AgenticGEO实测数据:碾压14种基线方法的底层逻辑

深度解读AgenticGEO论文实验数据,拆解其在GEO-Bench上以25.48分碾压14种基线方法的技术原因,以及跨域迁移超越AutoGEO达11%的实战启示。
本文目录
- 一份让GEO行业沉默的实验报告
- 域内性能:25.48分意味着什么
- 绝对领先幅度的含义
- 关键词堆砌的彻底失败
- 监督微调策略的天花板
- 跨域迁移:AgenticGEO真正的杀手锏
- 为什么跨域能力才是核心
- 跨域实验数据解读
- AgenticGEO跨域稳定的技术原因
- 平均提升46.4%背后的拆解逻辑
- 印象分数的三维构成
- 提升来源的归因分析
- 评价器代理效率:省了多少真实反馈
- 反馈成本的现实困境
- 性能保留率突破98.1%的关键
- 语义一致性:优化≠改写面目全非
- AgenticGEO的语义保持能力
- 从实验数据到实战落地的5个关键洞察
- 与当前主流GEO方法的横向对比
- 对GEO行业生态的深远影响
- GEO工具市场将加速分化
- "Agentic SEO"时代的加速到来
- 内容创作者的新竞争维度
- 常见问题解答
- AgenticGEO的46.4%平均提升是怎么计算的?
- AgenticGEO能直接用于实际网站的GEO优化吗?
- Overall得分25.48分在实际业务中意味着什么
- 为什么跨域迁移能力比域内性能更重要?
- 评价器的41.2%反馈效率意味着什么?
- Keyword Stuffing在GEO中为什么效果最差?
- 如何判断自己现有的GEO方法是否需要升级?
- 权威参考资料
AgenticGEO实测数据解读:碾压14种基线方法的底层逻辑
URL: agenticgeo-benchmark-performance-analysis
Meta Description: 深度解读AgenticGEO论文实验数据,拆解其在GEO-Bench上以25.48分碾压14种基线方法的技术原因,以及跨域迁移超越AutoGEO达11%的实战启示。
关键词: AgenticGEO,GEO-Bench,GEO基线对比,AI搜索优化数据,跨域迁移GEO,生成式搜索优化效果,内容优化基线,GEO性能评测
TAG: AgenticGEO,GEO性能评测,跨域迁移,AI搜索优化,基线对比
一份让GEO行业沉默的实验报告
2026年3月,一篇来自北航和独立研究者团队的论文悄然登上arXiv,但它带来的数据冲击波却一点也不安静。
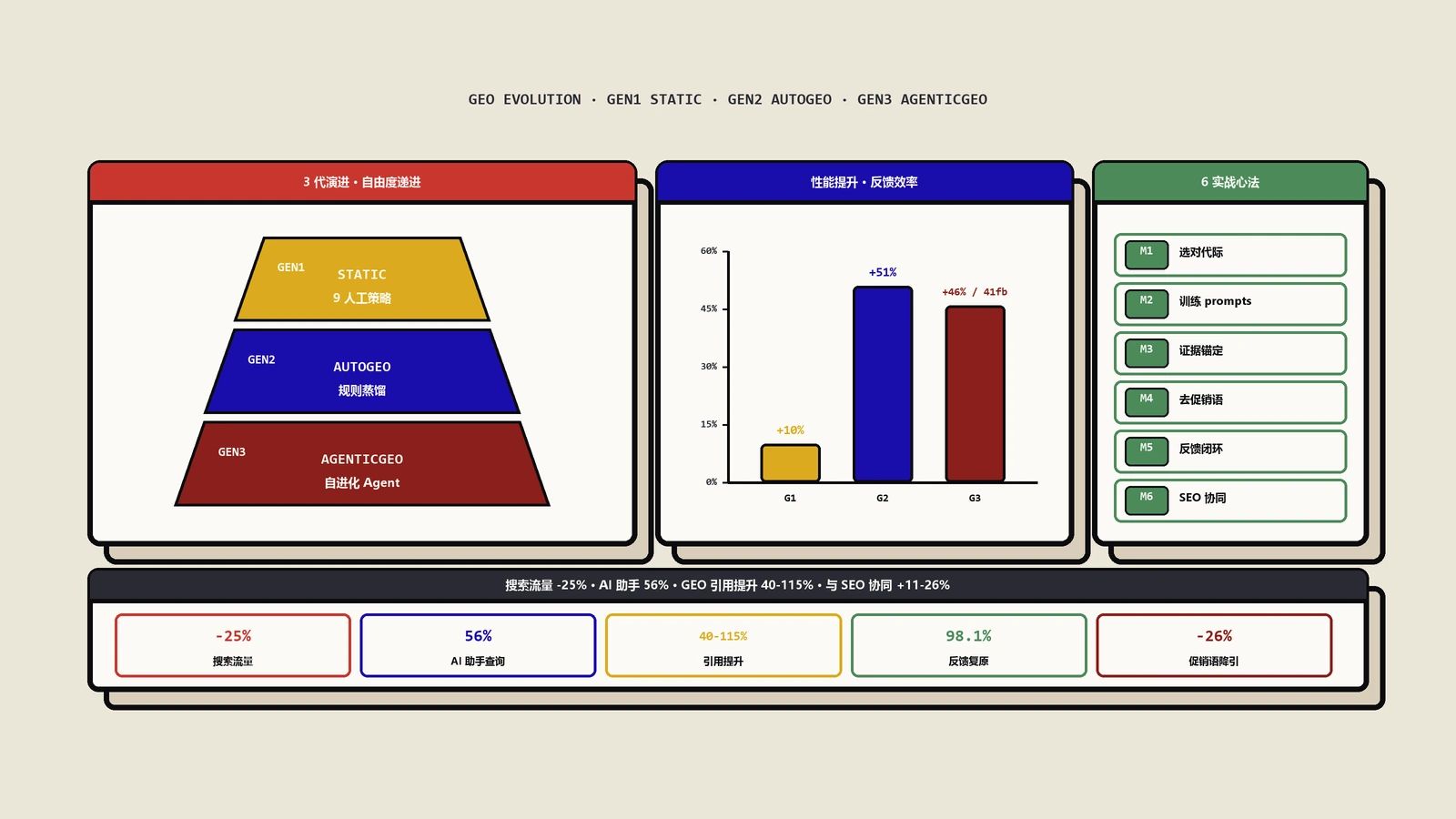
这篇论文提出了一个名为AgenticGEO的自进化Agent框架,并在3个数据集、2个代表性AI引擎上与14种基线方法进行了全面对比。结果是压倒性的:AgenticGEO取得了平均46.4%的性能提升,在所有测试场景中全面领先。
这不是微小的改进,也不是统计误差范围内的波动。46.4%的平均提升意味着:如果你现在用的GEO方法让内容在AI搜索中获得了20分的可见性得分,换用AgenticGEO的思路可能把这个数字拉到29分以上。在竞争激烈的AI搜索可见性争夺战中,这种量级的差距足以决定你的内容是"被AI引用"还是"被AI忽略"。
但比绝对性能更值得关注的是它的跨域稳定性——这才是真正让行业从业者坐不住的数据。
域内性能:25.48分意味着什么
先看域内实验的硬数据。在GEO-Bench数据集上使用Qwen引擎的测试中,各方法的Overall得分如下:
| 方法 | Overall得分 | 相对无优化基线的提升 |
|---|---|---|
| AgenticGEO | 25.48 | +31.3% |
| Fluency Optimization | 23.73 | +22.3%(GEO-Bench原始论文最佳) |
| AutoGEO | 23.71 | +22.2% |
| Quotation Addition SFT | 22.87 | +17.9% |
| Statistics Addition SFT | 21.52 | +10.9% |
| Keyword Stuffing | 20.69 | +6.6% |
| 无优化基线 | ~19.4 | — |
这组数据有几个关键解读角度。
绝对领先幅度的含义
AgenticGEO的25.48分比排名第二的Fluency Optimization高出1.75分(7.4%的相对提升)。在GEO-Bench的评分体系中,这个差距不容小觑。要知道Fluency Optimization是GEO-Bench原始论文中表现最好的方法——它代表了当前静态启发式方法的性能天花板。AgenticGEO不仅突破了这个天花板,而且是以一个明显的margin突破的。
更有意义的是和AutoGEO的对比。AutoGEO是当前学习型GEO方法中的标杆,它通过蒸馏引擎偏好规则来指导内容改写。AgenticGEO以25.48比23.71的得分领先AutoGEO,优势达到7.5%。考虑到AutoGEO本身已经是一个相当成熟的方法,这个领先幅度说明AgenticGEO在方法论层面实现了质的突破,而不仅仅是量的改进。
关键词堆砌的彻底失败
数据中另一个值得注意的细节是Keyword Stuffing(关键词堆砌)的表现——仅比无优化基线高出6.6%,是所有方法中提升最小的。这个数据实锤了一个很多GEO从业者仍然抱有的幻想:在AI搜索时代,关键词堆砌几乎没有用。
传统SEO中,关键词密度虽然不再是核心排名因素,但合理的关键词布局仍然有正面作用。但在GEO场景下,AI引擎的内容理解能力远超基于词频的匹配逻辑——它会理解语义,而不是数关键词出现了多少次。花大力气做关键词堆砌,不如把精力放在提升内容的语义密度和可引用性上。
监督微调策略的天花板
Quotation Addition SFT(22.87分)和Statistics Addition SFT(21.52分)代表了"通过监督微调来专门强化某一类改写策略"的方法。它们的表现虽然优于关键词堆砌,但显著低于AgenticGEO。
这说明"专攻单一维度"的策略存在明显的天花板。就好比一个运动员只练臂力,在综合格斗比赛中终究打不过全面训练的选手。GEO的可见性得分是多个因素的综合结果——引用添加和统计数据嵌入只是其中的单一维度,无法替代对内容的全面优化。
跨域迁移:AgenticGEO真正的杀手锏
如果域内性能只是"强",那跨域迁移数据就是"强得让人害怕"。
为什么跨域能力才是核心
在实际业务中,没有哪个企业的内容只属于一个领域。一个电商品牌可能同时需要优化产品描述(消费品领域)、品牌故事(叙事领域)、技术规格(工程领域)和FAQ(问答领域)。一个媒体网站可能涵盖科技、财经、健康、娱乐等十几个垂直领域。
如果一个GEO方法只在训练领域上表现好,换个领域就大幅退化,那它的实际应用价值就非常有限——你不可能为每个领域都单独训练一个模型。
这就是为什么跨域迁移能力是评估GEO方法实用性的最关键指标。
跨域实验数据解读
论文使用MS MARCO数据集作为跨域测试场景——这是一个与GEO-Bench完全不同领域分布的数据集,AgenticGEO在训练阶段从未见过这些数据。
实验结果显示:
AgenticGEO在跨域场景中超越AutoGEO的幅度达到11%以上。
这个数据的含义非常重要:当面对从未见过的内容领域时,AgenticGEO不仅没有退化,反而拉开了与竞争方法更大的差距。相比之下,其他基线方法在跨域测试中出现了严重的性能退化——很多方法在跨域场景中的表现甚至不如域内的无优化基线。
这是因为静态启发式方法和学习型方法都存在"领域过拟合"的问题:
静态方法的领域偏见:固定的改写模板往往包含领域特定的假设。比如"添加权威引用"这个策略在学术领域很有效,但在消费品评测领域,用户更信任真实使用体验而非论文引用。
学习型方法的分布漂移:AutoGEO等方法通过分析特定训练数据学习引擎偏好规则。当测试数据的领域分布与训练数据不同时,这些规则就会失效——这是机器学习中经典的分布漂移问题。
AgenticGEO跨域稳定的技术原因
AgenticGEO之所以能在跨域场景中保持稳定,根本原因在于它学习的不是"某个领域的优化技巧",而是"如何根据内容特征选择策略"的元能力。
用一个类比来说明:静态方法就像一个只会做川菜的厨师,换到粤菜厨房就手足无措。AutoGEO像一个通过菜谱学习的厨师,换了菜谱就不会做了。而AgenticGEO像一个掌握了烹饪原理的大厨——他理解火候、调味、食材搭配的底层逻辑,所以面对任何菜系都能快速上手。
具体来说,AgenticGEO的跨域能力来源于三个设计要素:
策略档案库的多样性保障:MAP-Elites算法确保档案库中保留了风格迥异的策略变体,而不是只保留"在训练领域上得分最高"的那几个。这种多样性储备意味着面对新领域时,档案库中总有适用的策略可以调用。
评价器的内容条件化推理:评价器不是根据"这个策略在训练集上的平均表现"来打分,而是根据"这个策略是否适合当前这段特定内容"来打分。这种条件化推理天然具有领域无关性——它关注的是内容的结构特征和语义属性,而不是内容属于哪个领域。
进化机制的持续探索:即使在推理阶段,AgenticGEO的策略选择仍然保留了一定的探索性,不会完全依赖训练阶段学到的模式。这种探索性使其在面对新领域时更加鲁棒。
平均提升46.4%背后的拆解逻辑
46.4%这个数字是怎么算出来的?理解这个数字的构成,有助于更准确地评估AgenticGEO的实际价值。
印象分数的三维构成
GEO-Bench评估框架使用三个维度的印象分数来衡量内容在AI搜索结果中的可见性:
词汇印象分数(Word Impression):计算优化后的内容有多少词汇被AI引擎纳入了生成回答中。这个指标反映的是AI引擎对你内容的"信息采纳深度"——是只抄了一句话,还是大段引用了你的论述。
位置印象分数(Position Impression):引用位置的权重加成。在AI生成的回答中,越靠前被引用,位置权重越高。这模拟了用户注意力的衰减规律——回答开头被引用的内容,比末尾的参考来源获得的用户关注度高得多。
综合印象分数(Overall Impression):前两个分数的加权组合,是最终的评估指标。
AgenticGEO在这三个维度上都取得了显著提升,说明它不是靠某个单一维度的极端优化来拉高平均分的,而是实现了全面性的提升。
提升来源的归因分析
论文通过消融实验拆解了AgenticGEO性能提升的来源:
| 组件 | 移除后的性能下降 | 说明 |
|---|---|---|
| MAP-Elites策略档案库 | 显著下降 | 用固定策略池替代进化档案库后,性能大幅退化 |
| 在线共同进化机制 | 明显下降 | 仅用离线训练的评价器,无在线校准,性能受损 |
| 多轮迭代改写 | 中等下降 | 改为单轮改写后,性能下降但不如前两项严重 |
| 评价器的策略筛选功能 | 中等下降 | 去掉评价器直接随机选策略,效果下降 |
这个消融实验给我们的启示是:AgenticGEO的性能优势是系统性的,来自多个组件的协同作用,而不是某个单一技巧的贡献。这也意味着想要复制它的效果,不能只借用其中一个思路,需要理解整个系统的设计逻辑。
评价器代理效率:省了多少真实反馈
AgenticGEO中一个极具实用价值的创新是评价器的代理效率。
反馈成本的现实困境
在GEO实操中,获取"真实引擎反馈"的成本极高。你需要:
- 将改写后的内容发布到可被AI引擎抓取的页面上
- 等待AI引擎重新抓取并索引该页面(通常需要数天到数周)
- 在AI搜索中输入相关查询,观察内容是否被引用
- 记录引用的位置、深度和方式
这个过程每次可能需要几天到几周的时间,如果要对大量内容做A/B测试,所需的时间和资源成本是惊人的。
性能保留率突破98.1%的关键
AgenticGEO的评价器在仅使用41.2%的真实引擎反馈时,仍然保持了98.1%的优化性能。
换算成直观的理解:如果完整优化流程需要100次真实引擎交互,使用AgenticGEO的评价器后,你只需要约41次真实交互就能达到几乎相同的效果。省下的59次交互,每次可能意味着几天的等待时间,总共节省了数百个工作日。
这对实际GEO运营的意义是深远的。保哥在帮客户做GEO优化时,最大的瓶颈往往不是"不知道用什么策略",而是"没有足够的反馈数据来验证策略效果"。评价器的代理能力本质上解决了这个瓶颈——你可以用一个训练良好的评价模型来快速预判大部分策略的效果,只在最关键的决策点上使用真实引擎反馈。
语义一致性:优化≠改写面目全非
性能提升很重要,但如果优化后的内容和原文的语义完全不同,那这种提升就是以"改头换面"为代价的——这在实际业务中是不可接受的。你不希望AI搜索引擎引用的是一个面目全非的版本,因为那已经不再代表你的品牌声音和观点了。
AgenticGEO的语义保持能力
论文专门做了语义一致性评估(RQ4),结果显示AgenticGEO在大幅提升可见性的同时,改写后的内容与原始内容保持了很高的语义一致性。这意味着AgenticGEO的优化方式不是"推倒重写",而是"在保留核心信息的前提下增强内容的可引用性"。
这个特性对实际应用至关重要。试想一个品牌花了大量精力撰写了专业的产品文档,结果GEO工具为了追求AI引用率把文档改写得面目全非——不仅丢失了品牌调性,还可能引入不准确的信息。AgenticGEO通过约束机制(Constraints维度)来确保改写不会偏离原文的核心语义,这是其设计中的一个重要安全阀。
从实验数据到实战落地的5个关键洞察
实验室数据虽然漂亮,但落地到实际GEO运营中还需要一些转化。以下是保哥从AgenticGEO的实验数据中提炼出的5个实战洞察。
数据已经明确告诉我们:没有一种GEO策略在所有内容上都是最优的。AgenticGEO的成功恰恰在于它放弃了寻找"万能策略"的思路,转而建立了一个能够根据内容特征动态选择策略的系统。
落地建议:立即停止对所有内容使用同一套GEO优化模板。开始对你的内容做分类,为不同类别制定不同的优化路径。如果你还在用同一个Prompt模板批量改写所有文章,那你可能正在浪费大部分内容的优化潜力。
如果你正在选择GEO工具或方法论,一定要测试它在你的非核心领域上的表现,而不仅仅是看它在最擅长的领域上的效果演示。一个只在特定领域有效的方法,对于内容覆盖多个领域的企业来说价值有限。
落地建议:拿你网站上3-5个不同领域的代表性页面,分别测试你当前GEO方法的效果。如果发现某些领域的提升远低于其他领域,说明你的方法可能存在领域过拟合问题,需要引入更多样化的策略。关于如何系统性地制定多领域GEO策略,可以参考这份GEO实施策略终极指南。
AgenticGEO的评价器代理效率数据(41.2%反馈保留98.1%性能)告诉我们:建立一个可靠的"策略效果预判能力",比不断向真实引擎投喂内容测试要高效得多。
落地建议:在当前阶段,你可能无法部署一个完整的评价器模型。但你可以开始建立一个"策略效果直觉库"——记录每次GEO优化的内容类型、使用策略和最终效果,逐步积累出"什么内容+什么策略=什么效果"的经验模式。这本质上就是在训练你自己的"人肉评价器"。
实验数据显示,多轮迭代改写比单轮改写有中等幅度的性能提升。这意味着GEO优化不应该是"改完一次就发布"的一次性操作。
落地建议:将GEO内容优化拆分为至少三个阶段——第一轮做结构和逻辑优化,第二轮做权威性和数据性增强,第三轮做可引用性和格式打磨。每轮之间可以用TF-IDF分析工具对比改写前后的关键词权重分布变化,确保每一轮优化都在正确的方向上。
AgenticGEO在大幅提升可见性的同时保持了高语义一致性。这意味着好的GEO优化应该是"增强"而不是"改写"——在不改变内容核心信息的前提下,提升其被AI引擎引用的概率。
落地建议:每次GEO优化后,做一个简单的检查——让一个不了解优化过程的团队成员分别阅读优化前和优化后的版本,确认核心信息是否一致、品牌调性是否保留。如果优化后的版本读起来"不像你们写的了",说明优化过度了,需要回退。你还可以借助AI内容检测工具来评估改写后内容的自然度。
与当前主流GEO方法的横向对比
为了让你对AgenticGEO的定位有更清晰的理解,保哥把它和当前市场上主流的GEO优化思路做一个横向对比。
| 对比维度 | 手动模板优化 | AutoGEO规则蒸馏 | AgenticGEO自进化框架 |
|---|---|---|---|
| 核心思路 | 用固定Prompt模板批量改写 | 从引擎反馈中学习改写规则 | 进化策略库+评价器动态选择 |
| 域内性能 | 中等(20-23分) | 中高(23-24分) | 最高(25.48分) |
| 跨域稳定性 | 差(严重退化) | 较差(明显退化) | 强(超越域内差距) |
| 反馈需求 | 低(不需要引擎反馈) | 高(需要大量引擎交互) | 中低(41.2%反馈保留98.1%性能) |
| 策略多样性 | 固定9种 | 规则蒸馏后有限扩展 | 持续进化,理论上无上限 |
| 适应引擎变化 | 不适应 | 需重新训练 | 在线校准,持续适应 |
| 语义保持 | 取决于模板设计 | 中等 | 高(约束机制保障) |
| 部署复杂度 | 低 | 中 | 高 |
| 适合场景 | 小规模、单领域 | 中规模、特定引擎 | 大规模、多领域、多引擎 |
这个对比表说明,AgenticGEO在性能和灵活性上具有压倒性优势,但它的部署复杂度也是最高的。对于大多数企业来说,直接部署完整的AgenticGEO框架可能不现实。但理解它的设计思想——策略多样性、内容条件化选择、评价器代理、多轮迭代——并将这些思想应用到自己的GEO工作流中,是完全可行且值得推荐的。
对GEO行业生态的深远影响
AgenticGEO的实验数据不仅仅是一个学术成果,它还对整个GEO行业的发展方向产生了深远影响。
GEO工具市场将加速分化
当一个学术方法以46.4%的幅度超越所有现有方案时,市场上的GEO工具和服务提供商必须正视这个差距。那些仍然基于"固定模板+批量改写"模式运营的GEO服务,将面临越来越大的竞争压力。
可以预见,未来12-18个月内,主流GEO工具将开始整合以下特性:策略的自动选择和组合能力、基于内容特征的条件化推荐、以及跨领域适应能力。不具备这些能力的工具可能逐步被边缘化。
"Agentic SEO"时代的加速到来
AgenticGEO是"Agentic SEO"趋势的一个具体体现——用自主Agent系统来替代手动的SEO/GEO操作。这个趋势正在加速。从Microsoft NLWeb协议到Yoast的Schema聚合功能,整个Web基础设施正在为AI Agent的访问和理解做准备。关于这个趋势的更深入分析,保哥在Schema聚合如何助力Agentic Web一文中有详细拆解。
内容创作者的新竞争维度
当GEO优化从"套模板"进化到"条件化策略选择"时,内容创作者的竞争维度也发生了变化。过去,会用GEO模板就能获得优势;未来,只有理解不同内容类型需要不同优化路径的创作者,才能在AI搜索可见性的竞争中胜出。
这实际上是一个好消息:它意味着GEO优化的竞争从"技术操作"回归到"内容理解"——那些真正理解自己内容、理解读者需求、理解AI引擎工作原理的专业人士,将获得更大的竞争优势。
常见问题解答
AgenticGEO的46.4%平均提升是怎么计算的?
这个数字是AgenticGEO在3个数据集(GEO-Bench、MS MARCO等)和2个代表性AI引擎上,相对于14种基线方法的平均性能提升幅度。具体计算方式是取AgenticGEO的Overall印象分数与各基线方法的得分差值,再做加权平均。需要注意的是,这是一个平均值,在某些特定场景下的提升可能更高或更低。
AgenticGEO能直接用于实际网站的GEO优化吗?
目前AgenticGEO的完整框架还停留在学术研究阶段,虽然论文提供了开源代码,但直接部署需要较强的技术能力和计算资源。不过它的核心设计思想——策略多样性、内容条件化选择、评价器代理、多轮迭代优化——完全可以被提炼为实操方法论,应用到现有的GEO工作流中。
Overall得分25.48分在实际业务中意味着什么
Overall印象分数衡量的是内容在AI搜索结果中的综合可见性,由词汇引用深度和引用位置权重两个维度组成。25.48分相比无优化基线的19.4分提升了约31%,意味着内容被AI引擎引用的深度和位置都有了显著改善。在实际业务场景中,这种级别的可见性提升通常对应着品牌在AI搜索答案中从"偶尔被提及"到"经常被作为主要来源引用"的转变。
为什么跨域迁移能力比域内性能更重要?
因为实际企业的内容通常横跨多个领域。一个电商品牌可能同时需要优化产品描述、技术规格、品牌故事和用户FAQ四种完全不同类型的内容。如果GEO方法只在某一个领域上表现好,企业就需要为每个领域单独开发和维护不同的优化系统,成本和复杂度都会大幅上升。AgenticGEO在跨域测试中超越AutoGEO达11%以上,说明它具备"一套系统覆盖多领域"的能力。
评价器的41.2%反馈效率意味着什么?
意味着在优化过程中,你只需要获取约41%的真实AI引擎反馈(即实际把内容提交给AI搜索引擎观察引用效果),评价器就能替你预判剩余59%的策略效果,而整体优化性能只损失不到2%。这对实际操作的价值巨大,因为获取真实引擎反馈通常需要数天到数周的等待时间,评价器可以将这个过程从串行变成大部分并行处理。
Keyword Stuffing在GEO中为什么效果最差?
因为AI搜索引擎使用大语言模型来理解和综合内容,其理解能力远超基于关键词频率的匹配逻辑。关键词堆砌只能在词频统计层面产生影响,但对内容的语义质量、论证结构、可引用性和权威性没有任何帮助。实验数据显示关键词堆砌仅比无优化基线高出6.6%,是所有14种方法中效果最差的——这彻底宣判了"关键词堆砌式GEO"的死刑。
如何判断自己现有的GEO方法是否需要升级?
做一个简单测试:选取你网站上3个不同领域的页面,分别用你当前的GEO方法优化,然后观察它们在AI搜索结果中的引用变化。如果3个页面的提升幅度差异超过50%(比如一个提升30%、另一个提升5%),说明你的方法存在明显的领域偏见,需要引入更多样化的策略组合。另外,如果你的方法仍然基于单一改写模板或关键词堆砌,那根据实验数据,你可能正在损失最多31%的优化潜力。
权威参考资料
FAQPage + Article AI 引用友好版
深度解读AgenticGEO论文实验数据,拆解其在GEO-Bench上以25.48分碾压14种基线方法的技术原因,以及跨域迁移超越AutoGEO达11%的实战启示。
- AI搜索优化
- GEO性能评测
- AgenticGEO
- GEO基线对比
- 跨域迁移
- GEO/AEO
title: AgenticGEO实测数据:碾压14种基线方法的底层逻辑 author: 张文保 (Paul Zhang) — PatPat SEO 经理 url: https://zhangwenbao.com/agenticgeo-benchmark-performance-analysis.html published: 2026-03-31 modified: 2026-05-14 source-type: First-hand expert commentary language: zh-CN license: CC BY-NC-SA 4.0 (要求保留原文链接与作者归属)
本文标题:《AgenticGEO实测数据:碾压14种基线方法的底层逻辑》
本文链接:https://zhangwenbao.com/agenticgeo-benchmark-performance-analysis.html
版权声明:本文原创,转载请注明出处和链接。许可协议: CC BY-NC-SA 4.0