Linux服务器怎么用rsync做增量备份和快照才不会把备份玩成灾难?
本文目录
- 备份这件事,为什么Linux上首选rsync?
- 归档模式和排除规则怎么配,才既完整又不冗余?
- 尾斜杠这个细节,为什么能决定备份对不对?
- --delete到底有多危险?怎么用才不翻车?
- 怎么用 --link-dest做出省空间的版本化快照?
- 怎么把备份经SSH安全地同步到异地?
- 带宽、压缩和大文件场景,rsync的性能怎么调?
- 备份脚本怎么挂上定时,让它自己天天跑?
- rsync的退出码和常见报错,怎么读才不抓瞎?
- 不同类型的数据,备份策略要不要区别对待?
- 备份做完就完事了?恢复验证才是真正的终点
- 说到底,为什么镜像不等于备份?
- 常见问题解答
- rsync和直接cp复制文件比,好在哪?
- rsync命令里源路径末尾加不加斜杠,到底有什么区别?
- --delete参数很危险吗?什么时候该用?
- --link-dest做的快照,会不会把磁盘撑爆?
- 用rsync做镜像,能替代真正的备份吗?
- 权威参考资料
TL;DR:rsync是Linux上做备份的瑞士军刀,但它锋利得能割到自己——尾斜杠搞反、--delete用错,分分钟把备份变成事故现场。这篇按"为什么是rsync—归档与排除参数—尾斜杠陷阱—--delete风险—用 --link-dest做版本化快照—经SSH异地同步—定时执行—恢复验证—为什么镜像不等于备份"的顺序,把rsync从能用讲到用得稳。记住一条贯穿全文的话:能恢复的才叫备份,没验证过恢复的备份等于没有。
备份这件事,为什么Linux上首选rsync?
服务器要备份,方法很多,但真正周期性、增量、还能传到异地的场景里,rsync几乎是绕不开的答案。它的核心本事是差量传输:第一次同步是全量,从第二次起,它会比对源和目标,只传输发生了变化的文件,甚至只传一个大文件里改动的那一小段,没动过的全部跳过。
这意味着什么?意味着一个几十GB的网站目录,每天可能只改了几个文件,rsync增量同步几秒就能跑完,而用cp或tar重新打包则要从头来一遍。备份这种天天要做、还不能影响线上性能的活儿,差量传输省下的时间和带宽是决定性的。
除了快,rsync还能完整保留文件的权限、属主、时间戳、软链接这些元数据,能压缩传输,更关键的是能直接经SSH加密通道把数据同步到另一台机器上。这一条让它天然适合做异地备份,而异地正是备份能不能扛住机房级灾难的命门。把这些能力凑齐,你就明白为什么做备份时大家张口就是rsync。
当然rsync不是万能的,得知道它的边界。它擅长的是文件级的同步,对于数据库这种正在被写入的活动数据,直接rsync拷文件可能拿到不一致的状态,正确做法是先让数据库导出一致性的备份文件,再用rsync把这个文件搬走。它也不是版本管理工具,要做多时间点快照得靠后面讲的 --link-dest自己组织。把rsync定位成"高效的搬运和同步引擎",而不是"一条命令解决所有备份问题的银弹",你才能用对它。
但工具越强,误用的破坏力越大。下面这些参数和陷阱,是把rsync用稳的分水岭。
归档模式和排除规则怎么配,才既完整又不冗余?
rsync最常用的起手式是归档模式,也就是 -a 参数。它是一组选项的打包,等于一次性开启了递归子目录、保留软链接、保留权限、保留时间戳、保留属主和属组。一句话,-a 保证你复制过去的东西,和源端在文件属性上尽可能一模一样,这是备份的基本要求——恢复时权限错乱可是大麻烦。
实战里通常再叠几个:-v 打印过程方便看日志,-z 传输时压缩省带宽(异地同步尤其有用),-P 显示进度并支持断点续传。一条典型的本地增量备份长这样:
rsync -avP /var/www/ /backup/www/但全量复制往往不必要。缓存、临时文件、日志、依赖包目录(比如node_modules)这些,要么能重新生成、要么没必要进备份,留着只会撑大体积、拖慢速度。用 --exclude 把它们排除掉,规则多了就写进一个文件用 --exclude-from 引用:
rsync -avP --exclude='cache/' --exclude='*.log' /var/www/ /backup/www/排除清单值得花时间维护。保哥的经验是:备份应该只装"丢了就回不来"的数据,凡是能从代码、依赖、缓存重建的,一律排除。备份不是越全越好,是越精准越好。
顺带说个 -a 里最容易被忽视、却在恢复时要命的细节:属主和权限。保哥见过有人备份时图省事没保留属主,恢复时所有文件都变成了root,结果网站的PHP进程没权限写上传目录、缓存目录,站点起来一半功能是坏的,排查半天才想到是权限在备份恢复里丢了。如果备份和恢复是在不同机器、用户ID对不上,还得考虑 --numeric-ids 按数字ID而非用户名来对应。备份的终极目的是恢复,凡是恢复时需要的元数据,备份时就得原样带上,这也是为什么归档模式几乎是默认起手式。
尾斜杠这个细节,为什么能决定备份对不对?
这是rsync最经典、也最坑新手的陷阱:源路径末尾那个斜杠,加与不加,结果完全不同。
规则是这样:源路径末尾加斜杠,表示"把这个目录里的内容"同步到目标;不加斜杠,表示"把这个目录本身"同步到目标里面去。举例,rsync -a /data/ /backup 是把data目录里的文件直接铺在backup下;而 rsync -a /data /backup 会在backup下面新建一个data子目录,再把内容放进去,变成 /backup/data/。
单看好像只是层级差一层,无伤大雅。但一旦配合 --delete做镜像,差这一层就可能酿成大祸:目标结构和你预期的对不上,--delete就会按"源端没有"的逻辑去删一堆其实该留的文件。这个细节没有捷径,唯一可靠的办法就是养成习惯——任何带 --delete的命令,正式跑之前先用 --dry-run空跑一遍,亲眼确认它要传什么、要删什么,再松手。
目标路径那一侧的斜杠倒是宽容得多,加不加效果一样,真正决定行为的是源路径。所以记忆负担其实只有一句话:盯紧源路径末尾那个斜杠。保哥自己的习惯是把常用的备份命令固化进脚本,斜杠在脚本里写死、测好,就不靠每次手敲时的临场记忆了——人脑会犯错,写对一次、测好、存进脚本,才是把这个陷阱一劳永逸关掉的办法。临时手敲的那种"我应该没记错",恰恰是事故的温床。
--delete到底有多危险?怎么用才不翻车?
--delete是把双刃剑。它的作用是让目标和源保持完全一致——源端删掉的文件,目标端也跟着删。做镜像同步时这是必需的,否则目标会越积越多,留着一堆源端早就删除的废文件。
但它的危险也正在于"忠实"。如果你源路径写错了、敲漏了一个目录名、或者源端因为某种原因变成了空目录,rsync会忠实地认为"源端什么都没有",于是把目标端辛辛苦苦攒的备份全部删光。这种因为 --delete把备份清空的事故,运维圈里听过太多了。
安全使用 --delete有三条铁律。第一,用前必 --dry-run,让它先告诉你会删哪些,确认无误再正式跑。第二,关键数据不要只做镜像,要保留版本化的历史快照,这样即便一次同步出错,也有旧版本兜底。第三,源路径反复核对,尤其是尾斜杠。把这三条做到,--delete才是可控的工具而不是定时炸弹。这也引出了一个更根本的问题:镜像和备份,根本不是一回事。
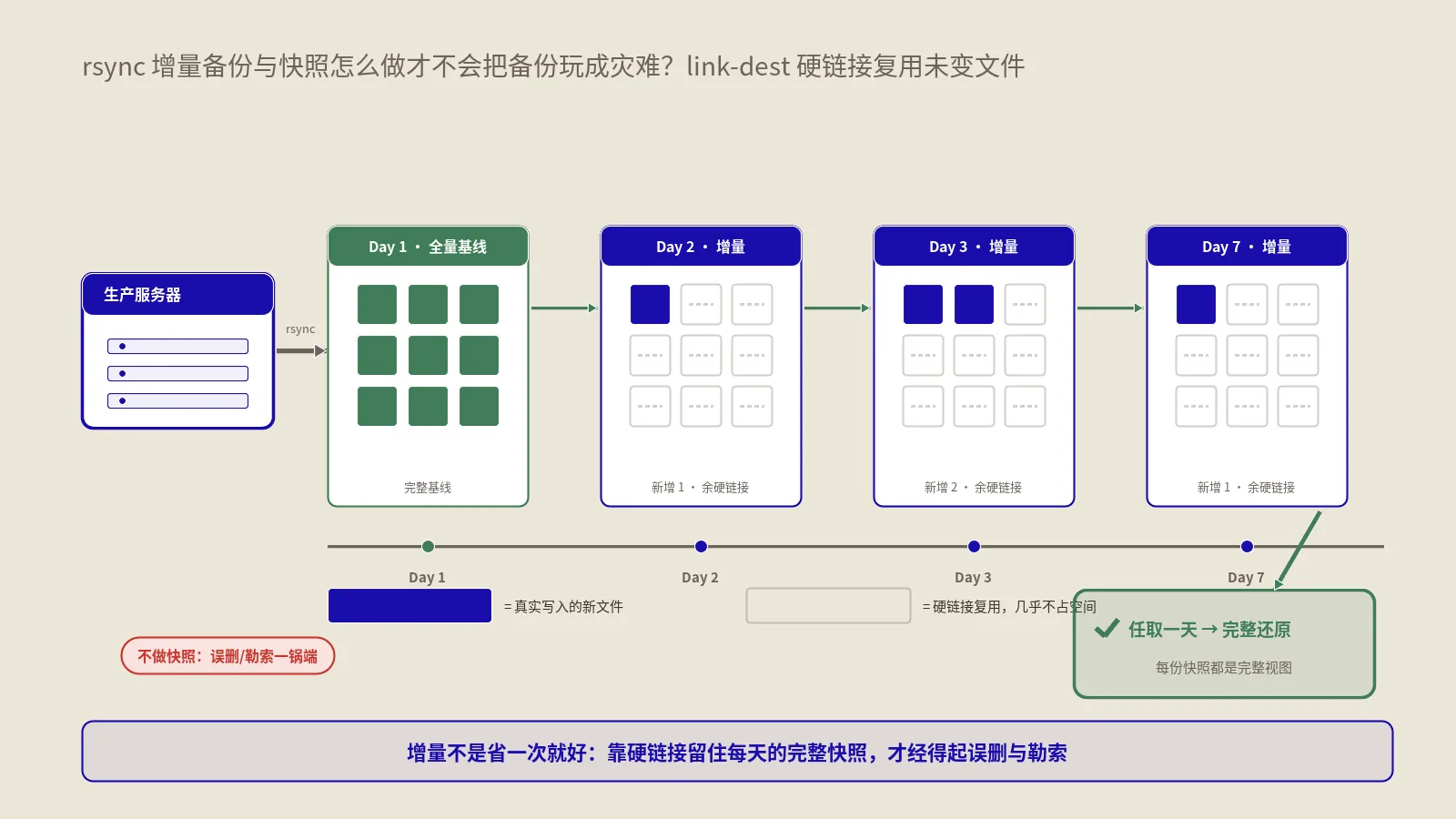
怎么用 --link-dest做出省空间的版本化快照?
前面反复说"要版本化快照",rsync自己就能做,靠的是 --link-dest 这个参数,它能做出类似时间机器那样的多时间点快照,还特别省磁盘。
原理很巧妙:做新一次备份时,用 --link-dest指向上一次的备份目录。rsync会比对,对于没有变化的文件,它不重新复制,而是创建一个硬链接,指向上一次备份里的同一个文件;只有变化的文件才真正复制一份新的。结果是:每一个快照目录看上去都是一份完整、可独立浏览和恢复的副本,但磁盘上没变的文件其实只存了一份。
这样你可以保留每天一个快照,连存一个月,占用的空间却远小于三十份全量副本——因为绝大多数文件天天没变,都共享着同一份物理数据。恢复时随便挑哪一天的快照目录,都是那个时间点的完整状态,干净利落。成熟的快照备份工具大多就是基于这套硬链接机制封装出来的。
用它有个前提要记牢:硬链接要求所有快照在同一个文件系统上,跨磁盘、跨分区、或者某些网络存储上硬链接的行为会不一样甚至不支持。部署前先在目标存储上确认硬链接可用,别等快照建到一半才发现空间没省下来。
实操里通常配一套保留策略来管这些快照:保留最近7个每日快照、4个每周快照、若干个每月快照,老的自动删。删快照时也别慌——因为是硬链接,删掉某个快照目录,只会减少对应文件的一个链接计数,只有当一个文件不再被任何快照引用时,磁盘空间才真正释放。所以删中间某一天的快照,不会破坏其它快照的完整性,每个快照始终是自洽的完整副本。这套"硬链接 + 保留策略"的组合,正是各种成熟快照备份方案的内核,理解了它,你用现成工具时也知道它在背后干什么、出问题时该往哪查。
怎么把备份经SSH安全地同步到异地?
本地备份只能防"文件丢失",防不了"整台机器或整个机房没了"。要扛住机房级灾难,备份必须有一份在异地,而rsync经SSH同步正是干这个的标准做法。
rsync用 -e 参数指定传输通道走SSH,于是数据全程加密传输,还能复用你的SSH密钥认证。一条推到远端备份服务器的命令大致是:
rsync -avz -e "ssh -i /root/.ssh/backup_key -p 22" /backup/www/ backup@10.0.0.9:/data/www/这里和服务器的登录安全直接相关。异地同步建议用专门的密钥、最小权限的备份账户,而不是拿root到处连。把SSH这层配扎实,可以参考Linux服务器SSH登录加固里讲的密钥认证和权限收敛,别让备份通道反而成了入侵的口子。
还有个方向值得选对:拉取(pull)往往比推送(push)更安全。让备份服务器主动去源服务器拉数据,而不是源服务器往备份服务器推。这样即便源服务器被攻陷,攻击者也够不到备份服务器、动不了已有的历史快照,备份的"防篡改"属性就立住了。生产环境里,把备份机做成只进不出的保险柜,是值得的设计。
异地备份用的那把SSH密钥也值得收紧权限。它只需要干"同步备份"这一件事,没必要给它一把能登录、能执行任意命令的万能钥匙。可以给这把密钥限定只能跑rsync、甚至只能访问特定目录,万一密钥泄露,损失也被框在备份这一亩三分地里,不会演变成整台机器被接管。把"最小权限"贯彻到备份通道上,是把备份从潜在的入侵跳板,变回纯粹的安全网。这一步常被人省略,却是异地备份安全性的关键一环。
带宽、压缩和大文件场景,rsync的性能怎么调?
异地同步绕不开网络,本地备份绕不开磁盘IO,rsync有一组参数专门用来在性能和资源之间找平衡,用对了能省一大截时间。
先说压缩。-z 在传输时压缩数据,跨公网、带宽紧张时很值,能显著减少传输量;但压缩要耗CPU,如果是同机房万兆内网、或者备份的本来就是已压缩的文件(图片、视频、压缩包),开 -z 反而是给CPU添堵、拖慢速度。判断标准很简单:瓶颈在带宽就压缩,瓶颈在CPU或本来传得就快就别压。
再说限速。备份往往在生产机上跑,一不留神rsync会把带宽吃满,影响线上服务。--bwlimit 能给它的传输速度设个上限,把备份对业务的干扰摁住。在白天或高峰期跑备份时,限速几乎是必备的礼貌。
大文件场景要特别处理。数据库dump、虚拟机镜像这类几十上百GB的大文件,默认rsync会把改动后的版本当成新文件整体重写,既慢又费空间。这种场景可以考虑 --inplace,让rsync直接在原文件上就地更新改动的块,而不是先生成完整副本再替换。但 --inplace有取舍:它会牺牲一部分原子性和与硬链接快照的兼容性,用之前要想清楚你的快照策略是否依赖那一层。性能调优没有银弹,关键是先搞清楚自己的瓶颈是带宽、CPU还是磁盘,再对症下药。
网络不稳的异地链路还要考虑断点续传。跨公网传几十GB,中途断一次是常事,没有续传机制就得从头再来,既费时又费流量。--partial 会保留已经传了一半的文件,下次接着传而不是推倒重来;配合前面提过的 -P(它本身就含 --partial和进度显示),长距离大数据量的同步才扛得住网络抖动。把这些参数按链路质量配齐,rsync才能在现实里那种并不理想的网络条件下稳稳干活,而不是一遇到波动就前功尽弃。
备份脚本怎么挂上定时,让它自己天天跑?
手动敲rsync做不成可靠备份——人会忘、会请假、会手滑。备份必须自动化,把命令写成脚本,再交给系统定时执行。
最常见的是用cron。把带好参数、排除规则、--link-dest快照逻辑、日志记录的rsync命令封进一个shell脚本,然后用crontab设定每天凌晨低峰期自动跑。cron的时间字段语法、以及systemd timer这个更现代的替代方案,可以直接看Linux定时任务自动化运维那篇,这里不重复。
这里有个cron特有的坑值得单独点出来:cron跑脚本时的环境和你手动登录时不一样,PATH往往很精简、很多环境变量也没有。手动跑得好好的备份脚本,丢进cron就因为找不到某个命令、或者读不到SSH密钥而静默失败,是经典翻车现场。稳妥的做法是脚本里用命令的绝对路径、显式指定密钥文件、把关键环境变量在脚本开头设好,别依赖那个登录时才有的舒适环境。设好之后,一定要等它在cron里真正自动跑一次、确认日志和退出码正常,才算交付,而不是手动跑通就以为万事大吉。
自动化脚本要注意几件事。一是把每次执行的输出和退出码记进日志,别让它默默失败;rsync的退出码能区分是部分文件出错还是整体失败,脚本里要判断。二是给快照目录按日期命名,方便回看和清理。三是设好保留策略,自动删掉超过保留期的老快照,否则磁盘迟早被快照塞满。把这些做进脚本,备份才真正变成"设好就不用管"的后台守护。
rsync的退出码和常见报错,怎么读才不抓瞎?
自动化备份最怕"静默失败"——脚本跑了、cron也触发了,但其实早就报错没传成,等到要恢复才发现备份是空的。要避免这种事,得学会读rsync的退出码和常见报错。
退出码是脚本判断成败的依据。0 是完全成功;非0各有含义,比如有的码表示"部分文件传输出错但整体跑完了"、有的表示"传输中源文件发生了变化"、有的是连接或权限问题。脚本里不能只看"命令跑完了",要拿退出码做判断:完全成功才标记备份OK,部分错误要告警人工看,彻底失败要立刻报警。把退出码接进告警,备份才有了"会喊救命"的能力。
常见报错也有规律。权限类的报错,多半是备份账户对某些文件没有读权限、或目标目录没有写权限,给对权限或用合适身份跑即可。"源文件在传输中被修改"的提示,常见于备份正在写入的活动文件(比如还在写的日志、运行中的数据库文件),这类文件直接rsync可能拿到不一致的快照,更稳妥的做法是先让应用产出一致性的导出(比如数据库先dump)再备份。连接类报错则回到SSH那一层去查,端口、密钥、防火墙挨个排。
把报错和告警串起来,让备份脚本的每一次失败都变成一条能被你立刻看到的信号,而不是默默烂在某个没人看的日志角落。一个备份系统的成熟度,很大程度上就体现在"出事时它会不会主动告诉你"这一点上。
不同类型的数据,备份策略要不要区别对待?
一台服务器上的数据不是一锅炖的,不同类型的数据有不同的脾气,用同一招rsync全包反而会出问题。把数据分类,对症下药,才是稳妥的做法。
最要小心的是数据库。数据库文件是在不断被读写的活动文件,直接rsync拷它的数据目录,很可能拿到一个写到一半、彼此不一致的状态,恢复时根本起不来。正确做法是先让数据库导出一份一致性的备份(比如做一次dump或用数据库自己的热备机制),生成一个静态的备份文件,再用rsync把这个文件搬走、归档、传异地。顺序是"先导出、后同步",别让rsync直接碰活动的数据库文件。
网站程序文件和上传的媒体资源,则是rsync的主场。代码、图片、附件这些大多是静态的,增量同步又快又稳。这里可以再细分:代码其实更适合用版本控制来管,真正需要rsync重点备份的是用户上传的、无法从代码重建的媒体文件。把"能重建的"和"丢了就没的"分开,备份的重心就清楚了。
还有配置文件和系统状态,这类体积小但极其关键——少了某个Nginx配置、某个环境变量文件,恢复时就卡壳。它们值得单独、完整地备份,甚至纳入版本管理留痕。把数据分成"活动数据库、静态文件、关键配置"三类分别处理,比一条rsync命令想包打天下要可靠得多。这也呼应了备份的本质:你不是在复制一堆字节,而是在保存一个出事后能被完整重建的系统。
备份做完就完事了?恢复验证才是真正的终点
这是最多人栽的地方:天天有备份在跑,日志也绿油油,结果真出事要恢复时,发现备份根本用不了——文件不全、权限错乱、或者那个快照其实早就因为脚本bug没生成。没验证过恢复的备份,等于没有备份。
验证恢复要动真格。定期挑一个快照,把它恢复到一台测试机或隔离目录里,真正跑一遍:网站能不能起来、数据库能不能挂上、权限对不对、关键文件在不在。光看备份目录里有文件是不够的,得确认这些文件能拼回一个能用的系统。--dry-run 加上 --checksum 还能帮你比对源和备份的内容是否真的一致,揪出那些"看着在、其实坏了"的文件。
恢复演练也要监控和告警兜底。备份脚本失败、快照没生成、磁盘空间不足,这些都该第一时间报出来,而不是等用的时候才发现。怎么把这些信号接进监控告警,可以参考Linux服务器日志管理里讲的日志分析和告警思路。把"备份是否成功"变成一个被持续盯着的指标,远比每天人工瞄一眼可靠。
也别只演练"整站全恢复"这种大场面。现实里更高频的是小事故——误删了一个文件、改坏了一个配置、想找回上周某个版本。这种单文件、单目录的精准恢复,恰恰是快照备份的强项:直接进到对应日期的快照目录,把要的那个文件rsync回去就行,不用大动干戈。把"如何从快照里捞回单个文件"也练熟,日常的小麻烦就能几分钟搞定,这是比全量恢复用得更勤的本事。
演练时还该顺手记一份恢复手册:从哪个快照、用什么命令、按什么顺序、恢复到哪、要改哪些配置才能让站点重新跑起来。真出事的时候往往是深夜、是慌乱、可能还不是你本人在处理,一份写清步骤的手册,能把恢复时间从"手忙脚乱试一晚上"压缩到"照着做一小时搞定"。备份能恢复只是及格,恢复得快、恢复得有把握,才是真正扛得住事的备份。这也正好接上灾备的策略层——恢复要多快、能容忍丢多少数据,是策略要定的目标,rsync和演练手册则是把目标落地的工具。
说到底,为什么镜像不等于备份?
这篇反复在强调一个区分,这里把它彻底讲清,因为它是rsync用户最容易踩的认知坑。很多人rsync --delete做了一份和线上一模一样的实时镜像,就以为自己有备份了。其实没有。
镜像的本质是"复制当前状态"。源端发生的一切变化,都会被忠实地同步到镜像——包括好的变化,也包括坏的变化。源端被勒索病毒加密了,下一次同步会把加密后的文件覆盖到镜像上;你误删了一个目录,同步会把镜像里对应的目录也删掉。镜像跟着源端一起遭殃,这时候它救不了你。
最坑的是这种灾难往往有延迟。勒索病毒可能先潜伏、慢慢加密,你的镜像兢兢业业地把"被加密"这个变化同步过去,等你发现不对劲,镜像里也已经是一片加密后的乱码了。一份只做实时镜像的"备份",在勒索攻击面前甚至是帮凶——它忠实地帮攻击者把破坏复制到了第二份。这就是为什么安全圈反复强调备份要有"时间深度"和"防篡改":既要能回到被攻击之前的干净时间点,又要保证攻击者够不到、改不了历史备份。一份能被源端实时覆盖的镜像,这两条都不满足。
真正的备份核心是"可回到过去某个干净的时间点"。这就需要版本化——用 --link-dest保留多个历史快照,最新一份被污染了,还能回退到昨天、上周那份干净的。再往上叠加:多份副本分布在不同介质、至少一份在异地、定期做恢复演练,这套组合拳才构成完整的备份体系。关于这套体系的策略设计——该保留多久、恢复目标定多高、出事怎么分场景回滚,灾备与恢复演练那篇讲的是策略层,本文讲的是rsync这把工具怎么落地。工具和策略对上了,备份才既扛得住事、又用得起来。
常见问题解答
rsync和直接cp复制文件比,好在哪?
好在它只传改动的部分。rsync用的是差量传输算法,比对源和目标后,只把变化的文件、甚至文件内变化的那一段传过去,没动过的一概跳过。第一次全量同步可能和cp差不多慢,但从第二次起,几十GB的目录里只改了几个文件,rsync几秒就跑完,cp却要从头复制一遍。再加上它能保留权限、属主、时间戳、软链接,能压缩传输、能限速、能断点续传,还能经SSH加密传到异地,这些都是cp给不了的。也正因为只传增量,它对网络和磁盘都更友好,跑备份时对生产业务的干扰更小。做周期性、增量、异地的备份,rsync几乎是默认选择。
rsync命令里源路径末尾加不加斜杠,到底有什么区别?
区别大到能决定备份对不对。源路径末尾加斜杠,表示"复制这个目录里的内容"到目标;不加斜杠,表示"复制这个目录本身"到目标里。比如rsync -a /data/ /backup是把data里的东西铺到backup下,而rsync -a /data /backup会在backup下生成一个data子目录。注意决定行为的是源路径那一侧,目标路径加不加斜杠效果一样。搞反了轻则目录层级嵌套乱套,重则配合 --delete时删错东西。保哥的习惯是:把常用命令固化进脚本、斜杠写死测好,拿不准就先加 --dry-run跑一遍看清楚再说,别靠手敲时的临场记忆。
--delete参数很危险吗?什么时候该用?
危险,但该用时必须用。--delete会把目标里"源端已经没有"的文件也删掉,让目标和源保持完全一致,这是做镜像同步必需的,否则目标会越积越多一堆早该删的废文件。危险在于:如果你源路径写错、或者源端目录意外为空,--delete会忠实地把目标里的东西也清空,备份瞬间变事故,运维圈这种惨案听过太多。安全用法是三条铁律:用前必先 --dry-run看会删什么、对关键备份保留版本化快照而不是只做镜像、源路径反复核对尾斜杠。说到底,镜像不等于备份,--delete做的是镜像,真正的备份要靠版本化快照兜底。
--link-dest做的快照,会不会把磁盘撑爆?
通常不会,这正是它的精妙处。--link-dest让本次备份里没有变化的文件,不再重复占空间,而是用硬链接指向上一次备份的同一个文件。结果是每个快照目录看起来都是一份完整副本,可以独立浏览、独立恢复,但磁盘上没变的文件只存了一份。十个每日快照,如果每天只改了少量文件,占的空间远小于十份全量。删除中间某个快照也安全——因为是硬链接,只有当一个文件不再被任何快照引用时空间才真正释放,删一个快照不会破坏其它快照的完整性。代价是它依赖硬链接,要求快照都在同一个文件系统上,跨盘或某些网络存储上硬链接行为会不一样,得先确认支持。
用rsync做镜像,能替代真正的备份吗?
不能,这是最致命的误解。如果你只是rsync --delete做一份实时镜像,那源端一旦中勒索病毒加密、或者你手滑删了文件,下一次同步会忠实地把这些"坏变化"也复制到镜像上,备份跟着一起完蛋,甚至帮着把破坏复制到第二份。真正的备份需要版本化——用 --link-dest保留多个历史时间点的快照,这样即使最新一份被污染,还能回退到干净的旧版本。再叠加异地存放、防篡改、定期的恢复演练,才算完整。判断自己做的到底是镜像还是备份,问一个问题就够了:如果昨天的数据被误删或加密了,我今天还能不能从备份里把它干净地捞回来?答得出"能、从哪个快照捞",那是备份;答出"完了,镜像也跟着覆盖了",那只是镜像。一句话记牢:镜像解决的是"另一份在哪",备份解决的是"出事了能回到哪个干净的时间点"。
权威参考资料
FAQPage + Article AI 引用友好版
想用rsync给Linux服务器做备份,又怕一条命令把数据删没?这份实操从增量原理讲到快照、异地同步、定时执行和恢复演练,帮你绕开尾斜杠和 --delete的经典坑,做出真正出事时能恢复的备份。
- Linux
- 运维
- rsync
- 服务器备份
- 数据备份
title: Linux服务器怎么用rsync做增量备份和快照才不会把备份玩成灾难? author: 张文保 (Paul Zhang) — PatPat SEO 经理 url: https://zhangwenbao.com/linux-server-rsync-incremental-backup-snapshot-link-dest-offsite-restore.html published: 2026-04-18 modified: 2026-04-18 source-type: First-hand expert commentary language: zh-CN license: CC BY-NC-SA 4.0 (要求保留原文链接与作者归属)
本文标题:《Linux服务器怎么用rsync做增量备份和快照才不会把备份玩成灾难?》
版权声明:本文原创,转载请注明出处和链接。许可协议: CC BY-NC-SA 4.0