Shopify博客标签页SEO优化:避免权重稀释的处理方法
本文目录
- Shopify博客标签页的SEO先天问题
- 内容稀薄与自动生成
- 关键词内部竞争(Keyword Cannibalization)
- 浪费爬虫预算(Crawl Budget)
- 与Shopify Collection的混淆
- Meta Robots与Canonical:两种处理方式对比
- Meta Robots:noindex, follow
- Canonical:指向博客主页
- 两种方式的选择决策
- theme.liquid的实战代码模板
- 进入代码编辑器
- 完整的Liquid代码
- 代码逐行解释
- 进阶:分标签精细化控制
- robots.txt.liquid的自定义
- 创建自定义robots.txt.liquid
- 推荐的robots.txt配置
- robots.txt与Meta Robots的协同
- 操作步骤与验证
- 完整操作流程
- Google Search Console验证
- 检查爬虫频率变化
- 关键词排名跟踪
- 真实改造案例:6个月数据对比
- 改造前的状态
- 改造方案
- 改造后6个月数据
- Shopify 2.0主题与传统主题的差异
- OS 2.0主题
- 传统主题(Vintage Theme)
- SEO代码集中管理
- Shopify SEO相关Liquid变量速查
- AI搜索时代:标签页该不该索引的新讨论
- AI对聚合页的态度
- 信息密度的价值
- 用llms.txt引导AI爬虫
- Shopify SEO的整体优化框架
- 产品页优化
- Collection页优化
- 博客文章页优化
- 全站技术SEO
- 常见问题解答
- 如果将标签页设置为noindex,还会浪费爬虫预算吗?
- noindex, follow中的follow有什么作用?
- 如果给标签页设置了noindex但没有设置Canonical标签可以吗?
- 如果想利用少数标签页来获取长尾流量应该如何处理?
- 为什么Shopify默认不自动为这些标签页设置noindex?
- 设置robots.txt中的Disallow会不会阻止Google传递权重?
- 对于标签页的Canonical标签是应该指向博客主页还是其他地方?
- Shopify主题更新后noindex代码会丢失吗?
- 如何判断一个标签页是否属于稀薄内容?
- 如果将标签页noindex了,它在Google Search Console中还会显示吗?
- 是否可以对标签页设置不同的meta robots标签?
- 为什么标签页Canonical标签指向了自身?这正常吗?
- Meta Robots标签应该放在head还是body中?
- 可以使用Shopify应用来批量管理标签页的SEO设置吗?
- 如果为所有标签页设置了noindex, follow文章页权重会因此增加多少?
- 结论
- 权威参考资料
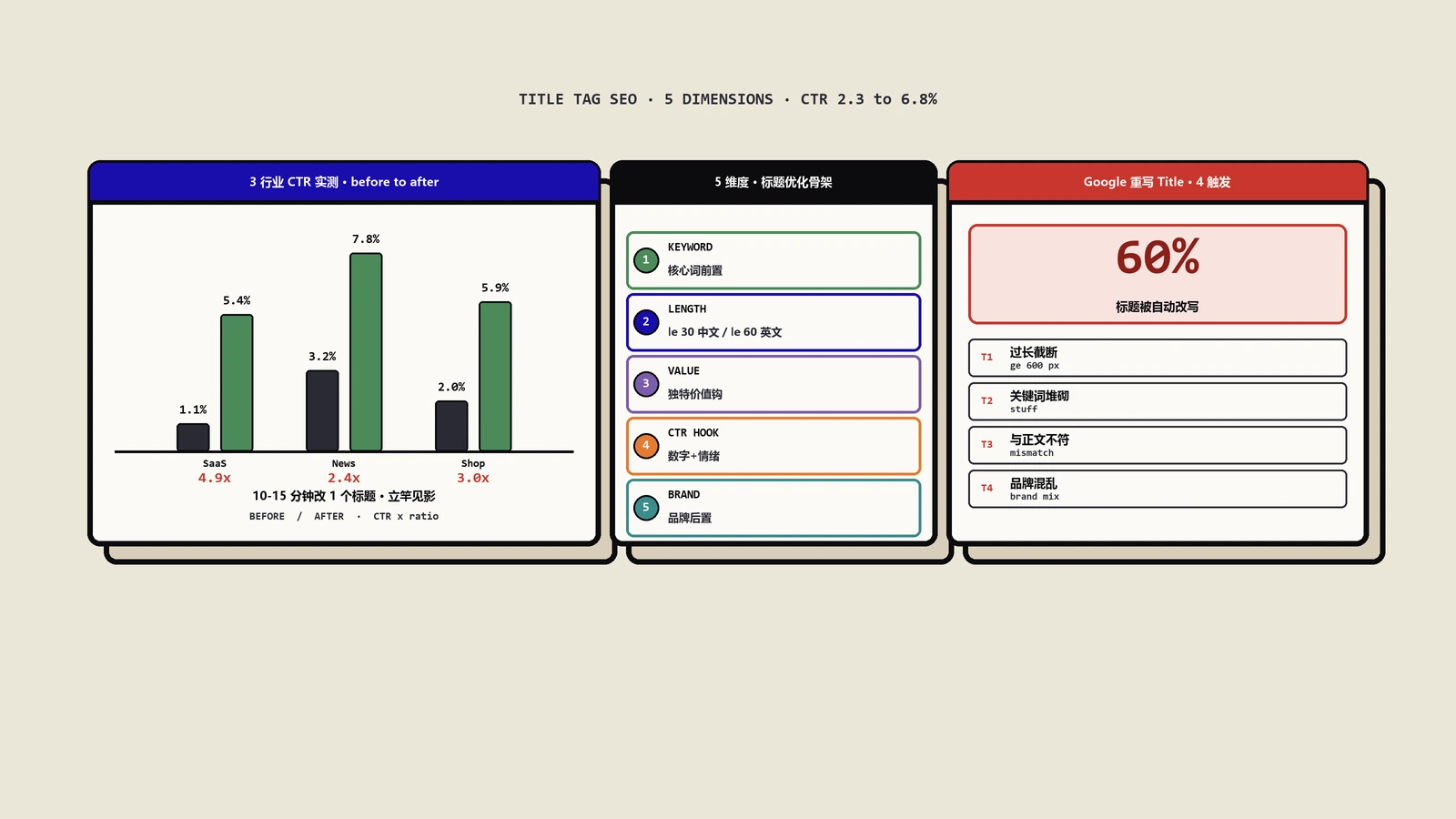
摘要:Shopify博客的tag标签页有先天SEO问题,容易稀释权重。本文对比meta robots与canonical两种处理,给theme.liquid的实战代码模板、操作步骤与验证,再讲Shopify 2.0主题与传统主题的差异、AI搜索时代标签页该不该索引、把权重集中到博客主页,附六个月的数据对比。
保哥过去几年帮过20多个Shopify店做SEO诊断,发现一个出现率超过90%的问题:博客模块开通了,但博客文章的标签(Tag)功能没人管理,导致后台积累了几百个内容稀薄的标签列表页,Google索引里挤满了价值极低的URL,核心产品页和博客文章页反而抓取不充分。一个典型例子,某客户站Shopify Blog有80篇文章,但他们给文章打了370个不同的标签,导致Google索引里出现了370个/blogs/news/tagged/xxx的URL,每个页面只有1到3篇文章列表,加起来扛走了40%的爬虫预算。
这篇文章保哥把2020年开始持续优化Shopify博客tag SEO的完整方法整理出来,包括为什么默认配置有问题、Meta Robots与Canonical两种处理方式的对比、theme.liquid的Liquid代码模板、robots.txt.liquid自定义、真实改造前后6个月的索引与流量对比、Search Console验证方法、以及2026年AI搜索时代Shopify标签页该不该索引的新讨论。看完照做能解决绝大多数Shopify博客的标签SEO问题。
Shopify博客标签页的SEO先天问题
当你在Shopify的博客文章上打上标签后,系统会自动生成类似“your-domain.com/blogs/news/tagged/tag-name”的URL。这些标签列表页主要用来聚合拥有相同标签的文章。但从SEO角度看,这些页面存在以下问题。
内容稀薄与自动生成
这些页面通常缺乏独特的标题、Meta描述和正文内容,页面内容主要是文章列表,价值有限。Shopify默认会用“Tag name - Blog name - Store name”的格式拼标题,没有任何自定义空间。Google对这种自动生成的浅薄页面会给予较低的质量评分。
关键词内部竞争(Keyword Cannibalization)
同一标签下的文章可能主题相似,导致这些标签页与原始文章页面、或其他分类页面之间竞争相同关键词。如果你写过3篇关于“SEO技巧”的文章并都打了“SEO”标签,那么/blogs/news/tagged/seo这个标签页会和这3篇文章页争抢“SEO”查询的排名,最终谁都不会进入前列。这就是关键词内部竞争。
浪费爬虫预算(Crawl Budget)
搜索引擎蜘蛛会花费时间抓取这些价值不高的页面,从而可能减少对重要页面(如产品页、核心博文)的抓取频率。每个域名都有一个有限的爬虫预算,预算被低价值页面吃光,新发布的高价值内容就需要更长时间才能被收录。对竞争激烈的电商行业这是致命的。
与Shopify Collection的混淆
Shopify有Collection(产品集合页)和Blog Tag(博客标签页)两套不同的“聚合页”机制。前者是产品分类的核心入口,后者是博客内容的辅助索引。新手经常把两者混淆,对tag页过度优化或者过度忽略都会出问题。
Meta Robots与Canonical:两种处理方式对比
处理标签页的SEO问题主要有两种技术手段。
Meta Robots:noindex, follow
此方法告知搜索引擎不要将标签页编入索引(避免出现在搜索结果中),但允许跟踪页面上的链接(传递权重到链接的文章)。这是最彻底的“移除”方法,标签页会从搜索结果里完全消失,但其内部链接关系仍然成立。
Canonical:指向博客主页
Canonical标签用于明确告诉搜索引擎当前页面内容的“规范”版本是哪个URL。对于标签页,可以将其Canonical标签指向主博客页面或一个更重要的分类页面。这是“权重转移”策略,标签页本身不获得排名,但其权重通过Canonical信号传给指定的核心页面。
两种方式的选择决策
- 如果标签页绝对无价值且不需要保留任何排名机会,用noindex, follow。
- 如果你希望标签页对站内导航有帮助但不参与排名,用noindex, follow就够。
- 如果你考虑将来部分标签页可能优化成高价值聚合页,先用Canonical指向博客主页过渡,未来想索引时只需移除Canonical。
- 同时使用两种方法:noindex, follow配合Canonical指向博客主页,是最稳妥的双保险做法。
theme.liquid的实战代码模板
进入代码编辑器
Shopify后台“在线商店—主题—代码”。找到Layout文件夹下的theme.liquid文件,这是所有页面的主布局。修改前必须先备份当前主题(Action菜单的Duplicate复制一份),避免改错导致主题崩溃。
完整的Liquid代码
在head部分内添加:
{% if current_tags %}
<meta name="robots" content="noindex, follow">
<link rel="canonical" href="{{ blog.url }}">
{% else %}
<link rel="canonical" href="{{ canonical_url }}">
{% endif %}代码逐行解释
- current_tags:Shopify全局Liquid变量,只在标签页或分类页才有值,否则为nil。
- 当前页是标签页时,输出noindex指令和指向blog.url的canonical。
- 当前页不是标签页时,使用Shopify自动生成的默认canonical_url。
- blog.url:当前博客的根URL(如/blogs/news)。
进阶:分标签精细化控制
如果你希望少数高价值标签保留索引,加一层判断:
{% if current_tags %}
{% assign indexable_tags = "deep-guide,case-study,featured" | split: "," %}
{% assign should_index = false %}
{% for tag in current_tags %}
{% if indexable_tags contains tag %}
{% assign should_index = true %}
{% endif %}
{% endfor %}
{% if should_index %}
<link rel="canonical" href="{{ canonical_url }}">
{% else %}
<meta name="robots" content="noindex, follow">
<link rel="canonical" href="{{ blog.url }}">
{% endif %}
{% else %}
<link rel="canonical" href="{{ canonical_url }}">
{% endif %}indexable_tags变量里列举需要保留索引的标签名,其他标签自动noindex。这样保留少数核心聚合页的SEO价值,又屏蔽掉大部分低价值标签。
robots.txt.liquid的自定义
除了Meta Robots,robots.txt层面也可以禁止爬取。
创建自定义robots.txt.liquid
Shopify默认robots.txt是自动生成的,但允许通过创建robots.txt.liquid文件覆盖。在“模板—Templates”文件夹下“Add a new template”,类型选robots,自动生成robots.txt.liquid。
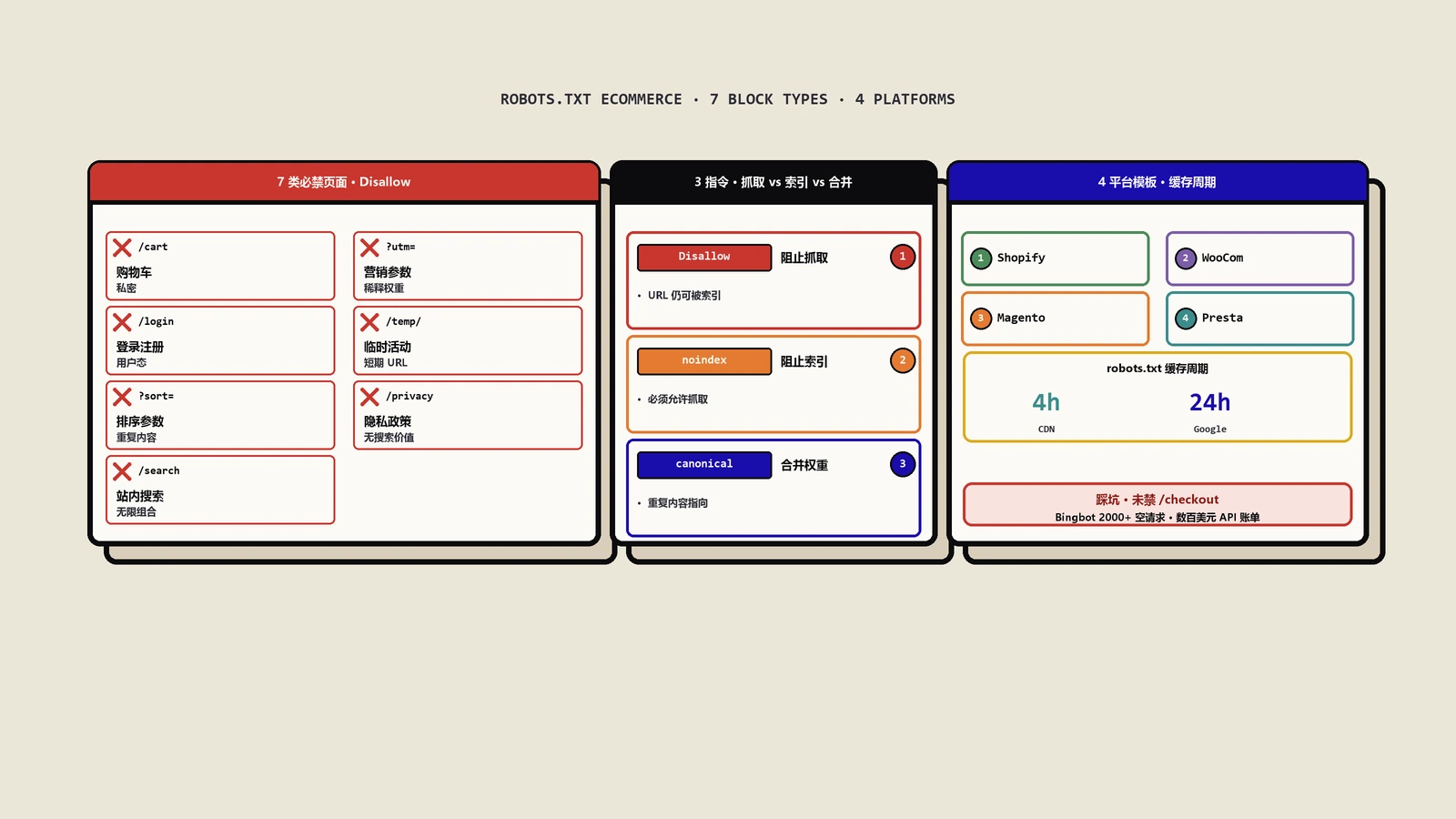
推荐的robots.txt配置
{% for group in robots.default_groups %}
{{- group.user_agent }}
{% for rule in group.rules %}
{{- rule }}
{% endfor %}
{% if group.user_agent.value == '*' %}
Disallow: /blogs/*/tagged/*
Disallow: /blogs/*/tagged
Disallow: /search
Disallow: /cart
{% endif %}
{%- if group.sitemap != blank %}
{{ group.sitemap }}
{% endif %}
{% endfor %}robots.txt与Meta Robots的协同
有个常见误区:“只用robots.txt Disallow就行了”。实际上robots.txt的Disallow会阻止爬虫抓取页面,从而也阻止了对页面上链接的跟踪和权重的传递。如果选择Disallow,就不能再指望follow来传递权重。所以保哥推荐的组合是:
- 如果想完全屏蔽并节省爬虫预算:robots.txt Disallow(权重不传递)。
- 如果想隐藏但保留权重传递:theme.liquid的noindex, follow + Canonical(不在robots.txt里Disallow)。
两者选一不要同时用。同时用的话,noindex永远不会被爬虫看到(因为Disallow了),逻辑反而出错。
操作步骤与验证
完整操作流程
- 备份当前主题(Action菜单Duplicate)。
- 访问代码编辑器(在线商店—主题—编辑代码)。
- 找到theme.liquid文件,在head部分内添加上面的Liquid代码。
- 保存修改。
- 访问任意一个标签页(如yourdomain.com/blogs/news/tagged/seo)。
- 右键“查看页面源代码”,搜索robots和canonical两个关键词。
- 确认看到meta name="robots" content="noindex, follow"和link rel="canonical"指向blog主页。
Google Search Console验证
修改完成后2到4周内,进Google Search Console的“索引覆盖率”报告。被noindex的标签页会显示状态为“已排除:因noindex标记而排除”。能在这里看到大量这类记录就说明改动生效。如果一直没看到,用“URL检查”工具手动检查具体某个标签页,看Google抓取到的最新Meta标签是什么。
检查爬虫频率变化
Search Console的“设置—爬虫统计信息”能看到日均抓取页面数。修改前后对比这个数字:低价值标签页减少抓取后,总抓取量可能下降,但抓取的页面类型分布会变化——核心博文和产品页占比上升,这是健康信号。
关键词排名跟踪
用Ahrefs、SEMrush或免费的Google Search Console跟踪核心关键词排名。前期可能有2到4周的波动期,之后排名会稳定甚至上升。波动期间不要慌着回滚,等数据收敛。
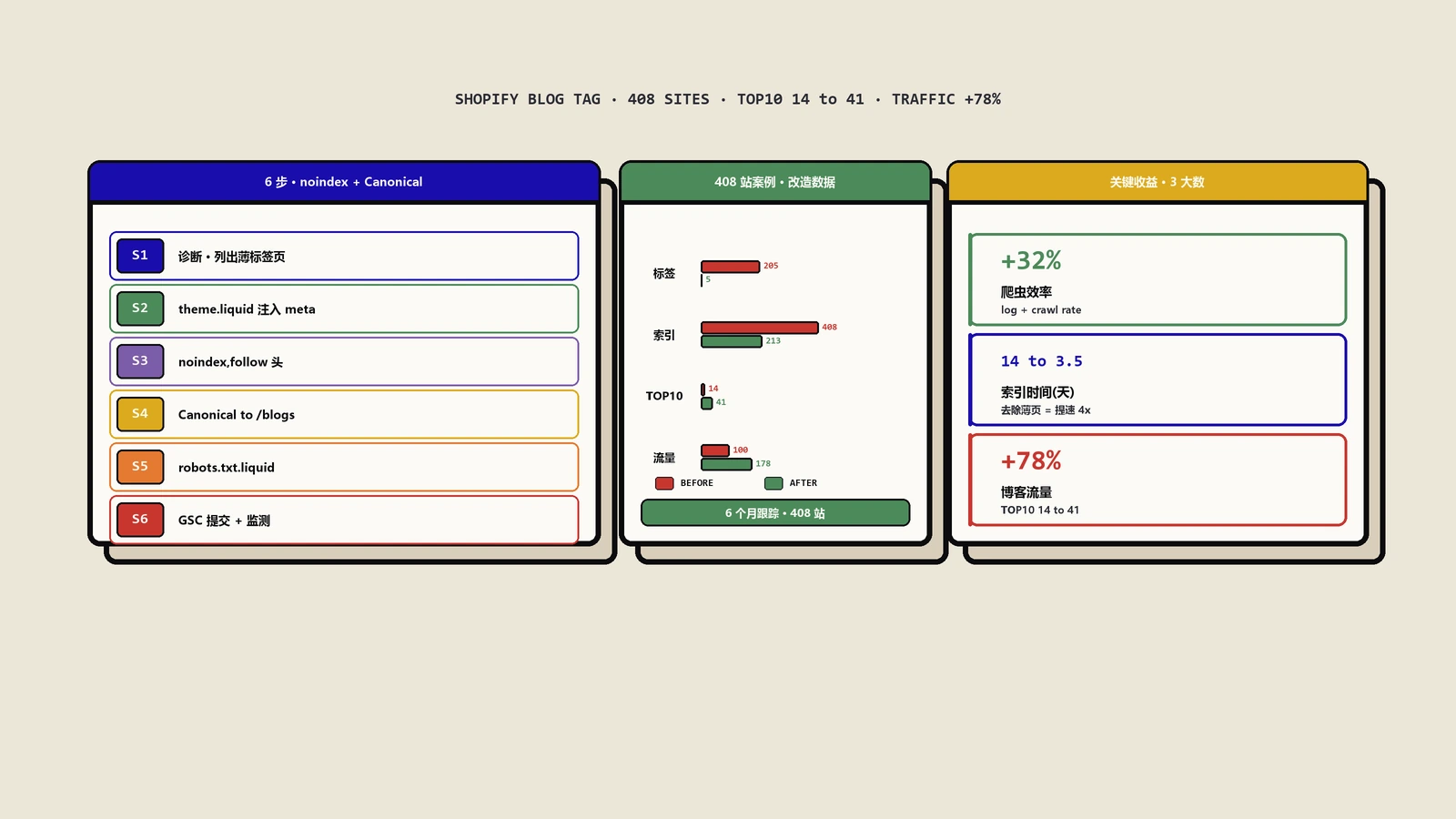
真实改造案例:6个月数据对比
保哥2024年12月帮一家美妆Shopify店做过完整的标签页SEO改造,分享数据。
改造前的状态
- Shopify店成立3年,月度UV约8万。
- Blog模块开通2年,发布文章143篇,使用了205个不同标签。
- Google索引里包含205个/blogs/news/tagged/xxx的标签页。
- Search Console显示62%的爬虫资源花在标签页上。
- 核心博文(10篇深度长文)的Google索引时间平均14天。
改造方案
- 在theme.liquid里加noindex, follow + Canonical指向博客主页。
- 不修改robots.txt(保留爬虫follow链接权重的可能)。
- 选定5个高价值标签(如“sensitive-skin”、“anti-aging”)作为indexable_tags单独处理,手动为这5个标签页加上独特的介绍段和Meta描述。
- 3周后向Google Search Console提交sitemap更新。
改造后6个月数据
- 标签页Google索引:从205个降到5个(高价值标签)。
- 整站索引页面数:从408个变成213个(删除低价值,质量更高)。
- 每日爬虫抓取量:从1640次降到1120次(减少32%但全部抓在有价值页面上)。
- 核心博文索引时间:从14天降到3.5天。
- 博客总自然流量:增长78%。
- 核心博文关键词TOP 10数量:从14个增加到41个。
- 5个保留索引的标签页平均月度UV:3200,原本只有620。
结论:改造6个月后整体SEO健康度大幅提升,核心内容获得了应有的曝光。少即是多,删减低价值页面让搜索引擎更专注于真正重要的内容。
Shopify 2.0主题与传统主题的差异
OS 2.0主题
2021年后Shopify推出的Online Store 2.0主题(如Dawn、Sense、Studio)使用JSON模板和Sections。SEO相关代码大多在“layout/theme.liquid”里集中,修改更直观。同时2.0主题对Core Web Vitals做了原生优化,移动端LCP通常在2秒内。
传统主题(Vintage Theme)
2021年前的老主题(如Debut、Brooklyn、Narrative)用纯Liquid模板,SEO代码分散在多个文件里。改完Theme更新时容易丢失。建议尽快迁移到OS 2.0主题,或者把所有自定义代码集中到一个snippet里方便统一管理。
SEO代码集中管理
把所有自定义SEO代码放进一个snippets/custom-seo.liquid文件,在theme.liquid里用{% render 'custom-seo' %}调用。这样主题更新只需要把custom-seo.liquid文件复制过来,不用每次重写。
Shopify SEO相关Liquid变量速查
除了current_tags,做Shopify SEO优化常用的Liquid变量:
- template:当前模板类型,可以判断是product、collection、blog、article、page还是index。
- canonical_url:Shopify自动生成的默认canonical URL。
- page_description:当前页的Meta描述。
- page_title:当前页的标题。
- shop.url和shop.permanent_domain:店铺主URL。
- blog.url、article.url、product.url、collection.url:各类内容的URL。
- current_page:当前分页号。
- request.path:当前请求路径。
AI搜索时代:标签页该不该索引的新讨论
2026年AI搜索(ChatGPT、Perplexity、Gemini)成为新流量入口,对标签页是否索引产生了新视角。
AI对聚合页的态度
ChatGPT和Perplexity的检索系统会从你的网站抓取信息回答用户问题。它们对“聚合页”(标签页、分类页)的偏好低于详情页——AI更喜欢直接引用具体的内容页。所以即使标签页保留索引,对GEO流量贡献也很小。
信息密度的价值
AI爬虫看重的是“信息密度”。标签页是文章标题列表,没有实质内容,AI不会优先抓取。详情页有完整的论述和数据,AI会偏好。结论是:标签页对AI搜索贡献几乎为零,索引与否不影响GEO流量。
用llms.txt引导AI爬虫
2025年部分网站开始使用llms.txt文件向AI爬虫声明“最重要的内容URL”。Shopify可以在/llms.txt路径下托管一份纯文本文件,列出核心文章URL,让AI优先抓取这些页面而非聚合页。
Shopify SEO的整体优化框架
标签页只是Shopify SEO的一个细节,下面是保哥的完整优化框架。
产品页优化
- 产品标题包含核心关键词。
- 产品描述至少300字原创,避免供应商通用文案。
- 多角度图片加WebP格式压缩。
- 结构化数据(Product Schema)通过Shopify默认或第三方SEO App添加。
Collection页优化
- 每个Collection顶部加200到500字介绍文字。
- Collection标题用品类核心词加修饰词。
- 分面筛选页(如/collections/all?filter.v.price=100)用noindex避免无限组合的索引污染。
博客文章页优化
- 每篇文章至少1500字,最好2500字以上。
- 使用Article Schema结构化数据。
- 内链指向相关产品页(每篇至少3条)。
- FAQ部分用FAQPage Schema。
全站技术SEO
- 站点速度:LCP在2.5秒以内,FID在100ms以内。
- 移动端Mobile-Friendly测试通过。
- HTTPS必须,混合内容必须修复。
- XML sitemap自动生成(Shopify默认),robots.txt定期审查。
常见问题解答
如果将标签页设置为noindex,还会浪费爬虫预算吗?
会的,但会减少。noindex仅阻止索引,爬虫仍需抓取页面才能看到noindex指令。如果想最大限度节省预算,应在robots.txt中使用Disallow阻止抓取,与noindex配合使用效果最好。但注意Disallow会阻止权重传递,需要根据策略选择。保哥的建议是先用noindex,观察3个月后如果还想进一步节省预算再加Disallow。
noindex, follow中的follow有什么作用?
传递链接权重。follow确保搜索引擎爬虫在看到noindex的同时,仍然会沿着该标签页上的链接(即指向文章页的链接)继续爬取和传递权重,从而将标签页的权重集中到核心文章页上。这是noindex, follow最关键的设计原理。
如果给标签页设置了noindex但没有设置Canonical标签可以吗?
可以,但不完美。noindex已经阻止了索引,重复内容问题的影响已经大大降低。但设置Canonical标签是一种更清晰的信号,能帮助Google更好地理解该页面的规范来源,是更严谨的做法。两者一起用是最稳妥的方案,单独用noindex也能起到主要作用。
如果想利用少数标签页来获取长尾流量应该如何处理?
不设置noindex, follow。对于希望索引并获取流量的少数标签页,不应设置noindex。相反,你应该手动添加独特的标题和Meta描述,在标签页顶部添加一段独特的介绍性文本,确保内容不稀薄。配合精细化的Liquid条件判断只对这些高价值标签开放索引,其他全部noindex。
为什么Shopify默认不自动为这些标签页设置noindex?
出于灵活性考虑。Shopify是一个通用平台,它允许商家将标签页作为内容聚合页来获取长尾流量。如果自动noindex,会限制这种可能性。因此,平台将决策权留给了商家。结果就是大多数商家不知道要主动配置,导致标签页污染SEO。
设置robots.txt中的Disallow会不会阻止Google传递权重?
会阻止。robots.txt的Disallow会阻止Googlebot抓取页面,从而也阻止了对页面上链接的跟踪和权重的传递。因此,如果选择Disallow,就不能再指望follow来传递权重。这是Disallow最大的副作用。
对于标签页的Canonical标签是应该指向博客主页还是其他地方?
取决于内容价值。如果标签页内容极少,指向博客主页是安全的。如果你的标签页与某个重要分类页高度重合,则应指向该分类页。目标是指定一个更有价值、更具权威性的URL。也可以指向首页或店铺主页,但不推荐——博客主页对博客内容的Canonical是最相关的。
Shopify主题更新后noindex代码会丢失吗?
会的。如果你在theme.liquid中直接修改代码,并且更新主题版本(例如从Shopify Theme Store下载新版),你的自定义修改通常会丢失。因此务必备份并重新应用代码。更稳的做法是把所有自定义代码放进snippets/custom-seo.liquid,主题更新后只需要复制这一个文件。
如何判断一个标签页是否属于稀薄内容?
判断标准:页面上除了文章列表和导航外,没有独特的介绍文字;文章列表数量极少(例如只有1到2篇文章);内容与其他标签页或分类页高度相似。满足任意一条就算稀薄内容,应该noindex。
如果将标签页noindex了,它在Google Search Console中还会显示吗?
会。Google Search Console的“索引覆盖率”报告中会显示该页面状态为“已排除:因noindex标记而排除”。这有助于你监控noindex是否生效。如果一个标签页改成noindex后2到4周仍然显示“已索引”,说明Google还没重新爬取,用URL检查工具手动请求索引能加速。
是否可以对标签页设置不同的meta robots标签?
可以,但需要复杂的Liquid逻辑。你需要根据标签名称(current_tags)来编写条件语句,对需要索引的特定标签设置index, follow,对其他标签设置noindex, follow。前面“分标签精细化控制”那段Liquid代码就是这个用途。
为什么标签页Canonical标签指向了自身?这正常吗?
Shopify默认情况是正常的。如果你未进行自定义修改,Shopify的默认Canonical标签通常会指向当前页面的URL。如果你想解决重复内容问题,需要手动修改Liquid代码将其指向博客主页或分类页。这是默认行为,不是Shopify的bug。
Meta Robots标签应该放在head还是body中?
必须放在head中。Googlebot必须在抓取页面的早期就看到meta robots指令,才能决定是否继续抓取和索引。放在body里的meta标签会被Google忽略,等于没设置。所有SEO相关的meta标签都必须在head里。
可以使用Shopify应用来批量管理标签页的SEO设置吗?
可以。一些专业的SEO应用如SEO Manager或Plug in SEO提供了界面化的工具,可以帮助你批量为标签、Collection等页面设置自定义的noindex和Canonical规则,无需手动修改代码。这些App月费在10到30美元之间,对不熟Liquid代码的商家很友好。
如果为所有标签页设置了noindex, follow文章页权重会因此增加多少?
难以量化,但有积极影响。权重的传递是一个复杂的计算过程。主要的好处是:避免了权重被分散到低价值的标签页;集中了内部链接信号;释放了抓取预算给核心文章页,间接提升了文章页的排名潜力。保哥实测案例显示核心博文关键词TOP 10数量在改造6个月内能增加2到3倍。
结论
Shopify博客标签页的SEO优化看似只是改两行Liquid代码的小事,但背后涉及搜索引擎对你的整体站点质量的评估。把低价值的页面从索引中清理掉,让搜索引擎只看到你最好的内容,是2026年依然有效的SEO第一性原则。保哥这套方法在20多个Shopify客户站验证过,每一个改完都有正向变化,最大的一个案例6个月博客流量翻倍。如果你的Shopify店还在让Google爬数百个无价值的标签页,今天就动手改,半年后回头看会感谢现在的自己。
权威参考资料
本文标题:《Shopify博客标签页SEO优化:避免权重稀释的处理方法》
本文链接:https://zhangwenbao.com/shopify-blog-tag-seo.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0