Headless CMS上线SEO集体失分?sitemap、重定向这套基建得自己重搭
本文目录
- 为什么Headless CMS一上线,SEO反而集体失分?
- 传统WordPress帮你默默做了哪些SEO基础设施?
- Headless架构里,这些基础设施到底搬到了哪一层?
- meta标签和标题,该由CMS建模还是前端写死?
- sitemap没了自动生成,Headless怎么动态生成才不漏页?
- canonical在Headless里为什么特别容易出错?
- 最容易被忘记的一层:历史重定向规则迁到哪去了?
- 结构化数据在Headless里,该在哪一层注入?
- 内容预览和发布工作流,怎么不把draft泄漏给谷歌?
- Headless SEO基础设施重建,保哥的迁移检查清单长什么样?
- 这套Headless迁移,最常踩的5个坑是什么?
- 常见问题解答
- Headless CMS真的会让SEO变差吗,问题到底出在哪?
- meta标题和描述,该在CMS里建模还是在前端代码里写?
- Headless站的sitemap怎么生成才不会漏页或过期?
- 从WordPress迁到Headless,历史的301重定向规则怎么办?
- 结构化数据在Headless架构里,应该谁来注入?
- 内容预览和草稿,怎么防止被谷歌抓到泄漏出去?
- 权威参考资料
摘要:从WordPress迁到Headless CMS,团队往往只盯着前端多快、内容建模多优雅,却忽略一件要命的事:Yoast那套你用了多年的SEO基础设施,解耦那一刻全没了。sitemap不再自动生成、meta没人输出、canonical没人管、历史301重定向不知去向、结构化数据也得手动注入。这些活在传统CMS里是插件默默替你做的,到Headless全得自己在前端或边缘层重建。这篇不讲该不该上Headless,只把这套消失的SEO基建一项项拆开:原来在哪、该搬哪层、谁来重建、最容易在哪翻车。
为什么Headless CMS一上线,SEO反而集体失分?
保哥这两年接的诊断盘子里,有一类越来越常见:团队雄心勃勃把站从WordPress迁到Headless CMS,前端用上了最新的框架,首屏快得飞起,内容建模也做得干净漂亮。可上线两三个月后一看数据,傻眼了——自然流量没涨反而往下掉,老页面排名集体滑坡,新内容半天进不了索引。
团队第一反应往往是怀疑内容质量或者谷歌算法变了,查来查去都不对。保哥过去一看,根子几乎都在同一个地方:那套你用了好几年、早就习以为常的SEO基础设施,在解耦那一刻悄无声息地全没了,而没有一个人意识到它本来就需要被重建。
这事的隐蔽性在于,传统WordPress加Yoast的组合,把太多SEO的脏活累活默默替你干了。sitemap自动生成、每个页面的meta标签输出、canonical标记、面包屑的结构化数据、slug改动后的自动重定向——这些你可能从没手动配过,它们就一直在那儿运转。装个插件,全有了。
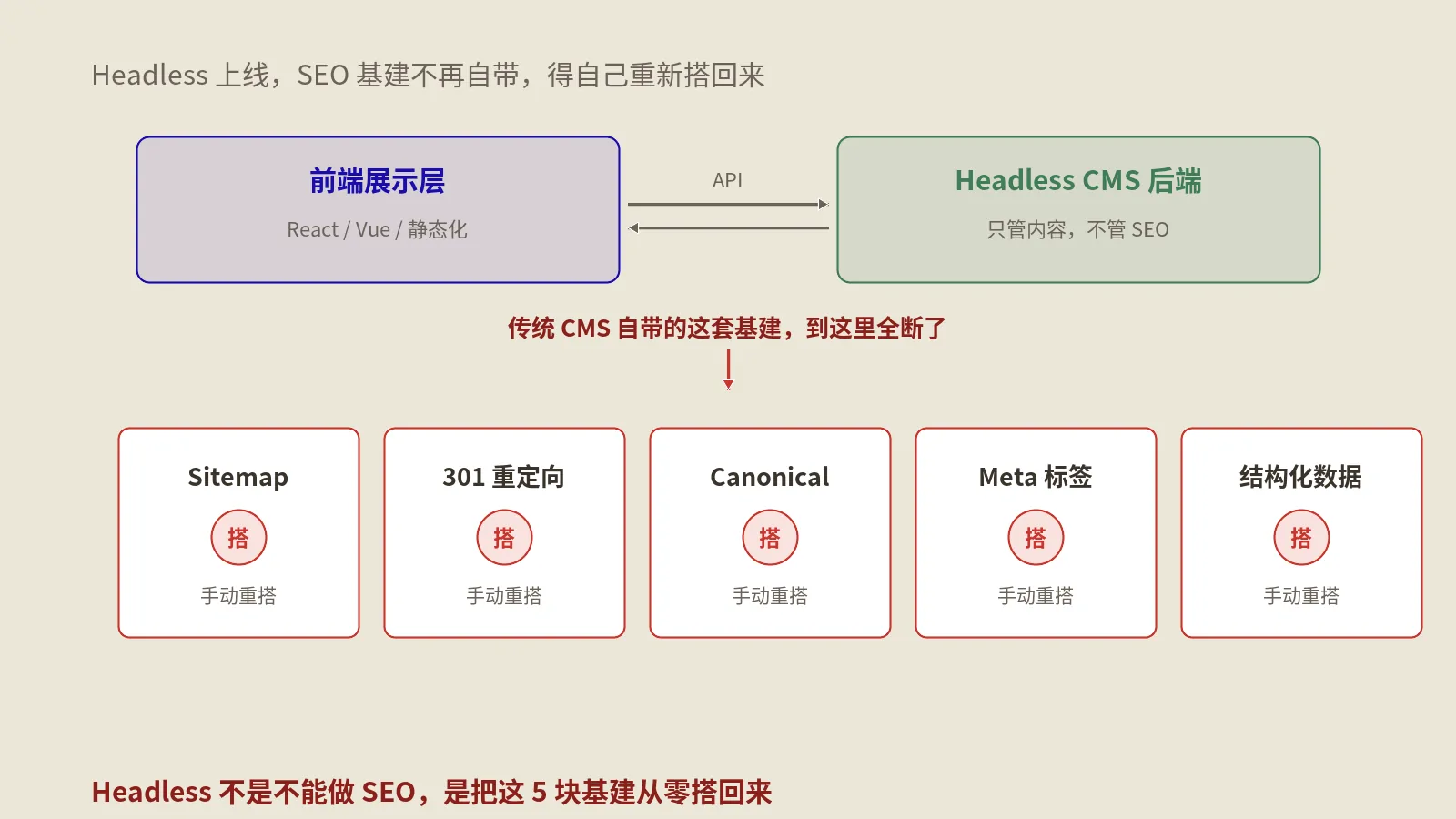
可Headless架构的本质是把内容和呈现彻底拆开:内容躺在Sanity、Strapi或Contentful里,前端是另一套独立的应用。这一拆,那些原本绑在WordPress主题和插件里的SEO功能,没有任何一项会自动跟着内容跑到新前端去。它们不是坏了,是压根就不存在了。这篇文章要做的,就是把这套消失的基建一项一项拎出来,告诉你它原来在哪、现在该搬到哪、谁来重建。
传统WordPress帮你默默做了哪些SEO基础设施?
要重建,先得知道丢了什么。保哥让每个准备上Headless的团队做的第一件事,就是把传统CMS替你做的SEO工作列一张完整清单——不列不知道,一列吓一跳,原来插件背后扛了这么多活。
第一类是页面级meta管理。每个页面的标题标签、meta描述、Open Graph社交分享标签,Yoast都给了可视化编辑框,编辑填一填就输出到页面head里。第二类是sitemap自动生成。你发一篇新文章,sitemap自动把它加进去,还按类型分好了卷,谷歌随时能拉到最新的内容地图。
第三类是canonical与重复内容处理。分页、标签页、带参数的URL,插件自动给它们打上指向规范版本的canonical,免得谷歌判重复。第四类是重定向管理。你改了一篇文章的slug,WordPress自动建一条老地址到新地址的301;用了Redirection这类插件的,还能手动维护一大批历史跳转规则。
第五类是结构化数据注入。面包屑、文章、FAQ的JSON-LD,主题或插件按页面类型自动吐出来。第六类是robots与索引控制。哪些页面noindex、robots.txt怎么写,后台勾几个选项就配好了。这六类活,平时你几乎感觉不到它们的存在,正因为感觉不到,迁移时才最容易整建制地漏掉。这套隐性失分的清单,保哥在独立站CMS第一年SEO隐性失分排查那篇里按平台拆得更细,迁移前值得对照自查。
Headless架构里,这些基础设施到底搬到了哪一层?
盘点完丢了什么,下一个关键问题是:这些活在Headless的新世界里,该由谁来接?保哥习惯把Headless站的技术栈分成三层来想这件事,每一项SEO基建都要明确落到其中某一层,悬在半空没人认领的,就是上线后要出事的。
第一层是内容层,也就是CMS本身。它的职责是把SEO需要的原料以字段的形式存好——SEO标题、meta描述、canonical覆盖值、是否noindex、结构化数据需要的各种属性。CMS不负责渲染,只负责把这些数据建模清楚、让编辑能维护。
第二层是构建与渲染层,也就是Next.js这类前端框架。它是这套基建的主战场——读取CMS的字段渲染进页面head、用代码动态生成sitemap、按内容类型组装JSON-LD、决定每个页面用什么渲染方式。原来插件干的大部分活,现在都搬到了这一层用代码实现。
第三层是边缘与中间件层,也就是CDN、反向代理或框架的中间件。它管的是那些更靠近请求入口的事:历史重定向规则的执行、X-Robots-Tag响应头、预览环境的鉴权拦截。重定向这种需要在内容渲染之前就生效的逻辑,放这一层最合适。
想清楚三层归属,迁移就有了图纸:每一项SEO基建对着图纸认领到具体某一层,不留模糊地带。Headless的SEO事故,十有八九是某项基建悬在三层之间、谁都以为别人会做。下面就按这张图纸,把几项最关键、最容易出事的基建逐个拆开。这套架构的整体取舍,可以先看Headless CMS对SEO的真实考验那篇的六维度避坑。
meta标签和标题,该由CMS建模还是前端写死?
第一个常见纠结是meta标签归谁管。保哥的答案很明确:在CMS里建模成字段,由前端消费,绝不在前端代码里写死。这是职责分工问题,不是技术品味问题。
具体做法是给每个内容类型——文章、产品、落地页——都挂上一组专门的SEO字段:SEO标题、meta描述、canonical覆盖、社交分享图、noindex开关。这组字段做进CMS的内容模型,编辑在后台填内容的同时就能顺手维护这篇的meta,想给某篇文章配个更勾人的搜索结果标题,自己改字段就行,不用提需求等开发排期。
前端这边,用框架提供的元数据接口去读这些字段。Next.js的Metadata API就是干这个的,你在页面组件里把CMS查回来的SEO字段映射成元数据对象,框架自动渲染成head里的title、meta、og标签。一套机制,全站统一。
为什么不能前端写死?保哥见过一个做B2B SaaS的客户,前端图省事把meta描述按模板写死成产品名加一句通用话术,结果全站几百个页面的meta描述几乎一模一样,谷歌在搜索结果里大量截断重写,点击率惨淡。改成CMS字段、让内容团队逐页填之后才缓过来。meta是给搜索用户看的第一眼文案,必须能逐页定制,写死等于放弃这块阵地。
sitemap没了自动生成,Headless怎么动态生成才不漏页?
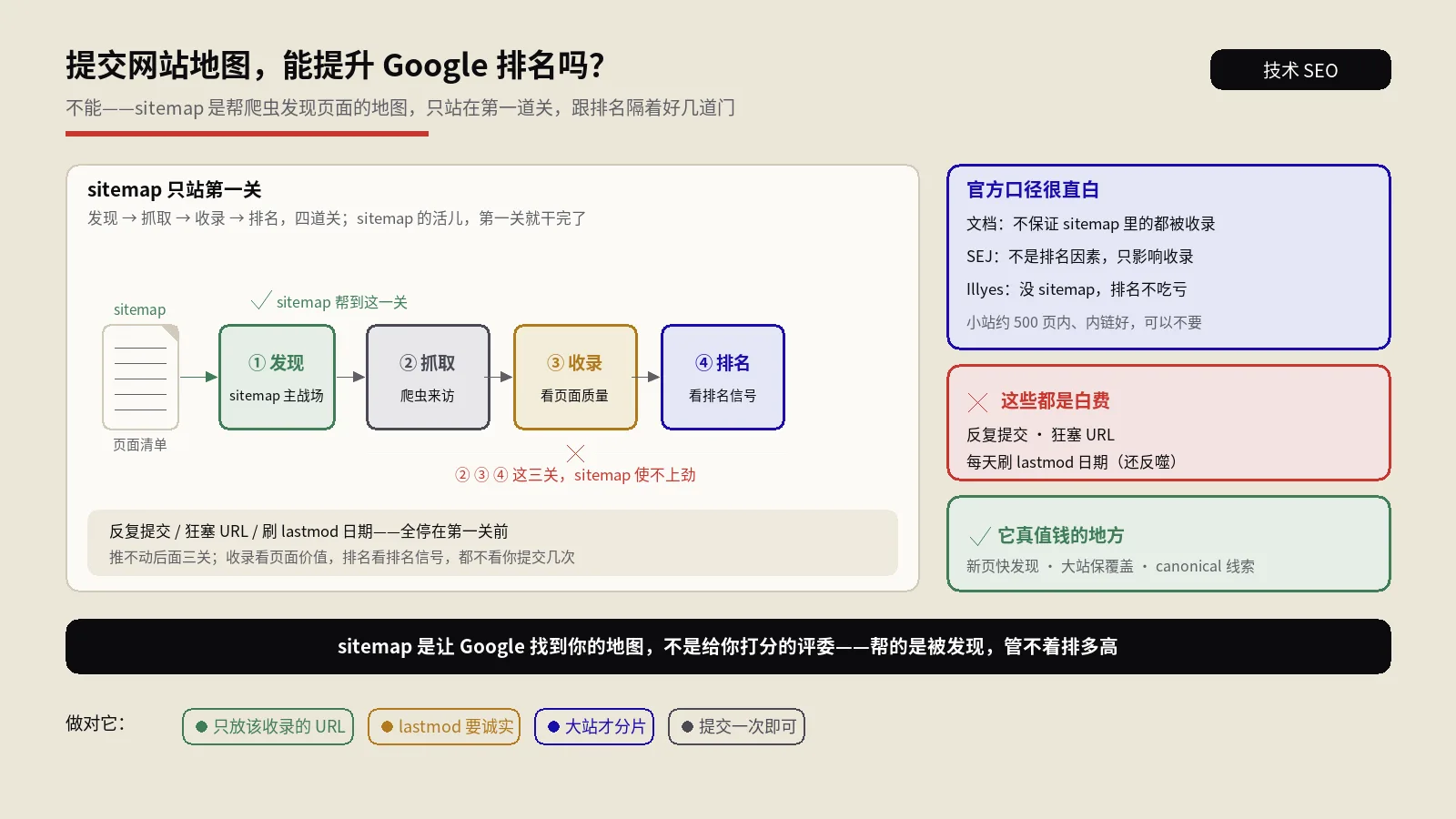
sitemap是Headless迁移里最直观会丢的一项,也是最好补的一项,前提是你得知道要补。保哥的铁律是:Headless站的sitemap必须动态生成,绝不能手写静态文件。原因很简单,内容存在CMS里、数量天天变,手写的第二天就过期了。
正确姿势是用前端框架在构建时或请求时,从CMS拉取全部已发布内容,按规则程序化地生成sitemap。以Next.js为例,它有专门的sitemap文件约定,你导出一个函数,函数里从CMS查出所有内容、返回一个URL数组,框架就自动产出合规的XML,连最后修改时间、更新频率这些字段都能带上。
这套机制的好处是sitemap永远跟着CMS的真实内容走,发了就有、删了就没,不存在过期。Next.js官方文档Next.js官方文档 — sitemap.xml文件约定(代码生成站点地图)里把这套代码生成机制讲得很全,包括怎么程序化拉数据、怎么带多语言alternates。
内容量大的时候有两个细节要抓。一是分卷,谷歌规定单个sitemap最多5万条URL,上万SKU的电商站得用框架的多sitemap机制按段拆开,每卷管一批。二是新鲜度,新发布的内容要能及时进sitemap,要么靠发布触发的增量重建,要么定时整体重新生成,别让新页面在sitemap外面晾着。
生成之后别忘了在Search Console提交,并养成一个习惯:定期拿sitemap里的URL数和CMS里已发布内容的总数对一对账,两个数字对不上,差额就是被漏掉、没进sitemap的页面。
保哥碰过一个做服装DTC的站,迁完Headless自我感觉良好,直到三个月后做对账才发现:sitemap里只有800多条URL,CMS里已发布的商品却有2300多个。一查根源,前端生成sitemap的函数只拉了文章这一个内容类型,把商品和分类页两整类整个漏在了外面,等于大半个站谷歌根本不知道存在。补全内容类型、重新生成提交后,那批商品页才陆续进了索引。这就是为什么对账这一步省不得——你以为生成了sitemap,不等于它把页面收全了。
谷歌官方对sitemap的格式、上限和提交方式有明确规范,Google Search Central — Build and Submit a Sitemap这一页是动手前该过一遍的依据。
canonical在Headless里为什么特别容易出错?
canonical标签在传统CMS里几乎不用操心,插件自动处理。可到了Headless,它成了出错重灾区,原因是Headless架构天然制造了一堆“同一内容多个URL”的场景。
第一个坑是预览域名。Headless常有预览环境、Staging环境、生产环境好几套,同一篇内容在好几个域名下都能访问。如果预览或Staging的页面canonical没指向生产正式URL、又不小心被谷歌抓到,就可能出现规范版本指错、甚至Staging站抢了正式站排名的怪事。
第二个坑是多前端消费同一套内容。Headless的内容可以被网站、App、小程序多个前端复用,同一篇文章在主站和某个子站都渲染了一份,谁是规范版本必须用canonical明确声明,否则谷歌自己挑,挑错了你也没辙。第三个坑是参数和分页,筛选参数、分页页这些变体的canonical该怎么指,前端得有统一规则,不能漏。
保哥的处理原则是:canonical必须由前端渲染层统一输出,并且有一条明确的默认规则——每个页面的canonical默认指向它自己的生产环境规范URL,特殊情况由CMS的canonical覆盖字段接管。这条默认规则一旦写进前端模板,全站就有了统一兜底,剩下的只是处理少数例外。
谷歌官方把指定canonical的几种方法和优先级讲得很清楚,Google Search Central — How to specify a canonical URL with rel=canonical and other methods里说明了重定向、rel=canonical、sitemap三种信号的强弱差异,配规则时该对着看。canonical本身的冲突诊断,站内后端工程师SEO协作7个动作点那篇有更细的排查思路,只是要记住:在Headless里这些活从后端插件转移到了前端构建层。
最容易被忘记的一层:历史重定向规则迁到哪去了?
如果说前面几项是大家多少会想到的,那这一项就是整个迁移里最容易被全队集体遗忘、后果又最惨烈的——历史重定向规则。保哥几乎每次做Headless迁移诊断,都要专门把这一项拎出来反复确认,因为漏的概率实在太高。
问题的根源在于,WordPress里的重定向规则藏在好几个地方:可能在Redirection插件的数据库表里,可能在 .htaccess文件里,可能是某些SEO插件在你改slug时自动建的。这些规则平时静静运转,把老链接、改过名的页面、外链指向的旧地址,一条条301到正确的新位置。它们维系着你多年积累的外链权重和老流量。
迁到Headless,这些载体全都不存在了。Redirection插件没了,.htaccess可能也换了服务器逻辑,于是所有这些重定向规则若不主动搬走,就等于凭空蒸发。结果是大量老URL直接404,靠老链接进来的访客撞墙、外链传来的权重断在死页上,这种损失是实打实的真金白银。
保哥的标准动作分三步。第一,迁移前完整导出现有所有重定向规则,把插件表、服务器配置里的跳转全捞出来,整理成一张老URL到新URL的映射表。第二,把这张映射表在Headless的中间件层或CDN边缘层重新实现,让每条老地址都还能正确301到新位置。第三,上线后用爬虫工具全站扫一遍老URL,确认没有该跳的变成了404。重定向这东西平时看不见摸不着,可一旦断了,你会在流量曲线上看得清清楚楚。
结构化数据在Headless里,该在哪一层注入?
结构化数据是Headless里另一项需要重新安排归属的基建。传统CMS里主题自动吐JSON-LD,Headless里得自己想清楚:数据从哪来、谁来组装、在哪输出。保哥的分工原则是数据来源在CMS,组装和注入在前端。
拆开说,结构化数据需要的原料——产品的价格库存、文章的作者和发布时间、面包屑的层级、FAQ的问答对——这些都是内容,本来就该存在CMS的内容模型里,跟着内容一起维护。前端在渲染每一类页面时,根据页面类型选对应的结构化数据模板:产品页拼Product、文章页拼Article、带问答的拼FAQPage,把CMS里的字段填进模板,输出成页面里的JSON-LD script标签。
这么分有两个好处。一是结构化数据和页面实际内容天然一致,因为它们读的是同一份CMS字段,编辑改了价格,页面显示和结构化数据一起变,不会出现Schema里写一个价、页面显示另一个价的打架。二是编辑不用碰代码,他们只管在CMS里填业务字段,JSON-LD的语法和拼装全交给前端模板,出错概率大大降低。
这里有个反面教材。保哥见过一个做母婴用品的站,图省事让编辑直接在CMS的富文本里手写整段JSON-LD,结果编辑既不懂语法、又经常忘了和正文同步,上线后一片结构化数据报错、价格和正文对不上,富媒体结果全掉了。
JSON-LD是给机器读的代码,别让内容编辑手写,正确姿势永远是CMS存结构化字段、前端按模板拼装。JSON-LD作为谷歌推荐的结构化数据格式,它的基本原理和适用场景,Google Search Central — Introduction to structured data markup in Google Search这一页讲得最权威。
内容预览和发布工作流,怎么不把draft泄漏给谷歌?
Headless的一大卖点是实时预览——编辑在CMS里改内容,能立刻在一个预览地址看到渲染效果,不用发布。这个体验很爽,但保哥得提醒一句:配置不当的预览,是把未发布草稿泄漏给谷歌的高发地带。
风险在于,预览地址如果和正式环境共用域名、又没做访问控制,谷歌爬虫可能顺着某个链接就爬进了预览页,把还没发布、甚至带内部备注或敏感价格的草稿给索引了。轻则索引里出现一堆不该有的草稿页稀释权重,重则未公开的信息提前走光。
保哥的标准配置是三道闸。第一,预览环境和正式环境彻底隔开,预览走独立的预览模式或独立子域,绝不和生产混在一个可被公开抓取的地址下。第二,预览环境整体加noindex,统一打上X-Robots-Tag的noindex响应头加robots限制,再用访问令牌或登录鉴权挡住非授权访问,确保只有登录编辑能看。第三,正式环境只渲染已发布状态的内容,草稿在数据查询层就过滤掉,根本不进正式页面。
发布工作流这边,配合发布触发的webhook做增量重建或ISR,让内容一旦发布就及时更新上线、没发布就完全不可见。这套渲染策略本身怎么选——SSR、SSG还是ISR,对抓取和AI引用各有什么影响,保哥在AI爬虫抓不到JS渲染那篇里用实测数据拆过,可以和这篇的基建视角对着看,一个管“内容怎么渲染出来”,一个管“渲染出来的页面SEO基建全不全”。
Headless SEO基础设施重建,保哥的迁移检查清单长什么样?
讲了这么多项,落到执行得有张能逐条打钩的清单。保哥把Headless迁移要重建的SEO基建整理成下面这张表,每一行对应一项基建、它该落在哪一层、上线前怎么验。照着这张表过一遍,能避开绝大多数集体遗忘式的事故。
| SEO基建项 | 归属层 | 上线前验收方式 |
|---|---|---|
| 页面meta标题与描述 | CMS建模 + 前端消费 | 抽查多页head,确认逐页不同、非模板 |
| 动态sitemap生成 | 构建渲染层 | URL数与CMS内容总数对账 |
| canonical输出规则 | 前端渲染层 | 抽查预览/参数页canonical指向生产URL |
| 历史301重定向 | 边缘/中间件层 | 爬虫全站扫老URL,确认无404 |
| 结构化数据JSON-LD | CMS字段 + 前端拼装 | 富媒体测试工具实测各内容类型 |
| robots与noindex控制 | 边缘层 + 前端 | 确认预览noindex、正式页可索引 |
| 预览环境隔离 | 边缘/中间件层 | 确认预览页不可被公开抓取 |
这张清单的价值不在它列了多全,而在它把每一项都钉到了一个明确的责任层上。Headless迁移的SEO翻车,本质都是责任真空——某项基建悬在内容、前端、边缘三层之间,谁都默认别人会做。清单的作用就是把这些真空一个个填上名字,让每项基建都有人认领、有验收标准。
这套Headless迁移,最常踩的5个坑是什么?
最后把保哥这些年踩过、见过的高频坑收个尾,对照自查,能少摔很多跟头。
坑一:以为内容迁过去SEO就跟过去了。这是最根本的认知误区。内容是内容,SEO基建是基建,两者在Headless里彻底分家。内容搬得再干净,sitemap、meta、重定向这些一项不补,谷歌那边照样是个残站。
坑二:sitemap用静态文件手写。Headless内容天天变,手写sitemap当天就过期、漏页。必须用框架代码动态生成、对账验收,把它当成一个会随内容自动更新的程序,而不是一个一次性文件。
坑三:历史重定向规则整建制遗忘。这是损失最直接的坑。Redirection插件、.htaccess里的老跳转不主动导出重建,老链接全断在404上,外链权重凭空蒸发。迁移清单必须单列一项专门核对。
坑四:预览环境裸奔被谷歌抓到。预览不加noindex、不做鉴权,草稿和敏感内容泄漏进索引。预览方便归方便,三道闸——隔离、noindex、鉴权——一道都不能少。
坑五:让编辑在CMS里手写JSON-LD。结构化数据是给机器读的代码,交给不懂语法的编辑手写,必然语法错加内容脱节。正确姿势永远是CMS存字段、前端按模板拼。
这五个坑有个共同点:它们全都不在Headless这个架构的“先进”之处,而在迁移时被先进光环掩盖掉的那些“不性感”的基础工作。Headless给了你更快的前端和更灵活的内容,但它把传统CMS默默替你扛的SEO基建一并卸了下来,这副担子得你自己重新挑起来。把这篇当成迁移前的一张体检表,上线前每一项都确认有人认领、有验收标准,你的Headless站才不会快是快了、谷歌却找不着它。
常见问题解答
Headless CMS真的会让SEO变差吗,问题到底出在哪?
Headless本身不会让SEO变差,让它变差的是迁移时漏掉了基础设施重建。保哥的经验是,团队从WordPress搬到Headless,注意力全在前端框架和内容建模上,却没人意识到Yoast这类插件原来默默承担了多少SEO工作:sitemap自动生成、每个页面的meta标签输出、canonical标记、面包屑结构化数据、历史重定向管理。这些在传统CMS里装个插件就全有了,解耦之后一项都不会自动跟过来。结果就是前端跑分漂亮、内容也优质,可谷歌那边sitemap是空的、meta缺失、老链接全404,自然流量自然往下掉。问题不在Headless这个架构,在于没把消失的基建一项项补回来。
meta标题和描述,该在CMS里建模还是在前端代码里写?
应该在CMS里建模成专门的SEO字段,由前端去消费,而不是在前端代码里写死。保哥的做法是给每个内容类型加上一组SEO字段:SEO标题、meta描述、canonical覆盖、社交分享图、是否noindex。这样运营和编辑能在CMS后台直接维护每篇内容的meta,不用每次都找开发改代码。前端这边用框架的元数据接口,比如Next.js的Metadata API,把这些字段读出来渲染进页面head。这套分工的关键是职责清晰:内容和SEO文案归编辑在CMS管,渲染和技术实现归前端。最怕的是两头都不管,meta字段建了没人填、或者前端写死了一套编辑改不动,上线后一查全站标题描述千篇一律。
Headless站的sitemap怎么生成才不会漏页或过期?
核心是动态生成,别用静态文件手写。Headless站的内容存在CMS里、数量还在不断变,手写sitemap第二天就过期。正确做法是用前端框架在构建或请求时从CMS拉取全部已发布内容、按规则生成sitemap。以Next.js为例,它有专门的sitemap文件约定,你导出一个函数从CMS查出所有内容、返回URL数组,框架自动生成合规的XML。内容上万条时记得按谷歌每个sitemap 5万条URL的上限分卷,用框架的多sitemap机制拆。还要确保新发布内容能及时进sitemap,要么走增量重建、要么定时重新生成。保哥的建议是上线后在Search Console提交并盯着收录数,对比CMS里的内容总数,差额就是漏掉的页面。
从WordPress迁到Headless,历史的301重定向规则怎么办?
这是整个迁移里最容易被全队遗忘、后果又最严重的一环。WordPress里那些301重定向,可能存在Redirection插件、可能在 .htaccess、也可能是某些SEO插件自动维护的,迁到Headless之后这些载体全没了,规则若不主动搬走就等于凭空消失。后果是所有靠老链接进来的流量和外链权重瞬间断在404上。保哥的标准动作是迁移前先把所有现存重定向规则完整导出,包括WordPress默认的slug变更重定向,整理成一张映射表,再在Headless的中间件层或CDN边缘层重新实现,确保每条老URL都还能301到新位置。重定向这东西平时看不见,断了却是真金白银的流量损失,迁移清单里必须单列一项专门核对。
结构化数据在Headless架构里,应该谁来注入?
由前端按内容类型注入JSON-LD,但数据来源还是CMS。保哥的分工是这样:结构化数据需要的原料——产品价格、文章作者、发布时间、面包屑层级、FAQ问答——这些字段都在CMS的内容模型里存着;前端在渲染每一类页面时,根据内容类型组装对应的JSON-LD,比如产品页注入Product、文章页注入Article、带问答的注入FAQPage,把CMS字段填进去,输出到页面里的script标签。这样既保证了结构化数据和页面实际内容一致,又让编辑改了价格或作者后结构化数据自动跟着变。注意别在CMS里手写整段JSON-LD让编辑维护,那既容易出语法错、又和页面内容容易脱节,正确姿势是CMS存结构化字段、前端按模板拼装。
内容预览和草稿,怎么防止被谷歌抓到泄漏出去?
关键是把预览环境和正式环境彻底隔开,并给预览加noindex。Headless的一大卖点是实时预览,编辑能在发布前看到草稿渲染效果,但这个预览地址如果配置不当被谷歌抓到,未发布的草稿、甚至带敏感信息的内容就泄漏了。保哥的标准配置是:预览走独立的预览模式或独立子域,整个预览环境统一加X-Robots-Tag noindex响应头和robots限制,再用访问令牌或鉴权挡住非授权访问,确保只有登录的编辑能看。正式环境只渲染已发布状态的内容,草稿状态在数据查询层就过滤掉,根本不进正式页面。再配合发布触发的webhook做增量重建或ISR,让内容一发布就更新、没发布就完全不可见。预览方便是好事,但别让方便变成谷歌索引里的事故。
权威参考资料
本文标题:《Headless CMS上线SEO集体失分?sitemap、重定向这套基建得自己重搭》
本文链接:https://zhangwenbao.com/headless-cms-seo-infrastructure-rebuild-sitemap-meta-canonical-redirect.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0