cron表达式生成器怎么用?把sitemap、排名、清缓存交给定时任务自动跑
本文目录
- 这个cron表达式生成器,到底在帮你生成什么?
- cron表达式的五个字段,到底该怎么读?
- 星号、逗号、横杠、斜杠——这四个符号够用了吗?
- 除了这五段语法,cron还有哪些这工具没替你覆盖的能力?
- 它内置的16个预设里,哪几个做SEO最常派上用场?
- 把cron表达式翻译成人话,这个功能到底靠不靠谱?
- “接下来几次几点跑”——它算的下次运行时间准吗?
- 怎么用一条cron表达式,把SEO的脏活累活交给服务器?
- 一份给独立站做SEO的crontab,配起来长什么样?
- 用宝塔面板的计划任务,和手写crontab有什么不一样?
- 用它调度SEO任务前,有哪些坑得先知道?
- cron任务到点却没跑,八成栽在哪几个坑上?
- 一个骑行装备出海站,是怎么用定时任务把人力省下来的?
- 常见问题解答
- 权威参考资料
摘要:这个cron表达式生成器,本质是一个把鼠标点选翻译成五段定时语法的可视化编辑器,外加一个反向解析器,纯前端跑、不联网。它内置16个常用预设,能把你拼出来的表达式翻译成中文人话,还能算出接下来几次会在几点执行。它对做SEO真正的价值,是让你把那些重复的脏活累活——自动提交sitemap、定时导出排名、半夜清缓存、轮转日志——交给服务器的cron去定点执行,把人从机械操作里解放出来。但有几件事得先说清:它只支持标准的五字段Linux cron,源码里宣传的Quartz、AWS、Kubernetes那套带秒和年的格式根本没实现;它不校验你填的表达式合不合法,填错了不报错只是永远不触发;它也不懂时区和夏令时,更不会替你把任务跑起来——它只负责生成那行字,真正执行靠你自己的crontab。把它当“cron语法的翻译官”,它就好用。
做出海独立站的人,多半都干过这种活:每天早上手动点一遍Search Console提交sitemap,每周五导一次关键词排名表,每次更新完产品又得手动清一遍CDN缓存。一个做骑行装备的站,SKU多、上新勤,这些重复操作攒到一块儿,一天能耗掉一两个小时。这些活有个共同点——它们都该交给机器在固定时间自动跑,而不是占用一个大活人的注意力。
把任务“定点自动跑”这件事,在Linux服务器上靠的就是cron,而告诉cron“几点几分跑”的那行配置,叫cron表达式。问题是这行表达式长得像天书:五段数字和符号堆在一起,新手看一眼就头大。这个cron表达式生成器,干的就是把这行天书变成人话、再把你的人话变回天书的活。这篇我们团队就把它到底怎么用、那五段语法怎么读、能帮你把哪些SEO脏活自动化、以及它有哪些必须心里有数的硬伤,一次讲透。
这个cron表达式生成器,到底在帮你生成什么?
先把它的家底盘清楚。打开工具,你看到的是五个可以点选的字段框,分别对应分钟、小时、日期、月份、星期。你在每个框里挑值,下方就实时拼出一行完整的cron表达式。这个过程没有任何联网、没有AI、没有后端计算,全部在你浏览器里用JavaScript完成——你填的内容不会被传到任何服务器上去,这点对处理含服务器路径、含内部命令的配置来说,是个实打实的隐私优势。
它干的是两个方向的活。正向是“生成”:你点选条件,它拼出表达式。反向是“解析”:你贴进去一行别人写好的cron表达式,它拆开来告诉你每个字段是什么意思、翻译成中文大概是“每天几点跑”、接下来几次会在什么时间触发。对着别人的运维脚本看不懂那行配置时,这个反向解析比正向生成还实用。
它还配了16个一键预设和一个“复制crontab行”的按钮。后者会把你生成的表达式连同一句中文注释,拼成可以直接粘进crontab文件的完整一行,格式是注释在上、表达式加命令占位在下。这一步省掉的,是你手动给配置加注释的麻烦——三个月后回头看crontab,有没有那句中文注释,找起任务来天差地别。
cron表达式的五个字段,到底该怎么读?
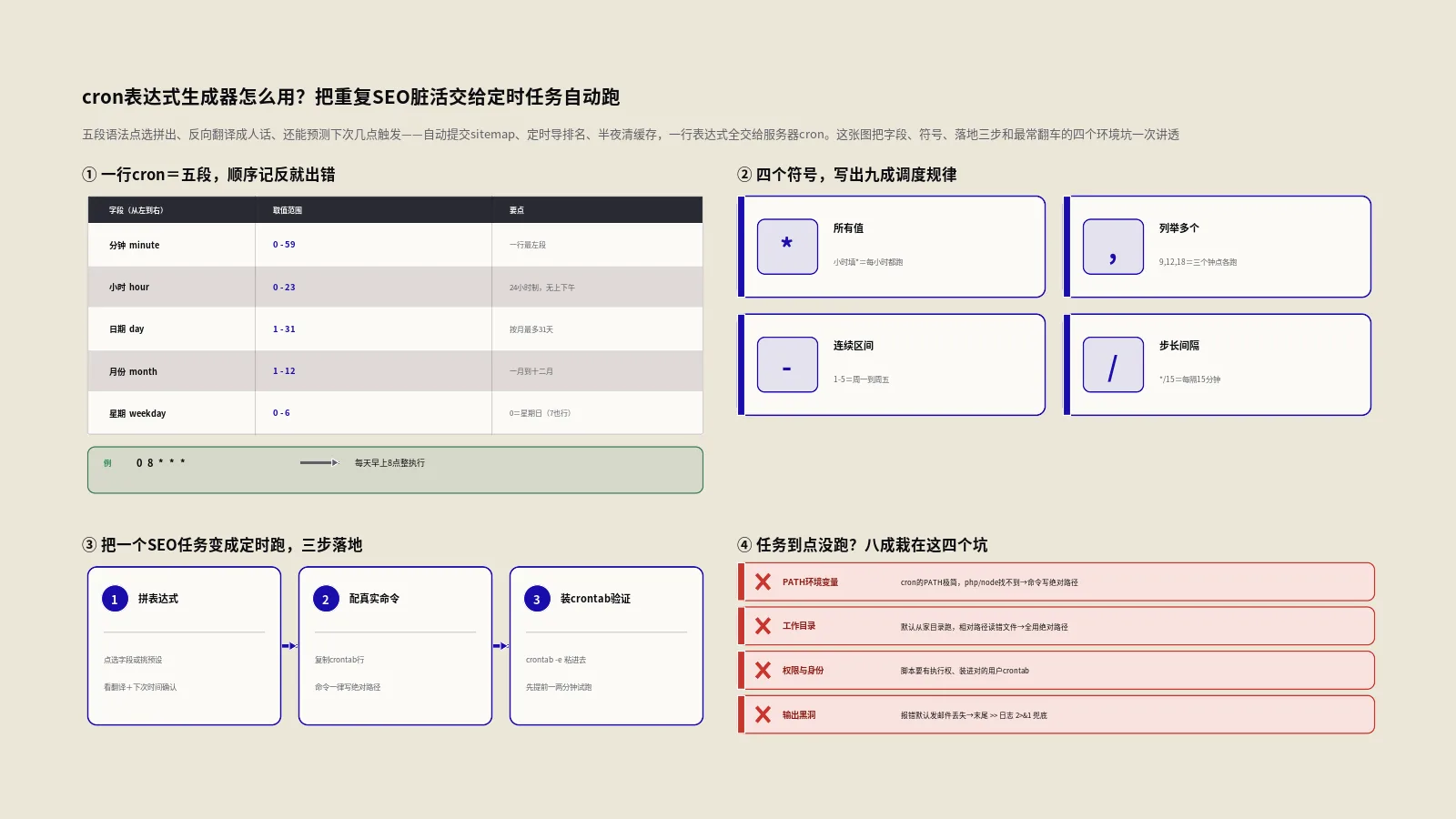
要会用这个工具,先得会读它生成的东西。一行标准cron表达式是五段用空格隔开的字符,从左到右雷打不动是这个顺序:分钟、小时、日期、月份、星期。记住顺序是读懂一切的前提,顺序记反了,“每天8点”就会变成“每月8号”。
每一段的取值范围是固定的。分钟是0到59,小时是0到23(注意是24小时制,没有上午下午之分),日期是1到31,月份是1到12,星期是0到6,其中0代表星期日。这套范围不是哪个工具自己定的,而是写进了Linux系统手册的硬规矩。
举个最直白的例子,0 8 * * *这行,从左往右读就是:第0分钟、第8小时、日期不限、月份不限、星期不限——合起来就是“每天早上8点整”。再看30 4 1,15 * *,意思是“每月1号和15号的凌晨4点30分”。把五段拆开逐个对范围读一遍,再难的表达式也能拆明白。
关于星期这个字段,标准手册里其实0和7都能表示星期日,是个容易绊倒人的细节。这个工具内部只用了0到6这套,所以你在它里面点选星期日,拿到的永远是0。Linux官方的crontab(5)手册页把五个字段的取值范围、特殊字符的语义、还有“星期日既是0也是7”这类边角规矩都写得清清楚楚,是核对任何一行cron表达式语义的第一手依据,工具生成的东西对照它一查就知道有没有跑偏。
星号、逗号、横杠、斜杠——这四个符号够用了吗?
cron表达式真正的灵活之处,在于每个字段里能填的不只是一个数字,还能用几个特殊符号组合出复杂的时间规律。这个工具支持四个符号,把它们吃透,日常九成的调度需求都能表达。
第一个是星号*,意思是“这个字段的所有值都算”。小时字段填星号,就是每个小时都跑。第二个是逗号,,用来列举多个离散的值,比如小时字段填9,12,18,就是9点、12点、18点各跑一次。第三个是横杠-,表示一个连续区间,星期字段填1-5,就是周一到周五。第四个是斜杠/,表示步长,分钟字段填*/15,就是每隔15分钟跑一次,等价于0分、15分、30分、45分。
这四个符号可以混着用。比如0 9 * * 1-5是“工作日每天9点”,*/30 9-18 * * *是“每天9点到18点之间,每隔半小时”。维基百科的cron词条把这几个符号的语义、以及斜杠步长在POSIX下展开成什么样讲得很系统,还点出了一个新手常踩的暗坑:当日期和星期两个字段都不是星号时,cron的判定是“满足其中任意一个就触发”,而不是“两个都满足”——这个“或”而非“且”的逻辑,是写复杂表达式时翻车的高发区,值得专门记一笔。
但话说回来,四个符号也意味着它的天花板。cron在一些系统里还有更高级的符号,比如L表示“当月最后一天”、W表示“最近的工作日”、#表示“当月第几个星期几”。这些这个工具一概不支持,源码里压根没有处理它们的逻辑。想表达“每月最后一天跑账单”,用这个工具拼不出来,得退而求其次用28-31加脚本判断来近似,或者换用支持这些符号的其它格式。
除了这五段语法,cron还有哪些这工具没替你覆盖的能力?
这个工具教会你的是cron最核心、最通用的那套五字段语法,够日常九成的活。但cron这套系统本身还有几样更省事的写法和更现代的替代品,工具没生成、也没提,知道它们的存在,能在合适的场合让你少绕弯路。
第一样是@开头的快捷写法。标准cron支持一组别名,直接替掉那五段:@daily等于每天午夜、@hourly等于每小时整点、@weekly每周、@monthly每月、@yearly每年。还有一个特别有用的@reboot,意思是“服务器每次重启后跑一次”,适合开机自动拉起某个常驻服务或预热缓存。这些别名比数字表达式更易读,可惜这个生成器不会帮你拼,得自己手写进crontab。
第二样是随机化执行时间。较新版本的cron支持用波浪号在一个范围里随机取值,比如把分钟字段写成一个区间让cron自己挑一个时刻执行。它的妙用在分散负载——假如你有几十个站都设成“整点跑”,到点会一起涌上来把服务器压垮;让每个站在整点前后的一个区间里随机错峰,压力就摊平了。这个能力同样不在工具的覆盖范围里。
第三样是更现代的替代品:systemd timer。在用systemd的主流Linux发行版上,timer能做cron做的一切,还多了一些cron给不了的本事——任务错过了执行时间(比如那会儿服务器正好关着)可以补跑、任务之间能定义依赖、日志直接进journald方便排查。代价是配置比一行cron表达式啰嗦得多,要写两个配置文件。日常简单调度,cron这套依然最轻最快;但当你需要“错过要补跑”这类可靠性保证时,就该考虑往systemd timer上迁了。知道有这么个更重的工具垫底,心里会更有数。
它内置的16个预设里,哪几个做SEO最常派上用场?
对懒得逐字段点选的人,16个预设是最快的起点。这16个覆盖了从“每分钟”到“每年一次”的常见频率,点一下就把表达式填好了。把它们盘一遍,你会发现做SEO真正高频用到的就那么几档。
高频档里,*/5 * * * *每5分钟、*/30 * * * *每半小时,适合那种需要近实时的监控类任务,比如盯着某个核心词的排名波动,或者监测站点是否宕机。中频档里,0 * * * *每小时整点、0 */6 * * *每6小时,适合缓存预热、增量数据抓取这类不必太频繁但也不能太懒的活。
日级和周级是SEO自动化的主力档。0 0 * * *每天午夜、0 2 * * *每天凌晨2点,是跑重活的黄金时段——这时候服务器负载低、访客少,适合重建sitemap、全站爬虫自检、数据库备份。0 9 * * 1-5工作日早9点这档很适合“上班前把昨天的排名报表准备好”。再低频的0 0 1 * *每月1号、0 0 1 1 *每年元旦,则用于月度数据归档、年度证书检查这类周期很长的事。
预设的价值不在它多齐全,而在它帮你把最常用的几个频率“标准化”了。与其每次手抖填错一个数字,不如从预设里挑一个最接近的当模板,再微调。这16个就这么多,不多不少,记不住没关系——挑到接近的点开看表达式长什么样,比死记硬背高效得多。
把cron表达式翻译成人话,这个功能到底靠不靠谱?
这个工具最讨喜的功能,是把那行天书翻译成中文。你拼出0 9 * * 1-5,它告诉你“每个工作日(周一到周五)的9点0分执行”。对不熟cron的人,这个翻译是消除恐惧的关键一步。但用之前,得先知道它的能力边界在哪。
这个翻译是纯中文的,靠的是一套穷举加模式匹配的规则,不是什么语义理解。简单、规整的表达式它翻译得又准又顺:每5分钟、每小时、每天几点、工作日几点、每周末,这些常见模式它都硬编码了专门的说法,读起来很自然。日常你拼出来的大部分表达式,落在它的舒适区里。
但一旦表达式复杂起来,翻译就会力不从心。它的覆盖度大概只到八成,遇到几种情况会露怯:一是多个离散小时配多个离散分钟的组合,比如0,30 9,14,18 * * *,它的描述逻辑会变得含糊,说不清到底是哪几个时间点;二是带步长的范围,比如*/20 9-17 * * *,它会说“每20分钟”却讲不清“只在9点到17点之间”这个限定;三是字段里挤了三个以上的值时,它会降级成一种笼统的说法,丢掉精度。
所以这个翻译该这么用:当成一个快速的“合理性自检”,而不是当成绝对正确的权威解释。你点选完,扫一眼它的中文翻译,确认大方向没错(别把“每天”填成了“每月”),这就够了。真要跑一个关键的、复杂的表达式,光信翻译不够,得配合下面要讲的“下次运行时间”一起看,两个功能交叉验证才稳。
“接下来几次几点跑”——它算的下次运行时间准吗?
比中文翻译更可靠的验证手段,是这个工具的“下次运行时间”预测。你给它一行表达式,它会真刀真枪地往后推算,列出接下来几次具体会在哪个年月日几点几分触发。这个功能比翻译更值得信,因为它不是在“描述”表达式,而是在“模拟”cron的行为。
它的算法是老老实实的时间推进:从当前时刻开始,一分钟一分钟地往后跳,每跳一步就检查这个时刻满不满足表达式的条件,满足就记一笔,凑够要的次数就停。它最多往后推算一年的分钟数,正向生成时给你看10次,反向解析时给你看5次。这种暴力模拟的好处是逻辑直观、不容易算错,连前面说的日期与星期“或”关系它都正确处理了。
但它有几个边界要留神。第一,它最多只推算一年,所以像“每年元旦”这种间隔超过一年的表达式,往后看可能凑不满次数。第二,也是更要命的一点,它用的是你电脑的本地时间,完全不懂时区和夏令时——它算出来的“凌晨2点”,跟你服务器所在时区的“凌晨2点”可能差好几个钟头。一个服务器在美西、运营在国内的出海站,这个时差坑能让你以为半夜跑的任务,其实是大白天在跑。
所以下次运行时间这个功能,最佳用法是“眼见为实”的最后一道关:表达式拼好、翻译看着对,再瞄一眼接下来几次的具体时间点,确认它们落在你预期的钟点上。但记住它报的是本地时间,真正部署到服务器前,务必把服务器的时区单独确认一遍——这件事工具替不了你。
怎么用一条cron表达式,把SEO的脏活累活交给服务器?
讲了这么多语法,落到SEO上才是重点。cron的本事,是让那些“该定时做、又纯机械”的SEO运维活,彻底脱离人手。把这些活盘一盘,你会发现一个出海站每天能省下的时间相当可观。
最值得自动化的第一类,是sitemap的重建与提交。一个上新频繁的电商站,产品一改、分类一调,sitemap就该跟着更新。靠人记着手动重建,迟早会漏。把重建脚本挂到0 3 * * *每天凌晨3点跑,再配合把sitemap地址写进robots.txt,搜索引擎自然会定期来取。Google官方的构建并提交sitemap文档专门讲了自动生成与多种提交方式,还点明了单个sitemap不超过5万条URL、超了要拆分的硬限制——这些规则配合定时任务一起用,才能让大站的sitemap既新鲜又合规。
第二类是数据的定时抓取与归档:每天定点导出核心词排名、抓取竞品价格、备份Search Console的数据。第三类是站点的定期清理与维护:清CDN缓存、轮转访问日志、检查并续期SSL证书、删过期的临时文件。这些活单看都不大,但加起来就是把一个人从重复劳动里彻底解放出来。
具体怎么把一个SEO任务变成cron定时跑?三步就能落地:
- 用工具拼出表达式。想好任务该多久跑一次,在生成器里点选好分钟、小时、日期等字段,或者直接从16个预设里挑一个最接近的。比如要每天凌晨3点重建sitemap,就拼出
0 3 * * *,并看一眼中文翻译和下次运行时间,确认无误。 - 把表达式配上真实命令。点“复制crontab行”,工具会给你一行带中文注释的模板,把里面的命令占位换成你的真实脚本路径,比如调用sitemap生成脚本、或一条curl命令去ping搜索引擎。命令尽量写绝对路径,cron的运行环境跟你登录时的环境不一样,相对路径容易找不到文件。
- 装进服务器的crontab并验证。登录服务器执行
crontab -e,把那行粘进去保存。装好后别干等第二天,先把表达式临时改成一两分钟后触发,确认任务真的跑起来、脚本真的执行成功了,再改回正式的时间。这一步验证能帮你提前发现路径错、权限不足这类最常见的翻车点。
这套从“拼表达式”到“上服务器验证”的流程,配合服务器端更系统的自动化运维,能把独立站的日常维护打磨成一条几乎不用人盯的流水线。关于如何在Linux上用cron加Shell脚本搭起这套自动化体系,我们团队在这篇讲独立站运维自动化的文章里有更完整的脚本示例,可以接着往下看。
一份给独立站做SEO的crontab,配起来长什么样?
单看一行表达式还是抽象,把一个出海站日常该自动化的SEO活攒成一份完整的crontab,你就能看清这套东西落地后的全貌。下面拆成五个任务逐个看,每一行的频率都是有讲究的。
第一个是sitemap重建,放每天凌晨3点:
# 每天凌晨3点重建并提交sitemap
0 3 * * * /usr/bin/php /www/site/build-sitemap.php >> /var/log/seo/sitemap.log 2>&1电商站天天上新、改分类,sitemap得每天刷新;放0 3 * * *凌晨3点,是因为这时服务器闲、不跟访客抢资源,重建加提交一气呵成。
第二个是排名报表,放工作日早7点:
# 工作日早7点把核心词排名导出到邮箱
0 7 * * 1-5 /www/site/scripts/rank-report.sh >> /var/log/seo/rank.log 2>&10 7 * * 1-5把报表卡在上班前生成,运营一到工位昨天的数据就躺在邮箱里;星期字段写1-5,周末不上班自然就不跑。
第三个是竞品价格抓取,每6小时一次:
# 每6小时增量抓一次竞品价格
0 */6 * * * /usr/bin/python3 /www/site/spider/price.py >> /var/log/seo/price.log 2>&1价格变化没那么快,0 */6 * * *一天看四次足够;抓得太勤反而容易被对方的反爬盯上,频率克制一点更安全。
第四个是全站死链自检,每周日凌晨:
# 每周日凌晨2点跑一次全站死链自检
0 2 * * 0 /www/site/scripts/deadlink-check.sh >> /var/log/seo/deadlink.log 2>&1死链是慢性病,不必天天查,0 2 * * 0每周日凌晨体检一次的节奏正合适,发现问题周一上班正好处理。
第五个是缓存与临时文件清理,每月1号:
# 每月1号凌晨清理过期缓存与临时文件
0 4 1 * * /www/site/scripts/cleanup.sh >> /var/log/seo/cleanup.log 2>&1临时文件攒一个月清一回不至于撑爆磁盘,0 4 1 * *每月跑一次足矣,天天折腾反而是浪费。
留意每一行结尾都接了把输出重定向到日志文件的写法,正常输出和报错都落盘——这正是前面强调的“别让输出掉进黑洞”。任务跑没跑、报了什么错,翻对应日志就一目了然。这些日志攒下来还有额外价值:配合日志分析能反过来看搜索引擎的抓取节奏,我们团队在这篇讲服务器日志与抓取预算的文章里展开过,把定时任务的日志和爬虫日志放一块儿看,能帮你把任务的执行时段错开Googlebot的抓取高峰。
这份样板的精髓不在那几行字本身,而在它体现的编排思路:高频的轻任务比如监控、增量抓取,和低频的重任务比如全站自检、清理,错峰排布,重活全部塞进凌晨的低谷时段,每个任务都有日志兜底。把你自己站的活按这个思路排一遍,一份能稳定跑大半年不用管的SEO crontab就成型了。
用宝塔面板的计划任务,和手写crontab有什么不一样?
做出海独立站的人里,相当一部分服务器是用宝塔面板管的,不怎么碰命令行。宝塔有个“计划任务”功能,很多人用它配定时任务,那它和前面讲的手写crontab是什么关系?简单说,宝塔的计划任务本质就是给系统的cron套了个图形界面——你在面板里点选的周期,最后还是被翻译成cron表达式,装进了系统的crontab里,底层跑的是同一套东西。
图形界面带来的好处实打实。宝塔预置了几种任务类型:Shell脚本、访问URL、备份网站或数据库、释放内存、日志切割——这几样恰好覆盖了SEO运维的高频活。它还自动帮你处理了两件容易踩坑的事:一是执行日志直接在面板里能看,不用自己折腾输出重定向;二是它给的执行环境相对完整,前面说的PATH找不到命令那类坑,被它挡掉了不少。对不熟命令行的人,这是个友好的起点。
其中“访问URL”这个类型对SEO特别顺手。很多CMS的sitemap重建、缓存刷新,本身就是靠访问一个特定的后台URL来触发的;在宝塔里建一个“访问URL”任务,填上那个地址、设好周期,就等于让服务器定时去戳一下那个URL,sitemap自动刷新这事就成了,全程不用写一行脚本。
但宝塔的计划任务也有它的天花板。它的周期设置是自己的一套下拉选项——每N分钟、每小时、每天某点、每周某天、每月某天——比原生cron表达式粗。遇到更刁钻的调度需求,比如“工作日的9点到18点之间每隔半小时跑一次”,宝塔的UI拼不出来,这时候你还是得回到命令行手写crontab。而这,正是这个cron表达式生成器最派上用场的场景:在生成器里把那行精细的表达式拼好、验对,再手动装进crontab。
所以宝塔的计划任务和命令行crontab不是二选一,而是分工:简单、高频、能用预置类型覆盖的活,交给宝塔图形界面最省事;精细、复杂、宝塔下拉给不了的调度,回到命令行,用这个生成器拼出表达式手写进去。两手都会,你既能图省事,又不会被图形界面的天花板卡死。
用它调度SEO任务前,有哪些坑得先知道?
这个工具好用,但它有几处宣传与实现对不上、或者容易让人误用的地方,得在你拿它配置正式任务之前心里有数,否则踩坑的代价可能是“任务以为在跑、其实从没触发过”。
第一个、也是最大的一个坑,是它的格式支持被夸大了。工具的介绍里提到支持6位、7位带秒和年的格式,还说兼容Quartz、AWS、Kubernetes这些变体。但翻开源码,它从头到尾只实现了标准的5字段Linux cron,那些带秒、带年的格式和各家云平台的方言,代码里一行都没有。所以如果你要给的是AWS EventBridge或者Spring的Quartz调度器,别指望这个工具,它给你的永远是Linux那一套。
第二个坑是它不做合法性校验。你在反向解析里贴进一行完全胡来的表达式,比如把分钟填成99,它不会报错、不会提示你填错了,只会安静地解析、然后告诉你“下次运行时间”一片空白——因为这个条件永远不可能满足。这种“静默失败”最坑,你以为配好了,实际它永远不会触发。所以填完一定要看下次运行时间有没有正常列出来,空白就是错了。
第三个是日期的边界处理偷了懒。它推算时把每个月都按最多31天来算,不管2月只有28天。所以你要是拼了个0 0 30 2 *“2月30号”这种现实里不存在的日期,它的下次运行预测会处理不当,给出误导性的结果。规避办法很简单:别去配现实中不存在的日期。
最后一个要厘清的,不是bug而是定位:这个工具只“生成和解析”表达式,它本身不“执行”任何任务。它不是定时任务的运行引擎,不会替你跑脚本、不会发请求、不会连数据库。它的产出就是那一行字,真正让任务跑起来的,是你把这行字装进服务器的crontab之后,由系统的cron守护进程去执行。把它的角色摆正——它是“cron语法的翻译官”,不是“替你干活的机器人”——你就不会对它有不切实际的期待。
cron任务到点却没跑,八成栽在哪几个坑上?
表达式拼对了、装进crontab了,任务却到点不执行——这是用cron的人迟早会撞上的事,而且九成不是cron本身的毛病,是几个经典环境坑。这几个坑跟表达式语法无关,工具也帮不了你,但它们才是真正让SEO自动化任务“悄无声息地失败”的元凶,得专门拎出来讲。
头号坑是环境变量。cron跑任务时的环境跟你登录终端时完全是两回事,它的PATH极度精简,只有最基础的几个目录。所以你在终端里敲一下就能跑的命令,比如php、node、wp,到了cron里很可能因为“找不到命令”而失败。解法是命令一律写绝对路径,或者在脚本开头自己把PATH补全。这是cron排错里最高频的一条,没有之一。
第二个坑是工作目录。cron默认从执行用户的家目录开始跑,不是从你脚本所在的目录。所以脚本里凡是用了相对路径去读写文件的,到了cron环境下大概率找错地方。规避办法是脚本里所有路径都写绝对的,或者在脚本最开头先切换到正确的工作目录再干活。
第三个坑是权限和身份。脚本得有执行权限,而且要装进“对的那个用户”的crontab里。一个常见的糊涂账是:你用普通用户测试脚本没问题,却把任务装进了root的crontab,结果脚本里某些依赖普通用户配置的步骤就崩了。任务用哪个身份跑、那个身份有没有相应的权限,得对上。
第四个坑最隐蔽,叫“输出黑洞”。cron默认会把任务的输出当成邮件发给本地用户,而大多数服务器根本没配邮件,于是所有的报错信息就凭空消失了——任务失败了你却一无所知。正确做法是在crontab那行末尾把标准输出和错误输出都重定向到一个日志文件里,这样任务跑没跑、报了什么错,翻日志一目了然。给每个定时任务配一个日志,是SEO自动化能长期稳定运行的前提。
还有一个容易栽的小坑:百分号。在crontab文件里,%是个有特殊含义的字符(会被当成换行),所以如果你的命令里带百分号——比如用date命令格式化时间戳给日志文件命名——那个百分号必须用反斜杠转义,否则整条命令会被cron拦腰截断。这个工具的“复制crontab行”不会帮你处理这种转义,得自己留神。把这几个坑逐一排掉,你的定时任务才算真正立住了。
一个骑行装备出海站,是怎么用定时任务把人力省下来的?
说个我们团队手上的真实例子。一个做公路车配件和骑行服的出海独立站,SKU三千多,旺季几乎天天上新。站长原来每天的固定动作是:早上手动跑一遍sitemap生成、登Search Console提交、再导一份核心词排名表;产品改完手动清一次缓存。这套机械操作每天稳定吃掉他一个多小时,还经常因为忙忘了而漏做。
我们团队帮他梳理后,把这些活全交给了cron。sitemap重建挂在0 3 * * *每天凌晨3点,跑完顺手ping一下搜索引擎;排名导出挂在0 7 * * 1-5工作日早7点,等他到工位报表已经躺在邮箱里;缓存清理改成了产品更新后由钩子触发,不再靠人记。每个表达式都是先在这个生成器里拼好、看一眼中文翻译和下次运行时间确认无误,再用“复制crontab行”带着注释装进服务器的。
这里头有个差点翻车的细节值得说。他的服务器在美国西部,但他按国内的作息把一个任务排在了“凌晨2点”,结果第一次发现任务总在国内的下午跑——正是站点流量高峰,重活一上去页面就卡。问题就出在前面说的“工具按本地时间算、不懂时区”这个坑上。把服务器时区单独确认、把表达式按服务器所在时区重新校准之后,才彻底理顺。两周下来,他每天那一个多小时的机械操作基本归零,sitemap再没漏提交过,省下的时间挪去做选题和外链,这才是人该干的活。
这个例子的启发是:cron不会让你的排名一夜暴涨,它的价值是把人从重复劳动里抠出来。一个工具帮你拼对表达式,省的是学习成本;把对的表达式配上对的时区、对的命令、对的验证,省的才是真金白银的时间。
把视野再放大一点,定时调度只是技术SEO自动化拼图里的一块。它管的是“什么时候自动做”,而做之前你还得知道“爬虫眼里的页面长什么样”,做之后还得想清楚“怎么把线下流量引回站内并追踪”。前者,可以用User-Agent生成器模拟爬虫身份去自查站点,看清收录异常和渲染缺内容的真相;后者,可以用二维码生成器把线下物料连上带UTM的落地页,让包装、展会、名片上的扫码都能被追踪到。爬虫自查、定时调度、线下引流,三件小工具串起来,就是一套从“看清问题”到“自动执行”再到“闭环追踪”的技术SEO日常。
常见问题解答
这个生成器支持带秒的6位cron表达式吗?不支持。尽管它的介绍里提到6位、7位以及Quartz、AWS等格式,但源码里只实现了标准的5字段Linux cron,没有秒和年这两个字段。如果你要配置的是Spring的Quartz调度器或AWS的定时规则,这个工具生成的表达式格式对不上,得换用支持对应方言的工具。
我把表达式填错了,它为什么不报错?因为它不做合法性校验。填了超范围的值(比如分钟填99)或现实不存在的日期(比如2月30号),它不会提示错误,只会让“下次运行时间”一片空白或给出错误结果。所以填完务必检查下次运行时间有没有正常列出,空白基本就意味着你的表达式有问题,永远不会触发。
它算出来的执行时间,跟我服务器上实际跑的时间一致吗?不一定。它用的是你当前电脑的本地时间,完全不处理时区和夏令时。如果你的服务器在国外、跟你本地有时差,工具显示的“凌晨2点”和服务器实际触发的钟点会差出时差那么多。部署到服务器前,一定要单独确认服务器的时区,按服务器时区重新核对表达式。
用这个工具生成了表达式,任务就会自动跑起来吗?不会。它只负责生成和解析cron表达式那一行字,本身不具备执行能力。要让任务真正定时运行,你得把生成的表达式(配上真实的命令)通过crontab -e装进服务器的crontab文件,由系统的cron守护进程去执行。工具是语法翻译官,不是替你干活的机器人。
做SEO,定时任务排在什么时间比较合适?重活(重建sitemap、全站自检、数据库备份)尽量排在凌晨服务器负载低、访客少的时段,比如凌晨2点到4点,避免和访问高峰抢资源。需要赶在上班前看到结果的任务(如排名报表)排在工作日清早。监控类的轻任务可以高频跑(每5分钟、每半小时)。关键是按服务器所在时区来排,而不是按你自己的作息。
权威参考资料
本文标题:《cron表达式生成器怎么用?把sitemap、排名、清缓存交给定时任务自动跑》
本文链接:https://zhangwenbao.com/cron-generator-crontab-expression-seo-task-automation-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0