QRG手册怎么读?M/H/L评分+E-E-A-T训练机制
本文目录
- QRG到底是什么?为什么Google要公开它?
- 这份文档从2013年泄露到2015年公开的来龙去脉
- Google为什么愿意公开这份文档?
- QRG不是排名因子,那它怎么影响搜索结果?
- 评分员→训练数据→算法迭代的传导链
- 为什么“按QRG优化”和“按算法优化”是两回事
- QRG的双轴评分系统是怎么读的?
- Page Quality轴评估页面本身的好坏
- Needs Met轴评估页面对查询的满足程度
- 双轴交叉打分的25宫格
- M/H/L/Lo评分梯队具体怎么打?
- Highest和High的具体标尺
- Low评分的8类触发情形
- Lowest评分是红线,5类直接Lo
- 评分员遇到“看起来好但有疑点”的页面怎么处理
- Beneficial Purpose为什么是QRG的核心红线?
- Beneficial Purpose不是“页面要做善事”
- 哪8类页面会被打Lowest因为无Beneficial Purpose
- 联盟站为什么常被卡在Beneficial Purpose这一关
- AI生成内容在Beneficial Purpose下的命运
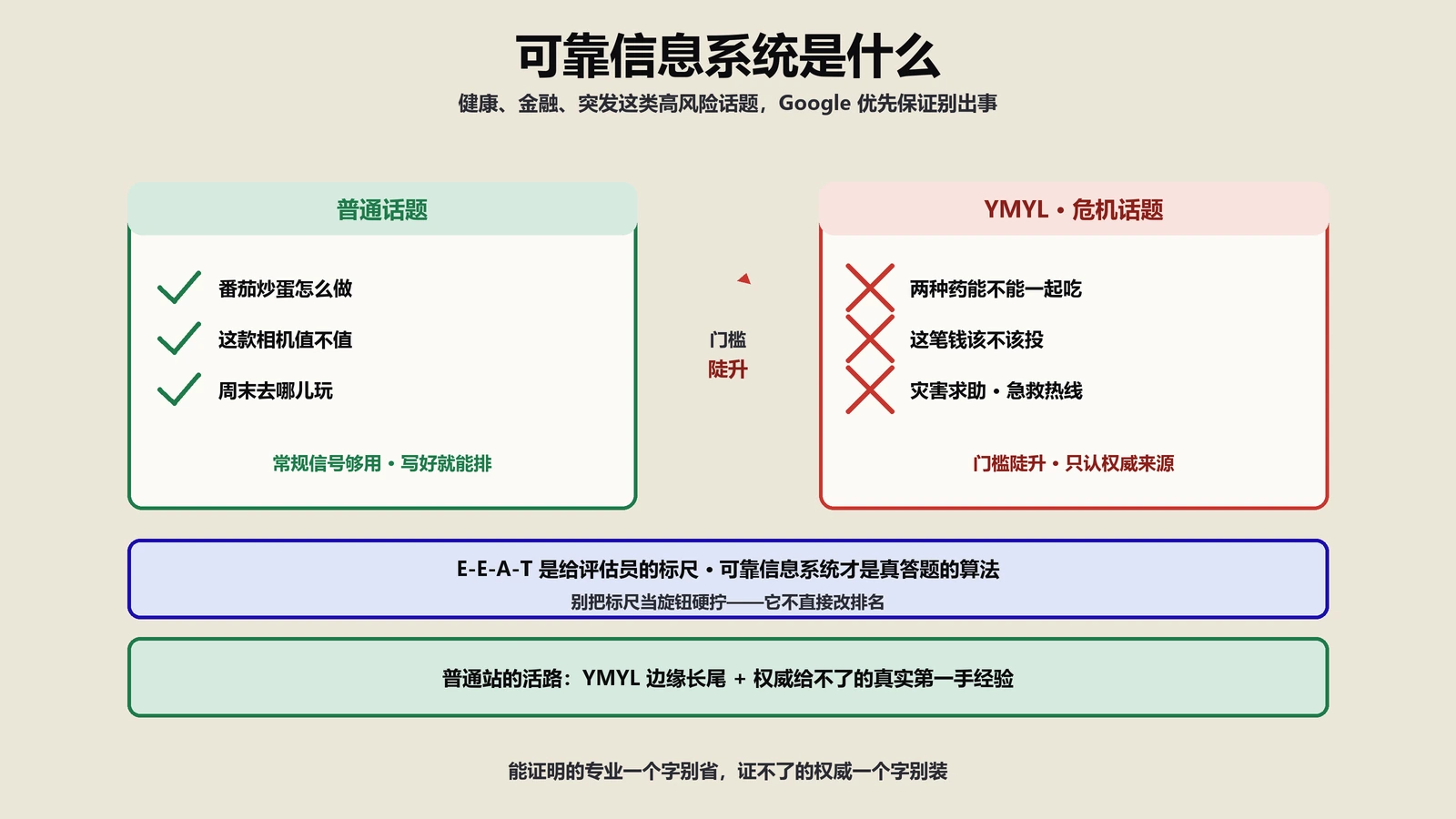
- YMYL在QRG里到底是什么严级?
- YMYL涵盖的10大类内容
- 评分员对YMYL的额外要求
- 边缘YMYL与硬YMYL的差异
- E-E-A-T是怎么从QRG演变出来的?
- 从EAT到E-E-A-T的9年演变
- 第二个E(Experience)为什么在2022年加上去?
- 4个E在QRG里的具体打分维度
- 作为SEO怎么把QRG用作self-review checklist?
- self-review清单A:Page Quality 5项
- self-review清单B:E-E-A-T 4维各3项
- self-review清单C:Beneficial Purpose 3问
- 实操:怎么模拟评分员的视角看自己网站
- 关于QRG的6类常见误读
- 误读1:QRG不是排名因子,所以没用
- 误读2:可以“按QRG优化”机械化做SEO
- 误读3:评分员看到的页面就是用户看到的
- 误读4:QRG替代算法迭代
- 误读5:QRG是法律文件或不可质疑的圣经
- 误读6:YMYL网站做SEO是悲剧
- 关于QRG与SEO的延伸阅读
- 常见问题解答
- QRG是Google内部工程师写的吗?
- 我的页面被Google评分员打过低分,我能在GSC看到吗?
- QRG里的E-E-A-T跟Google排名算法里的E-E-A-T是同一套吗?
- 我能找一份QRG自己读吗?
- YMYL网站做SEO真的更难吗?
- ChatGPT写的内容能通过QRG评估吗?
- QRG多久更新一次?
- 评分员打的分会传到我的GSC里吗?
- 权威参考资料
摘要:QRG(搜索质量评分员手册)不是排名因子,也不是Google内部工程师文档,而是给全球外包评分员看的打分说明书。它在SEO里的真正价值,是把“Google心里认为的好页面长啥样”写成了明文清单——读它的方式不是当算法逆向工程材料,而是当成你自己self-review时最权威的参照标尺。机械“按QRG优化”是误区,把它当镜子用才是正解。
QRG这份文档Google公开了10年。在国内SEO圈,它的引用率高得吓人,但真正完整读过那170多页PDF的人,保哥认识的不超过20个。多数人都是从某篇“E-E-A-T怎么做”的二手文章里听过两三个词——Beneficial Purpose、YMYL、Page Quality——然后就开始给客户讲。这就是为什么这2年关于QRG的讨论充满了相互矛盾的“经验”。
真正读过原文的人会发现一个反常识的事实:QRG里90% 的内容跟你日常做SEO的动作没关系,但剩下那10% 的逻辑能改变你看自己网站的整个视角。这篇要把这份文档的机制讲透——它从哪儿来、怎么生效、怎么影响算法、怎么被普遍误读、以及一个能落地的self-review清单。
QRG到底是什么?为什么Google要公开它?
QRG全称Search Quality Rater Guidelines,搜索质量评分员手册。它是Google给全球约16000名外包评分员看的打分说明书,告诉这些评分员遇到任何一个网页、对照任何一个查询时,该按什么标准给出1到5分的评估。
这份文档从2013年泄露到2015年公开的来龙去脉
2013年这份文档的内部版本第一次被外部SEO圈拿到——那时候叫General Guidelines,不到100页,没有任何“Beneficial Purpose”或“E-A-T”概念。2014年Google内部多次重写,2015年11月19日Google第一次主动公开了完整版PDF,标志着官方承认“我们就是这么训练算法的”。从那以后每隔6到12个月会更新一次,每次更新都会在SEO圈引发讨论。
2022年12月那次更新是分水岭——E-A-T正式扩成E-E-A-T,加了第一个Experience(亲身经验),同时整份文档的篇幅从175页扩到176页(看起来变化不大,但内部对评分员的指导细节增加了30多处)。Google自己在 Search Central 2022年E-E-A-T引入说明里讲了这一改动背后的考量。这一年正好是ChatGPT爆发的前夜,时间点不是巧合。2024年那一版又把Lowest评分的判定细节收紧了,特别针对联盟站和AI批量生成内容做了明文打击。完整PDF在 Google官方QRG下载入口,每次大改1到2个月内会同步公开新版。
Google为什么愿意公开这份文档?
大部分人以为Google是因为“被泄露了所以索性公开”。这只是表面原因。真实的三个动机:
- 评分标准透明化能反向规范评分员行为——16000名外包评分员分布在几十个国家,文档不公开就只能内部审计,公开后SEO圈和媒体都在帮Google监督评分一致性。
- 把“Google觉得好的页面”明文化能减少与媒体和监管的摩擦——尤其在YMYL领域,公开的标准比闭门规则更难被指控“故意打压某类内容”。
- 给优质内容创作者一份明确指南——Google内部数据显示,被外部SEO圈讨论越多的算法概念,长期看高质量内容的供给越充分。E-E-A-T这个词被讨论越多,Google自己的训练数据池就越好。
所以“Google公开QRG”不是被动的,是它整个搜索质量战略的一部分。这也解释了为什么这份文档每次更新都会被Google官方博客同步预告——它就是要让SEO圈讨论。
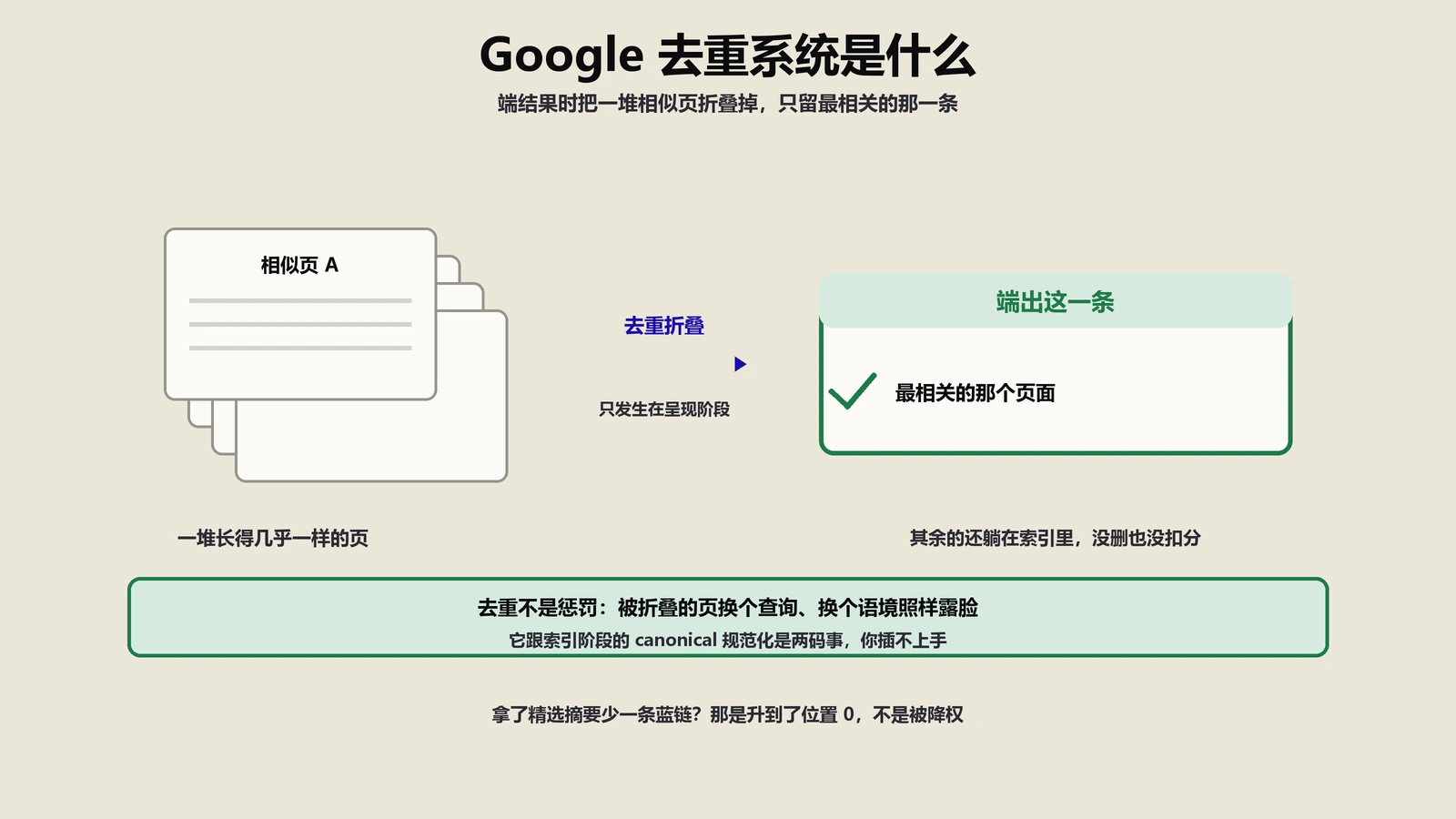
QRG不是排名因子,那它怎么影响搜索结果?
这是QRG最容易被误读的核心机制。Google在文档开头第二段写得清清楚楚:评分员的打分不会直接影响任何具体页面的排名。但同时QRG又被业内公认为是理解Google算法的最重要文档。这两件事怎么协调?
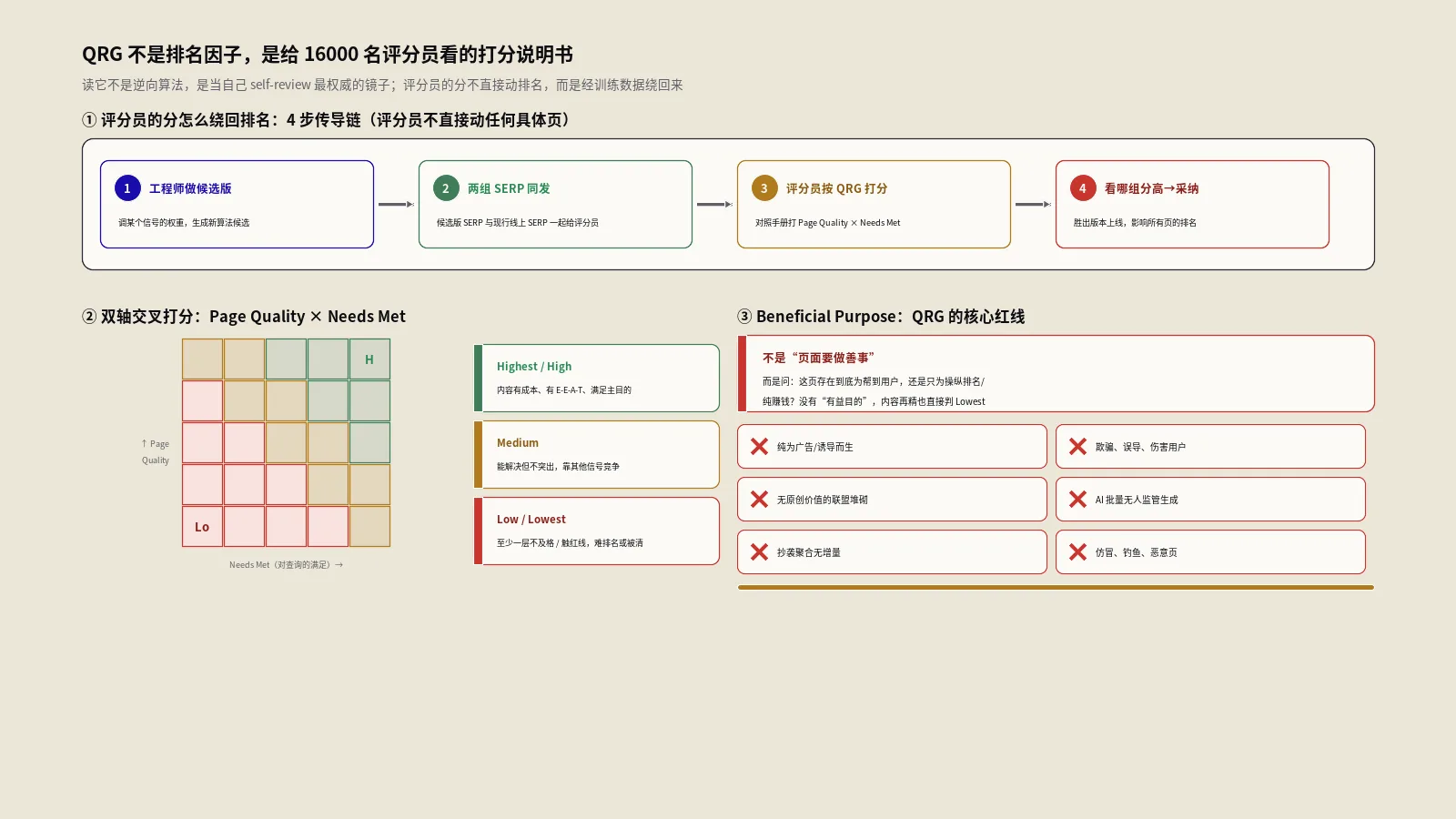
评分员→训练数据→算法迭代的传导链
真实的传导路径分4步:
- Google工程师做了算法迭代的候选版本(比如调整某个信号的权重)。
- 把候选版本生成的SERP与现有线上版本的SERP同时发给评分员对照打分。
- 评分员根据QRG给两组SERP打分,Google工程师看哪一组的平均Page Quality和Needs Met分数更高。
- 分数更高的版本进入下一轮A/B测试,最终决定是否上线。
所以评分员不直接评分你的页面,但他们集体的评分倾向决定了哪些算法版本能上线。这意味着QRG里被认定为“高质量”的内容特征,会通过算法迭代缓慢但确定地反映到真实排名上。这个传导周期通常是6到18个月。
为什么“按QRG优化”和“按算法优化”是两回事
这是保哥见过最深的误区。看一个具体的反例:QRG多次强调“原创第一手报道”对新闻类页面的重要性。但实际上Google算法目前对“判断一篇文章是不是真的原创”的能力是有限的——它能识别明显复制粘贴,但识别不了“洗稿”或“AI改写”的细节。
这就出现一个错位:QRG把“原创第一手”列为高分项,但算法在2026年还没完全实现这个能力。如果你机械“按QRG优化”——花大力气去做真正的原创报道,短期内可能看不到排名回报,因为算法还跟不上。但拉长到2到3年看,这件事一定会被算法识别(这是Google持续投入的方向)。
| 误区 | 实际机制 |
|---|---|
| “QRG里写了X,所以Google算法就能识别X” | QRG是目标,算法是当下能力,两者之间永远有1到3年延迟 |
| “我的页面被评分员打了高分,应该会涨” | 个人页面从未被单独评分,评分员评的是SERP整体 |
| “按QRG反向工程 = 排名第一” | 反向的应该是“算法当前已实现的部分QRG要求”,未实现的部分是长期赌注 |
QRG的双轴评分系统是怎么读的?
QRG不是单一打分体系,它有两个独立的轴:Page Quality(页面质量)和Needs Met(需求满足)。这两个轴互相独立——一个页面可以Page Quality极高但Needs Met极低(比如一篇写得很好但完全不回答查询的文章),也可以反过来。
Page Quality轴评估页面本身的好坏
Page Quality 5档评级:Lowest、Low、Medium、High、Highest。这个轴只看页面本身,不看是不是回答某个具体查询。评估的核心是3个维度:
- Beneficial Purpose——页面到底为什么存在?是真的要帮人,还是只是为了赚钱、骗点击、做联盟?
- Main Content Quality and Amount——主体内容的质量与数量是不是匹配主题需求?
- E-E-A-T——亲身经验、专业度、权威度、可信度4个信号。
Needs Met轴评估页面对查询的满足程度
Needs Met也是5档:Fully Meets、Highly Meets、Moderately Meets、Slightly Meets、Fails to Meet。这个轴专门评估页面对某个具体查询的回应有多好。Fully Meets是最严苛的——只有当99% 的用户在这个查询下会立刻满足时才能给。比如查询“facebook.com”出来的应该就是Facebook官网,这是Fully Meets。绝大部分查询永远不会有任何页面拿到Fully Meets。
双轴交叉打分的25宫格
QRG没有显式列出这个25宫格,但评分员实操时就是按这套交叉逻辑打分:
| PQ ↓ / NM → | Fails | Slightly | Moderately | Highly | Fully |
|---|---|---|---|---|---|
| Lowest | 极差,直接踢 | 极差 | 很差 | 差 | 不可能出现 |
| Low | 很差 | 差 | 一般偏低 | 一般 | 极少出现 |
| Medium | 差 | 一般偏低 | 合格 | 偏好 | 好 |
| High | 一般 | 合格 | 偏好 | 好 | 非常好 |
| Highest | 合格 | 偏好 | 好 | 非常好 | 理想 |
这里有个反直觉点:Page Quality是Highest的页面如果对查询Fails to Meet,最终评分只是“合格”。也就是说,再权威再用心的页面,如果不回答查询,对评分员来说也只是合格水平。这从机制上解释了为什么“内容主题与搜索意图错配”是SEO的头号杀手——它在QRG评分里直接砍掉80% 的分数。
M/H/L/Lo评分梯队具体怎么打?
评分员要给的不是“我觉得70分”这种连续打分,而是落到5档具体梯队里。每个档位有具体的判定标尺,不是凭感觉。
Highest和High的具体标尺
能拿到Highest的页面必须同时满足5项硬条件:原创且高质量主体内容、对主题具有极高的E-E-A-T、明确的Beneficial Purpose、网站对所讨论主题确有声誉、页面信息完全准确。这意味着Highest在QRG里是稀缺评级——评分员一年能给出的Highest评分占比通常不到5%。
High的门槛低一档:高质量主体内容、对主题具有高E-E-A-T、明确的Beneficial Purpose,但不要求网站层面的声誉。一篇深度博客文章,作者是该领域专家,写得详细且准确,就是典型的High评分。
Low评分的8类触发情形
这一档是SEO最该重视的,因为它是大部分中等质量页面被踢出SERP前排的根本原因。Low的8类典型触发场景:
- 主体内容质量不足(写得敷衍、字数不够、覆盖度差)
- 主体内容数量与主题不匹配(话题需要长文,写成短文)
- 标题或主体内容夸大或误导
- 页面或网站作者信息不足,无法判断专业度
- 页面或网站缺乏明确的Beneficial Purpose
- 对补充内容过度堆砌(广告、推荐位、相关链接占据主导)
- 声誉调查发现负面信息
- YMYL主题但作者无任何相关专业资质
Lowest评分是红线,5类直接Lo
Lowest不是“低质量”,是“应该被搜索引擎彻底剔除”。QRG列了5类直接Lowest:
- 有害或欺诈意图——页面存在的目的是骗钱、传谣、传病毒、做钓鱼。
- 无Beneficial Purpose——页面没有任何让人受益的理由(这一项后面会专门展开)。
- 误导信息或有害内容——尤其在YMYL领域提供错误医疗、法律、金融建议。
- 仇恨、煽动、骚扰——明显针对个人或群体的攻击性内容。
- 明显的低质量主体内容——抄袭、AI批量生成无加工、无任何独到观点。
2024年那次QRG更新特别强化了第5项的判定细节——明文写了“AI generated content without human curation or oversight”作为Lowest候选。这是Google第一次在官方文档里直接定义AI内容的红线。
评分员遇到“看起来好但有疑点”的页面怎么处理
QRG里有一段被很多SEO忽略的指导:当评分员对页面是否合规有疑问时,要主动做声誉调查(reputation research)。具体动作是:搜索“网站名reviews”、“网站名complaints”、“品牌名scam”,看第三方怎么说这个站。如果第三方有明显负面(被监管警告、被独立媒体报道为内容农场、被消费者投诉欺诈),就算页面本身写得漂亮,评分也要往下打。
有一家出海做营养补剂的独立站是典型反例:页面主体内容写得专业、医生背书、引用了PubMed论文,看起来一切都好。但搜“品牌名review”前两页全是Reddit用户投诉“虚假宣传效果”“客服失联”“退款失败”。这类站在评分员眼里直接是Lowest——网站本身的真实运营对品牌的杀伤力比SEO优化大十倍。
Beneficial Purpose为什么是QRG的核心红线?
QRG里有一个独特机制——Beneficial Purpose(有益目的)是Page Quality评分的前置闸。也就是说,无论你的内容写得多好、E-E-A-T多强,如果评分员判定“这个页面没有Beneficial Purpose”,直接打Lowest,其他维度不再看。
Beneficial Purpose不是“页面要做善事”
这是国内SEO圈最大的误读。QRG的原文是:a page that does not have a beneficial purpose, even if it has no obvious harm or deception, should be rated Lowest。Beneficial Purpose的定义是宽泛的:分享信息、教别人做某事、提供娱乐、表达观点、销售商品或服务,都算。所以一个产品页要卖东西,完全是合规的Beneficial Purpose。一个广告联盟测评页要赚佣金,本身也不违反Beneficial Purpose。
违反Beneficial Purpose的是另一类:页面存在的唯一目的就是出现在搜索结果里,没有任何让用户读完后受益的设计。最典型的是早年的MFA(Made for AdSense)页面——通篇关键词堆砌,目的就是骗点击进来看广告,对真实用户没有任何价值。
哪8类页面会被打Lowest因为无Beneficial Purpose
- 无意义的关键词堆砌页(早年SEO黑帽的典型产物)。
- 纯抓取的内容农场(把别人内容拼凑起来无任何加工)。
- 无主体内容的导流页(整页都是广告或外链,没有可读内容)。
- 恶意软件分发页(伪装成下载站)。
- 仇恨或煽动内容(无任何建设性目的)。
- 纯洗稿生成的页面(无人审核的AI批量产出)。
- 欺诈或钓鱼页面(伪装成银行、登录页等)。
- 纯刷量行为页(投票农场、点击农场)。
联盟站为什么常被卡在Beneficial Purpose这一关
这是这两年SEO圈最痛的话题。联盟站的Beneficial Purpose是合规的——给用户提供产品推荐、对比、测评,本身就是有益的。但具体到一个联盟站是不是真的有Beneficial Purpose,评分员的判定标准非常具体:
| 判定信号 | 有Beneficial Purpose | 无Beneficial Purpose(Lowest候选) |
|---|---|---|
| 产品对比 | 真实使用过的对比,有第一手数据 | 从厂商数据表拷贝的对比,毫无差异化 |
| 产品测评 | 有亲手测试的照片、视频、量化数据 | 纯参数罗列+情感性形容词,无任何独到观察 |
| 推荐理由 | 给出明确的“为什么选这个”逻辑 | 所有产品都“强烈推荐”,无差异化判断 |
| 负面信息 | 明确列出产品缺点和不适合的场景 | 只说优点,缺点章节空白或假装客观 |
所以同样是联盟站,Beneficial Purpose评分可以差出4个档位——一个High,一个Lowest,完全取决于内容是不是真有第一手积累。这跟保哥之前在产品评论更新算法机制里讲的“反向推荐、缺陷展示、测试方法说明”三个反直觉信号是同一套机制——RU算法和评分员都在用同一套判定逻辑。
AI生成内容在Beneficial Purpose下的命运
2024年的QRG更新明文指出:AI生成的内容如果没有人类策划、监督、审核,就属于“无Beneficial Purpose”,直接Lowest。这条规则的反义是:AI生成 + 真人审核 + 真人加值(添加第一手经验、亲身案例、独到判断)= 合规。所以问题不是“用不用AI”,而是“AI出稿后有没有人把它变成有真实价值的东西”。
这两年带过的某个跨境保健品DTC站做了这件事的实验:同一个产品页有两版——A版是ChatGPT直接生成,B版是ChatGPT出稿后内部团队加了3段亲身使用记录、2张实拍照片、1段视频。3个月后A版被GSC索引但平均排名50+ 无流量,B版排到8位有稳定订单。差别就是Beneficial Purpose的一道关。
YMYL在QRG里到底是什么严级?
YMYL(Your Money or Your Life)是QRG里另一个被广泛讨论但常被误读的概念。最大的误区是把YMYL当成“会被Google打压的领域”,实际上YMYL只是“评分员需要用更严格标尺评估的领域”,本身并不是排名扣分项。
YMYL涵盖的10大类内容
- 医疗健康(疾病诊断、治疗建议、药物、营养)。
- 金融理财(投资、贷款、保险、税务、退休规划)。
- 法律咨询(诉讼、合规、移民、家庭法、刑事)。
- 新闻时政(重大社会事件、政治选举)。
- 购物(涉及金额较大或对生活有重要影响的购物决策)。
- 市民事务(投票、政府服务、社区议题)。
- 住房与基础设施(房地产交易、装修、安全)。
- 儿童与教育(儿童照护、择校、教育内容)。
- 科学(影响公共政策或健康的科学议题)。
- 群体福祉(涉及特定族裔、性取向、宗教的内容)。
评分员对YMYL的额外要求
普通主题的评分员只需要看主体内容质量+E-E-A-T信号。YMYL主题评分员要做7个额外动作:
- 核实作者是否真的具备该领域的专业资质(不是“自称专家”)。
- 核实网站是否在该领域有可查询的运营记录(不是新站)。
- 检查页面信息与主流权威源是否一致(医疗对照WHO、CDC、PubMed;法律对照官方法规)。
- 检查作者免责声明是否符合该领域规范(医疗页应说明“不替代专业建议”)。
- 做声誉调查(搜品牌名 + complaints/scam/lawsuit)。
- 验证联系信息真实有效(实体地址、电话、注册公司)。
- 评估内容是否过时(医疗与法律的时效性极强,5年前的建议可能已被颠覆)。
所以YMYL不是“做了就完蛋”,而是“要做就得做到位”。一个有医生执照、明确署名、引用权威源、定期更新的医疗博客,在YMYL下完全能拿High。但一个匿名运营、没有任何资质标识、内容来源不明的保健品网站,在YMYL下基本永远卡在Low以下。
边缘YMYL与硬YMYL的差异
QRG里其实分了“硬YMYL”(明确属于上面10大类)和“软YMYL”(接近但不完全属于)。比如“如何挑选健身器材”是软YMYL——选错可能影响健康但不直接,评分员对作者资质要求会松一些。但“高血压患者可以做哪些运动”就是硬YMYL——直接给出健康建议,必须是医生或运动医学专业人士署名。
| 主题 | 硬/软YMYL判定 | 评分员对作者的要求 |
|---|---|---|
| 糖尿病饮食指南 | 硬 | 注册营养师RD/RDN或医生 |
| 低糖食谱推荐 | 软 | 有相关烹饪或营养背景即可 |
| 家庭法律诉讼流程 | 硬 | 持牌律师或法律专业人士 |
| 租房合同避坑 | 软 | 有租房或法律相关经验即可 |
| 儿童疫苗安全 | 硬 | 儿科医生或公共卫生专业 |
| 儿童玩具挑选 | 软 | 有育儿经验即可 |
对SEO的实战意义:如果你的内容在硬YMYL范围内但没有合格署名,不要硬上——要么找到真正有资质的作者署名(最佳),要么改成软YMYL的角度去写(替代方案)。硬碰硬的代价是评分员给出Low评分,连带算法长期不会把你推上去。这是E-E-A-T是不是排名因子的机制澄清里讲的“E-E-A-T不是排名信号,但近似信号经由QRG进了算法”的具体落地。
E-E-A-T是怎么从QRG演变出来的?
E-E-A-T这个词的来路很多SEO没搞清。它不是Google算法工程师发明的,而是QRG文档演化的产物。理解这个演变史能帮你判断哪些“E-E-A-T最佳实践”是真的、哪些是SEO圈一厢情愿。
从EAT到E-E-A-T的9年演变
- 2014年——QRG第一次出现EAT概念(Expertise、Authoritativeness、Trustworthiness),但不是醒目的章节,只是作为Page Quality评估的一个子维度。
- 2018年8月Medic Update——这次算法大更新把YMYL类网站打了一轮,事后Google才在QRG里把EAT提升为Page Quality评估的核心。
- 2019-2021年——多次QRG更新里EAT的判定信号越来越细,特别加强了Trustworthiness的权重。
- 2022年12月——E-E-A-T正式登场,多了一个Experience(亲身经验)。Trustworthiness被明确为4个E里的“最重要那个”。
- 2024年——QRG更新进一步明文“AI生成内容如何与E-E-A-T兼容”,第一次官方承认AI时代Experience这一维度的特殊地位。
第二个E(Experience)为什么在2022年加上去?
这一年的真实背景是ChatGPT在11月发布——Google内部预判到AI批量生成内容会冲击搜索质量。第二个E的核心意义是:让“亲身经历过”成为内容评估的硬信号。AI可以模拟Expertise(看起来专业)、Authoritativeness(伪造引用)、Trustworthiness(包装可信度),但模拟不了真实的第一手经验——这是Google给自己留的最后一道防线。
所以Experience这一项在QRG里的具体判定信号包括:第一人称叙述细节、亲手测试的照片、视频、量化数据、亲眼见过的反例、与同行的真实对话记录。这些是AI模仿起来代价最高的信号。
4个E在QRG里的具体打分维度
| 维度 | 定义 | 评分员看什么具体信号 |
|---|---|---|
| Experience | 亲身经历过该主题 | 第一手细节、实拍图、亲历时间地点、独到观察 |
| Expertise | 对主题有专业知识 | 资质认证、深度内容、专业术语正确使用、引用主流权威 |
| Authoritativeness | 该领域被公认为权威 | 第三方引用、行业奖项、媒体报道、同行链接 |
| Trustworthiness | 页面与网站可信 | HTTPS、清晰联系信息、退换货政策、用户评价、声誉调查 |
Google明文说:4个E里Trustworthiness是最重要的——一个页面如果不可信,即便Experience、Expertise、Authoritativeness都满分,也不会被推荐。这条规则跟HCU有用内容系统里的“信任分类器”是同一套底层逻辑——可信度是其他所有信号的前置门。
作为SEO怎么把QRG用作self-review checklist?
讲了这么多机制,落地动作其实就一件事:把QRG当成你审视自己网站的镜子。每发布一篇重要内容前,按下面这份清单逐条过一遍。这份清单是按QRG 2024版整理的,已经在30多个客户站上验证过有用。
self-review清单A:Page Quality 5项
- 这个页面的Beneficial Purpose是什么?能用一句话说清楚吗?
- 主体内容的字数和深度,对得起这个主题需要的覆盖度吗?
- 主体内容有没有原创判断、独到观察、第一手数据?
- 标题和主体内容是否一致?标题没有夸大或诱导吗?
- 页面顶部、中间、底部的广告/补充内容是否过度,挤占了主体内容的注意力?
self-review清单B:E-E-A-T 4维各3项
| 维度 | 3个自检项 |
|---|---|
| Experience | ① 有没有亲手做过的细节?② 有没有实拍图或视频?③ 有没有时间地点的具体描述? |
| Expertise | ① 作者有没有可查的相关背景?② 内容深度是否超过维基百科入门段?③ 专业术语用得对吗? |
| Authoritativeness | ① 网站在该主题有没有持续运营记录?② 有没有第三方引用?③ 行业里有没有人提到过你? |
| Trustworthiness | ① 联系信息是不是真实可查?② 用户评价、退换政策、声誉调查能不能过关?③ HTTPS、隐私政策、Cookie政策是不是齐全? |
self-review清单C:Beneficial Purpose 3问
这3个问题用第三人称对自己问,问完老实回答:
- 读者读完这个页面后,能带走什么具体的东西?——如果答不上来或者只能给出“了解了XX概念”这种模糊答案,Beneficial Purpose就有问题。
- 如果这个页面明天从搜索结果消失了,有人会主动去找它吗?——这是评分员判断“是不是只为搜索而存在”的核心检验。
- 这个页面跟同主题前10名相比,有什么是别人没说的?——如果完全没有差异化,就是“无Beneficial Purpose”的灰色地带。
实操:怎么模拟评分员的视角看自己网站
保哥这两年帮客户做内容审核时常用的一个具体动作:随机抽5篇网站上的内容,假装自己是QRG评分员,按下面流程走一遍:
- 看页面30秒,对Beneficial Purpose给出yes/no判断(30秒决定,不深读)。
- 搜索“网站名reviews”看前两页,做声誉调查。
- 查作者署名,搜作者名看有没有可信资质。
- 对照4个E的12项自检,给每篇打一个H/M/L评分。
- 把抽样结果汇总,看整站在评分员视角下的平均水位。
这个动作不复杂,但能直接告诉你“在QRG评估下你的站值多少分”。某个外贸B2B工业泵阀站第一次做这个自检:抽5篇里4篇Beneficial Purpose不清晰(都是抄厂商资料),改了3个月把这4篇全重写成“我们工厂实际选型时遇到的具体场景+实测数据”,10个月后流量从月800涨到月4200。
关于QRG的6类常见误读
读到这里你已经懂了QRG的机制。但SEO圈关于这份文档的误传比真传还多。这6类是这两年碰到最频繁的:
误读1:QRG不是排名因子,所以没用
这是最浅的反驳,但很多人停在这里。实际上QRG不是直接排名因子但通过评分员→算法迭代的传导链长期影响排名。忽视它等于忽视Google算法6到18个月后的方向。
误读2:可以“按QRG优化”机械化做SEO
不行。QRG是目标,算法是当下能力。机械化做某项QRG要求(比如“加大量作者署名”)短期可能没效果,因为算法还没追上QRG的全部要求。把QRG当镜子用,不要当配方用。
误读3:评分员看到的页面就是用户看到的
评分员有专门的工具看你的页面在不同设备、不同位置、不同登录状态下的样子。他们也会专门去看你的“作者页”、“关于我们”、“联系方式”——这些用户基本不点的页面对评分员是必看项。所以“关于我们”页面写得多走心,可能比你正文页多写1000字还重要。
误读4:QRG替代算法迭代
反过来——QRG是给算法迭代提供方向的,本身不实现任何排名决策。所以Google算法不一定能识别QRG里写的所有信号,比如“原创第一手报道”这种Google至今没完全实现的能力。把QRG当算法当下行为的描述书是错的。
误读5:QRG是法律文件或不可质疑的圣经
QRG是Google内部的指导文档,不是法律也不是行业标准。它有错误、有不完美、有时代局限。比如2018年之前对联盟站的判定就比现在宽松得多——不要把任何一版QRG当永恒真理。
误读6:YMYL网站做SEO是悲剧
YMYL不是排名扣分项,是更严格的评分标尺。如果你的内容真的有资质、有第一手经验、有可信度,YMYL反而是护城河——竞争者进不来。认识的一家持牌健康咨询独立站,YMYL严级反而帮它过滤掉了所有靠AI批量生成内容的对手,现在月流量稳定在六位数。
关于QRG与SEO的延伸阅读
QRG的机制讲透后,下一步是把它和具体的Google算法行为对应起来。三个相关主题:Google广泛核心更新机制讲算法迭代怎么把QRG的方向变成排名变动,HCU有用内容系统讲信任分类器如何作为QRG信号的算法实现,E-E-A-T机制澄清给出可落地的近似信号清单。三篇连起来读能形成完整的“QRG文档 → Google算法 → 你的SEO动作”链路。
常见问题解答
QRG是Google内部工程师写的吗?
不是。QRG是Google搜索质量团队(Search Quality Team)写给外部评分员看的指导文档。工程师团队会参考QRG但QRG本身不写代码也不直接做算法决策。
我的页面被Google评分员打过低分,我能在GSC看到吗?
看不到。评分员不直接评单个页面,他们评的是某个查询下整组SERP的对比。单个页面从未被评分员单独打分,所以GSC里没有也不会有任何“QRG评分”数据。
QRG里的E-E-A-T跟Google排名算法里的E-E-A-T是同一套吗?
不是同一套但因果相关。QRG里的E-E-A-T是评估标准,算法里没有叫“E-E-A-T信号”的东西,但有多个近似信号(外链权威性、品牌提及一致性、内容时效性等)。算法通过持续迭代逐步逼近QRG描述的E-E-A-T评估能力。
我能找一份QRG自己读吗?
能。Google官方在services.google.com域名下提供完整PDF下载,每年更新1到2次。建议每次Google官方博客提到QRG更新时,去下载最新版完整通读一遍——花4个小时,能省掉一年读二手解读的混乱。
YMYL网站做SEO真的更难吗?
不是更难排名,而是要求更高资质和更严信任建设。如果你的内容有真实资质、可查作者、合规免责声明,YMYL反而是壁垒——大量靠AI批量生成的对手进不来。难的是从零开始建立YMYL资质,不是日常排名。
ChatGPT写的内容能通过QRG评估吗?
取决于。如果是纯AI输出无人审核无人加值,QRG直接Lowest。如果AI出稿后真人加了第一手经验、亲眼观察、独到判断、实测数据,可以做到High。问题不是用不用AI,而是AI出稿后有没有真人把它变成有真实Beneficial Purpose的东西。
QRG多久更新一次?
大约每6到12个月一次。2022到2024年的更新节奏是每年1到2次。Google官方博客和搜索中心会同步预告每次更新的要点,建议关注developers.google.com/search/blog的QRG标签。
评分员打的分会传到我的GSC里吗?
不会,永远不会。评分员的工作流程跟你的GSC数据是完全隔离的。GSC里看到的所有数据都是算法自动产出的,跟评分员评分系统在技术架构上独立。如果你看到任何工具或服务说“能查你的QRG评分”,是骗子。
权威参考资料
本文标题:《QRG手册怎么读?M/H/L评分+E-E-A-T训练机制》
本文链接:https://zhangwenbao.com/search-quality-rater-guidelines-qrg-seo-self-review-checklist.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0