Google排序后还要重排几次?Twiddler栈与召回到上线的8层架构实证

本文目录
- Twiddler到底是什么?为什么2024之前没人当回事?
- 为什么2024之前SEO圈基本不提它?
- 2024 leak与反垄断庭审材料补了什么知识空白?
- 召回到上线之间,事后重排栈到底分几层?
- 对照流水线全景文,这里的纵向深度多了什么?
- NavBoost、Glomar、Tangram等核心Twiddler各做什么?
- NavBoost:基于点击行为的事后调权层
- Glomar与同源去重Twiddler
- Tangram与本地化、新鲜度、SERP拼装
- QDF触发后的新鲜度专用Twiddler
- 为什么我同一关键词不同时刻刷新结果不一样?
- 5类机制让同查询结果在波动
- 对排名监测工具的启示
- 事后调权先看站点级还是查询级Twiddler?
- 三层优先级模型
- 站点级压制的体感识别
- Mustang、Ascorer、Superroot这些组件和Twiddler怎么协作?
- 查询类型决定调用顺序
- 重排栈实证对SEO落地意味着什么?
- 在线教育长尾词案例
- Twiddler框架未来会怎么变?SGE与AI Overview接入了哪些层?
- AI Overview在重排栈的接入位置
- SGE与AI Overview对SEO实操的实际影响
- 重排栈在未来2-3年的可能演化方向
- Twiddler框架对甲方汇报的解释力
- 常见问题解答
- Twiddler和RankBrain是一回事吗?
- NavBoost真的会因为我的页面CTR高就把我顶上去吗?
- 为什么我同一个关键词不同时刻刷新结果不一样?
- Twiddler调权能不能被SEO操作直接影响?
- 事后重排发现我被静默压制了,怎么诊断?
- AI Overview是另一个Twiddler吗?
- leak文档值不值得我深读?
- 权威参考资料
摘要:Google排名不是排一次就定下来。在Mustang与Ascorer算完初排之后,Superroot会触发一组叫Twiddler的事后重排模块——NavBoost看用户点击行为、Glomar做去重压制、Tangram拼装本地化与新鲜度、个性化层按登录态切片,每个Twiddler都能局部覆盖前面的分数。2024年Content Warehouse API泄漏与反垄断庭审材料把这套机制实证了出来,但大多数运营人还在用“一次排序定终身”的旧地图。这篇按召回到上线8层架构拆,把每层职责、典型Twiddler、能动的信号、SEO落地操作映射讲透;同时辨析它与召回到重排四阶段流水线全景(横向通用拆解)、NavBoost单信号品牌实证(单一信号深挖)的差异——本篇切纵向重排层细节,是这两篇的延伸不是替代。
保哥做SEO二十多年里,看过太多关键词排名“为什么今天又掉了”的复盘报告,绝大多数都卡在一个共同的错觉里:以为搜索引擎给一个查询打一次分、按分数排好就完事。可真实的Google排名是一条很长的流水线,初排只是中间一站。后面那些不出名的事后重排层——Twiddler框架里的几十上百个模块——才是把“一份候选清单”翻译成“你看到的那个SERP”的关键。2024年Content Warehouse API泄漏与美国司法部反垄断庭审材料公开后,这套机制第一次有了大规模可引用的实证依据,而不是十几年下来都靠猜。
Twiddler到底是什么?为什么2024之前没人当回事?
Twiddler这个词最早不是营销圈造的,是Google内部工程文档里就在用的术语,意思就是“对一份已经打过分的搜索结果做局部调整的可插拔模块”。一个Twiddler可以做这几件事:把某个结果向上推、向下压、整个剔出、要求集合内不能同源域名超过几条、强制插入一条新闻盒、改变结果片段的呈现方式。每个Twiddler都不需要重跑整个排名打分模型,它只在已经算好的初排结果之上“扭一下”——这就是Twiddler这个词的字面含义。
为什么2024之前SEO圈基本不提它?
原因有三层。第一,Google官方从来没有系统性披露过Twiddler框架,公开文档里出现的“算法”几乎都指Mustang等召回排序模型,而不是事后重排层。第二,Twiddler不属于核心更新(Core Update)的发布节奏——核心更新调的是底层分数模型,Twiddler是上面的覆盖层,它的迭代更频繁、更小步、几乎不发公告。第三,从SEO实操体感看,Twiddler调整往往呈现为“看起来没规律”的局部波动,行业里很容易归因为“算法噪声”或“日常波动”,没人深究背后机制。
2024 leak与反垄断庭审材料补了什么知识空白?
2024年5月,Content Warehouse API文档意外被推送到公开GitHub镜像,里面披露了大量Google内部对页面、链接、查询、用户行为信号的数据建模属性。同时美国司法部诉Google反垄断案的庭审证词里,Pandu Nayak等Google排名负责人也作证确认了NavBoost、Glue、Tangram等模块的存在和大致职责。这两批材料合起来,让SEO行业第一次有了对Twiddler框架的可对照实证基础。下面这张表整理了2024 leak实证(部分)与之前的业界推测的对比:
| 主题 | 2024 leak实证 | 2024之前业界推测 | 推测错在哪 |
|---|---|---|---|
| 点击信号 | NavBoost用GoodClicks/BadClicks与长按返回信号做事后调权 | Mueller反复说“我们不用点击作为排名信号” | 说的是不直接作为排序特征,但作为Twiddler调权输入是另一回事 |
| 同站压制 | Glomar等模块明确做同源去重,限制单站点占位 | 普遍认为同站多结果靠“算法自然压制” | 有专门Twiddler处理,是规则不是自然衰减 |
| 本地化 | Tangram做地理与设备适配的事后重排 | 本地化被当成“独立本地包算法” | 本地化是事后重排层,能覆盖通用SERP |
| 新鲜度 | QDF触发后由专用Twiddler在事后层拔高新结果 | 认为QDF是单一公式 | QDF是触发条件,执行靠重排层 |
| 站点信任 | Site Quality信号在Twiddler层做整站权重抬升或压制 | 归因为“网站权威”模糊概念 | 有量化分数和具体Twiddler应用方式 |
这张表的价值不在每一条具体是什么——具体的Twiddler名字、字段定义和实际生效逻辑随时都可能改——而在结构性认知的修正:Google排名从来不是“一个公式打一次分”,而是“初排+一长串可插拔事后调整”,第二段比第一段灵活得多,也是大量短期波动的真实来源。
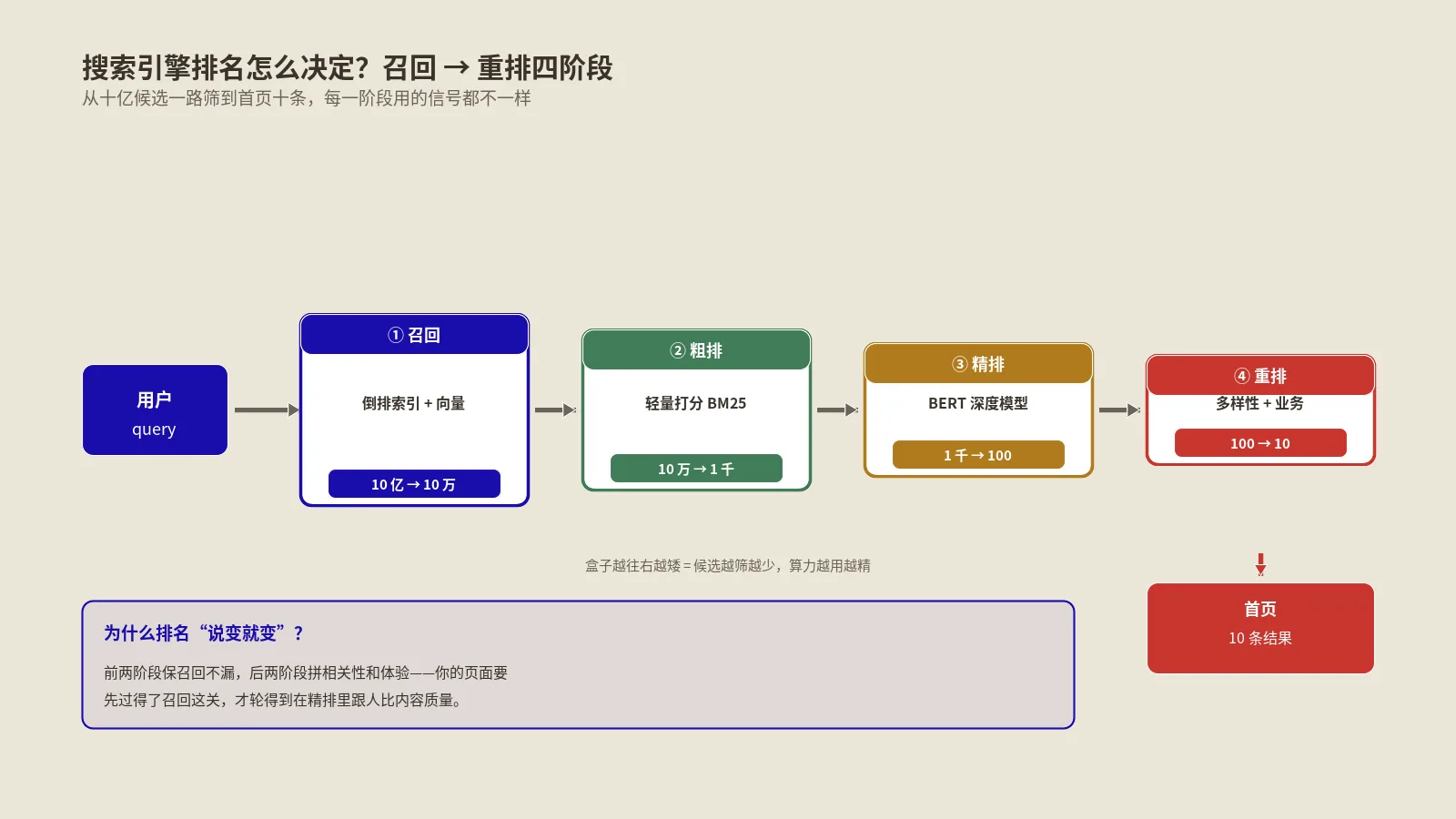
召回到上线之间,事后重排栈到底分几层?
把Google排名的整条流水线展开看,从你按下回车到SERP出现在屏幕上,中间至少经过8个可辨识的阶段。每一阶段都可能在Twiddler框架下挂着多个模块,下面这张表是按照leak实证 + 反垄断庭审 + Mueller公开发言交叉印证得到的,可作为分析自己排名异动的工程化地图。
| 层 | 名称 | 核心职责 | 是否常驻Twiddler | 对SEO的可观测体感 |
|---|---|---|---|---|
| 1 | Query Understanding(含RankBrain、Neural Matching、MUM) | 把用户查询翻译成实体、意图、向量表征 | 否,是召回前置层 | 同一关键词不同表述召回到的页面集差别很大 |
| 2 | Recall(Mustang等召回组件) | 从倒排索引选出几百到几千个候选页面 | 否,但可被Twiddler影响候选池构成 | 页面没进候选池你看再多排名工具都没用 |
| 3 | Initial Ranking(Ascorer等初排打分) | 对候选池每个页面打一个综合质量分 | 否,是核心排序层 | 这是核心更新真正改的地方 |
| 4 | Superroot调度 | 触发后续Twiddler、决定调用顺序和参数 | 否,是Twiddler调度器 | 查询类型决定哪些Twiddler被激活 |
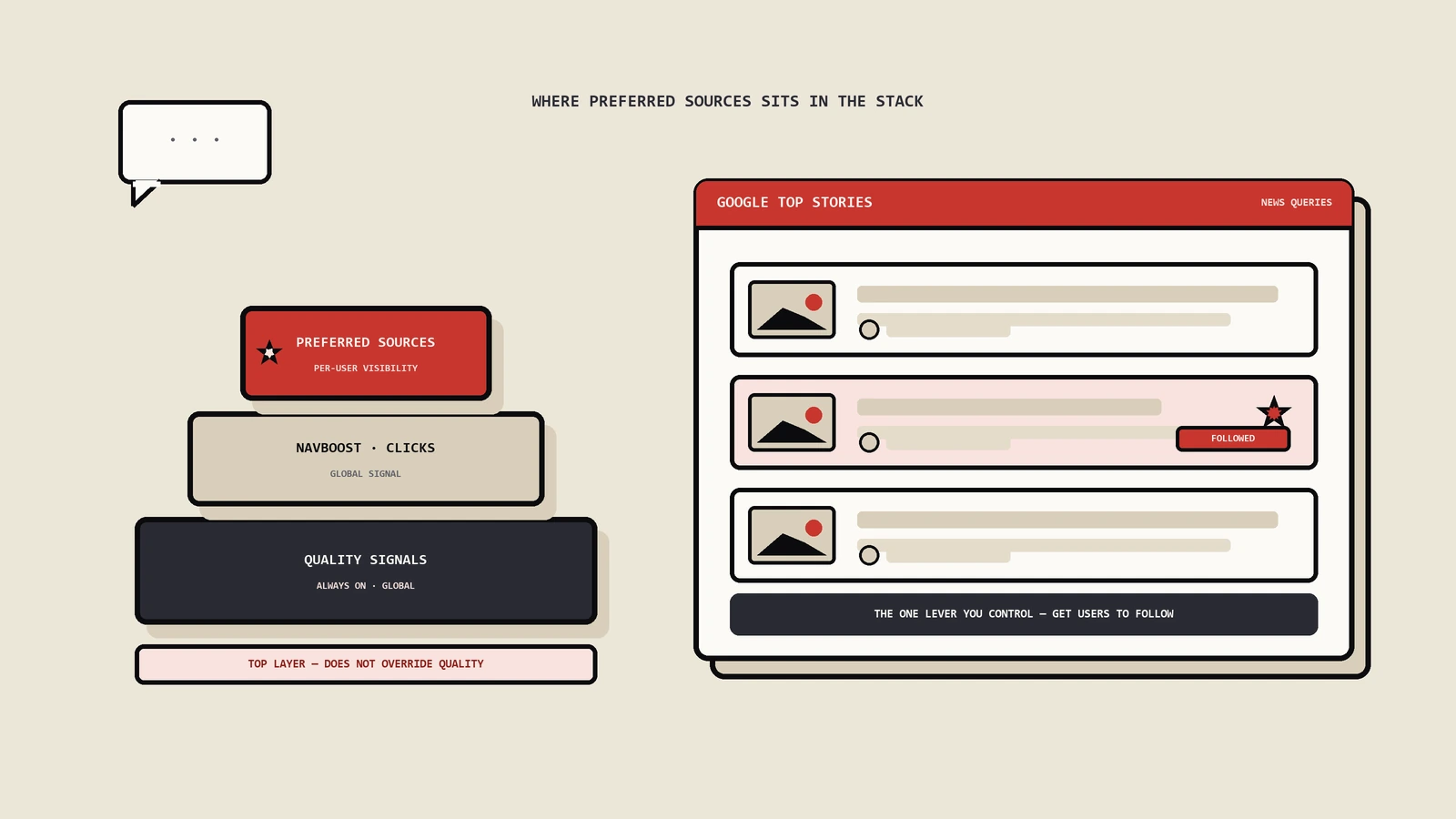
| 5 | Site-Level Twiddler(含Site Quality、HCS等) | 对站点级整体做抬升或压制 | 是 | 整站流量整体浮动而非单页 |
| 6 | Query-Level Twiddler(含NavBoost、QDF、Glomar等) | 按查询特性做单页排序调整 | 是 | 同站点不同页面波动方向不一致 |
| 7 | Personalization Twiddler(登录态、地理、历史) | 按用户上下文做个性化覆盖 | 是 | 同一查询不同设备结果不同 |
| 8 | Tangram拼装与SERP渲染 | 把蓝链、AI Overview、PAA、视频、本地包拼成最终SERP | 部分模块属Twiddler | 位置变化但页面分数没变也可能是这层导致 |
这套8层架构有一个反直觉的特性:越靠后的层,覆盖能力越强但触发条件越严格。也就是说,初排算出的分数可能在第5-8层被覆盖到完全看不出来,但这种覆盖是有触发条件的——不是每个查询每次都会全部走完所有Twiddler,而是Superroot按查询类型挑哪些Twiddler上场。
对照流水线全景文,这里的纵向深度多了什么?
站内已经有一篇“搜索引擎排名召回到重排四阶段拆解”(前文TLDR已链),那篇是横向全景视角,把召回、初排、重排、服务拆成四段讲。本篇切的是其中“重排”这一段的纵向深度——把“重排”展开成Site-Level Twiddler、Query-Level Twiddler、Personalization Twiddler三层不同优先级的可插拔事后调整。两篇互为补充,不重叠。
NavBoost、Glomar、Tangram等核心Twiddler各做什么?
Twiddler不是一两个模块,是几十上百个挂在事后重排层的可插拔组件。下面挑出leak实证 + 反垄断证词里出现过的核心几个,按职责分类讲。
NavBoost:基于点击行为的事后调权层
NavBoost是leak后被SEO行业关注最多的Twiddler。它的核心机制是用户对SERP结果的“点击体感”——具体说是GoodClicks(点进去停留长、不返回的点击)、BadClicks(点进去立刻按返回键的点击)、LastLongestClick(一次查询里最后那个点了之后没再回SERP的结果)三个指标,对查询结果做调权。重要的是它怎么用这些信号:
- NavBoost看的不是绝对点击数,而是相对比例与衰减——同一查询下你的BadClicks比例高于同位竞品就被压
- 有上限和冷却——同一查询同一结果短期内的NavBoost调权幅度有封顶,刷不动也撑不久
- 按查询分桶——同一页面在不同关键词下NavBoost调权是独立计算的,不会跨查询累积
- 受SafeSearch与垃圾过滤层并行约束——NavBoost抬上去也可能被其他Twiddler同时压下来
保哥服务过一家跨境美妆DTC客户,曾经在某产品测评关键词上排名稳定第4位连续8周,第9周突然掉到第11位,没有任何技术调整、内容调整、外链事件。复盘下来发现SERP第1-3位被一个新出现的视频测评站占据,那个站的GoodClicks比例显著高于纯文本测评,触发NavBoost对所有同位文本结果的相对压制——这种“被竞品的好体验反向挤下来”是NavBoost典型机制,靠链接和内容硬刚没用,需要做产品页本身的用户体验改造来重新拉回GoodClicks占比。
Glomar与同源去重Twiddler
Glomar是leak里出现的同源结果限制模块。它的核心是确保单一站点在同一SERP上不会占太多位置——通常是两条蓝链上限,少数高权威站点偶尔三条。Glomar不在召回或初排层工作,而是在事后重排层把超出上限的同站结果整条压走。这就是为什么有时候你优化得很好的同站第3条结果排不上去,不是单页分数不够,而是Glomar拒绝把你的第3条结果放进SERP里。
Tangram与本地化、新鲜度、SERP拼装
Tangram是leak里出现频率很高的拼装层模块,职责是把蓝链、本地包、知识面板、新闻盒、视频缩略图、AI Overview等组件按某种“槽位+优先级”模型拼成最终SERP。Tangram不直接给页面打分,它是决定“该展示什么类型的结果块”的层。对SEO实操的体感就是:你的页面初排算分排第3,但SERP上前三位被新闻盒、视频缩略图、本地包占了,你的蓝链实际显示位置变成第6位——这种“位置变化但分数没变”的现象多数是Tangram拼装策略导致的,不是你的排名掉了。
QDF触发后的新鲜度专用Twiddler
QDF(Query Deserves Freshness)不是单一公式,它是一个触发条件:当某个查询的近期搜索量、相关新闻发布密度、社交平台讨论度三个信号同时上升到阈值,QDF会触发,然后调用专用的新鲜度Twiddler把近期发布的内容拔高、把陈旧的常青内容压低。这就是为什么“突发新闻类查询”里几小时前发的稿能压住老资源——不是老内容质量下降,是QDF Twiddler在事后层做时效性覆盖。
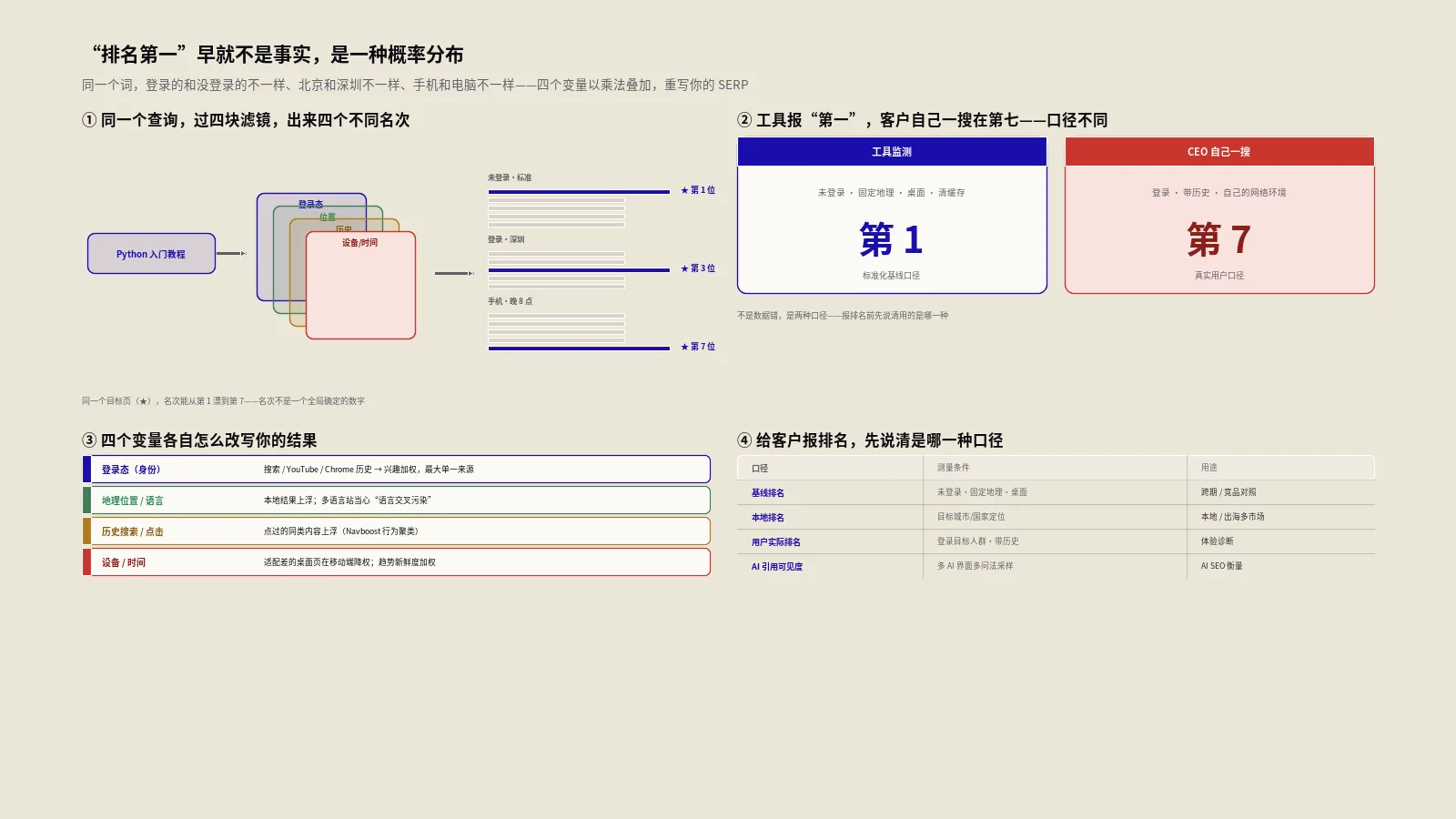
为什么我同一关键词不同时刻刷新结果不一样?
这个问题几乎所有SEO从业者都被甲方问过,过去标准答案是“个性化和地理本地化”。但leak之后我们知道事情更复杂——同一关键词同一设备同一登录态短时间内刷新两次结果不一样,背后至少有5类机制在轮换。
5类机制让同查询结果在波动
| 机制 | 触发层 | 典型表现 | 能不能改 |
|---|---|---|---|
| 个性化Twiddler | 第7层 | 登录态下你历史看过的内容更靠前 | SEO影响有限,可做点击复购重复访问 |
| 地理本地化Tangram | 第8层 | IP切换城市结果整体重洗 | 本地SEO与多地服务覆盖可改 |
| QDF触发与衰减 | 第6层 | 新闻爆发期排名暴动几小时后恢复 | 常青内容做不了,新闻类内容可对接 |
| A/B实验分桶 | 各层 | 不同会话拿到不同的实验组结果 | SEO完全不能影响 |
| SERP渲染抖动 | 第8层 | 同分数结果间的微小排序差异 | 正常工程现象,无法消除 |
对排名监测工具的启示
这套机制对排名监测工具的可信度有直接影响。任何单点采样的排名数据,本质上抓到的都是5类机制叠加后的某一个“切片快照”,不能简单当成“我的真实排名”看待。靠谱的做法是:
- 同一查询多次采样(建议每天2-4次),取中位数而非单点
- 分设备分地理采样(移动端、桌面端、登录态、未登录态、主要市场城市各自一份)
- 同步看GSC的展现量分布——展现量稳定且点击率稳定,单点排名波动可以忽略
- 把A/B实验抖动作为基线噪声扣除——长期保持80% 以上同位的排名才算“稳定”
事后调权先看站点级还是查询级Twiddler?
事后重排层不是平铺的,三类Twiddler在Superroot调度时有明确的优先级与作用顺序。这个顺序决定了“为什么我整站流量在某次更新后整体下滑了30%,但某些热门词反而排名上升”——因为站点级Twiddler先把整站压低,但某些查询级Twiddler(比如QDF或NavBoost)又把特定页面在特定查询下重新拔起来。
三层优先级模型
| 层级 | 典型Twiddler | 作用范围 | 触发条件 | 调整幅度 |
|---|---|---|---|---|
| Site-Level站点级 | Site Quality、HCS、Site Authority | 整站所有页面 | 整站质量信号变化 | 大幅、长期 |
| Query-Level查询级 | NavBoost、QDF、Glomar、商业意图层 | 特定查询命中的页面 | 查询特性触发 | 中幅、按查询独立 |
| Personalization个性化 | 登录态、地理、设备、历史 | 单用户单会话 | 用户上下文 | 小幅、即时 |
站点级压制的体感识别
站点级Twiddler调整最难处理,因为它一调就是整站集体反应。识别站点级被压制有几个特征信号:
- 不是单页掉,是整站的80% 以上页面在同一周内同时下滑
- 各分类下都掉,不集中在某个分类或某种内容类型
- 核心品牌词排名几乎不动,但所有非品牌词同步下滑
- 新发文章上线后的“起飞速度”比之前显著变慢
- GSC展现量整体降,不是CTR问题
这五个信号同时出现,几乎可以判断站点级Twiddler出了变化——不是某次Core Update重新评估了你的整站质量分,就是HCS站点级分类器把你打到了“unhelpful”那一类。修复路径不是改内容,是从源头改信号:内容质量评估、E-E-A-T信号补全、用户行为体感改造、站点信任度建设——这些都不是几周能见效的工作。
Mustang、Ascorer、Superroot这些组件和Twiddler怎么协作?
很多人把Mustang、Ascorer、Superroot、Twiddler这些名词混在一起讲,其实它们在流水线上是不同位置的不同组件,分工很清楚。下面这张表整理出来:
| 组件 | 位置 | 核心职责 | 与Twiddler关系 |
|---|---|---|---|
| Mustang | 召回层 | 从倒排索引拉取候选页面集 | 不直接调用Twiddler,但决定Twiddler能“重排”哪些页面 |
| Ascorer | 初排层 | 对候选页面打综合质量分 | 给Twiddler提供基础分数 |
| Superroot | 调度层 | 按查询特性决定调用哪些Twiddler、什么顺序 | Twiddler调度器 |
| Twiddler | 重排层 | 对初排结果做局部覆盖、压制、拔高 | 自己就是 |
| Tangram(部分) | 拼装层 | SERP组件拼装 | 部分模块属Twiddler框架 |
查询类型决定调用顺序
Superroot不是机械地走遍所有Twiddler,而是根据查询类型动态决定调用集合:
- 本地服务类查询(“附近的牙医诊所”):Tangram优先级最高,本地包必现,NavBoost退到第二位
- 新闻热点类查询(“美联储加息”):QDF Twiddler第一时间触发,新鲜度压倒一切,Glomar同源去重收紧到一条
- 购物比价类查询(“AirPods Pro 2价格”):商业意图Twiddler拔高电商页面,购物盒子优先于普通蓝链
- 导航类查询(直接搜品牌名):NavBoost主导,品牌词GoodClicks信号几乎一锤定音
- 信息探索类查询(“什么是GEO”):知识面板与AI Overview优先于蓝链,Tangram配合
这就是为什么单一关键词类型的优化思路不能跨类型套用——同样是排第5位,本地服务类查询的第5位上面三位是本地包,购物类查询的第5位上面三位是购物盒子,新闻类查询的第5位上面三位是新闻盒。每种SERP形态下你的“提升排名”动作完全不同。
重排栈实证对SEO落地意味着什么?
了解Twiddler框架不是为了写论文,是为了把日常SEO操作的“为什么这么做”重新校准。下面这张映射表把8类常见SEO操作对应到了它们真正起作用的Twiddler层,把“我做这件事是在影响哪一层”讲清楚。
| SEO操作 | 影响层 | 典型Twiddler | 见效周期 | 常见误区 |
|---|---|---|---|---|
| 外链建设 | 初排层信号、站点级Twiddler | Site Authority、SpamBrain | 3-6个月 | 以为是单页效应,其实多数是站点级累积 |
| 内容质量改造 | 初排层、HCS站点级Twiddler | HCS、Content Quality | 核心更新窗口 | 不是改一篇就行,是整站质量分被重新评估 |
| 页面体验优化 | NavBoost查询级Twiddler | NavBoost | 4-12周 | 不是CWV直接排名,是改善GoodClicks占比 |
| 本地化部署 | Tangram拼装层 | Tangram本地化 | 2-8周 | 不是优化关键词,是匹配地理触发条件 |
| 新闻时效抢占 | QDF触发Twiddler | QDF Freshness | 几小时到几天 | 常青策略反而错位 |
| 实体与品牌建设 | 初排实体信号、个性化Twiddler | Entity、Personalization | 6-18个月 | 不是堆品牌词出现次数,是建立实体识别 |
| 同站架构重组 | Glomar同源去重边界 | Glomar | 2-6周 | 同站多页冲一个词反而被Glomar卡死 |
| 结构化数据 | Tangram SERP拼装 | Tangram | 2-12周 | 不是直接排名,是争取SERP上更显眼的展示 |
在线教育长尾词案例
保哥带过一家做IT在线教育的客户,他们一个很长的长尾词“Python入门多久能找到工作”原来稳定在第2位,某次Core Update后掉到第8位。客户的第一反应是“我们的内容是不是被HCS打掉了”,要做整站重写。我们做诊断时分了4步:
- 看整站流量曲线——没有显著下滑,证明站点级Twiddler没动
- 看同分类其他长尾词排名——80% 都在原位,少数甚至上升
- 看新进前3的竞品页面——是3篇明显“用户口碑型”的Reddit讨论帖和YouTube视频转写
- 对比GSC展现量与CTR——展现量基本没变,CTR反而上升了,但排名就是不回来
合起来诊断结论是:QDF Twiddler触发了,因为这个查询类型从“信息探索类”开始向“用户口碑探索类”漂移,Tangram拼装策略调整后给Reddit与YouTube留了固定槽位,蓝链候选池实际可用位减少。修复路径不是改内容质量,而是在这篇文章里加入“真实学员故事”和“具体行业入职案例”这类用户口碑型表达,让我们的页面变成“既是教科书又是经验贴”的混合体——重新匹配漂移后的查询意图。8周后这个词回到第3位,比原位低一档但比第8位好得多——位置上限被Reddit与YouTube槽位顶死,回不到第2位是Tangram结构性的限制不是单页问题。
Twiddler框架未来会怎么变?SGE与AI Overview接入了哪些层?
2024年5月Google I/O上AI Overview全量推出后,很多人问“AI Overview是不是把Twiddler都重写了”,其实不是。AI Overview更像是接入Twiddler框架的一组新模块,底层重排栈基本没动。它的接入位置可以拆成三段看。
AI Overview在重排栈的接入位置
| 阶段 | 组件 | 职责 |
|---|---|---|
| 触发判定 | Query Classifier | 判断这个查询是否值得生成AI Overview(YMYL、个性化建议、复杂综合类倾向于触发) |
| 素材池构建 | 从初排候选池抽取 | 不是另起一套召回,是从Mustang已经召回的池子里选可被引用的段落 |
| 来源选择Twiddler | 新增的Citation Twiddler | 从素材池里挑被引用的3-8个来源,优先选高E-E-A-T信号与高语义匹配度 |
| 生成与展示 | Gemini模型生成 | 把素材合成AI Overview框,再交给Tangram拼到SERP顶部 |
SGE与AI Overview对SEO实操的实际影响
底层Twiddler没消失——NavBoost还在调权、Glomar还在去重、QDF还在触发。新增的是Citation Twiddler这一层,它决定你能不能被AI Overview引用。这个Twiddler选源的逻辑跟蓝链排名不完全重合——经常出现“我蓝链排不进第1页,但被AI Overview引用了”,或者反过来“我蓝链稳第1位,但AI Overview不引用我”的现象。要在AI Overview时代不被边缘化,需要做的工作可以拆成3个层级:
- 段落级可引用性——单段落能独立成立、有清晰定义性表述、信号密度足够高,让Citation Twiddler容易抽取
- 实体与权威信号——作者署名、机构关联、外部权威站点的引用支持,让Citation Twiddler在选源时把你列入“可信源”
- 主题深度与广度的平衡——AI Overview倾向于引用“一个主题讲透的页面”而不是“什么都讲一点的综合页”,单意图聚焦的内容相对更容易被引用
这层Citation Twiddler还在快速演进,每隔几个月引用逻辑就会有大幅变化。从Mueller公开发言和社区一手信号反推算法变化仍然是相对靠谱的早期信号源——配合GSC展现量与AI Overview出现频率的监控,可以提前发现Citation Twiddler的变化趋势。
重排栈在未来2-3年的可能演化方向
从2024 leak公开到现在一年多时间里,几条演化趋势已经能看出来。第一条是Twiddler数量在增加而不是减少——AI Overview接入只是带来了新的Twiddler,老的NavBoost、Glomar、Tangram都还在岗位上。第二条是Twiddler之间的冲突仲裁机制在加强——以前不同Twiddler之间有时会“打架”(一个推上去另一个压下来),现在Superroot调度器在做更复杂的冲突仲裁,避免两个Twiddler互相抵消。第三条是个性化层Twiddler在变深——单用户的搜索历史不只用来重排当前会话,还在影响下次会话的查询理解层。这三条加起来意味着:未来排名解释的复杂度会继续上升,“为什么我掉了”会越来越难给单一原因,多因素叠加诊断会成为常态。
对SEO实操的最大启示是:不要追单一Twiddler信号。leak出来之后行业里冒出过一阵“NavBoost信号工程”的风潮,把所有精力压在改善GoodClicks占比上——这种押宝单一Twiddler的做法在框架稳定时还能见点效,框架本身在快速演化时反而会被打回原形。把8层架构每层都做到合格线以上,比把某一层做到110分更重要。Reasonable Surfer链接算法在今天的落地对应到链接质量信号层的工程化思路,可以参照那篇做对照——单层做好、多层叠加才是稳态打法。
Twiddler框架对甲方汇报的解释力
保哥服务过一家出海工业品B2B SaaS客户,市场总监被CEO问“为什么我们某个核心关键词排名一周内从第3位掉到第9位但下周又自动回到了第4位”——这种问题在“一次排序定终身”的旧地图里根本解释不了,市场总监很难给CEO一个体面的答复。复盘下来用Twiddler框架给的诊断报告:第一周触发了QDF(一个行业头部媒体发了一篇深度报道,QDF启动新鲜度重排把那篇报道拔到前3位,挤掉了我们);第二周QDF衰减(新鲜度信号过期)排名自动回归。这种“机制可名状、波动可解释、不慌乱乱改”的诊断口径,对甲方信任度的建立比任何漂亮排名增长报告都管用——能讲清楚为什么动了,比纠正动了多少更重要。
常见问题解答
Twiddler和RankBrain是一回事吗?
不是。RankBrain在召回与初排阶段做语义理解的特征贡献者,Twiddler是事后重排框架,对初排结果做局部覆盖、压制、拔高。两者层级、调用时机和作用范围都不同。
NavBoost真的会因为我的页面CTR高就把我顶上去吗?
不会简单这样工作。NavBoost看GoodClicks与BadClicks的相对比例和长按返回的衰减信号,且每个查询有上限和冷却。短期刷高CTR多数会被识别成噪声打回,不能当成增长杠杆操作。
为什么我同一个关键词不同时刻刷新结果不一样?
Tangram与个性化层Twiddler在事后重排时会按时间窗、地理位置、设备、登录态对结果做局部覆盖。同一关键词两次刷新中间,新鲜度信号、本地化SERP、广告盒子位置都可能触发不同Twiddler重新排序。
Twiddler调权能不能被SEO操作直接影响?
可以影响但不能直接操控。Twiddler读的是召回与初排层算出来的结构化信号——你能改的是这些底层信号本身(内容质量、站点信任、品牌实体、用户行为体感),不能去hack Twiddler这一层。
事后重排发现我被静默压制了,怎么诊断?
对照GSC的展现量与点击率分布、跨设备跨地理结果、AI Overview与SGE接管段是否吃掉了你的曝光、是否伴随站点级(不是单页)下滑。多数时候被压制源头是Site Quality与NavBoost而非链接或技术。
AI Overview是另一个Twiddler吗?
更接近一组接入重排栈的额外组件。它从十蓝链候选池里挑出可被引用的段落作为答案盒底层,再走自己的来源选择层。底层Twiddler没消失,AI Overview是新加的一层选源与展示框架。
leak文档值不值得我深读?
值得读但要小心解读。Content Warehouse API文档不等于活跃代码,里面有大量历史遗留、未上线、实验性属性。把leak当佐证而不是真相,结合反垄断庭审证词与Mueller公开发言交叉验证,才不会走偏。
权威参考资料
本文标题:《Google排序后还要重排几次?Twiddler栈与召回到上线的8层架构实证》
本文链接:https://zhangwenbao.com/google-rerank-twiddler-navboost-leak-architecture.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0