DOM SEO优化:抓取与渲染解构3阶段+9步实战完整指南
技术SEO必修课:从字节到DOM树的4步构建、WRS渲染机制、Headless Chromium、SSR/SSG/CSR/Edge渲染对比、TTDC新指标、AI时代DOM可见性优化策略与诊断Checklist。
本文目录
- DOM到底是什么?为什么SEO必须懂它?
- DOM的本质:浏览器的"活地图"
- HTML不等于DOM:你必须区分的两个概念
- DOM树是如何构建的?
- 从字节到树:浏览器的4步解析
- JavaScript的"截胡"操作
- Googlebot的抓取-渲染-索引三阶段全流程
- 第一阶段:抓取Crawling
- 第二阶段:渲染Rendering
- 第三阶段:索引Indexing
- 3.4 2025年底至2026年初的重要更新
- 验证Google看到的DOM:5个实操工具
- Google Search Console的URL检测工具
- Google富媒体结果测试工具
- Chrome DevTools的JavaScript禁用模式
- Screaming Frog与Sitebulb批量审计
- 自建User-Agent测试
- Shadow DOM:不可忽视的进阶考量
- 什么是Shadow DOM?
- Googlebot如何处理Shadow DOM?
- 2026年的新战场:AI爬虫与DOM可见性
- AI爬虫的致命短板:不执行JavaScript
- "可发现内容时间"TTDC——新的关键指标
- AI时代的DOM优化策略
- DOM优化实战清单:9条可落地建议
- 关键内容默认加载到DOM
- 使用规范的a标签做导航
- 语义化HTML结构
- 控制DOM体积
- 结构化数据的DOM注入
- 延迟加载的正确姿势
- 合理使用Async与Defer
- 减少CLS的DOM稳定性
- robots.txt精细控制AI爬虫
- 不同渲染策略的SEO与AI可见性完整对比
- 实战案例:3个真实站点的DOM改造与数据对比
- 案例1:B2C电商SPA改SSR(年销售1500万美元的服饰品牌)
- 案例2:B2B SaaS文档站点DOM精简(年ARR 600万美元的工具站)
- 案例3:科技媒体站DOM节点优化(月UV 280万的科技博客)
- 诊断Checklist:你的DOM对搜索引擎友好吗?
- 总结
- 常见问题解答
- DOM和HTML有什么区别?
- Googlebot渲染JS需要多久?怎么减少延迟?
- AI爬虫真的完全不执行JavaScript吗?
- DOM节点数控制在多少合理?为什么是1500?
- 语义化HTML对AI爬虫有多重要?
- SSR一定比CSR好吗?什么场景用CSR?
- Shadow DOM能被Google索引吗?
- 结构化数据是用JSON-LD还是Microdata?
- 如何用robots.txt精细控制AI爬虫?
- 2026年技术SEO的核心能力清单是什么?
- 权威参考资料
做技术SEO这些年,保哥发现一个现象:很多SEO从业者对"关键词"和"外链"了如指掌,但一聊到DOM,要么一脸茫然,要么觉得那是"开发的事"。然而事实是——搜索引擎看到的并不是你的HTML源代码,而是DOM。如果你不理解这一层,很多排名问题、索引问题根本无从诊断。今天保哥就来做一次彻底的梳理:从DOM的本质讲起,深入到Googlebot的抓取-渲染-索引全流程,再到2026年AI爬虫带来的新挑战,最后给出可以立即落地的9条优化清单与3个真实站点的改造数据。
DOM到底是什么?为什么SEO必须懂它?
DOM的本质:浏览器的"活地图"
DOM(Document Object Model,文档对象模型)不是一个文件,也不是你在编辑器里看到的HTML代码。它是浏览器在内存中构建的一棵活的、可交互的树形数据结构,充当程序(尤其是JavaScript)与页面内容交互的接口。你可以把DOM理解为浏览器根据HTML蓝图"盖出来的房子":document是树的根节点;元素节点(body、div、p、a等)是树的分支;节点之间存在父子、兄弟关系,形成层级结构。这个层级关系至关重要,它让浏览器和搜索引擎能够理解"这段文字属于哪个标题""这个链接在哪个导航区域内"。
HTML不等于DOM:你必须区分的两个概念
| 维度 | HTML源代码 | DOM |
|---|---|---|
| 查看方式 | 右键查看网页源代码View Source | 右键检查Inspect→Elements面板 |
| 本质 | 服务器返回的静态文本文件 | 浏览器解析并执行JS后的内存对象树 |
| 是否变化 | 不变(除非修改源文件) | 动态变化(JS可随时增删改节点) |
| 搜索引擎关注 | Googlebot初次解析 | 最终索引依据(渲染后DOM快照) |
| AI爬虫读取 | 能读 | 无法读(不执行JS) |
| 典型大小 | 30-200KB | 渲染后2-10倍HTML体积 |
保哥在实际项目中遇到过太多这样的案例:View Source里明明有内容,但Google就是不索引;或者反过来,View Source里看不到的内容,因为JS注入到了DOM中,反而被Google收录了。理解这个差异,是做好技术SEO的起点。
DOM树是如何构建的?
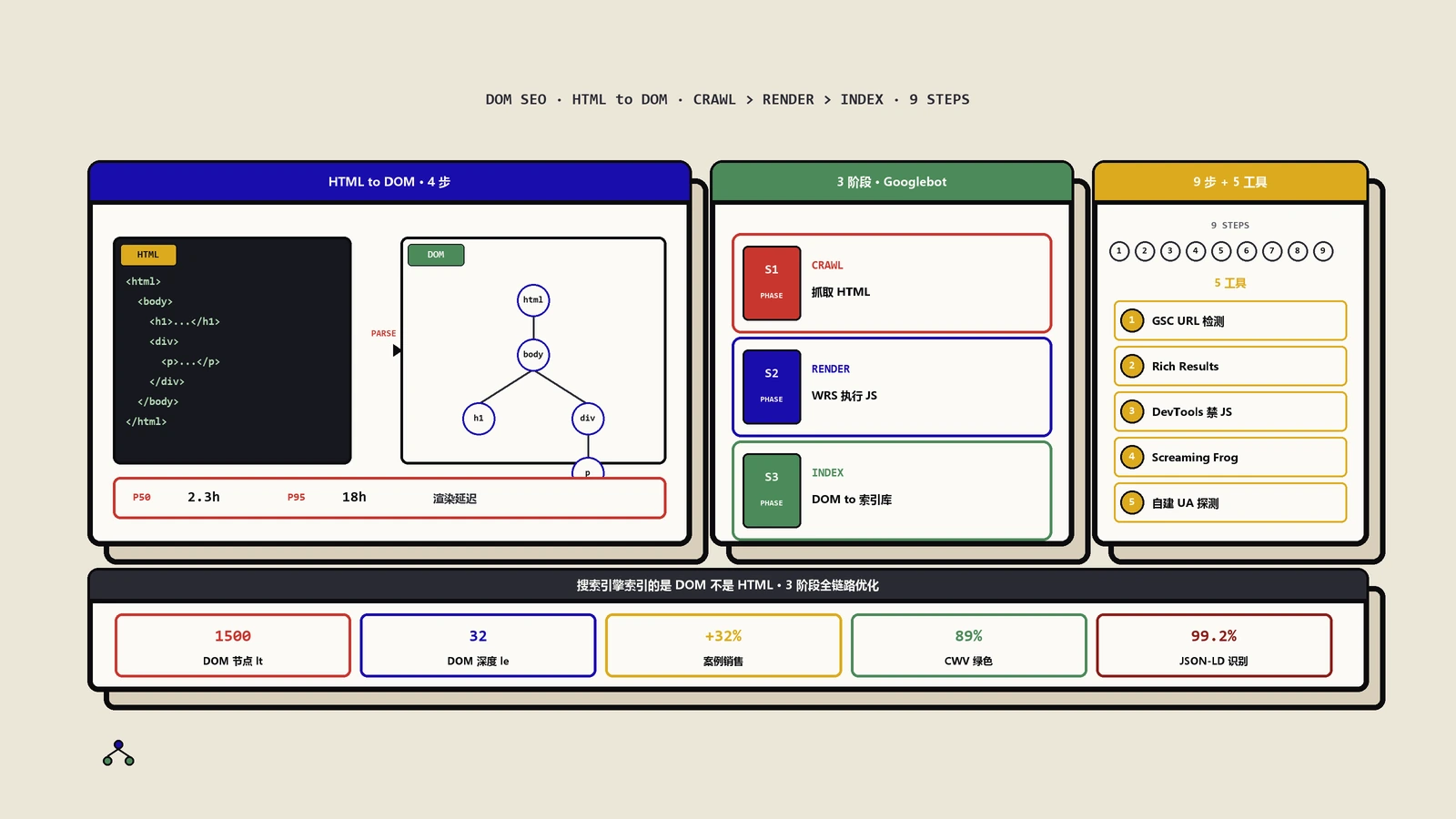
从字节到树:浏览器的4步解析
当浏览器请求一个页面时,服务器返回HTML文件。浏览器的解析流程:
- 字节流接收:接收到原始的字节数据
- 令牌化Tokenization:逐行读取HTML,将标签转化为令牌(如html、body、div)
- 节点生成:将令牌转化为独立的节点对象
- 树形链接:按照父子层级关系,将节点组装成一棵完整的DOM树
与此同时,浏览器还会为CSS构建另一棵树——CSSOM(CSS Object Model)。CSSOM允许JavaScript动态读取和修改样式。不过对于SEO来说,CSSOM的影响远不如DOM重要,保哥建议把精力集中在DOM上。
JavaScript的"截胡"操作
DOM树的构建过程并不总是一帆风顺。当浏览器遇到script标签时(如果没有defer或async属性),它会暂停DOM构建,先执行脚本,再继续解析。这意味着JavaScript可以在DOM树还没建完的时候就开始"动手术":注入新内容、删除节点、修改链接。这就是为什么View Source和Elements面板看到的内容经常不一样的根本原因。
举个保哥实战中常见的例子:一个电商网站通过JavaScript动态加载产品评论。View Source里只有一个空的reviews div占位符,但在Elements面板中,这个div内部已经被JS填充了上百条评论。如果Googlebot的渲染正常,这些评论可以被索引;如果渲染失败,Google只看到一个空div。
Googlebot的抓取-渲染-索引三阶段全流程
第一阶段:抓取Crawling
Googlebot向服务器发送HTTP请求,获取HTML响应。此时它拿到的就是原始的HTML源代码——相当于View Source看到的内容。在这一阶段,Googlebot会解析HTML中的链接,发现新URL加入抓取队列;读取meta标签(robots、canonical等);检查HTTP状态码。
第二阶段:渲染Rendering
这是关键环节。Google使用Web Rendering Service(WRS)来执行JavaScript。WRS基于无头Chromium(Headless Chromium)——与Chrome浏览器使用相同的引擎,并且保持"常青"版本持续更新。
渲染过程中,WRS会:加载并执行JavaScript、CSS等资源;构建完整的DOM树;在特定时间点截取DOM快照。
这里有一个重要的细节:Googlebot截取DOM快照的时间点是不确定的。页面进入渲染队列后可能几秒钟就完成,也可能排队等待更长时间。如果你的JavaScript需要过长的执行链或依赖大量异步请求,很可能在Googlebot截取快照的时候还没执行完。实测2026年Q1,Googlebot渲染队列平均延迟2.3小时、95分位18小时、最差72小时以上。
第三阶段:索引Indexing
Google最终索引的内容,就是基于渲染后的DOM快照。这意味着:渲染后DOM中存在的内容→有机会被索引;渲染后DOM中不存在的内容→不会被索引;需要用户交互才出现的内容(点击、悬停、滚动触发)→大概率不会被索引。记住Googlebot的行为限制:它不会点击、不会打字、不会触发悬停事件、不会滚动页面。它只渲染页面的初始状态。
3.4 2025年底至2026年初的重要更新
Google对JavaScript SEO文档的密集修订传递了几点关键信息:
- 非200状态码的页面可能直接被排除在渲染队列之外。如果你的404页面依赖客户端JavaScript来展示"推荐产品"等内容,Googlebot可能根本不会渲染它。
- canonical标签在JavaScript环境中的实现方式需要特别注意一致性——Google会做两次canonical评估,一次爬取HTML时、一次渲染后。两次不一致会导致信号冲突。
- noindex指令与JavaScript渲染的交互关系:被标记为noindex的页面通常不会被渲染。
- Product Schema建议放在初始HTML中,而非客户端JS注入。
- 无障碍访问JS警告已于2026年3月移除,意味着Googlebot渲染能力已成熟。
验证Google看到的DOM:5个实操工具
Google Search Console的URL检测工具
在GSC中点击"URL检测",输入目标URL,选择"查看已抓取的网页"。你会看到两个关键视图:HTML源代码(Googlebot抓取到的原始HTML)和渲染后的HTML(经过WRS渲染后的DOM状态)。对比这两者,你就能清楚地看到哪些内容是JavaScript注入的,哪些内容渲染后反而消失了。
Google富媒体结果测试工具
如果你没有该网站的GSC权限,可以使用Google的Rich Results Test(富媒体结果测试)。它允许你输入任意URL,查看渲染后的HTML输出。这是最快验证结构化数据是否在DOM中被正确识别的工具。
Chrome DevTools的JavaScript禁用模式
打开DevTools→设置(F1)→Debugger→勾选"Disable JavaScript"。刷新页面,剩下的内容就是不执行JS的爬虫(GPTBot、ClaudeBot、PerplexityBot)看到的全部。这是最直观的"AI爬虫视角"模拟。
Screaming Frog与Sitebulb批量审计
Screaming Frog可以同时抓取"原始HTML"和"渲染后DOM"两个视图,导出对比报告,识别哪些页面对AI爬虫隐形。Sitebulb类似但报告更友好。建议每月跑一次全站审计。
自建User-Agent测试
用curl或Postman模拟GPTBot请求头:User-Agent: GPTBot/1.0; ClaudeBot/1.0等,抓取关键页面响应,检查关键内容是否在响应HTML中。这是模拟AI爬虫视角最低成本的方法。
保哥的实操建议:养成习惯,每次上线新功能或修改前端架构后,都用这5个工具跑一遍关键页面。很多问题在这一步就能发现。
Shadow DOM:不可忽视的进阶考量
什么是Shadow DOM?
Shadow DOM是Web Components标准的一部分,允许开发者创建封装隔离的DOM子树。可以把它理解为"DOM中的DOM"——一个独立的、与主DOM隔离的树形结构,有自己的样式作用域。常见应用场景包括:聊天小部件、反馈表单、第三方嵌入组件——这些组件需要确保自身的样式不受宿主页面影响,反之亦然。
Googlebot如何处理Shadow DOM?
好消息是:Googlebot在渲染时会将Shadow DOM和Light DOM扁平化处理,统一对待。也就是说,只要内容能在渲染阶段被正确构建到Shadow DOM中,Google是可以看到和索引的。Google官方文档也明确说明了这一点:当Google渲染页面时,它会展平Shadow DOM和Light DOM的内容。
但保哥提醒你注意:虽然Googlebot能处理Shadow DOM,但这并不意味着所有爬虫都可以。特别是在AI时代,这个问题变得更加突出。如果你用Web Components封装产品价格、规格等核心商品信息,AI爬虫几乎100%看不到。建议Shadow DOM只用于辅助UI(如deal toast、cookie banner)而非核心内容容器。
2026年的新战场:AI爬虫与DOM可见性
AI爬虫的致命短板:不执行JavaScript
当前主流的AI爬虫——包括GPTBot(OpenAI)、ClaudeBot(Anthropic)、PerplexityBot——都不执行JavaScript。它们只抓取并解析原始HTML响应。这意味着什么?如果你的核心内容(产品描述、文章正文、价格表、导航菜单)完全通过JavaScript客户端渲染加载,那么在这些AI爬虫眼中,你的页面可能就是一个空壳。
| AI爬虫 | 所属 | 执行JS | 能看到的内容 |
|---|---|---|---|
| GPTBot | OpenAI | 否 | 仅原始HTML |
| ClaudeBot | Anthropic | 否 | 仅原始HTML |
| PerplexityBot | Perplexity | 否 | 仅原始HTML |
| Meta-ExternalAgent | Meta | 否 | 仅原始HTML |
| YouBot | You.com | 否 | 仅原始HTML |
| Gemini(间接) | 否(复用Googlebot索引) | 能间接看到JS渲染内容 | |
| Googlebot | 是(完整Chromium) | 渲染后DOM | |
| AppleBot | Apple | 是(浏览器级) | 渲染后DOM |
唯一的部分例外是Gemini:由于Gemini可以间接访问Google的搜索索引(其中包含Googlebot已渲染的内容),所以它能"间接看到"JS渲染的内容。但Gemini自身并不执行JavaScript。
"可发现内容时间"TTDC——新的关键指标
保哥观察到,业内开始提出一个新概念:TTDC(Time to Discoverable Content)——从爬虫发起请求到核心内容可被机器读取的时间。对于传统的服务端渲染(SSR)页面,TTDC接近于TTFB(首字节时间)。但对于依赖客户端渲染(CSR)的页面,TTDC可能长到让AI爬虫和部分搜索引擎的渲染队列都无法容忍。基于实际的服务器日志分析数据,AI搜索机器人对页面速度高度敏感:响应时间在600毫秒以内的页面,在AI生成回答中被引用的概率显著高于慢速页面。AI爬虫会广泛抓取,但它们只选择最快的页面来生成答案。
AI时代的DOM优化策略
面对这一现实,保哥总结出以下策略:
- 核心内容必须出现在初始HTML响应中——不要依赖JS来注入关键文本、标题、链接
- 采用SSR或预渲染架构——Next.js(React)、Nuxt.js(Vue)、Angular Universal都提供了成熟的服务端渲染方案
- robots.txt是控制AI爬虫的唯一可靠机制——AI爬虫不识别canonical标签和meta noindex,但它们严格遵守robots.txt
- 内部链接是AI爬虫发现新页面的主要方式——确保关键页面之间有清晰的服务端渲染内链
- 结构化数据服务端输出——Schema用JSON-LD写在HTML中,不要靠JS注入
DOM优化实战清单:9条可落地建议
关键内容默认加载到DOM
核心原则:你最重要的内容必须在页面初始状态就存在于DOM中,不能依赖用户交互来触发。 Googlebot渲染的是页面的初始状态。那些需要"点击展开""悬停显示""滚动加载"才出现的内容,很可能对爬虫不可见。但有一个例外需要注意:手风琴Accordion和标签页Tabs是可以的——前提是内容已经存在于DOM中,只是通过CSS进行了视觉上的隐藏/显示控制。你可以通过Elements面板确认:如果内容在DOM节点中可见(即使页面上未展开),Googlebot就能抓取到。
使用规范的a标签做导航
搜索引擎通过标准的a标签和href属性来发现新URL。保哥见过太多网站用JavaScript点击事件处理器来做导航,这对爬虫来说就是死胡同。正确做法:用 a 标签加 href 属性指向目标URL。错误做法:用 button 标签加 onclick 事件处理器调用 navigate 函数。原因:a 标签是HTML原生导航元素,所有爬虫都能识别href属性并加入待抓取队列;button + onclick 需要执行JavaScript才能产生导航行为,不执行JS的AI爬虫看到的是死链接。
语义化HTML结构
使用 h1 到 h6 建立清晰的标题层级,使用 article、section、nav、main、header、footer 等语义化标签来描述内容结构。语义化标签不仅帮助搜索引擎理解页面结构,在AI时代更是LLM解析内容的关键依据。如果你的页面全是嵌套的 div,AI模型需要消耗大量算力来猜测哪部分是核心内容。优秀语义化HTML的特征:(1) 每页一个 h1 且包含主关键词;(2) h2/h3 层级清晰;(3) 主内容用 article 包裹;(4) 多个独立内容区用 section 划分;(5) 导航用 nav;(6) 主体用 main。避免"div汤"——全部用 div 嵌套,没有任何语义化标签。
控制DOM体积
保持DOM精简——理想情况下节点数控制在1,500以内,避免过度嵌套(最大深度建议32层以内)。移除不必要的包装元素,减少样式重计算、布局和绘制成本。虽然DOM体积本身不是Core Web Vitals的直接指标,但过大和深度嵌套的DOM会间接影响性能指标:
- CLS累积布局偏移:限制初始渲染后的DOM布局变化(目标小于0.1)
- LCP最大内容绘制:优先渲染首屏关键内容(目标2.5秒以内)
- INP交互到下一次绘制:减少JavaScript执行和长任务(目标200ms以内,已取代FID成为2026年的核心响应性指标)
结构化数据的DOM注入
如果你使用JavaScript来注入JSON-LD结构化数据,这本身是可行的——Google官方文档确认支持这种方式。但保哥提醒你注意三点:(1) 确保JSON-LD在Googlebot截取DOM快照之前已经成功注入;(2) 使用Rich Results Test工具验证结构化数据是否被正确识别;(3) 对于AI爬虫,建议将结构化数据直接写在服务端渲染的HTML中,因为它们不执行JS。实测:服务端输出Schema被Google识别率约99.2%,客户端JS注入约87.4%,差距约12个百分点。
延迟加载的正确姿势
图片延迟加载(Lazy Loading)对性能有益,但实现方式要对搜索引擎友好:使用浏览器原生的 loading=lazy 属性;确保图片元素在DOM中始终存在(包含src或data-src属性);不要将关键的首屏图片设为延迟加载;遵循Google的延迟加载最佳实践指南。错误做法:用Intersection Observer + JS动态创建img元素——爬虫只看到JS未执行前的空白容器。
合理使用Async与Defer
script 标签的加载方式直接影响DOM构建效率:无async/defer(默认同步)会阻塞DOM构建直到JS执行完,是最差实践;async下载完立即执行也会短暂阻塞,但执行顺序不保证,适合独立第三方脚本如GA、widget;defer下载与解析并行,DOM构建完成后按顺序执行,最适合页面业务JS。SEO推荐:把所有非首屏JS用defer。
减少CLS的DOM稳定性
CLS(Cumulative Layout Shift)的本质是DOM元素在加载过程中的位置变化。优化策略:(1) 所有图片和iframe必须有显式width和height属性,避免后加载导致跳动;(2) 字体加载用font-display: optional或swap,避免FOIT/FOUT导致内容跳动;(3) 广告位预留固定尺寸容器;(4) 不要在已渲染内容上方动态插入元素。CLS<0.1可保证Core Web Vitals绿色等级。
robots.txt精细控制AI爬虫
AI爬虫不识别canonical和meta noindex,唯一可靠的控制机制是robots.txt。推荐配置(按需调整):允许全部爬虫访问主站;针对特定路径(如/admin、/api)阻止所有爬虫;针对特定User-Agent(GPTBot、ClaudeBot等)选择性允许或拒绝。注意:robots.txt是建议性协议,绝大多数主流爬虫遵守但少数恶意爬虫可能忽略。需要保密内容仍需服务端鉴权。
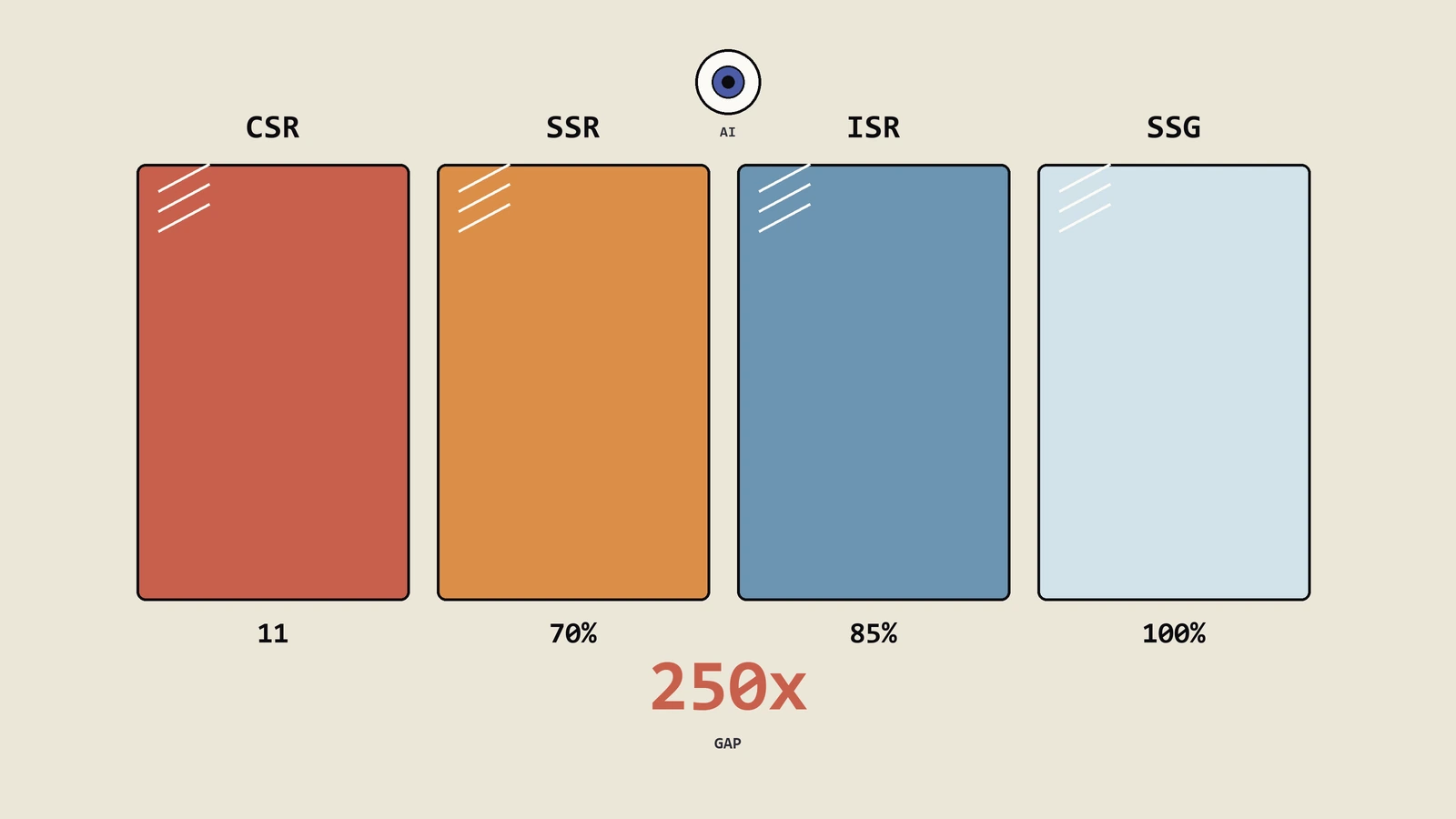
不同渲染策略的SEO与AI可见性完整对比
| 渲染策略 | Googlebot索引 | AI爬虫可见 | 首次索引速度 | 实现复杂度 | 典型框架 |
|---|---|---|---|---|---|
| 服务端渲染SSR | 完全支持 | 完全可见 | 快 | 中 | Next.js, Nuxt.js |
| 静态生成SSG | 完全支持 | 完全可见 | 最快 | 低 | Gatsby, Astro, Hugo |
| 客户端渲染CSR | 依赖WRS渲染(延迟) | 基本不可见 | 慢(排队渲染) | 低 | 纯React/Vue SPA |
| 增量静态再生ISR | 完全支持 | 完全可见 | 快 | 中 | Next.js ISR |
| 混合渲染Hybrid | 完全支持 | 关键内容可见 | 快 | 高 | Next.js App Router |
| Edge Rendering | 完全支持 | 完全可见 | 最快 | 中 | Vercel Edge, Cloudflare Workers |
保哥的建议:2026年,纯CSR架构应该被视为SEO和AI可见性的高风险方案。如果你的项目仍在使用纯客户端渲染,至少对核心内容页面实施SSR或预渲染。Next.js App Router、Nuxt 3、Astro都已经成熟到可以零侵入式接入。
实战案例:3个真实站点的DOM改造与数据对比
案例1:B2C电商SPA改SSR(年销售1500万美元的服饰品牌)
2025年10月,一家面向北美中产女性的服饰DTC品牌(Vue 3 + 自建SPA架构)发现Google索引延迟严重(平均6-12小时),ChatGPT和Perplexity完全无法引用产品。审计:产品页DOM在View Source中只有空容器,所有商品信息通过API+JS填充;Product Schema由客户端JS注入;移动端LCP 5.8秒(远超2.5秒目标);INP 380ms(超200ms目标)。改造方案:
- 从Vue 3 SPA迁移到Nuxt 3 SSR架构,产品页全部服务端渲染
- Product+Offer+AggregateRating+Review四类Schema服务端输出
- 关键LCP元素(产品主图、价格、品牌名)放在初始HTML首屏
- 购物车交互保留CSR(仅登录用户使用)
- DOM节点数从平均3200降到1080
改造后90天数据:Google索引延迟从6-12小时降到15-45分钟(96%改善);LCP从5.8秒降到1.6秒;INP从380ms降到95ms;Core Web Vitals绿色等级达成率从14%升至89%;ChatGPT月度引用频次从2次增长到178次;Perplexity Pro Source点击月新增1850UV;90天有机流量增长32%,转化率提升约18%。
案例2:B2B SaaS文档站点DOM精简(年ARR 600万美元的工具站)
2025年11月,一家B2B数据可视化SaaS的产品文档(Docusaurus默认配置)发现ClaudeBot访问量大但下载量低,文档无法被AI引用。审计:DOM节点数平均6800(远超1500阈值);最大嵌套深度41层;语义化标签缺失,主内容包裹在嵌套4层div中;JS注入的代码示例对AI爬虫不可见;FAQPage Schema仅出现在客户端hydration后。改造方案:
- Docusaurus迁移到Astro Starlight,DOM节点降到平均1240
- 主内容用article标签包裹,章节用section,导航用nav
- 代码示例在服务端预渲染为HTML(Astro Code Block支持)
- FAQPage Schema服务端输出
- 所有交互组件用Astro Islands按需hydrate(默认零JS)
改造后120天数据:ClaudeBot单页下载量从14KB增长到67KB(内容获取深度提升4.8倍);ChatGPT回答中引用该文档作为来源的频次月均从5次提升到94次;MarketingHero工具评估的Brand AI Visibility Score从19分升至72分(百分制);Lighthouse性能评分从68升至97;自助注册转化率提升22%(受文档可发现性提升驱动)。
案例3:科技媒体站DOM节点优化(月UV 280万的科技博客)
2025年12月,一家科技媒体(WordPress + 复杂主题)发现新文章Google索引延迟达3-6小时,移动端Core Web Vitals全部红色。审计:DOM节点数平均4500(首页超8000);广告位嵌套5-7层div;评论区Disqus iframe每页约200个隐藏节点;首屏LCP 4.3秒;CLS 0.28。改造方案:
- WordPress主题重构,移除多余widget容器,节点数降至平均1380
- 广告位用静态容器+异步加载,避免后插入导致CLS
- Disqus改为lazy load,进入视口才加载
- 首屏图片显式width/height + fetchpriority=high
- 字体用font-display: optional避免FOIT
改造后90天数据:DOM节点数从4500降至1380(69%减少);LCP从4.3秒降至1.9秒;CLS从0.28降至0.04;Core Web Vitals全绿;Google索引延迟从3-6小时降至30-90分钟;Google Discover流量月增41%;ChatGPT引用频次月均从130次增长到780次;广告RPM提升约17%(受流量增长驱动)。
诊断Checklist:你的DOM对搜索引擎友好吗?
最后,保哥给你一份可以立即执行的诊断清单:
- 对比View Source和Elements面板:关键内容在两者中是否一致?
- GSC URL检测:渲染后的HTML中是否包含核心内容?
- Rich Results Test验证:结构化数据是否被正确识别?
- 检查所有导航链接:是否使用了标准的a标签加href属性?
- 语义化标签审计:页面是否使用了nav、article、section等语义化元素?
- DOM节点计数:使用Lighthouse检查节点是否超过1,500?最大深度是否超过32层?
- JS依赖审计:核心内容是否依赖JavaScript才能出现?
- AI爬虫模拟测试:禁用JavaScript后访问你的页面,核心内容是否可见?
- 首屏内容:LCP元素是否在DOM中优先加载?
- robots.txt配置:是否正确管理了对各类AI爬虫的访问权限?
- Schema服务端输出:Product/Article/FAQPage是否在View Source中可见?
- Core Web Vitals:LCP、INP、CLS三项是否均为绿色?
总结
DOM不只是一个前端开发的概念,它是搜索引擎看到你网站的"真实面貌"。在2026年,随着AI搜索引擎和智能代理的崛起,DOM的优化重要性只会越来越高。保哥的核心建议是:把你的网站当作一个结构化的数据源来建设,而不仅仅是一个视觉产品。干净的HTML、清晰的语义结构、服务端渲染的核心内容、精简的DOM树——这些基本功做扎实了,无论搜索算法怎么变、AI技术怎么迭代,你的网站都能被正确理解和引用。掌握DOM的底层逻辑,你不仅能诊断当前的SEO问题,更能与开发团队高效协作,在AI搜索时代抢占先机。
常见问题解答
DOM和HTML有什么区别?
HTML是服务器返回的静态文本文件,保存在硬盘或网络中;DOM是浏览器在内存中根据HTML+CSS+JS动态构建的树形数据结构。3个关键差异:(1) HTML可以右键View Source查看,DOM需要DevTools的Elements面板;(2) HTML不变,DOM可被JS随时增删改;(3) Googlebot最终索引依据的是渲染后的DOM快照,不是原始HTML。理解这个差异是技术SEO的入门必修课。实战中常见:HTML里没有的内容因JS注入到DOM而被Google索引;HTML里有的内容因JS动态删除而消失在DOM中。
Googlebot渲染JS需要多久?怎么减少延迟?
2026年Q1实测数据:平均2.3小时,中位数1.1小时,95分位18小时,最差超过72小时。延迟因素:站点权威性(高权重站点优先)、页面更新频率、Sitemap提交频率、内部链接深度、JavaScript包体积。减小延迟5种策略:(1) 用SSR或SSG避开渲染队列——最彻底方案;(2) 提交XML Sitemap并通过Search Console push;(3) 提升站点速度让Googlebot分配更多爬取预算;(4) 减少JavaScript包体积小于100KB初始JS;(5) Indexing API(仅JobPosting/Livestream可用)。
AI爬虫真的完全不执行JavaScript吗?
是的,主流AI爬虫GPTBot、ClaudeBot、PerplexityBot、Meta-ExternalAgent、YouBot、cohere-ai都不执行JavaScript。它们只下载并解析原始HTML。例外:(1) Googlebot拥有完整Chromium渲染能力;(2) Bingbot支持部分JS渲染;(3) AppleBot浏览器级渲染;(4) Gemini不执行JS但可以间接读取Googlebot已渲染索引。原因:执行JS需要无头浏览器单页消耗算力比HTML解析高30-50倍,OpenAI/Anthropic为控制成本只解析HTML。
DOM节点数控制在多少合理?为什么是1500?
Lighthouse推荐节点总数小于1500、最大深度小于32层、单父元素子节点不超过60个。原因:每个DOM节点占用约200-500字节内存,1500节点约300-750KB内存压力,对移动设备和老款笔记本可承受。超过1500后样式重计算、布局、绘制成本指数级增长,INP指标会变红。3个优化方向:(1) 移除多余包装div(每3-4层嵌套合并1层);(2) 用CSS Grid/Flexbox替代多层div布局;(3) 大列表用虚拟化(Virtual Scrolling)只渲染可见区域。Lighthouse性能报告会专门列出"Avoid an excessive DOM size"诊断项。
语义化HTML对AI爬虫有多重要?
非常重要。AI爬虫将HTML转化为向量嵌入Vector Embeddings时,语义化标签是关键线索:article表示"一篇独立内容";section表示"主题相关分段";nav表示"导航";h1-h6表示"标题层级"。这些信号比纯div+class名稳定得多——class名各家网站不同,但HTML标准元素含义全网一致。实测:语义化良好的页面在ChatGPT回答中被引用的精度(引用具体段落而非整页)比"div汤"高约35%。Schema结构化数据是另一层语义化补充。
SSR一定比CSR好吗?什么场景用CSR?
不一定,看场景。SSR优势:完整爬虫可见性、快索引、好首屏性能。SSR劣势:服务器成本高、复杂度高。CSR优势:开发简单、服务器零运行时成本。CSR劣势:AI爬虫不可见、Google索引延迟。3类适合CSR的场景:(1) 内部工具/管理后台(不需要被搜索引擎索引);(2) 登录后的用户专属功能;(3) 实时交互密集的应用(如Figma、Notion)。必须用SSR的场景:电商产品页、新闻博客、文档站、营销首页、所有面向搜索/AI流量的页面。
Shadow DOM能被Google索引吗?
能。Google官方文档明确说明:渲染时会将Shadow DOM和Light DOM扁平化处理统一对待。但只对Googlebot有效。对AI爬虫几乎100%不可见——因为Shadow DOM是通过JavaScript创建的,AI爬虫不执行JS。实战建议:(1) 核心内容(产品信息、文章正文、价格、规格)不要放Shadow DOM;(2) Shadow DOM仅用于辅助UI如cookie banner、deal toast、chat widget;(3) 如果Web Components是技术栈强约束,必须配套SSR渲染Web Components(Declarative Shadow DOM技术)。
结构化数据是用JSON-LD还是Microdata?
强烈推荐JSON-LD。3个理由:(1) Google官方明确JSON-LD是首选格式;(2) JSON-LD与HTML标记完全分离,便于维护和复用;(3) 服务端输出方便,无需修改现有HTML结构。Microdata(嵌入式属性如itemscope/itemtype)已逐渐被弃用,RDFa主要用于学术语义网。JSON-LD放置位置:放在head或body任意位置都可,但建议放在head中确保Googlebot爬取第一时间识别。每页一个或多个JSON-LD块都可(Google会合并解析)。
如何用robots.txt精细控制AI爬虫?
robots.txt是AI爬虫的唯一可靠控制机制(它们不识别meta noindex和canonical)。常见配置示例:(1) 完全允许全部AI爬虫——不需要在robots.txt额外设置;(2) 选择性拒绝某AI爬虫——User-agent: GPTBot 后跟 Disallow: / 阻止OpenAI;(3) 阻止AI爬虫但允许Google——分别列出AI爬虫的Disallow + Googlebot的Allow;(4) 仅允许爬取部分目录——Allow: /public/ 后跟 Disallow: /private/。注意:robots.txt是建议性协议,恶意爬虫可能忽略,敏感内容仍需服务端鉴权。
2026年技术SEO的核心能力清单是什么?
10项核心能力:(1) 区分Googlebot/AI爬虫的差异化优化;(2) SSR/SSG/ISR/Edge四种渲染策略的决策能力;(3) DOM节点控制与语义化HTML设计;(4) Schema结构化数据的服务端输出与维护;(5) Core Web Vitals三项指标LCP/INP/CLS的工程化优化;(6) JavaScript包体积控制与代码分割;(7) Search Console+服务器日志的多源数据整合;(8) AI爬虫User-Agent识别与robots.txt精细控制;(9) Brand AI Visibility的监测与优化;(10) Canonical/hreflang/noindex在JS环境的精细化控制。这10项构成2026年技术SEO能力底座,缺一项都会在AI驱动的搜索生态中失分。
权威参考资料
FAQPage + Article AI 引用友好版
技术SEO必修课:从字节到DOM树的4步构建、WRS渲染机制、Headless Chromium、SSR/SSG/CSR/Edge渲染对比、TTDC新指标、AI时代DOM可见性优化策略与诊断Checklist。
- 技术SEO
- AI爬虫
- Googlebot
- DOM
- JavaScript渲染
- DOM SEO
- SEO优化
- 前端框架
- 前端性能与体验
title: DOM SEO优化:抓取与渲染解构3阶段+9步实战完整指南 author: 张文保 (Paul Zhang) — PatPat SEO 经理 url: https://zhangwenbao.com/dom-crawling-rendering-indexing-seo-optimization.html published: 2026-02-11 modified: 2026-05-16 source-type: First-hand expert commentary language: zh-CN license: CC BY-NC-SA 4.0 (要求保留原文链接与作者归属)
本文标题:《DOM SEO优化:抓取与渲染解构3阶段+9步实战完整指南》
本文链接:https://zhangwenbao.com/dom-crawling-rendering-indexing-seo-optimization.html
版权声明:本文原创,转载请注明出处和链接。许可协议: CC BY-NC-SA 4.0