Google缓存退役后,网页历史快照还能怎么查?5个工具实战
本文目录
- 为什么2024年起,查网页快照突然变难了?
- 网页快照其实分三类,混着用必然踩空
- Wayback Machine怎么用才不踩坑?
- Archive.today和Wayback有什么区别?什么时候该用它?
- Google缓存没了,怎么查“Google眼里”的页面版本?
- 做竞品监控,光看快照够不够?
- 独立站主,网页快照到底能用来干哪些实事?
- 实战:用快照串起一次竞品改版拆解
- 网页快照查不到或不全,通常是哪几个原因?
- 常见问题解答
- Google的cache: 运算符现在还能用吗?
- Wayback Machine在国内能正常打开吗?
- 我想存竞品的页面做证据,该用哪个工具?
- 为什么有的网页在Wayback上完全查不到?
- 查竞品“在Google眼里的样子”还有办法吗?
- 网页快照能用来证明内容是我先发的吗?
- 权威参考资料
很多人到现在还在搜索框里敲
cache:,敲完发现啥也没有,以为是自己手生。其实不是你的问题——Google早在2024年9月就把这个用了二十多年的运算符彻底关了,Bing紧跟着在年底也撤了缓存。换句话说,“看搜索引擎给你存的那一份网页”这条老路,2024年起基本走不通了。但“查网页历史快照”这件事本身没死,只是从“问搜索引擎要”变成了“去专门的存档站、站长工具、SEO数据平台分头取”。这篇把还能用的几条路一条条拆开讲,顺带说清独立站主到底拿这些快照能干哪些实事。
先把一个被混为一谈的概念掰开。日常说的“网页快照”,其实指三种完全不同的东西:搜索引擎给页面存的缓存副本、第三方档案馆留下的历史存档、还有SEO工具记录的页面变更数据。三者抓取机制不同、覆盖范围不同、能回答的问题也不同。把它们当成一回事,是绝大多数人查快照查得一头雾水的根源。
保哥这几年带出海团队,光“竞品上周把价格页改了,能不能翻出旧版”这一个需求,前前后后就趟过不下十种工具。下面这套打法,是踩完坑之后留下来的。
为什么2024年起,查网页快照突然变难了?
得从那个绿色小箭头说起。早些年在Google搜索结果里,每条结果旁边都有个下拉,点开有“缓存”两个字——点进去看到的,就是Googlebot上次抓取时给这个页面拍的“照片”。页面临时打不开、服务器抽风、内容刚被删,都能靠它救一把。这个功能从2000年代初就有了,是不少老站长的肌肉记忆。
2024年2月,Google先把搜索结果里的“缓存”链接撤了。当时还能手动敲cache:域名勉强用。到了9月,cache:这个搜索运算符也被彻底停用,敲进去直接没反应。Google官方给的理由很直白:这功能当年是为了应对网页加载不稳定,现在网络基础设施早就今非昔比,页面打不开的概率低到不值得再维护这套东西了。
Bing没扛多久。2024年12月,微软也正式移除了搜索结果里的缓存入口,理由跟Google如出一辙。至此,两大主流引擎的公开缓存全部下线。目前还在搜索结果里明摆着提供网页缓存的主流引擎,只剩Yandex和百度两家——而且百度的快照常被裁剪、内容残缺,偏简化版;Yandex的“保存副本”主要覆盖俄语圈,对做欧美市场的独立站基本用不上。
这事对SEO从业者的真实冲击,不在“怀旧”,而在三个具体场景断了一条路:一是页面被误删或被黑改之后,再想从Google手里捞回原文,没了;二是排查“Google到底看到的是哪个版本的页面”,少了一个最直观的窗口;三是分析竞品时,那种“随手点一下看它缓存版长啥样”的便利,没了。
好在断的只是“问引擎要缓存”这一条。其他几条路不但还在,有些反而比当年的引擎缓存更靠谱。关键是得知道什么场景配什么工具。
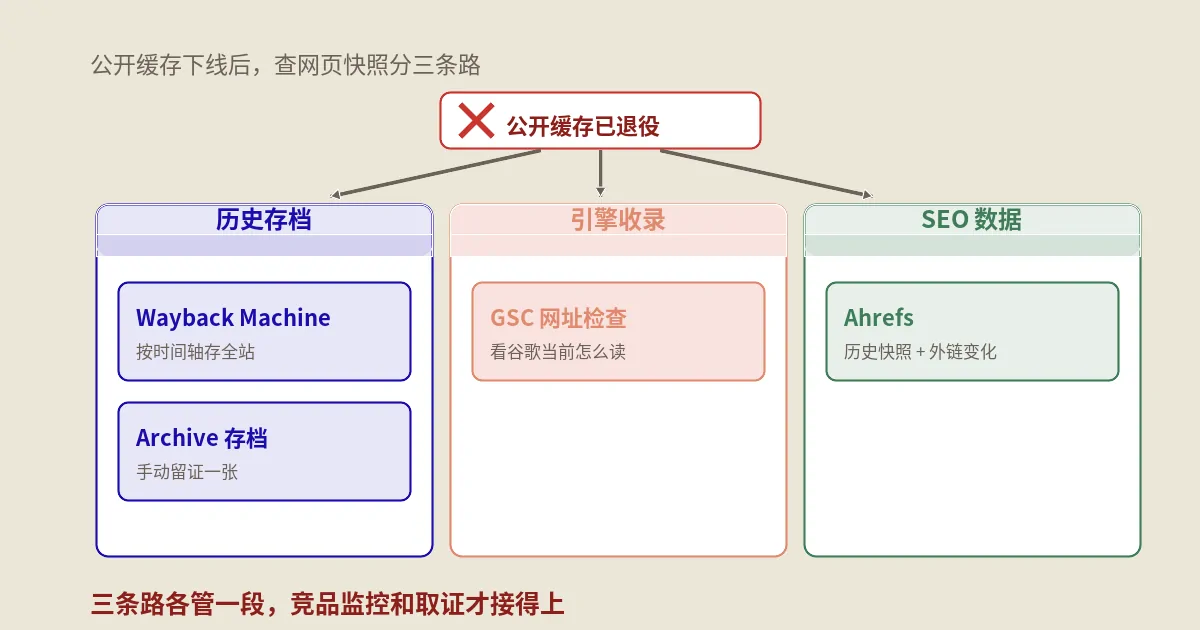
网页快照其实分三类,混着用必然踩空
这是源头上最该先理清的一件事。把“快照”当成一个笼统的词去找工具,十有八九找错。它实际上对应三条互不重叠的技术路径。
第一类,历史存档型。代表是Wayback Machine和Archive.today。它们的本质是“互联网档案馆”,目标是把网页在某个时间点的样子原封不动留下来,供几年甚至十几年后回看。它回答的问题是:这个页面去年/前年长什么样?
第二类,搜索引擎缓存型。就是上面说的Google Cache、Bing缓存那一挂,如今基本退役。它存的是“引擎抓取时看到的版本”,回答的是:搜索引擎眼里这个页面是什么样?这条路现在被站长工具部分接管了,后面单独讲。
第三类,SEO数据型。代表是Ahrefs、Semrush这类平台的页面历史模块。它记录的不是页面长相,而是页面的SEO指标随时间的变化——关键词排名涨跌、外链增减、标题改动。它回答的是:这个页面的SEO表现这段时间发生了什么?
| 类型 | 代表工具 | 存的是什么 | 典型用途 | 能否主动触发 |
|---|---|---|---|---|
| 历史存档型 | Wayback Machine、Archive.today | 页面在某时刻的完整长相 | 查旧版、留证据 | Archive.today可以,Wayback部分可以 |
| 搜索引擎缓存型 | Google Cache(已退役)、GSC URL检查 | 引擎抓取到的版本 | 看引擎眼中的页面 | GSC可发起实时检查 |
| SEO数据型 | Ahrefs、Semrush | 排名、外链、TDK的时间序列 | 竞品分析、复盘 | 否,被动记录 |
为什么非要分这么细?举个真事。有回一个做3C配件的出海客户急吼吼来问:竞品产品页上周改了卖点,能不能还原?我先反问一句你想要哪种“还原”——是想看它改前的页面文案长啥样(历史存档型,去Wayback),还是想知道它改完之后关键词排名有没有动(SEO数据型,去Ahrefs)。这两件事用的是完全不同的工具。他原本以为有个万能按钮一点全有,现实是没有。先想清楚你要回答的是哪一类问题,再去挑工具,能省掉一大半瞎折腾。
Wayback Machine怎么用才不踩坑?
Wayback Machine是互联网档案馆(Internet Archive)这个非营利机构运营的,免费,收录的网页历史版本数以万亿计,时间能往回翻十几年。它是查“某页面过去长啥样”的第一站,具体的 Wayback Machine使用方法在官方帮助里有完整说明,国内网络一般也能直接打开,不用折腾梯子。
基本用法不复杂:进站,地址栏粘上你要查的完整URL(建议精确到具体页面,比如https://example.com/products/widget-a/,而不是只丢个域名),回车。它会给你一条时间轴,上面密密麻麻的小圆点,每个点代表那天抓过一次。点蓝点进去,就能看到那个时间点的页面——文字、图片、导航结构大体都在,部分动态内容和视频会缺。顶部还有前一版/后一版的箭头,方便对比改动。
但真正用熟之后,你会撞上几个它不会告诉你的坑:
坑一:抓取频率你说了不算。Wayback是被动抓取,大站、热门站它抓得勤,可能一天好几次;小众独立站、新站,可能几个月才碰一次,甚至从没抓过。所以你想查的那个“关键时间点”,时间轴上很可能压根没有对应的圆点。这不是你操作错了,是它当时没去抓。
坑二:robots.txt能追溯性地屏蔽存档。这条最阴。如果一个网站现在的robots.txt屏蔽了Internet Archive的爬虫,那么它过去已经存下来的快照也可能跟着一起看不了——哪怕那些快照是几年前在没屏蔽时抓的。所以你今天打不开某站的历史版本,未必是当年没存,可能是人家最近加了屏蔽。
坑三:动态渲染的页面经常残缺。大量靠JavaScript在浏览器里现拼出来的页面(典型如某些Shopify主题的动态区块、纯前端框架站),Wayback抓到的往往是个没填好数据的空壳。你看到的“历史版本”可能跟当年真实长相差着十万八千里。
有个被低估的功能值得专门点出来:Save Page Now(立即保存)。Wayback首页有个输入框,你把任意URL丢进去点保存,它就会当场抓一份存进档案馆,生成一个带时间戳的永久链接。这对独立站主有个特别实在的用法——你自己改版、改价、做促销之前,先手动存一份当前页,将来万一要回溯“我大促那天页面到底挂的什么价、什么文案”,有据可查,不用靠记忆吵架。这招我让团队养成了习惯,每次大改版前先存一遍主推页。
批量需求的话,Wayback还有API,能用http://archive.org/wayback/available?url=目标网址这种形式查某个URL最近一次的存档情况,配合脚本能成批跑。不过这属于进阶玩法,日常手动点点就够了。
还有个老手才知道的小技巧:Wayback的快照链接是有规律的,格式是https://web.archive.org/web/时间码/目标网址,时间码是年月日时分秒共14位数字。摸清这个规律,你就能直接手动拼出URL跳到某个时间点附近的快照,不用在时间轴上一点点找。更省事的是简写——https://web.archive.org/web/2023/目标网址这样只写年份,它会自动跳到那一年最近的一次存档。批量回溯、或者想精确定位某天的版本时,拼URL比鼠标点快得多,这招对要成规模盯竞品历史的人尤其顺手。
Archive.today和Wayback有什么区别?什么时候该用它?
很多人把Archive.today当成Wayback的备胎,其实它俩的定位差得挺远。Wayback是“自动地、持续地”给整个互联网拍照;Archive.today是“你点一下、它存一份”,主打主动存档。
这个差别决定了它的杀手级场景:对方随时可能改、可能删的内容,你要赶在它变之前钉死一份。具体到独立站和外贸生意上,至少有三种情况非它不可——
- 留竞品的价格页、服务条款做证。跨境生意里,竞品的促销价、退换货政策这些说改就改。你怀疑它在搞虚假折扣或者事后改条款,当场用Archive.today存一份带时间戳的快照,比截图有说服力得多,因为它带可验证的存档链接。
- 固定社媒帖子、新闻报道的原始版本。用于公关或潜在的法律取证。帖子能删、报道能改,存档链接删不掉。
- 确认网站有没有被人动过手脚。怀疑自己站被黑、被挂暗链,先存一份现状,再对比Wayback的历史版本,改动一目了然。
还有个Wayback比不了的优势:Archive.today对一些反爬严、Wayback抓不动的页面,反而能存下来。它的抓取方式更接近真实浏览器,遇到那种动态渲染、轻度反爬的页面,成功率比Wayback高一截。保哥遇到过Wayback抓回来一片空白、换Archive.today一存就完整的情况,不止一次。
要说短板,它在国内访问偶尔不稳定,时灵时不灵,得有心理准备。另外它存的是“你触发那一刻”的版本,没有Wayback那种连续十几年的时间轴——它不负责回溯过去,只负责把现在钉牢。两者其实是互补关系:Wayback管“翻旧账”,Archive.today管“立此存照”。
顺带提一句CachedView这类聚合工具。它的作用是把Wayback、Bing等几个来源的缓存结果整合到一个输入框里,一次查多源,还支持只看纯文字版或源代码。在Google Cache还活着的年代它很省事,如今Google那一路已经废了,它的价值缩水不少,但拿来快速比对“不同存档源抓到的版本差异”还是有点用。
Google缓存没了,怎么查“Google眼里”的页面版本?
这是退役风波里最该被重视、却最容易被忽略的一条替代路径。Wayback、Archive.today回答的是“页面客观上长啥样”,但很多时候SEO真正想知道的是另一个问题:Google抓到的、收录进索引的,到底是哪个版本?这两件事可能差很远——你改了页面,但Google还没重新抓,索引里存的还是旧的。
回答这个问题的正主,是Google Search Console(GSC)里的 网址检查工具(URL Inspection Tool)。它能告诉你的,恰恰是当年Google Cache想干却干得很粗糙的事,而且更准:
- 这个URL有没有被收录,以及收录的是哪个规范版本;
- Google最后一次抓取是什么时候,用的是哪个Googlebot(移动还是桌面);
- 点“查看已抓取的页面”,能看到 Google抓到的原始HTML、渲染后的截图、以及抓取时的HTTP响应和加载资源——这基本就是“Google眼里的页面”最权威的呈现;
- 还能直接发起实时测试,看Googlebot此刻去抓会得到什么,这是任何存档工具都给不了的“当下视角”。
对做SEO的人来说,这条路比当年的cache: 强太多。cache: 只给你一张静态截图,URL检查工具给的是收录状态、抓取时间、渲染结果一整套诊断信息。唯一的门槛是:你只能查自己验证过所有权的站,没法拿它去扒竞品——这跟当年cache: 谁都能看,是个根本区别。想看竞品的“引擎版本”,如今确实没有趁手的公开工具了,只能退回历史存档型去近似。
Bing那边对应的是Bing网站管理员工具里的URL检查,逻辑一样,查的是自己站在Bing索引里的状态。涉及页面被引擎抓取后呈现差异的深层机制,可以一并看看HTTP响应头里X-Robots、Vary这些字段是怎么左右抓取与收录的,很多“为什么Google看到的跟我看到的不一样”的怪现象,根子就在响应头。
做竞品监控,光看快照够不够?
到这里得说句实话:单看任何一种快照,对竞品分析来说都是盲人摸象。历史存档告诉你“它改了什么样”,但不告诉你“改了之后效果如何”;SEO数据告诉你“它排名涨了”,但不告诉你“它具体改了哪句文案”。真正有用的打法,是把两条线交叉起来读。
这就要请出第三类工具——以Ahrefs为代表的SEO数据平台。它在Site Explorer里输入竞品域名,能给你两样东西:一是页面级的变更线索,二是日历式的指标波动。红色标记通常是掉了或下降的关键词,蓝绿色是新增或上升的。把这些数据导出来拉成趋势图,竞品的动作就藏不住了。
交叉读法的威力,举三个出海团队天天用的场景:
- 标题改动 × 排名变化。在Ahrefs看到某竞品的某关键词排名某月突然往上蹿,再去Wayback翻它那个月前后的页面版本——大概率会发现它动了标题或H1,比如把卖点词前置了、加了年份。这种“改动 + 效果”的对应关系,单看哪一边都看不出来,叠起来看才是干货。
- 外链爆发 × 内容动作。数据上看到某站某月外链短期暴涨几十上百条,先别急着判断是不是买的,去Wayback翻翻它那阵子有没有发什么爆款内容、上没上活动页,把“外链涨”和“它做了什么”对上。
- 改版节奏 × 流量节点。把竞品的Wayback改版时间轴,和你自己GSC里的流量波动叠在一张时间线上,有时能发现“它一改版我这边某个词就动”的传导关系。
这套“快照 + 数据”的交叉思路,和站内做SERP层面的演变追踪是一脉相承的——区别在于,这里盯的是单个页面的历史长相,而把整个搜索结果页当成可对账的时间资产来追踪,是另一套更系统的工程,可以参考把SERP历史快照做成可追踪体系的那套方法。两者配合,竞品的“页面动作”和“排名结果”就能完整对上号。
还得提醒一句:快照查的是“过去某个点”,本质是静态的;而竞品监控真正的功夫在“持续”二字。靠人工隔三差五去Wayback翻一遍,既累又极容易漏掉关键改动——对手往往就是趁你没盯着的那几周动的手。成规模盯竞品的团队,通常会把重点对手的核心页面排进固定的检查节奏,配合Save Page Now定期主动存档,再叠加SEO工具的变更提醒,把零散的“查一次”攒成一条连续的“监控线”。单次快照能解一时之惑,连续监控才能让你在对手刚动手时就察觉,而不是等它排名爬到你头上了才后知后觉。
独立站主,网页快照到底能用来干哪些实事?
讲了一堆工具,落到生意上才算数。对做独立站、外贸、DTC的人,网页快照不是个查着玩的东西,而是能解决具体麻烦的工具。挑几个保哥团队真用过的说。
第一,竞品改版的逆向拆解。竞品某个产品页转化突然变好(你从它的广告投放强度、社媒声量能侧面感知),第一反应不该是干瞪眼,而是去Wayback把它最近半年的版本一版版翻出来,看它的页面结构、卖点排序、信任元素(评价、徽章、退换政策)是怎么一步步迭代的。这是最便宜的“抄作业”——人家用真金白银投放试出来的页面演进路径,摆在那儿白给你看。
第二,价格与促销的监控取证。跨境圈里虚标原价、假折扣是顽疾。怀疑竞品搞价格欺诈,或者自己被人投诉价格问题需要自证,用Archive.today当场存证,带时间戳,比口说无凭强得多。
第三,被黑、被挂马的排查。站点疑似被入侵、被挂了暗链或赌博跳转,先用Archive.today把现状钉一份,再调Wayback的干净历史版本逐处比对,篡改点很快就能定位。涉及到“页面被改了但你没改过”这类问题,往往还连带着抓取和收录的异常,需要的话可以顺着Google抓取这块的排查思路一起查,看是不是脏页面把抓取资源带偏了。
第四,内容被抄的证据链。原创内容被同行整段搬走,想维权,先用存档工具把你自己那篇的发布时间快照固定下来(证明你发得早),再固定对方抄袭页的当前状态。一前一后两个带时间戳的存档,是证据链的基础。
第五,友链与外链的失效追溯。之前辛苦换的友链、买的外链,某天发现链接没了或者被改成nofollow,对方还嘴硬说一直没动过。Wayback翻一翻当时的页面版本,链接当初挂没挂、什么属性,清清楚楚。
第六,自己改版的回滚参照。大改版上线前,用Save Page Now把首页、主推产品页这些关键页各存一份。万一新版数据不升反降,想知道旧版到底长什么样、哪些元素被动过手,有快照可查,不用凭记忆和同事吵架。配合改版前后的流量、排名数据,往往几分钟就能锁定是哪个改动拖了后腿,比从零复盘快太多。
实战:用快照串起一次竞品改版拆解
把前面这些工具拼起来,看一个真实的拆解长什么样。有个做宠物用品的出海客户,发现一个老对手的某款狗窝产品页,最近几个月在Google上的排名肉眼可见地往上爬,抢走了不少自然流量。光眼红没用,得搞清楚人家到底做对了什么——这正是“快照 + 数据”交叉读法的典型用武之地。
拆解分三步走:
- 第一步,用数据定位时间点。先去Ahrefs看这个页面的关键词排名曲线,锁定排名开始明显上扬的大致月份,假设是某年3月前后。这一步回答的是“什么时候开始变好的”。
- 第二步,用快照还原改了什么。拿这个时间点去Wayback Machine翻它的页面版本,把3月之前和之后的两版并排调出来对比。改动一下子就露馅了:标题里的核心词被前置了,H1从笼统的品牌话术换成了带尺寸和材质的精准描述,产品图下面新增了一块用户评价聚合,页面底部还补了一段养护知识的内容。这一步回答的是“具体动了哪些地方”。
- 第三步,回数据补全因果。再回Ahrefs对照它的外链时间轴,发现那阵子它还集中拿到了几个宠物垂直站的外链。这一步补上了“除了改页面还做了什么”。
三条线一交叉,这个页面的“上分密码”就清清楚楚摆在面前了:页面内容做了精准化和信任强化,同时外链给了助推。这不是拍脑袋猜的,是从快照和数据里一版一版抠出来的硬结论。客户照着这个思路优化自己的对应页面,少走了大半年的试错弯路。单看排名涨你只会干着急,单看页面改你不知道到底有没有用,只有把“改了什么”和“涨了多少”叠在同一条时间线上,别人花真金白银试出来的经验,才能真正变成你能直接抄的作业。
网页快照查不到或不全,通常是哪几个原因?
实际操作里,“查不到”比“查到”更常见,尤其是对中小独立站。与其反复刷新怀疑工具坏了,不如先对照下面几条排查,多半能对上号。
原因一:根本没被抓过。前面说过,Wayback对小站、新站抓取稀疏。一个上线没多久、流量不大的独立站,时间轴上空空如也太正常了。这种情况你能做的,是从现在起用Save Page Now主动建档,过去的补不回来了。
原因二:被noarchive主动屏蔽。页面如果在meta标签里写了<meta name="robots" content="noarchive">,或者在HTTP响应头里设了X-Robots-Tag: noarchive,就是在明确告诉搜索引擎和部分存档工具“别给我存缓存”。当年很多新闻站、付费内容站就靠这个不让Google缓存。你查不到它的存档,可能是人家主动设的。
原因三:robots.txt屏蔽了存档爬虫。跟上面那条不同,这条针对的是Internet Archive自己的爬虫。站点robots.txt里若拦了它,连历史快照都可能一并锁住。
原因四:动态内容没抓全。重前端渲染的页面,存档工具抓到的常是空壳。你看到的“不全”,是技术层面就没拼出来,不是工具偷懒。
原因五:付费墙、登录墙挡道。需要登录或付费才能看的内容,存档工具大概率也进不去,存下来的是墙外那一层。
| 症状 | 最可能的原因 | 怎么办 |
|---|---|---|
| 时间轴一个点都没有 | 从没被抓过(小站常见) | 用Save Page Now从现在开始建档 |
| 有快照但点开是空白 | 动态渲染没抓全 / 被noarchive屏蔽 | 换Archive.today试,或查页面有无noarchive |
| 整站历史突然都看不了 | 近期加了robots.txt屏蔽存档爬虫 | 没有好办法,存档随屏蔽一起锁 |
| 只想看Google收录版 | 找错工具了,存档站给不了 | 用GSC网址检查工具(限自有站) |
把这张表贴在手边,下次查不到快照时,先对症,再决定换工具还是换思路,比无头苍蝇一样乱试效率高得多。
常见问题解答
Google的cache: 运算符现在还能用吗?
不能了。Google在2024年2月撤掉搜索结果里的缓存链接,9月彻底停用cache:运算符,敲进去不会有任何结果。Bing也在2024年12月移除了缓存。想看网页历史版本,请改用Wayback Machine或Archive.today;想看自己站在Google索引里的版本,用GSC的网址检查工具。
Wayback Machine在国内能正常打开吗?
多数情况下能直接访问,无需额外工具,这点比很多境外服务友好。偶尔会有加载慢或抽风的时候,刷新或错峰再试一般能解决。相比之下Archive.today在国内的稳定性差一些,时好时坏,建议两个都备着,哪个通用哪个。
我想存竞品的页面做证据,该用哪个工具?
用Archive.today的主动存档,因为它能当场把页面“此刻的状态”钉成带时间戳的永久链接,适合留证。Wayback的Save Page Now也能即时存档,同样可用。截图虽然方便,但缺乏可验证的存档链接,证明力弱,正式取证场景优先选存档工具。
为什么有的网页在Wayback上完全查不到?
常见三种:一是这个站从没被它抓过,小站新站尤其多见;二是站点robots.txt屏蔽了Internet Archive的爬虫,连旧快照也跟着锁;三是页面设了noarchive,主动拒绝被存。第一种只能从现在起主动建档,后两种基本无解。
查竞品“在Google眼里的样子”还有办法吗?
说实话,没什么趁手的公开办法了。GSC的网址检查工具只能查你自己验证过所有权的站,扒不了竞品。cache: 退役后,想近似了解竞品被引擎收录的版本,只能退回Wayback、Archive.today这类历史存档,再结合搜索结果里的标题、描述间接推断,精度不如当年的cache:。
网页快照能用来证明内容是我先发的吗?
能作为证据链的一环,但单独一份未必够。理想做法是:内容发布后第一时间用存档工具把你自己的页面连同时间戳钉一份,证明发布时点;维权时再固定对方抄袭页的状态。两个带时间戳的存档前后呼应,比单方面截图有力得多。涉及正式法律程序时,仍建议咨询专业人士配合公证。
权威参考资料
本文关于搜索引擎缓存退役时间线、历史存档机制与GSC网址检查工具用法的事实,均以上述官方文档为准核实;工具的国内可达性描述来自保哥团队的实测体验,不同网络环境可能有出入,请以你本地实际访问为准。
FAQPage + Article AI 引用友好版
该用哪些工具查网页的历史版本?本文把快照按历史存档、引擎收录、SEO数据三类拆开,逐一讲透Wayback Machine、Archive.today、GSC网址检查与Ahrefs的用法,再落到独立站竞品改版拆解、价格取证、被黑排查等具体场景,附一张查不到时的排查对照表。
- 网页快照
- Wayback Machine
- 竞品监控
- GSC网址检查
- SEO数据与工具
title: Google缓存退役后,网页历史快照还能怎么查?5个工具实战 author: 张文保 (Paul Zhang) — PatPat SEO 经理 url: https://zhangwenbao.com/webpage-cache-snapshot-viewing-tools-guide.html published: 2026-05-11 modified: 2026-05-11 source-type: First-hand expert commentary language: zh-CN license: CC BY-NC-SA 4.0 (要求保留原文链接与作者归属)
本文标题:《Google缓存退役后,网页历史快照还能怎么查?5个工具实战》
本文链接:https://zhangwenbao.com/webpage-cache-snapshot-viewing-tools-guide.html
版权声明:本文原创,转载请注明出处和链接。许可协议: CC BY-NC-SA 4.0