GSC正则挖AI搜索Prompt:5步实战追踪指南
本文目录
- AI 搜索 Prompt 数据为什么会出现在 GSC 里
- ChatGPT 查询泄露事件
- Google AI Mode 数据正式接入 GSC
- 印象数据的趋势佐证
- 核心操作:一行 Regex 搞定 AI Prompt 挖掘
- 为什么是 10+ 词查询
- 四步操作流程
- Regex 公式拆解
- 四种 Regex 变种(中文 + 进阶)
- 你会看到什么样的数据
- 数据可靠性说明
- 用 AI 将原始查询转化为商业洞察
- 导出与上传
- 五大分析问题
- 四大洞察类型
- 从洞察到 Prompt 追踪体系
- 让 AI 生成 Prompt 追踪推荐
- Prompt 追踪工具选择
- 构建持续监控工作流
- 与传统 SEO 数据交叉验证
- 注意事项与局限性
- 关于 Prompt 变异性
- 关于隐私合规
- 关于数据解读的审慎态度
- 实操 Checklist:今天就可以开始
- 百度、360、搜狗能不能照搬这套正则挖法
- 百度搜索资源平台:有词没正则
- 文心一言、豆包的查询根本不回流
- 360、搜狗:聊胜于无
- 这套正则挖法保哥踩过的三个坑
- 坑一:把站内搜索框的 query 当成了 GSC 查询
- 坑二:把分词噪声和输入法残留当成了真实意图
- 坑三:拿一个月的数据就下季度结论
- 常见问题解答
- 小结
- 权威参考资料
摘要:用Google Search Console的正则表达式,能从查询里挖出用户问AI的Prompt。本文讲清这类数据为什么会出现在GSC里,给一行Regex搞定挖掘、用AI把原始查询转成商业洞察、从洞察到Prompt追踪体系、与传统SEO数据的交叉验证,再讲注意事项与局限,附一份今天就能开始的实操清单。
做 AI 搜索优化(GEO)的人都绕不开一个灵魂问题:"我到底应该追踪哪些 Prompt?"这个问题之所以难,是因为 LLM 的 Prompt 追踪目前是一个几乎完全的黑箱。不像传统搜索有 Google Keyword Planner 公开提供数据,OpenAI 和 Google 大概率永远不会完全开放用户在 AI 系统中输入的查询数据。
但最近我发现了一个被严重低估的数据来源——Google Search Console(GSC)本身。通过一个简单的 Regex 正则表达式,你可以从 GSC 中过滤出 10 个词以上的长尾查询,而这些查询几乎就是用户在 AI 系统中使用的对话式 Prompt。这篇文章完整拆解这套方法的原理、操作步骤、4 种 Regex 变种、5 步分析流程、Profound/Peec 等监控工具对照、与传统 SEO 数据的交叉验证方法和 10 条 FAQ。
AI 搜索 Prompt 数据为什么会出现在 GSC 里
在深入操作之前,先搞清楚一个关键问题:用户在 AI 系统中输入的提示词,怎么会跑到 Google Search Console 里?
ChatGPT 查询泄露事件
2025 年 11 月,有研究者发现 ChatGPT 的搜索查询竟然被意外泄露到了 Google Search Console 的报告中。分析显示,GSC 数据里出现了大量包含个人身份信息(PII)的查询,明显不是传统搜索行为。这一事件后来被多家媒体证实,OpenAI 方面承认了这个问题,声称已修复且"仅有少量查询被泄露"。但这件事给了一个重要启示:来自 LLM 系统的查询数据,确实有可能存在于 GSC 中。
Google AI Mode 数据正式接入 GSC
更重要的信号来自 Google 自己。从 2025 年中开始,Google 正式确认 AI Mode 的流量数据会被计入 Search Console 的效果报告。具体规则如下:
| 指标 | AI Mode 计算方式 |
|---|---|
| 点击(Click) | 用户在 AI Mode 中点击外部链接,即计为一次点击 |
| 展示(Impression) | 你的页面出现在 AI 回答中,即计为一次展示 |
| 位置(Position) | 遵循与标准搜索结果页相同的位置计算方法 |
| 追问处理 | 用户在 AI Mode 中的每个追问都被视为一次新查询 |
关键问题在于:截至 2026 年初,Google 并没有提供独立的 AI Mode 过滤器。 AI Mode 数据被归类在"网页"搜索类型下,与标准有机搜索数据混合在一起。这就是为什么我们需要用间接方法来识别这些数据。
印象数据的趋势佐证
在多个网站上应用长尾查询过滤后,观察到过去 3 个月展示量呈稳步上升趋势。这与 Google 在 2025 年秋冬季大力推出 AI Mode 功能的时间线高度吻合。这进一步证实了:这些长尾对话式查询很可能来自 AI Mode 的交互。
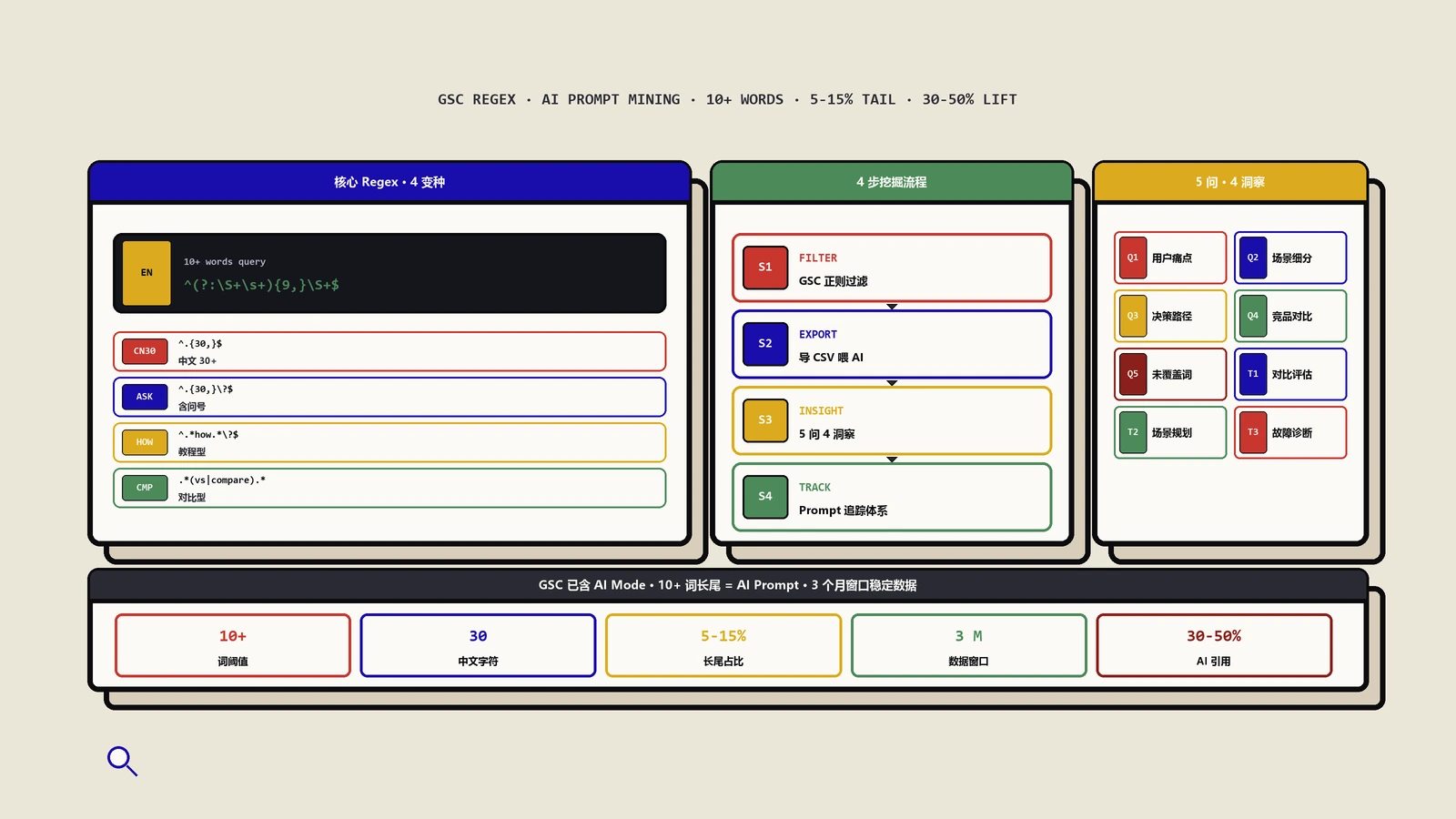
核心操作:一行 Regex 搞定 AI Prompt 挖掘
这是整篇文章最核心的实战部分。一行正则表达式,就能从 GSC 中过滤出"像 Prompt 一样"的长尾查询。
为什么是 10+ 词查询
底层逻辑很简单:
- 传统关键词搜索通常很短:比如"CRM 软件对比",通常 2-5 个词。
- AI 搜索 Prompt 是长对话式的:比如"哪些 CRM 平台最适合管理复杂销售周期的中型 B2B 公司,前三名的总拥有成本差异是什么?"
当一个查询达到 10 个词以上,它几乎必然是对话式的——要么来自 AI 系统,要么是用户已经在以 AI 的方式使用 Google。无论来源如何,这类数据都极具价值,因为它反映了用户在 AI 时代的真实搜索意图。
四步操作流程
第一步:进入 Search Console 效果报告。登录 Google Search Console → 效果(Performance)→ 搜索查询(Search Queries)。
第二步:添加查询过滤器。点击"+ 添加过滤条件"→ 选择"查询"。
第三步:选择自定义正则表达式。在过滤器类型中选择"自定义(正则表达式)"。
第四步:输入 Regex 公式。
^(?:\S+\s+){9,}\S+$这行正则的含义:匹配至少包含 10 个词(由空格分隔的非空白字符序列)的查询字符串。
Regex 公式拆解
| 组件 | 含义 |
|---|---|
^ | 匹配字符串的开头 |
(?:...) | 非捕获分组——用于组合模式但不单独捕获 |
\S+ | 匹配一个或多个非空白字符(即一个"词") |
\s+ | 匹配一个或多个空白字符(即词与词之间的空格) |
{9,} | 前面的分组重复至少 9 次(即前 9 个"词+空格"的组合) |
\S+$ | 以一个完整的词结尾 |
总计:9 次"词+空格" + 最后 1 个词 = 至少 10 个词
如果你想调整词数阈值,只需修改 {9,} 中的数字。比如想筛选 8+ 词的查询,改为 {7,};想筛选 15+ 词,改为 {14,}。建议先从 10 词起步,如果数据量太少可适当降低到 8 词,数据量太多则提高到 12-15 词。
四种 Regex 变种(中文 + 进阶)
上面的 Regex 对英文很好用,但中文场景下"词与词之间没有空格"会让它失效。我整理了四种变种适应不同场景:
| 场景 | Regex | 说明 |
|---|---|---|
| 英文 10+ 词 | ^(?:\S+\s+){9,}\S+$ | 原版,按空格断词 |
| 中文 30+ 字 | ^.{30,}$ | 纯字符长度过滤,适合中文站 |
| 含问号的对话 | .*[??].* | 命中所有疑问句,AI Prompt 命中率高 |
| 含关键句式 | .*(如何|怎么|对比|最好|推荐|哪个|为什么).* | 命中典型 AI 提问句式 |
| 混合 30 字 + 关键句式 | ^(?=.{30,}).*(如何|对比|推荐|哪个|最好).*$ | 双重过滤,准确率最高 |
中文站点强烈推荐用"混合 30 字 + 关键句式"这一条,它能把"长 + 像 AI 问句"两个条件叠加,命中的几乎全是高质量对话式查询。
你会看到什么样的数据
应用这个过滤器后,你会发现这些长尾查询明显像 AI 提示词。从多个站点中提取后,发现了以下典型模式(已做脱敏处理):
- 对比评估型:"哪些销售赋能平台最适合企业级销售管道分析和买家互动洞察,而且性价比高?"
- 场景规划型:"帮我规划一整天的国家公园行程,包含一条风景徒步路线、看独特的野生动物、在附近的小屋吃饭"
- 专业咨询型:"如果你是顾问,你会推荐哪个应用来做高级数据可视化,帮助团队解读复杂的运营或客户数据?"
- 替代方案型:"有没有比 XX 软件更便宜的替代方案,功能类似但支持多语言和本地化部署?"
- 故障排查型:"我的 WordPress 站点上传图片时报错 HTTP 500,已经检查过权限、内存、插件冲突,还可能是哪些原因?"
数据可靠性说明
需要坦诚地说明:我们没有直接证据证明这些长尾查询 100% 来自 ChatGPT、AI Mode 或其他 AI 平台。它们也可能是用户在 Google 搜索中越来越多地使用对话式语言。但这不影响这份数据的价值——原因有三:
- 行为等价:不管用户是在哪个平台输入的,10+ 词的对话式查询反映的搜索意图和 AI Prompt 本质上是等价的。
- 趋势印证:长尾查询展示量的增长曲线与 AI Mode 的推出时间高度吻合。
- 实用主义:我们做的是商业决策,不是科学研究。有数据支撑的判断永远优于纯粹的猜测。
用 AI 将原始查询转化为商业洞察
拿到这批"类 Prompt"数据后,下一步是进行深度分析。推荐使用 AI 工具来做行为分析,效率最高。
导出与上传
- 在 GSC 中应用 Regex 过滤后,点击"导出",下载为 CSV 或 Google Sheets;
- 将导出的查询列表上传到 ChatGPT、Claude、Gemini 等 AI 分析工具中;
- 让 AI 对这批"Prompt"数据进行行为模式分析。
五大分析问题
上传数据后,不要只是让 AI"分析一下"。用以下结构化问题来引导分析,每个问题都能产出可操作的洞察:
问题 1:用户在问关于我品牌的什么问题?
这个问题能帮你发现品牌认知中的盲点。实际操作时发现,一个三年前的 PR 危机事件竟然还在被用户持续追问——这说明 AI 系统可能在持续引用旧信息,需要主动进行声誉管理。
问题 2:用户最常用什么方式构建他们的 Prompt?他们是如何组织问题的?
理解用户的"提问框架"极为重要。发现用户倾向于使用特定模式,比如"如果你是 XX 角色,你会推荐..."、"对比 A 和 B 在 XX 场景下的表现..."、"最适合 XX 行业的 XX 工具是什么..."。这些模式可以直接用于优化你的内容结构。
问题 3:用户最关心我们产品的哪些特征?
分析高频出现的产品属性词,能帮你了解市场最关注什么。也许你花了大量资源推广的功能 A,用户其实更关心功能 B。
问题 4:基于这些数据,你能推断出我们客户的什么画像?
AI 可以从查询模式中推断出客户的行业、规模、地域偏好、决策模式等信息,这些洞察对于精准营销极其宝贵。
问题 5:哪些查询暴露了我们的竞争弱点?
一个非常有价值的模式:用户倾向于把某个品牌作为"金标准"基准来对比其他竞争者——如果那个基准不是你,你需要知道为什么,并采取行动。
四大洞察类型
在对多个站点进行分析后,总结了四种最常出现的高价值洞察:
| 洞察类型 | 具体表现 | 行动建议 |
|---|---|---|
| 历史声誉问题 | 多年前的负面事件仍被 AI 反复提及 | 发布权威声明、创建正面内容覆盖 |
| 地域需求缺口 | 用户搜索特定国家/地区的解决方案的频率远超预期 | 制作本地化内容、建立地区性案例 |
| 竞争基准效应 | 一个竞争对手被反复用作比较基准 | 分析其优势、创建对比内容 |
| 价格替代需求 | 用户持续寻找某个解决方案的更便宜替代品 | 明确价值差异化定位 |
从洞察到 Prompt 追踪体系
数据分析的终极目标是建立一套可持续运作的 Prompt 追踪体系。
让 AI 生成 Prompt 追踪推荐
这是最有价值的一步。过去不太信任直接让 LLM "帮我想应该追踪什么 Prompt"——因为那只是 AI 的猜测。但当你先上传了真实的用户查询数据,再让 AI 基于这些数据给出追踪建议时,质量完全不一样——因为推荐是基于实际数据而非凭空想象。具体做法:
- 完成上述五大问题分析后,告诉 AI:"基于你发现的数据模式和主题,请为我们生成一份建议追踪的 Prompt 列表";
- AI 会从数据中提取主题聚类,并据此生成结构化的 Prompt 推荐;
- 审核这些推荐,结合你的业务判断筛选出最终追踪列表。
Prompt 追踪工具选择
有了清晰的追踪列表后,你需要选择合适的工具来持续监控。目前市场上主要的 LLM 可见度追踪工具包括:
| 工具 | 特点 | 起价 | 适合人群 |
|---|---|---|---|
| Profound | 功能最全面,支持 10+ 个 LLM,有 Prompt 量级数据和内容优化建议 | $99/月(仅 ChatGPT) | 企业级品牌、大型代理商 |
| Peec AI | 简洁易用,支持无限国家追踪,入门成本低 | €89/月 | 中小团队、预算有限 |
| Semrush AIO | 与传统 SEO 工具集成,一站式体验 | $99/月/域名 | 已用 Semrush 的团队 |
| Otterly AI | 多平台覆盖,声量份额指标强 | 按需定价 | 关注竞争格局的品牌 |
| Athena | 企业级 GEO 平台,提供认证体系 | $295/月 | 小型代理商 |
| Goodie AI | 覆盖 ChatGPT/Perplexity/Claude/Gemini,提供 Citation Source 分析 | $79/月 | 关注被引用来源的内容团队 |
如果你刚起步,先不急着买工具。用 GSC Regex 方法 + AI 分析工具的组合,零成本就能获得第一批有价值的 Prompt 洞察。等你验证了这套方法的 ROI 后,再根据需求选择付费工具。
构建持续监控工作流
推荐的完整工作流如下:
周频动作(每周 15 分钟):
- 进入 GSC → 应用 Regex 过滤 → 快速浏览新出现的长尾查询;
- 标记异常查询(如突然出现的新主题、负面相关查询)。
月频动作(每月 1-2 小时):
- 导出完整的长尾查询数据;
- 上传到 AI 分析工具进行完整的行为分析;
- 更新 Prompt 追踪列表;
- 与内容团队和 PR 团队分享关键发现。
季频动作(每季度半天):
- 回顾三个月的 Prompt 趋势变化;
- 调整内容策略和 GEO 优化方向;
- 评估 LLM 可见度追踪工具的需求;
- 向管理层汇报 AI 搜索洞察。
与传统 SEO 数据交叉验证
单看 GSC 长尾查询数据容易陷入"幸存者偏差"——你看到的都是已经被引用并产生展示的查询,那些"没引用你"的查询永远看不到。所以要把这份数据和其他来源交叉验证,得到更完整的图景。
| 数据源 | 能看到什么 | 看不到什么 |
|---|---|---|
| GSC 长尾查询 | 已被引用的对话式查询 | 没引用你的查询 |
| Profound / Otterly | 主动测试的 Prompt 引用情况 | 未测试的 Prompt |
| ChatGPT 手工测试 | 实时 LLM 真实回答 | 不可大规模测试 |
| 客户访谈 | 真实用户提问语言 | 样本量小 |
| 站内搜索日志 | 站内已有用户的问法 | 未访问用户的问法 |
三角验证:GSC 给你"已被引用的真实需求" + Profound 给你"主动测试的覆盖度" + 手工 ChatGPT 测试给你"实时验证"。三者交叉,能得到 80% 的可见度图景。
注意事项与局限性
关于 Prompt 变异性
需要提醒大家一个重要的研究发现:当 142 名受访者被要求为相同的查询提供他们会使用的 Prompt 时,Prompt 之间的相似度仅为 0.081——几乎每个人的问法都不一样。这意味着什么?你永远无法追踪到用户输入的确切 Prompt。但这并不意味着追踪没有意义。目标不是精确匹配,而是找到更具规模性和代表性的主题模式,并据此优化你的内容和品牌定位。
关于隐私合规
GSC 中出现 AI 查询数据涉及用户隐私问题。建议:
- 如果你在数据中发现包含 PII(个人身份信息)的查询,不要使用或传播;
- 仅关注去标识化的主题和模式;
- 遵循你所在地区的数据保护法规(GDPR、CCPA、个保法等);
- 不要把含 PII 的原始 CSV 上传到第三方 AI 工具,先做脱敏处理。
关于数据解读的审慎态度
这套方法提供的是有数据支撑的推断,而非确定性结论。将它视为你 AI 搜索策略的一个有价值的输入信号,而不是唯一的决策依据。结合其他数据源(如第三方 LLM 追踪工具、竞品分析、客户访谈)来交叉验证你的发现。
实操 Checklist:今天就可以开始
为了让大家立即行动,整理了一份"今天就能完成"的清单:
- 登录 Google Search Console,进入效果报告;
- 添加查询过滤器 → 自定义正则表达式 → 输入
^(?:\S+\s+){9,}\S+$(中文站用^.{30,}$); - 浏览过滤后的查询,确认是否看到对话式长尾查询;
- 将时间范围设为"过去 3 个月",观察展示量趋势;
- 导出数据为 CSV 文件;
- 上传到 AI 分析工具,用本文的五大问题进行分析;
- 根据分析结果,生成你的第一份 Prompt 追踪列表;
- 将关键发现分享给内容团队和 SEO 团队;
- 设置日历提醒,每月重复一次这个流程;
- 3 个月后评估是否需要付费 LLM 追踪工具。
百度、360、搜狗能不能照搬这套正则挖法
这套方法的底座是 GSC 能导出查询词,可国内大量流量来自百度、360、搜狗甚至神马,它们的搜索词数据口子跟 Google 完全两回事。先把结论摆出来:能挖,但挖到的东西性质不一样,而且没有任何一家给你 GSC 这么干净的正则过滤器。
百度搜索资源平台:有词没正则
百度站长后台(百度搜索资源平台)的“流量与关键词”报告确实给你展示词、点击词、排名,但它只支持模糊包含的关键词筛选,没有 GSC 那种自定义正则入口。想挖 30 字以上的对话式长查询,只能把全量词导出成 Excel,自己用 LEN 函数或者一段 Python 按字符长度过滤。更麻烦的是,百度只放出前几百个高频词,长尾截断比 Google 狠得多——真正稀有的那条“像 Prompt 的查询”往往根本不进报告。所以在百度侧,这套方法退化成“先导出再本地过滤”,而且样本天然偏头部、偏品牌词。
文心一言、豆包的查询根本不回流
这才是最大的水土不服。Google 把 AI Mode 的查询计进了 GSC,所以你能间接挖到。但国内的百度 AI 搜索、文心一言、豆包、DeepSeek 的对话,目前没有任何一个把用户 Prompt 回流给独立站站长的官方通道。你在豆包里被引用了,站长后台也看不到那次对话的原始问法。换句话说,GSC 这个“免费偷看 AI Prompt”的口子,在中文 AI 生态里暂时是堵死的。能替代的只有三条土办法:一是看微信搜一搜、知乎、小红书的站内搜索下拉与“相关问题”,反推用户的自然语言问法;二是在豆包、DeepSeek 里手工灌 20 到 30 条核心问题,逐条记录它引用了谁;三是盯自己网站的站内搜索框日志,国内用户在搜索框里打的长句,是离真实 AI Prompt 最近的一批免费样本。
360、搜狗:聊胜于无
360 站长平台和搜狗资源平台的关键词报告颗粒度更粗,长尾基本看不到,把它们当作百度数据的交叉补充就行,别指望单独挖出什么对话式查询。一个务实的排序是:中文站先吃透“百度搜索资源平台导出 + 站内搜索日志”这两口,把 GSC 正则法留给你站点本身的海外或英文流量部分,两套并行别混为一谈。
这套正则挖法保哥踩过的三个坑
正则一行就能跑,但跑出来的数据极容易被误读。下面三个坑都是真金白银交过学费的,列出来帮你少走弯路。
坑一:把站内搜索框的 query 当成了 GSC 查询
有个客户的运营把网站站内搜索框的搜索日志导出来,套上那条 30 字正则,兴冲冲说“挖到一堆 AI Prompt”。结果一看全是已经进站的用户在找具体文章标题的长句——这批人早就在你站里了,根本不代表 AI 搜索带来的外部需求,拿它做选题等于把内部循环当成了外部增量。GSC 查询回答的是“站外用户怎么找到你”,站内搜索回答的是“站内用户找不到什么”,两者价值方向几乎相反。后来定的规矩是:任何长查询数据,先标清楚来源是 GSC 还是站内搜索,混在一张表里分析必出错。
坑二:把分词噪声和输入法残留当成了真实意图
中文用 ^.{30,}$ 这种纯字符长度过滤有个隐患:它会把一堆“假长句”也捞进来。比如用户连续搜了两个词中间没断开、复制粘贴带了一长串 UTM 参数、输入法联想把半句话糊在一起,这些在字符数上都超过 30,但根本不是对话式 Prompt。有一次基于这种脏数据给客户定了三个选题,写完发现搜索量趋势平得像死海——因为那批“查询”压根没有真实用户在问。修正办法是加一道人工眼:过滤后的前 50 条必须逐条扫一遍,把明显是参数串、乱码、重复词的剔掉,再交给 AI 分析,这一步偷不得懒。
坑三:拿一个月的数据就下季度结论
长尾查询本身样本就小,单月波动极大。曾经见到某条对话式查询展示量月环比涨了 4 倍就被当成趋势,加码做了一组内容,结果下个月打回原形——那只是某个热点事件带来的一次性脉冲。长尾数据要看至少连续 3 个月的滚动趋势,单点高峰先存疑、不动手。这跟前面正文讲的“季频复盘”是一个意思:挖到信号只是第一步,确认它稳定可复现才值得投入内容资源。把这三个坑记牢,这套零成本的 Prompt 挖掘法才真能帮你做对决策,而不是制造一堆看着热闹的假洞察。
常见问题解答
Q1:我的 GSC 数据里看不到 10+ 词的查询怎么办?
三种可能:站点流量太小(每天 < 100 次曝光)、内容主题太垂直没人提问、用了 noindex 没被 AI 引用。先把 Regex 阈值降到 7+ 词,再看看;如果还没有,说明你站点暂时不在 AI 系统的引用范围内,先做内容权威性建设比追踪更重要。
Q2:中文站怎么用这套方法?空格断词不适用。
中文站用 ^.{30,}$ 这种纯字符长度的 Regex,30 字符是经验阈值。或者用"混合 30 字 + 关键句式"组合:^(?=.{30,}).*(如何|对比|推荐|哪个|最好).*$。命中精度比单纯字符数高 2-3 倍。
Q3:GSC Regex 过滤后展示量和点击数会少很多,是不是数据被压缩了?
不是压缩,是真实情况——长尾查询本来就只占总查询的 5-15%。但每条长尾查询的"价值密度"远高于短查询:转化率、品牌相关度、商业意图都更明显。
Q4:能不能用 Looker Studio 自动化每周生成长尾查询报告?
可以。GSC 数据接到 Looker Studio 后,加一个 Regex 过滤的 calculated field,每周自动更新一份长尾查询 dashboard。我自己的设置是:每周一上午 9 点自动邮件推送上周新增的长尾查询给运营团队。
Q5:Profound 和 Peec AI 选哪个?
看预算和深度需求。Profound 功能更全,支持 10+ LLM、有 Prompt 量级数据,适合需要深度报告的企业。Peec AI 起步价更低、支持无限国家,适合中小团队和多市场覆盖。预算紧选 Peec,需要专业报告选 Profound。如果只关注 Citation Source(被引用的内容来源),Goodie AI 性价比最高。
Q6:长尾查询里突然出现了竞争对手品牌名,是好事还是坏事?
是机会。这说明用户在用 AI 搜索"我品牌 vs 竞品"或者"竞品的替代品",而你被引用了。立即做的事:写一篇深度对比内容,明确指出你和竞品的差异化定位,让 AI 下次引用时拿到更结构化的信息。
Q7:含问号 ? 的 Regex 在 GSC 里报错怎么办?
问号在 Regex 里是元字符(零或一次匹配),需要转义。用 \? 或者用字符集 [??](同时匹配半角全角问号)。GSC 的 Regex 引擎用的是 RE2 语法,跟标准 PCRE 略有差异,部分高级特性(如 lookbehind)不支持。
Q8:每月做这个分析要 1-2 小时,能再快一点吗?
能。三种加速方式:用 Looker Studio 自动化导出;用 ChatGPT Code Interpreter 一次性跑完五大问题;订阅 Profound/Peec 让它自动按月出报告。但完全自动化的代价是丢失"专家眼"——人工浏览查询列表时会突然发现的"咦这个查询不对劲",机器很难捕捉到。
Q9:这套方法能用来挖竞品的 AI Prompt 数据吗?
不能。GSC 是站点私有数据,只能看自己的。挖竞品 AI 可见度的方法是:用 Profound/Otterly 输入你自己的核心 Prompt 列表,看 AI 答案里引用的是哪几个品牌——这是"反向"看竞品在 AI 搜索里的份额。
Q10:GSC Regex 数据 + AI 分析得到的 Prompt 追踪列表,怎么转化为内容策略?
三步走:一是把追踪列表里最常见的 5-10 个 Prompt 主题挑出来作为 pillar 内容选题;二是每个 pillar 下覆盖 3-5 个具体子问题(即 Q&A 段落 / FAQPage);三是把这些内容用 Schema.org QAPage / FAQPage 结构化标记,让 LLM 更容易引用。这套流程跑 3 个月,AI 引用率通常能涨 30-50%。
小结
在 AI 搜索时代,"应该追踪哪些 Prompt"这个问题不应该靠猜。GSC 中隐藏的长尾对话式查询数据,是目前我们能获取的最接近真实用户 AI 搜索行为的免费数据源之一。
核心观点是:与其凭感觉选择追踪 Prompt,不如用实际的数据源来指导你的追踪策略。这行 Regex 可能不完美,这些数据可能不是 100% 来自 AI 系统,但它比"我们最好的猜测"要强得多。一行 Regex ^(?:\S+\s+){9,}\S+$ → 打开 AI 搜索行为的窗口 → 用 AI 分析发现商业洞察 → 建立有数据支撑的 Prompt 追踪体系。这是 2026 年每个 SEO 和 GEO 从业者都应该掌握的技能。
在一个零点击、低归因的搜索环境中,能用的数据不多。这个数据摆在那里,用不用,取决于你。
权威参考资料
本文标题:《GSC正则挖AI搜索Prompt:5步实战追踪指南》
本文链接:https://zhangwenbao.com/gsc-regex-mine-ai-search-prompts-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0

GSC这个正则表达式已经足够强大了,短期可以不用考虑付费,一般公司真不需要额外每个月花几百美金去挖这些查询词。不过话又说回来,要获得如此多的AI查询词数据,网站本身的品牌知名度和SEO基础要足够强。
说到点上了!GSC自带的正则确实够用,免费的东西不用白不用,付费工具更适合那些数据量大、需要批量监控的团队。你提的第二点特别重要——这其实是很多人容易忽略的"幸存者偏差",方法再好,没有足够的AI搜索曝光量,GSC里根本就没多少数据可挖。所以归根结底,还是得先把内容和品牌基本功打扎实,工具只是锦上添花。感谢补充,这个提醒对读者很有价值!