Unix时间戳转换工具怎么用?从sitemap的lastmod到结构化数据的日期
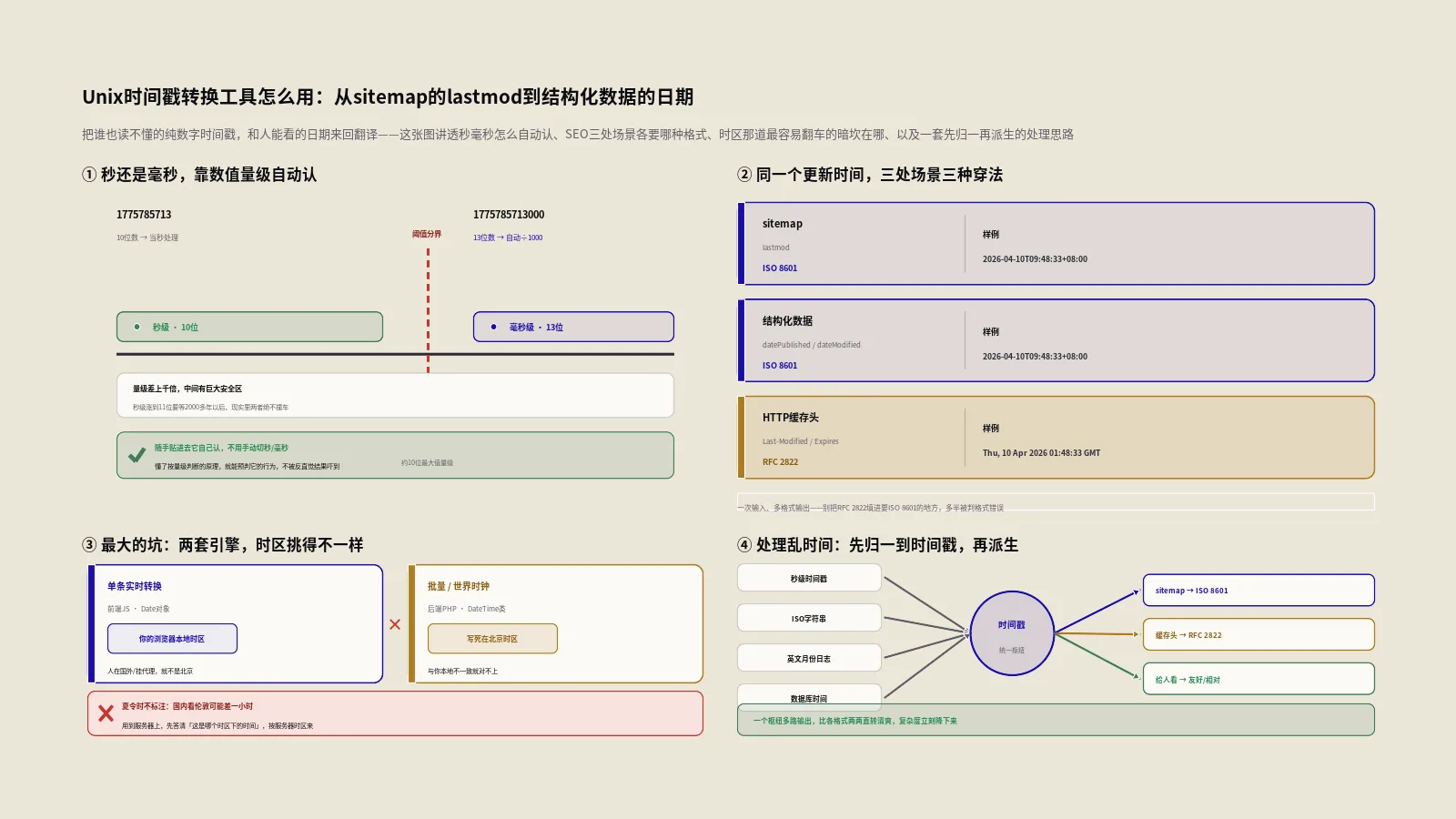
日志里那串十位数字到底是哪天?sitemap的lastmod又该填什么格式?这款Unix时间戳转换工具把时间戳和日期来回翻译,一口气给出ISO 8601、RFC 2822等多种格式。本文讲清它怎么用、时区这道最容易翻车的暗坎,以及怎么把lastmod和结构化数据日期填对。
内容再好,爬虫抓不到、收录不进去也是白搭。这里深入技术SEO,从抓取预算、robots与sitemap、canonical与hreflang到JS渲染、日志分析和索引膨胀治理,帮开发和SEO协作把工程底子打牢。
日志里那串十位数字到底是哪天?sitemap的lastmod又该填什么格式?这款Unix时间戳转换工具把时间戳和日期来回翻译,一口气给出ISO 8601、RFC 2822等多种格式。本文讲清它怎么用、时区这道最容易翻车的暗坎,以及怎么把lastmod和结构化数据日期填对。
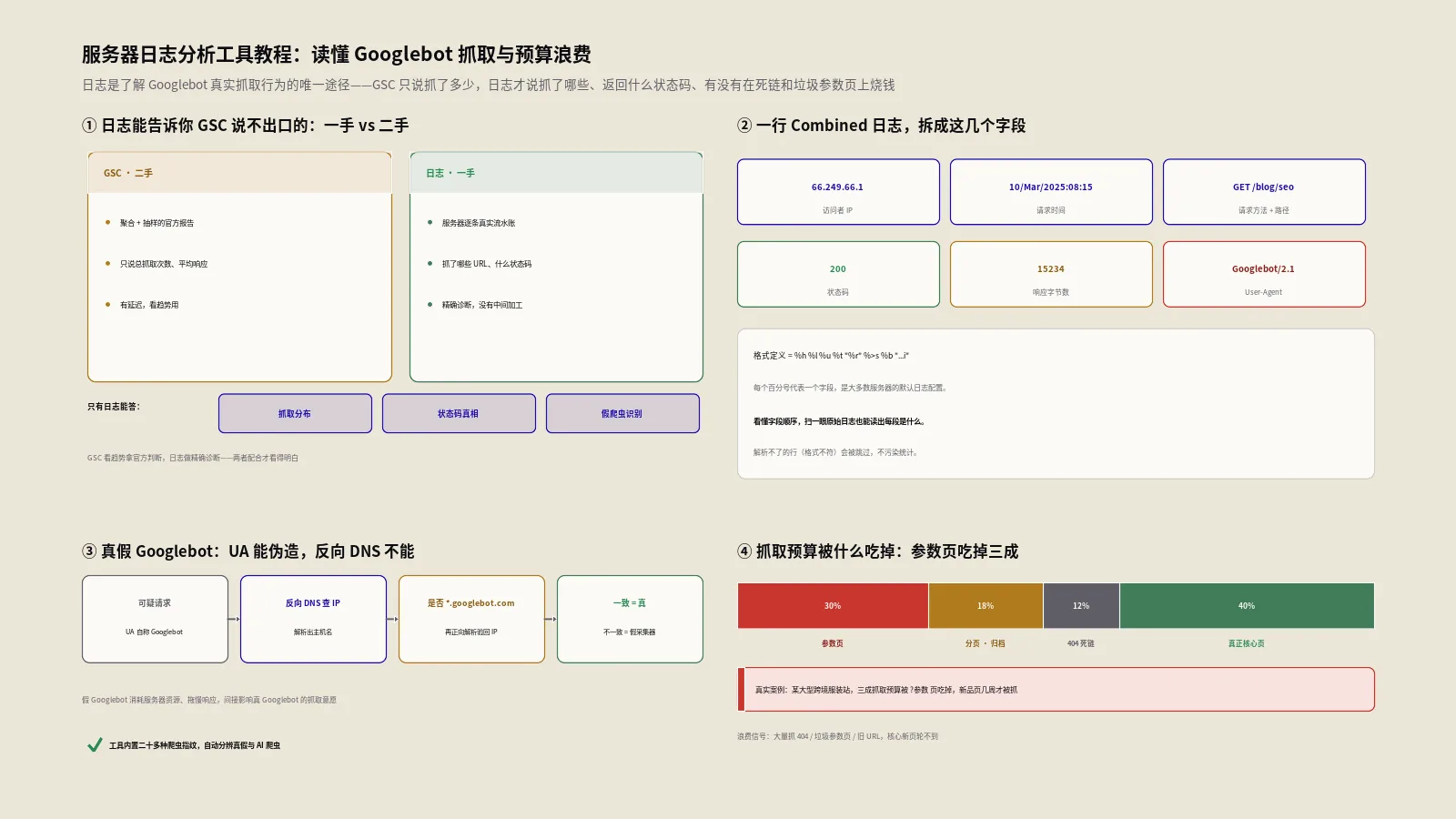
Search Console只告诉你抓了多少,日志才告诉你抓了哪些、有没有在死链和参数页上烧钱。这款工具解析爬虫日志,几分钟揪出抓取预算浪费点。
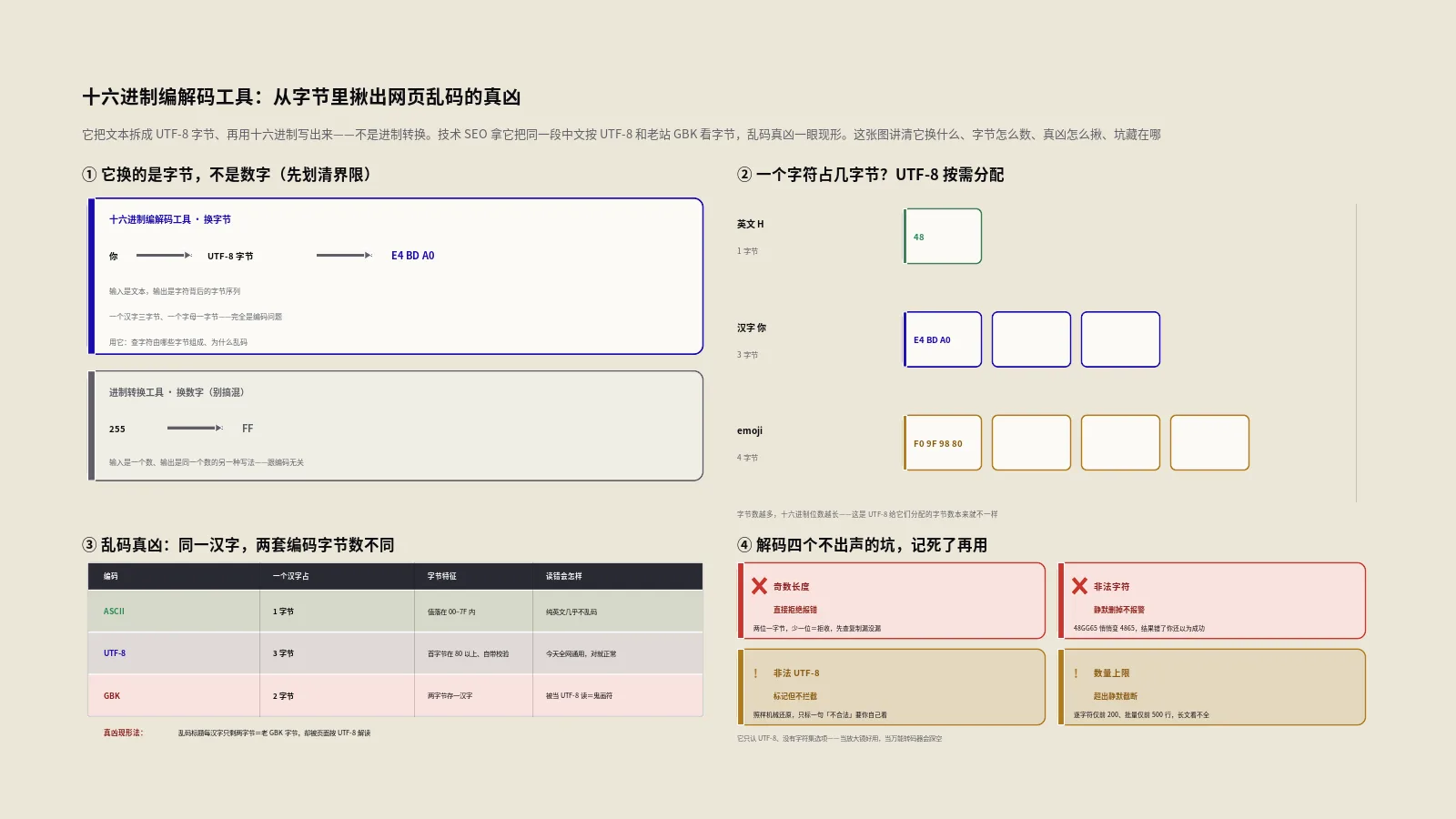
网页中文变成问号方块,光看屏幕永远猜不出原因。这款十六进制编解码工具把文本拆成UTF-8字节摊给你看,本文讲清文本变字节的原理、六种分隔符怎么选、怎么对比字节揪出GBK冒充UTF-8的乱码真凶,以及奇数长度被拒、非法字符静默删除这些不出声的坑。
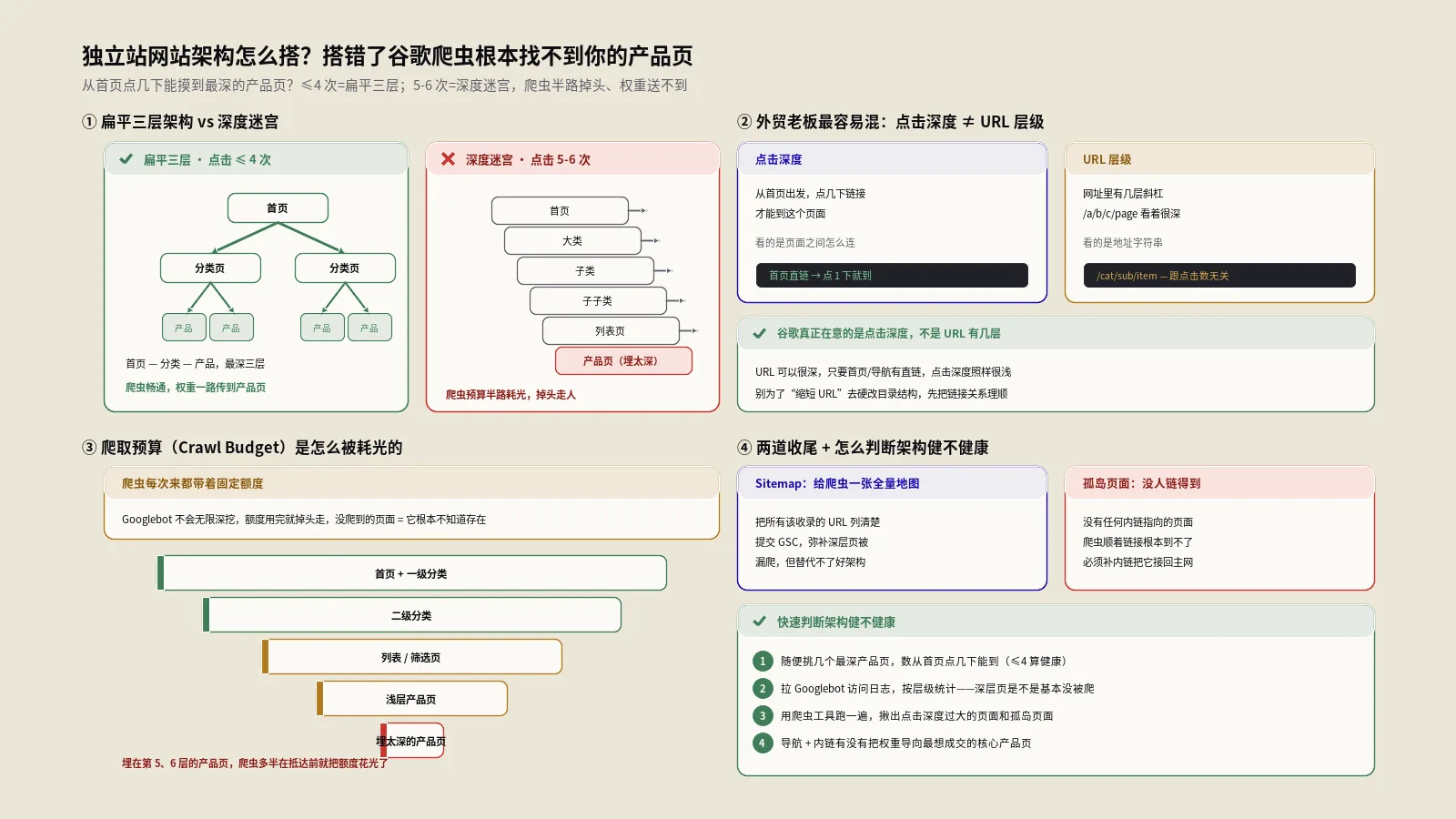
发了几百个产品页,谷歌却只收录零星几个?多半不是内容的锅,而是网站架构这个地基没打好。这篇从外贸独立站视角,把扁平三层结构、点击深度、爬取预算和内链权重一次讲透,帮你把埋在第六层的产品页捞回谷歌眼前。
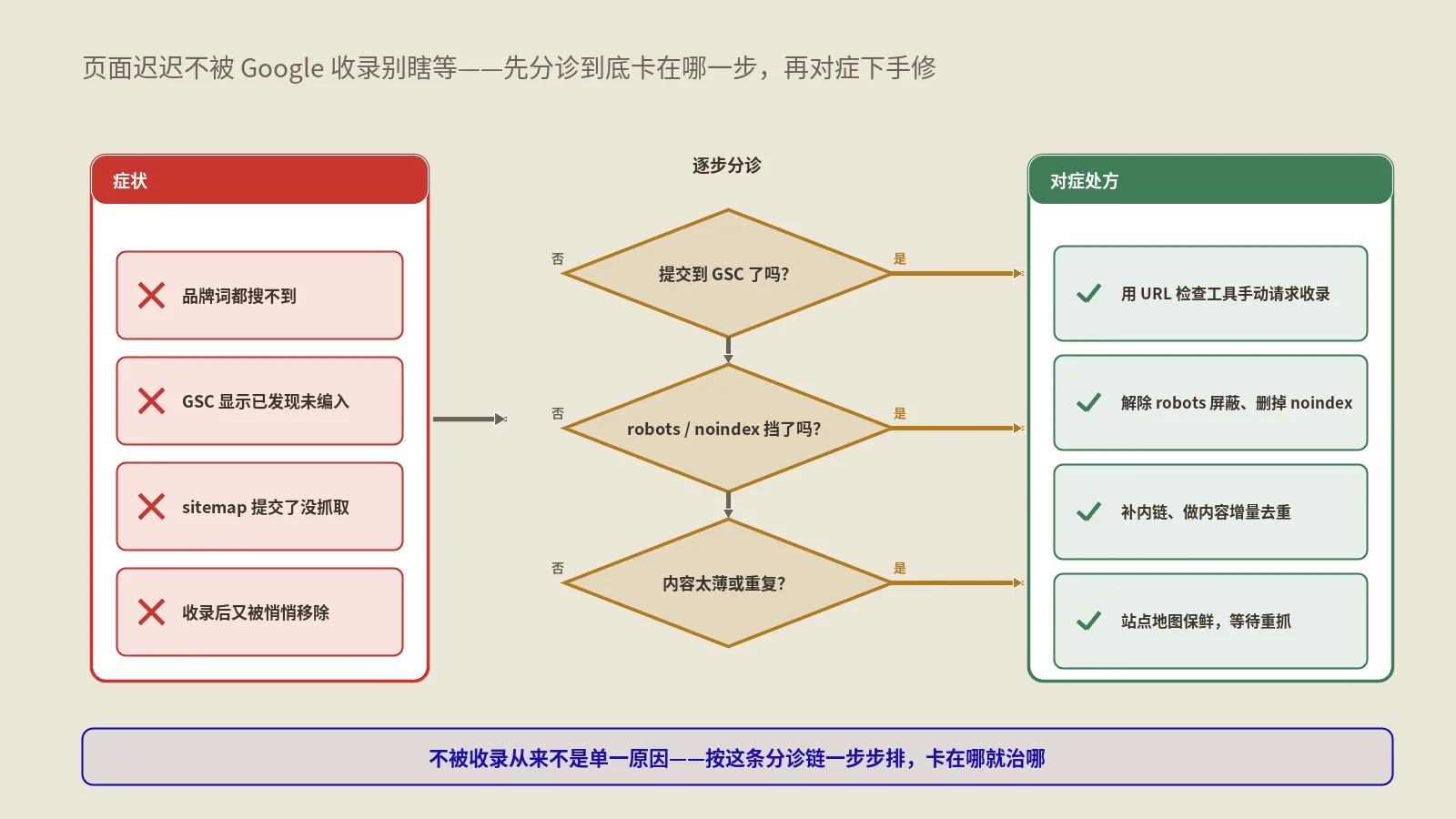
辛苦写的文章发出去,谷歌却迟迟不收,site一查只有首页?这篇从读懂搜索后台的几种未收录状态讲起,按新页、深层页、整站三种情形给出能照着做的排查与修复清单,并戳破不少似是而非的收录传言。
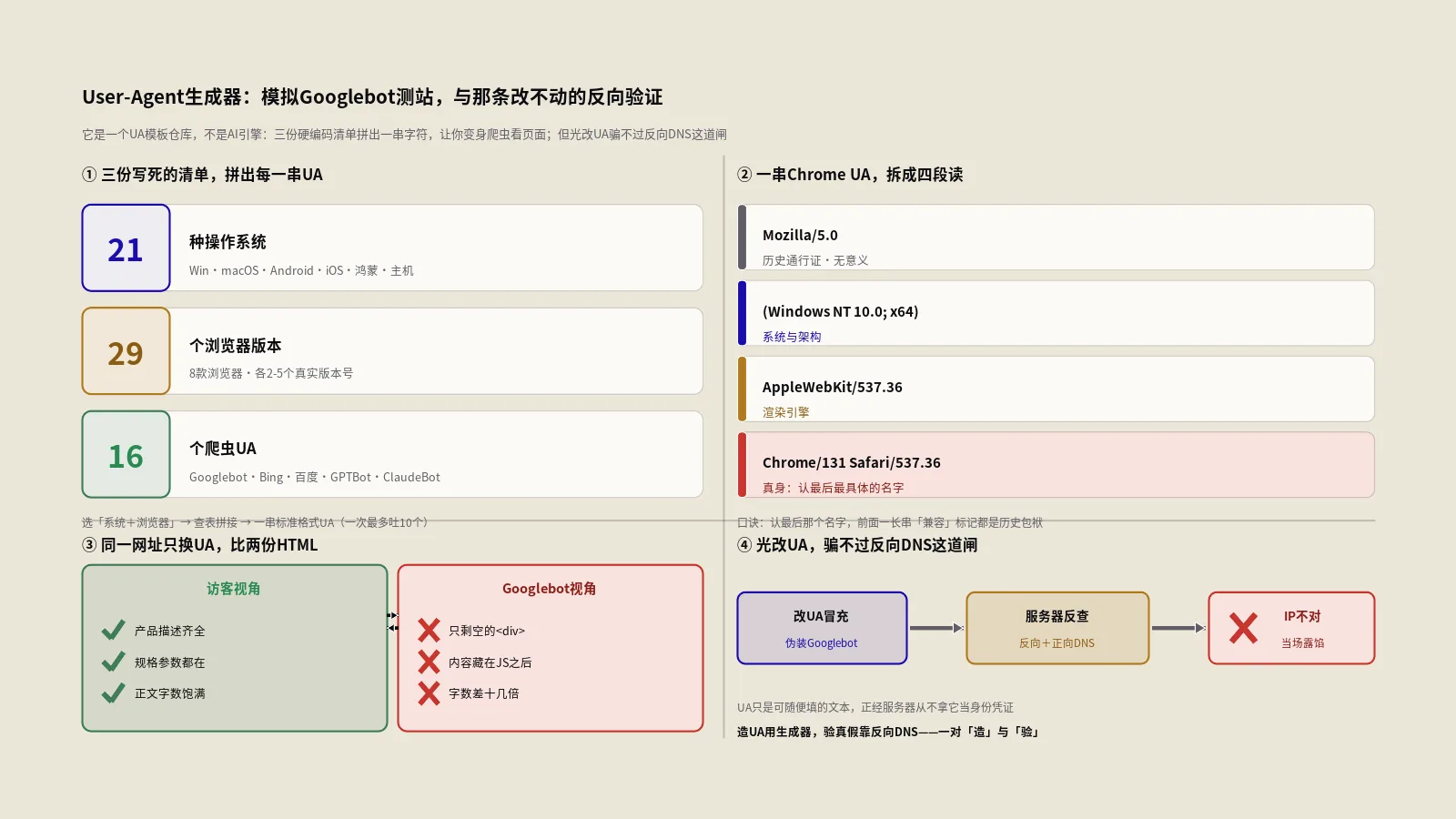
这是一款技术SEO常备的UA字符串工具:选好系统和浏览器,或直接挑一个搜索引擎蜘蛛,它就还你一串规范的身份标识。把它复制进curl或脚本,你就能以蜘蛛的视角重新打开自己的页面,看清收录异常、前端框架空壳、手机版错配这些只在爬虫眼里现形的毛病。
sitemap的lastmod、结构化数据的datePublished、HTTP的Last-Modified,三处日期格式各不相同。本文讲清这款日期格式化工具能给哪些标准格式、它按服务器时区算不做转换的硬边界,以及Last-Modified为什么不能照搬它的输出。

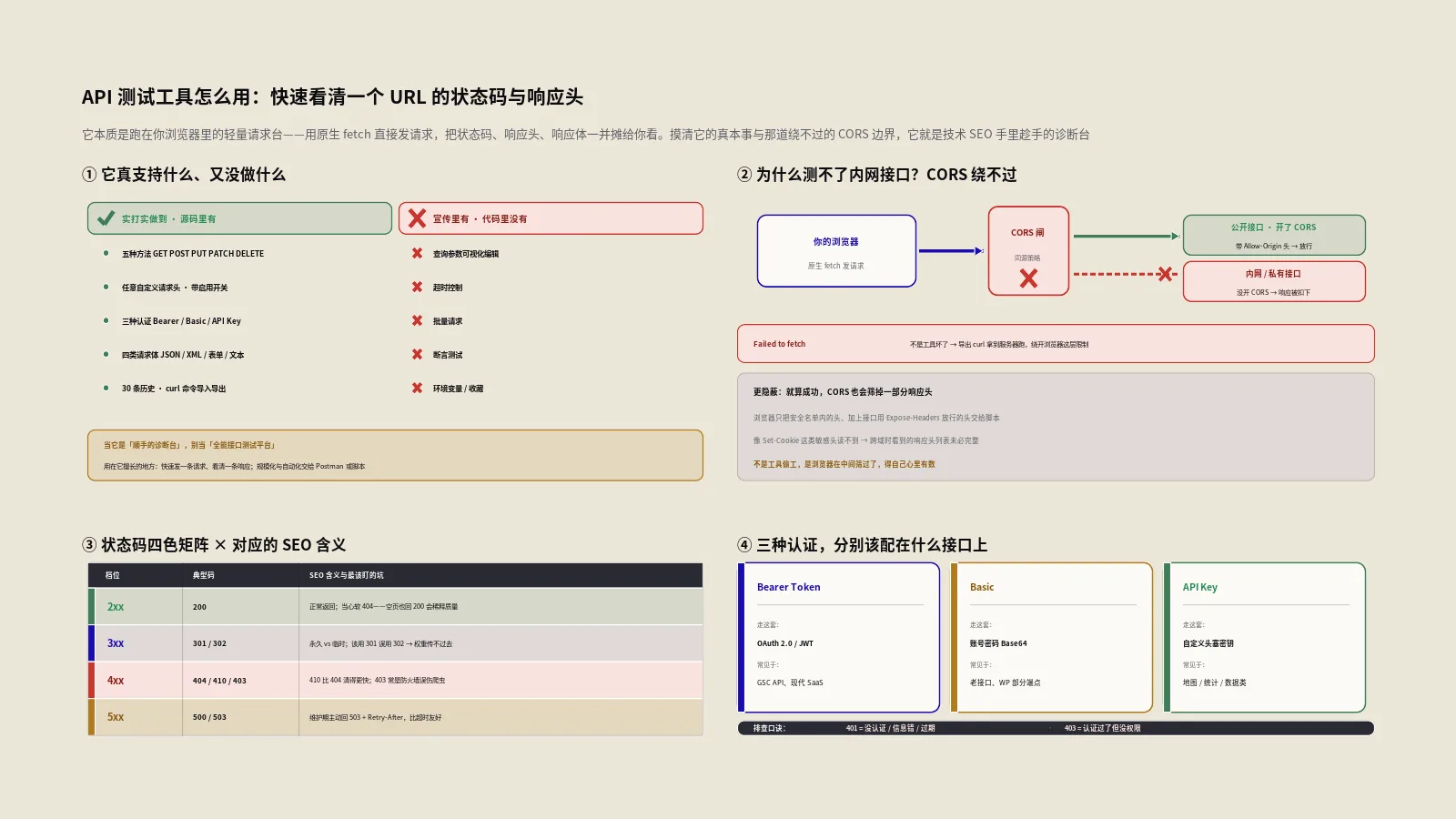
用浏览器就能发请求的轻量接口测试台。本文讲清它靠fetch直发、被CORS死死管着的能力边界,以及怎么拿它查URL状态码、X-Robots-Tag响应头、headless接口返回这些技术SEO日常排查活。
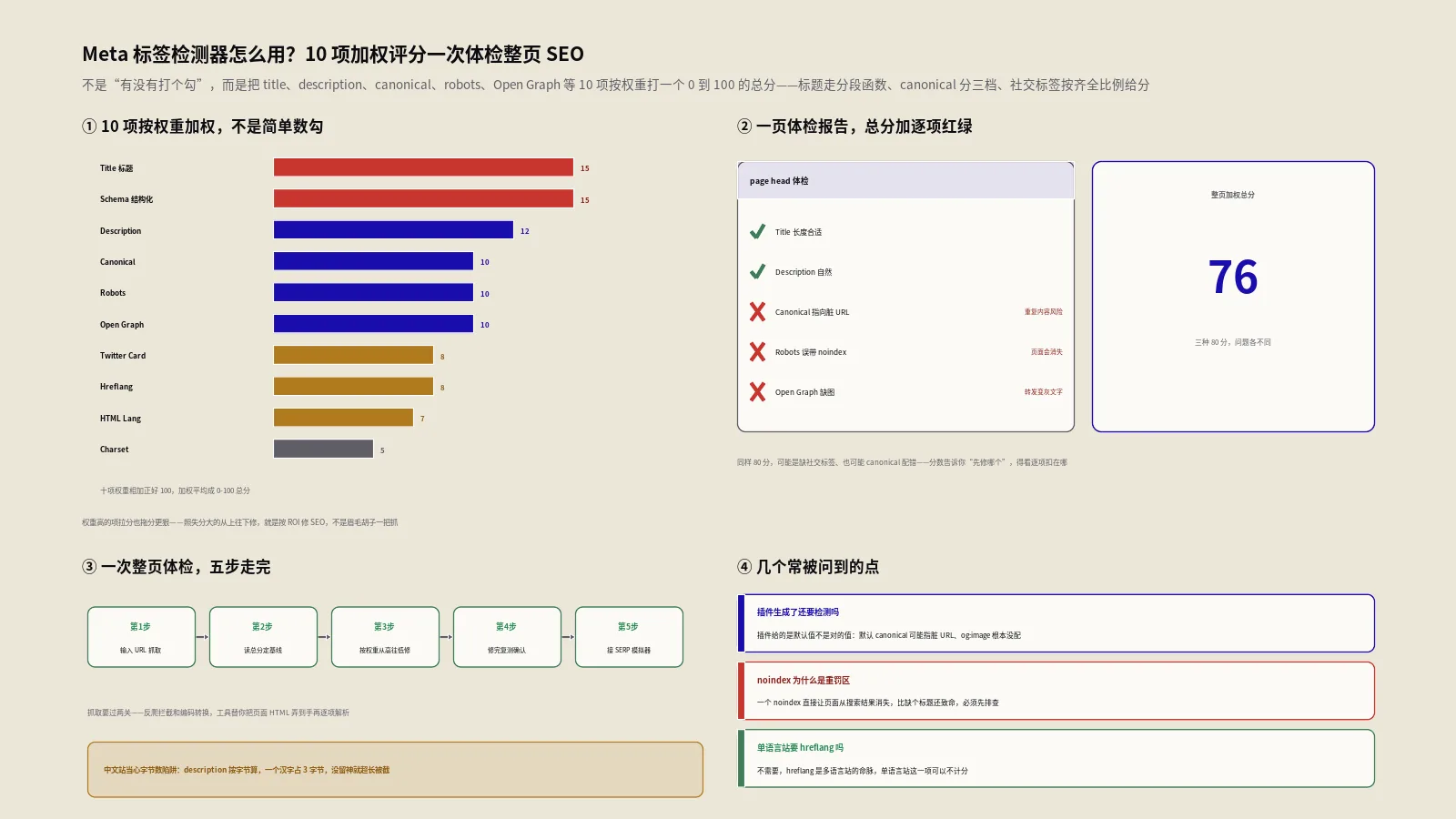
title写了、description也填了,页面SEO就稳了?canonical指错、robots误带noindex这些藏在head里的雷,得靠加权评分一次扫出来。这篇拆透10项权重与扣分逻辑。
保哥拆PWA与传统SEO框架失效根因+Service Worker对Googlebot抓取三层影响+App Shell/SSR/CSR架构对SEO真实差异+manifest与installable+离线缓存与索引一致性三方案+GPTBot/ClaudeBot/Bingbot对SW的处理差异+8类典型PWA SEO问题清单+CWV假数据陷阱+旧站升级PWA四步保稳路线。

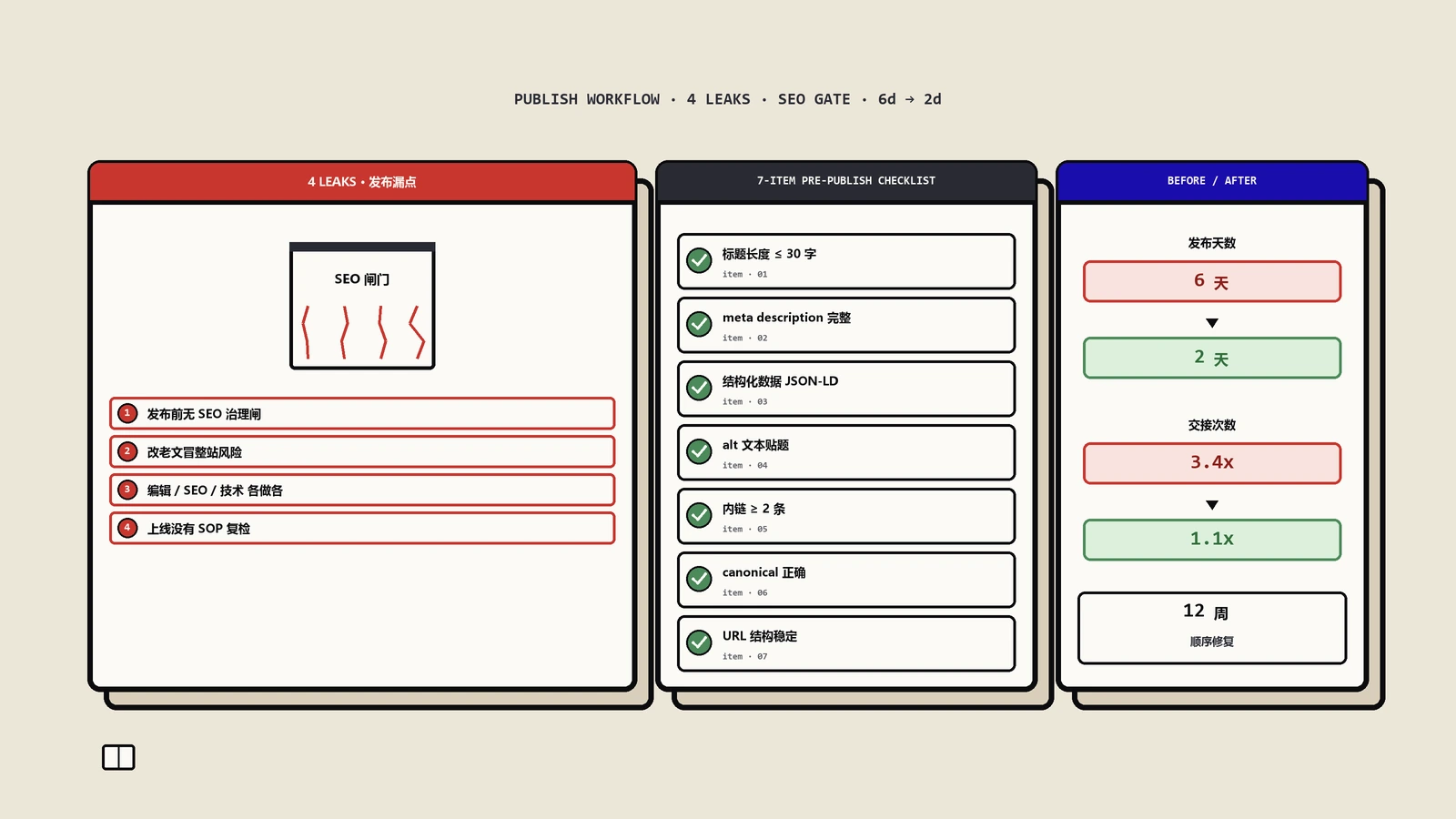
发了几百篇文章自然流量还是平的,问题未必出在内容本身。保哥排查内容站发现,更高频的漏点是发布工序。这篇拆解发布流程碎片化成本的三笔账,给出发布前治理闸、安全改动空间、协作前置、时效内容快速通道四套修法,配出海园艺DTC内容站12周改造复盘,告诉你哪一步在漏分、今天能堵的第一个口子是什么。
独立站SEO指标制定指南,剖析PV、总流量、关键词数等虚荣指标的危害,提供以转化效率、流量质量和长期价值为核心的KPI/OKR框架,结合DTC实战案例帮助电商从流量繁荣转向利润增长。

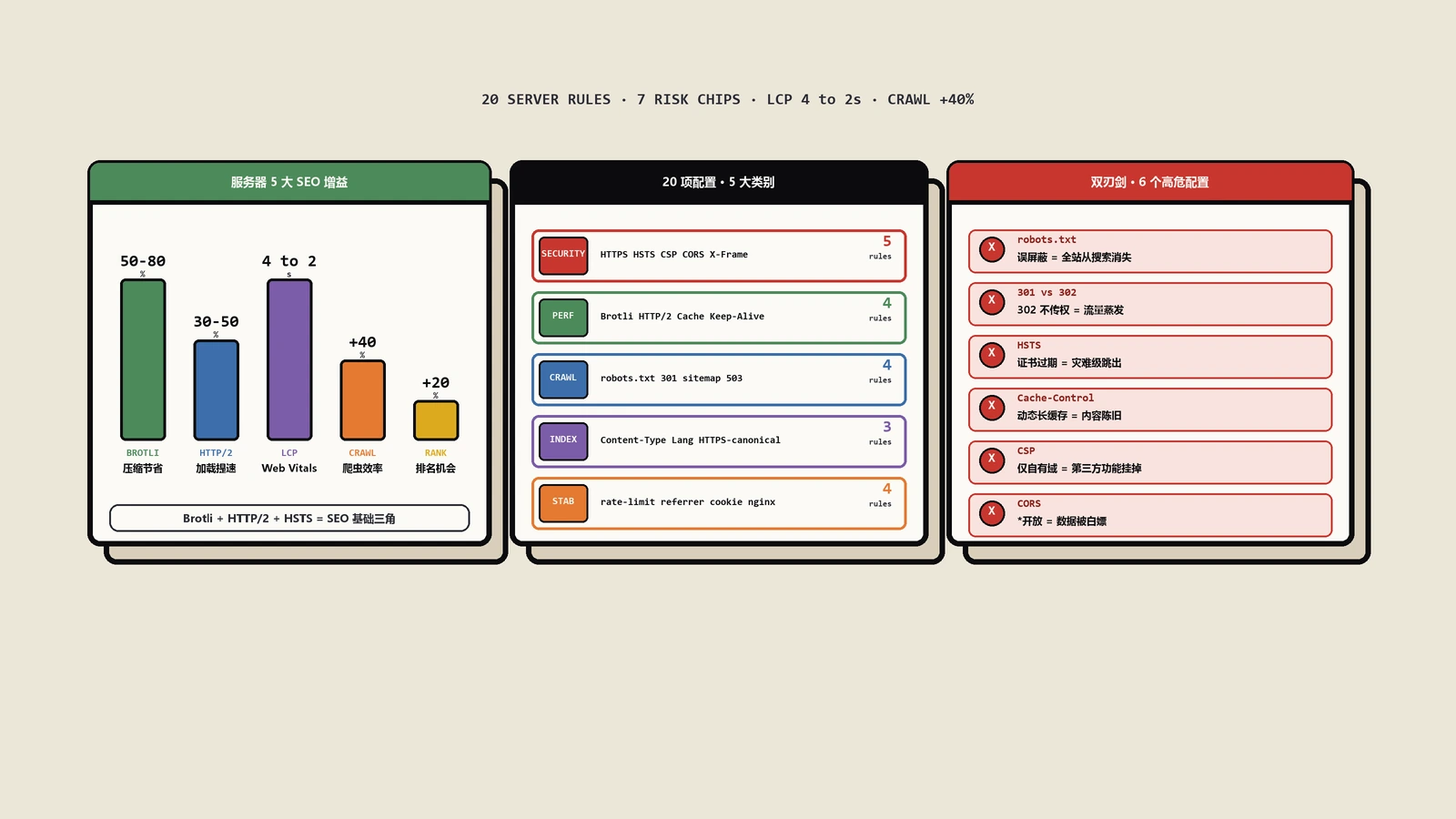
保哥总结的20项常见服务器配置对SEO的利弊:CSP、nosniff、Referrer-Policy、HTTPS与HSTS、缓存、CORS、301与302、robots.txt、Gzip/Brotli、X-Frame-Options、HTTP/2、404与503、Keep-Alive、Cookie安全、速率限制、字符集、反向代理、Content-Language。
前端工程师SEO协作7个动作点综合指南:语义化HTML与可索引性、Core Web Vitals三指标LCP/INP/CLS、渲染策略SSR/SSG/ISR/CSR分桶、客户端路由元数据动态注入、资源加载与图片治理、Search Console联动监控。覆盖22周5团队真实账本、6类客户决策树、12步落地SOP、5类代码层踩坑、5个反信号判断点;面向独立站团队的前端工程师与SEO顾问跨职能协作。

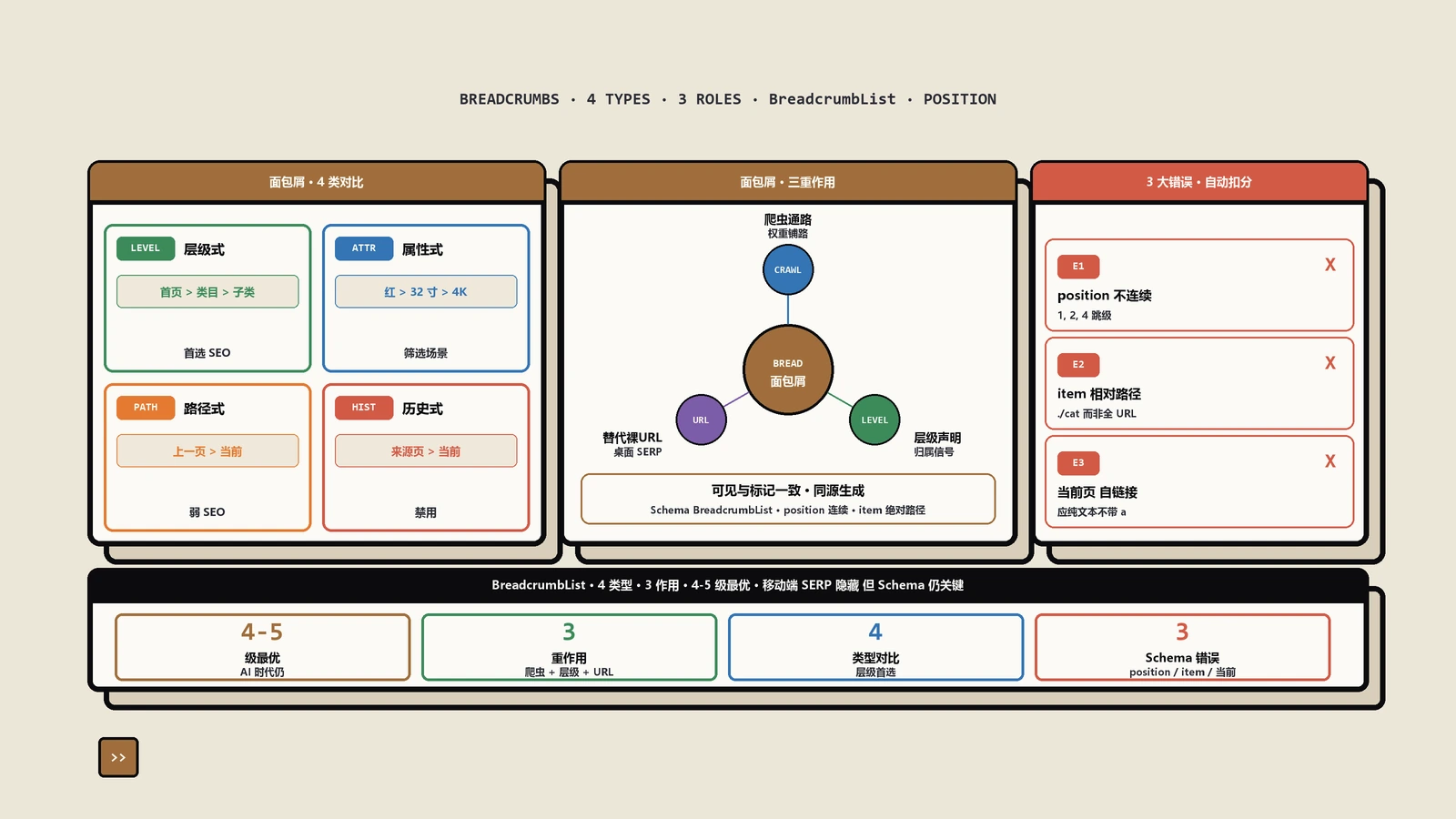
面包屑移动端不显示了就不用做了?这个判断把它真正在干的三件事一起扔了。讲清面包屑通过哪三个机制影响SEO、四种类型怎么选不踩重复坑、BreadcrumbList三个高发错、可见与标记为何必须一致、各平台落地与AI时代的定位。
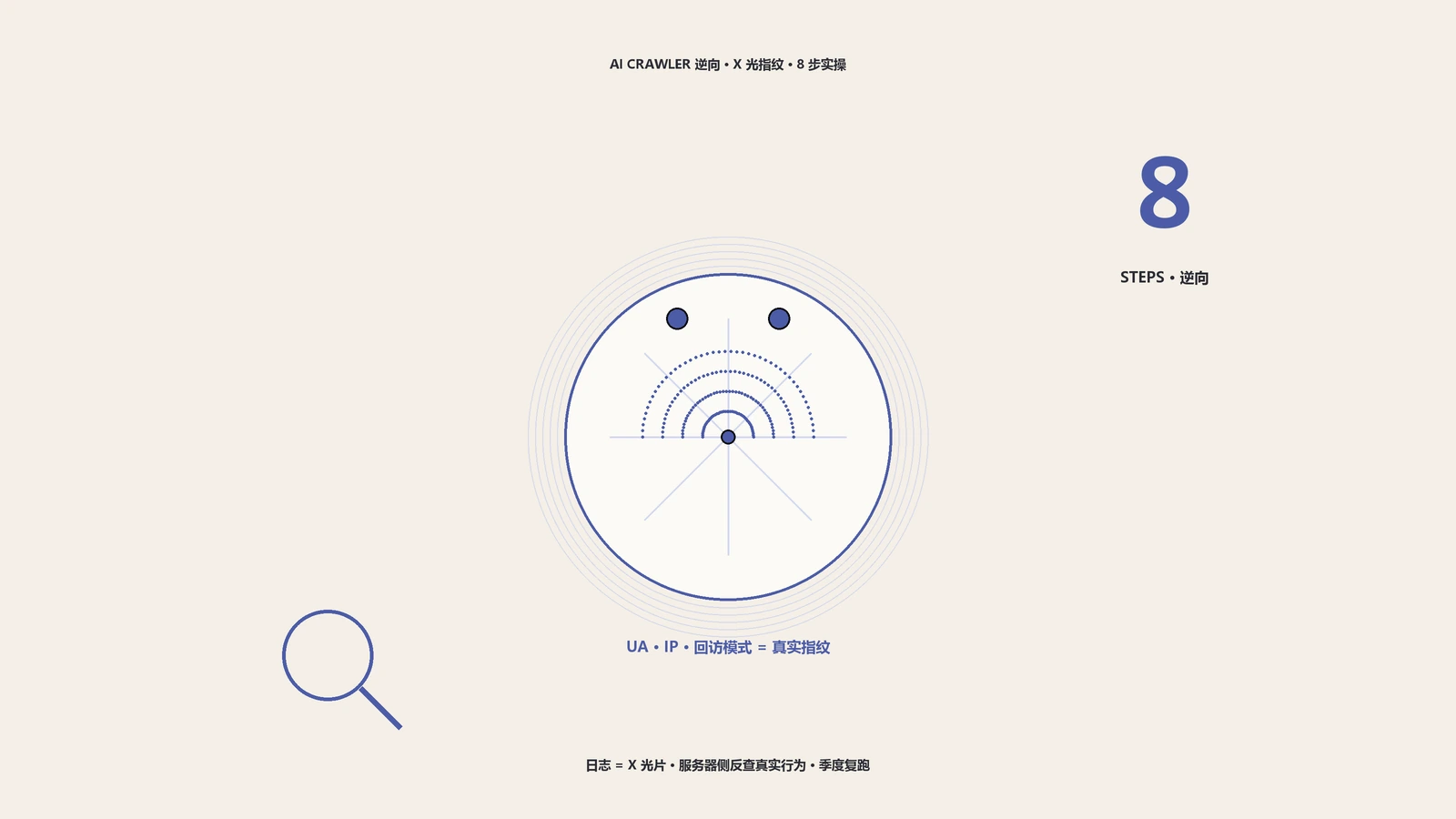
14种AI客户端、3类抓取经济学、5种日志里的病:别再照官方文档和llms.txt模板猜了。这篇用一个能复现请求指纹的模拟器加访问日志反查,把robots、llms.txt、渲染策略从凭感觉改成可验证的工程,再讲清怎么固化成每季度自动复跑的能力
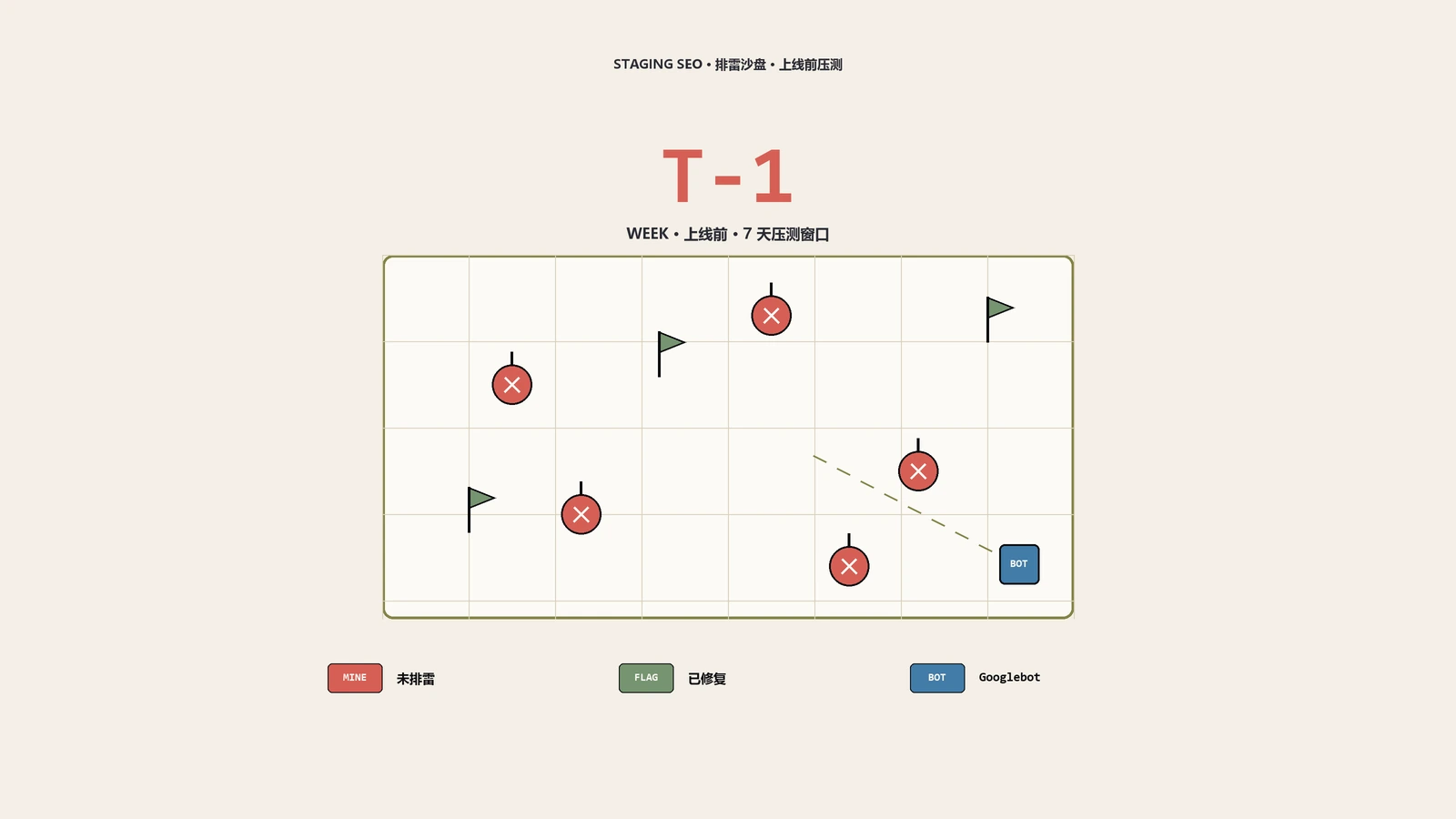
做瑜伽服装的出海独立站客户,改版上线第3天自然流量掉了将近四成。开发团队很委屈:预发布环境点过一圈,页面都正常。问题是他们只用人类浏览器看过,从没用爬虫视角压过——移动端列表页靠JS异步加载,爬虫拿到的是空壳。这篇把预发布环境压测拆成8个可执行维度:镜像生产到什么程度、为什么要多用户代理爬、JS渲染怎么开关双测、SEO元素怎么批量跨页型测、性能基准为什么要先在生产立、哪些边界用例最爱爆雷、为什么每次上线都得重测老bug,最后给一份按上线…
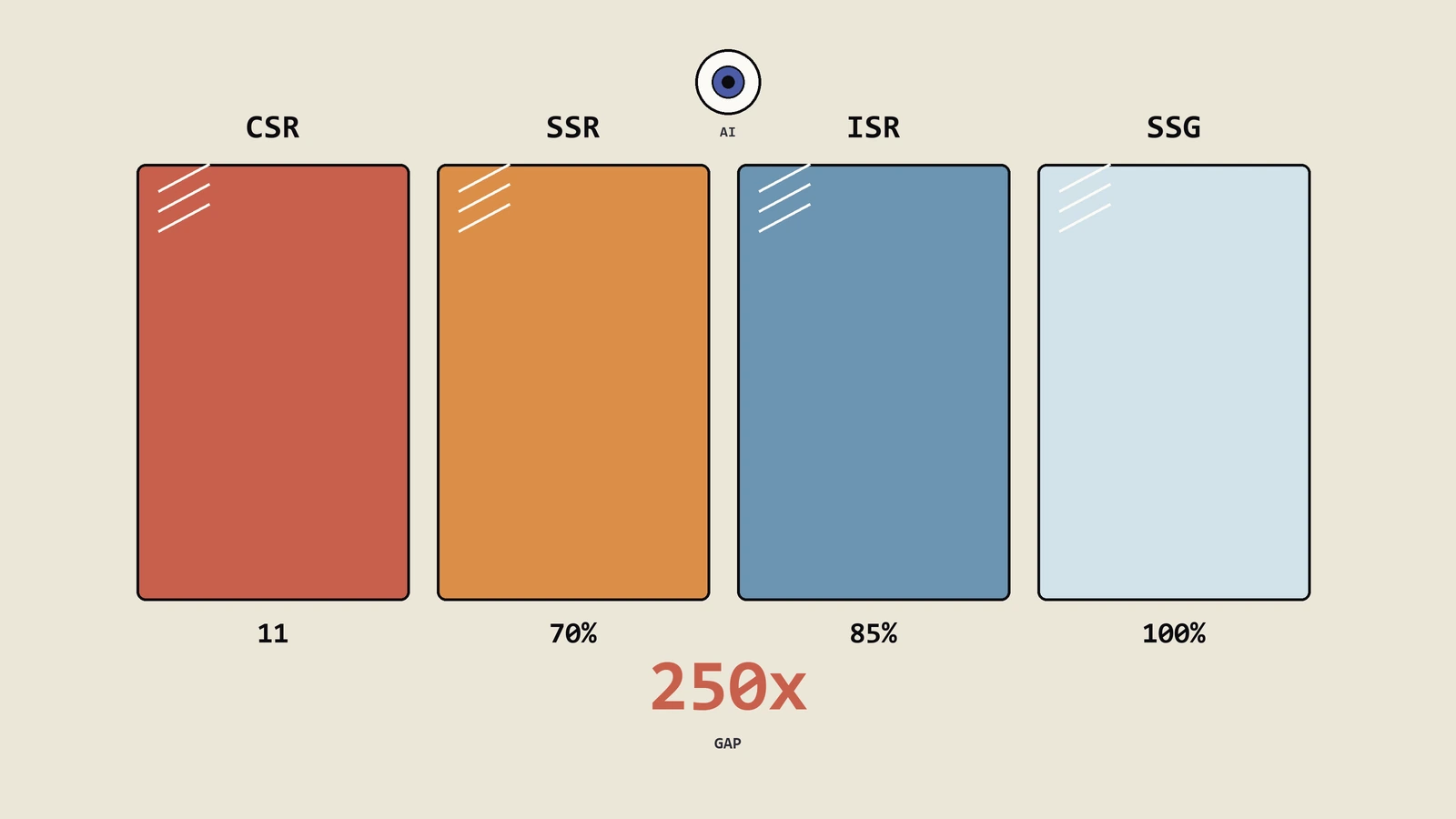
GPTBot普遍不渲染JavaScript,CSR站点对AI爬虫几乎透明。本文实测四象限渲染策略对AI引用率的影响、三家不同栈改造前后数据对照,给一组可在自己服务器跑出来的UA模拟命令,配hydration后改DOM等隐性坑的排查清单。
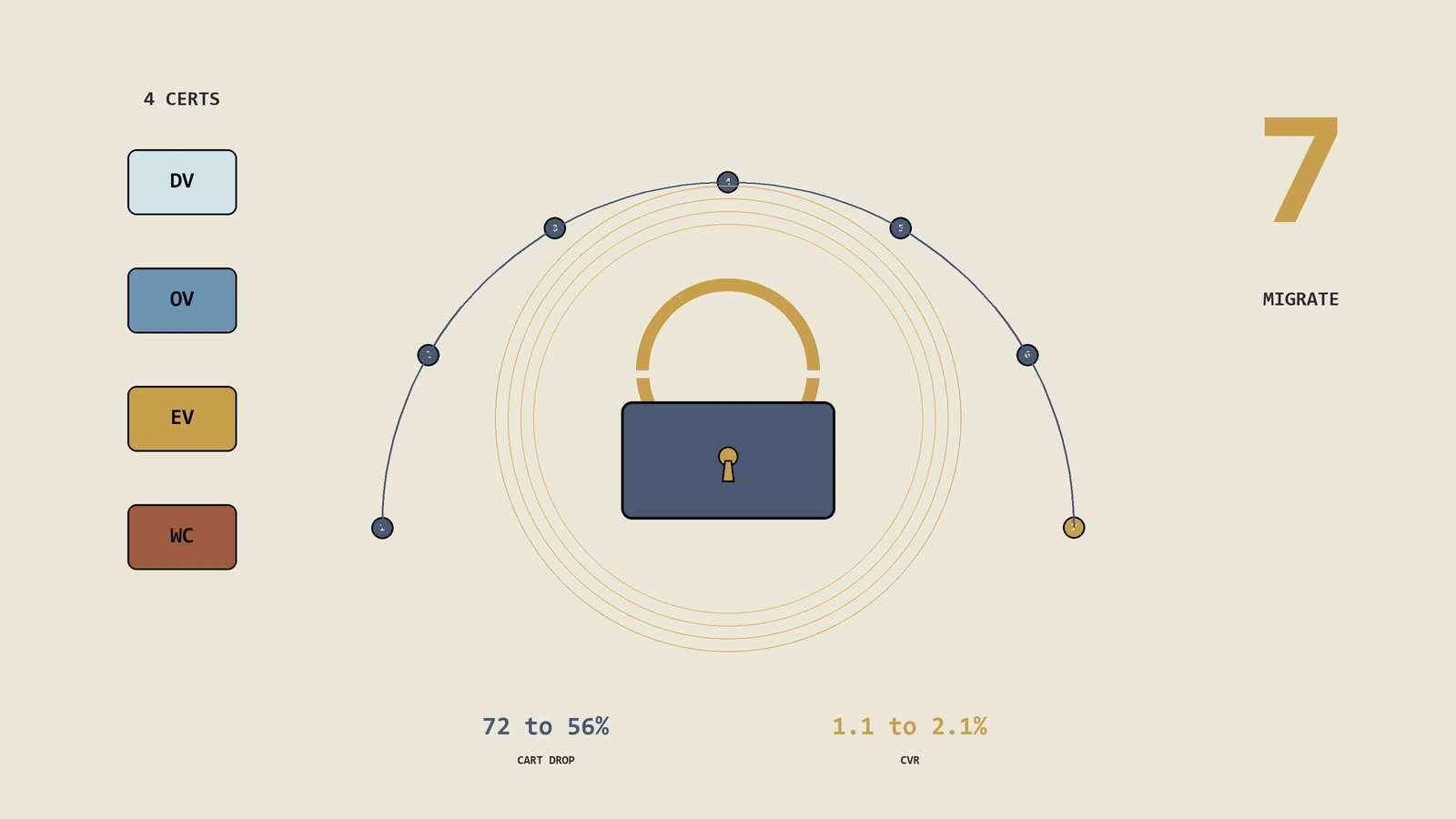
HTTPS到底是不是Google排名因素?证书要选DV还是OV、EV?HTTP迁HTTPS要不要逐页301、哪些环节最容易出错?这篇用一份完整流程清单回答这几个问题。本文从SSL与TLS的关系讲起,对照三种证书的差异和选型逻辑,把HTTP到HTTPS迁移拆成十五个具体动作,配混合内容Mixed Content的三层排查方法、HSTS与CSP等安全头的配置建议,再给迁移后的监控指标清单,最后用一个出海珠宝配饰独立站HTTPS迁移12周从掉…
页面速度对Google排名的权重到底有多大?怎么判断站点在哪一档?要先改图片还是先改服务端?本文从2010年到2026年的算法时间线讲起,拆解LCP、INP、CLS三个指标各自的阈值和触发条件,对照PSI、Lighthouse、WebPageTest、CrUX四个测速工具的数据源差异,把图片资源、JavaScript与CSS、服务端响应三层影响因素分别配诊断方法和修复ROI优先级矩阵,再讲怎么把速度数据接入90天闭环决策流程,最后给一个…
