GEO技术端这样优化,AI爬虫才能抓得到、读得懂、引得出
本文目录
- GEO做了一堆内容,AI还是不引用你?先别急着怪内容
- GEO技术端到底指什么?和排名向的技术SEO是一回事吗?
- 为什么说技术端是GEO的及格线,不是加分项?
- 把技术端拆成一条诊断线:从能不能被抓到能不能被引,要过几关?
- 第一关·可达:AI爬虫到底进不进得来你的站?
- 比robots更隐蔽:CDN、WAF、托管主机会不会替你偷偷把AI爬虫挡了?
- 怎么用一条命令十秒自查AI爬虫到底被放行还是被拦?
- 第二关·可渲染:抓进来了,AI真的读到你的内容了吗?
- SSR、SSG、预渲染到底该怎么选才不踩坑?
- 第三关·可理解:内容读到了,AI能看懂你的页面结构吗?
- 结构化数据到底要不要加?加了就会被引用吗?
- 第四关·可抽取:看懂了,AI能把你的内容整段拎出来引用吗?
- 第五关·可信与稳定:你的服务器扛得住AI爬虫的抓取量吗?
- 新鲜度信号在技术端怎么做才不是假改时间戳?
- 这五关该按什么顺序排查、先修哪一关?
- 日志才是唯一的真相,怎么从访问日志里看出AI爬虫的真实行为?
- 不靠感觉,怎么验证技术端改完真的生效了?
- 不同技术栈的站,技术端重心为什么不一样?
- 出海便携投影仪独立站的技术端排查,是怎么一步步做的?
- 技术端做对了,是不是就一定会被AI引用了?
- 技术端做完就一劳永逸了吗?最容易踩的几个坑是什么?
- AI会不会以后绕过网站直接读Feed,技术端就白做了?
- 一个人或小团队,技术端第一周该先动哪里?
- 常见问题解答
- 权威参考资料
摘要:很多人做GEO,一头扎进内容——改写法、堆术语、研究怎么被AI引用,结果折腾半天AI还是当你不存在。问题常常不在内容,而在更底下那一层:你的内容压根没被AI爬虫抓到、抓到了没渲染出来、或者渲染了却被切得它读不懂、抽不出。这层就是GEO的技术端,它决定的不是“你比别人好多少”,而是“AI到底看不看得见你”。这篇我把技术端拆成一条能照着走的诊断线:可达(爬虫进不进得来)→ 可渲染(进来了读不读得到内容)→ 可理解(读到了看不看得懂结构)→ 可抽取(看懂了能不能整段引出)→ 可信稳定(扛不扛得住持续抓取),最后加一层怎么验证。每一关都给“怎么自查”加“坑在哪”两段,再用一个出海便携投影仪独立站的真实排查串一遍。一句话先放这儿:技术端不是GEO的加分项,是入场资格——这一关任何一道断了,后面内容做得再漂亮都白搭。
GEO做了一堆内容,AI还是不引用你?先别急着怪内容
这两年找保哥看GEO的人,十个里有七八个一上来就问内容怎么改:要不要写成问答、要不要把结论提前、要不要堆点专业术语让AI觉得权威。这些当然都有用,但我每次都先泼一句:你确定AI真读到你这页内容了吗?很多站根本不是输在内容质量,而是输在AI爬虫压根没把你这页抓回去、或者抓回去看到的是一片空白。内容是地基上盖的楼,技术端才是地基,地基塌了楼盖得再好也没人看得见。
这就是我要单独写技术端这一篇的原因。GEO的内容打法、可抽取写法、信息增益,我在别处讲过不少;但执行里最先卡死一个站的,往往是那些看不见摸不着的技术环节——一条robots规则、一个默认拦爬虫的托管主机、一套首屏全靠JS渲染的前端框架。这些东西不在内容里,你盯着稿子改一辈子也改不出来。所以这篇只管一件事:让AI抓得到、读得懂、引得出你的内容,把这条技术地基一关一关查通。
GEO技术端到底指什么?和排名向的技术SEO是一回事吗?
先把范围框清楚,不然越聊越散。我说的GEO技术端,指的是“让AI搜索引擎能抓取、渲染、理解、抽取你网页内容”所涉及的技术环节,核心是一条链:可达 → 可渲染 → 可理解 → 可抽取 → 可信稳定。它跟传统排名向的技术SEO有大量重叠——可抓取、可渲染这两关,给Google排名做和给AI引用做,本来就是同一件事。值得高兴的是,这意味着你过去技术SEO的底子没白打。Google官方在《AI功能与你的网站》文档里说得很直白:为AI功能优化,用的是和整体Google搜索一样的基础SEO最佳实践,没有额外要求,也不需要别的特殊优化。
但技术端和内容GEO得分开。可抽取块怎么写、信息增益怎么挖、被谁引用,那是内容层的事,这篇不碰;技术端只管“内容能不能被AI这套管道顺利吃进去”。坑在哪:很多人把这两层搅在一起,要么以为做了内容就等于做了GEO(结果技术端卡死,内容根本没进AI的索引),要么以为修了技术就够了(结果抓得到却没东西可引)。这篇专攻技术端这半边,内容那半边我会在该链出去的地方点明。如果你要的是把内容、外链、E-E-A-T、国际化那些也一并查的全站体检,可以看企业网站SEO审计框架那篇,那是整站的总账,而这篇只把其中技术端这一块单独拆深。
为什么说技术端是GEO的及格线,不是加分项?
加分项的意思是“做了更好,不做也能及格”;及格线的意思是“没过这条线,后面一分都拿不到”。技术端是后者。AI搜索的逻辑是先从索引里把候选内容召回,再从候选里挑、抽、引。你的内容如果在第一步“召回”就因为抓不到、渲染不出而进不了候选池,那它后面再优质都没有参赛资格——AI不会引用一个它从没见过的页面。
所以技术端的投入产出比有个特点:它不是线性的,是开关式的。一个被托管主机拦掉AI爬虫的站,内容做到100分,AI可见度还是0;把那道拦截关掉,可见度可能一夜之间从0跳起来。坑在哪:技术端这道开关平时悄无声息,掉到0也不报警,你还在那儿埋头改内容,以为是写得不够好。我的习惯是接手任何一个GEO项目,第一件事不是看内容,是把技术端这条线从头到尾跑一遍,确认AI至少“看得见”这个站,再谈优化。
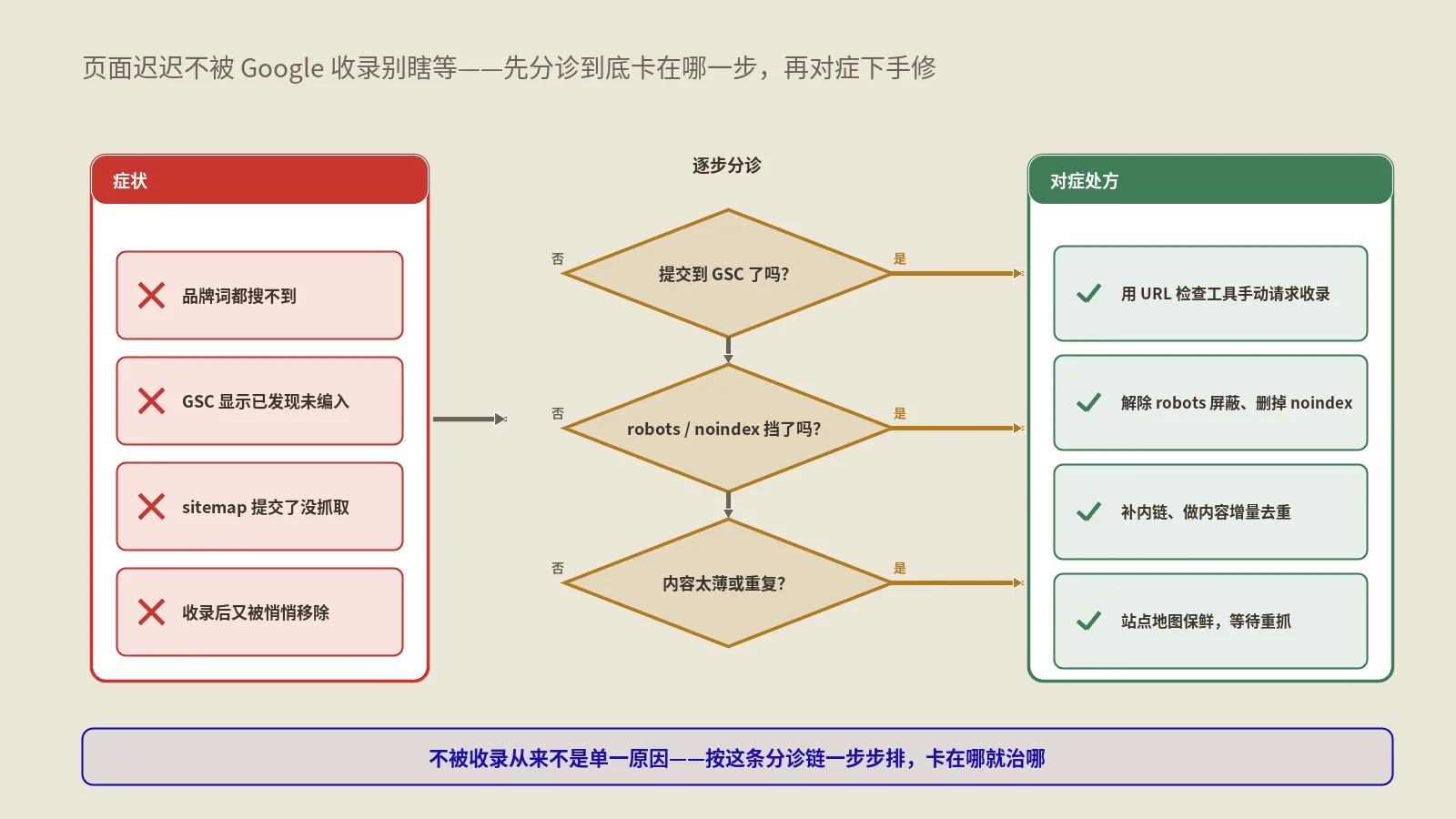
把技术端拆成一条诊断线:从能不能被抓到能不能被引,要过几关?
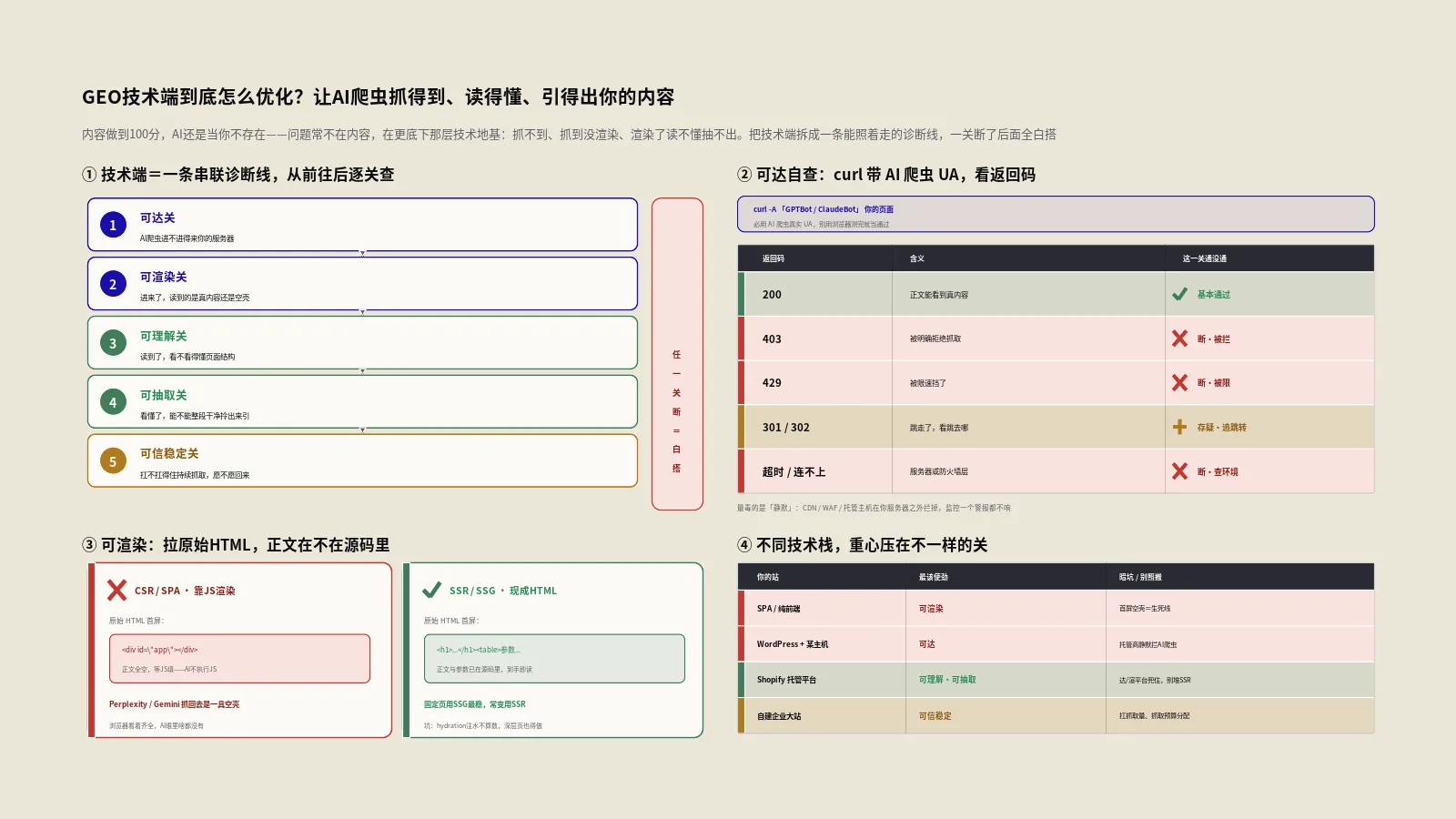
我把技术端拆成五关加一层验证,照着顺序走,哪一关断了后面就别白费力气。第一关可达:AI爬虫进不进得来你的服务器。第二关可渲染:进来了,它读到的是真内容还是一片空白。第三关可理解:读到了,它能不能看懂页面结构、分得清主次。第四关可抽取:看懂了,它能不能把某一段干净地拎出来当引用。第五关可信稳定:你的站扛不扛得住AI爬虫的抓取量,能不能让它持续、稳定地回来抓。最后一层是验证:不靠感觉,怎么证明每一关真的通了。
这条线最大的价值是定位。AI不引用你,原因可能在五关里任意一关,蒙着头乱改最浪费时间。坑在哪:大多数人一上来就跳到第三、四关折腾结构化数据和写法,却没发现第一关爬虫就被拦在门外。务实的排查永远从最致命、最靠前的可达关往后走——前面的关没通,后面的功夫全是空中楼阁。下面一关一关拆。
第一关·可达:AI爬虫到底进不进得来你的站?
可达是技术端的第一道门,也是最容易被自己人无意中焊死的一道。先看robots.txt。这是你主动告诉爬虫“哪些能抓哪些别抓”的文件,Google官方对它的定义是“robots.txt文件告诉搜索引擎爬虫,它能访问你站点上的哪些URL”,主要用来管理爬虫流量。
问题是AI爬虫各有各的user-agent——OpenAI的GPTBot、Anthropic的ClaudeBot、Perplexity的PerplexityBot、Common Crawl的CCBot、还有Google的Google-Extended,你得明确知道自己的robots是放行还是拦了它们。
坑在哪:robots对AI爬虫常常是“全有或全无”的开关——要么这个bot整站能抓,要么整站被Disallow挡死,没有中间地带。我见过不少站当年为了“防内容被白嫖”一刀切Disallow了GPTBot、CCBot,后来想做GEO了却忘了这茬,AI自然一个字都引不到。所以第一步就是打开你的 /robots.txt看清楚,到底放行了哪些AI爬虫、拦了哪些,这件事比改任何一篇内容都优先。要不要对AI爬虫收费、用robots还是WAF来管,那是另一层取舍,但前提是你先得知道现在拦的是谁。
比robots更隐蔽:CDN、WAF、托管主机会不会替你偷偷把AI爬虫挡了?
robots是你自己写的,至少看得见。真正阴险的是你根本不知道的那层拦截——CDN、WAF(Web应用防火墙)、托管主机,可能在你毫不知情的情况下默认就把AI爬虫挡在门外。它们的逻辑是“AI爬虫抓取量大、像异常流量,先拦了再说”,于是AI爬虫还没碰到你的网站、没读到你的robots,就在更外面那一层被原地打回。这件事我专门写过一篇拆解,托管主机悄悄拦AI爬虫导致引用归零那篇里讲得很细,这里只点核心。
坑在哪:这种拦截最毒的地方是“静默”——你的SEO监控工具一个警报都不会响,因为拦截发生在你服务器之外,工具看到的一切正常。等你发现自己从AI答案里彻底消失,可能已经过去几个月。我的做法是把这层当成可达关里优先级最高的盲区来查:用AI爬虫的user-agent去模拟请求,看返回的是200还是被403、429拦了。一旦发现是托管商或CDN干的,得去它们的后台找“bot管理”“AI爬虫”相关开关,有些平台允许你放行,有些则连关都不让关,那就得考虑换环境了。
怎么用一条命令十秒自查AI爬虫到底被放行还是被拦?
不用装任何工具,一条curl命令就能自查。在终端里带上AI爬虫的user-agent去请求你自己的页面,比如模拟GPTBot或ClaudeBot抓首页,看它返回什么状态码、返回的HTML里有没有真内容。返回200且能看到正文,说明这一关基本通了;返回403是被明确拒绝,429是被限速挡了,301/302要看跳去哪,连不上或超时则可能是服务器或防火墙层的问题。多换几个AI爬虫的UA各跑一遍,因为它们可能被区别对待。
坑在哪:返回码不是只有200和404两种,得会读它在说什么。很多人看到不是404就以为没事,其实403和429同样意味着AI抓不到你。还有个隐蔽点:有些站对普通浏览器返回200、对AI爬虫的UA却返回不一样的东西,这种“看人下菜”的差异化响应正是cloaking的灰色地带,自己排查时一定要严格用AI爬虫的真实UA去测,别用浏览器测完就当通过了。十秒钟的自查,能省掉几个月的盲目改内容。
第二关·可渲染:抓进来了,AI真的读到你的内容了吗?
过了可达关,爬虫进来了,但它读到的不一定是你看到的那个页面。关键差别在JavaScript渲染。Google处理JS是分阶段的,官方文档讲Google分三个阶段处理JavaScript网页——抓取、渲染、索引,页面会先排进渲染队列,“可能要等几秒,也可能更久”,等资源允许时再用无头Chromium执行JS。
注意,连有能力渲染JS的Googlebot都要把渲染推迟到队列里慢慢处理;而大多数AI爬虫——GPTBot、ClaudeBot这些——干脆不执行JS。这意味着如果你的内容是靠JS在浏览器端动态加载的(CSR/SPA那种),AI爬虫抓回去的首屏HTML很可能是一具空壳。
坑在哪:这是SPA、纯前端框架站的头号死穴。你在浏览器里看页面内容齐全,因为浏览器执行了JS;但AI爬虫拿到的原始HTML里啥都没有,Perplexity、Gemini这类完全看不到你的内容。这件事我在SPA站AI爬不到的真相那篇里用四种渲染模式实测过引用率差异。自查很简单:用curl拉你页面的原始HTML(不执行JS的那种),或者用浏览器“查看网页源代码”(不是审查元素),看正文文字在不在源码里。如果源码里是空div、内容全靠JS填,那AI大概率读不到。
SSR、SSG、预渲染到底该怎么选才不踩坑?
渲染问题的解法就是让内容在到达AI爬虫之前就已经是现成的HTML。常见三条路:SSR(服务端渲染,每次请求服务器现拼好HTML再发出去)、SSG(静态生成,构建时就把页面生成成静态HTML文件)、以及预渲染(专门给爬虫返回一份渲染好的快照)。内容相对固定的页面(产品、文章、规格),SSG最稳也最省;内容频繁变动的,SSR更合适;实在改不动前端架构的,预渲染是个折中补丁。Google官方也提醒服务端渲染或预渲染“仍然是个好主意,因为它让你的网站对用户和爬虫都更快”。
坑在哪:hydration(注水)不算数。很多现代框架号称“同构”,但如果首屏关键内容还是等JS注水后才出现,对不执行JS的AI爬虫来说仍是空的,别被框架文档里的“支持SSR”几个字糊弄过去。还有个常见错误是只给首页做了SSR,深层的产品页、文章页还是纯CSR——而那些深层页才是AI真正要引用的内容承载页。检验标准只有一个:拉原始HTML,看你最想被引用的那批页面,正文到底在不在源码里。
第三关·可理解:内容读到了,AI能看懂你的页面结构吗?
内容进到HTML里了,下一关是AI能不能看懂这页的结构——哪是标题、哪是正文、哪是主内容、哪是导航和广告。这靠的是语义化HTML:用h1到h6搭出清晰的标题层级,用ul/ol写列表、用table写表格,而不是满屏的div套div、靠CSS视觉上看起来像标题。结构清晰,AI才能准确判断这页在讲什么、哪段是回答某个问题的关键。新一代agentic浏览器甚至直接读页面的accessibility tree(无障碍树)来理解页面,语义标签打得正不正,直接影响它读得对不对。
坑在哪:别把关键信息塞进AI读不到的地方。常见的有三种——把核心卖点或参数做成一张图片(图里的文字AI读不出,除非配了准确的alt)、把内容藏进需要点击才展开的JS交互组件里(tab、手风琴,如果展开内容是JS动态注入的,源码里没有)、或者用canvas之类画出来的文字。我见过把整张规格表做成图片的站,用户看着清楚,AI眼里那一块完全是空白。务实的原则是:凡是你想让AI读到、引用的信息,都得以真实的、语义化的HTML文本形式存在于源码里。
结构化数据到底要不要加?加了就会被引用吗?
这是技术端被误解最深的一条。结构化数据(schema.org标记)能帮搜索引擎更准确地理解页面的实体和关系,该加的(Product、FAQPage、Article、BreadcrumbList这些匹配你内容类型的)还是值得加,它对传统富媒体结果也有用。但你得放下一个幻想:加了schema,AI就会来引用你。这是不成立的。
坑在哪:很多GEO课和工具把“狂加结构化数据”当成被AI引用的开关来卖,这是误导。Google官方说得明明白白:要出现在AI Overviews或AI Mode里“没有额外要求,也不需要别的特殊优化”,并且“没有什么你必须额外添加的特殊schema.org结构化数据”,也“不需要创建新的机器可读文件、AI文本文件”。
所以结构化数据是“帮助理解的辅助信号”,不是“被引用的触发开关”。把它当基础卫生做好就行——加准确、别造假(标记的内容必须和页面可见内容一致,否则适得其反),但别指望靠堆schema钻空子。这一关的重点是结构清晰、语义正确,而不是标记的数量。
第四关·可抽取:看懂了,AI能把你的内容整段拎出来引用吗?
AI引用不是引用整个页面,是引用其中某一段。它把你一篇长文切成很多个独立的小块(passage),每块单独评估、单独召回、单独决定要不要引。所以哪怕你整页看懂了,如果没有任何一段是“能被干净拎出来、单独读也成立”的,AI也很难引你。普林斯顿那篇被反复引用的GEO研究就实测过,在内容里加入引用、统计数字和权威引述,能把页面在生成式引擎里的可见度提升最高约40%——本质就是把内容做得更“可抽取”。
这一关偏内容,但有实打实的技术抓手。技术上要保证的是:一个完整的事实或结论,别在HTML结构上被切得七零八落。比如一段话的主语在一个div、数字在另一个被JS折叠的组件、单位又在图片里,AI切块时就拼不回一个完整可引的事实。把一个要点写成一个结构完整的段落或一行表格,主语、结论、数字、单位都在同一个语义块里,AI才好整段拎走。坑在哪:别把可抽取理解成单纯的技术活——内容本身得有值得被引的东西(具体怎么写成可抽取块、怎么靠信息增益让AI选你而不是同行,那是内容层的功夫),技术端只负责“别让承载方式把好内容切碎了”。
第五关·可信与稳定:你的服务器扛得住AI爬虫的抓取量吗?
前四关解决“能不能被读懂引出”,第五关解决“能不能持续、稳定地被抓”。AI爬虫的抓取量已经大得惊人,有数据显示某些AI爬虫的抓取量已经数倍于传统Googlebot。如果你的服务器响应慢、动不动5xx报错或超时,爬虫一次次碰壁,会逐渐减少来抓你的频率,你的抓取预算(crawl budget)就这么悄悄流失了。稳定、够快的服务器,是让AI愿意反复回来抓你新内容的前提。
坑在哪:这一关和上一关有个微妙的取舍。AI爬虫量大,有些站为了省服务器资源会去限速甚至拦截——结果可达关又被自己掐了。该不该为AI爬虫的高流量买单、要不要上按次抓取这类机制,是个商业取舍,但技术上至少要保证:正常放行的那些AI爬虫,你的服务器能稳稳接住。另外别忽视HTTPS、证书有效、重定向链干净这些基础卫生——一条绕好几跳的重定向链、一个过期证书,都可能让爬虫半路放弃。这些不起眼,却是“可信”二字的底色。
新鲜度信号在技术端怎么做才不是假改时间戳?
AI在很多场景下偏好新鲜内容,技术端能做的是把“这页确实更新了”这个信号准确地传出去:sitemap里的lastmod字段如实反映最后修改时间、内容真有实质更新时同步更新页面上的发布/修改日期、保持一个合理的更新节奏让爬虫知道你这站是活的。这些是技术层能给新鲜度添的合法砝码。
坑在哪:千万别把新鲜度做成“假改时间戳”。我见过有人写脚本每天把全站文章的修改日期刷成当天,内容一个字没动,指望靠这个骗AI觉得新鲜。这种操作不光没用,被识别出来还会损害信任——sitemap的lastmod和页面实际内容对不上,反而是个负信号。新鲜度的正解是真更新,技术端只负责把真实的更新如实、及时地告诉爬虫,而不是伪造一个假象。常青的机制类内容本来就不靠刷新鲜度,硬刷只会弄巧成拙。
这五关该按什么顺序排查、先修哪一关?
顺序很重要,因为这五关是串联的,前面断了后面全废。我的排查优先级是严格从前往后:先确认可达(爬虫进得来),再看可渲染(读得到内容),然后才是可理解、可抽取,最后管可信稳定。一个被robots或托管主机拦死的站,你去优化它的结构化数据和可抽取写法,纯属浪费——AI连门都进不来,里面装修得再好也没人看。有个被反复验证的原则:技术修复永远先于内容投入。
坑在哪:人的本能恰恰相反,大家更愿意做看得见、好交差的活——改写文章、加schema,因为这些“有产出感”;而查robots、看托管商有没有拦爬虫这种活,枯燥又没成就感,最容易被跳过。结果就是把钱和精力投在第三、四关,第一关的窟窿却一直漏着。我接项目的铁律是:技术端这条线没从头跑通、没确认AI至少看得见这个站之前,不动任何内容预算。把致命度最高、最靠前的关先堵上,回报永远最快。
日志才是唯一的真相,怎么从访问日志里看出AI爬虫的真实行为?
前面所有自查都是“你主动去探”,而服务器访问日志是“爬虫真实来过留下的脚印”,它才是唯一不会骗你的真相。日志里能看到:哪些AI爬虫真的来过、来的频率、抓了哪些页面、各自拿到的是200还是403/429、抓取集中在哪、又冷落了哪。这些是任何第三方工具都给不了的一手数据。怎么把这件事做成长期能力,我在从访问日志逆向AI爬虫真实偏好那篇里拆成了可复用的步骤。
坑在哪:日志里的user-agent是可以伪造的,别看到一条写着GPTBot的请求就当真是OpenAI来了。真假爬虫要靠反查IP(rDNS)来验证——官方爬虫的来源IP段是公开的,对不上的就是冒充。这点在你打算根据日志做放行/拦截决策时尤其关键,被伪造的爬虫骗着开了口子,等于白防。把日志分析固化成每月一次的例行动作,你才能真正掌握AI到底怎么对待你的站,而不是停留在“我以为我优化了”。
不靠感觉,怎么验证技术端改完真的生效了?
改完得验证,不然你不知道到底通没通。我用一套组合拳:用AI爬虫的UA curl一遍,确认可达和首屏内容(验前两关);用搜索平台的URL检查/抓取工具看渲染后的页面长啥样(验渲染和理解);拉原始HTML确认关键内容和语义标签都在(验可抽取的承载);回到日志看真实抓取记录(验整条链);最后做终极验证——直接去AI引擎里搜你目标查询,看它引不引你、引的是哪页哪段。
坑在哪:别用单一信号下结论。只看“浏览器里页面正常”就当通过,是最常见的误判——浏览器执行了JS,你看到的根本不是AI看到的。也别只看一个AI引擎,不同引擎抓取和渲染能力不一样,得抓共性。还有,技术端的效果有滞后——AI重新抓取、重新进索引、重新被召回引用需要时间,改完当天去搜没被引,不代表没生效,得给它几周再复测。把验证排成固定节奏,而不是改完拍脑袋说“应该好了”。
不同技术栈的站,技术端重心为什么不一样?
同一条诊断线,落到不同技术栈的站,最该使劲的关不一样。纯前端框架/SPA站,第二关可渲染是生死线,别的都还行就这关最容易全盘归零;用WordPress又托管在某些主机上的站,第一关可达里的“托管商静默拦截”是最大暗坑;Shopify这类高度托管的平台,可达和渲染平台基本替你兜住了,重心要往可理解、可抽取移;自建的企业大站,第五关可信稳定(服务器扛抓取量、抓取预算分配)和站点架构更关键。
坑在哪:照搬别人的GEO技术清单,最容易在这里翻车。一个Shopify店主拿着给SPA站写的“赶紧上SSR”清单折腾半天,其实平台早替他渲染好了,纯属白忙;反过来一个SPA站老板看了“加结构化数据”的攻略猛堆schema,可渲染那关还空着,schema标的内容AI根本读不到。务实的做法是先判断自己是什么栈、最可能卡在哪一关,把诊断线的重心压到那一关上,而不是每关平均用力。这也是为什么我前面强调要按这条线逐关自查——先定位,再发力。
出海便携投影仪独立站的技术端排查,是怎么一步步做的?
用一个真实类型的场景串一遍。一个做出海家用便携投影仪的独立站,产品本身不差——主打ANSI流明够亮、原生1080P分辨率、自动梯形校正、短投射比适合小卧室,这些都是实打实可核查的参数。内容也写了一堆选购指南,但老板发现,用户在AI里问“适合小卧室的便携投影仪推荐”,从来没出现过他家。第一反应是内容不够好,想再砸钱写。保哥让他先别动内容,按诊断线走一遍技术端。
第一关可达:curl模拟ClaudeBot一抓,返回403——站托管在一个默认拦AI爬虫的平台上,爬虫根本没进门。第二关可渲染:站是SPA架构,拉原始HTML一看,产品规格全是空的,参数都靠JS在tab里动态加载,AI即便进来也读不到那些关键参数。第三、四关:规格表干脆做成了一张图片,AI连文字都提不出。问题全在技术端,跟内容质量没半毛钱关系。
修法也对应着来:去托管商后台放行主流AI爬虫(可达),把规格页和产品页改成服务端渲染、关键参数进静态HTML(可渲染),把图片规格表重写成真实的HTML表格、每行参数主语单位齐全(可理解+可抽取),最后盯日志确认AI爬虫真的开始来抓了。几周后复测,目标查询里开始出现他家产品。整个过程没改一个字的内容卖点,只是把技术地基从塌的修成通的。这就是技术端作为及格线的意义——它决定的不是好坏,是有没有。
技术端做对了,是不是就一定会被AI引用了?
不是。技术端做对,换来的是“AI看得见你、读得懂你、能抽取你”——也就是拿到了参赛资格,进了候选池。但从“被抓到”到“被引用”,中间还隔着内容质量这道坎。AI在候选里挑谁来引,靠的是内容本身够不够好、有没有信息增益、是不是比同行那篇更值得引。被索引、被抓取,不等于被引用,这是两件事。
坑在哪:别把技术端当成GEO的全部,做完技术就以为大功告成。我见过把技术端打磨到极致、却始终没什么引用的站,一看内容——全是同质化的车轱辘话,AI凭什么从一堆一样的页面里挑你?技术端解决的是“能不能被看见”,内容解决的是“看见了凭什么选你”。两条腿都得有。所以技术端跑通之后,发力点就该交棒给内容了——这也是为什么我反复说技术端是及格线:它是必要条件,不是充分条件。
技术端做完就一劳永逸了吗?最容易踩的几个坑是什么?
技术端不是一次性工程,它会自己悄悄退化。集中说几个我见得最多的坑。第一,只盯内容GEO、完全不查技术端,结果AI压根没读到,是最大也最普遍的坑。第二,迷信结构化数据,以为加了schema就会被引用,前面说过Google官方亲口否了。第三,以为技术端做完就一劳永逸——托管商一次升级、CDN一次策略变更、前端一次重构,都可能在你不知情时把某一关重新焊死,AI可见度无声归零。
第四,为了讨好AI爬虫把闸门全放开,结果服务器被高频抓取薅垮,或者被伪造的爬虫钻空子,可达和可信稳定打架。第五,把“被AI抓到”等同于“被AI引用”,看到日志里爬虫来了就放心,却没去AI引擎里实测到底引没引。坑在哪:这几个坑的共性是“以为做完了”。技术端得有个复查机制——我的习惯是季度性把这条诊断线重跑一遍,再配合每月看一次日志,确保没有哪一关在你没注意的时候又断了。把它当成持续监控的制度,而不是做完就归档的一次性项目。
AI会不会以后绕过网站直接读Feed,技术端就白做了?
有人担心:电商不是有商品Feed吗,AI直接读Feed不就行了,何必费劲优化网页技术端?短期内不用担心这个。Feed给的是结构化的单品参数(价格、库存、规格),适合做候选筛选;但AI要理解品类、对比优劣、给出选购判断,还得读你的网页内容——Feed给不了“为什么适合小卧室”这种判断依据。而且AI的实时回答大量依赖对网页的实时抓取(grounding),这条管道短期不会消失。
坑在哪:别因为这种“未来可能变”的猜测,就拖着不做眼下确定有用的事。技术端这条诊断线,今天就实打实决定着你能不能被AI看见,这是确定的收益;而“AI全面绕过网页”是个还没发生、且短期看不到的假设。我的判断是:网页技术端在可见的将来仍是GEO的地基,Feed是补充不是替代。与其为遥远的不确定性焦虑,不如先把今天这五关查通——这才是务实的做法。
一个人或小团队,技术端第一周该先动哪里?
不用一上来就想全做完,给个能落地的第一周清单。第一天,curl自查可达:用主流AI爬虫的UA抓自己的关键页面,看返回码,确认没被robots或托管商拦。第二天,查可渲染:拉原始HTML,看最想被引用的那批页面正文在不在源码里,SPA站重点查这个。第三天,扫可理解:看关键信息有没有被埋进图片、JS折叠组件,把规格表这种重灾区揪出来。这三天就能定位出绝大多数致命问题。
剩下的时间,把发现的最致命那一关先修掉(通常是可达或可渲染,一关修好可见度就能有质变),再去翻服务器日志看AI爬虫的真实脚印。坑在哪:小团队最容易犯的错是顺序反了——一上来纠结要不要给每页加结构化数据、要不要写得更可抽取,却没发现爬虫第一关就被挡在门外。务实的顺序永远是“先确认看得见,再谈优化”:把可达、可渲染这两关先通了,让AI至少能读到你,再把功夫往后面几关和内容上铺。技术端是GEO里最不需要花钱、却最容易被默认配置坑掉的一层,老老实实一关一关查通,比追任何新概念都划算。
常见问题解答
我的内容质量很高,为什么AI搜索还是从来不引用我?
八成卡在技术端某一关,而不是内容。最常见的是两种:一是AI爬虫被robots、CDN、WAF或托管主机拦在门外(可达关),AI压根没抓到你;二是你的站是SPA/纯前端渲染,AI爬虫不执行JS,抓回去的是空壳(可渲染关)。先用AI爬虫的user-agent curl自查返回码,再拉原始HTML看正文在不在源码里,定位到具体哪一关断了,比反复改内容有效得多。
GEO技术端和传统技术SEO是同一回事吗,做了一套是不是另一套就不用做?
大量重叠但不完全等同。可抓取、可渲染这两关,给Google排名做和给AI引用做基本是同一件事,所以技术SEO的底子能直接复用。但GEO技术端多了两层重心:一是AI爬虫专属的可达问题(很多AI bot的UA被单独拦,且常被托管商静默拦截),二是可抽取(passage级别的承载方式)。把传统技术SEO做扎实是基础,再针对AI爬虫补上这两层。
给页面加了结构化数据,是不是就能被AI引用了?
不能。这是被误导最深的一条。Google官方明确说过,出现在AI Overviews或AI Mode没有额外要求,不需要特殊的schema.org结构化数据,也不用建AI专用文件。结构化数据是帮助理解的辅助信号,该加的准确加上、内容必须和标记一致,但它不是被引用的开关。被不被引,最终看内容质量和可抽取性,不是看你标了多少schema。
怎么确认我的站到底被哪些AI爬虫抓了、有没有被偷偷拦?
最可靠的是看服务器访问日志,它记录了哪些爬虫真来过、拿到的是200还是403/429。配合用各家AI爬虫的UA做curl自查交叉验证。注意日志里的user-agent能伪造,要根据来源IP反查(rDNS)验证真假。如果发现AI爬虫拿到的是403/429而你自己没设过拦截,多半是CDN、WAF或托管主机那一层干的,去它们后台找bot管理相关开关。
我是Shopify/WordPress这类托管平台,技术端还有得优化吗?
有,但重心不同。Shopify这类平台把可达和渲染基本替你兜住了,你该把精力放在可理解和可抽取——别把关键参数做成图片、用语义化的标题和表格、内容写成能被整段拎出的块。WordPress要特别警惕托管主机静默拦AI爬虫这个暗坑,先用AI爬虫UA自查可达。判断清楚自己平台最可能卡哪一关,把力气压到那关,别照搬给自建站写的清单。
权威参考资料
本文标题:《GEO技术端这样优化,AI爬虫才能抓得到、读得懂、引得出》
本文链接:https://zhangwenbao.com/geo-technical-optimization-crawl-render-extract-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0