。
- 真人痕迹注入:每篇至少保证有一处第一手经验段落(具体数字、具体场景、具体判断),这是降分和提质的双赢动作。
- 月度抽检:对已发布的老内容随机抽10% 复测,揪出早期纯AI批量生产的存量,排期翻新。
- 团队对齐:把120短语库做成一份“禁用词速查表”发给写手,从源头减少AI口头禅。
这套SOP跑顺之后,你会发现写手的初稿质量本身在提升——因为他们开始有意识地避开套话、主动塞进第一手经验,检测这一步反而越来越少触发退回。这就是把工具流程化的复利:它不只是把关,更在悄悄改变团队的写作习惯。一个月下来,AI味这件事就从“发完才发现”变成了“写的时候就不会犯”,这才是检测工具真正的价值落点。
把文章粘进去,立刻得到12项语言特征评分、0到100的AI概率分和逐句红黄绿标注,每一句为什么可疑都写得明明白白,支持中英文。改稿前先体检一次,心里就有数了。
如果你想沿着“被AI引用”这条线继续往下走,可以顺手看看同系列的实体关联分析器,它讲的是怎么让AI从看见你到引用你;想从根上理解E-E-A-T怎么落成可执行清单,站内这篇E-E-A-T到底是不是排名因素的拆解值得一读。
常见问题解答
AI检测分降到多少才算安全?
没有绝对安全线,但保哥的经验阈值是40。低于40,文章在语言肌理上已经足够像真人,大多数商业检测器也不会轻易判它AI。卡在40到60是灰色地带,建议再修;高于60基本会被判AI生成,必须动手。要强调的是,这个分只是参考,最终还得拿你要面对的具体检测器复测。
这工具能100% 骗过所有AI检测器吗?
不能,任何宣称能100% 的工具都在吹牛。它用的是语言学特征,和GPTZero那种基于真实困惑度的模型法不是一个原理,能帮你定位并消除大部分明显的AI痕迹,但不保证通过每一个检测器。正确心态是把它当改稿地图,而不是免死金牌。
把AI痕迹改没了,会不会内容质量也下降了?
恰恰相反,如果你按正确方法改。降AI痕迹的核心动作是删套话、打散句式、加第一手经验,这些每一项都在提升而不是降低内容质量。会变差的只有一种情况:为了降分胡乱替换词、塞无意义的口语,那是本末倒置。记住目标是更像专家随手写,不是更乱。
为什么我用真人写的稿子,也被判了高AI分?
常见原因有三个:一是你不自觉地用了很多AI也爱用的万能词(significant、various、综上所述);二是句子长度太均匀,缺少突发性;三是过于工整地用一二三列举。真人写作如果太“规范”,也会撞上AI特征。看逐句标红,按提示的原因微调即可,不必怀疑自己。
降低AI分和做GEO让AI引用,是不是矛盾的?
不矛盾。降AI分管的是语言肌理(像不像真人写的),GEO管的是结构骨架(方不方便AI抽取)。理想内容是真人肌理加利于抽取的骨架:读起来像专家随笔,结构上却整齐到机器一看就懂。先降AI味保真人感,再上结构优化提引用,两步是递进关系,不是二选一。
Google会因为内容是AI写的就惩罚我吗?
不会因为“是AI写的”本身惩罚你。Google的有用内容指南说得很清楚:它奖励的是高质量、以人为本、有原创价值的内容,不在意生产方式;它打击的是用自动化批量生产、操纵排名的低质内容。所以别只盯着检测分,真正要做的是让内容有真本事——AI检测分低只是结果,不是目的。
本文标题:《AI内容检测工具怎么用?12项语言特征拆解AI痕迹,附逐句降痕实战》
本文链接:https://zhangwenbao.com/ai-detector-12-signal-humanize-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0