搭一套SEO监控告警体系,在掉量前抓住事故
本文目录
- 为什么SEO事故,总是等掉得很惨了才被发现?
- SEO事故的两个特点:渐进、无声
- 人工巡检为什么必然漏?
- 监控和“看仪表盘”,是一回事吗?
- 仪表盘是被动的,监控是主动的
- 监控的核心动作是“设告警”不是“看数字”
- 一个SEO监控体系该盯住哪些信号?
- 抓取层:搜索引擎还进得来吗?
- 索引层:你的页面还在索引里吗?
- 排名与流量层:用户还能找到你吗?
- 页面健康层:页面本身还健康吗?
- 内容与外链层:你的资产还在吗?
- 每个信号的告警线,该怎么定?
- 先建基线,再谈阈值
- 四种阈值,按指标性格挑
- 阈值要随业务校准,不是定完就不管
- 告警怎么分级,才不会变成狼来了?
- 四个告警等级
- 每级配什么渠道、什么响应时限
- 监控体系用什么搭?要不要一步到位?
- 数据从哪来
- 从手动到自动,分三个阶段走
- 自建脚本还是买现成的?
- 告警疲劳,是监控体系的头号杀手
- 误报为什么会累积成灾
- 治理告警疲劳的几个手法
- 收到告警之后,怎么从信号查到根因?
- 第一步:先确认是真事故还是数据问题
- 第二步:按层级从下往上排查
- 第三步:把这次事故反哺回监控体系
- 不同规模的站,监控该做到什么程度?
- AI搜索时代,要新增哪些监控项?
- AI爬虫的抓取情况
- AI引用的得失
- 一次改版翻车,怎么让一个站补上了监控这一课?
- 第一次改版:掉了三成流量,两个月后才发现
- 补课:给改版这种高风险动作装哨兵
- 第二次改版:告警当晚就响了
- 把监控从“项目”变成“习惯”
- 常见问题解答
- 小网站有必要搭SEO监控体系吗?
- 监控和做个数据仪表盘有什么区别?
- 告警阈值到底该定多少?
- 怎么避免监控告警太多、最后没人看?
- 流量掉了,监控告警却没响,是哪里出问题了?
- AI搜索时代,监控体系要大改吗?
- 权威参考资料
摘要:SEO出事故,几乎从不“砰”一声砸下来,它是渐进的、无声的——等你靠肉眼发现流量不对劲,往往已经掉了两三个月。靠人定期巡检看仪表盘根本兜不住。真正管用的是一套监控告警体系:给抓取、索引、排名、流量、页面健康这几层各设基线和阈值,异常自动报警、分级推给该负责的人。监控的核心动作不是“看数字”,是“设告警”。
问一个问题:如果你的网站今天出了一个会慢慢吃掉三成自然流量的技术问题,你大概多久会发现?很多人给的答案是“流量掉下来我就知道了”。但流量这东西,平时本来就有波动,今天比昨天少一点、这周比上周低一截,太正常了。等到某天你终于觉得“好像不太对”,回头拉曲线一看,下滑其实从两个月前就开始了。这两个月,问题一直在,没人按响过警报。
这就是SEO事故最折磨人的地方——它不像服务器宕机,宕机是“砰”一声、所有人立刻知道;SEO事故是渐进的、无声的,它给你一段长长的、毫无知觉的下滑期。这篇要讲的,就是怎么给这种“无声的下滑”装上警报:一套SEO监控与告警体系该盯哪些信号、告警线怎么定、怎么分级、用什么搭、又怎么不让它变成没人理的噪音。
为什么SEO事故,总是等掉得很惨了才被发现?
要搭监控,先得理解你在防的这个敌人长什么样。SEO事故和别的线上事故,性格很不一样,这个差别决定了为什么“人盯”这个办法注定失效。
SEO事故的两个特点:渐进、无声
第一个特点是渐进。一个技术失误——比如改版时不小心给一批页面加上了禁止索引的标记——它的影响不会当天爆发。搜索引擎要重新抓到这些页面、重新处理、把它们移出索引,这个过程要好几周。流量是跟着索引一点点漏掉的,曲线上看就是一条缓坡,不是悬崖。缓坡最骗人,因为它每一天的跌幅都小到可以被解释成“正常波动”。
第二个特点是无声。服务器出问题,监控系统会报错,用户会投诉,错误日志会刷屏。但SEO事故里,你的网站对访客可能完全正常——页面打得开、下单走得通、客服没接到任何抱怨。出问题的是“搜索引擎怎么看你”,而搜索引擎不会打电话通知你。它默默地少抓了你、少收录了你、把你往下挪了几位,整个过程没有一丝声响。渐进加无声,等于一个能潜伏很久的慢性病。
人工巡检为什么必然漏?
面对慢性病,很多团队的办法是“定期检查”——安排人每周或每月把GSC、把分析工具翻一遍。这个办法的出发点是好的,但它有三个绕不过去的漏洞。
一是频率永远不够。你每周看一次,事故就有最多七天在黑暗里发酵;你每月看一次,那就是一个月。而前面说了,渐进式下滑每一天的迹象都很微弱,看的间隔越长,越容易被当成波动放过。二是注意力会漂移。人巡检的时候,盯的是“今天我想看的那几个数”,那些不在视线里的指标——某个角落的抓取错误数、某类页面的收录量——常年没人看。事故偏偏最爱从没人看的角落开始。三是没有基线,人脑对“正常范围”的记忆是模糊的,今天这个数到底算不算异常,全凭感觉,感觉是会骗人的。
结论很直接:靠人按时去“看”,防不住一个渐进、无声、还专挑冷门角落下手的敌人。你需要的不是更勤快的人,是一套不知疲倦、不会漂移、有明确基线的系统。
监控和“看仪表盘”,是一回事吗?
这里要先掰开一个最常见的误解。很多人说“我们有监控”,你一问,其实是“我们做了个仪表盘”。仪表盘和监控,是两件事。混淆这两者,是监控体系建不起来的头号原因。
仪表盘是被动的,监控是主动的
仪表盘的工作方式是“等你来看”。它把数据画成好看的图,挂在那里,你想起来了、有空了,就打开瞄一眼。它的有效性,完全取决于“有没有人去看、看得够不够勤、看的人够不够敏感”。换句话说,仪表盘把“发现问题”这件事的责任,又推回给了那个会漂移、会偷懒、没有基线的人脑。它没有解决问题,只是把问题包装得漂亮了一点。
监控的工作方式正相反——它“主动来找你”。监控系统自己一直在看数据,一旦某个指标越过了预设的线,它主动发出动作:发一条消息、推一个通知、亮一个红灯。在一切正常的时候,一个好的监控系统应该是安静的,你感觉不到它存在;只有出事的时候,它才出声。仪表盘是“你去找问题”,监控是“问题来找你”,方向完全相反。
监控的核心动作是“设告警”不是“看数字”
所以搭监控体系,真正的工作量不在“把数据接进来画成图”,而在“为每一个值得盯的指标,定义出什么情况算异常、异常了通知谁”。这个“定义异常并触发通知”的规则,就是告警。一套监控体系的质量,不取决于它的图有多炫,取决于它的告警规则定得准不准。
这也意味着,你完全可以有一个朴素到只有几行数字、毫不好看的监控系统,但它每条数字背后都挂着一条告警规则——这样的系统,比一个有二十张精美图表、却一条告警都没设的仪表盘,有用得多。先把这个观念扭过来:你要建的是告警,不是图表。图表是给你出事后排查用的,告警才是替你站岗的。
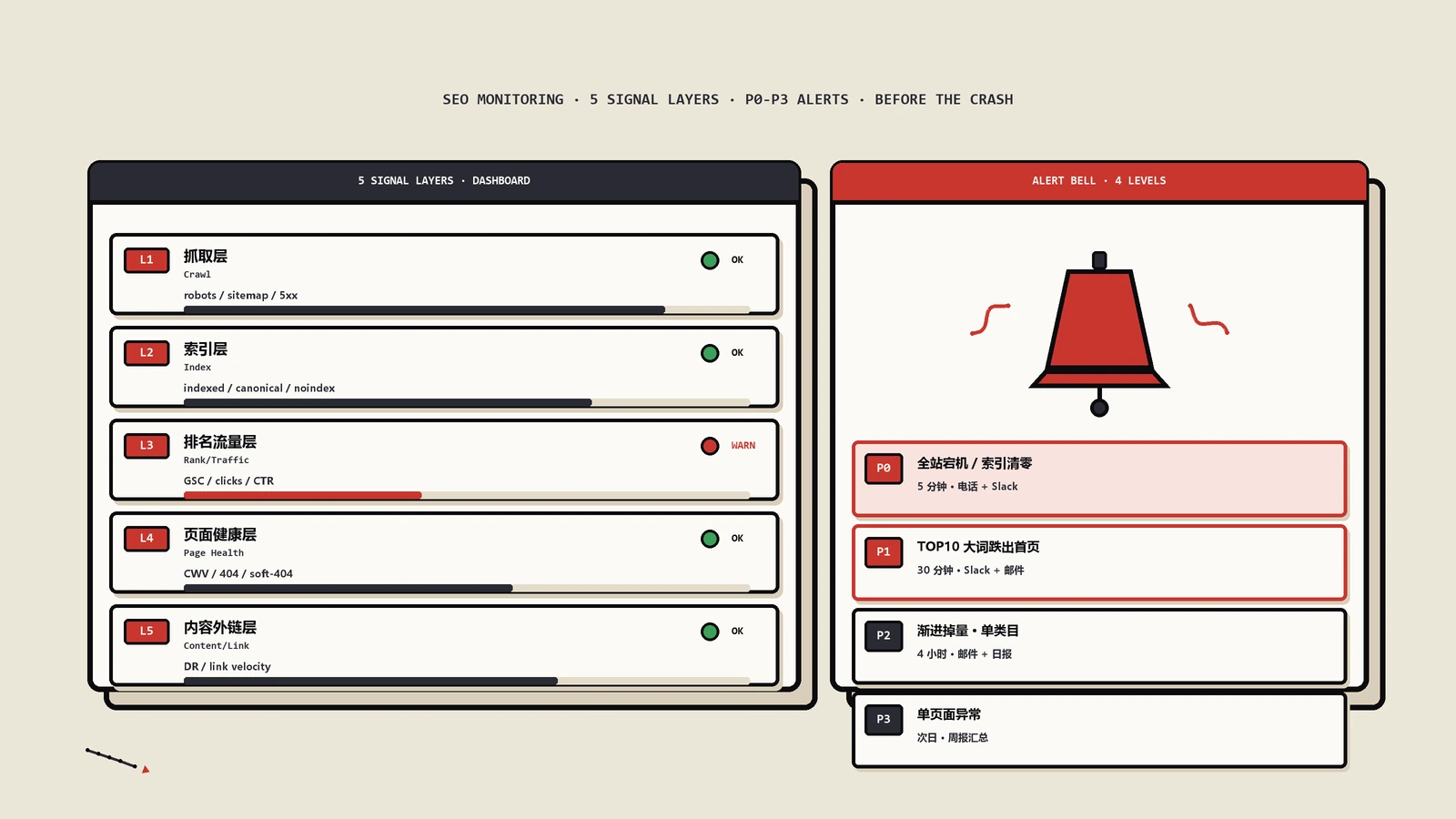
一个SEO监控体系该盯住哪些信号?
明确了要设告警,下一个问题是:给什么设?SEO的链条很长,从搜索引擎来抓你、到用户最终点进来,中间要过很多关。监控要做的,是在这条链上分层布岗,每一层都有哨兵。
抓取层:搜索引擎还进得来吗?
这是最底层,也是最容易被整段忽略的一层。监控项包括:robots文件能不能正常访问、内容有没有被意外封禁,sitemap文件可不可达、里面的URL数对不对,服务器返回给爬虫的状态码里5xx错误的比例,以及爬虫每天抓取的页面量有没有突变。抓取层一旦出问题——比如robots被误改、服务器频繁给爬虫5xx——影响是全站性的、最致命的,所以这一层的告警优先级最高。
索引层:你的页面还在索引里吗?
抓取之上是索引。监控项是:被收录的页面总数,索引覆盖报告里各类状态的数量变化,尤其是“已抓取未编入索引”“已发现未编入索引”这类异常状态的页面数有没有激增,以及关键页面有没有从索引里掉出去。收录数的“缓慢流失”,是渐进式事故最典型的早期信号,这一层必须有哨兵。
排名与流量层:用户还能找到你吗?
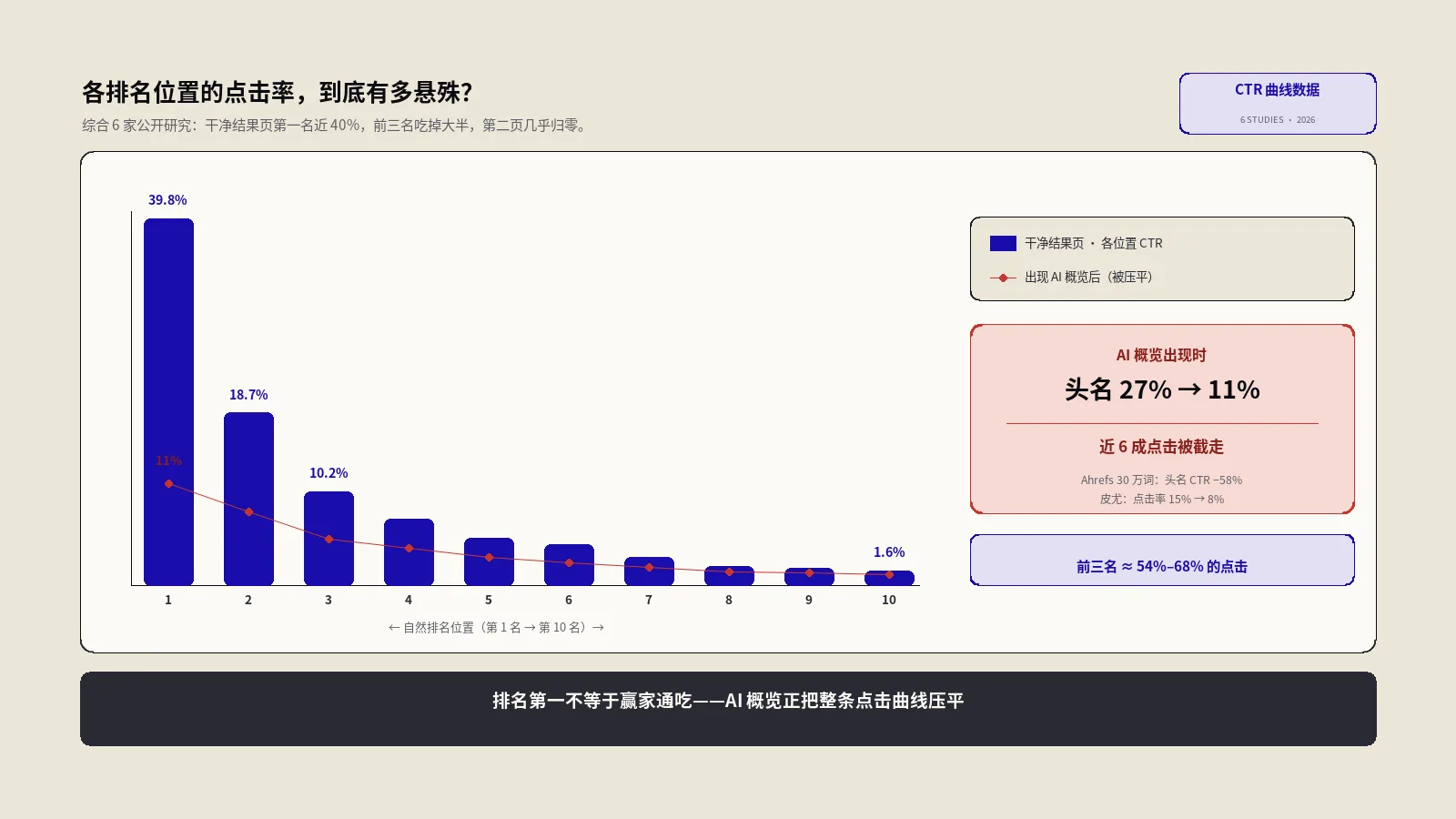
再往上是排名和流量。排名层监控核心关键词的位置、整体的可见度——排名数据本身有采样频率和噪声的问题,怎么采才既省钱又可靠,是排名追踪的采样设计那篇专门讲的事;流量层监控自然搜索流量的总量、以及流量在不同落地页、不同页面类型上的分布。这里有个要点:不要只监控“总流量”这一个数。总流量是高度聚合的,一个角落的塌方会被其他地方的平稳掩盖掉。要监控“分组后的流量”——按页面类型分、按目录分,某一组突然塌了,总数还没怎么动,但分组监控能第一时间抓到。
页面健康层:页面本身还健康吗?
这一层盯的是页面的技术健康度:核心网页指标这类体验数据有没有恶化,新出现的404数量,重定向有没有形成链条或死循环,结构化数据的有效性——有没有一批页面的富结果标记突然报错。页面健康层的问题通常不会一夜之间搞垮全站,但它会持续地、温水煮青蛙地拖你的后腿。
内容与外链层:你的资产还在吗?
最上面一层,盯的是“资产被动了”。内容方面:关键页面的内容有没有被人误删、误改,标题这些关键标签有没有被改动。外链方面:指向你重要页面的高价值外链有没有丢失。这一层对内容站和电商站尤其重要——一个带来大量流量的页面被某个同事在不知情的情况下改了或下了,没有监控的话,你可能永远不知道流量是怎么没的。
| 监控层 | 核心监控项 | 典型事故 | 告警优先级 |
|---|---|---|---|
| 抓取层 | robots可达性、sitemap、5xx比例、抓取量 | robots误封、服务器频繁5xx | 最高 |
| 索引层 | 收录页数、索引覆盖状态、关键页是否在索引 | 批量页面被移出索引 | 高 |
| 排名与流量层 | 核心词排名、可见度、分组后的自然流量 | 核心词集体下滑、某类页面塌方 | 高 |
| 页面健康层 | 核心网页指标、新增404、重定向链、结构化数据有效性 | 富结果批量失效、重定向死循环 | 中 |
| 内容与外链层 | 关键页内容与标签变更、重要外链存活 | 高流量页被误改误删、关键外链丢失 | 中 |
每个信号的告警线,该怎么定?
布好了岗,每个哨兵还得知道“看到什么程度该喊”。喊得太早,全是误报;喊得太晚,等于没喊。这条线怎么定,是监控体系最需要手艺的部分。
先建基线,再谈阈值
所有告警线的前提,是先有“基线”——这个指标在正常情况下,长什么样。基线不是一个固定的数,它包含三样东西:正常的中枢水平、正常的波动幅度、以及正常的周期规律(比如多数网站工作日和周末的流量天然不同,月初月末也可能有别)。没有基线,你定的任何阈值都是拍脑袋。所以搭监控的第一步不是设告警,是先采集够长一段时间的历史数据,把每个指标的基线摸出来。指标的口径、什么算一次干净的数据,本身也要先理清楚,这部分可以参考SEO指标层与口径治理那篇,口径不统一,基线就是错的。
四种阈值,按指标性格挑
有了基线,阈值有四种定法。第一种是绝对线:某个指标低于(或高于)一个写死的数就报警,适合那些有明确红线的项,比如5xx错误比例超过某个百分点。第二种是波动带:以基线为中,正常波动幅度为上下沿,跌破下沿就报警,适合流量这种天天波动的指标。第三种是同比:和上周同一天、去年同一时段比,适合有强周期性的指标,能避开周末效应、季节效应。第四种是分组对比:同一类页面里大多数表现平稳、唯独一组异动,就报警,特别擅长抓“局部塌方”。
| 阈值类型 | 怎么判异常 | 适合的指标 |
|---|---|---|
| 绝对线 | 越过一个写死的数值 | 5xx比例、404数量等有明确红线的项 |
| 波动带 | 跌出基线上下正常波动范围 | 自然流量、抓取量等天天波动的项 |
| 同比 | 对比上周同日、去年同期 | 有强周末或季节周期的指标 |
| 分组对比 | 同类里多数平稳、个别组异动 | 分页面类型、分目录的流量与收录 |
阈值要随业务校准,不是定完就不管
阈值不是一次定死的。业务在变——你做了一次大促、上了一批新页面、赶上了行业淡旺季——基线会跟着移。如果阈值不跟着校准,你会在旺季被一堆“流量暴涨”的告警烦死,在淡季又对真正的下滑无动于衷。所以阈值要定期回看:过去这段时间,告警里有多少是真事故、多少是误报?误报多了,说明阈值太敏感,该放宽;如果出了事故却没报警,说明太迟钝,该收紧。阈值是个需要持续喂养的活物。
告警怎么分级,才不会变成狼来了?
所有告警都用同一种方式、同样的紧迫感推送,是新手监控体系最常见的死法。一个“某页面富结果标记失效”的小问题,和一个“全站抓取量归零”的灾难,如果用同一个红色感叹号、推给同一群人,结果就是——重要的和不重要的混在一起,时间一长,所有人对所有告警都麻木。告警必须分级。
四个告警等级
保哥惯用的是四级。最低是“信息级”:有点异动,但不一定是问题,记录下来即可,不打扰任何人。然后是“警告级”:确实偏离了正常,需要有人看一眼、判断一下,但不紧急,可以当天内处理。再上是“严重级”:明确的事故正在发生,影响在扩大,需要当天立刻有人介入。最高是“紧急级”:全站性的、流量在大块大块掉的灾难,需要立刻、不分昼夜地响应。
每级配什么渠道、什么响应时限
分级的意义,在于每一级配不同的“吵闹程度”。信息级只进日志,没人会被打扰。警告级进一个团队群或一封汇总邮件,大家有空时会看到。严重级要点对点推送给具体负责人,确保当天被看到。紧急级则要用能把人从睡梦里叫醒的方式——电话、强提醒——并且要有一条“升级路径”:第一个人在约定时间内没响应,自动通知第二个人。等级、渠道、响应时限、责任人,这四样一一对应钉死,告警体系才算有了纪律。
| 等级 | 含义 | 推送渠道 | 响应时限 |
|---|---|---|---|
| 信息级 | 有异动,未必是问题 | 只进日志 | 无需响应 |
| 警告级 | 偏离正常,需判断 | 团队群、汇总邮件 | 当天内看一眼 |
| 严重级 | 事故正在发生且扩大 | 点对点推送给负责人 | 当天立即介入 |
| 紧急级 | 全站性、大块掉量的灾难 | 电话、强提醒、带升级路径 | 立即、不分昼夜 |
监控体系用什么搭?要不要一步到位?
讲到工具,很多人就卡住了,觉得搭监控是个大工程,要写一堆代码、要买贵的平台。其实不必。监控体系最该避免的就是“想一步到位”——一步到位的计划,通常的下场是永远停在计划阶段。
数据从哪来
SEO监控的数据源主要有几个:搜索引擎的站长工具(抓取、索引、排名、富结果数据都在这里,而且大多提供接口,可以自动取,关于它本身怎么用可以看站长工具完整诊断指南);网站分析工具(自然流量、落地页、用户行为);第三方SEO工具(核心词排名、外链存活);以及服务器日志(最真实的爬虫抓取行为)。监控体系做的事,就是定时从这些源头取数、和基线比、超线就告警。
从手动到自动,分三个阶段走
不要一开始就追求全自动。比较稳的路径是分三阶段。第一阶段,半手动:用一张固定的检查清单,每周固定时间、由固定的人,把上面那几层信号过一遍,并把数字记进一个表格——这一步的价值是先把“该看哪些、正常值是多少”跑顺,把基线攒出来。第二阶段,半自动:把最关键、最致命的那几个信号(抓取层、索引层)先用脚本接上接口自动取数、自动判阈值、自动发告警,其余的还靠手动。第三阶段,自动化:把成熟的监控逻辑沉淀成定时任务,纳入一套有纪律的工程流程里持续运行——这一步和SEO工作的整体工程化是一回事,可以参考SEO自动化的工程化架构,本文讲的是“监控什么、怎么告警”,那篇讲的是“怎么把它做成跑得久的工程”,两者搭着看。
自建脚本还是买现成的?
判断标准是站点规模和团队能力。小站和没有开发资源的团队,优先用现成工具的内置告警功能——很多SEO工具、分析工具本身就带阈值告警,配一配就能用,没必要自己造。有一定规模、有开发能力的团队,核心信号值得自建脚本,因为自建的告警逻辑可以完全贴合你自己的业务节奏和页面分组,比通用工具的告警更精准。多数团队的现实选择是混合:通用的项用现成工具,业务特异性强的项自建,两者并存。
告警疲劳,是监控体系的头号杀手
一套监控体系,最后通常不是死于“没搭起来”,而是死于“搭起来了,但所有人都把它静音了”。这个慢性死法有个名字,叫告警疲劳。它值得单独拎出来讲,因为它太隐蔽——体系看着还在运行,实际上已经没人理了。
误报为什么会累积成灾
告警疲劳的根源是误报。一套新上线的监控,阈值多半定得偏敏感,于是它频繁地为一些根本不是问题的波动报警。头几次,大家还认真去看;看了几次发现都是虚惊,第四次、第五次,人就开始扫一眼标题就划掉;再往后,干脆设置了免打扰。问题是,等到某天那条告警是真的,它也一起被划掉了。一套天天喊狼来了的监控,比没有监控更危险——因为它给了你一种“我有监控”的虚假安全感。
治理告警疲劳的几个手法
治理它有几个实在的手法。一是认真做分级,把绝大多数不紧急的项压到信息级和警告级,别让它们去打扰人,把“会响”的名额留给真严重的。二是定期回看误报,每过一段时间统计告警的真假比例,对那些常年误报的规则,要么放宽阈值,要么改判定逻辑。三是做告警合并和静默窗口:同一个根因引发的一连串告警,合并成一条;已知的、正在处理的问题,开一个静默窗口,别让它在解决前反复刷屏。四是给每条告警规则一个明确的“主人”,没有主人的告警规则,是误报的温床,定期清理。监控体系要像花园一样持续修剪,不修剪,它就长成没人愿意进的杂草地。
收到告警之后,怎么从信号查到根因?
告警响了,只是开始。告警告诉你的是“某个指标不对劲”,不是“哪里出了问题”。从“信号”到“根因”,中间还有一段排查路要走。有章法地走,比慌乱地乱翻快得多。
第一步:先确认是真事故还是数据问题
收到告警,先别急着改网站。第一件事是确认这个告警本身是不是真的。有相当一部分“流量暴跌”告警,根因是数据侧——分析工具的统计代码被某次发布弄掉了、数据接口当天抽风、口径被人改了。判断方法:如果是真的SEO事故,多个独立数据源会互相印证(站长工具的点击在跌、分析工具的会话也在跌、服务器日志的爬虫量也在变);如果只有单一来源的某一个数在跌、别的源都正常,那大概率是这个数据源自己的问题。先排掉数据问题,能省下大量往错误方向排查的时间。
第二步:按层级从下往上排查
确认是真事故后,沿着前面那五层,从最底层往上查。先查抓取层:爬虫还进得来吗、robots和服务器状态正常吗?抓取层没问题,再查索引层:页面还在索引里吗、有没有批量掉出?索引层没问题,再往上查排名、查页面健康、查内容外链有没有被动过。之所以从下往上,是因为底层的问题会向上传导——抓取断了,索引、排名、流量必然跟着出问题;反过来,流量掉了却不一定是抓取的锅。从地基往上查,能最快地把范围收窄到真正的那一层,避免在表层的流量数字上空转。
第三步:把这次事故反哺回监控体系
排查完、修复完,还有最后一步,也是最多人省略的一步:回头问一句,这次事故,监控体系为什么没能更早抓到它?如果是某一层压根没设哨兵,那就把这层补上;如果是设了、但阈值太迟钝没触发,那就把阈值收紧;如果是告警其实响了、却被淹没在一堆误报里没人看,那要治理的是告警疲劳。每一次真实事故,都是对监控体系最好的一次校准机会——它用真金白银的代价,告诉了你这套体系的某个具体漏洞在哪。把这个漏洞补上,下一次同类事故就会被提前拦住。一套会从事故里学习、不断长出新哨兵的监控体系,才是活的;一套定完就不再变的监控,迟早会被新的事故绕过去。
不同规模的站,监控该做到什么程度?
监控体系不是越重越好,它要和站点的规模、团队的能力匹配。给一个三五个人的小站套一套大厂级的监控,结果一定是建不起来或者没人维护。按规模分档,量力而行。
| 站点规模 | 监控重点 | 建议做法 |
|---|---|---|
| 小型站(个人、小团队) | 抓取层、索引层、总自然流量 | 固定每周手动检查清单,加站长工具自带的邮件告警 |
| 中型站(有专职SEO、少量开发) | 五层全覆盖,流量按页面类型分组 | 关键层自建脚本自动告警,其余用现成工具,做告警分级 |
| 大型站(电商、内容平台) | 五层全覆盖且分组精细,加内容外链变更监控 | 自动化监控纳入工程流程,完整分级与升级路径,专人维护阈值 |
这张表的用法不是对号入座、照抄了事,而是给你一个起点。哪怕你是最小的站,至少要守住抓取层和索引层这两道底线——它们最致命,而站长工具的自带告警几乎零成本就能配上。监控体系可以从简陋开始,但不能从“没有”开始。
AI搜索时代,要新增哪些监控项?
传统那五层监控,在AI搜索时代依然成立、依然是地基。但确实有几个新的监控项,值得加进体系里。
AI爬虫的抓取情况
除了传统搜索引擎的爬虫,现在还有一批AI公司的爬虫在访问你的网站——有的是为训练模型抓取,有的是在用户提问时实时来取内容。这些爬虫的访问,会清清楚楚地记在你的服务器日志里。值得新增一个监控项:这些AI爬虫有没有被你的防火墙或防爬策略误伤、被挡在门外。如果你的内容被AI引用的前提是它能抓到你,那么“AI爬虫进不进得来”就和“传统爬虫进不进得来”一样,是抓取层该有的哨兵。
AI引用的得失
另一个新监控项,是你的品牌、你的内容在AI答案里的出现情况。这件事比传统排名难量化得多——AI答案没有一个稳定的“第几名”,同一个问题问两次答案都可能不同。但你至少可以定期、用一组固定的核心问题去问主流的AI引擎,记录你有没有被提及、被引用,做成一条粗粒度的趋势线。它做不到传统排名监控那样精确,但能帮你及时发现“我在AI答案里整体在变得更可见还是更隐身”这个大方向。这一层目前还粗糙,但值得现在就开始攒数据。
关于这两个新监控项,有个心态上的提醒。它们目前的精度,远不如传统五层那么成熟——AI爬虫的标识在变、AI答案的不稳定性很高,你很难给它们设出像5xx比例那样干脆的阈值。所以现阶段对这两项,更现实的定位是“观察”而非“严格告警”:把它们放在信息级或警告级,定期看趋势,而不是指望它们像抓取层告警那样精准触发。但越是早期、越是粗糙,越值得现在就开始记录——等AI搜索的份额再涨一截,你手里这条从今天就开始攒的趋势线,会比那时候才从零开始的人,多出一段谁也补不回来的历史。监控这件事,最贵的从来不是工具,是时间。
一次改版翻车,怎么让一个站补上了监控这一课?
道理讲再多,不如一个真实的教训有说服力。保哥手上有个做跨境户外装备的独立站客户,这两年踩过一次很典型的坑,又靠监控把第二次同类风险稳稳接住,这一前一后正好把这篇的价值说透。
第一次改版:掉了三成流量,两个月后才发现
这个站前年做过一次比较大的改版,换了前端框架、顺手重做了一部分URL结构。改版上线那天,团队反复点了首页、商品页、下单流程,一切正常,就以为成了。问题恰恰藏在“对用户正常”的背后:改版时,一批商品筛选页的规范标记指错了对象,还有一部分新URL被开发在模板里误加了禁止索引的标记,旧的sitemap也没及时更新、还指着一堆已经不存在的地址。
这些问题,用户一个都感觉不到——页面照样打得开,东西照样买得了。但搜索引擎那边,开始一点点把这批页面移出索引。流量跟着索引,沿着一条不陡的缓坡往下滑。团队当时没有任何监控,全靠每隔一阵打开分析工具瞄一眼,而那条缓坡每天的跌幅,都小到被解释成“最近大盘就这样”。直到两个多月后,有人终于觉得不对劲、认真拉了曲线,才发现自然流量已经掉了三成多,而下滑的起点,精准地落在改版上线那一天。两个多月的损失,全是因为没人、也没有任何东西,在改版之后替他们盯着索引层。
补课:给改版这种高风险动作装哨兵
这次教训之后,这个站才认真补上了监控这一课。他们没有一上来追求大而全,而是按本文说的路径,先把最致命的两层做扎实:抓取层盯robots、sitemap可达性和服务器状态码,索引层盯收录总数、盯“已抓取未编入索引”这类异常状态的页面数,再加上一个按页面类型分组的流量监控。这几项都设了基线和阈值,索引层和抓取层的异常直接定为严重级,点对点推送给技术负责人。
这里有个被反复强调的认知值得记下来:改版、迁移、换CMS这类“高风险动作”,是SEO事故最密集的来源。监控体系平时是常态运行,但在做这类高风险动作的前后,要专门把抓取层和索引层的告警调到最灵敏——因为你明确知道,如果要出事,大概率就在这几天、就在这两层。
第二次改版:告警当晚就响了
补课之后大约半年,这个站又做了一次规模小一些的改版。这一次,剧本完全不同。改版上线当天晚上,索引层的告警就响了:监控脚本发现“已抓取未编入索引”状态的页面数,相比基线出现了明显的异常上涨,同时一类页面的分组收录数在往下走。告警按严重级点对点推给了负责人,当晚就有人去查。
顺着前面讲的“从下往上排查”,很快定位到根因——又是改版时一批页面的规范标记配置出了岔子,和上一次的病根属于同一类。不同的是,这次从问题发生到被定位,只隔了几个小时,而不是两个多月。第二天问题就修复了,搜索引擎还没来得及把页面大批移出索引,流量几乎没受影响。同样的坑,第一次摔得鼻青脸肿,第二次轻轻一脚就迈过去了——中间隔着的,就是一套哪怕只覆盖两层、但真的在站岗的监控。这个案例最值钱的地方不在那几个数字,而在它证明了一件事:监控的回报,往往不体现在它报警的那天,而体现在它替你避免的那场你永远不会知道有多惨的事故里。
把监控从“项目”变成“习惯”
最后说一句心里话。监控体系最难的部分,从来不是技术——设几个阈值、写几个取数脚本,都不难。最难的是把它从一个“做完就放那儿”的项目,变成一个持续被维护的习惯:阈值有人定期校准、误报有人定期清理、新上的业务有人记得加上对应的监控、告警响了有人真的去查。
一套没人维护的监控体系,会以肉眼可见的速度腐烂——阈值过时、告警全是误报、最后被集体静音,和没有它没两样。所以保哥的建议是,从第一天起就给它配一个明确的主人和一个固定的维护节奏,哪怕每月只花半天回看一次。监控的价值,不在你搭好它的那一刻,而在它日复一日替你站岗、在某个你毫无察觉的清晨,替你按响那个本来要两个月后才会发现的警报。那一次,它就把你为它花的所有时间,连本带利还给你了。
常见问题解答
小网站有必要搭SEO监控体系吗?
有必要,但要轻。小站不需要复杂系统,但至少要守住抓取层和索引层这两道底线——robots、sitemap、收录数。最省事的做法是把搜索引擎站长工具自带的邮件告警打开,再配一张每周固定检查的清单。成本几乎为零,却能挡掉最致命的那类全站性事故。
监控和做个数据仪表盘有什么区别?
区别在被动还是主动。仪表盘是你想起来才去看,发现问题靠人盯,会漏、会迟。监控是系统自己盯着数据,越过预设阈值就主动报警找你。正常时它安静,出事时它出声。仪表盘是出事后排查用的工具,监控才是替你站岗的。两者可以并存,但不能用仪表盘冒充监控。
告警阈值到底该定多少?
没有通用数值,阈值必须基于你自己的基线。先采集足够长的历史数据,摸清每个指标正常的中枢、波动幅度和周期规律,再据此设阈值:有明确红线的用绝对值,天天波动的用波动带,强周期的用同比。定完还要定期回看真假告警比例,持续校准。照搬别人的阈值数字基本没用。
怎么避免监控告警太多、最后没人看?
核心是分级加治理。把告警分成信息、警告、严重、紧急四级,只有严重和紧急才点对点打扰人,其余进日志和汇总。然后定期统计误报率,对常年误报的规则放宽或改逻辑,做同根因告警合并和已知问题静默窗口,并给每条规则指定主人。告警体系要像花园一样持续修剪。
流量掉了,监控告警却没响,是哪里出问题了?
通常是两种情况。一是没监控到那一层——比如你只盯了总流量,没做分组监控,某类页面的塌方被其他页面的平稳掩盖了。二是阈值太迟钝,渐进式下滑每天跌幅都没触线。解决办法是补上分组监控,并把核心指标的阈值往灵敏调一档,必要时加同比判定来识别缓坡。
AI搜索时代,监控体系要大改吗?
不用大改,传统的抓取、索引、排名、流量、页面健康五层依然是地基。要做的是新增两项:一是监控AI爬虫有没有被防爬策略误伤挡在门外,这属于抓取层的延伸;二是用一组固定问题定期问主流AI引擎,粗粒度地跟踪品牌和内容被引用的趋势。新增而非推翻。
权威参考资料
本文标题:《搭一套SEO监控告警体系,在掉量前抓住事故》
本文链接:https://zhangwenbao.com/seo-monitoring-alerting-regression-detection-system.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0