Google说搜索不需要llms.txt,Chrome却偷偷在查它
本文目录
- Google一边说不用,Chrome一边在查,到底哪个算数?
- Lighthouse新加的“代理浏览”审计,到底在查什么?
- 这个矛盾,其实一点都不矛盾?
- Mueller那句“这不是为了SEO”,该怎么正确理解?
- 那llms.txt到底什么样的站该做,什么站别瞎折腾?
- 把llms.txt当成robots.txt来理解,错在哪?
- 比llms.txt更该上心的,是可访问性这件老事?
- CLS这种老体验指标,怎么突然和AI代理扯上关系了?
- WebMCP又是个什么新东西,我现在得管它吗?
- 什么是“代理引擎优化”,它和GEO是一回事吗?
- 出海独立站,现在该不该为“代理时代”提前下注?
- 把这件事放回正确的位置:一份判断清单
- 常见问题解答
- Google说不需要llms.txt,我到底还要不要做?
- Chrome Lighthouse查llms.txt,是不是说明它要影响排名了?
- discovery和functionality,这两个概念到底怎么区分?
- 可访问性树是什么,为什么对AI代理这么重要?
- “代理引擎优化”是个全新的东西吗,我需要从头学吗?
- 出海小团队资源有限,这件事的优先级该怎么排?
- 权威参考资料
一句话结论:Google嘴上说搜索排名不需要llms.txt,转头却在Chrome的Lighthouse里加了一项检查,看你有没有这个文件。别被这层表面矛盾绕晕——关键是分清两件事:被搜索引擎找到(这是SEO),和被AI代理高效使用(这是另一码事)。llms.txt属于后者。对绝大多数出海站来说,它顺手生成即可,真正该上心的,是可访问性和布局稳定这些既利于代理、又利于真人的老地基。
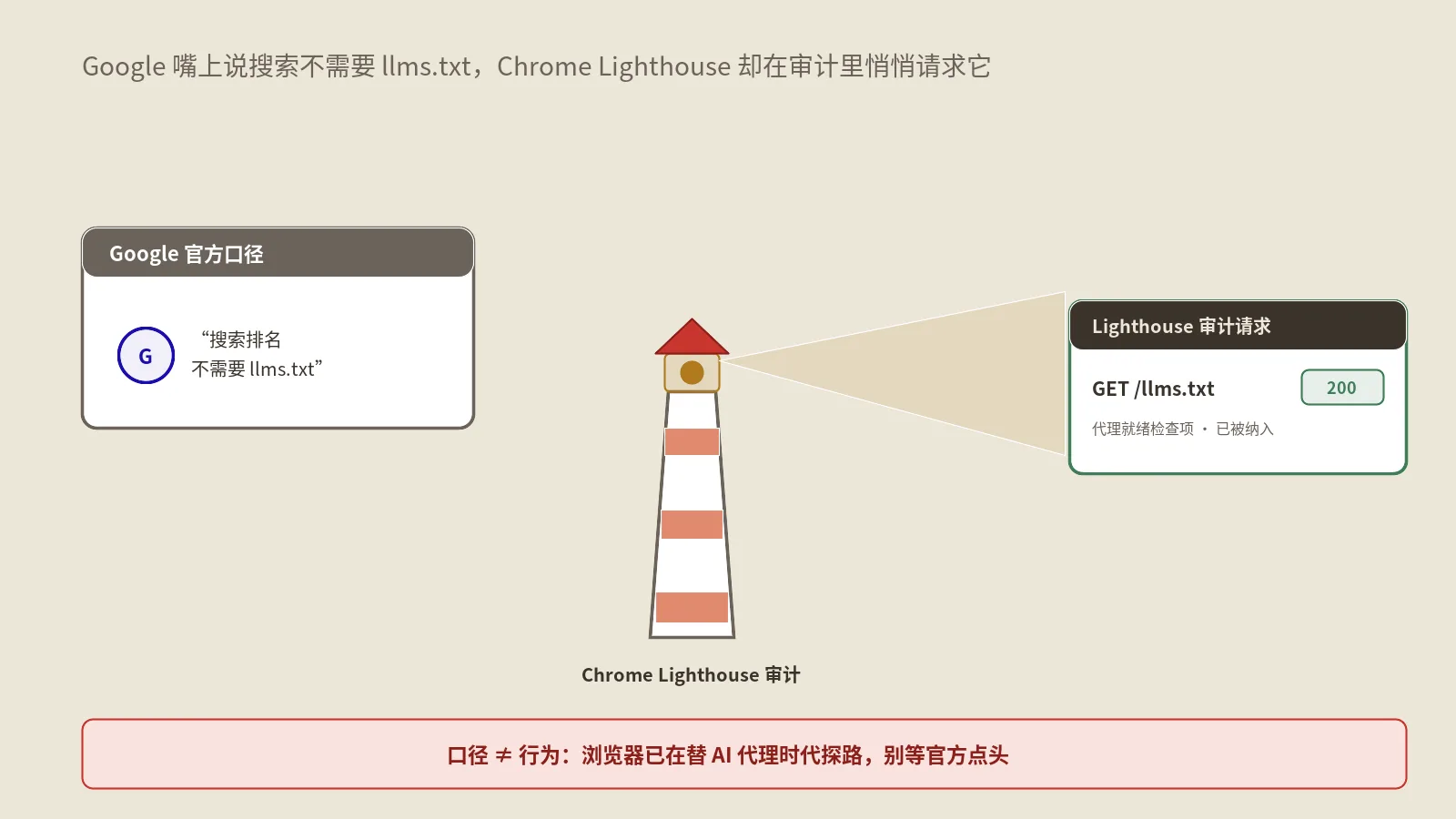
最近SEO圈有个让人有点懵的信号:Google一边在官方指南里白纸黑字写着“你不需要llms.txt”,一边在自家Chrome浏览器的Lighthouse工具里,悄悄加了一项检查——看你的网站有没有llms.txt。
这就尴尬了。到底听谁的?是该连夜给所有站补上llms.txt,还是继续当它不存在?
保哥的建议是:先别急着动手,把这件事背后的逻辑捋清楚。一旦你理解了Google这两个动作其实在说两件不同的事,你就不会再纠结,反而能做出比跟风更聪明的决定。这篇就来把这层窗户纸捅破。
Google一边说不用,Chrome一边在查,到底哪个算数?
先把这两个看似打架的事实摆清楚。
第一个事实:就在不久前,Google发了一份关于“为生成式AI搜索做优化”的官方指南,里面有一节专门“辟谣”,点名了一串“你不需要做的事”,llms.txt赫然在列。原话的意思是:你不需要为了出现在生成式AI搜索里,去创建什么新的机器可读文件、AI文本文件或者Markdown版本。
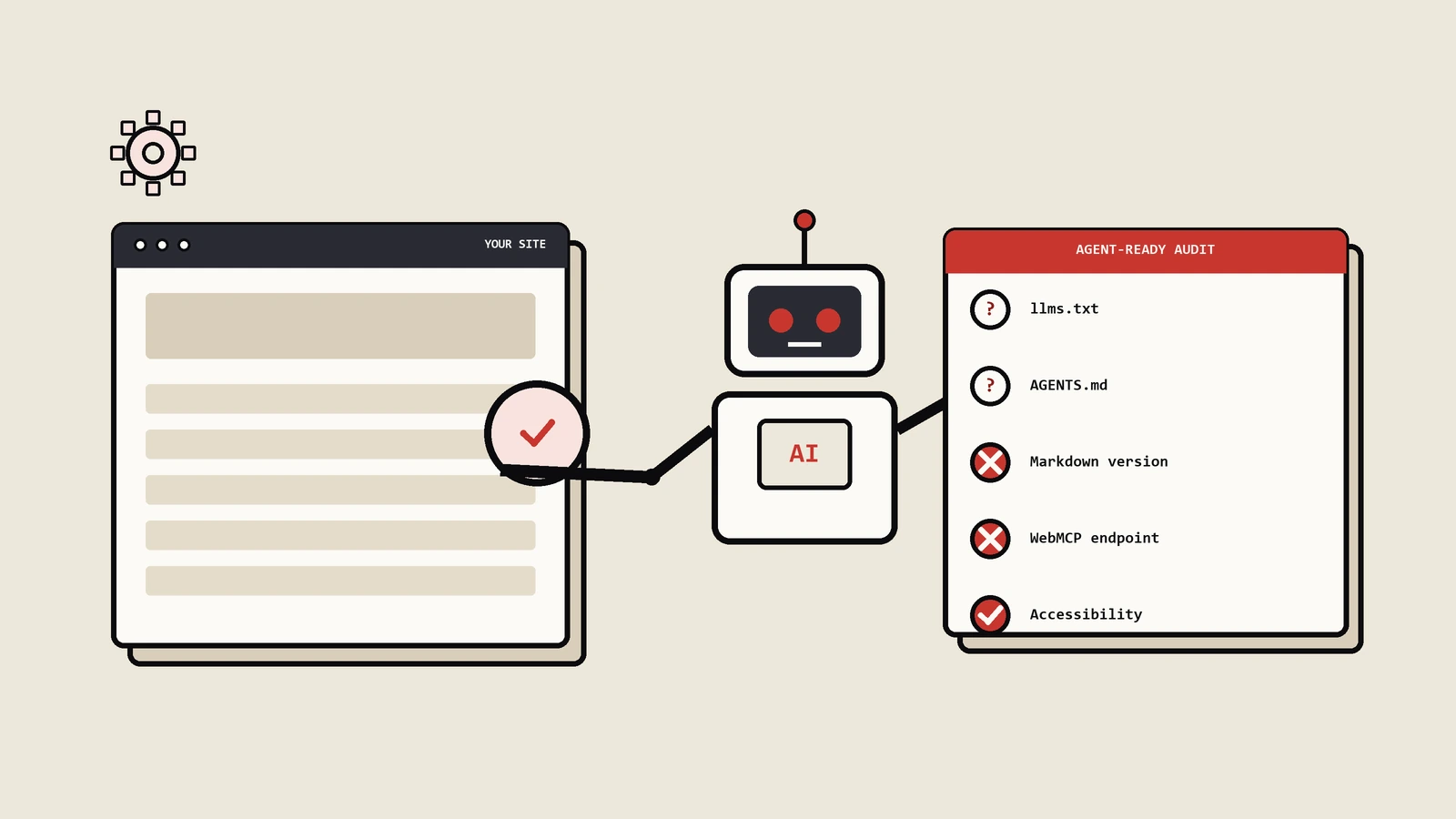
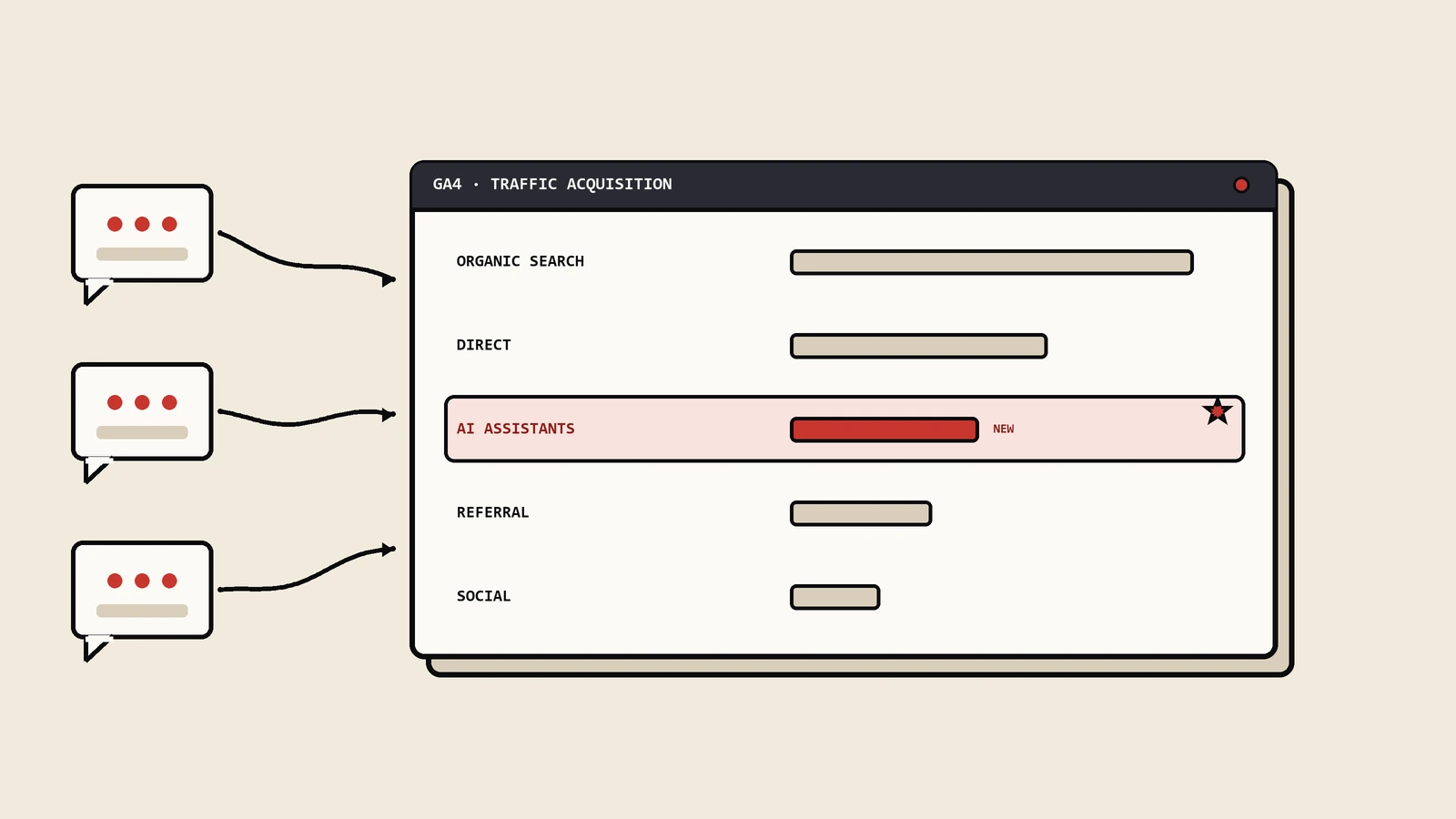
第二个事实:几乎前后脚,Chrome的Lighthouse(就是那个你做网页性能体检常用的工具)新增了一个叫“代理浏览”(Agentic Browsing)的审计类别。这个类别会检查好几样东西,其中明明白白有一项,就是看你的站有没有llms.txt。
同一家公司,左手说“这玩意儿对搜索没用”,右手在体检表上给它列了一栏。换谁都得犯嘀咕:这不是自己打自己的脸吗?
但如果你就此得出“Google嘴上一套背后一套”的结论,那就把问题想浅了。真相是:这两个动作压根不在一个频道上。一个说的是“搜索排名”,一个说的是“代理可用性”。它们是两件不同的事,各自成立,谁也没骗你。关于Google那份叫停一堆动作的官方指南到底说了什么,我在Google官方指南叫停5个动作那篇里逐条拆过,可以先垫个底。
要理清这个,得先看看Lighthouse这个新审计,到底在查什么。
Lighthouse新加的“代理浏览”审计,到底在查什么?
这个“代理浏览”审计,Google给它的定位是:评估一个网站“为机器交互准备得怎么样”。注意,是机器交互,不是人,也不是传统的搜索爬虫,而是越来越多会替用户跑腿办事的AI代理。
它具体查这么几样:
- WebMCP集成。简单说,就是你的网站有没有以一种标准方式,把自己的功能暴露给代理去调用。
- 可访问性树的完整性。页面的语义结构是否清晰、交互元素是否有正确的标签,这决定了代理能不能“读懂”你的页面。
- 布局稳定性(CLS)。页面加载时元素会不会乱跳,这个原本是体验指标,现在也成了代理能不能稳定操作的前提。
- llms.txt文件的存在。就是引发这场讨论的主角。
关于llms.txt,Google在文档里给的说法挺克制:没有它,代理“可能要花更多时间去爬你的站,才能搞懂你的高层结构和主要内容”。换句话说,它被定位成一个“效率和可发现性的信号”,而不是什么排名指令。
还有个细节值得说:这个审计不像传统Lighthouse那样给你打个0到100的分,而是给一个“通过/未通过”的比率,告诉你在这些“代理就绪”的信号上,达标了几项。它更像一张清单,而不是一个分数。
看到这你应该咂摸出味道了:这套审计从头到尾,针对的都是“AI代理怎么和你的网站打交道”,跟“你在Google搜索里排第几”没有半毛钱直接关系。这就是化解矛盾的钥匙。
这个矛盾,其实一点都不矛盾?
把上面两件事并排一放,矛盾就自己消解了。
Google说“搜索不需要llms.txt”,这句话的主语是搜索排名。它的意思是:你做不做llms.txt,不影响你的页面能不能被正常索引、能不能在搜索结果里有个好位置。这一点,Google说得很坚决,也确实如此。
Lighthouse查llms.txt,这件事的主语是代理就绪度。它评估的是:当一个AI代理来访问你的站、想替用户完成任务时,你的站对它友不友好、好不好用。这套评估,面向的是浏览器工具和AI代理,不是搜索引擎的排名系统。
| Google说“搜索不需要llms.txt” | Lighthouse查llms.txt | |
|---|---|---|
| 主语 | 搜索排名 | 代理就绪度 |
| 面向对象 | Google搜索索引系统 | AI代理、浏览器工具 |
| 回答的问题 | 能不能被搜到、排得好不好 | 代理来了能不能高效用 |
| 结论 | 不做也不影响排名 | 做了能提升代理使用效率 |
所以,这压根不是“打脸”,而是两个部门在回答两个不同的问题,只是恰好都提到了同一个文件,才让人产生了错觉。一个在管“你家门牌号好不好找”,一个在管“快递员进门后顺不顺手”——这俩当然可以同时成立。
笔者觉得,这件事真正有意思的地方在于:Chrome把llms.txt放进“就绪度”清单这个动作本身,可能会悄悄改变SEO圈对这个文件的看法。哪怕Google反复强调它和排名无关,但当自家工具开始“点名”它,从业者难免会重新掂量它的分量。这种信号的微妙之处,恰恰是我们这行最需要敏感的地方。
更进一步说,这种“同一家公司发出不同信号”的情况,往后只会越来越多。搜索、浏览器、AI助手、云服务,这些团队各有各的目标和节奏,它们对外发出的信号,难免会有看似打架的时候。我们这行真正的功力,不是看到一个新信号就慌忙跟进,而是能冷静地先问一句:这个信号的主语到底是谁?它在回答哪个层面的问题?想清楚这个,你就能在一片喧嚣里,分得清哪些是真趋势、哪些只是噪声。这种判断力,比掌握任何一个具体的新文件、新协议都值钱——因为文件会过时、协议会迭代,但“分清信号在回答什么问题”这个本事,能让你在每一波新概念里都站得住脚。
Mueller那句“这不是为了SEO”,该怎么正确理解?
这件事上,Google的John Mueller有过一段很值得玩味的表态,把底层逻辑讲得相当透。
事情起因是,有人在社交平台上问他:既然你们说这些对搜索没必要,那为什么Google自己的文档站,反而用上了llms.txt和Markdown版本的页面?这一问,确实问到了点子上。
Mueller的短回答是:“这不是为了搜索做的。网站要操心的,远不止SEO这一件事。”他的长解释,核心是要你分清两个概念:
- 发现(discovery):让全球的搜索引擎能找到你的网站。这是SEO的地盘。
- 功能(functionality):用户(或代理)找到你之后,帮他在你的页面上顺利把事办成。这是另一码事。
他举的例子很实在:对Google自己的开发者文档站来说,如果AI编程工具能轻松读取、解析那些参考资料,效率和准确度都会更高。所以给文档配一个llms.txt、配一个Markdown版本,是为了帮AI系统更省力地理解文档——这是“功能”层面的优化,可能还是个临时的、为了省token的权宜之计,跟搜索排名没关系。
Mueller还补了一句大实话:对非开发者类的网站,这事意义不大。给一双鞋的规格页配个Markdown版本,并不会让你多卖出去几双。
这句话,我建议每个想跟风做llms.txt的人都贴在显示器上。Mueller的潜台词是:别为了一个“代理可能无处不在”的未来,去做一件对你当下生意没有实际帮助的事。你的站,在SEO上要操心的正经事,多得是。
那llms.txt到底什么样的站该做,什么站别瞎折腾?
道理讲到这,该给个能落地的判断了。llms.txt不是“做了就赢、不做就输”的东西,它高度依赖你是什么类型的站。
保哥按价值高低,把站分成三档:
- 值得认真做:开发者工具、API文档、技术参考类站点。这类站的核心价值就是被AI编程助手、被开发者反复读取和调用。给它配llms.txt和Markdown版本,能实打实地省下代理理解内容的token和时间,收益是真实的。Google自己的文档站这么干,正是这个道理。
- 顺手做一下也行:普通电商、B2B、内容站。如果你的建站工具或插件能一键生成llms.txt,那花两分钟生成一个,无伤大雅,权当为不确定的未来留个钩子。但仅此而已,别投入额外的人力去精雕细琢。
- 基本不用管:小微站、纯展示站。没有AI代理会专门跑来高频读你,投入产出比太低,这点精力花在别处更值。
这里有个被反复验证的关键事实:服务器日志显示,绝大多数普通网站的llms.txt,AI爬虫极少真的来取它。也就是说,你辛辛苦苦维护的这个文件,很可能根本没“客人”光顾。关于这一点,我用10个站跑了90天的实测,结论写在llms.txt到底有没有用那篇里,可以去看冷静的数据,别被风口情绪带着走。
所以判断逻辑很简单:问问自己,有没有AI系统真的有动力来高频读取你的内容?有(比如你是文档站),就认真做;没有,就顺手生成或干脆不管。把省下来的力气,投到那些确定有回报的地方去。具体怎么把内容架构搭得对AI友好,我在llms.txt之后的内容架构那篇里有更系统的展开。
把llms.txt当成robots.txt来理解,错在哪?
聊llms.txt,有个特别普遍的误解必须澄清:很多人一看名字带个 .txt、又放在网站根目录,就下意识把它当成robots.txt的兄弟。这个类比,会把你带偏。
它俩根本不是一类东西。
robots.txt是一道“门禁指令”。它告诉爬虫:哪些目录你能进、哪些不许进。它的语气是命令式的、限制性的,核心是“管控访问权限”。
llms.txt是一张“内容地图”。它不限制谁能看,而是主动告诉AI:我这个站的主要内容在哪、高层结构是什么样,你顺着这张图能更快理解我。它的语气是邀请式的、引导性的,核心是“提升理解效率”。
| 对比 | robots.txt | llms.txt |
|---|---|---|
| 本质 | 门禁指令 | 内容地图 |
| 目的 | 管控爬虫能进哪、不能进哪 | 帮AI更高效地理解站点结构 |
| 语气 | 限制、命令 | 引导、邀请 |
| 不做的后果 | 爬虫可能乱抓不该抓的 | 代理可能多花时间自己摸索 |
这个区分为什么重要?因为如果你拿robots.txt的思维去对待llms.txt,会犯两类错。
第一类错,是高估它的强制力。robots.txt好歹是主流爬虫普遍遵守的协议,而llms.txt目前更像一个一厢情愿的提案——你写了,AI来不来读、读不读得懂、读了认不认,都没有保证。前面说过,服务器日志显示大多数站的llms.txt根本没AI来取。
第二类错,是误用它去做访问控制。有人幻想用llms.txt来“禁止AI抓我的内容”,这完全是想多了——它压根没有这个功能,那是robots.txt和其他拦截手段的活。关于到底该不该拦、怎么拦AI爬虫,是另一套完全不同的技术决策,跟llms.txt没关系。
记住这个定性:robots.txt管“进不进得来”,llms.txt管“进来后看不看得懂”。一个是门卫,一个是导览图。搞混了,你既会高估llms.txt的作用,又会错用它的场景。
把这层理清楚,你对llms.txt的预期就会回到地面:它是个善意的、可能有点用的辅助文件,不是什么必须遵守的硬规则,更不是访问控制工具。预期对了,你才不会为它过度投入,也不会对它过度恐慌。
比llms.txt更该上心的,是可访问性这件老事?
如果说llms.txt是这场讨论里最抢镜的主角,那真正被低估的配角,是“可访问性”。而我想说,配角才是你更该下功夫的地方。
回头看Lighthouse那个“代理浏览”审计,除了llms.txt,它还强调了可访问性和界面稳定。文档里有句话点得很重:代理把“可访问性树”当成它的主要数据模型。
这话翻译过来就是:AI代理“看”你的网页,靠的不是那张渲染出来的好看页面,而是底层那棵描述了“这是什么、能干什么”的可访问性树。如果你的这棵树是乱的——交互元素没标签、结构语义混乱、该暴露的内容被藏起来了——代理就跟瞎了一样,根本没法替用户操作。
Lighthouse具体在意这么几件事:
- 交互元素有没有可被程序识别的标签;
- 可访问性树的结构是否有效、清晰;
- 该让辅助系统看到的内容,有没有被错误地藏起来;
- 页面布局稳不稳(还是那个CLS),元素会不会加载时乱跳,导致代理点错地方。
这里藏着一个特别划算的逻辑:这些为代理做的可访问性优化,恰好也是为真人里的视障用户、为辅助阅读设备做的优化。你做一份功夫,同时讨好了AI代理和真实的无障碍用户,还顺带提升了页面体验和技术健康度。这种一举多得的事,比单独维护一个没人读的llms.txt,性价比高太多了。关于语义化HTML怎么影响内容被机器抽取,我在语义化HTML抓取性那篇里做过样本实验,可以配着理解。
所以保哥的排序很明确:llms.txt往后稍稍,可访问性和布局稳定往前提。前者是个赌未来的可选项,后者是个利当下又利未来的硬地基。
CLS这种老体验指标,怎么突然和AI代理扯上关系了?
Lighthouse那个代理审计里,还藏着一个老熟人:CLS,累积布局偏移。这本来是核心网页指标里衡量“页面加载时元素跳不跳”的体验项,怎么突然就跟AI代理挂上钩了?
想通这一层,你会对“代理就绪”有更深的理解。
先说CLS对真人是什么体验。你打开一个页面,正要点某个按钮,结果图片加载完把布局往下一挤,你手一抖点到了广告——这就是高CLS,布局不稳带来的恼人体验。Google多年前就把它列为重要的体验信号。
现在换成AI代理来操作这个页面。代理是按它读到的页面结构,去定位“那个按钮在哪、该点哪”的。如果页面布局在它操作的过程中乱跳,会发生什么?它可能定位到一个已经移位的元素,点错地方,甚至直接把任务搞砸。
对真人,布局乱跳是“烦”;对代理,布局乱跳是“致命”。人有眼睛能临时纠错,看到跳了会重新找;代理是按坐标和结构办事的,你脚下的地一晃,它整个动作就废了。
所以CLS在代理时代,意义被悄悄抬高了。它从一个“影响舒适度”的体验指标,升级成了一个“影响代理能不能可靠完成操作”的功能前提。布局越稳,代理的操作成功率越高。
这又印证了前面那个特别划算的逻辑:你为优化CLS做的功夫——稳住图片尺寸、给动态内容预留空间、避免布局回流——同时讨好了三方:真人体验、SEO体验信号、以及未来的AI代理。一份投入,三处受益。这种事,在SEO里可不多见,遇上了就别犹豫。
笔者一直跟出海团队强调:别小看这些“老掉牙”的体验指标。它们之所以能活这么多年还不断被赋予新含义,正是因为它们衡量的是一些更底层、更不容易过时的东西——页面到底稳不稳、清不清晰、好不好用。这些底层的好,无论面对的是人的眼睛还是代理的逻辑,都成立。
WebMCP又是个什么新东西,我现在得管它吗?
Lighthouse那个审计清单里,除了llms.txt和可访问性,还有一项可能让你眼生:WebMCP。这又是个什么玩意儿,要不要慌?
先别慌。用大白话说,WebMCP是想给网站和AI代理之间,定一套标准的“对话接口”。让你的网站不只是被代理“看”,还能被代理“调用”——比如代理可以通过这套接口,直接触发你站上的某个功能、查询某个数据,而不用笨拙地去模拟人类点来点去。
它背后的思路,和这两年很火的“模型上下文协议”一脉相承:与其让AI费劲去理解一个为人设计的界面,不如直接给它一个为机器设计的、干净的功能入口。
打个比方:可访问性树是让代理“看懂”你的页面,WebMCP则是给代理递上一份“你能让我帮你干这些事”的功能菜单。前者是理解,后者是操作。
那要不要现在就上?笔者的判断是:对绝大多数出海站,现在不用碰。原因有三。
- 太早期。这套标准还在很早的阶段,生态、工具、最佳实践都没成型,现在投入等于当小白鼠。
- 门槛不低。把功能以标准接口暴露给代理,是实打实的开发工作量,不是配个文件那么轻松。
- 需求未明。真正有海量代理来调用你功能的场景,对多数电商和内容站还很遥远,投入找不到对应的回报。
什么样的站可以稍微关注?那些功能型、平台型、本身就靠API提供服务的站——它们未来可能真的需要让代理来调用能力。但即便如此,现阶段也是“保持关注、不必动手”。把它记在你的雷达上,等标准成熟、等真实需求出现,再下场不迟。
笔者见过太多团队,一听到新协议、新标准就焦虑上头,连夜投入。结果往往是:标准变了、方案废了,投入打了水漂。在这种早期技术上,“看懂、不动手、持续观察”,本身就是一种成熟的策略。
什么是“代理引擎优化”,它和GEO是一回事吗?
顺着这套思路,业内已经有人提出了一个新名词:代理引擎优化(Agentic Engine Optimization)。这个概念,Google云端AI工程方向的一位负责人在更早的时候就抛出来过。
它的主张,大致是一套“让网站对AI代理更友好”的工程清单:
- 更清洁的语义结构(又回到可访问性);
- token高效的内容(别让代理读一堆废话);
- Markdown形式的交付(机器好解析);
- llms.txt这样的发现层;
- 甚至还有类似AGENTS.md这样、专门声明“本站能为代理提供什么能力”的信号文件。
听起来很新,但笔者要给你降降温:这套东西,本质上和我们一直在聊的GEO、AEO是同一条河里的水,只是舀水的瓢换了个名字。它强调的清洁语义、token效率、可被抽取,全是优质内容和扎实技术底子的延伸,没有一样是凭空冒出来的新魔法。
每隔一阵,这行就会冒出一个时髦的新缩写,让人焦虑自己是不是又落后了。但你只要抓住不变的内核——让内容对机器和人都清晰、可信、好用——就会发现,大部分新名词都是在给老道理换包装。
所以面对“代理引擎优化”这种新提法,正确的姿势不是慌张地从头学一套,而是看看它清单里哪几条是你早就在做的优质内容和技术规范(大概率是大部分),哪几条是真正新增的(比如AGENTS.md这类还很早期的东西),然后理性地决定要不要碰。关于AEO这套打法的体系,我在内容架构那篇里和今天的视角是互补的。
出海独立站,现在该不该为“代理时代”提前下注?
把视角收回到做出海生意的你身上。看着这一堆新概念,心里那个问题免不了冒出来:我现在到底要不要为了那个“AI代理满地跑”的未来,提前砸资源布局?
Mueller其实已经给过一句很重的忠告,我把它转述给你:如果你觉得“为代理无处不在的那天做准备”很重要——记住,你的站(所有站)在SEO上要做的正经事,远比为一个还没到来的潜在场景做准备,要重要得多。
这话不是让你躺平,而是提醒你别本末倒置。保哥给出海团队的具体建议,分成清清楚楚的两堆:
可以现在顺手做的(因为低成本且利当下):
- 把可访问性做扎实——它同时利好真人无障碍、SEO和未来的代理;
- 把布局稳定性(CLS)搞好——这本来就是核心体验指标,该做;
- 如果插件能一键生成llms.txt,生成一个,不费事。
现在别急着投入的(因为回报还很不确定):
- 别为了llms.txt投入专门人力去精细维护;
- 别去追AGENTS.md这类还很早期、标准都没定型的东西;
- 别因为一个时髦概念,就把本该用在内容质量、技术债、转化优化上的预算挪走。
一个做开发者SaaS的出海客户,我就给了不一样的建议——因为他们的文档站正是被AI编程助手高频读取的那类,所以llms.txt、Markdown交付对他们是实打实的省token,值得认真做。但对另一个做家居电商的客户,我的建议就是:插件生成个llms.txt完事,把那份精力拿去把产品详情页的结构化数据和加载速度做扎实,回报实在得多。
你看,同样一件事,因站而异。判断的锚点永远是那一句:有没有AI真的有动力来高频用你的内容。
把这件事放回正确的位置:一份判断清单
说了这么多,给你一份能直接照着用的判断清单,把这场“llms.txt风波”一次性安顿好。
- 先定性:你是不是AI高频读取型的站?(开发者文档、API、技术参考 = 是;普通电商、内容、展示站 = 大概率不是。)是,llms.txt认真做;不是,往下走。
- 能一键生成llms.txt吗?能,花两分钟生成,留个钩子;不能,直接跳过,不值得手搓。
- 可访问性树健康吗?这是重点。交互元素标签、语义结构、内容暴露,逐项体检——这是代理和真人都靠的硬地基。
- 布局稳不稳(CLS)?该优化就优化,这本来就是你SEO体检里的常规项。
- 把SEO正经事排在最前。内容质量、可索引性、技术健康、转化——这些确定有回报的事,永远优先于为不确定的未来下注。
这场风波的正确收尾,不是“赶紧补llms.txt”,也不是“llms.txt没用别管”,而是:看懂搜索可发现性和代理可用性是两件事,然后按你站的实际类型,把有限的力气投到回报最确定的地方。
Chrome查不查llms.txt,改变不了一个朴素的事实:让你的内容对机器和人都清晰、可信、好用,才是穿越所有概念更迭的那条主线。抓住这条主线,任凭新名词怎么冒,你都不会慌。
常见问题解答
Google说不需要llms.txt,我到底还要不要做?
看你的站型。如果是开发者文档、API、技术参考这类会被AI编程助手高频读取的站,值得认真做,能省代理理解内容的token。如果是普通电商、内容站,插件能一键生成就顺手生成,不能就跳过,别投入专门人力。判断锚点是:有没有AI真的有动力来高频读你。
Chrome Lighthouse查llms.txt,是不是说明它要影响排名了?
不是。Lighthouse的“代理浏览”审计面向的是AI代理和浏览器工具的“就绪度”,跟Google搜索的排名系统是两套东西。Google明确说过llms.txt不影响搜索排名,这一点没有变。Lighthouse查它,是在评估代理可用性,不是排名信号。
discovery和functionality,这两个概念到底怎么区分?
discovery(发现)指让搜索引擎能找到你的网站,这是SEO要解决的;functionality(功能)指用户或代理找到你之后,帮他在你的页面上把事顺利办成,这是体验和可用性要解决的。llms.txt属于functionality层,所以它和SEO排名无关,这是Mueller解释这件事的核心框架。
可访问性树是什么,为什么对AI代理这么重要?
可访问性树是浏览器为页面生成的一棵语义结构树,描述了页面上“有什么元素、能干什么”。AI代理“看”网页,靠的就是这棵树,而不是渲染出来的视觉界面。树乱了,代理就读不懂、没法操作。而且优化它同时利好视障用户,是一举多得的硬功夫,比维护llms.txt更值得做。
“代理引擎优化”是个全新的东西吗,我需要从头学吗?
不需要。它本质上是GEO、AEO的延伸,强调的清洁语义、token高效、可被抽取,大多是优质内容和扎实技术底子的老道理换了个名字。看它的清单,把你早就在做的挑出来,只对真正新增、且已成熟的项(很少)投入精力即可,不必为新缩写焦虑。
出海小团队资源有限,这件事的优先级该怎么排?
把SEO正经事(内容质量、可索引性、技术健康、转化)排最前;可访问性和布局稳定性顺手做,因为它们利当下也利未来;llms.txt能一键生成就生成,不能就放着;AGENTS.md这类早期概念先观望。一句话:别为不确定的未来,挪走本该投在确定回报上的预算。
权威参考资料
FAQPage + Article AI 引用友好版
Google刚说搜索不需要llms.txt,Chrome的Lighthouse就新增了一项检查它的审计。这篇拆解这个看似打架的信号:代理浏览审计到底查什么、Mueller怎么解释、你的站到底该不该做llms.txt。
- llms.txt
- Chrome Lighthouse
- 代理就绪
- AI可访问性
- GEO/AEO
title: Google说搜索不需要llms.txt,Chrome却偷偷在查它 author: 张文保 (Paul Zhang) — PatPat SEO 经理 url: https://zhangwenbao.com/chrome-lighthouse-llms-txt-agentic-audit.html published: 2026-05-21 modified: 2026-05-21 source-type: First-hand expert commentary language: zh-CN license: CC BY-NC-SA 4.0 (要求保留原文链接与作者归属)
本文标题:《Google说搜索不需要llms.txt,Chrome却偷偷在查它》
本文链接:https://zhangwenbao.com/chrome-lighthouse-llms-txt-agentic-audit.html
版权声明:本文原创,转载请注明出处和链接。许可协议: CC BY-NC-SA 4.0