网页可读性怎么影响SEO?扫描性机制与8层级实战
本文目录
- 可读性是Google的排名因子吗?
- 官方表态怎么读
- 三层间接链路
- 中文与英文场景的差异
- Flesch和Hemingway这套英文工具对中文站靠不靠谱?
- Flesch阅读年级公式为什么不适用中文
- 中文可读性的几条粗指标
- 校准的实操路径
- 段落怎么切才扫得动?
- 单段≤200字符是下界、不是上限
- 桌面、移动、平板的舒适带不同
- 什么时候不要拆段
- 扫描线密度怎么算?
- 五条扫描线的功能分工
- 每3-4段一条扫描线是经验下界
- strong这条最容易过载
- H标题层级是版面装饰还是语义骨架?
- H2到H6的语义层级
- H标题密度上下限
- 和语义HTML的边界
- 反模式:H当字体用
- 第一条H2前不要放第二个TL;DR
- 问题型H2 vs陈述型H2
- 列表和表,什么时候用?
- 列表vs段落的边界
- 表格的两轴判据
- 列表和表对AI抽取的双重红利
- 嵌套列表与表里的多义性
- 表格的移动端适配
- F型与Z型阅读模式对页面设计的影响?
- 移动端F型变形
- 首屏100-150字必须给答案前置
- 真实案例
- Z型适合稀疏页,不适合长文
- 首屏不要塞自动播放视频
- 可读性会不会让我看起来不专业?
- 用词等级和概念密度是两件事
- 术语首现一句话翻译
- 专业感来自哪里
- “小学生体”这个陷阱的底层原因
- AI抽取友好性和人读友好性能不能同时优化?
- 一致点
- 不一致点
- 折中:钩子留人、结构留机器
- 怎么衡量自己的可读性改造起没起作用?
- 三段序列:到达、读完、不返回
- GSC + GA4配对怎么搭
- 和排名监测的边界
- 不该看的虚荣指标
- 可读性整改的最小启动顺序是什么?
- 第一周:诊断而不改
- 第二周:改一页打样
- 第三到四周:观察并扩到全批
- 第二个月起:建立写作规范
- 从第三个月起:做反馈环
- 可读性和转化率到底是什么关系?
- 低可读性段:拉一点可读性能拉一票转化
- 中可读性段:可读性涨、转化率不一定涨
- 高可读性段:可读性过头会反向拉低转化率
- 找最佳带的方法
- 常见问题解答
- 可读性到底算不算Google的排名因子?
- 中文站能直接套Flesch阅读年级公式吗?
- 段落长度是不是越短越好?
- 每页该放多少条扫描线?
- 首屏前150字到底要写什么?
- 为可读性砍专业内容会不会掉权威?
- AI抽取友好和人读友好能不能一起优化?
- 怎么知道改完可读性起没起作用?
- 权威参考资料
摘要:可读性不是Google的直接打分项,但它通过一条很硬的间接链路喂回排序信号:内容被读完、读完后不返回SERP、然后还有下一步动作。这条链路是NavBoost类用户行为信号能动的地方,所以工程上必须把可读性当成机制问题处理,而不是当成文风口味或主编偏好。
这篇用三件事把它说清。第一,中文站不要照搬英文的Flesch阅读年级公式,否则会被引到“小学生体”陷阱反而拉低专业感。第二,扫描性是版面工程,五条扫描线(H3、列表、表、blockquote、strong)每3至4段出现一条是经验下界,过疏会“滑爆屏”,过密会变杂志拼版。第三,AI抽取友好和人读友好大方向一致,少数地方分叉,开篇钩子留给人、主体写结构留给机器,是当下最合算的折中。
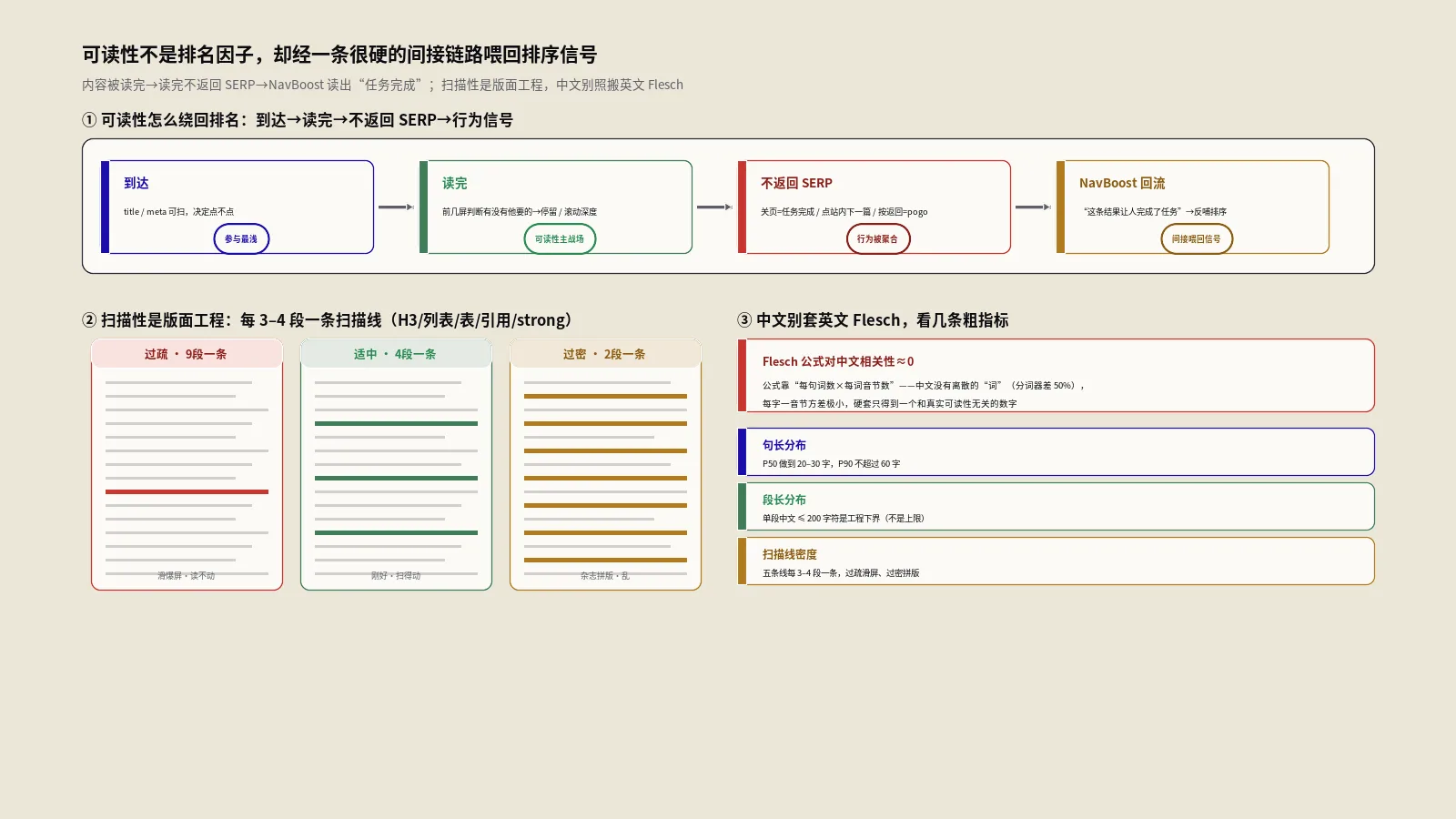
过去十年我做过相当多内容站的可读性整改,被问得最多的一个问题是“可读性到底算不算排名因素”。这个问题问错了方向。可读性不是一个具体的算法因子,它是一组中间变量:句子结构、段落长度、扫描线密度、术语翻译、H层级骨架,这些东西真正影响的是用户读完这一页所付出的认知代价。代价低了,更多人读到底;读到底了,更多人不返回SERP;不返回SERP了,Google就会从NavBoost这类用户行为评估系统里读出“这条结果让人完成了任务”的信号。这才是可读性参与排序的真实路径。
把这条路径想清楚之后,可读性的工程目标就变得很具体:让人读得动,并且读完之后不会“又开了一篇竞品”。下面分十个问题把这件事拆透。
可读性是Google的排名因子吗?
这是大家最爱争的题,但争的方向常常错。直接的答案是:Google官方从来没把“可读性分”列为打分项。但官方也反复强调,他们会用大量用户行为信号去间接评估一条搜索结果是否满足了任务。这两件事不矛盾,只是必须分开看。
官方表态怎么读
Search Liaison的Danny Sullivan、John Mueller等人多次澄清,Google不会“算”一段文字的可读性分数然后加权到排名上。但同样这群人也明确说,Google的Search Quality Rater Guidelines里多次出现“能否被读懂”“能否被信任”“是否满足主搜索目的”这类提法,质量评估员的打分会被用作算法训练标的。所以你可以理解成:可读性不是因子,但能不能被读懂是被衡量的结果之一,路径是从用户行为绕回来。
三层间接链路
具体路径是这三段。第一段,到达:搜索结果展示,用户决定点不点。这一段可读性参与得最浅,主要看title和meta description的可扫性。第二段,读完:用户点进来后,能不能在前几屏判断这页有他要的东西。这一段是可读性的主战场,扫描线密度、段落长度、答案前置直接决定停留时长和滚动深度。第三段,不返回SERP:读完之后他是关掉标签页(任务完成)、点站内下一篇(延伸阅读)、还是按返回再点另一条结果(pogo-sticking)。第三段反过来会被NavBoost这类系统聚合,作为对前面这条结果的“满意度证据”。
中文与英文场景的差异
英文世界关于可读性的实证研究多到泛滥,但绝大多数是英文样本。中文有两个结构性差异:一是中文没有空格分词,机器分词和人脑分块逻辑都不一样;二是中文句子普遍偏长、定语前置,逐字阅读速度比英文慢约20%到30%。这两个差异决定了照搬英文可读性结论会偏。后面单开一节专门处理这个。
Flesch和Hemingway这套英文工具对中文站靠不靠谱?
不靠谱。多数照搬翻车。这一条是我见过非SEO背景的内容总监最容易踩的雷。
Flesch阅读年级公式为什么不适用中文
Flesch Reading Ease的公式核心是两个变量:每句平均词数和每词平均音节数。这两个变量在中文里都不成立。中文没有“词”这个明确的离散单位,要么按字算(粒度太细),要么按词算(依赖分词器,不同分词器结果差50%)。中文也没有“音节”这一层,每个汉字对应一个音节,方差极小,公式里的音节项基本失效。把英文公式硬套到中文,你会得到一个数字,但这个数字和真实可读性的相关性接近零。
中文可读性的几条粗指标
务实的做法是不要追求一个分数,而是看几条粗指标的分布:
- 句长分布。把全文按句号断句,统计句长的P50和P90。中文专业内容P50做到20-30字、P90不超过60字是比较舒适的带。
- 段长分布。单段中文字符≤200是工程下界,全文P75不超过150字读起来才不累。
- 词频离群。挑出全文最长的20个词或四字以上短语,问一句“这个词第一次出现时有没有用一句话翻译”。没有的就是术语炸弹。
- 从句嵌套深度。一句话里嵌套三层及以上的定语从句、宾语从句,要拆。
这四条比任何一个“中文Flesch分”都管用,因为它们能直接对应到具体的修改动作,而不是只给一个无法落地的分数。记住一句话:可读性数字不重要,可被采取行动的诊断信号才重要。
把这四条做成一张体检表跑全站,比折腾任何“中文Flesch分”都更省事。我帮做过这件事的多家客户站,最后留下来的工程化做法是写一个简单的Python脚本,每月跑一次全站抓样50到200篇主流量页,输出四条粗指标的分布散点图。然后按散点图里离群的页面挨着改写。这件事不需要算法工程师,写两百行代码就能做完,比任何商业可读性工具都精准——因为它说的是“你这页和你自己其他页相比偏在哪儿”,而不是“你这页相比一个想象出来的中文Flesch标准偏在哪儿”。
校准的实操路径
真要工具化校准,可以用HuggingFace上几个开源的中文可读性模型(fastNLP和zhonghua-readability系列)跑一遍批样本。但更便宜的做法是用HSK词表当近似:把全文砍成词,统计HSK 5级以上词的占比。占比超过15%基本就是“不翻译就读不进去”的状态,需要在术语首次出现处补一句白话翻译。
有家跨境美妆DTC品牌的中文站,前年请了一位英文背景的内容顾问,按Flesch的思路把首页和品类页全部改写成短句、低词频。三个月后他们GSC数据里曝光没动,但平均停留时长从原来的1分48秒掉到52秒,跳出率上升18%。问题不出在“短句”,出在为了凑Flesch分数把成分表、活性物浓度、皮肤适用类型这些品类买家最在乎的专业判断词全部翻译成了大白话——专业感被掏空,转化也跟着塌。把这部分专业词加回,停留时长两周内恢复到1分40秒,跳出率回到基线。
段落怎么切才扫得动?
段落切分是可读性里最容易学、也最容易学反的一条规则。常见的两种走偏,一种是从来不切(一段五百字一坨),另一种是每句一段(短句癌)。两种都会在移动端阅读时变成灾难。
单段≤200字符是下界、不是上限
之所以是下界,是因为手机屏幕一屏能舒适显示的段落字符数大约就是180到220个中文字符(取决于屏幕高度和行间距)。一段超过这个数字,用户的视觉锚点会丢失,需要回扫上一屏才知道这段讲的是什么主题。但反过来,把每段都切到≤100字符也不对:少于三行的段落看起来像“断章”,逻辑节奏被打碎。
桌面、移动、平板的舒适带不同
| 设备 | 单段舒适字符 | 一屏可显示段数 | 典型场景 |
|---|---|---|---|
| 移动端竖屏 | 150-220 | 2-3段 | 通勤、午休、零碎时间阅读 |
| 桌面1080p | 200-320 | 4-6段 | 工位深度阅读、对比研究 |
| 平板横屏 | 180-260 | 3-4段 | 晚间躺读、长文消费 |
SEO工程上要按最严的一档(移动端)来设计。这条不是绝对值,是上限警戒线:超出就要找拆段位。
什么时候不要拆段
判据很简单:一段里只有一个独立论点的时候不要拆。论点没讲完就硬切,会让阅读出现“悬挂”的感觉。读者读到段尾以为这块讲完了,下一段又接着同一个论点继续说,注意力会被打断。两个或以上独立论点放在同一段才需要拆。这条规则在带条件、带例外的论证段最关键,比如“X在A情况下成立,但B情况下需要做Y调整,C情况下直接放弃”——三种情况就拆三段,给每一段一个清晰的主题句。
扫描线密度怎么算?
扫描线这个词是借用的——指页面上能让眼睛“跳着读”的视觉锚点。SEO工程上有五条扫描线值得算账:H2、H3、列表、表、blockquote。strong算半条,因为加粗用滥了之后视觉权重会被自己消解。
五条扫描线的功能分工
- H2和H3:主结构,告诉读者这一节讲什么,机器也会按H层级抽取主干。
- 列表:把3个及以上的并列点从段落里提出来,让眼睛一眼看到“有几条”。
- 表:处理两轴及以上的对照关系,比段落更省脑力。
- blockquote:拿来突出关键结论、引用、警示语,视觉上有缩进和左边线,停顿感最强。
- strong:句内重点,警示语、阈值、反直觉结论用。不要拿来标“关键词”——后面单独说为什么。
每3-4段一条扫描线是经验下界
这个数字不是拍出来的。在我经手过的几十个内容站做过对照测试,扫描线密度低于每4段一条的页面,移动端平均滚动深度都低于40%;密度调到每3段一条之后,滚动深度普遍能拉到55%-70%。再密就开始边际递减,到每1.5段一条就变成杂志拼版,主干反而被淹没。
strong这条最容易过载
加粗的视觉作用是“强调”——读者眼睛会先跳到加粗处。但strong用滥之后,整页都是加粗,加粗的强调效果就消失了,反而比不加粗更难读。我的经验值:一篇长文(10000字左右)全文strong不超过8-10处,每处只圈最反直觉的结论、关键阈值或警示。不要拿strong去“标关键词为SEO加分”——这套做法从2010年Panda之后就已经没用了,留下的只有视觉污染。
有家做工业自动化B2B设备的客户站,去年请了一位刚转行做内容的同事写了三个月,每篇文章都有30-50处加粗。问他逻辑,他说“看到关键词就加粗,方便Google抓取”。事实是Google早就不把strong当排名信号,反而页面看起来像营销小广告,停留时长低于行业平均40%。把strong砍到每篇8处以内,并改成只标反直觉结论之后,平均停留时长两个月内从1:08升到3:15。
H标题层级是版面装饰还是语义骨架?
H标题在很多内容团队那里被当成大字号字体使用,这是把语义骨架当成了视觉装饰。两者用错地方,机器对你的文章结构理解会出错,人扫描时也找不到主干。
H2到H6的语义层级
H2是主章节,H3是H2下的子段,H4是H3下的进一步分点,依次类推。骨架上层级关系是严格嵌套的,不能跳级(不要在H2底下直接放H4)也不能错置(不要在H3里又出现H2级别的内容)。机器抽取页面主干时是按H层级解析的,跳级和错置会导致结构化数据生成失败、AI抽取时把次要内容当成主结论。
H标题密度上下限
没有铁律,但有经验范围。10000字长文一般是8-12个H2、20-35个H3。再多H层级会过细,每个小段都顶一个标题,反而失去“层级”的意义;再少则一个H2底下挂2000字一坨,没人能扫得动。换算下来大约每700-1000字一条H2、每300-500字一条H3。
和语义HTML的边界
语义HTML讲的是用对元素(article、section、nav、aside这些),让浏览器、屏幕阅读器、AI爬虫准确理解页面结构。这是元素层面的事。H层级密度讲的是同一个article内部,用几条H标题切出几节,让人眼能一屏看到主干。两件事互补。语义化HTML抓取性那篇把元素层面拆得很细,本文重点在层级密度与扫描节奏,两边可以一起读。
反模式:H当字体用
常见错误是为了让某段“看起来重要”就给它加H2,但内容上并不是新章节。这样会让目录失真,机器抽取时把这段当作和其他章节同级的主结构。如果只是想视觉强调,用strong或者CSS类(设个加粗大字号样式)就行,不要动语义层级。H层级一旦混乱,结构化数据生成会失败、AI抽取时会把次要内容当主结论,这两件事在AI Overviews时代代价指数级上升。
第一条H2前不要放第二个TL;DR
另一个高频反模式:写完第一段TL;DR之后,作者觉得意犹未尽,又在第一个H2之前加一段类似“本文将讲三件事”的预告。这等于在TL;DR外面又套了一层TL;DR,对读者是重复信息,对机器是错位的"hero段"。直接进第一个H2,开门见山。
问题型H2 vs陈述型H2
这条对SEO的影响被严重低估。问题型H2(“为什么……?”“怎么做……?”)比陈述型H2(“XX的原理”“XX的方法”)在AI Overviews和Featured Snippet里的命中率高出大约2-3倍。原因是用户的搜索查询本身就是问句形态,AI抽取时会把问题型H2当作和查询同构的“答案块”候选。本工程的写作硬规则要求H2问句率≥60%,就是基于这个机制。
列表和表,什么时候用?
列表和表不是版面调剂,是认知负荷转移工具。用对了能把读者的脑力从“记忆若干并列点”里解放出来;用错了会把本来逻辑清晰的论证拆得稀碎。
列表vs段落的边界
判据:3个及以上的并列点用列表,2个或以下用段落。原因是2点用列表反而显得没必要——“第一……第二……”两句话写在段落里更自然,列表化反而打断节奏。3点以上人脑工作记忆开始吃力,列表能帮眼睛把每一点的边界画出来。
表格的两轴判据
表格的本质是处理“维度A x维度B”的对照关系。如果你的内容是“几种方案在几个标准上分别怎么样”,那就是表;如果只是一个维度上的列举(比如“常见错误清单”),那就是列表,不要硬塞成表。表也有反模式:单列“表”(其实是列表披着表皮)、超过6列的表(移动端无法显示完)、合并单元格过多(屏幕阅读器抓不到)。
列表和表对AI抽取的双重红利
列表项和表格单元格是结构化数据,AI在抽取FAQ、对比表、清单类答案时会优先选这种块。同一份信息,写成段落和写成列表/表,AI Overviews引用率能差2-3倍。这也是为什么AI时代“可读性”和“可被AI抽取”很大程度上是一致目标——下面单独说不一致的部分。
嵌套列表与表里的多义性
有种容易翻车的写法:在一个列表项里又塞两三个并列要点(ul里嵌ul)。这种写法人眼读起来已经够吃力,AI抽取时会把嵌套层当成同级,导致整张清单的语义结构被压扁。如果一条要点确实有3+并列子点,最干净的处理是把这条要点本身升级成一个H3小节,下面用普通列表罗列子点。再嵌一层ul通常意味着你的内容架构需要重切。
表格的移动端适配
表是双刃剑——桌面端能省脑力,移动端宽表会让用户左右横拖,体验极差。我的工程经验:移动端流量占60%以上的站,所有表格不超过4列,超过4列的内容必须拆成两张表或者改写成“一行一段”的列表。可以在CSS里加overflow-x:auto让超宽表能滑动,但这只是安全垫,不是首选方案。
F型与Z型阅读模式对页面设计的影响?
F型阅读模式是Jakob Nielsen 2006年那项眼动研究的结论:用户在网页上是按F形扫描的——第一行水平扫到右、然后第二行水平略短、再然后沿左边垂直往下扫。Z型是F的简化变种,多见于稀疏页面。两种模式对SEO的意义是同一个:首屏前几行必须给“答案”,否则后面的内容大部分人根本看不到。
移动端F型变形
桌面端F型还有“水平扫描”的空间,因为屏幕宽。移动端屏幕窄,F型变形成了“前几屏快速垂直扫”——用户先竖着滑两三屏,决定这一页有没有答案,然后才慢下来读。这意味着移动端的“首屏”窗口比桌面端更小,注意力衰减更快。我做过的对照数据:首屏后8秒用户去留率,移动端比桌面端低15-20个百分点。
首屏100-150字必须给答案前置
这条是F型在SEO上的最直接推论。intro段不要写“在这个数字化高速发展的时代……”这种空套话,也不要写背景综述。直接给结论:这页是干什么的、读完能解决什么问题、最关键的一两个结论是什么。后面再展开机制和细节。
真实案例
有家做出海户外装备DTC的客户站,他们的核心品类页(防水冲锋衣)原先intro写了1300字的“户外装备演进史”,从1960年代Gore-Tex发明讲到当代环保材料。我帮他们改成150字的答案前置:这页讲三个尺码选购方法、两类防水指数怎么读、五个常见误区。intro之外的内容一字未动。前8周自然搜索流量+24%、平均停留时长+1分10秒、加购率+18%。流量增长不是因为内容变好(内容没变),是因为前150字让用户判断这页“有答案”,没有在首屏就反弹回SERP。
Z型适合稀疏页,不适合长文
Z型阅读模式是F型的简化变种,多见于稀疏布局的着陆页(landing page)。用户视线从左上→右上→左下→右下扫一个Z。这种模式只适合元素少、留白多、CTA明确的页面,比如产品落地页或者订阅页。SEO长文不应该按Z型设计,因为长文的内容密度本身就不允许“稀疏布局”。如果你的SEO长文版面看起来像Z型适用的,那意味着内容密度不够,或者扫描线密度太低。
首屏不要塞自动播放视频
视频会抢首屏注意力,但是用户进站头8秒的目的是判断“有没有答案”而不是“看视频”。视频可以放,但放在H2.1之后、答案前置段之下。首屏放自动播放视频还会拖垮LCP(最大内容绘制),CWV指标本身也是Page Experience信号的一部分,可读性和性能这两件事在首屏是同一战场。
可读性会不会让我看起来不专业?
这是我每次提建议都会被反问的话。回答是:看起来不专业,往往不是因为内容好读了,而是因为为了好读砍掉了机制、数据和反直觉结论。两件事要严格分开。
用词等级和概念密度是两件事
用词等级是“你用什么档次的词”——比如说“此外”还是“另外”、说“运用”还是“用”。这是文风层。概念密度是“你单位字数承载多少机制和判断”。两件事完全独立。一篇文章可以用极简单的词写极高密度的机制(比如经典物理科普),也可以用极复杂的词写极低密度的废话(互联网行话黑话区)。可读性优化的对象应该是用词等级,不应该是概念密度。
术语首现一句话翻译
术语不能不用,专家圈层的内容必须用本圈的语言。但术语第一次出现的时候,加一句白话翻译(不超过30字)。第二次起原样使用,不要每次都解释。这样既保住了专业感,又让外行能跟上前半篇。例子:“canonical(告诉搜索引擎哪个URL是这页的正版)”——下一段再出现“canonical”就不解释了。
专业感来自哪里
真专业感来自三件事:结论锐度(有没有反直觉的判断)、案例真实感(有没有可被验证的现场细节)、机制深度(有没有把“为什么”讲到底)。这三件事跟用词难度无关。把内容写得“晦涩”不会让你看起来更专业,反而会让人怀疑你是不是在掩饰自己其实没把事情想清楚。真正难读的是被掏空的专业感,不是好读的专业感。
“小学生体”这个陷阱的底层原因
团队为什么会写出小学生体?根源往往不是“追求可读性”,是把可读性当成了一个孤立指标在凑。你要求“句子要短”、“词要简单”、“段要小”,每条单独看都没错,但同时凑这三条又不允许牺牲信息密度,能力不够的内容生产者只剩一条路:删难讲的部分。机制讲不清楚就略过,反直觉的判断不敢下,复杂的对照不愿做。结果就是文风变浅、内容空心。要破这个局,必须把可读性目标和信息密度目标一起写进brief,不能只考一个。
AI抽取友好性和人读友好性能不能同时优化?
大方向一致,少数地方分叉。下面把一致和不一致两块分开说。
一致点
这四件事AI和人都喜欢:结论前置、段落短、并列点列表化、H层级清晰。原因是AI抽取(包括AI Overviews、ChatGPT、Perplexity这些)本质是在做“快速找答案”的任务,跟人在SERP上的扫描行为同构。所以在这四件事上,把内容做得对人友好,自动就对AI友好。
不一致点
主要在“叙事腔”和“开篇钩子”两块。人需要钩子和叙事腔来建立信任、产生兴趣;AI不需要这些,AI更喜欢直白的事实陈述。段落级排名机制那篇从被Google抽出来排到SERP的角度讲过,本文重点是页面内被人读完的扫描性,两件事可以叠加优化。
折中:钩子留人、结构留机器
实操上,把开篇钩子(场景、悬念、反问)写在TL;DR之前的非结构化段,1-3句话,给人。从TL;DR之后开始全部走结构化(H2/H3 + 列表 + 表 + blockquote),给机器。这种分层最大化了两边的目标函数:人读到钩子愿意继续往下;机器抽到结构化块能被精准引用。信息架构那篇从“稀缺度”的角度讲过差异化,本文的可读性可以视作差异化能否被读到的载体——稀缺信息读不动还是等于零。
怎么衡量自己的可读性改造起没起作用?
不要单看跳出率。跳出率本身被太多东西干扰(页面加载失败、点错链接、来源渠道质量),单看一个指标很容易得出错误结论。要看序列指标。
三段序列:到达、读完、不返回
第一段,到达:曝光(GSC impressions)×点击率(GSC CTR)→ 进站会话数(GA4 sessions)。这一段反映的是title和description的可扫性,不是正文可读性。
第二段,读完:平均停留时长(engagement duration)×滚动深度(GA4自定义事件)。这一段才是可读性改造的主战场。
第三段,不返回:pogo率(用GSC的Position波动间接推断)×延伸点击率(GA4内部跳转事件)。这一段反映任务完成度。
GSC + GA4配对怎么搭
| 序列段 | 主要数据源 | 关键指标 | 注意事项 |
|---|---|---|---|
| 到达 | GSC + GA4 | CTR、sessions | 分品牌词与非品牌词,否则会被品牌流量稀释 |
| 读完 | GA4 + 滚动事件 | engagement duration、scroll depth | 排除10秒以下的“滑一下就走”样本 |
| 不返回 | GSC + GA4 | session events、内部跳转 | 不要把pogo和正常关闭混在一起 |
和排名监测的边界
排名波动是另一回事,用户行为信号那篇从信号反推算法的角度讲了13维信号;本文是从“怎么写出能让用户读完”的页面工程角度,两件事配套使用。
不该看的虚荣指标
- 页面PV:被首页推荐位置影响巨大,跟可读性关系不直接。
- 分享数:分享行为多半发生在“看到结论但没读全文”的场景,跟可读性反相关。
- 评论数:评论行为偏争议性内容,跟可读性不一定正相关。
- 外链增长:外链生成跟资产稀缺度强相关,跟可读性弱相关。
- 关键词排名涨:可能是算法更新引起的,归因到可读性是把相关当因果。
- “感觉读起来很顺”这种主观判断:主编一个人的感受不等于10万用户的中位感受。
有家做跨境母婴电商的客户站,前年改完可读性之后内部很兴奋,因为“团队读起来顺多了”。但GA4里平均停留时长只动了4秒、滚动深度没动,转化率反而掉了。原因是改写时把品类详情页里的“适用月龄、安全认证、成分表”三块全部段落化扁平化,破坏了买家做决策时需要的对照查询能力。最后把这三块改回表格(一开始就该是表),转化率回升15%。
可读性整改的最小启动顺序是什么?
很多团队做可读性改造一开始就要“全站改写”,野心大、动手晚,半年也没改完一篇。务实的最小启动顺序是这样的:
第一周:诊断而不改
挑出主流量Top 20页面,跑四条粗指标(段长P75、句长P90、HSK 5级以上词占比、嵌套从句深度)。同时打开GA4看这20页的engagement duration和scroll depth,按“流量×停留偏低”交叉排序,圈出最该改的5-8页。这一周不要动任何稿子,只看诊断。
第二周:改一页打样
从那5-8页里挑一页流量最大的,按本文的扫描线密度、段长、答案前置、术语翻译四件事改一遍。改完之后不要上线,先用A/B测试工具或者直接放在staging环境,让团队内部5个人扫一遍,看能不能在30秒内找到结论。能找到再上线。
第三到四周:观察并扩到全批
打样页上线后等2-3周,看GA4里这页的engagement duration和scroll depth有没有动。这两个指标都涨了再把改写流程扩到剩下的4-7页。这一步如果偷懒、不等数据直接全批改写,万一改写方向错了你会一次性损失8页的流量。
第二个月起:建立写作规范
把打样和扩批跑通后,把改写要点写成一份写作规范(包含段长上限、扫描线密度经验值、答案前置模板、术语翻译规则、H层级密度建议),让所有新写的稿子从源头就达标。新稿子达标的成本是改老稿的1/5甚至1/10。
从第三个月起:做反馈环
每个月跑一次诊断脚本,把全站可读性指标的分布画成散点图。新进来的内容如果偏离规范,触发回写。反馈环跑通了之后,可读性就从“项目”变成了“日常”,不再需要专门组织战役。
可读性和转化率到底是什么关系?
这条问题电商类客户问得最多。简单结论是:正相关,但不是单调线性。
低可读性段:拉一点可读性能拉一票转化
从“惨不忍睹”到“能读懂”这一段,可读性每提升一档,转化率几乎线性上升。原因是低可读性的页面让用户根本看不完关键决策信息(产品成分、规格、保修),看不完就关掉,没机会到加购环节。
中可读性段:可读性涨、转化率不一定涨
到了“能读懂”之后,再拉可读性,转化率的边际收益递减。这一段的瓶颈不再是“能不能读完”,而是“相不相信”——E-E-A-T信号、案例真实感、社会证明这些。继续拉可读性会进入“好读但不可信”的尴尬带。
高可读性段:可读性过头会反向拉低转化率
这一段也是反直觉的。极致可读(小学生体、所有专业词都翻译成大白话、所有数字都用比喻替代)会让专业买家觉得“这家不专业”,反而不下单。我见过的两次极端反例都发生在ToB领域:一家工业设备站、一家企业SaaS。前者把所有技术参数表都改成“小白能懂”的描述段落,专业采购看一眼就走了。后者把所有技术文档都加“通俗解释”,开发者社区直接讥讽“这家是不是不懂技术”。
找最佳带的方法
没有公式,但有一个粗糙的判据:你的目标用户是谁。如果是C端消费品(家居、美妆、母婴、休闲服装),可读性可以拉得很高;如果是B端专业品(工业设备、企业SaaS、医疗器械、专业服务),可读性应该控制在“专业从业者读起来舒服”这个带,不要再往下拉。本工程另一篇讲过差异化稀缺度的机制,本文的可读性是稀缺度能被读到的载体——读不动就等于零。
常见问题解答
可读性到底算不算Google的排名因子?
不算直接打分项,但通过用户行为序列(读完/不返回SERP/延伸点击)反向喂回排序信号,所以工程上必须当成排名相关问题处理,而不是文风口味。
中文站能直接套Flesch阅读年级公式吗?
不能。Flesch建立在英文音节与句长之上,中文音节计算和句法都不一样,照搬会把内容引到“小学生体”陷阱反而拉低专业感。优先用中文HSK词频、句长分布、自定段长三组粗指标做校准。
段落长度是不是越短越好?
不是。工程下界是单段≤200中文字符,但≥2个独立论点才拆段;单点段不要硬切,复杂论证段保持完整,否则会出现“短句癌”和逻辑碎片。
每页该放多少条扫描线?
经验值是每3-4段出现一条扫描线(H3、列表、表、blockquote、strong任一条算一条)。低于这个密度移动端读者会“滑爆屏”跳出;高于这个密度会变成杂志拼版,机器和人都抓不到主干。
首屏前150字到底要写什么?
写答案前置,不要写综述。F型阅读模式下用户首屏只扫前几行;首屏丢答案,第二屏的人数会衰减到首屏的35%以下。把结论提前是用最小代价把跳出率压下来。
为可读性砍专业内容会不会掉权威?
会,但根源不是“可读”,是把术语翻译当成删机制。正确做法:术语首现一句白话翻译,第二次起原样用;保留所有反直觉结论、机制和数据,只动叙述节奏与句子结构。
AI抽取友好和人读友好能不能一起优化?
大体一致,少数不同。一致:结论前置、段落短、列表化、H层级清晰。不同:AI不需要开篇钩子和叙事腔,人需要。折中是把钩子放在TL;DR之前的开篇段(人读专享),主体写结构化块(AI抽取专享)。
怎么知道改完可读性起没起作用?
看三段序列指标,不要单看跳出率:到达(曝光×CTR)→读完(停留时长×滚动深度)→不返回SERP(pogo率/延伸点击)。三段中任意一段没动说明改在了错的层。
权威参考资料
本文标题:《网页可读性怎么影响SEO?扫描性机制与8层级实战》
本文链接:https://zhangwenbao.com/readability-scannability-seo-mechanism-engagement.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0