结构化数据生成器怎么用?13种Schema类型一键生成JSON-LD
手写JSON-LD嵌套层级一错、必填字段一漏,整段Schema就废了还不报错。结构化数据生成器把13种类型做成填表式,自动按规范嵌套、清洗空字段,输出可直接贴用的代码。

SEO不该凭感觉,得靠数据说话。这里聚焦SEO数据分析与工具,从Search Console、GA4指标体系到排名监测、日志分析和Ahrefs、Semrush用法,教你用数据驱动每一个优化决策。
手写JSON-LD嵌套层级一错、必填字段一漏,整段Schema就废了还不报错。结构化数据生成器把13种类型做成填表式,自动按规范嵌套、清洗空字段,输出可直接贴用的代码。
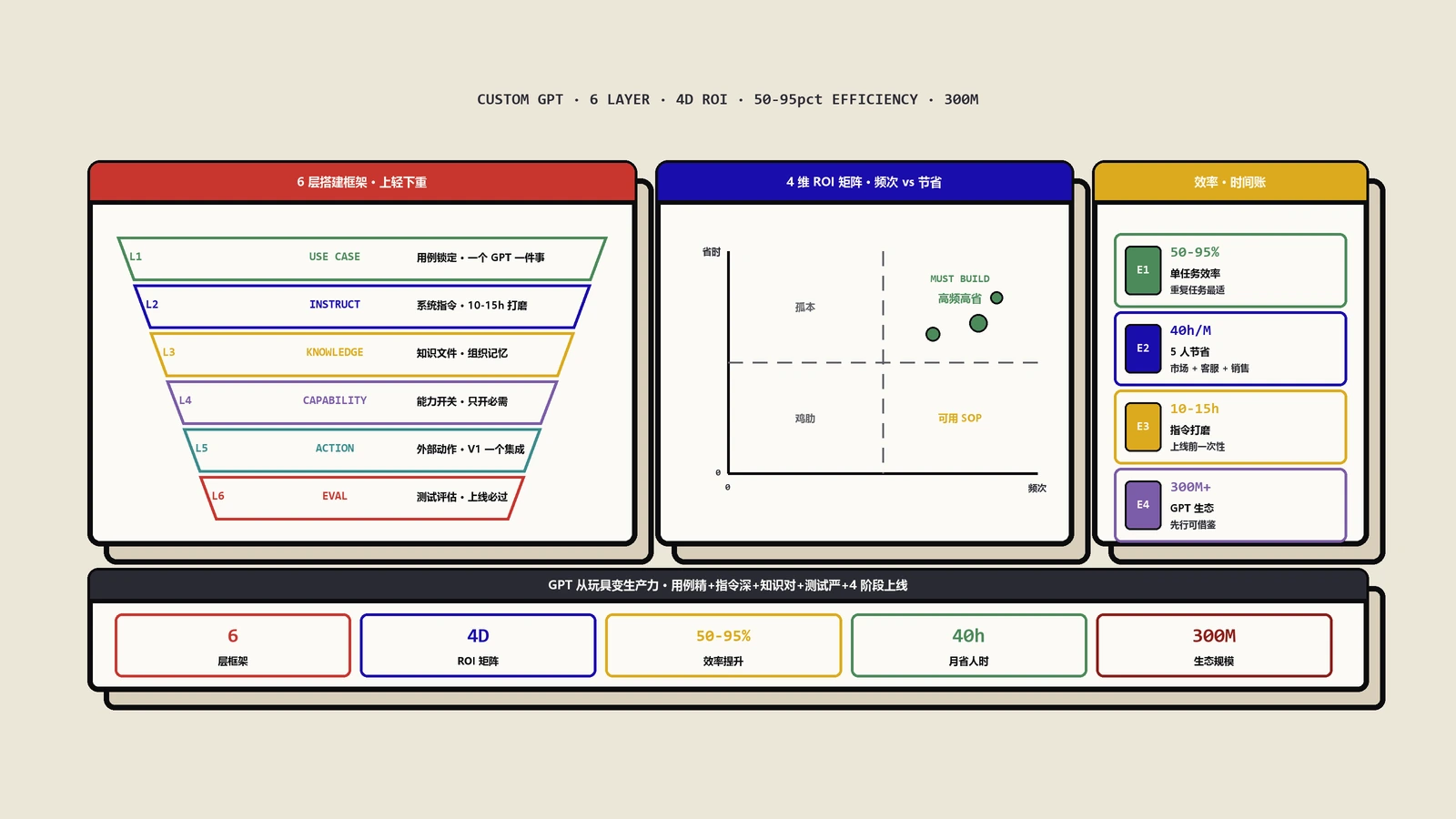
GPT商店上线300万个自定义GPT但绝大多数搭完就吃灰。本文用四维ROI评分矩阵帮你验证用例值不值得做,给出用例锁定、系统指令、知识文件、能力开关、外部动作、测试评估六层搭建框架的完整SOP,覆盖营销、SEO、销售、客服、运营各部门的高ROI场景,并提供幻觉防控、四阶段上线推广与度量体系的可操作方案。
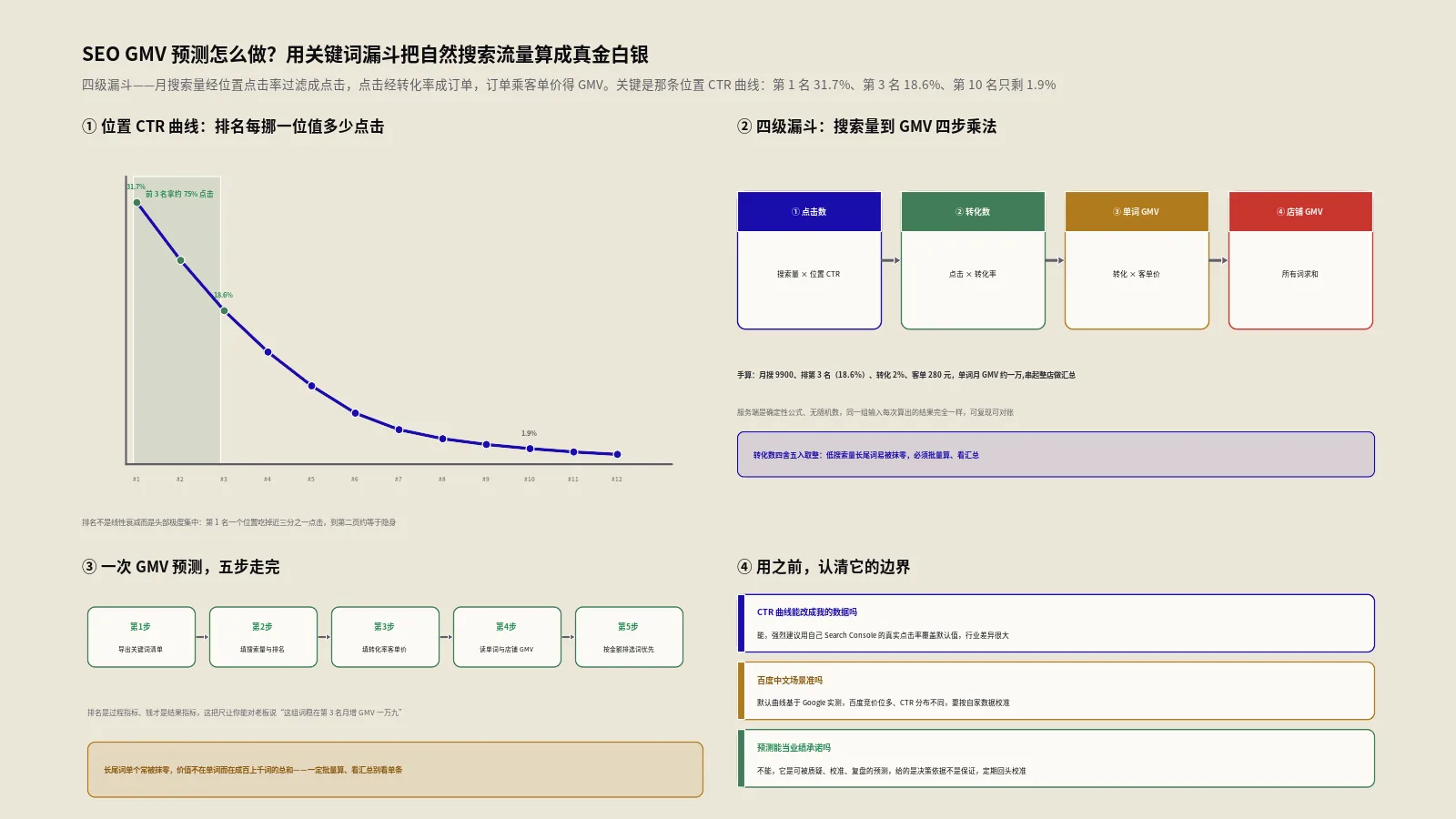
做了三个月把词推上首页,老板只问多挣了多少你却答不上来?这款工具把关键词清单逐个算成预期销售额再汇总成店铺业绩预测,让SEO报告从排名截图升级成一张能申请预算的收入表。
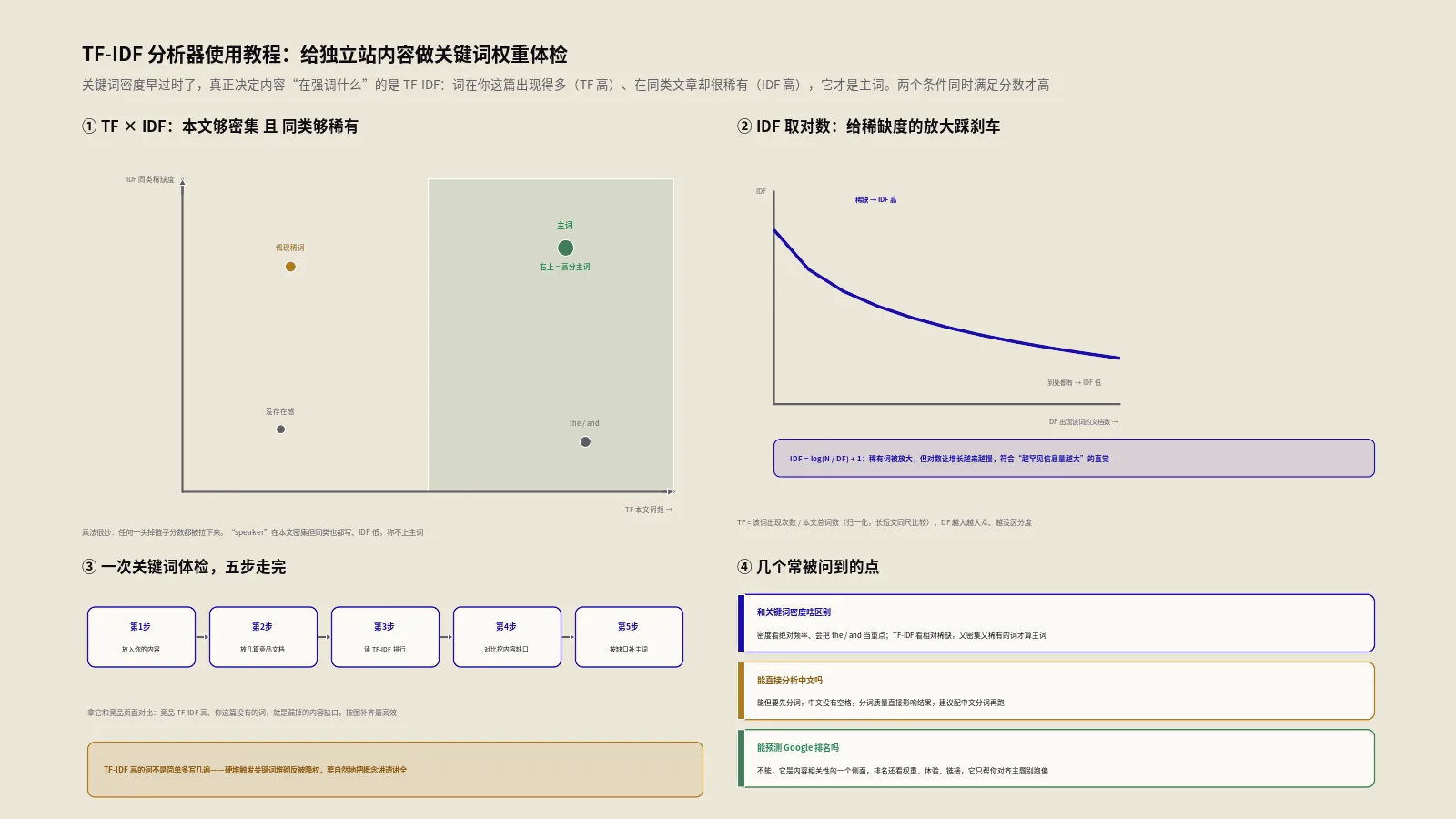
产品页关键词写了一堆,排名却上不去?多半是重点没压对。本文讲清楚为什么该用TF-IDF代替关键词密度,以及怎么借助免费在线工具,把自己的内容塞进竞品堆里横向对标,找出主词偏移和内容缺口。
三平台站长后台的告警体系到底该看哪几类、哪几类纯属噪声、哪几类必须当晚停手处置?保哥这一行陪外贸团队修过几十次手动操作罚单、链接异常通知、Core Web Vitals红灯,把GSC、Bing Webmaster、百度站长后台的告警谱系拉成一张对照表,加上8类告警分级SOP、自动化监控Webhook搭建、14天复议恢复完整时间线,写成一份能让团队照着抄的实战手册。

一个在Google几乎没流量的网站,却在Copilot里被引用超过3.6万次——把背后的147个grounding query拉出来,141个在Bing有排名,Google一个都没排。这组反差说明两件事:Bing排名和Copilot引用关系极紧,而且我们终于能看见AI是用哪几个词找到一篇内容的。Microsoft Clarity现在能显示Copilot引用时用的grounding query,AI检索这个黑盒裂开了一条缝。这篇把它当机制…

保哥拆SEO实验与CRO四大根本差异+5类核心实验场景判断+单因素隔离5陷阱+MDE公式与样本量计算+URL/KW/流量段三种分桶粒度+60-90天反馈周期工程方案+CUPED分层抽样+季节性算法波动外部信号三层扣除+SearchPilot与自建选型。

出海儿童积木玩具DTC团队2025年9月把SEO工具栈推倒重来,全员开始用AI做关键词、改页面、做外链。3个月之后保哥做季度复盘时看到的数据是:自然流量从月1.8万涨到4.6万(2.6倍)、AI Overviews引用月520次、SEO团队人均产出页面数从月12页提到月48页。这种增量不是单靠AI工具就能拿到的,背后是9大场景里每一个都把人和AI的分工切对了。

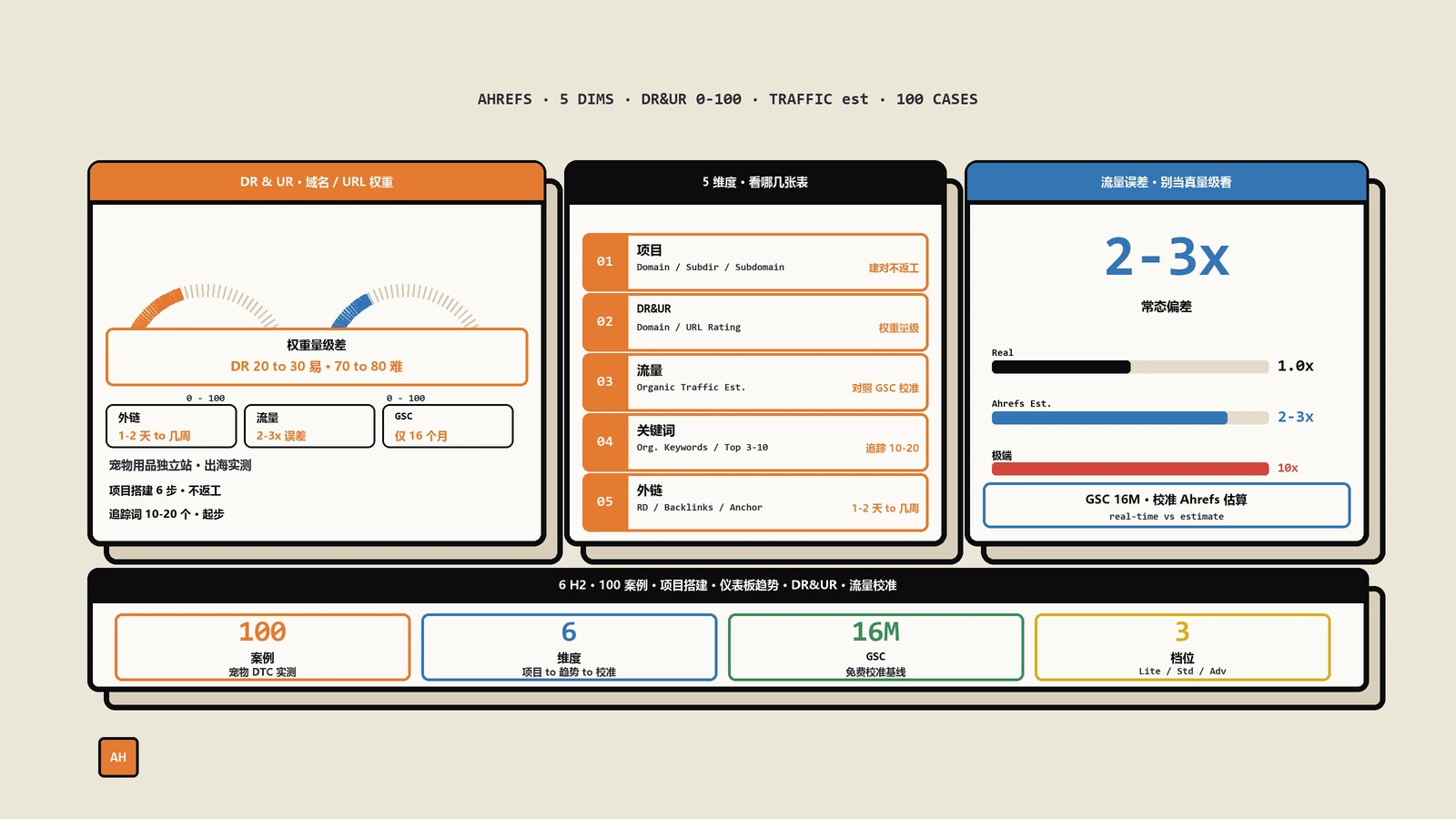
Ahrefs劝退新手的从来不是功能,是看不懂的英文缩写和一堆估算数字。本文讲清项目怎么建、已验证和未验证差在哪、DR与UR的计算逻辑和误差边界、哪些数字只能看趋势,并附一个出海宠物用品独立站从零搭Ahrefs的完整动线。
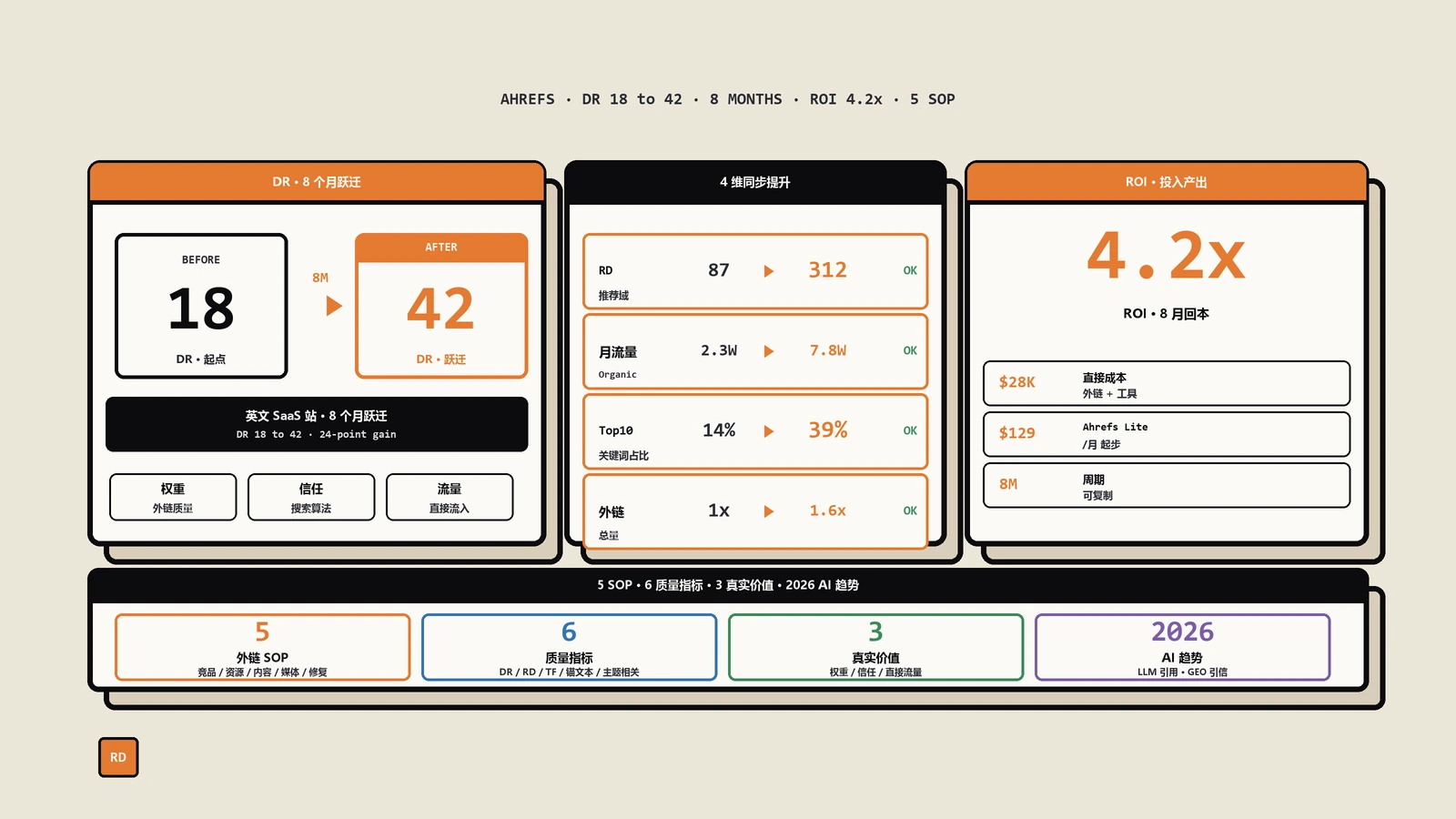
外链在LLM时代不是过时反而更重要。本文用一家SaaS的8个月实操拆解Ahrefs订阅档位选择、5套发现高质量外链的SOP、Link Intersect和Broken Link Building的完整流程、6个质量评估指标、5个常见误区,给出DR18到42、月流量2.3万到7.8万的真实数据复盘。
把ChatGPT当成关键词工具用三个月才发现,AI关键词研究不是输入种子词等返回长尾。保哥这一行带北美桌游卡牌DTC客户跑12周LLM工作流,从意图分解到AI模式选词、从GPT-4o/Claude/Gemini三类大模型分工到6类长尾扩展模式、再到竞品AI反推与缺口分析全跑过一遍,自然流量2.4万跳到6.8万,AI模式引用从0到月720次。这份5步工作流SOP把意图分解模板、铁律清单、失败踩坑都摆出来。

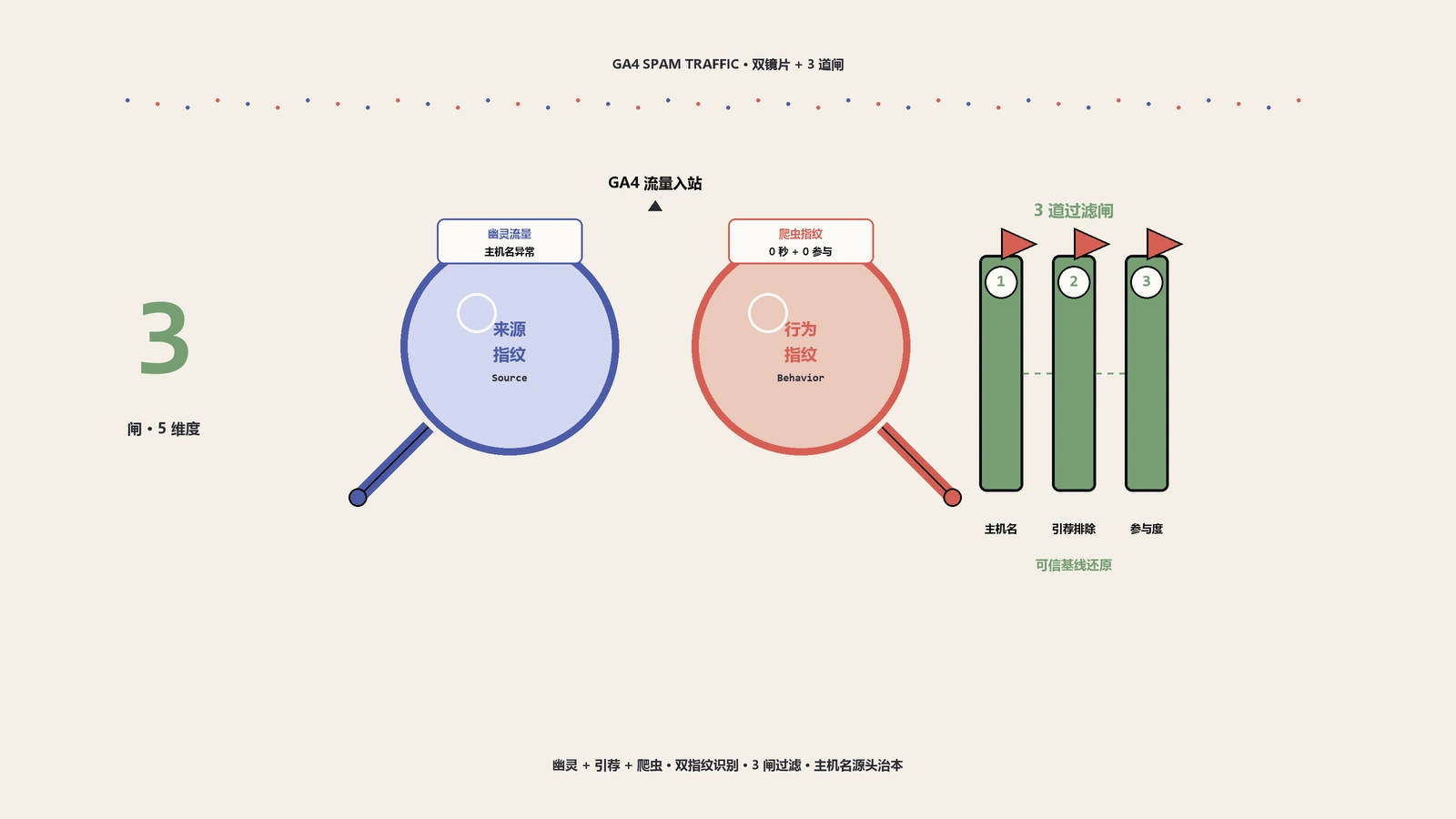
GA4流量一个月涨四成却没多一条线索,多半是垃圾流量在注水。它分幽灵、引荐爬虫、伪自然三类,专挑转化率、归因、跳出率下手,让你照着假数据做决策。讲清三类各自怎么混进来、双指纹怎么一眼认出、三层过滤每层挡什么、污染后怎么重建能信的基线。
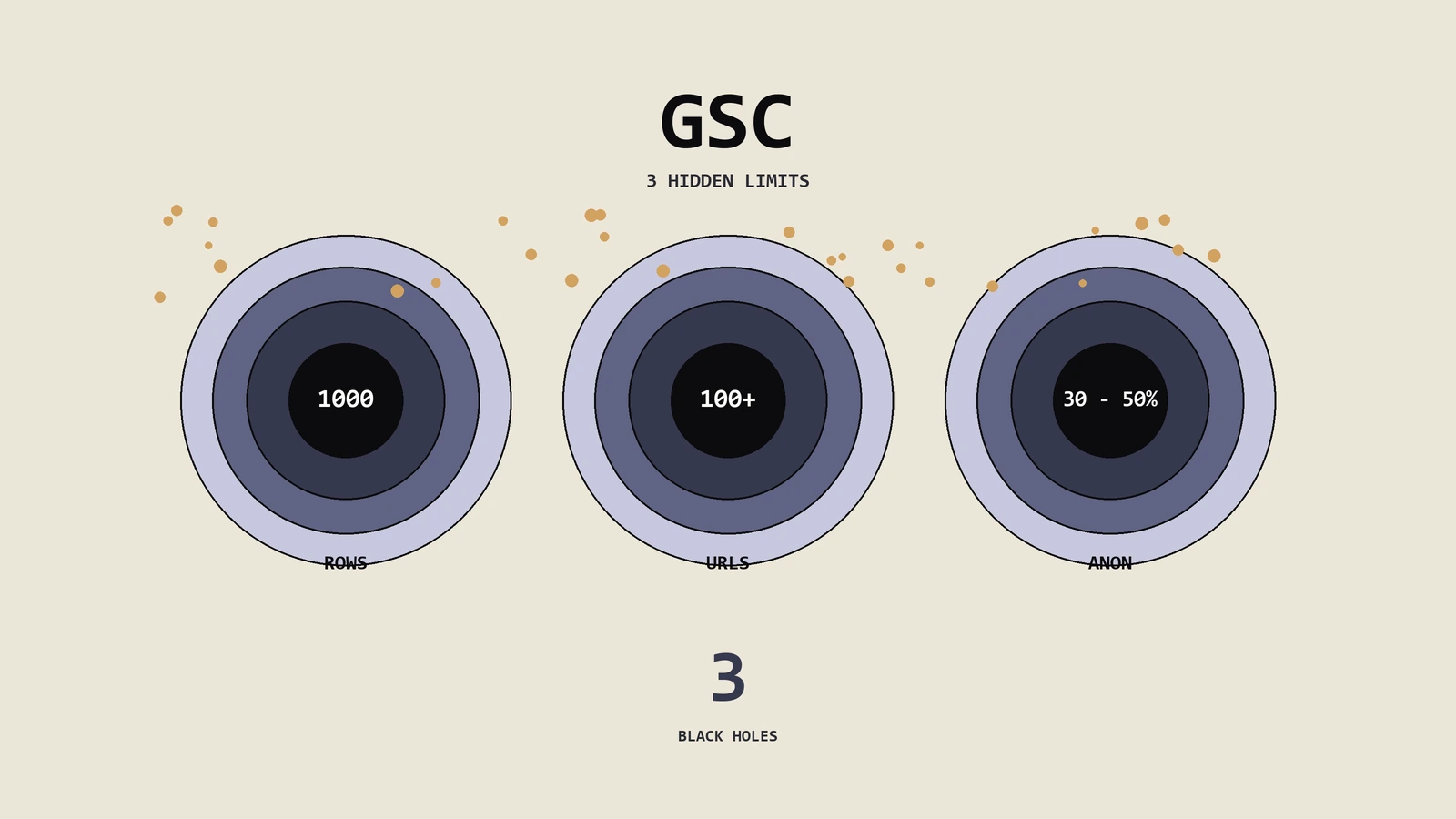
GSC报表里你看到的不是全部真实数据。1000行表格限制砍掉了大部分长尾查询、URL分组把零散流量塞进"其他"桶、阈值过滤把展现量低于隐私阈值的全部隐藏成anonymized查询——三大数据黑洞合起来吞掉的可能比你看到的还多。这篇把每个黑洞的机制讲清楚,给出多维拆分采样法、Search Analytics API工程化抽取、BigQuery大数据导出、三件API套件补洞、再到GA4与服务器日志三源对账的完整工程方案。
搜索量是预估比较值不是绝对真值,五个常见认知错误能把整个策略带偏:以为工具数字就是真实搜索次数、把GKP和Ahrefs数据当同一回事、忽略长尾累积效应、不看季节性单看年均值、新词盲信工具。保哥近三年帮十几个独立站校准搜索量后总结:核心价值是排序与比较不是精确预测。这篇用五维框架拆解数据可靠性,含工具横评、长尾累积估算法、季节性诊断SOP,附出海有机零食独立站搜索量误判复盘。
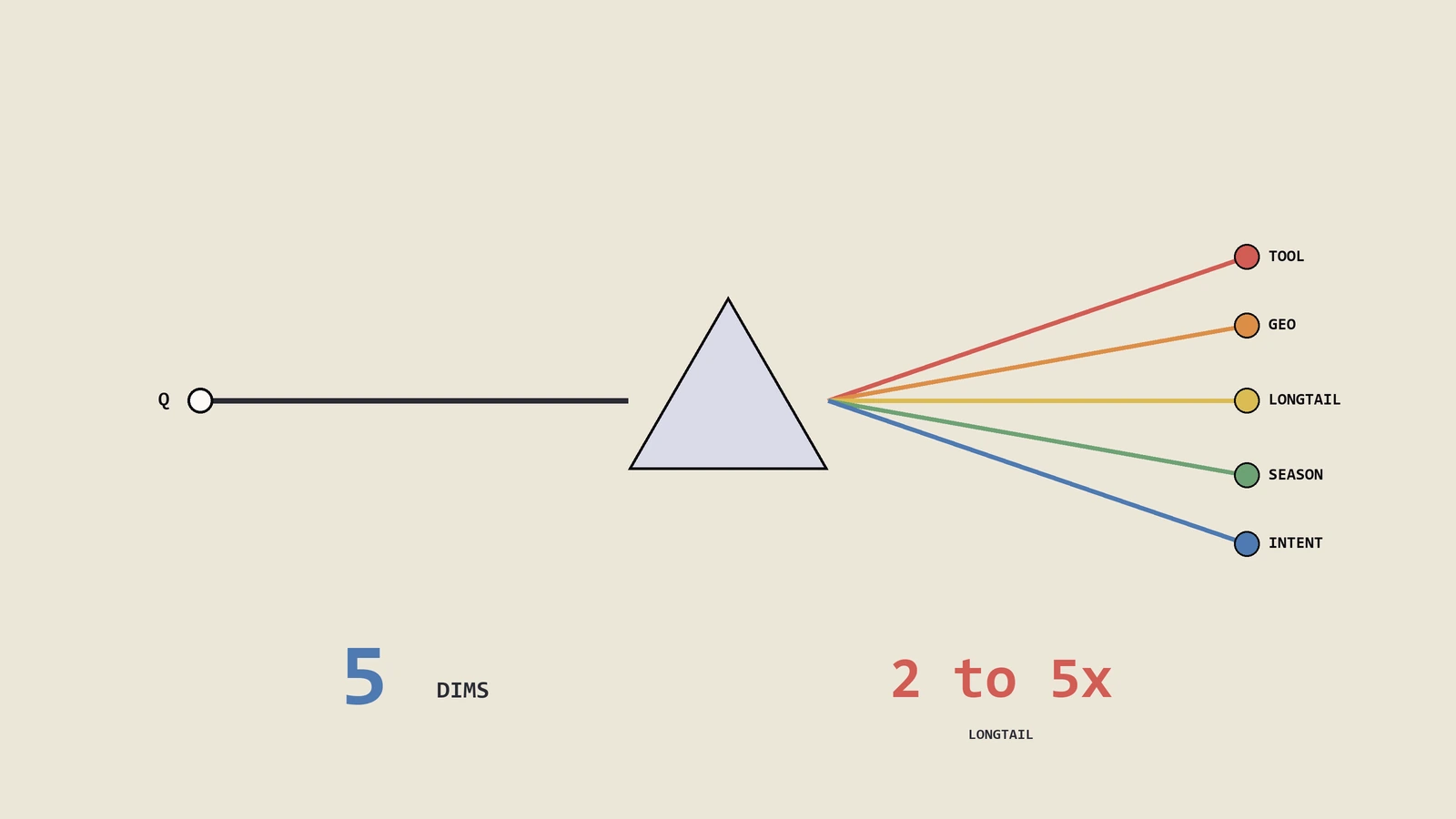
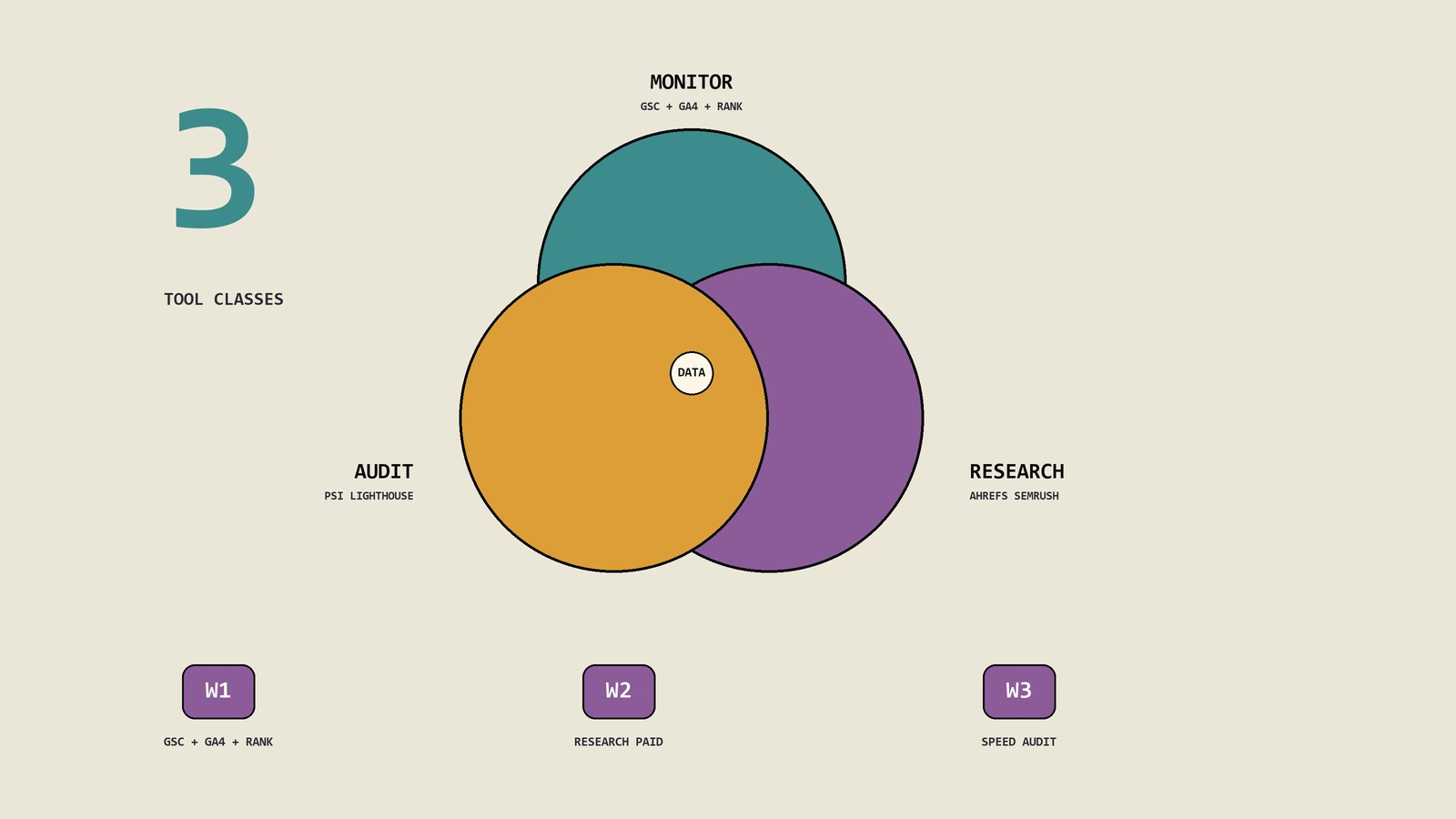
SEO是研究不是广告,数据是穿透Google算法黑盒的唯一拐杖。把SEO工具按成效监控/研究规划/网站健诊三类讲透,给出新手三周入手节奏与排名追踪习惯养成路径。
九成新手把Google Trends那个0到100当搜索量、把分开搜的两张图硬比大小,从根上就错了。本文先划清它和关键词工具的分工,再讲透相对值与抽样的底层机制,逐个拆七个技巧的落地动作,并给出一张选题排期表和一个出海节庆品类倒推排期的实战。

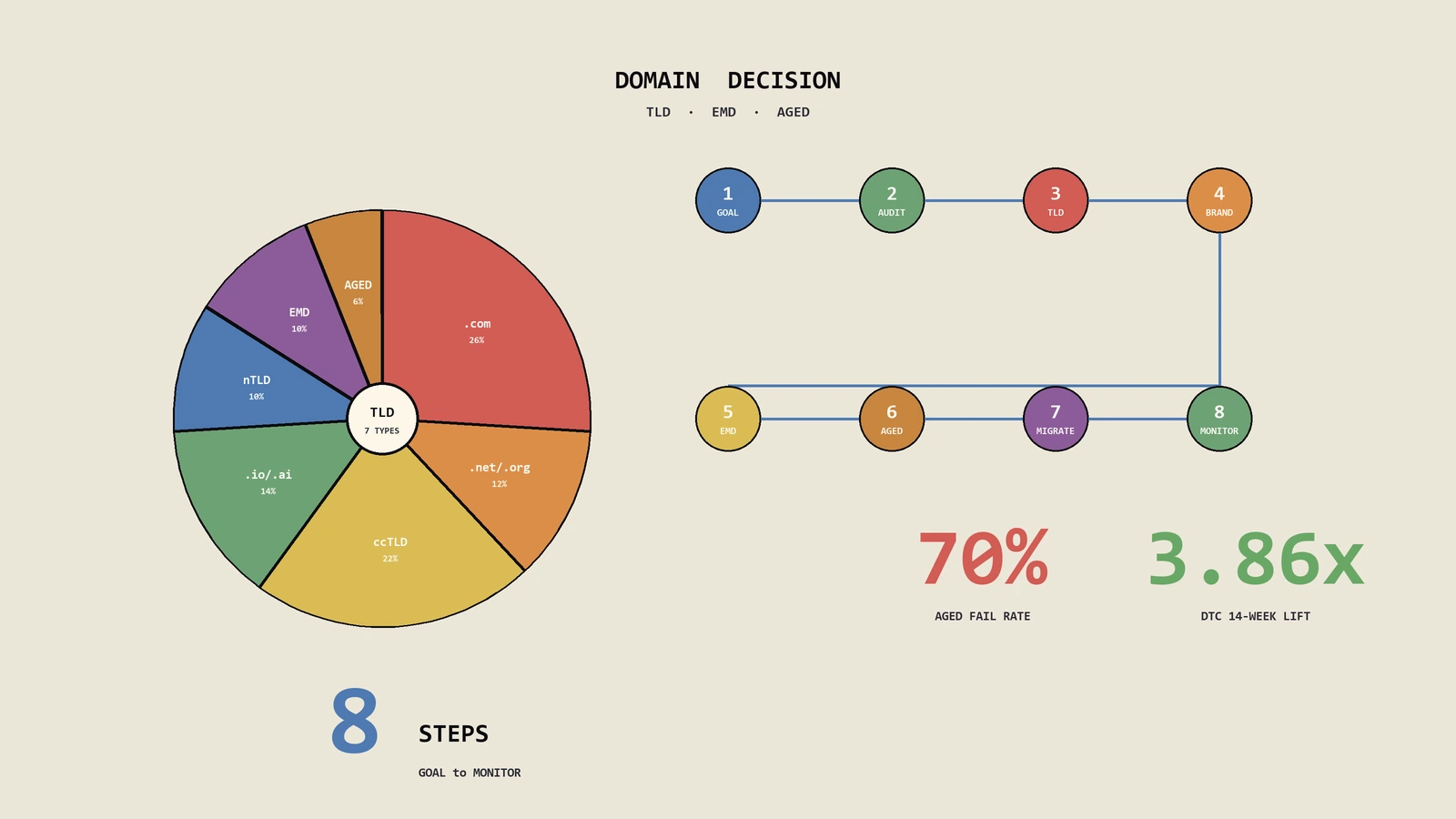
域名选择是SEO决策成本最高的一步——5年后想换品牌等于推倒重来。过去3年帮28家出海独立站做域名选型实操,跑出来一些反常识结论:EMD不再香、老域名70%是坑、多TLD防御性注册过头反而稀释品牌信号。本文把TLD 7类的SEO信号差异、品牌词对EMD的决策路径、老域名收购6维度评估法、新站沙盒期28客户实测数据、Google惩罚域名识别8步审查清单、出海hreflang矩阵下的域名编排、北美宠物用品DTC 5国域名矩阵14周翻4倍真账…
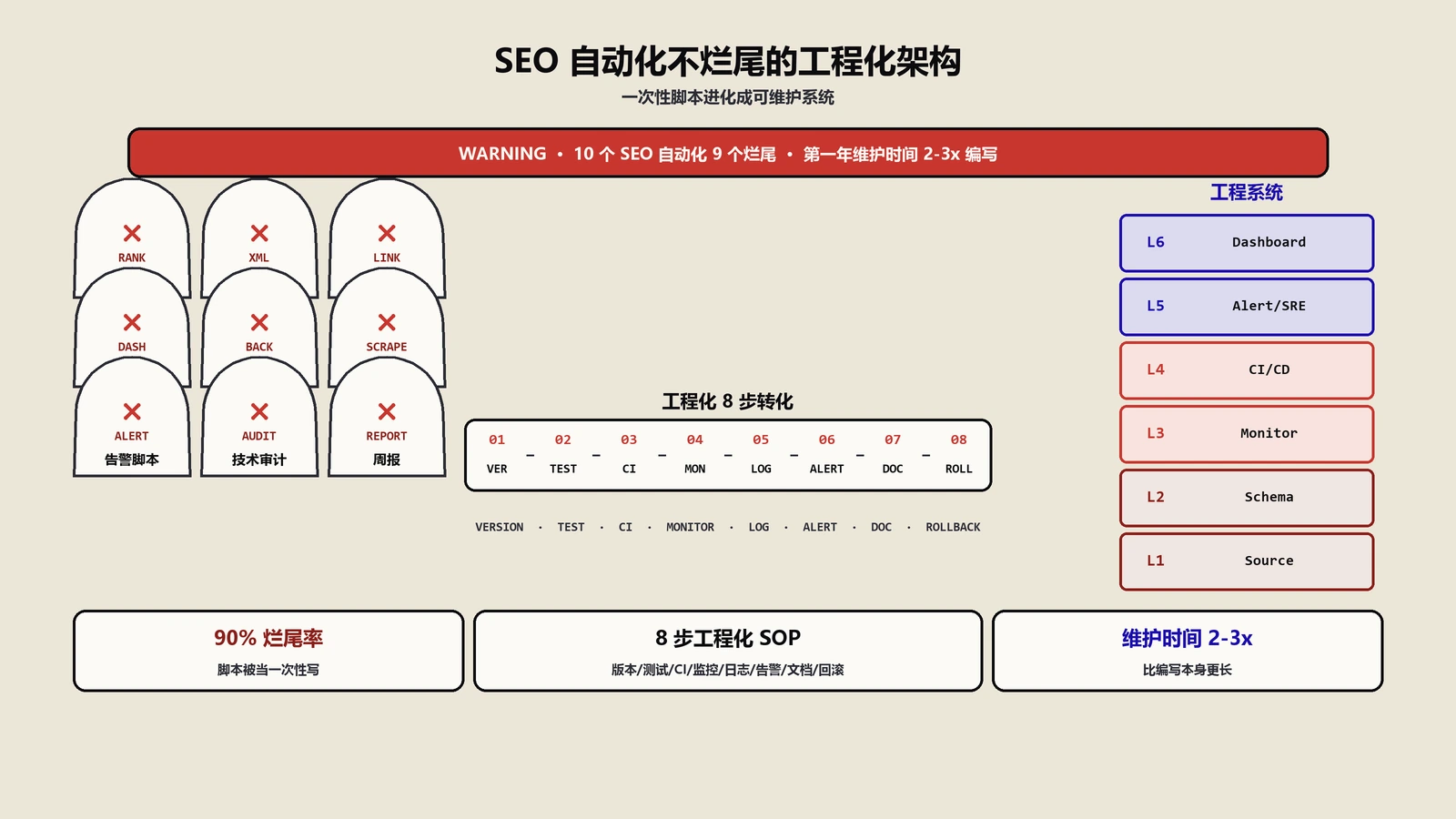
搭好了能跑、三周后静默喂错数据却没人发现——SEO自动化十个烂尾九个,不是脚本不会写,是没当成软件来维护。本文讲透烂尾的真实机制、哪些任务碰都不该碰、能跑三年的系统在架构上和一次性脚本差在哪、排名监控sitemap外链管道仪表盘各自的工程坑,以及AI让这件事是变快还是变脆。
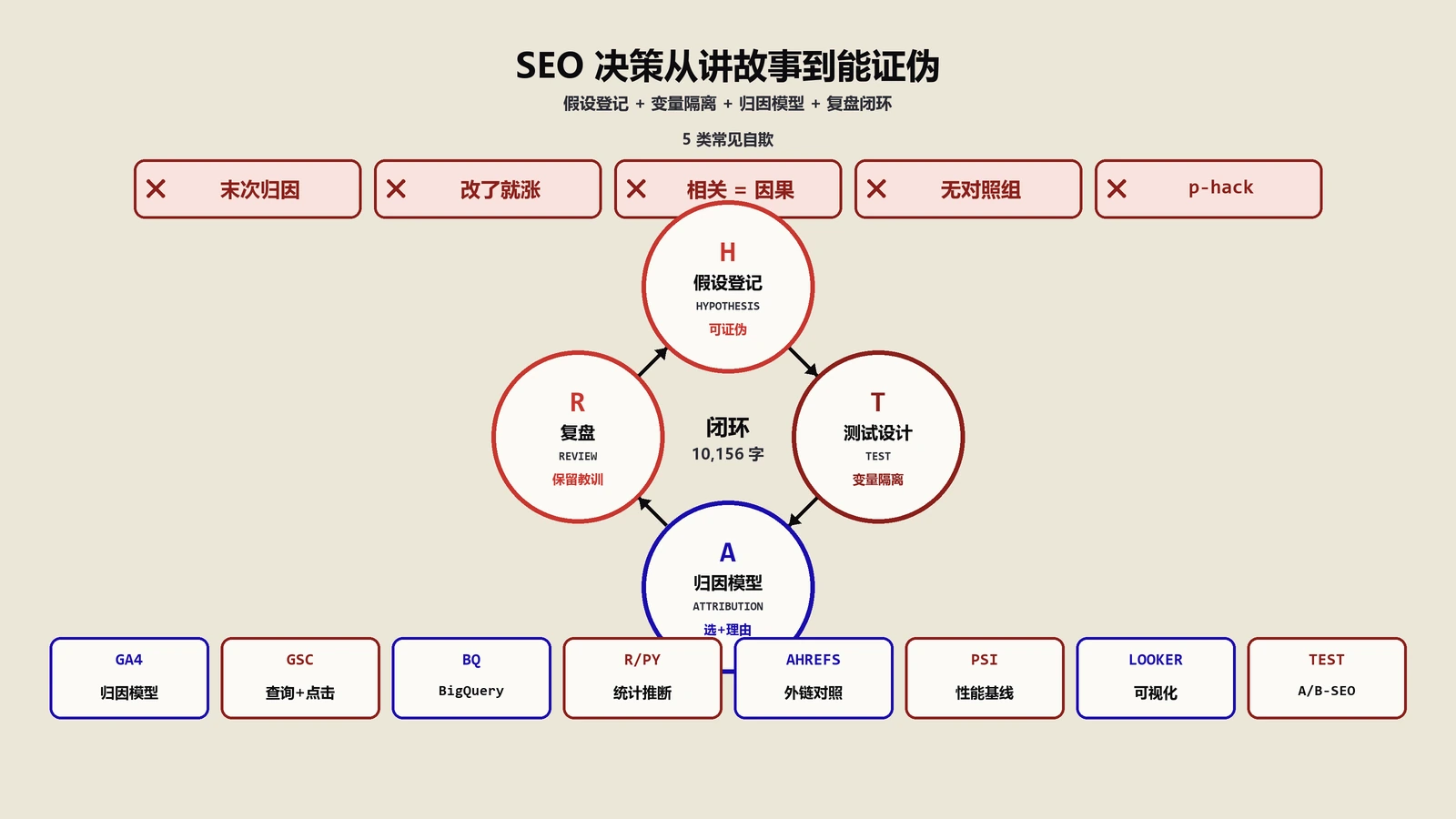
改了标题流量涨两成就说优化有效?这套推理几乎每个字都站不住。本文讲 SEO 决策怎么从拿数据讲故事变成能复盘能下注的方法论:可证伪假设、按问题选归因模型、隔离变量的测试设计、混杂因素扣除、不确定下的决策规则,以及六种伪装成数据驱动的自欺。
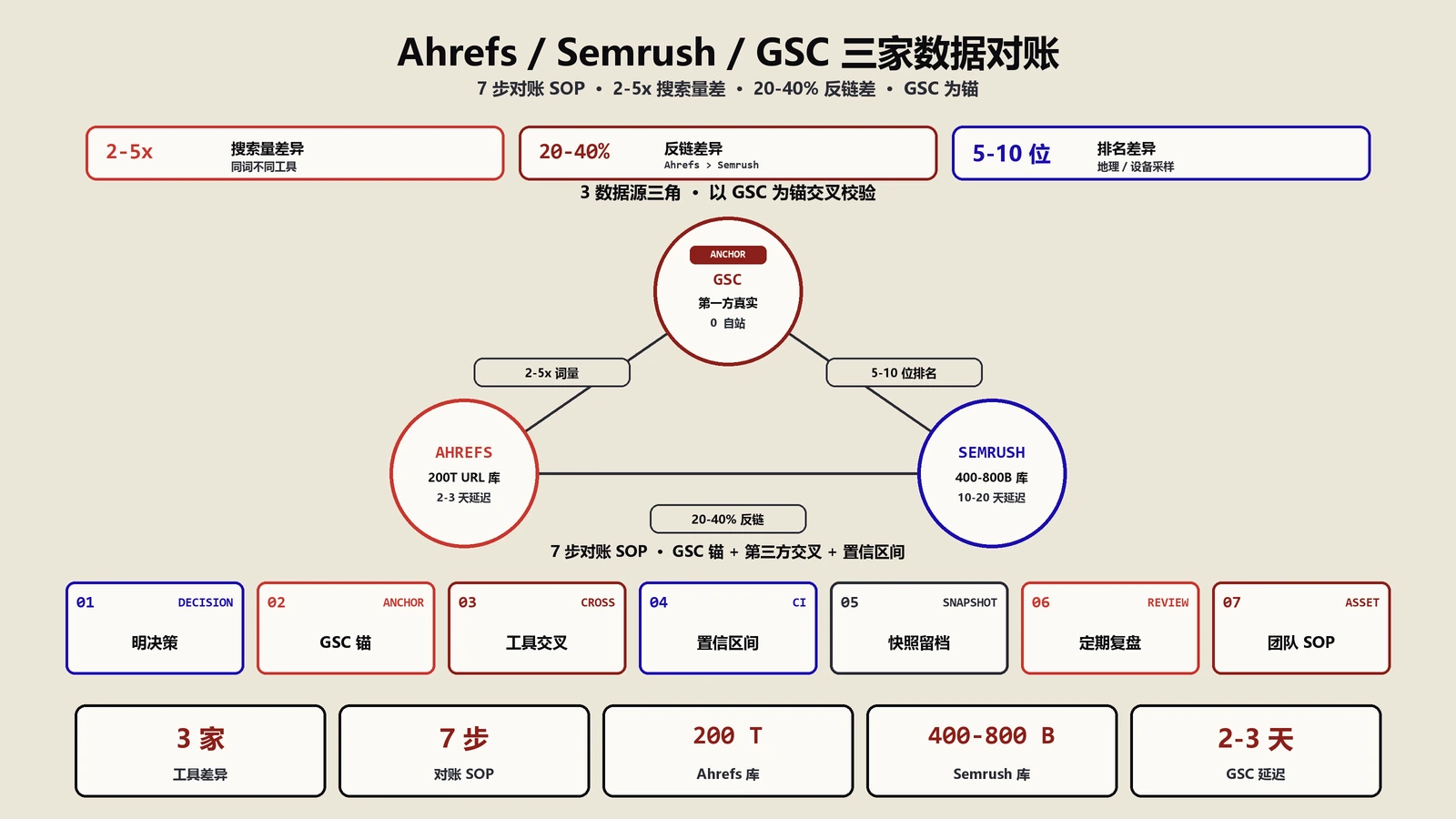
Ahrefs、Semrush、GSC三家SEO工具数据永远对不上是常态不是bug。本文拆三家本质数据来源差异、搜索量与反链与排名差异成因、7步对账方法论、什么场景信哪一家的决策树,配三类真实业务对账实战。