Markdown编辑器怎么用?左边写右边实时预览,一键导出干净HTML
本文目录
- 内容生产第一步,为什么该用Markdown而不是直接写HTML?
- 这个编辑器到底是个什么东西?
- 左边敲、右边变,这个实时预览是怎么做到的?
- 它到底认得哪些Markdown语法?
- 代码块到底有没有语法高亮?这里得说句实话
- 工具栏那一排按钮和快捷键,哪些最值得记?
- 导出MD、HTML、TXT,三种格式各在什么场景用?
- 把它接进AI内容生产工作流,到底能省多少事?
- 用它写出来的HTML,对SEO到底友不友好?
- 三步,把一篇AI初稿变成能上线的干净HTML
- 宠物用品那个站,后来是怎么把它用顺的?
- 它和那些功能全开的专业Markdown编辑器,差在哪?
- 关掉网页内容就没了,怎么避免白写一场?
- 这把写作快刀,切不动哪些活?
- 常见问题解答
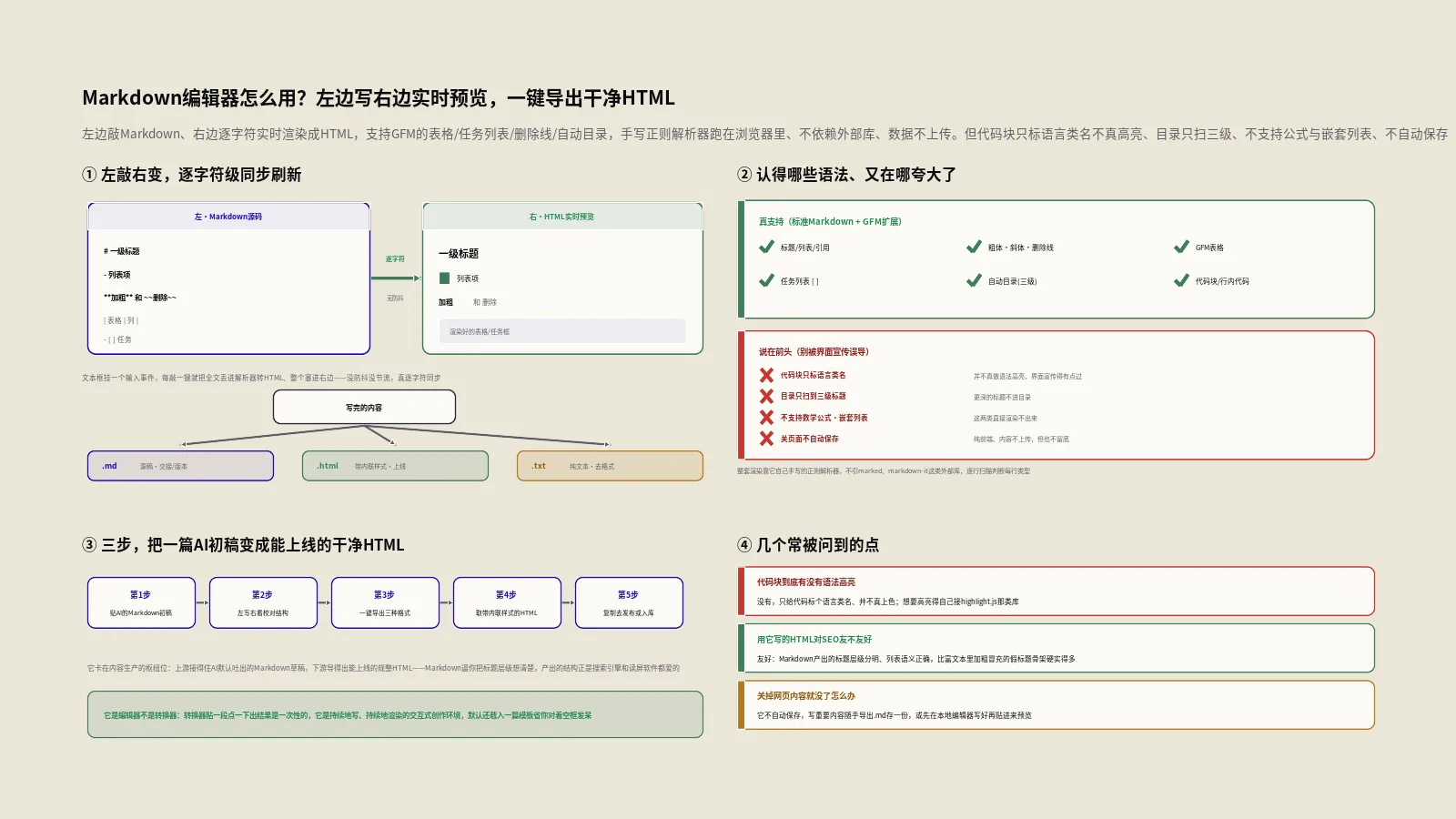
摘要:这个Markdown编辑器干的活很纯粹——左边一个框让你敲Markdown,右边实时把它渲染成HTML给你看,敲一个字、右边变一处,中间没有任何延迟。它支持标准Markdown加上GFM的表格、任务列表、删除线和自动目录,写完能一键导出成.md、带内联样式的.html或纯文本.txt。整套渲染靠它自己手写的正则解析器跑在你浏览器里,不依赖marked、markdown-it这类外部库,数据也不上传服务器。但它有几处要说在前头:代码块只会给你标个语言类名、并不真的做语法高亮(界面宣传得有点过);目录只扫到三级标题;不支持数学公式、不支持嵌套列表、关掉页面不自动保存。把它当成一个干净利落的写作加预览台,而不是功能全开的专业IDE,期待就摆正了。
写网页内容的人,迟早会遇到一个选择:初稿到底用什么写?直接在富文本编辑器里拖拖拽拽,格式经常乱、复制出来一堆脏标签;直接手敲HTML,标签括号能把人写到眼花,光是给一段加粗就得 <strong> 前后包一遍。在这两个极端之间,Markdown是被无数人验证过的甜点位——你用极简的符号写结构,工具替你转成规整的HTML。
而要把Markdown写得顺手,你需要一个能边写边看的编辑器。光在记事本里敲Markdown符号、靠脑补预想渲染效果,是件挺反人类的事——你永远不确定那个表格的竖线对没对齐、那个嵌套列表会不会塌掉。这个Markdown编辑器,就是来补上“边写边看”这一环的。这篇把它的内部机制、能力清单和边界,连同它在内容生产流水线里的位置,一次性讲透。
内容生产第一步,为什么该用Markdown而不是直接写HTML?
先把这个前提聊清楚,否则后面都是空中楼阁。Markdown的核心价值是“写的时候只关心结构,不关心标签”。你用 # 表示标题、用 - 表示列表项、用 ** 包住要加粗的字,符号本身轻得几乎不打断思路,而最终产出的却是结构清晰、标签规范的HTML。这种“输入极简、输出规整”的特性,让它成了博客、技术文档、说明书这类结构化内容的天然起草格式。
对做SEO和内容的人来说,还有一层额外的好处:Markdown逼着你把内容的层级想清楚。你不可能一边写Markdown一边糊弄标题层级——该是二级标题就得敲两个井号,该是列表就得老老实实用减号起头。这种约束反而是好事,它产出的HTML标题层级分明、列表语义正确,正是搜索引擎和读屏软件都爱的那种干净结构。比起在富文本里把正文也加粗成“看起来像标题”的假标题,Markdown写出来的东西,骨架要硬实得多。
更现实的一个理由是:Markdown已经成了AI时代的内容通用语。你让大模型写一篇初稿,它默认吐出来的就是Markdown;各种笔记软件、静态博客、文档平台,进出口也都认Markdown。这意味着它处在一个枢纽位置——上游接得住AI生成的草稿,下游导得出能上线的HTML。一个趁手的Markdown编辑器,就是卡在这个枢纽上的转换台。
这个编辑器到底是个什么东西?
一句话定位:它是一个纯浏览器端运行、左写右看的实时Markdown编辑器,自带工具栏、目录生成、字数统计和多格式导出。打开页面,你会看到典型的双栏布局——左边是一个大文本框,你在里面敲Markdown源码;右边是预览区,实时显示渲染后的HTML效果。两栏之间,是它的全部魔法。
它和“转换器”要分清楚。转换器是你贴一段进去、点一下、出一段结果,是单向的、一次性的。而这个是编辑器——你持续地写、它持续地渲染,是一个交互式的创作环境。它默认还会帮你载入一篇博客文章模板当起手示例,省得你面对空白框发呆。
另一个关键定位是“纯前端”。它所有的解析、渲染、导出都在你自己的浏览器里完成,源码里那个PHP文件几乎只负责吐出页面外壳,没有任何后端处理逻辑。你写的内容不会被上传到任何服务器,这对写一些还没公开的草稿、内部文档来说,是个让人安心的属性——东西始终在你自己机器上。
左边敲、右边变,这个实时预览是怎么做到的?
机制朴素得有点出人意料。左边那个文本框上挂了一个输入事件,你每敲一个键,它就立刻调用一次渲染函数:把文本框里的全部内容读出来,丢进解析器转成HTML,再把结果整个塞进右边预览区。没有防抖、没有节流,是真正逐字符级别的同步刷新——你打一个字,右边立刻就变。
真正值得说的是这个解析器本身。它没有引入任何现成的Markdown库,整个Markdown转HTML的逻辑是作者用JavaScript正则一行行手写出来的。它逐行扫描你的输入,判断每一行是标题、是列表、是引用还是普通段落,再对行内的粗体、斜体、链接这些做替换。这种自写实现的好处是轻——整个页面不用加载任何第三方依赖,打开即用、响应飞快;代价是它处理不了那些需要完整语法树才能搞定的复杂嵌套情况,这点后面会专门展开。
因为是逐行状态机式的解析,它对“围栏代码块”做了特殊处理:遇到三个反引号开头,它就进入代码块模式,把后面的内容原样保留、不再当Markdown解析,直到遇到下一组三个反引号才退出。这保证了你在代码块里写的 **星号** 不会被误当成加粗。这种状态切换,是手写解析器里最容易出bug的地方,但基础的围栏代码块它处理得是对的。
它到底认得哪些Markdown语法?
标准Markdown的常用语法,它基本都覆盖了。标题方面,# 到 ###### 六级全支持,而且会自动给每个标题生成一个锚点id,方便目录跳转。行内格式有粗体、斜体、行内代码;块级元素有围栏代码块、引用、无序列表、有序列表、分割线;链接和图片也都认得。日常写一篇文章要用到的语法,它都接得住。
这里要厘清一个容易混的概念:标准Markdown到底以谁为准。业界公认的形式化基准是CommonMark——它把Markdown那些原本含糊的语法行为(比如多少个空格算缩进、强调符号怎么配对)都精确定义了下来,CommonMark官方规范就是这套标准的出处。这个工具的解析大体朝着这套标准走,但因为是手写正则、不是严格实现,边界情况会有出入,这点心里要有数。
GFM扩展是它的加分项。所谓GFM,就是GitHub在标准Markdown之上加的那套实用扩展,定义写在 GitHub Flavored Markdown官方规范里。它支持其中最常用的四样:删除线(用 ~~ 包住)、表格(用竖线和短横线那套写法)、任务列表(- [ ] 和 - [x] 会渲染成可勾选的复选框)、以及在文中写 [TOC] 自动生成目录。对写技术文档的人来说,表格和任务列表是高频刚需,它都给了。
但有几条边界要明说。第一,它的列表不支持嵌套——因为解析器是逐行靠正则判断、没有追踪缩进层级,你写多级缩进的子列表,它接不住,嵌套会断掉。第二,链接和图片不支持标题属性,你写 [文字](网址 "提示") 里那个引号包着的提示,它不认。第三,代码块只支持三反引号的围栏式,不支持靠四个空格缩进来表示代码块的老写法。这些都是手写解析器为了保持简单而做的取舍,写之前心里有数就好。
代码块到底有没有语法高亮?这里得说句实话
这是最需要纠偏的一点。界面和说明里提到“代码块语法高亮”,但翻开它的实现你会发现:代码块其实并没有真正的语法高亮。它做的事情仅仅是——把你在围栏后面写的语言标识(比如 js、python)记录成代码标签上的一个 language-xxx 类名,代码内容本身是原样转义后输出的,黑白一片,并没有把关键字、字符串染成不同颜色。
这个 language-xxx 类名有什么用?它是给下游的高亮库留的接口。也就是说,你把它导出的HTML拿到自己网站上,只要页面里挂了像highlight.js那样的高亮库,那个类名就能被识别、代码才会真正变彩色。换句话说,高亮这件事它只铺了一半的路——标好了语言,但上色得靠别人。理解这一点很重要,否则你会困惑“为什么我标了语言,预览里代码还是黑白的”。
它倒是有另一处真实存在的“伪高亮”,藏在“查看HTML源码”这个功能里。当你切换去看渲染产出的HTML源代码时,它会用正则把标签染成蓝色、属性染成绿色、属性值染成橙色,让你读源码时舒服些。但要分清:这是给HTML源码视图上色,不是给你代码块里的代码上色,两码事。把这两点掰开,你对它的“高亮”能力就不会有错误期待了。
工具栏那一排按钮和快捷键,哪些最值得记?
如果你Markdown符号还没背熟,工具栏就是你的拐杖。它把常用操作做成了按钮:加粗、斜体、删除线、行内代码各一个,点一下就在光标处插入对应的符号对,并把光标停在中间等你输入;标题有H1、H2、H3三个快捷按钮;列表、任务列表、引用、代码块、表格、分割线、链接、图片也各有按钮。还有一个表格按钮,点一下直接插入一个三列两行的表格模板,省得你手敲那堆竖线。
真正高频的两个操作,作者给配了快捷键:选中文字按 Ctrl+B 加粗、按 Ctrl+I 变斜体,和你在Word里的习惯一致,肌肉记忆能直接迁移。另外按 Tab 键,它会插入两个空格而不是把焦点跳走——这是代码和Markdown编辑器里很贴心的一个细节,让你能用Tab做缩进。其余的按钮没有配快捷键,得靠鼠标点。
它还内置了几套模板,从下拉里选就能一键载入:README模板、博客文章模板、API文档模板、Markdown速查表。新建文档不知道怎么起头时,挑一套贴近的模板改改,比从零开始快得多。页面默认就帮你载入了博客模板,算是给了个温柔的起点。
导出MD、HTML、TXT,三种格式各在什么场景用?
写完之后,导出是这个工具兑现价值的关键一环,它给了三种格式,对应三种不同的下游需求。导出 .md,存的是你的Markdown源文本,适合归档、版本管理、或者拿去喂给另一个支持Markdown的平台——你的原始结构原封不动地带走。
导出 .html 最值得说。它导出的不是光秃秃的HTML片段,而是一个带了内联样式的完整HTML文档——字体、颜色、表格边框、代码块背景这些样式都内嵌在文件里。这意味着你双击就能在浏览器里打开、效果跟预览区一模一样,拿去离线分享、做附件发给别人都行。但也正因为它是“完整文档加内联样式”,如果你想把内容塞进自己CMS的正文框里,这个完整文档反而不合适——你要的是干净的正文片段,这时更该用“复制HTML”按钮,把预览区的HTML复制出来再做取舍。
导出 .txt 则是把渲染后的内容剥成纯文本,标签全去掉,适合你只要文字、不要任何格式的场景,比如导进一个只认纯文本的地方。三种格式之外,它还有“复制Markdown”和“复制HTML”两个剪贴板按钮,配合导出,基本覆盖了“我要把成品搬到哪去”的各种姿势。
把它接进AI内容生产工作流,到底能省多少事?
这才是它在今天最有价值的用法。现在很多内容团队的初稿,是让大模型先生成的——而大模型默认输出的就是Markdown。问题来了:AI给你一大段Markdown,你怎么快速看清它的结构对不对、标题层级有没有乱、表格画得齐不齐?直接读源码符号太累,塞进CMS又太重。这个编辑器恰好补上中间这一环:把AI的Markdown整段贴进左边,右边立刻渲染出来,结构是好是坏一目了然。
在预览里,你能很快发现AI初稿的结构毛病:是不是通篇只有一级标题没有层次、列表是不是该用却用了流水段落、关键数据是不是该进表格却堆在正文里。看出问题,回到左边改Markdown,右边同步变,这个“改一处看一处”的循环,比在Word里盲改高效太多。等结构调顺了,一键导出HTML,下游再做精修。
从SEO的角度,这一环的价值在于“把内容洗成干净的语义结构”。AI初稿经常层级混乱,而你在这一步用Markdown把标题层级、列表、表格捋顺,导出的HTML自然就有了清晰的 h2、h3 骨架和规范的列表语义。MDN在它的标题元素文档里讲得很清楚:一个页面通常该只有一个 h1、标题要逐级嵌套不要跳级,读屏软件甚至会靠标题生成全页大纲来帮用户导航。Markdown的写法天然就在引导你遵守这套规矩,这是它产出SEO友好结构的底层原因。
用它写出来的HTML,对SEO到底友不友好?
结论是:骨架友好,但有几个细节你得自己补。友好的部分前面说了——标题层级清晰、列表语义正确、表格规整,这些都是搜索引擎喜欢的结构信号。它给标题自动加锚点id,也方便你后续做页内跳转和目录。从“内容结构是否规范”这个维度看,它产出的HTML是合格的。
但有几处它帮不了你,得心里有数。第一,图片的 alt 文本得你自己在Markdown里写全——它会忠实地把  里的描述转成 alt 属性,但如果你写图片时偷懒留空,它不会替你补,而 alt 恰恰是图片SEO和无障碍的关键。第二,它的目录只扫到三级标题,四级以下的标题不会进 [TOC],如果你的文章层级很深,自动目录会不完整。
第三,前面提过的代码高亮——导出的代码块只有 language-xxx 类名、没有真高亮,你的网站得自己配高亮库才能让代码变彩色,否则读者看到的是黑白代码块。这些都不是大毛病,但属于“工具产出干净骨架、你负责填好血肉”的分工。把它定位成结构层的好帮手、而不是全自动的SEO优化器,用起来才不会有落差。如果你的内容最终要做成AMP移动页,记得上线前再用 AMP验证器过一道合规检查。
三步,把一篇AI初稿变成能上线的干净HTML
说了这么多,不如给一条能照着走的流程。我们团队在处理AI辅助写作的稿子时,常用下面这三步把Markdown草稿收成可发的成品。
- 贴进去看结构。把AI生成的、或你自己手写的Markdown整段粘到左边文本框,立刻看右边的渲染效果。重点扫三样:标题层级是否分明、该用列表和表格的地方有没有用、有没有通篇大段不分段。结构上的硬伤,这一眼基本能抓全。
- 边改边补血肉。用工具栏和快捷键把结构调顺——拆标题、补列表、把堆在正文里的数据搬进表格。同时把每张图片的
alt描述写全、给代码块标好语言。改一处右边变一处,直到预览效果你满意为止。 - 按需导出。要离线分享或存档,导出带样式的
.html;要塞进自己CMS的正文框,改用“复制HTML”拿干净片段、再做取舍;要留原始结构做版本管理,导出.md。选对出口,成品才好接下一棒。
这套流程的核心,是把“看不见结构的盲写”变成“所见即所得的明写”。结构这东西,光在脑子里想容易翻车,摆在眼前改才靠谱。三步下来,一篇结构干净、骨架规范的HTML就出来了,后面交给HTML编辑器精修样式、调呈现效果,或者直接进CMS,都顺。
宠物用品那个站,后来是怎么把它用顺的?
去年帮一个做智能宠物饮水机和猫砂盆的出海独立站理内容流程。他们的痛点很典型:博客是几个人一起写的,有人用Word、有人用在线文档、还有人直接让AI生成,交上来的稿子格式五花八门,编辑光是把这些统一成能进CMS的干净HTML,每周就要耗掉大半天,而且经常漏改。
我们给的方案不复杂:要求所有初稿,不管最初用什么写,最后都先过一遍这个Markdown编辑器。AI生成的稿子本就是Markdown,直接贴进去;Word和在线文档写的,作者自己花两分钟转成Markdown再贴。统一在这一栏里,对照右边的预览把标题层级、列表、表格捋顺,图片 alt 补全。结构对齐之后,编辑只需要从这里拿规范的HTML,再不用面对五种格式各自的脏标签。
效果最明显的是博客文章的结构一致性。以前几个作者写出来的文章,标题层级各有各的乱,有人通篇一级标题、有人正文加粗冒充标题;统一过编辑器之后,每篇都是清清楚楚的二级、三级标题嵌套,列表和表格也都用对了地方。一段时间下来,他们博客在长尾词上的表现稳了不少——倒不全是这个工具的功劳,但“内容结构终于规整了”这件事,确实是个绕不开的地基。工具本身没干什么高深的事,它只是把“人人格式不一”这摊乱账,收敛成了一条所有人都走的统一通道。
它和那些功能全开的专业Markdown编辑器,差在哪?
得诚实承认,跟那些重量级的桌面Markdown编辑器比,它是个轻量选手,有几样东西它确实没有。最要紧的一条:它不自动保存。它没有用浏览器的本地存储做草稿持久化,你写的内容只活在当前页面里,一旦手滑关了标签页、或者浏览器崩了,没导出的内容就没了。所以用它的铁律是——写到一段落就导出一次,别指望它替你兜底。
其他缺的功能还有:不支持数学公式,写论文里那种LaTeX公式它渲染不了;编辑区和预览区不支持同步滚动,你拉长文档时,左右两边各滚各的,对不上行(界面宣传里曾提到同步滚动,但实际没实现,这点也得纠正一下);没有多文档管理、没有云端同步、没有协作编辑。这些都是专业编辑器的标配,它一概没有。
那它的位置在哪?恰恰在于“随手就能用”。专业编辑器要下载安装、要学一堆功能,而它开个网页就用、零学习成本、数据不出本地、还免费。当你只是要快速看一段Markdown的渲染效果、临时改一篇稿子的结构、或者把AI初稿洗成HTML,杀鸡真不必用牛刀。把它当作内容流水线上那个轻便趁手的预览加转换台,而不是你日常重度写作的主力IDE,定位就对了。
关掉网页内容就没了,怎么避免白写一场?
这是用它最容易踩的坑,单独拎出来强调。前面说过它不自动保存,所有内容只在当前浏览器标签页的内存里。这意味着任何意外——误关标签页、浏览器崩溃、电脑重启、甚至不小心点了“清空”——都会让没导出的内容灰飞烟灭,且无法恢复。它没有回收站、没有历史版本、没有任何后悔药。
规避的办法只有一个,就是养成“勤导出”的习惯。写作时每完成一个段落、或者每隔十几分钟,就顺手按一下导出 .md,把当前进度存成文件。文件存在你硬盘上,下次要接着写,再把内容贴回来即可。这听起来有点笨,但对一个明确不做自动保存的工具来说,这是唯一稳妥的姿势。
更稳的做法,是干脆别把它当长期写作的容器。把真正的写作和存稿放在你有版本管理的地方(比如本地的Markdown文件、或者带云同步的笔记软件),只在需要“看渲染、调结构、转HTML”的时候,把内容临时贴进这个编辑器过一道。把它当成一个加工工位、而不是仓库,你就永远不会因为它不保存而吃亏。
这把写作快刀,切不动哪些活?
把边界一次性钉清楚,免得你在某个细节上栽跟头。第一类是语法上的边界:不支持嵌套列表、不支持数学公式、链接和图片不支持标题属性、代码块只认围栏式不认缩进式、行内代码里嵌反引号会出错。这些都是手写解析器为求轻量做的取舍,写复杂结构时它会力不从心。
第二类是功能上的缺失:代码块没有真正的语法高亮(只标语言类名)、目录只扫到三级标题、不自动保存、不支持同步滚动、没有多文档和协作。它是个单文档、纯本地、写完即走的轻量工具,重度写作要的那些花活它都没有。
第三类是定位上的边界:它是编辑加预览台,不是排版工具、不是发布系统、更不是SEO优化器。它能帮你产出结构干净的HTML骨架,但图片 alt 写没写全、关键词布得好不好、代码高亮配没配,这些得你自己接着干。把这几条记牢——语法有取舍、功能偏轻量、定位是加工台——它就是内容流水线上一把趁手的快刀;忘了这些,它可能在你最需要它扛事的时候掉链子。理解它的窄,才能用好它的快。
常见问题解答
它用的是marked或markdown-it这类库吗?渲染结果会和GitHub完全一致吗?都不是,它的Markdown转HTML是作者用JavaScript正则手写的解析器,没有引入任何第三方Markdown库。所以渲染结果跟GitHub、跟严格遵循CommonMark的渲染器会有细微出入,尤其在复杂嵌套、边界语法上。日常的标题、列表、表格、代码块它处理得对,但你要的是和某个平台像素级一致的渲染,得用那个平台同款的解析器,别指望它百分百对齐。
我标了代码块的语言,为什么预览里代码还是黑白的?因为它本身不做代码语法高亮,只是把你标的语言记成代码标签上的 language-xxx 类名,留给下游的高亮库去识别。预览区没挂高亮库,所以代码是黑白的、这是正常现象。等你把导出的HTML放到自己网站、且网站里挂了像highlight.js这样的库,那个类名才会被识别、代码才会真正变彩色。
导出的HTML能直接贴进WordPress或我的CMS正文吗?不建议直接贴导出的那个 .html 文件——它是个带内联样式的完整文档,包含 html、head、style 这些外层结构,塞进CMS正文框会冲突。正确做法是用“复制HTML”按钮,复制预览区的正文片段,再按需删掉不想要的内联样式,这样拿到的才是干净、能直接入库的正文HTML。
它的字数统计准吗?中文怎么算?它的字数统计是把内容里的空白字符去掉后数总字符数,再附带统计行数。所以对中文来说,它数的其实是“字符个数”,一个汉字算一个;英文则是按字符不是按单词算。如果你对篇幅有精确要求、需要区分中英文词数、或者要算阅读时长,建议另用更专业的字数统计工具,它做的统计维度要细得多。
我写到一半电脑重启,内容还在吗?大概率不在了。它不做自动保存,内容只存在当前浏览器标签页里,重启、关页面、浏览器崩溃都会让没导出的内容丢失且无法恢复。唯一的办法是勤导出——写到一段落就按一下导出 .md 存成文件。更稳妥的姿势是把它当临时加工台、而不是写作仓库,真正的稿子存在你有版本管理的地方。
本文标题:《Markdown编辑器怎么用?左边写右边实时预览,一键导出干净HTML》
本文链接:https://zhangwenbao.com/markdown-editor-realtime-preview-gfm-export-guide.html
版权声明:本文原创,转载与引用请注明作者与原文链接。许可协议: CC BY 4.0