谷歌排名背后的数学:你优化的从来不是内容,而是能被算成数字的信号
本文目录
摘要:你以为自己在优化“内容质量”“专业度”“信任感”,但谷歌的排名系统里根本没有这几个字段——它只认能被算成数字的东西。每一次排名,本质上都是一组数值特征喂进一个函数、吐出一个分数、再按分数排序。看不懂这层翻译,你做的大半优化其实是在对着一个不存在的输入使劲。这篇把谷歌排名背后真正在跑的数学摊开讲:检索阶段的BM25饱和曲线、稠密向量的余弦相似度、PageRank的随机游走、NavBoost的误差校正、以及把这一切拧成一个分数的学习排序模型——再翻译回一个出海独立站该死磕的那几个数字。
先抛一个会得罪人的判断:绝大多数中文SEO教程教你的“多写优质内容、提升专业度、建立信任”,在谷歌的排名管线里没有任何一个直接对应的旋钮。不是这些词没用,而是它们必须先被拆成机器能测量的代理变量,才有资格进入排名函数。你优化的若是那个抽象标签本身,等于在跟一个听不懂这个词的系统对话。
保哥做了二十多年SEO,这些年主要给出海DTC和B2B外贸独立站做顾问。见过太多人把“我内容明明很专业为什么不排名”挂在嘴边,却从没想过:谷歌凭什么知道你专业?它能读到的,从来不是“专业”这两个字,而是一堆它能编码、能比较、能塞进函数的数值信号。今天这篇,我们不讲玄学,只讲数学——讲清楚每一个排名决策背后,那条“输入→函数→数值→比较→位置”的链路到底怎么走。搞懂了它,你才知道自己该把力气使在哪。
为什么说搜索引擎本质上是一台数学机器?
这句话不是比喻,是字面意思。当谷歌为一个查询返回10条结果时,它执行的是一个排序操作:文档A排在文档B上面,只因为系统给A算出的综合分数比B高。而这个分数,百分之百来自可以被转化成数值的信号。
这是一条硬约束,不是设计者的偏好。排名函数接收输入、产出一个有序列表。如果某个东西不能被系统观测、编码、建模成一个特征值,它就进不了这个函数,就影响不了输出,也就影响不了你的位置。一个网站再“有情怀”、文案再“打动人”,只要这份打动没能转化成可测量的行为信号(比如更高的点击留存),它对排名的贡献就是零。
这套逻辑其实一点都不新。信息检索(Information Retrieval)这门学科积累了几十年的公开研究,谷歌的排名系统就站在这堆文献的肩膀上。数学是已知的、可查的,真正的问题只在于:你是在优化数学本身,还是在优化关于数学的叙事。前者是工程,后者是自我感动。
所以我常跟客户说,做SEO第一步要换一副眼镜:别再问“这篇内容好不好”,改成问“这篇内容里,有哪些东西能被谷歌算成数字,这些数字够不够高”。这个视角的切换,是精准优化和瞎使劲之间的分水岭。后面几节,我们就顺着这条链路,一个数字一个数字地拆。
你以为的“内容质量”,到底被谷歌翻译成了哪些数字?
很多听起来根本没法量化的东西,其实每天都在通过代理变量(proxy feature)被悄悄量化。所谓代理变量,就是“你想衡量A,但A测不了,于是你去测一组和A高度相关、又恰好能测的B、C、D”。谷歌干的就是这件事。
我把几个最常被误解的抽象概念,和它们背后的真实数值代理,列成一张对照表,你一看就明白“优化叙事”和“优化数学”差在哪:
| 你嘴上说的 | 谷歌实际在测的代理变量 |
|---|---|
| 内容质量 | 语言模型给出的相关性评分、内容结构特征(标题层级、信息密度)、用户行为模式(点击、停留、回退) |
| 品牌信任度 | 品牌词的搜索量、结果中的点击偏好、链接画像的形态特征 |
| 专业性(权威) | 实体关联强度、作者与机构信号、外部引用模式、链接图谱中的位置 |
| 相关性 | 词法匹配分(BM25)、查询与文档向量的余弦相似度 |
看懂这张表,你就明白一件事:抽象标签本身从不进入排名函数,进入的永远是它被拆解后的那些可测量代理变量。系统并不“理解”什么叫专业,它只是在处理“实体是否能消歧到知识图谱节点”“作者信号在多个数据源里是否一致”这类纯数值的东西。
这恰恰也是希望所在。它意味着“信任”“专业”这类虚词并非和排名绝缘——只要你能把它们落地成系统能算的代理信号,就能起作用。一个做工业阀门出口的B2B站,空喊“我们是行业专家”毫无意义;但如果它把产品的合规认证号、材质参数、第三方检测报告、行业协会引用、技术负责人的署名履历,一致地铺在站内站外多个触点上,谷歌就能把这些拼成“高实体关联 + 强作者信号”的数值——“专业”这个词,这才算翻译成了机器听得懂的语言。
所以,每当你想优化一个抽象目标,先逼自己回答一句:它对应的可测量代理是什么?答不上来,这个优化大概率是空转。这个习惯,比任何工具都值钱。
页面还没排名,先得过两道检索关——词法和语义谁更重要?
在谈排名之前,得先谈一件更前置的事:你的页面得先被“检索”出来,进入候选池,才有资格被排名。谷歌索引里躺着数千亿个文档,但对任何一个具体查询,它只会真正评分其中的几千个。决定哪几千个能进这个候选集的,就是检索阶段。
检索不是单一动作,而是多路并行的召回过程。其中两条主干道最关键:一条是词法匹配(lexical matching),靠的是关键词字面命中;另一条是稠密向量检索(dense retrieval),靠的是语义接近。此外还有查询改写、历史点击缓存等并行通道汇入同一个候选池,但抓住这两条主干道,核心机制就懂了七八成。
这里有个常被忽略的残酷事实:这两道关你至少得过一道,否则后面再强的权威、再好的用户互动都救不了你——因为你根本不在池子里。很多老站长疑惑“我外链那么硬怎么新页面没动静”,排查到最后往往发现,那个页面连候选池都没进去,权威信号压根没机会发挥。
那两道关哪个更重要?没有标准答案,要看查询类型。像“316不锈钢法兰DN50尺寸表”这种长尾、术语精确的查询,词法匹配的分量极重——用户用的就是这几个精确词,字面命中天然占优;而像“工厂阀门总漏水怎么排查”这种口语化、意图模糊的查询,语义检索的权重明显抬高,因为命中的关键不在用词一不一样,而在意思近不近。理解这一点,你就懂了为什么B2B技术站要把精确术语铺扎实,同时又不能写成只有机器看得懂的关键词清单。
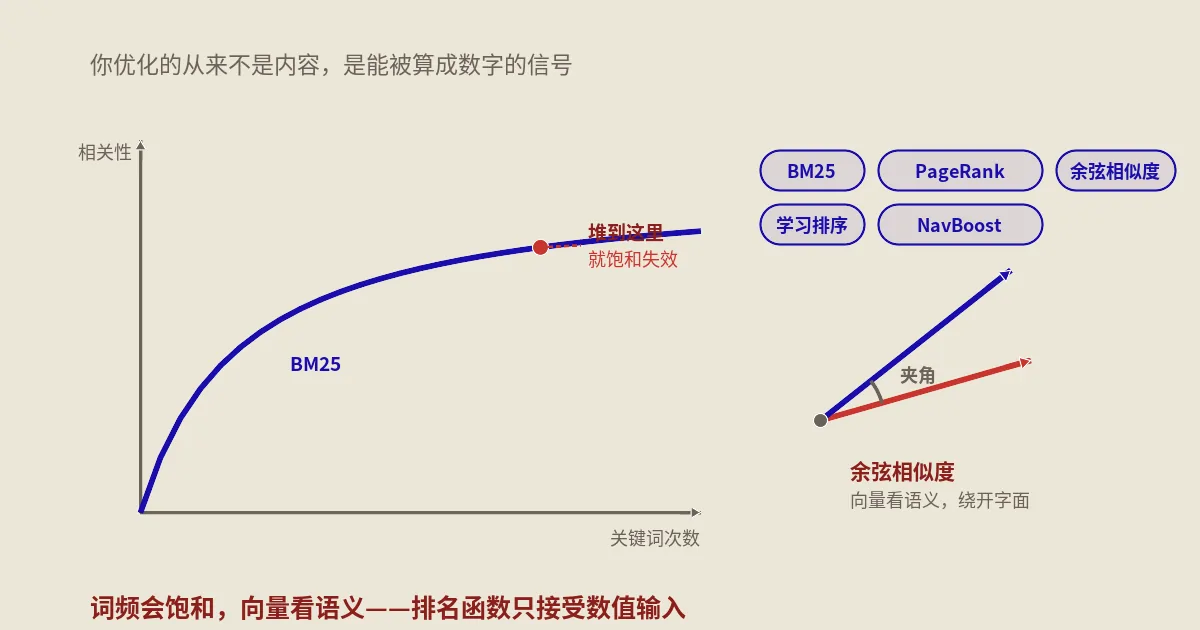
BM25那条饱和曲线,为什么能解释关键词堆砌为什么没用?
词法检索这条线,经典的数学模型叫BM25,由 Robertson和Zaragoza在概率相关性框架综述里形式化,至今仍是Elasticsearch、Lucene、OpenSearch这些主流检索系统的基线。即便现代搜索引擎叠加了神经检索,词法匹配依然是召回阶段甩不掉的地基。谷歌内部用的肯定是大量魔改变体,但BM25是理解词法检索原理最好的数学原型——它把抽象的“匹配”变得肉眼可见。
BM25衡量三件事:查询词在文档里出现的频率、这个词在整个索引里有多稀有、文档相对平均长度是长是短。它的计算公式长这样(放进代码块,免得符号吓到你):
score(D, Q) = Σ IDF(qi) × [ f(qi,D) × (k1 + 1) ]
÷ [ f(qi,D) + k1 × (1 − b + b × |D| ÷ avgdl) ]
别被吓退,逐项拆开特别好懂。f(qi,D) 是词在文档里的出现次数;IDF(qi) 是逆文档频率,越稀有的词分越高(“法兰”比“的”值钱);|D| ÷ avgdl 是文档长度除以平均长度,做长度归一化;k1 和 b 是两个调节旋钮,经验上 k1 取1.2到2.0、b 取0.75左右。
真正要命的是这个公式藏着一条饱和曲线。注意分母里也有 f(qi,D):当一个词出现得越来越多,分子分母同时变大,整个比值会逐渐逼近一个上限 k1 + 1 而不再增长。翻译成人话——一个关键词出现第10次带来的加分,远远小于它第1次出现;堆到第50次,几乎一点用都没有。这就是关键词堆砌在数学层面注定失效的根因:不管谷歌用的是哪个BM25变体,底层那条饱和曲线都在惩罚你。
还有一个反常识但极其重要的点:不存在一个固定的“好的BM25分数”。所有分数都是相对同一查询下其他文档而言的。你不需要达到某个绝对数字,你只需要比你的竞争对手高。这彻底改变了内容策略——你要做的不是“把关键词堆够”,而是“在同一主题下,用词的覆盖度和精准度压过排在你前面的那几个页面”。这也是为什么我总建议客户先去拆解SERP前5名实际在用哪些词、哪些近义术语、哪些长尾变体,而不是闷头对着一个词反复堆。这背后的相似度比对逻辑,和我在用余弦相似度做电商内容语义优化那篇里讲的语义维度是一体两面,可以对照着看。
向量、余弦、嵌入:语义检索到底在算什么相似度?
词法匹配有个天生的短板:它认字面,不认意思。用户搜“工厂阀门漏液”,你页面写的是“工业阀体渗漏处理”,字面几乎不重合,纯靠BM25很可能漏掉你。稠密向量检索就是来补这个缺口的。
它的做法是:把查询和文档分别转化成一个高维向量——一串浮点数,比如768维或更高。这串数字是“意义的数值表示”,意思相近的文本,向量在空间里的位置也相近。然后用余弦相似度(cosine similarity)衡量两个向量的夹角:
cos(θ) = (A · B) ÷ ( |A| × |B| )
分子是两个向量的点积,分母是各自模长的乘积。结果落在0到1之间,越接近1表示语义越接近。妙处在于:它衡量的是“方向”而非“长度”,所以一篇短问答和一篇长文档,只要讲的是同一件事,余弦相似度依然可以很高。这就是为什么“漏液”和“渗漏处理”字面对不上,语义却能被算到一块去。
真实的谷歌系统当然比一次余弦比对复杂得多——RankBrain、BERT、MUM这些涉及交叉编码、上下文理解、多任务架构,远不是基础向量比较能概括的。语义检索的演化脉络,从Hummingbird到BERT再到MUM,我在谷歌语义搜索理解能力的演进史里专门梳理过。但万变不离其宗:语言被转成数字,数字之间被比较。架构各异,这个底层思想恒定不变。
对内容操作的启示很直接:不要再执着于把目标关键词一字不差地塞进每个段落。语义检索意味着,你应该围绕一个主题,把相关概念、上下位词、用户会用的各种说法都自然覆盖到——让你这篇文档的向量,在语义空间里牢牢落在那个主题的核心区。一个做户外储能电源的出海站,与其在“便携电源”这个词上死磕密度,不如把“露营供电、停电应急、房车改装、太阳能板兼容、循环寿命”这些语义邻居都讲透,向量自然就漂亮。
这里还藏着一个反常识的推论,值得专门点破:词法和语义这两条检索通道,对内容的要求其实是有张力的。纯堆关键词,词法分可能上去,但读起来生硬、语义割裂,向量反而漂移;纯讲故事、刻意回避目标词,语义也许不差,词法召回却可能直接漏掉你。真正稳的内容,是两条通道都喂饱:精确术语该出现的地方自然出现(喂词法),同时把主题的语义邻域讲透、读起来像人话(喂语义)。这就是为什么我反对“要么堆词、要么纯创作”的二元对立——数学告诉你,召回是多通道的,你得同时讨好两套机制。B2B技术站尤其要拿捏这个平衡:精确型号、参数、认证编号一个都不能少(这是采购商搜索时的字面命中),但通篇只有参数表、没有把应用场景和选型逻辑讲清楚,语义向量又会显得单薄。两手都要硬,才是检索阶段的最优解。
通过检索只是入场——排名为什么是一条多层流水线而不是一次打分?
很多人脑子里的排名模型是:文档拿到一个总分,然后按分数从高到低排。这个模型错得很彻底。现代搜索排名是一条多阶段的流水线,不是一次性打分。
一个典型的架构大致是这样几层串起来的:
- 先对整个候选集做一轮轻量级粗排,快速筛掉大部分;
- 再用更深、更贵的重排序模型对剩下的每个文档做精细计算;
- 接着过一道道质量与垃圾分类器,该过滤的过滤、该降权的降权;
- 然后做多样性与时效性调整,避免10条结果长一个样;
- 最后是展示层决策——要不要出精选摘要、知识面板、结果分组。
这条流水线最值钱的认知是:很多“我页面明明相关却不排名”的情况,根本不是相关性出了问题,而是在下游某一层闸门被过滤或降权了。把排名理解成“一连串闸门”而不是“一个单一分数”,会彻底改变你诊断问题的方式——你会去逐层排查“我是卡在哪一道闸”,而不是笼统地归咎于“内容不行”。
顺带说,这条流水线和谷歌的分层索引机制是上下游关系:候选从哪一层索引里捞,本身就由分层决定;捞出来之后才进粗排重排。关于索引怎么分层、页面被丢进哪一层会直接决定它有没有资格进候选池,我在谷歌分层索引(Base、Zeppelin、Landfill)机制那篇里拆得很细,和本文正好首尾衔接。但无论哪一层,约束始终如一:系统不能把它表达成数字的东西,这一层就处理不了。下面三节,我们就挑流水线里最关键的三类数值信号,逐个看它们的数学长什么样。
PageRank的随机游走模型,二十年后还在以什么形式活着?
基于链接的权威性,数学原型是 PageRank算法。它的核心洞见一句话能说清:如果很多重要的页面链接到你,你就是重要的。算法把整个互联网建模成一张有向图,每个页面是节点,每条链接是一条有向边,然后计算一个概率分布——一个随机浏览者沿着链接不停乱点,最终停在任何一个页面上的概率。这个概率,就是该页面的权威值。它的迭代公式是:
PR(A) = (1 − d) ÷ N + d × Σ [ PR(Ti) ÷ C(Ti) ]
其中 d 是阻尼系数,经典取值0.85,代表“浏览者继续点链接而不是随机跳走的概率”;N 是页面总数;Ti 是所有链接到A的页面;C(Ti) 是 Ti 的出链数量。这个公式得反复迭代(数学上叫幂迭代)直到收敛,最终每个页面拿到一个稳定的权威值。它本质上是在求一个巨大矩阵的主特征向量——这就是PageRank的数学骨架。
有意思的是 C(Ti) 这个分母:一个页面的权威是被它所有出链平摊的。一个DR很高的页面,如果链了500个站,分到你头上的那一份就被稀释得很薄;反过来,一个权威页面正文里那条几乎是独家指向你的链接,传递的权重要重得多。这就是为什么“一条高质量正文链接顶一百条页脚批量链接”——不是玄学,是分母在起作用。关于不同形态的链接(按钮链接、JS链接)到底传不传权重,我在按钮链接和JS链接会不会稀释权威里有更细的拆解。
当然,谷歌现在用的早不是1998年那版原始PageRank了。它用的是更精密的变体,比如Nearest Seed:从一组受信任的“种子页面”出发,向外传播权威,离种子越近的页面拿到的信任越高。种子集不公开,所以第三方工具只能用经典PageRank去近似。但原理没变——权威性从链接图谱里算出来,输出是一个数值。对出海站的启示也没变:你要争取的,是来自主题相关、本身离“可信种子”近的权威站点的正文链接,而不是一堆离种子十万八千里的目录页、站群页给你投的废票。
NavBoost不是给好内容发奖,它到底在校正什么?
用户行为信号这块,绕不开NavBoost。但它的运作方式,和大多数SEO圈描述的“点击越多排名越高”差得很远。
NavBoost不是简单地“奖励好内容、给它更高排名”。它的真实角色更接近误差校正:识别排名模型的预测和用户实际满意度之间的偏差,然后做修正。打个比方——模型把某个页面排在第3,但用户一次次跳过前两名、专挑第3个点进去而且不回退,这个行为信号就会告诉系统:你这个排序错了,该把它往上提。它修正的是模型预测的错位,不是给页面发小红花。
更关键的是,喂进去的不是原始点击次数。NavBoost至少做了三件事来净化数据:
- 校正位置偏差——排名越靠前的结果天然点击越多,这部分“位置红利”会被扣掉,不然永远是富者愈富;
- 按查询类型和用户群体分段——同一个页面,对不同人群、不同查询意图,信号是分开统计的;
- 在时间窗口内聚合——过滤掉短期噪音和刷量,看的是一段时间内的稳定趋势。
而且很多信号是在查询层面而非单个文档层面运作的——系统在调整的,是它对“这类查询的用户到底想要什么”的整体理解,而不只是给某个页面单独打分。这就解释了一个常见现象:你某篇文章排名突然集体波动,未必是你这页出了事,可能是谷歌对整类查询的意图判断变了。所以指望靠“找人刷点击”来骗NavBoost,几乎必然失败:位置偏差被校正、噪音被时间窗口过滤、还分人群分查询——你那点小动作,在统计上根本激不起水花。能真正喂出正向行为信号的,只有“标题让人想点 + 内容让人不想回退”这一条老实路。
信号最终怎么拧成一个分数——加权求和还是机器学习?
到这里你可能会问:这么多信号——BM25、向量相似度、PageRank、行为信号、实体关联——最后是怎么合并成一个分数的?是不是各自乘个权重加起来?
早期检索系统确实是这么干的,固定的线性公式:score = w1·x1 + w2·x2 + w3·x3,每个信号一个静态权重,人工拍板。但现代搜索引擎早就把这套淘汰了。当前的标准做法叫学习排序(Learning to Rank,LTR):在海量人工标注的数据上训练一个机器学习模型,让它自己学出最优排序。LTR和固定公式的根本区别有三条,每一条都直接影响你的内容策略:
第一,特征之间是非线性关系。一个页面的链接权威,在“买工业空压机”这种商业查询里可能权重极高,但在“空压机异响怎么排查”这种信息查询里权重明显下降。模型是从数据里学出这些依赖上下文的交互的,不是人写死的系数。
第二,特征权重是动态的。它随查询类型、意图、垂直领域而变。根本不存在“一个”排名公式——存在的是一族函数,模型根据查询上下文在其中切换。所以“谷歌排名因素权重表”这种东西天然是伪命题:权重压根不固定。
第三,特征之间会交互。“高权威 + 低相关”这个组合产生的效果,不等于两个信号单独作用的简单相加。这种跨特征交互,正是神经重排序器专门设计来捕捉的。一个站权威再高,内容和查询不对路,照样上不去——因为模型学到了这俩特征的负向交互。
但请记牢一件事:模型再复杂,输入的约束丝毫没变——进入LTR模型的每一个特征,仍然必须是可计算的数值。数字进去,分数出来,按分数排序。LTR把“怎么组合”这件事变得无比精妙,却没有改变“只有数字才能进门”这条铁律。这一圈绕回来,正好印证了开篇那句话:你能优化的,永远只是那些能被算成数字的东西。
搞懂这套数学,到底能帮你少走哪些弯路?
你可能会想:我又不写搜索引擎,懂这些数学有什么用?用处大了——它能让你一眼识破行业里大半流传已久的伪命题,把预算和精力从无效动作上抠回来。下面几条,都是被前面的数学直接证伪的常见误区。
误区一:“关键词密度要控制在2% 到3%”。BM25的饱和曲线已经说清楚了,词频的边际收益递减,根本不存在一个魔法密度。死磕密度,要么堆到触发垃圾信号,要么白费功夫。正解是覆盖主题相关的词群,而不是把一个词数到第几次。
误区二:“外链越多,排名越好”。PageRank的分母 C(Ti) 告诉你,权威是被出链平摊的。100条来自高出链、低权威页面的链接,加起来可能不如1条来自权威页正文的链接。把买链接的预算砍掉九成,集中火力拿那几条真正算数的,回报立刻不一样。
误区三:“刷点击、刷停留能把排名顶上去”。NavBoost的位置偏差校正、分段聚合、时间窗口过滤,专门用来识别这种异常。小打小闹激不起水花,规模大了反而暴露。与其花钱刷量,不如把这笔钱投在让标题更想被点、内容更不想被关上。
误区四:“盯着一张‘排名因素权重表’优化就行”。学习排序是一族随上下文切换的函数,权重动态变化。任何号称“标题占18%、外链占22%”的精确权重表都是臆造。你该做的不是对着一张假表分配精力,而是判断你的目标查询属于哪种意图,再决定相关性和权威哪个该加码。
误区五:“我相关性做满了,没排名一定是内容不够好”。排名是条多层流水线,相关性只是第一关。很多时候你是在下游被质量分类器降权、或者根本没进对候选池。把所有锅都甩给“内容质量”,会让你在错误的方向上反复加戏。先定位卡在哪一层,再对症下药。
你看,这五条几乎涵盖了中文SEO圈最常见的执念。它们之所以能流传这么久,正是因为大多数人从没把底层数学搞清楚,只能人云亦云。一旦你理解了函数、饱和曲线、随机游走和误差校正,这些伪命题就再也忽悠不到你——这就是懂数学最实在的回报:省钱、省力、不被带偏。
把数学翻译回操作:一个出海站到底该优化哪几个数字?
讲了这么多数学,落到操作上其实可以大幅简化。绝大多数SEO动作,都能归进两个核心变量:权威(Authority)× 相关(Relevance)= 排名。用户行为、内容质量、实体可信度、技术可达性、时效性,最终都是通过具体特征影响这两个维度,或者作用在下游的重排阶段。把这两件事拆开,你就知道每个动作在喂哪个数字。
第一类,优化相关性——把检索和相关性信号做到最强:
- URL slug和H1精准反映查询意图,别让机器猜你在讲什么;
- 内容与查询及其语义邻居达到高相似度,围绕主题把相关概念覆盖全;
- 用词向排名靠前的页面对齐——不是抄它们,而是同一个主题本就需要同一套词汇,而数学就是这么衡量的。
第二类,建设权威性——积累链接图谱算法会奖励的信号:
- 争取来自主题相关、本身高权威来源的正文链接,盯质量不盯数量;
- 用内链结构把权威导向真正需要它的页面(内链是你唯一能自主分配权威的杠杆);
- 让整体链接画像在图分析里看起来自然,别留下批量购买的形态痕迹。
第三类,赚取正向用户信号——让行为数据去确认(或修正)排名模型的预测:
- 标题要能在SERP里赢得点击(这是喂给行为信号的第一口);
- 内容要真能解决查询、不让用户跳回去再点别人;
- 记住这些行为不是“对好内容的奖励”,而是保持排名模型准确的校准数据。
保哥去年帮一个做精密轴承出口的B2B独立站做诊断,就是用这套“拆数字”的框架。站长一开始执着于在首页堆“高品质轴承制造商”这类词,密度做到3% 还嫌不够,排名纹丝不动。我们做了三件事:把产品页的术语对齐到采购商真实会搜的精确型号和参数(喂相关性)、把一篇被几家行业媒体引用的技术白皮书用内链导权到核心产品页(喂权威)、把标题从自夸式改成“DN50法兰式球阀选型对照表”这种点击意图明确的句式(喂行为信号)。三个月后,核心型号词进了首页。变的不是“内容质量”这个虚词,变的是那几个能被算成数字的具体信号。
这就是把数学翻译回操作的全部要义:每做一个动作前,先问它在喂哪个数字;喂不到任何数字的动作,无论听起来多正确,都是自我感动。谷歌是一台数学机器,你得用它听得懂的语言跟它说话。把这套“先翻译成数字、再判断该不该做”的思维习惯练成肌肉记忆,你会发现自己对各种SEO玄学的免疫力肉眼可见地变强——别人还在为一条来路不明的“技巧”焦虑时,你已经能一眼看穿它到底喂没喂到任何一个真实可计算的信号。这份判断力,比任何单一技巧都更值钱,也更持久。
常见问题解答
关于谷歌排名的数学底层,几个被问到最多、也最容易踩坑的问题,集中答一下。
谷歌排名因素权重表到底靠不靠谱?基本是伪命题。谷歌用学习排序,特征权重随查询类型动态变化,根本不存在一张固定权重表。同一个信号在商业查询和信息查询里的分量可能天差地别,号称精确到百分比的权重榜都该打个问号。
关键词密度做到多少最合适?没有最优密度这回事。BM25有饱和曲线,一个词堆到一定次数后加分趋近于零,堆得越多越像作弊。与其纠结密度,不如把同主题的相关词、近义术语自然覆盖全,让语义向量落在主题核心区。
刷点击量能不能骗到NavBoost提升排名?几乎不可能。NavBoost会校正位置偏差、按查询和人群分段、在时间窗口里聚合过滤噪音,小规模刷量在统计上激不起水花,还可能被判为异常。把标题和内容做到让人想点、不想回退才是正路。
外链是不是越多越好?不是。PageRank里一个页面的权威被它所有出链平摊,来自批量站群页的链接稀释严重、近乎废票。一条来自高权威站点正文、几乎独家指向你的链接,胜过一百条页脚目录链接。盯质量不盯数量。
我内容写得很专业,为什么还是不排名?因为谷歌读不到“专业”这两个字,只能读它的代理信号——实体关联、作者署名、外部引用、行为数据。把专业落地成这些可测量信号它才算数。也可能你卡在排名流水线下游某道闸,而非相关性问题。
学习排序和老式加权公式最大的区别是什么?老式公式是线性的、权重人工写死;学习排序是机器从标注数据里学出来的,特征非线性、权重随上下文动态切换、还能捕捉特征交互。所以不存在单一排名公式,只有一族随查询切换的函数。
这些数学对中小出海站有实际用处吗?有,而且能省力。看懂数学你就知道哪些动作在喂可计算信号、哪些是自我感动。中小站资源有限,更该把力气集中在能被算成数字的权威与相关上,别在没有对应代理变量的虚目标上空转。
权威参考资料
本文标题:《谷歌排名背后的数学:你优化的从来不是内容,而是能被算成数字的信号》
本文链接:https://zhangwenbao.com/google-ranking-math-foundations.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0